你好,我是四火。
在上一讲中,我们了解了 MVC 这个老而弥坚的架构模式,而从这一讲开始,连同第 09、10 讲共计 3 篇,我将分别展开介绍 MVC 三大部分内容。今天我要讲的就是第一部分——模型(Model)。
首先我们要了解的是,我们总在谈“模型”,那到底什么是模型?
简单说来,模型就是当我们使用软件去解决真实世界中各种实际问题的时候,对那些我们关心的实际事物的抽象和简化。比如我们在软件系统中设计“人”这个事物类型的时候,通常只会考虑姓名、性别和年龄等一些系统用得着的必要属性,而不会把性格、血型和生辰八字等我们不关心的东西放进去。
更进一步讲,我们会谈领域模型(Domain Model)。“领域”两个字显然给出了抽象和简化的范围,不同的软件系统所属的领域是不同的,比如金融软件、医疗软件和社交软件等等。如今领域模型的概念包含了比其原本范围定义以外更多的内容,我们会更关注这个领域范围内各个模型实体之间的关系。
MVC 中的“模型”,说的是“模型层”,它正是由上述的领域模型来实现的,可是当我们讲这一层的时候,它包含了模型上承载的实实在在的业务数据,还有不同数据间的关联关系。因此,我们在谈模型层的时候,有时候会更关心领域模型这一抽象概念本身,有时候则会更关心数据本身。
第一次听到“贫血模型”“充血模型”这两个词的时候,可能你就会问了,什么玩意儿?领域模型还有贫血和充血之说?
其实,这两兄弟是 Martin Fowler 造出来的概念。要了解它们,得先知道这里讲的“血”是什么。
这里的“血”,就是逻辑。它既包括我们最关心的业务逻辑,也包含非业务逻辑 。因此,贫血模型(Anemic Domain Model),意味着模型实体在设计和实现上,不包含或包含很少的逻辑。通常这种情况下,逻辑是被挪了出去,由其它单独的一层代码(比如这层代码是“Service”)来完成。
严格说起来,贫血模型不是面向对象的,因为对象需要数据和逻辑的结合,这也是贫血模型反对者的重要观点之一。如果主要逻辑在 Service 里面,这一层对外暴露的接口也在 Service 上,那么事实上它就变成了面向“服务”的了,而模型实体,实际只扮演了 Service API 交互入参出参的角色,或者从本质上说,它只是遵循了一定封装规则的容器而已。
这时的模型实体,不包含逻辑,但包含状态,而逻辑被解耦到了无状态 Service 中。既然没有了状态,Service 中的方法,就成为过程式代码的了。请注意,不完全面向对象并不代表它一定“不好”,事实上,在互联网应用设计中,贫血模型和充血模式都有很多成功的使用案例,且非常常见。
比如这样的一个名为 Book 的类:
public class Book {
private int id;
private boolean onLoan;
public int getId() {
return this.id;
}
public void setId(int id) {
this.id = id;
}
public boolean isOnLoan() {
return this.loan;
}
public void setOnLoan(boolean onLoan) {
this.onLoan = onLoan;
}
}
你可以看到,它并没有任何实质上的逻辑在里面,方法也只有简单的 getters 和 setters 等属性获取和设置方法,它扮演的角色基本只是一个用作封装的容器。
那么真正的逻辑,特别是业务逻辑在哪里呢?有这样一个 Service:
public class BookService {
public Book lendOut(int bookId, int userId, Date date) { ... }
}
这个 lendOut 方法表示将书从图书馆借出,因此它需要接收图书 id 和 用户 id。在实现中,可能需要校验参数,可能需要查询数据库,可能需要将从数据源获得的原始数据装配到返回对象中,可能需要应用过滤条件,这里的内容,就是逻辑。
