
你好,我是四火。
HTTP 协议是互联网基础中的基础,和很多技术谈具体应用场景不同的是,几乎所有的互联网服务都是它的应用,没有它,互联网的“互联”将无从谈起,因此我们把它作为正式学习的开篇。
说到其原理和协议本身,我相信大多数人都能说出个大概来,比如,有哪些常见的方法,常见 HTTP 头,返回码的含义等等。但你是否想过,这个古老而富有生命力的互联网“基石”是怎样发展演化过来的呢?从它身上,我们能否管中窥豹,一叶知秋,找到互联网成长和演进的影子?
今天,我想带你从实践的角度,亲身感受下这个过程,相信除了 HTTP 本身,你还可以发现网络协议发展过程中的一些通用和具有共性的东西。
和很多其它协议一样,1991年,HTTP 在最开始的 0.9 版就定义了协议最核心的内容,虽说从功能上看只是具备了如今内容的一个小小的子集。比如,确定了客户端、服务端的这种基本结构,使用域名/IP 加端口号来确定目标地址的方式,还有换行回车作为基本的分隔符。
它非常简单,不支持请求正文,不支持除了 GET 以外的其它方法,不支持头部,甚至没有版本号的显式指定,而且整个请求只有一行,因而也被称为“The One-line Protocol”。比如:
GET /target.html
虽说 0.9 版本如今已经极少见到了,但幸运的是 Google 还依然支持(Bing 和 Baidu 不支持)。我们不妨自己动手,实践一下!虽然不能使用浏览器,但别忘了,我们还有一个更古老的工具 telnet。在命令行下建立连接:
telnet www.google.com 80
你会看到类似这样的提示:
Trying 2607:f8b0:400a:803::2004...
Connected to www.google.com.
Escape character is '^]'.
好,现在输入以下请求:
GET /
(请注意这里没有版本号,并不代表 HTTP 协议没有版本号,而是 0.9 版本的协议定义的请求中就是不带有版本号,这其实是该版本的一个缺陷)
接着,你会看到 Google 把首页 HTML 返回了:
HTTP/1.0 200 OK
...(此处省略多行HTTP 头)
...(此处省略正文)
到了1996年,HTTP 1.0 版本就稳定而成熟了,也是如今浏览器广泛支持的最低版本 HTTP 协议。引入了返回码,引入了 header,引入了多字符集,也终于支持多行请求了。
当然,它的问题也还有很多,支持的特性也远没有后来的 1.1 版本多样。比如,方法只支持 GET、HEAD、POST 这几个。但是,麻雀虽小五脏俱全,这是第一个具备广泛实际应用价值的协议版本。
你一样可以用和前面类似的方法来亲自动手实践一下,不过,HTTP 1.0 因为支持多行文本的请求,单纯使用 telnet 已经无法很好地一次发送它们了,其中一个解决办法就是使用 netcat。
好,我们先手写一份 HTTP/1.0 的多行请求,并保存到一个文件 request.txt 中:
GET / HTTP/1.0
User-Agent: Mozilla/1.22 (compatible; MSIE 2.0; Windows 3.1)
Accept: text/html
