你好,我是聂鹏程。今天,我来继续带你打卡分布式核心技术。
在前面三个模块中,我带你学习了分布式领域中的分布式协调与同步、分布式资源管理与负载调度,以及分布式计算技术,相信你对分布式技术已经有了一定的了解。
通过前面的学习,不知道你有没有发现分布式的本质就是多进程协作,共同完成任务。要协作,自然免不了通信。那么,多个进程之间是如何通信的呢?这也就是在“第四站:分布式通信技术”模块中,我将要为你讲解的问题。
话不多说,接下来我们就一起进入分布式通信的世界吧。今天,我首先带你打卡的是,分布式通信中的远程调用。
首先,我通过一个例子,来让你对远程调用和本地调用有一个直观了解。
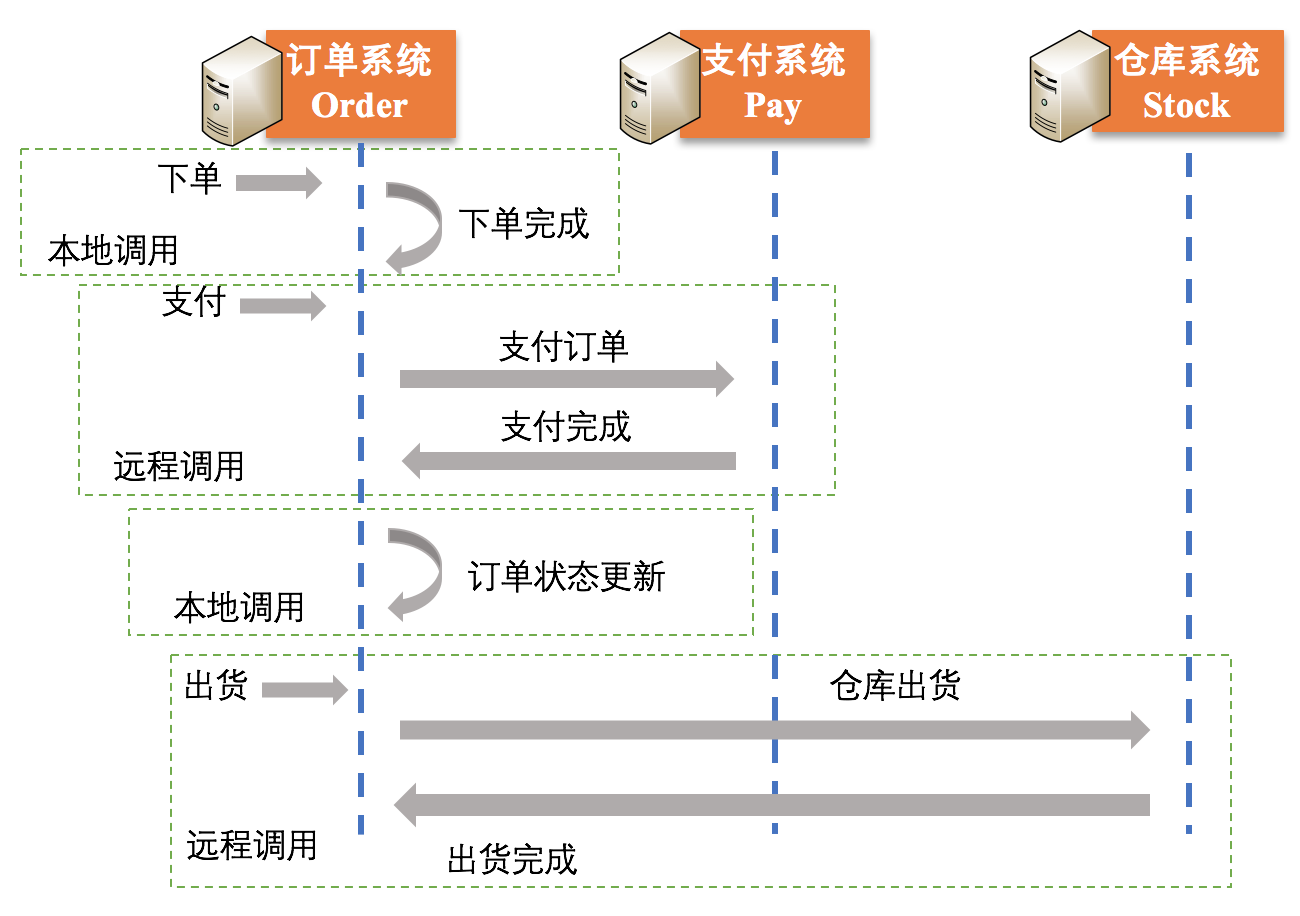
以电商购物平台为例,每一笔交易都涉及订单系统、支付系统和库存系统,假设三个系统分别部署在三台机器A、B、C中独立运行,订单交易流程如下所示:
在整个过程中,“下单”和“订单状态更新”两个操作属于本地调用,而“支付”和“出货”这两个操作是通过本地的订单系统调用其他两个机器上的函数(方法)实现的,属于远程调用。
整个订单交易流程如下图所示。
通过这个例子,你应该对本地调用和远程调用有了一个初步的认识了。那到底什么是本地调用,什么是远程调用呢?
本地调用通常指的是,进程内函数之间的相互调用;而远程调用,是进程间函数的相互调用,是一种进程间通信模式。通过远程调用,一个进程可以看到其他进程的函数、方法等,这是不是与我们通常所说的“千里眼”有点类似呢?
在分布式领域中,一个系统由很多服务组成,不同的服务由各自的进程单独负责。因此,远程调用在分布式通信中尤为重要。
根据进程是否部署在同一台机器上,远程调用可以分为如下两类:
在这两种远程调用中,RPC中的不同进程是跨机器的,适用于分布式场景。因此,在今天这篇文章中,我主要针对RPC进行详细讲解。接下来,我再提到远程调用时,主要指的就是RPC了。
