
你好,我是胡光,欢迎回来。最近为了防范疫情,很多人应该都窝在家里吧?春节假期除了娱乐放松,也不要忘记学习提高呀!
上次呢,我们知道了,原来程序的编译,是一个复杂的过程,其中重要的是三个阶段:预处理阶段,编译阶段和链接阶段 。
同时,我们也搞清楚了“源代码”和“待编译源码”两个概念的区别,其中“待编译源码”是由“源代码”经过预处理阶段所产生的代码,并且“待编译源码”才是决定程序最终功能的终版代码。
今天呢,我们继续上节课的知识,来具体学习几个重要的,能够影响“待编译源码”内容的预处理命令吧。
在正式开始今天课程之前,我们先来回顾一下任务内容:实现一个使用方法和 printf 函数一样的,但是输出信息却比 printf 更加人性化的,更加具体的 log 方法。
具体代码及事例,参考如下:
#include <stdio.h>
void func(int a) {
log("a = %d\n", a);
}
int main() {
int a = 123;
printf("a = %d\n", a);
log("a = %d\n", a);
func(a);
return 0;
}
a = 123
[main, 10] a = 123
[func, 4] a = 123
通过文稿代码可以看到,经过log方法后,我们获得了更多程序信息。但我们的任务是设计完 log 方法以后,请再给这个 log 方法提供一个小开关,使其很方便的打开或者关闭程序中所有 log 的输出信息。
回顾完了任务以后,就让我们一起来进行具体的预处理命令的学习吧。
在上一节,我们明确了 include 文件包含预处理命令的作用。今天,我们将来着重讲解两种预处理命令宏定义与条件编译。它们是什么意思呢?不要着急,听我一个个给你解释。
宏定义在预处理阶段的作用,就是做简单的替换,将 A 内容,替换成 B 内容,这里需要你特别注意的是,一个宏定义只能占一行代码,这可不是你所认为的一行代码,而是编译器所认为的一行代码,这里在后面,我们会详细来介绍一下。
这里先给你准备了一张示意图,用来说明宏定义的基本用法:
正如上图所示,宏定义以 #define 作为语句的开头,之后两部分,用空格分隔,在预处理阶段期间,会把代码中的 A 内容替换成 B 内容,以此来最终生成“待编译源码”。
下面我们就使用宏来实现一个读入圆的半径,输出圆面积的程序:
#include <stdio.h>
#define PI 3.1415926
int main() {
double r;
scanf("%lf", &r);
printf("%lf\n", PI * r * r);
return 0;
}
在上面程序中,我们定义了一个名字为 PI 的宏,其替换内容为3.1415926,也就是圆周率π的相似值。在主函数中,我们读入一个圆的半径值,存储在 r 变量中,然后输出圆的面积,在计算圆面积公式的时候,我们没有使用圆周率本来值来进行程序书写,而是使用刚刚上面定义的宏 PI 代替了圆周率的作用。
面对这份源代码,在预处理阶段的时候,编译器会把代码中所有使用 PI 的地方,都替换成3.1415926,也就是说,上述代码中的输出函数中,原本的 PI * r * r 的代码内容,会被编译器改写成为 3.1415926 * r * r 作为“待编译源码”。
通过这个例子,我想你就能差不多明白了,什么叫做“宏定义在预处理阶段做的就是简单的替换”以及“宏定义在代码中,只能占一行”,简单来说,就是宏定义关键字、原内容和替换内容 三者必须写到一行。
前面呢,我们说的是宏定义的最基本用法。其实,宏定义中的“原内容”的形式,不仅仅有刚才的类似于 PI 这种简单符号,还有一种更加灵活实用的带参数的形式,如图所示:

可以看到,我们定义了一个支持两个参数的宏,名字为 mul,替换的内容为 a * b。注意,替换内容中的 a 是宏参数中的 a,b 也是宏参数中的 b。这里我再强调一下,理解宏的工作过程,始终离不开那句话:宏做的就是简单替换。
下面给你举个例子:
#include <stdio.h>
#define mul(a, b) a * b
int main() {
printf("mul(3, 5) = %d\n", mul(3, 5));
printf("mul(3 + 4, 5) = %d\n", mul(3 + 4, 5));
return 0;
}
上面代码中,使用了 mul 宏,分别输出了 mul(3, 5) 的值,和 mul(3 + 4, 5) 的值。如果你把 mul 当成函数看待的话,你应该会觉得,第一行输出的值应该是 15,即 3 * 5 结果;第二行应该是 35,计算的应该是 7 * 5 的结果。
可如果你在你的环境中运行这个代码,你会看到第一行输出的结果确实是 15,和我们的预期一样,可第二行输出的却是 23,这个离我们预想的可就有点儿不一样了。
想要理解为什么输出的是 23,而不是 35 的话,我们需要综合以下两点来进行思考:
宏在预处理阶段将被展开,变成“待编译源码”中的内容,并且做的仅仅是简单的替换。也就是说,mul(a, b) 这个宏,替换的形式是 a * b;而 mul(3 + 4, 5) 中 3 + 4 是参数 a 的内容,5 是 b 的内容,依次替换为 a*b 式中的 a,b 的话,最终得到的替换内容应该是 “3 + 4 * 5”,这个才是“待编译源码”中真正的内容。面对这个替换以后的表达式,你就知道为什么输出的结果是 23,而不是 35 了吧。
所以,正如你所看到的,mul 的使用形式虽然和函数类似,可实际运行原理和函数完全不一样,甚至显得有些机械化。因为 mul 是宏,而宏做的就是简单的替换操作,变成最终的“待编译源码”中的内容。这个过程机械且简单,所以,我们有时也称其为傻瓜表达式。
再回来看上面的 mul 宏,使用形式像函数,但函数可以在代码中写成多行的一段代码。可宏呢,只能写成一行,就会使得当我们面对稍微复杂一点的替换内容,宏代码的可读性就会变得特别差。
还好,C 语言给我们提供了一种在行尾加 \(反斜杠)的语法,以此来告诉编译器,本行和下一行其实是同一行内容。这样就做到了:人在阅读代码的时候,看到的是两行代码,而编译器在解析的时候,会认为是一行代码,也就解决了复杂的宏定义的可读性的问题。
具体事例,看如下代码:
#include <stdio.h>
#define swap(a, b) { \
__typeof(a) __temp = a; \
a = b, b = __temp; \
}
int main() {
int num_a = 123, num_b = 456;
swap(num_a, num_b);
printf("num_a = %d\n", num_a);
printf("num_b = %d\n", num_b);
return 0;
}
如上代码中,我们定义了一个用于交换两个变量值的宏 swap,代码的第 2、3、4 行的末尾都有一个反斜杠,编译器就会认为把程序的这几行内容当成一行内容来对待。这样,既保证了宏定义的只占用一行的语法要求,又兼顾了代码可读性。
需要特别注意的是,代码中反斜杠的后面,不能出现任何其他内容。作为新手的话,这里是最容易出错的,很多人会在反斜杠后面多打一个空格,会导致反斜杠失去原本的作用,代码查错的时候,也不容易被发现,这里一定要十分小心。
此外,你看到上述代码中,多了一个__typeof方法,关于这个方法的作用呢,给你留个小的作业题,请你自行查阅相关资料,并用一句话描述 __typeof 的作用。欢迎在专栏的留言区里面写下你认为足够简洁的 __typeof的功能描述。
看完了宏定义之后,下面来让我们看看另一个使用的比较频繁的预处理命令:条件编译。说到条件编译,光看名字,你也许会联想到 if 条件分支语句。对,条件编译,就是预处理阶段的条件分支语句,其主要作用是根据条件,决定“源代码”中的哪些代码,接下来会被预处理继续进行处理。
我们先来从最容易理解的条件编译开始看起,来了解一下条件编译的语法格式:

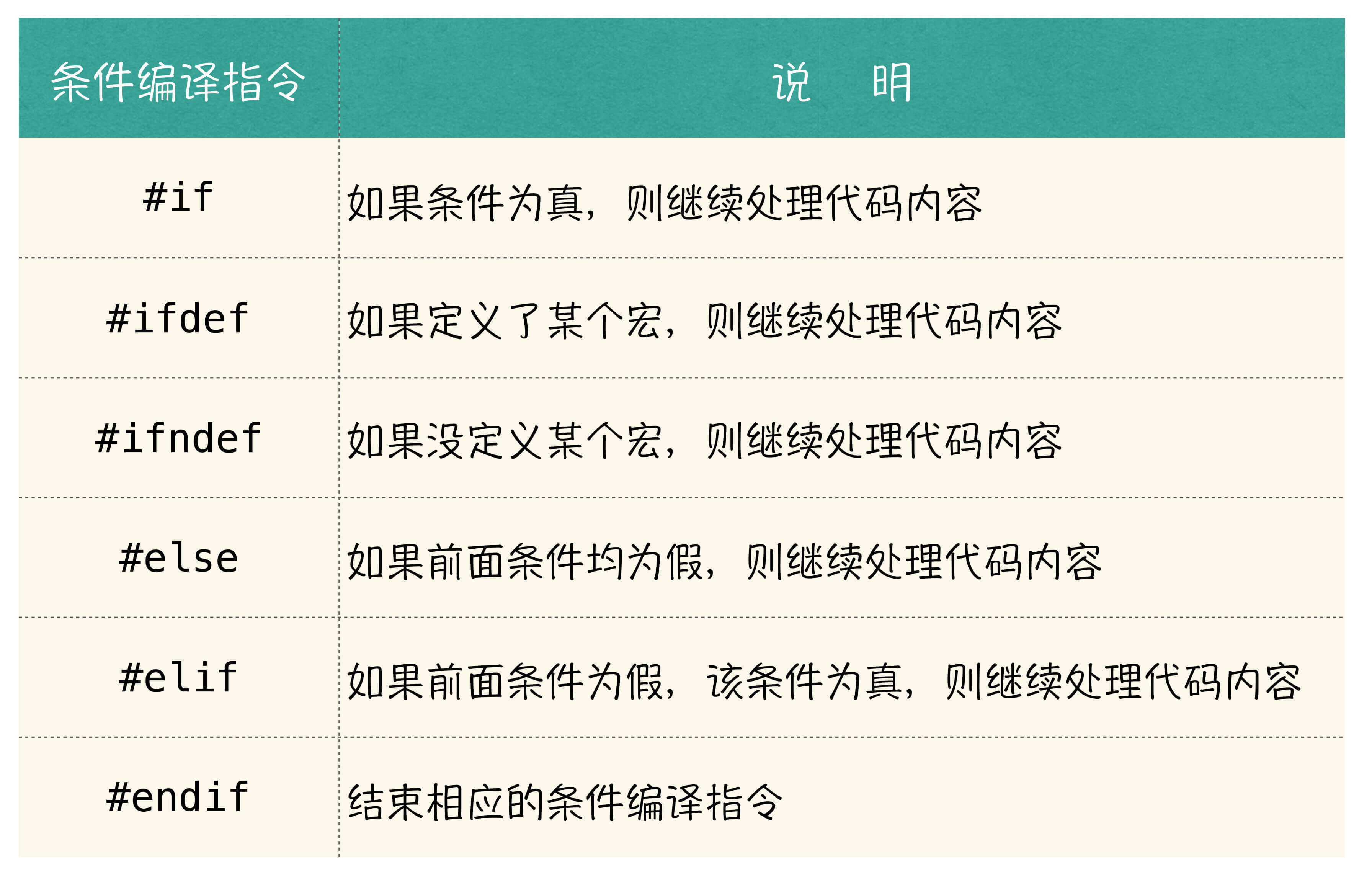
如图所示,这个条件编译以指令 #ifdef 作为开头,后面接了一个 Debug。意思是如果定义了Debug 这个宏,就让预处理器继续处理“代码内容1”,否则就处理“代码内容2”。记住,条件编译,可以没有 #else 部分,可最后一定要以 #endif 作为结束。
下面给你举个简单的例子:
#include <stdio.h>
#define Debug
#ifdef Debug
#define MAX_N 1000
#else
#define MAX_N 5000
#endif
int main() {
printf("MAX_N = %d\n", MAX_N);
return 0;
}
如果你运行上面这段代码,你的程序一定会输出 MAX_N = 1000,那是因为当代码运行到条件编译的时候,由于之前定义了 Debug 宏,条件编译的条件成立,保留的是第 4 行代码内容,所以主函数中的 MAX_N 宏最终就会被替换成为 1000。
如果你将第2行代码去掉的话,那么条件编译的条件就不成立了,最终被保留下来的是第 6 行代码,程序就会输出 MAX_N = 5000,关于这点,你可以自行尝试一下。
其实在条件编译中,除了我们刚才讲到的三个指令:#ifdef、#else、#endif 之外,还有 #if、#ifndef 以及 #elif 等指令。关于剩下的三个指令的含义和作用,有了这个基础之后,你就可以很轻松的学会了,我就不再赘述了。
我在这里给你准备了一张对照表,以说明这 6 个指令各自的作用:
请你完善下面代码中的 MAX 宏,MAX 宏的作用,就是接受两个元素,选择出两个元素中的最大值。完善以后的 MAX 宏,输出需要与如下给出的输出样例一致,注意,只能修改 MAX 宏的定义内容,不可以修改主函数中的内容。
#include <stdio.h>
#define P(item) printf("%s = %d\n", #item, item);
#define MAX(a, b) // TODO
int main() {
int a = 6;
P(MAX(2, 3));
P(5 + MAX(2, 3));
P(MAX(2, MAX(3, 4)));
P(MAX(2, 3 > 4 ? 3 : 4));
P(MAX(a++, 5));
P(a);
return 0;
}
输出结果参考:
MAX(2, 3) = 3
5 + MAX(2, 3) = 8
MAX(2, MAX(3, 4)) = 4
MAX(2, 3 > 4 ? 3 : 4) = 4
MAX(a++, 5) = 6
a = 7
准备完了上面的这些基础知识以后,下面来让我们回到最开始的那个任务。
首先我们来思考,要实现一个和 printf 使用方式一样的 log 方法, printf 函数是一个变参函数,那么 log 也需要支持变参,而 log 方法又比 printf 输出的更人性化一些,其中包括了可以输出所在的函数信息,以及所在的代码位置信息。这里,我们选择使用宏定义来实现所谓的 log 方法。
下面,就给你再补充一个小知识点,就是如何定义一个支持可变参数的 log 宏,看如下代码:
#define log(frm, args...) // 假装这里有内容,后续展开讲解
如上代码所示,在最后一个参数后面,加上三个点,就代表,这个宏除了第一个 frm 参数以外,后面接收的参数个数是可变的,那么后面的参数内容,统一存放在参数 args 中。
这样,我们就可以设计如下代码,使得 log 方法的使用方式与 printf 类似了:
#define log(frm, args...) printf(frm, args)
此时,log 方法的输出内容,只是和 printf 方法的输出内容是一致的,还无法输出所在函数以及所在代码位置的相关信息。