(根据协议,无论请求还是响应,在 HTTP 的头部结束后,必须增加一个额外的换行回车,因此上述代码最后这个空行是必须的,如果是 POST 请求,那么通常在这个空行之后会有正文)
你看上面的 User-Agent,我写入了一个假的浏览器和操作系统版本,假装我穿越来自 Window 3.1 的年代,并且用的是 IE 2.0,这样一来,我想不会有人比我更“老”了吧。
好,接着用类似的方法,使用 netcat 来发送这个请求:
netcat www.google.com 80 < ~/Downloads/request.txt
一样从 Google 收到了成功的报文。
不知这样的几次动手是否能给你一个启示:懂一点特定的协议,使用简单的命令行和文本编辑工具,我们就已经可以做很多事情了。比如上面这样改变 UA 头的办法,可以模拟不同的浏览器,就是用来分析浏览器适配(指根据不同浏览器的兼容性返回不同的页面数据)的常用方法。
1999 年,著名的 RFC2616,在 1.0 的基础上,大量帮助传输效率提升的特性被加入。
你可能知道,从网络协议分层上看, TCP 协议在 HTTP 协议的下方(TCP 是在 OSI 7 层协议的第 4 层,而 HTTP 则是在最高的第 7 层应用层,因此,前者更加“底层”一点)。
在 HTTP 1.0 版本时,每一组请求和响应的交互,都要完成一次 TCP 的连接和关闭操作,这在曾经的互联网资源比较贫瘠的时候并没有暴露出多大的问题,但随着互联网的迅速发展,这种通讯模式显然过于低效了。
于是这个问题的解决方案——HTTP 的长连接,就自然而然地出现了,它指的是打开一次 TCP 连接,可以被连续几次报文传输重用,这样一来,我们就不需要给每次请求和响应都创建专门的连接了:
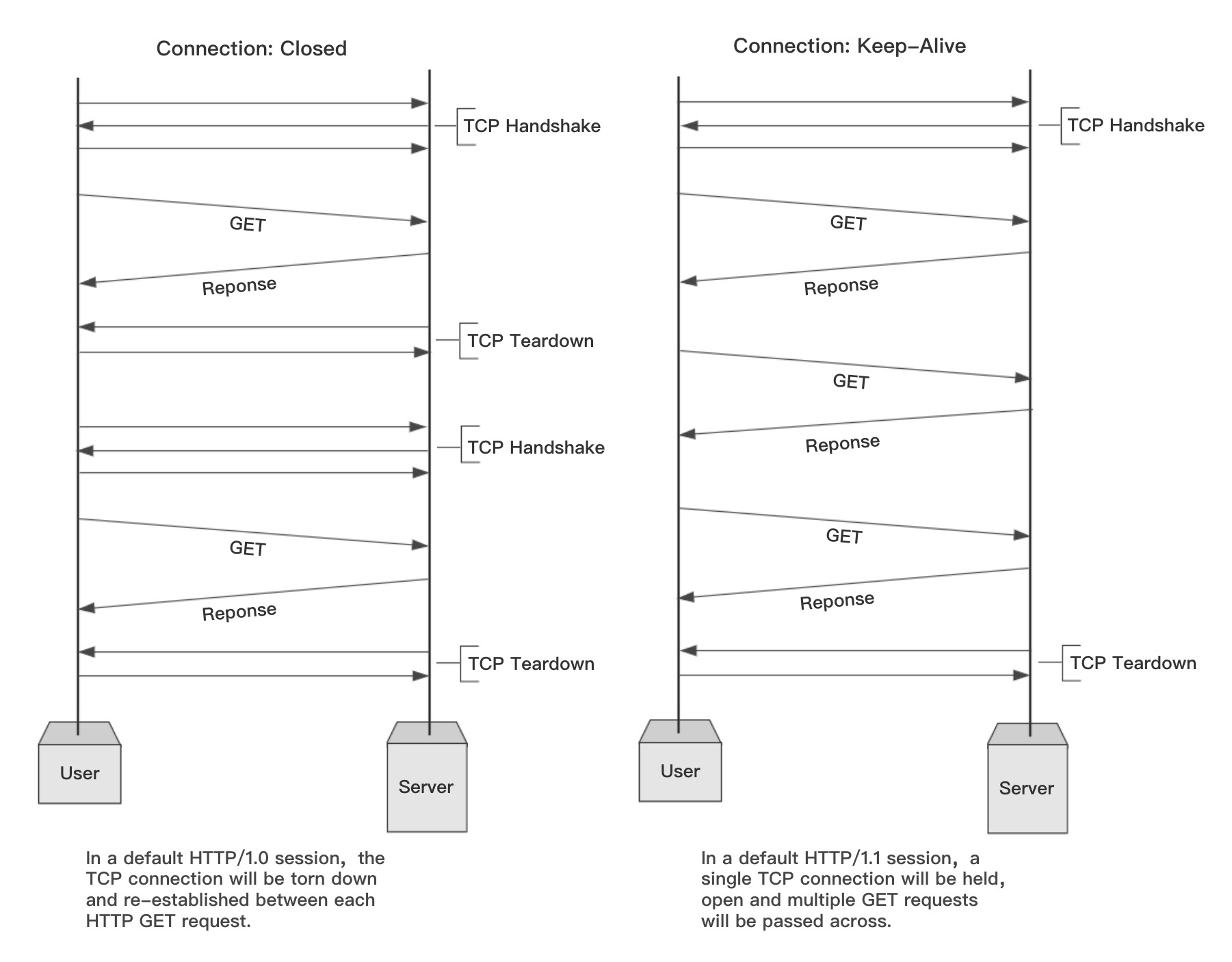 (上图来自 Evolution of HTTP — HTTP/0.9, HTTP/1.0, HTTP/1.1, Keep-Alive, Upgrade, and HTTPS)
(上图来自 Evolution of HTTP — HTTP/0.9, HTTP/1.0, HTTP/1.1, Keep-Alive, Upgrade, and HTTPS)
可以看到,通过建立长连接,中间的几次 TCP 连接开始和结束的握手都省掉了。
那好,我们还是使用 netcat,这次把版本号改成 1.1,同时打开长连接:
GET / HTTP/1.1
Host: www.google.com
User-Agent: Mozilla/1.22 (compatible; MSIE 2.0; Windows 3.1)
Connection: keep-alive
Accept: text/html
(别忘了上面那个空行)
相信你也注意到了上面客户端要求开启长连接的 HTTP 头:
Connection: keep-alive
再按老办法运行:
netcat www.google.com 80 < ~/Downloads/request.txt
我们果然得到了 Google 的响应:
HTTP/1.1 200 OK
Date: ...