我们经常会听别人提起 B/S ( Browser/Server,浏览器/服务器) 架构。在这种架构中,被调用方(服务器)有一个开放的接口,然后调用方(用户)通过Browser使用这个接口,来间接调用被调用方相应的服务,从而实现远程调用。
比如,用户A在自己的电脑上通过浏览器查询北京今天的天气, 浏览器会将用户查询请求通过远程调用方式调用远程服务器相应的服务,然后为用户返回北京今天的天气预报。
但是,B/S架构是基于HTTP协议实现的,每次调用接口时,都需要先进行HTTP请求。这样既繁琐又浪费时间,不适用于有低时延要求的大规模分布式系统,所以远程调用的实现大多采用更底层的网络通信协议。
接下来,我将为你介绍两种常用的远程调用机制:远程过程调用RPC(Remote Procedure Call)和远程方法调用RMI(Remote Method Invocation)。
首先,我们一起看一下RPC的原理和应用吧。
简单地说,RPC就是像调用本机器上的函数或方法一样,去执行远程机器上的函数或方法,并返回结果。在整个过程中,不感知底层具体的通信细节。
如下图所示,我们以刚才电商购物平台例子中的“支付”操作为例,来详细看看一次RPC调用的完整流程吧:
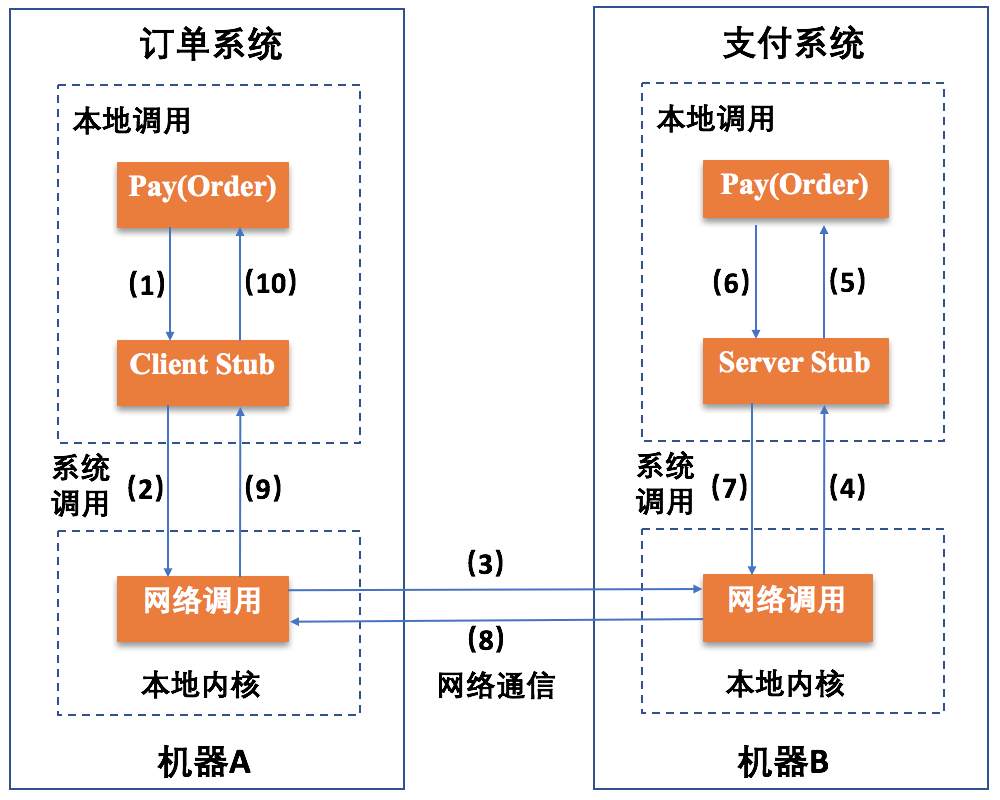
到此,整个RPC过程结束。
从整个流程可以看出,机器A上的Pay(Order)、 Client Stub 和网络调用之间的交互属于本地调用,机器B上的Pay(Order)、Server Stub和网络调用之间的交互也属于本地调用。而机器A和机器B之间的远程调用的核心是,发生在机器A上的网络调用和机器B上的网络调用。
