
你好,我是四火。
随着大数据和数据分析趋势的流行,数据可视化变得越来越重要,而许多全栈的学习材料并没有跟上节奏,去介绍这方面的技术。这一讲中,我们将介绍数据可视化的基本概念和原理,以及几个常用的 JavaScript 用来实现数据可视化的库。
数据可视化,即 Data Visualization,是指使用具备视觉表现力的图形和表格等工具,向用户传达数据信息的方式。在我工作过的每个大型团队中,数据可视化技术都有着其不可替代的用武之地。
在大数据分析团队,数据库可视化技术被用来分析数据变化,验证机器学习算法的效果;在高可用服务团队,数据可视化技术被用来了解和监视服务的运行状况,了解系统的压力和负载;在分布式平台团队,数据可视化技术用来俯瞰一个个异步任务的执行情况,以获知任务执行的健康状况……事实上,只要有工程的地方,数据可视化就扮演着举足轻重的角色。
在前端绘图,是数据可视化里面很常见的一个需求,我们常见的有位图和矢量图这样两种。
通常我们谈论的图片,绝大多数都是位图。位图又叫栅格图像,无论位图采用何种压缩算法,它本质就是点阵,它对于图像本身更具备普适性,无论图像的形状如何,都可以很容易分解为一个二维的点阵,更大的图,或者更高的分辨率,只是需要更密集的点阵而已。
你可能已经听说过矢量图。矢量图是使用点、线段或者多边形等基于数学方程的几何形状来表示的图像。将一个复杂图像使用矢量的方式来表达,显然要比位图困难得多,但是矢量图可以无损放大,因为它的本质是一组基于数学方程的几何形状的集合,因此无论放大多少倍,形状都不会发生失真或扭曲。并且图像越大,就越能比相应的位图节约空间,因为矢量图的大小和实际图像大小无关。倘若再采用独立的压缩算法进行压缩,矢量图可以基于文本压缩,从而获得很大的压缩比。
在早些年的项目中,在后端使用 Python 等语言预生成绘制图像的场景还比较多,但是如今已经少见一些了,大多数的图形生成都被搬到了前端。而这种情况也成为了前后端分离,以及数据和展示分离的典型场景,后端同步或异步生成不同维度的数据,浏览器则通过统一的 API 根据用户需求获取相应的数据;前端根据这些取得的数据在浏览器中现场绘制图像。关于服务端和客户端聚合的知识,如有遗忘,请回看 [第 09 讲]。
总的来看,前端绘图,和后端比起来,有这样几个显著的优势。
我们较常听到的 Web 绘图标准包括 VML、SVG 和 Canvas,其中 VML 是微软最初参与制定的标准,一直以来只有 IE 等少数浏览器支持,从 2012 年的 IE 10 开始它逐渐被废弃了;但是剩余两个,SVG 和 Canvas 有一定互补性,且如今都非常流行,下面我来介绍一下。
SVG 即 Scalable Vector Graphics,可缩放矢量图形。它是基于可扩展标记语言(XML),用于描述二维矢量图形的一种图形格式。在它之前,微软曾经向 W3C 交过 VML 的提议,但被拒绝了。之后才有了 SVG,由 W3C 制定,是一个开放标准,当时在 W3C 自己看来,SVG 的竞争对手应该主要是 Flash。
SVG 格式和前面提到的 VML 一样,支持脚本,容易被搜索引擎索引。SVG 可以嵌入外部对象,比如文字、PNG、JPG,也可以嵌入外部的 SVG。它在移动设备上存在两个子版本,分别叫做 SVG Basic 和 SVG Tiny。SVG 很快获得了各种浏览器的支持,一开始 IE 还坚守着自家的 VML 不放,但后来也慢慢被迫转移到了 SVG 的阵营,从 IE 9 才开始对 SVG 部分支持。
SVG 支持三种格式的图形:矢量图形、栅格图像和文本。所以你看,SVG 并不只是一个矢量图的简单表示规范,而是尝试把矢量图、位图和文字统一起来的标准。我们来亲自写一个 SVG 的小例子,在你的工作文件夹中建立 example.svg,并用文本编辑器打开,录入如下文字:
<?xml version="1.0" encoding="UTF-8"?>
<svg xmlns="http://www.w3.org/2000/svg" version="1.1" width="300" height="300">