Expires: -1
Cache-Control: private, max-age=0
Content-Type: text/html; charset=ISO-8859-1
Transfer-Encoding: chunked
...(此处省略多行HTTP 头)
127a
...(此处省略 HTML)
0
但是在响应中,值得注意的有两点:
Transfer-Encoding: chunked
127a
...
0
同时,之前我们见到过头部的 Content-Length 不见了。这是怎么回事呢?
事实上,如果协议头中存在上述的 chunked 头,表示将采用分块传输编码,响应的消息将由若干个块分次传输,而不是一次传回。刚才的 127a,指的是接下去这一块的大小,在这些有意义的块传输完毕后,会紧跟上一个长度为 0 的块和一个空行,表示传输结束了,这也是最后的那个 0 的含义。
值得注意的是,实际上在这个 0 之后,协议还允许放一些额外的信息,这部分会被称作“Trailer”,这个额外的信息可以是用来校验正确性的 checksum,可以是数字签名,或者传输完成的状态等等。
在长连接开启的情况下,使用 Content-Length 还是 chunked 头,必须具备其中一种。分块传输编码大大地提高了HTTP 交互的灵活性,服务端可以在还不知道最终将传递多少数据的时候,就可以一块一块将数据传回来。在 [第 03 讲] 中,你还会看到藉由分块传输,可以实现一些模拟服务端推送的技术,比如 Comet。
事实上 HTTP/1.1 还增加了很多其它的特性,比如更全面的方法,以及更全面的返回码,对指定客户端缓存策略的支持,对 content negotiation 的支持(即通过客户端请求的以 Accept 开头的头部来告知服务端它能接受的内容类型),等等。
现在最广泛使用的 HTTP 协议还是 1.1 ,但是 HTTP/2 已经提出,在保持兼容性的基础上,包含了这样几个重要改进:
在 HTTP/2 之后,我们展望未来,HTTP/3 已经箭在弦上。如同前面的版本更新一样,依旧围绕传输效率这个协议核心来做进一步改进,其承载协议将从 TCP 转移到基于 UDP 的 QUIC 上面来。
最后,我想说的是,HTTP 协议的进化史,恰恰是互联网进化史的一个绝佳缩影,从中你可以看到互联网发展的数个特质。比方说,长连接和分块传输很大程度上增强了 HTTP 交互模型上的灵活性,使得 B/S 架构下的消息即时推送成为可能。
今天我们了解了 HTTP 协议的进化史,并且用了动手操作的方法来帮助你理解内容,还分析了其中两个重要的特性,长连接和分块传输。希望经过今天的实践,除了知识本身的学习,你还能够在快速的动手验证中,强化自己的主观认识,并将这种学习知识的方式培养成一种习惯,这是学习全栈技能的一大法宝。
现在,让我们来进一步思考这样两个问题:
好,今天的分享就到这里,欢迎提出你的疑问,也期待你留言与我交流!
如果你对于使用 tcpdump 进行网络抓包这个技能已经了解了,就可以跳过下面的内容。反之,推荐你动动手。因为在学习任何网络协议的时候,网络抓包是一个非常基本的实践前置技能;而在实际定位问题的时候,也时不时需要抓包分析。这也是我在第一讲就放上这堂选修课的原因。
俗话说,耳听为虚,眼见为实,下面让我们继续动手实践。你当然可以尝试抓访问某个网站的包,但也可以在本机自己启动一个 web 服务,抓一段 HTTP GET 请求的报文。
利用 Python,在任意目录,一行命令就可以在端口 8080 上启动一个完备的 HTTP 服务(这大概是世界上最简单的启动一个 HTTP 服务的方式了):
python -m SimpleHTTPServer 8080
启动成功后,你应该能看到:
Serving HTTP on 0.0.0.0 port 8080 ...
接着使用 tcpdump 来抓包,注意抓的是 loopback 的包(本地发送到本地),因此执行:
sudo tcpdump -i lo0 -v 'port 8080' -w http.cap
这里的 -i 参数表示指定 interface,而因为客户端和服务端都在本地,因此使用 lo0(我使用的是 Mac,在某些Linux操作系统下可能是 lo,具体可以通过 ifconfig 查看)指定 loopback 的接口,这里我们只想捕获发往 8080 端口的数据包,结果汇总成 http.cap 文件。
打开浏览器敲入 http://localhost:8080 并回车,应该能看到启动 HTTP 服务路径下的文件(夹)列表。这时候你也应该能看到类似下面这样的文字,标志着多少包被捕获,多少包被过滤掉了:
24 packets captured
232 packets received by filter
好,现在我们使用 CTRL + C 结束这个抓包过程。
抓包后使用 Wireshark 打开该 http.cap 文件,在 filter 里面输入 http 以过滤掉别的我们不关心的数据包,我们应该能看到请求和响应至少两条数据。于是接下去的内容就是我们非常关心的了。

如果你看到这里,我想请你再思考下,在不设置上面的 http filter 的时候,我们会看到比这多得多的报文,它们不是 HTTP 的请求响应所以才被过滤掉了,那么,它们都有什么呢?