RPC的目的,其实就是要将第2到第8步的几个过程封装起来,让用户看不到这些细节。从用户的角度看,订单系统的进程只是做了一次普通的本地调用,然后就得到了结果。
也就是说,订单系统进程并不需要知道底层是如何传输的,在用户眼里,远程过程调用和调用一次本地服务没什么不同。这,就是RPC的核心。
接下来,我再带你一起看一下RPC与本地调用(进程内函数调用)的区别吧,以加深你对RPC的理解。
你可以先想象一下,本地调用过程是怎样的。
简单来说,同一进程是共享内存空间的,用户可以通过{函数名+参数}直接进行函数调用。
而在RPC中,由于不同进程内存空间无法共享,且涉及网络传输,所以不像本地调用那么简单。所以,RPC与本地调用主要有三点不同。
第一个区别是,调用ID和函数的映射。在本地调用中,由于在进程内调用,即使用的地址空间是同一个,因此程序可直接通过函数名来调用函数。而函数名的本质就是一个函数指针,可以看成函数在内存中的地址。比如,调用函数f(),编译器会帮我们找到函数f()相应的内存地址。但在RPC中,由于不同进程的地址空间不一样,因此单纯通过函数名去调用相应的服务是不行的。
所以在RPC中,所有的函数必须要有一个调用ID来唯一标识。一个机器上运行的进程在做远程过程调用时,必须附上这个调用ID。
另外,我们还需要在通信的两台机器间,分别维护一个函数与调用ID的映射表。两台机器维护的表中,相同的函数对应的调用ID必须保持一致。
当一台机器A上运行的进程P需要远程调用时,它就先查一下机器A维护的映射表,找出对应的调用ID,然后把它传到另一台机器B上,机器B通过查看它维护的映射表,从而确定进程P需要调用的函数,然后执行对应的代码,最后将执行结果返回到进程P。
第二个区别是,序列化和反序列化。我们知道了调用方调用远程服务时,需要向被调用方传输调用ID和对应的函数参数,那调用方究竟是怎么把这些数据传给被调用方的呢?