现在,我们再来了解一下充血模型(Rich Domain Model)。在充血模型的设计中,领域模型实体就是有血有肉的了,既包含数据,也包含逻辑,具备了更高程度的完备性和自恰性,并且,充血模型的设计才是真正面向对象的。在这种设计下,我们看不到 XXXService 这样的类了,而是通过操纵有状态的模型实体类,就可以达到数据变更的目的。
public class Book {
private int id;
private boolean onLoan;
public void lendOut(User user, Date date) { ... }
... // 省略属性的获取和设置方法
}
在这种方式下,lendOut 方法不再需要传入 bookId,因为它就在 Book 对象里面存着呢;也不再需要传出 Book 对象作为返回值,因为状态的改变直接反映在 Book 对象内部了,即 onLoan 会变成 true。
也就是说,Book 的行为和数据完完全全被封装的方法控制起来了,中间不会存在不应该出现的不一致状态,因为任何改变状态的行为只能通过 Book 的特定方法来进行,而它是可以被设计者严格把控的。
而在贫血模型中就做不到这一点,一是因为数据和行为分散在两处,二是为了在 Service 中能组装模型,模型实体中本不该对用户开放的接口会被迫暴露出来,于是整个过程中就会存在状态不一致的可能。
但是请注意,无论是充血模型还是贫血模型,它和 Model 层做到何种程度的解耦往往没有太大关系。比如说这个 lendOut 方法,在某些设计中,它可以拆分出去。对于贫血模型来说,它并非完全属于 BookService,可以拿到新建立的“借书关系”的服务中去,比如:
public class LoanService {
public Loan add(int bookId, int userId, Date date) { ... }
}
这样一来,借书的关系就可以单独维护了,借书行为发生的时候,Book 和 User 两个实体对应的数据都不需要发生变化,只需要改变这个借书关系的数据就可以了。对于充血模型来说,一样可以做类似拆分。
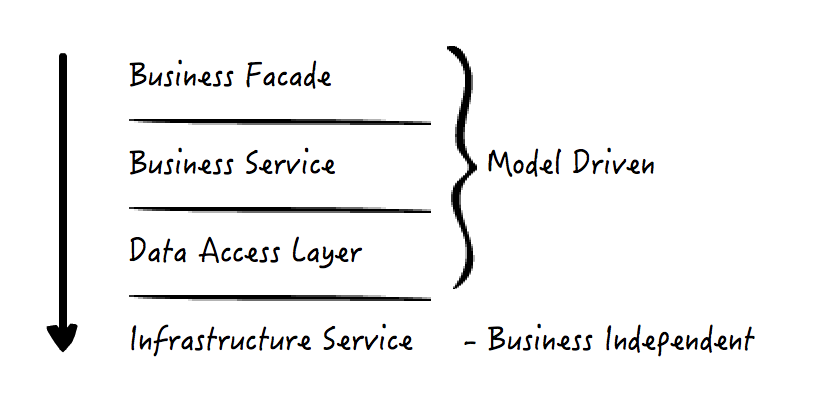
软件的耦合和复杂性问题往往都可以通过分层解决,模型层内部也一样,但是我们需要把握其中的度。层次划分过多、过细,并不利于开发人员严格遵从和保持层次的清晰,也容易导致产生过多的无用样板代码,从而降低开发效率。下面是一种比较常见的 Model 层,它是基于贫血模型的分层方式。
在这种划分方式下,每一层都可以调用自身所属层上的其它类,也可以调用自己下方一层的类,但是不允许往上调用,即依赖关系总是“靠上面的层”依赖着“靠下面的层”。最上面三层是和业务模型实体相关的,而最下面一层是基础设施服务,和业务无关。从上到下,我把各层依次简单介绍一下:
你也许听说过数据库的读写分离,其实,在模型的设计中,也有类似读写分离的机制,其中最常见的一种就叫做 CQRS(Command Query Responsibility Segregation,命令查询职责分离)。
一般我们设计的业务模型,会同时被用作读(查询模式)和写(命令模式),但是,实际上这两者是有明显区别的,在一些业务场景中,我们希望这两者被分别对待处理,那么这种情况下,CQRS 就是一个值得考虑的选项。
为什么要把命令和查询分离?我举个例子来说明吧,比如这样的贫血模型:
class Book {
private long id;
private String name;
private Date publicationDate;
private Date creationDate;
... // 省略其它属性和 getter/setter 方法
}
那么,相应地,就有这样一个 BookService:
class BookService {
public Book add(Book book);
public Pagination<Book> query(Book book);