<rect x="60" y="60" width="200" height="200" fill="red" stroke="black" stroke-width="2px" />
</svg>
我来对上述 XML 做个简单的解释:第一行了指明 XML 的版本和编码;第二行是一个 svg 的根节点,指明了协议和版本号,图像画布的大小(500 x 500),其中只包含一个矩形(rect),这个矩形的起始位置是(x, y),宽和高都为 200,填充红色,并使用 2px 宽的黑色线条来描边。
接着使用 Chrome 来打开这个文件,你将看到这样的效果:
接着我们另建立一个 HTML 文件:svg.html,加上 html 标签,并拷贝 XML 中的 svg 标签到这个 HTML 文件中:
<!DOCTYPE html>
<html>
<body>
<svg xmlns="http://www.w3.org/2000/svg" version="1.1" width="300" height="300">
<rect x="60" y="60" width="200" height="200" fill="red" stroke="black" stroke-width="2px" />
</svg>
</body>
</html>
用 Chrome 打开看看效果——嗯,再次展示了这个红色方块。反复点击 Chrome 的 View 菜单下的 Zoom In 选项,将图像放到最大,观察矩形的边角,没有任何模糊和失真,这证明了它确实是矢量图。

最后打开 Chrome 的开发者工具,在控制台键入:
$("svg>rect").setAttribute("fill", "green");
你会看到这个矢量图从红色变成了绿色。这充分说明,svg 就是普普通通的 HTML 标签,它可以响应 JavaScript 的控制。自此,图像对于天天和 HTML 打交道的程序员来说,再也不是一个“二进制黑盒”了。
Canvas 标签是 HTML 5 的标签之一,标签可以定义一片区域,允许 JavaScript 动态渲染图像。开始由苹果推出,自家的 Safari 率先支持,IE 从 IE 9 开始支持。
Canvas 和 SVG 有相当程度的互补之处,我们来实现一个 Canvas 的例子,体会下这一点。请在任何工作文件夹中,建立 canvas.html,并写入:
<!DOCTYPE html>
<html>
<body>
<canvas width="300" height="300"></canvas>
<script type="text/javascript">
var canvas = document.getElementsByTagName('canvas')[0];
var ctx = canvas.getContext('2d');
ctx.rect(60,60,200,200);
ctx.fillStyle = 'RED';
ctx.fill();
ctx.strokeStyle = 'BLACK';
ctx.stroke();
</script>
</body>
</html>
代码很容易理解,获取到 canvas 节点以后,获取一个 2D 上下文,接着设置好矩形的位置和大小,分别进行填充和描线的操作。接着使用 Chrome 打开,你会发现效果和 SVG 的例子一样,展示了这个具备黑色边框的红色方块。

看起来和 SVG 差不多对不对?我们也来执行相同的操作,反复点击 Chrome 的 View 菜单下的 Zoom In 选项,将图像放到最大:

你看,矩形的边角不再清晰,这说明这种方式绘制的不是矢量图,而是位图。再使用 Chrome 的开发者工具,点击左上角的 DOM 选择箭头,选中这个矩形,我们发现,和 SVG 不同的是,这个 canvas 节点内部并没有任何 DOM 结构。
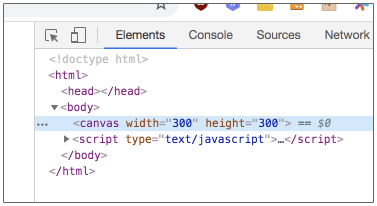