在本地调用中,进程之间共享内存等,因此我们只需要把参数压到栈里,然后进程自己去栈里读取就行。但是在RPC中,两个进程分布在不同的机器上,使用的是不同机器的内存,因此不可能通过内存来传递参数。
而网络协议传输的内容是二进制流,无法直接传输参数的类型,因此这就需要调用方把参数先转成一个二进制流,传到被调用方后,被调用方再把二进制流转换成自己能读取的格式。调用方将参数转换成二进制流,通常称作序列化。被调用方对二进制的转换通常叫作反序列化。
同理,被调用方将结果返回给调用方,也需要有序列化和反序列化的过程。也就是说,RPC与本地调用相比,参数的传递需要进行序列化和反序列化操作。
第三个区别是,网络传输协议。序列化和反序列化解决了调用方和被调用方之间的数据传输格式问题,但要想序列化后的数据能在网络中顺利传输,还需要有相应的网络协议,比如TCP、UDP等,因此就需要有一个底层通信层。
调用方通过该通信层把调用ID和序列化后的参数传给被调用方,被调用方同样需要该通信层将序列化后的调用结果返回到调用方。
也就是说,只要调用方和被调用方可以互传数据,就可以作为这个底层通信层。因此,它所使用的网络协议可以有很多,只要能完成网络传输即可。目前来看,大部分RPC框架采用的是TCP协议。
说完RPC的核心原理,下面我以一个具有代表性的RPC框架Apache Dubbo为例,帮助你更加深入地了解RPC。
在讲解Dubbo之前,你可以先想一下:如果你是一个RPC框架的设计者,你会如何设计呢?
首先必须得有服务的提供方和调用方。如下图所示,假设服务提供方1~4为调用方1~4提供服务,每个调用方都可以任意访问服务提供方。
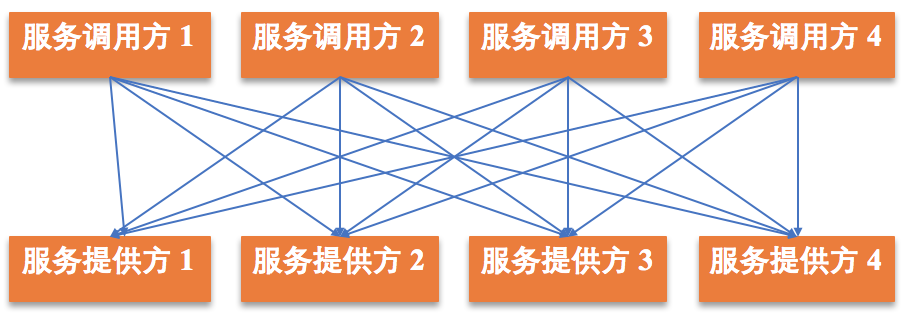
当服务提供方和服务调用方越来越多时,服务调用关系会愈加复杂。假设服务提供方有n个, 服务调用方有m个,则调用关系可达n*m,这会导致系统的通信量很大。此时,你可能会想到,为什么不使用一个服务注册中心来进行统一管理呢,这样调用方只需要到服务注册中心去查找相应的地址即可。
这个想法很好,如下图所示,我们在服务调用方和服务提供方之间增加一个服务注册中心,这样调用方通过服务注册中心去访问提供方相应的服务,这个服务注册中心相当于服务调用方和提供方的中心枢纽。
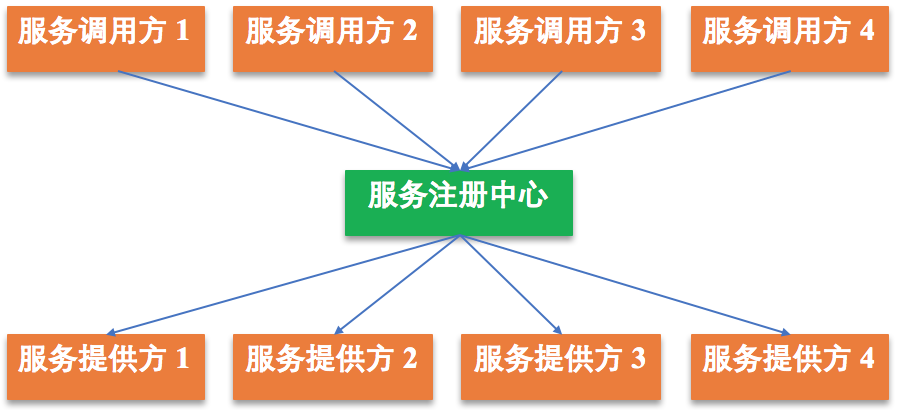
这样是不是好多了呢?
Dubbo就是在引入服务注册中心的基础上,又加入了监控中心组件(用来监控服务的调用情况,以方便进行服务治理),实现了一个RPC框架。如下图所示,Dubbo的架构主要包括4部分:
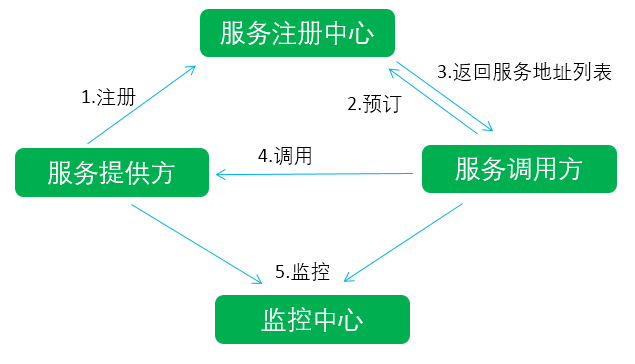
可以看到,Dubbo的大致工作流程如下:
接下来,我再带你学习另一个远程调用机制RMI。
RMI是一个用于实现RPC的Java API,能够让本地Java虚拟机上运行的对象调用远程方法如同调用本地方法,隐藏通信细节。
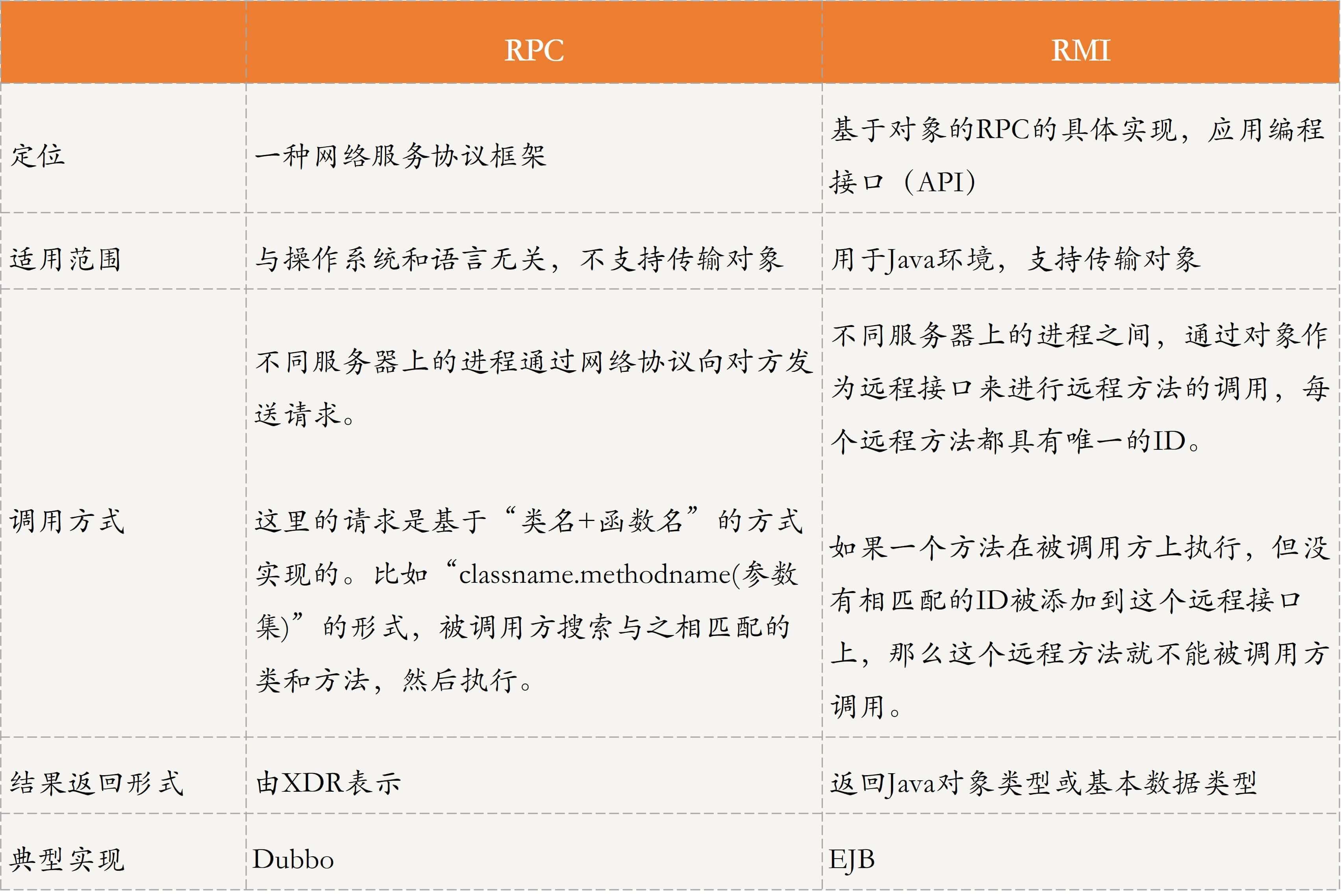
RMI可以说是RPC的一种具体形式,其原理与RPC基本一致,唯一不同的是RMI是基于对象的,充分利用了面向对象的思想去实现整个过程,其本质就是一种基于对象的RPC实现。
RMI的具体原理如下图所示:
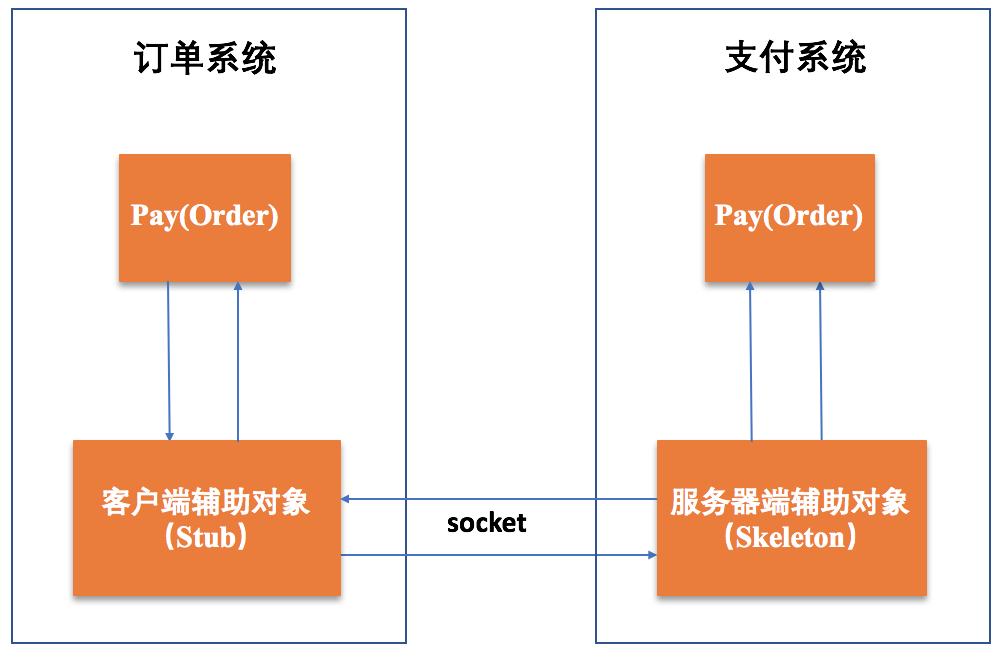
RMI的实现中,客户端的订单系统中的Stub是客户端的一个辅助对象,用于与服务端实现远程调用;服务端的支付系统中Skeleton是服务端的一个辅助对象,用于与客户端实现远程调用。
也就是说,客户端订单系统的Pay(Order)调用本地Stub对象上的方法,Stub对调用信息(比如变量、方法名等)进行打包,然后通过网络发送给服务端的Skeleton对象,Skeleton对象将收到的包进行解析,并调用服务端Pay(Order)系统中的相应对象和方法进行计算,计算结果又会以类似的方式返回给客户端。
为此,我们可以看出,RMI与PRC最大的不同在于调用方式和返回结果的形式,RMI通过对象作为远程接口来进行远程方法的调用,返回的结果也是对象形式,比如Java对象类型,或者是基本数据类型等。
RMI的典型实现框架有EJB(Enterprise JavaBean,企业级JavaBean),如果你需要深入了解这个框架的话,可以参考其官方文档。
好了,上面我带你学习了RPC和RMI,接下来我通过一个表格来对比下它们的异同吧,以方便你进一步理解与记忆。
分布式领域中,我们经常会听到同步和异步这两个词,那么远程过程调用存在同步和异步吗?
答案是肯定的。
远程过程调用包括同步调用和异步调用两种,它们的含义分别是:
也就是说,同步调用和异步调用的区别是,是否等待被调用方执行完成并返回结果。
因此,同步调用通常适用于需要关注被调用方计算结果的场景,比如用户查询天气预报,调用方需要直接返回结果;异步调用通常适用于对响应效率要求高、但对结果正确性要求相对较低的场景,比如用户下发部署一个任务,但真正执行该任务需要进行资源匹配和调度、进程拉起等过程,时间比较长,如果用户进程阻塞在那里,会导致体验很差,这种情况下可以采用异步调用。
今天,我主要与你分享了分布式通信中的远程调用。
我以电商购物平台为例,首先让你对本地调用和远程调用有了一定的认识,然后分析了两种常用的远程调用机制RPC和RMI,并对两者进行了比较。除此之外,我还介绍了Dubbo这个代表性的RPC框架。
接下来,我们再回顾下今天涉及的几个与远程调用相关的核心概念吧。
本地调用通常指的是同一台机器进程间函数的相互调用,而远程调用是指不同机器进程间函数的相互调用。
RPC是指调用方通过参数传递的方式调用远程服务,并得到返回的结果。在整个过程中,RPC会隐藏具体的通信细节,使得调用方就像在调用本地函数或方法一样。
RMI可以说是一个用于实现RPC的Java API,能够让本地Java虚拟机上运行的对象调用远程方法如同调用本地方法,隐藏通信细节。
Dubbo是一个代表性的RPC框架,服务提供方首先将自身提供的服务注册到注册中心,调用方通过注册中心获取提供的相对应的服务地址列表,然后选择其中一个地址去调用相应的服务。
最后,我再通过一张思维导图来归纳一下今天的核心知识点吧。
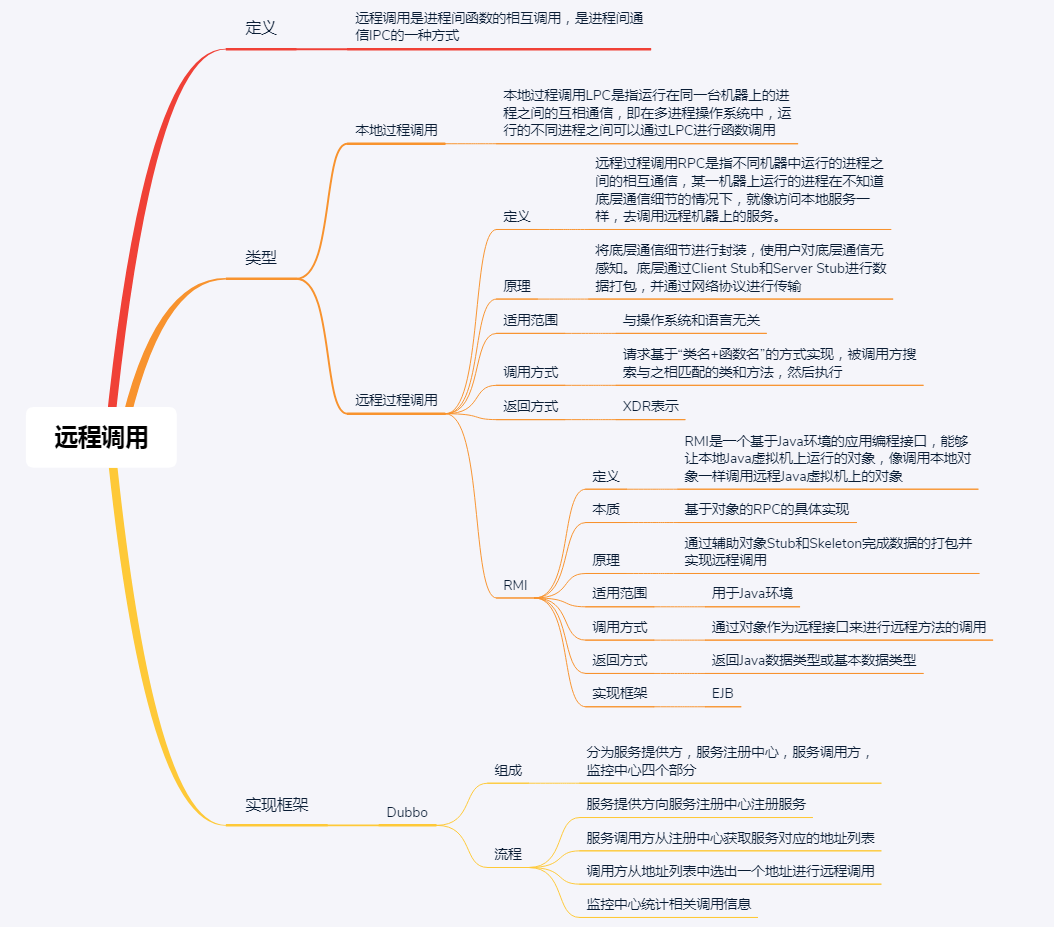
现在,是不是觉得RPC没有之前那么神秘了呢?如果你对RPC感兴趣的话,Dubbo就是一个很棒的出发点。加油,赶紧开启你的分布式通信之旅吧。
在Dubbo中引入了一个注册中心来存储服务提供方的地址列表,若服务消费方每次调用时都去注册中心查询地址列表,如果频繁查询,会导致效率比较低,你会如何解决这个问题呢?
我是聂鹏程,感谢你的收听,欢迎你在评论区给我留言分享你的观点,也欢迎你把这篇文章分享给更多的朋友一起阅读。我们下期再会!
评论