}
这个接口提供了两个方法:
一个叫做 add 方法,接收一个 book 对象,这个对象的 name 和 publicationDate 属性会被当做实际值写入数据库,但是 id 会被忽略,因为 id 是数据库自动生成的,具备唯一性,creationDate 也会被忽略,因为它也是由数据库自动生成的,表示数据条目的创建时间。写入数据库完成后,返回一个能够反映实际写入库中数据的 Book 对象,它的 id 和 creationDate 都填上了数据库生成的实际值。
你看,这个方法,实际做了两件事,一件是插入数据,即写操作;另一件是返回数据库写入的实际对象,即读操作。
另一个方法是 query 方法,用于查询,这个 Book 入参,被用来承载查询参数了 。比方说,如果它的 author 值为“Jim”,表示查询作者名字为“Jim”的图书,返回一个分页对象,内含分页后的结果列表。
但这个方法,其实有着明显的问题。这个问题就是,查询条件的表达,并不能用简单的业务模型很好地表达。换言之,这个模型 Book,能用来表示写入,却不适合用来表示查询。为什么呢?
比方说,你要查询出版日期从 2018 年到 2019 年之间的图书,你该怎么构造这个 Book 对象?很难办对吧,因为 Book 只能包含一个 publicationDate 参数,这种“难办”的本质原因,是模型的不匹配,即这个 Book 对象根本就不适合用来做查询调用的模型。
在清楚了问题以后,解决方法 CQRS 就自然而然产生了。简单来说,CQRS 模式下,模型层的接口分为且只分为两种:
也就是说,它把命令和查询的模型彻底分开了。上面的例子 ,使用 CQRS 的方式来改写一下,会变成这样:
class BookService {
public void add(Book book);
public Pagination<Book> query(Query bookQuery);
}
你看,在 add 操作的时候,不再有返回值;而在 query 操作的时候,入参变成了一个 Query 对象,这是一个专门的“查询对象”,查询对象里面可以放置多个查询条件,比如:
Query bookQuery = new Query(Book.class);
query.addCriteria(Criteria.greaterThan("publicationDate", date_2018));
query.addCriteria(Criteria.lessThan("publicationDate", date_2019));
读到这里,不知道你有没有联想到这样两个知识点:
第一个知识点,在 [第 04 讲] 我们学习 REST 风格的时候,我们把 HTTP 的请求从两个维度进行划分,是否幂等,以及是否安全。按照这个角度来考量,CQRS 中的命令,可能是幂等的(例如对象更新),也可能不是幂等的(例如对象创建),但一定是不安全的;CQRS 中的查询,一定是幂等的,且一定是安全的。
第二个知识点,在 [第 07 讲] 我们学习 MVC 的一般化,其中的“第二种”典型情况时,Controller 会调用 Model 层的,执行写入操作;而 View 层会调用 Model 层,执行只读操作——看起来这不就是最适合 CQRS 的一种应用场景吗?
所以说,技术确实都是相通的。
今天我们详细剖析了 MVC 架构中 Model 层的方方面面,并结合例子理解了贫血模型和充血模型的概念和特点,还介绍了一种典型的模型层的内部层次划分方法,接着介绍了 CQRS 这种将命令和查询行为解耦开的模型层设计方式。
其中,贫血模型和充血模型的理解是这一讲的重点,这里我再强调一下:
最后,我来提两个问题,一同检验下今天的学习成果吧:
好,今天的内容就到这里,有余力还可以了解下扩展阅读的内容。有关今天的知识点,如果你在实际的工作经历中遇到过,其实是非常适合拿来一起比较的。可以谈谈你在这方面的经验,也可以分享你的不同理解,期待你的想法!