虽然这是一个小小的例子,但足以看出 Canvas 和 SVG 之间的明显差异和互补性了。
总的来说,从图片描述过程上来说,SVG 是 HTML 标签原生支持的,因此就可以使用这种声明式的语言来描述图片,它更加直观、形象、具体,每一个图形组成的 DOM 都可以很方便地绑定和用户交互的事件。这种在渲染技术上通过提供一套完整的图像绘制模型来实现的方式叫做 Retained Mode。
Canvas 则是藉由 JavaScript 的命令式的语言对既定 API 的调用,来完成图像的绘制,canvas 标签的内部,并没有任何 DOM 结构,这让它无法使用传统的 DOM 对象绑定的方式来和图像内部的元素进行互动,但它更直接、可编程性强,在浏览器内存中不需要为了图形维护一棵巨大的 DOM 树,这也让它在遇到大量的密集对象时,拥有更高的渲染性能。这种在渲染技术上通过直接调用图形对象的绘制命令接口来实现的方式叫做 Immediate Mode。
讲到这里,不知道你是否联想到了我们之前反复提到过的,声明式编程和命令式编程在全栈技术中的应用,如果你忘记了,可以回看 [第 07 讲] 中的介绍。所以,我想再次说,技术都是相通的。
 (上图来自 SVG vs canvas: how to choose,比较了 SVG 和 Canvas 其中的一些优劣)
(上图来自 SVG vs canvas: how to choose,比较了 SVG 和 Canvas 其中的一些优劣)
我们从这些例子中可以看出来,无论选用哪一种技术,HTML 5 的出现,都给了浏览器底气。以往由于其自身能力的限制,浏览器的很多领土都被播放器控件、Flash 等蚕食了,HTML 5 正助其将领土重新夺回来(你可能已经听说了,Chrome 已经开始用提示条警告:从 2020 年 12 月起 Chrome 将不再支持 Flash)。
使用这种方式,以往浏览器内的这些插件和扩展的“黑盒”全部通过原生的 HTML 标签完成替换支持,少了一个软件“层”,多了一分透明,视频、音频等媒体由浏览器底层直接支持,性能会更加出色,交互性更好。
数据可视化的 JavaScript 库有很多,我想它们可以简单分为两类:绝大多数都比较专精,完成某一类的图表绘制工作,比如 Flot;但是也有一些相对通用而强大,比如 D3.js。
Flot 是一个非常简单的图表绘制的 jQuery 插件,这样类似的库有很多,它们绝大多数包含这样两个特点:
我们拿 Flot 举例,来感受一下这两个特点,比如下面这个例子,绘制一条正弦曲线,代码非常得简洁。
首先在 HTML 页面中建立一个 div:
<div id="plot"></div>
接着在 JavaScript 中,写入如下代码:
let data = $.map([...Array(1000).keys()],
(x, i) => [[i, Math.sin(x/100)]]);
$.plot("#plot", [{ data }], {
xaxis: { ticks: [
0,
[ 100 * Math.PI, "Pi" ],
[ 200 * Math.PI, "2Pi" ],
[ 300 * Math.PI, "3Pi" ]
]}
});
按照前面说的常见步骤,我来简单解释一下。
通过这样简单的代码,就可以得到如下效果:
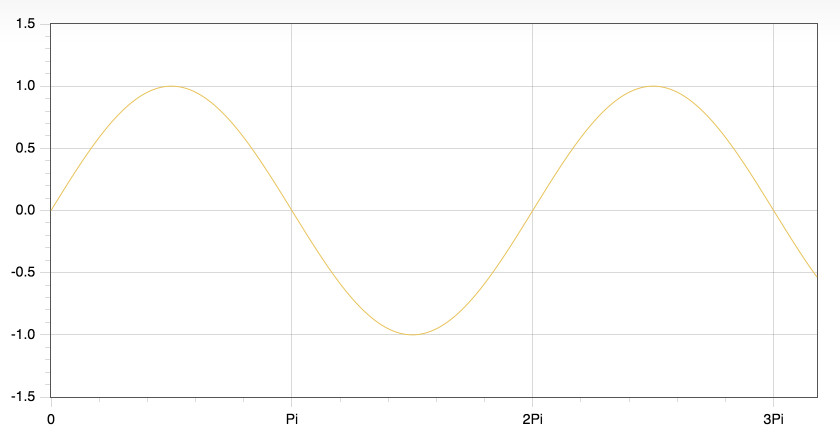
如果你考察生成的对象,你会发现它是使用 Canvas 来绘制的。
第二类可视化 JavaScript 库相对较为通用。D3.js 是一个基于数据的操作文档的 JavaScript 库,可以让你绑定任何数据到 DOM,支持 DIV 这类常规 DOM 进行的图案生成,也支持 SVG 这种图案的生成。D3 帮助你屏蔽了浏览器差异,并且通过基于容器和数据匹配状态变更的解耦设计,这种方式对于绘制某些动态变化的、画布元素根据数据按照一定规则变动的图像,代码会非常得清晰简洁。
这种方法就是 “Enter and Exit” 机制,下面我们来着重理解一下它。