下面,我们来补充最后一个知识点,就是编译器会预设一些宏,这些宏会为我们提供很多与代码相关的有用信息,具体如下表所示:
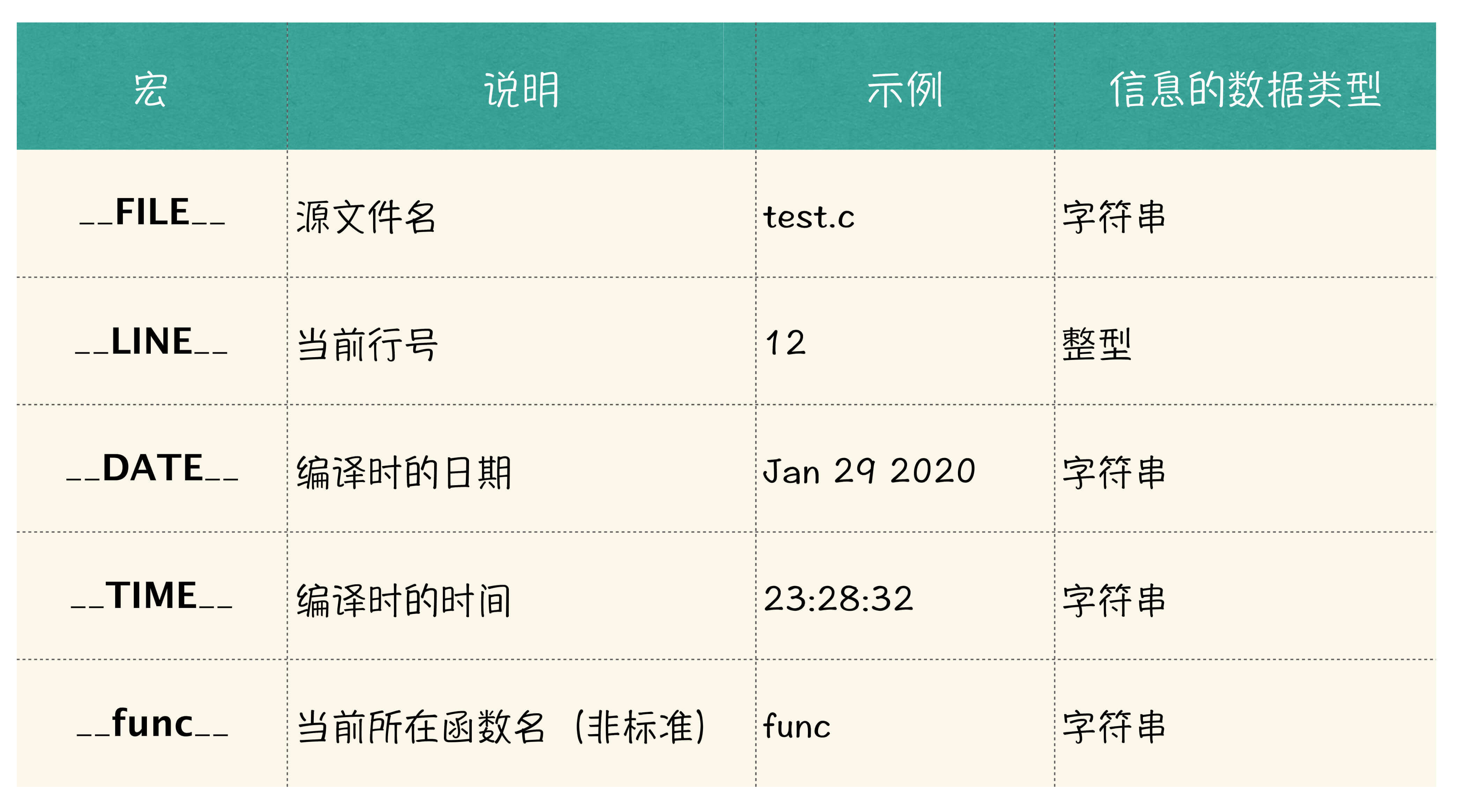
我们看到表中有两个宏,是我们这个任务所需要的,一个是 __func__代表了当前所在的函数名,另一个是__LINE__代表了当前行号。
其中宏__func__后面的说明中,注明了是“非标准”,什么叫做非标准呢,也就是说,在不同的编译器中,这个宏的名称可能是不同的,甚至某些编译器不提供这个宏,也是有可能的。例如在 VC 6.0 的环境中就没有__func__宏,因为这个宏不是 C 语言标准里面的东西。
通过这个__func__宏,我想让你初步认识到什么是代码的 “可移植性”,也就是说,你写了一份代码,当你的运行环境发生改变时,你的代码到底要不要做修改?如果要做修改,到底要做多少修改?这是代码的可移植性所讨论的问题。
放到今天这个例子中,就是说,如果你在你的代码中,不做任何处理的,直接使用__func__宏,那么就会影响你代码的可移植性。如果还不清楚什么是代码的可移植性,你就回想一下,当初我们输出彩色文字的那个代码,是不是在有些人的环境中,无法输出彩色文字?
最后,有了这些基础知识以后,就不难完成这个任务了,下面是我给出的 log 宏的参考代码:
#define log(frm, args...) {
printf("[%s : %d] ",__func__,__LINE__); \
printf(frm, args); \
}
正如你看到的,log 宏的定义中,使用了编写多行宏的技巧,就是在行尾添加反斜杠,以达到增强代码可读性的目的。然后 log 宏中,包含两个 printf 输出语句,第一个 printf 语句,输出函数以及代码位置信息;第二个 printf语句,输出 log 宏所接收的内容。
至此,我们看似完成了最初的任务,可不要高兴太早,所有与宏相关的东西,都没那么简单。上面的这个实现,其实是有 Bug,不信的话,你就在你的环境中,尝试像如下代码一样调用 log 宏:
log("hello world\n");
这个就是今天给你留的最后一个需要自己独立解决的小 Bug,记住,勤用及善用搜索引擎,会大大提升你的学习效率和效果。至于如何方便的开关日志输出,参考今天的条件编译,思考一下,我相信这个难不倒你。
通过这个任务呢,我们大体的认识了预处理命令家族,算是全方位地了解了宏及条件编译相关的内容。下面呢,我来给你做一下今天这节课的课程小结:
至此,我们就完成了“语言基础篇”的全部内容,从下一节开始呢,我们将进入注重培养编程思维“编码能力训练篇”的学习。届时,我们的学习更偏重于思维方式的训练和讲解,不会像语言基础篇一样,有这么多零零碎碎的知识点。我也相信,只要你勤于思考,就一定跟得上学习节奏。
好了,今天就到这里了,我是胡光,我们“编码能力训练篇”,不见不散。
评论