这种机制建立在容器节点和数据映射的关系上,即“一个萝卜一个坑”,数据项就是萝卜,容器节点就是坑。在数据变动的过程中,通过每个节点位置和每个数据项的匹配,发生如下三种行为之一:
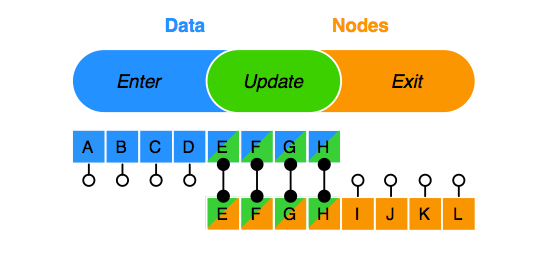 (来自 D3: Data-Driven Documents)
(来自 D3: Data-Driven Documents)
下面,我们还是让代码说话,用一个简单的小例子,来展示这个过程。HTML 中有这样一个 DOM,作为画布,准备用 D3.js 在上面作画:
<svg></svg>
定义一个作画方法 render,任何时候我们希望针对改变的数据,重新更新画布,只需要调用下面定义的 render 方法:
let render = (data) => {
// 选择节点
var circles = d3
.select('svg')
.selectAll('circle');
// 默认行为,对应于 update
circles.data(data)
.attr('r', 20)
.attr('cx', (d, i) => { return i * 50 + 20; })
.attr('cy', (d, i) => { return 20; })
.style('fill', 'BLUE')
// 新 data 加入,对应于 enter
circles.data(data)
.enter()
.append('circle')
.attr('r', 20)
.attr('cx', (d, i) => { return i * 50 + 20; })
.attr('cy', (d, i) => { return 20; })
.style('opacity', 0)
.style('fill', 'RED')
.transition()
.duration(1000)
.style('opacity', 1)
// 旧 data 离开,对应于 exit
circles.data(data)
.exit()
.transition()
.duration(1000)
.style('opacity',0)
.remove();
};
你看,render 方法包含了这样几步:
其中链式调用中的 transition() 定义了在执行某些过程时,以过渡动画的方式来进行,例子中无论是“挖坑”还是“填坑”,都通过透明度渐变的方法来实现过渡。
最后,我们在第 0 秒的时候种下了 3 个萝卜,由于之前没有萝卜坑,于是发生了三次 enter 行为;第 2 秒的时候我们将萝卜减少到了 2 个,于是发生了一次 exit 行为;在第 4 秒的时候我们将萝卜数量变为 4 个,于是发生两次 enter 行为:
render([1, 2, 3]);
setTimeout(() => { render([1, 2]); }, 2000);
setTimeout(() => { render([1, 2, 3, 4]); }, 4000);
效果如下:

不知道你是否还记得我们在 [第 16 讲] 中介绍过的 Redux,D3.js 的这种机制和 Redux 的状态管理有着相似和相通之处。状态都在统一的地方维护,而状态的改变,都通过事件的发生和响应机制来进行,且都将事件的响应逻辑(回调)交给用户来完成。其实,这是一种很常见的“套路”,我们在后面的学习中,还将见到它的实现。
今天,我们学习了 Web 绘图标准的基础知识,比较了 SVG 和 Canvas 这两种具备互补性的技术实现;同时,我们也学习了 Flot 和 D3.js 这两个差异很大,但都具备代表性的可视化 JavaScript 库。
希望你除了这两项同类技术之间孰优孰劣的比较以外,还掌握了不同类型技术之间联系比较的方法。随着学习的进行,对不同类型技术慢慢具备“深入”和“浅出”两个方向的理解,逐渐将充满关联的知识体系网状结构建立起来。
最后,我来提两个问题,供你思考一下吧: