
你好,我是聂鹏程。今天,我来继续带你打卡分布式核心技术。
在上一篇文章,我带你学习了分布式通信技术中的发布订阅。总结来说,发布订阅就是发布者产生数据到消息中心,订阅者订阅自己感兴趣的消息,消息中心根据订阅者的订阅情况,将相关消息或数据发送给对应的订阅者。所以,我将其思想,概括为“送货上门”。
在实际使用场景中,还有一种常用的通信方式,就是将消息或数据放到一个队列里,谁需要谁就去队列里面取。在分布式领域中,这种模式叫“消息队列”。与发布订阅相比,消息队列技术的核心思想可以概括为“货物自取”。
接下来,我们就一起打卡分布式通信技术中的消息队列吧。
回想一下,在上一篇学术电子论文订阅的例子中,出版社或会议方将论文发布到论文网站(或平台)上,然后论文网站再将论文推送给订阅相关论文的老师或学生。这里的论文网站就是消息中心,负责根据订阅信息将论文送货上门,角色非常关键。
但其实,除了将论文送货上门外,我们还能想到另外一种模式,也就是出版社或会议方将论文发布到论文网站进行存储,老师或学生根据需要到论文网站按需购买文章。
这种思想,在分布式通信领域中称为消息队列模式,论文网站充当的就是消息队列的角色,也非常关键。接下来,我再通过一个具体的应用案例来帮助你更加深入地理解什么是消息队列吧。
比如,很多系统都提供了用户注册功能,注册完成后发送通知邮件。如下图所示,假设用户通过邮箱进行注册,填写完注册信息并点击提交后,系统的处理过程主要分为两步:
假设,系统将注册信息写入数据库需要花费400ms、给用户发送通知邮件需要花费600ms。
这时,注册消息写入数据库和发送通知邮件这两个组件间是直接交互,且是同步通信方式。那么,从用户提交注册到收到响应,需要等系统完成这两个步骤。也就是说,如果不考虑通信延迟的话,注册系统对用户的响应时间是1000ms,即1s。
如下图所示,如果引入消息队列作为注册消息写入数据库和发送通知邮件这两个组件间的中间通信者,那么这两个组件就可以实现异步通信、异步执行。引入消息队列后,上述步骤可以分为三步:
也就是说,采用消息队列模式,只需要第2步完成,即可给用户返回响应。第3步发送通知邮件可以在返回响应之后执行。
用户的注册信息写入数据库之后,通过数据库的可靠性设计来保证用户注册信息不会丢失,也就是说发送通知邮件的组件一定可以获取到用户注册信息,即保证会给注册用户发送通知邮件。也就是说,消息队列的引入不会影响用户注册网站,但会提升用户响应效率。

通常情况下,将消息写入消息队列的速度很快,假设需要100ms。那么,引入消息队列后,发送通知邮件实现了异步读取,系统响应时间缩短为500ms,响应速度提升了一倍,提升了用户体验。
讲完了用户注册这个例子,我们再来看消息队列的定义就比较容易理解了。
队列是一种具有先进先出特点的数据结构,消息队列是基于队列实现的,存储具有特定格式的消息数据,比如定义一个包含消息类型、标志消息唯一性的ID、消息内容的一个结构体作为消息数据的特定格式。消息以特定格式放入这个队列的尾部后可以直接返回,并不需要系统马上处理,之后会有其他进程从队列头部开始读取消息,按照消息放入的顺序逐一处理。
从上面的例子中,我们也可以看出引入消息队列的好处是,提高响应速度,以及实现组件间的解耦。
现在,我把消息队列的工作原理从用户注册这个例子中剥离出来,给你一个更加直接的解释吧。
消息队列的核心结构,如下图所示。与发布订阅模式类似,消息队列模式也是包括3个核心部分:
具体流程是,生产者将发送的消息插入消息队列,也就是入队,之后会有一个消费者从消息队列中逐次取出消息进行处理,完成出队。

了解了消息队列的工作原理,接下来我以阿里开源的RocketMQ为例,与你进一步介绍消息队列的原理、工作机制和实践应用。
首先,我们看一下RocketMQ的架构图,形成一个整体认知。
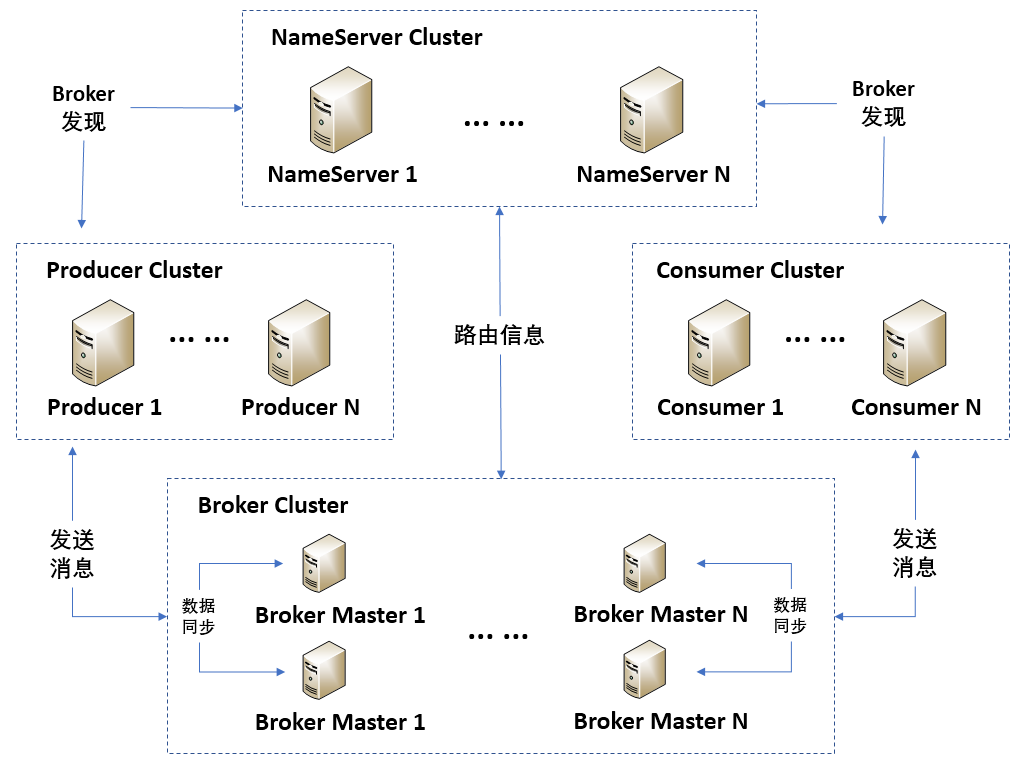
RokcetMQ共包括NameServer Cluster、Producer Cluster、Broker Cluster和Consumer Cluster共4部分。接下来,我们一起看看每部分的具体功能吧。
NameServer Cluster,指的是名字服务器集群。这个集群的功能与Kafka中引入的ZooKeeper类似,提供分布式服务的协同和管理功能,在RocketMQ中主要是管理Broker的信息,包括有哪些Broker、Broker的地址和状态等,以方便生产者获取Broker信息发布消息,以及订阅者根据Broker信息获取消息。
Producer Cluster,指的是生产者集群,负责接收用户数据,然后将数据发布到消息队列中心Broker Cluster。那么,生产者按照集群的方式进行部署,好处是什么呢?在我看来,好处可以概括为以下两点:
Consumer Cluster,指的是消费者集群,负责从Broker中获取消息进行消费。Consumer以集群方式进行部署的好处是,提升消费者的消费能力,以避免消息队列中心存储溢出,消息被丢弃。
Broker Cluster,指的是Broker集群,负责存储Producer Cluster发布的数据,以方便消费者进行消费。
Broker Cluster中的每个Broker都进行了主从设计,即每个Broker分为Broker Master 和 Broker Slave,Master 既可以写又可以读,Slave 不可以写只可以读。每次Broker Master会把接收到的消息同步给Broker Slave,以实现数据备份。一旦Broker Master崩溃了,就可以切换到Broker Slave继续提供服务。这种设计的好处是,提高了系统的可靠性。
可以看出,Broker Cluster就是我们今天要讲的核心“消息队列中心”,那么它到底是如何采用队列实现的呢?接下来,我们就一起看看Broker Cluster的实现方式吧。
如下图所示,在Broker Cluster中,消息的存储采用主题(Topic)+消息队列(Queue)的方式实现:
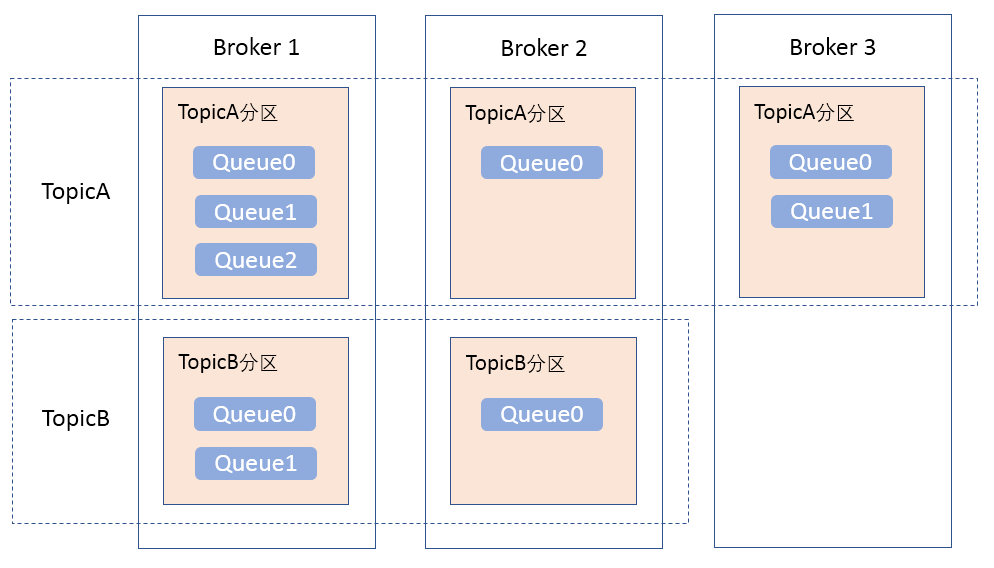
与Kafka一样,RocketMQ中的主题也是一个逻辑概念。一个主题可以分区,分布在各个不同的Broker中,每个Broker上只有该主题的部分数据。每个主题分区中,队列的数量可以不同,由用户在创建主题时指定。队列是资源分配的基本单元,消息进行存储时会存放到相应主题的分区中。
上面我为你介绍了RocketMQ的关键组件。接下来,我们再看看RocketMQ的工作流程,如下图所示:
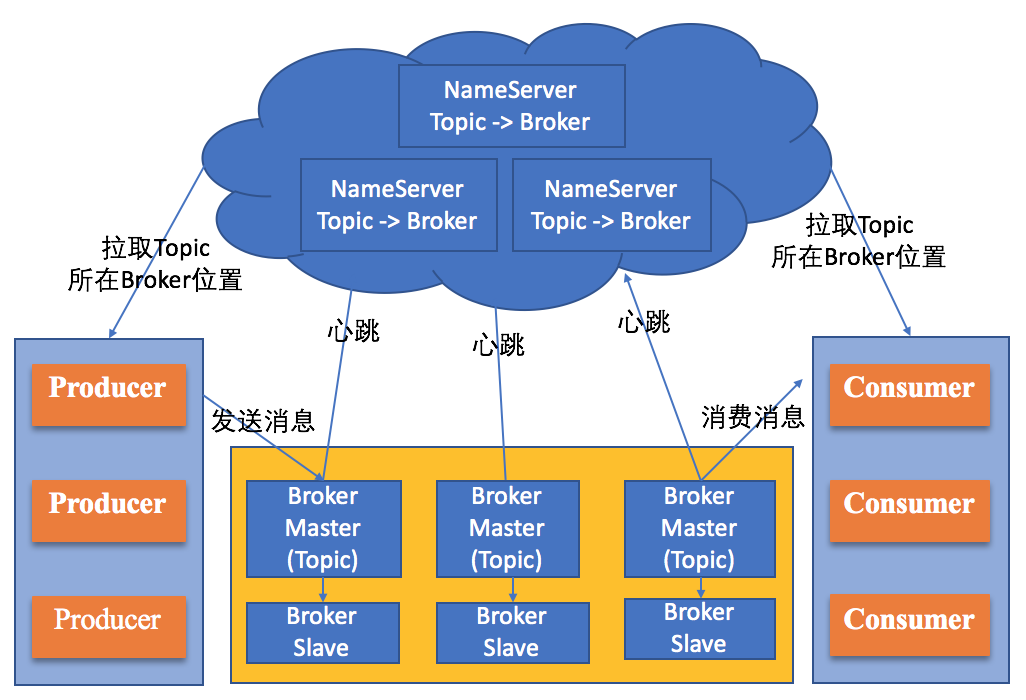
通过对RocketMQ的介绍,相信你已经对消息队列有比较深刻的认识了。接下来,我们再看看消息队列模式适用于什么场景吧。
消息队列模式,是根据消费者需求到消息队列获取数据消费的,消费者只需要知道消息队列地址即可,消息队列中心也无需提前知道消费者信息。也就是说,这种模式对消费者没有特别需求,因此比较适合消费者为临时用户的场景。
比如目前,阿里内部将RocketMQ应用于购物交易、充值、消息推送等多个场景,因为在这些场景下,每个消费者不是常驻进程或服务,几乎都是临时存在。此外,滴滴、联想等公司也都有采用RocketMQ。
概括地说,发布订阅和消息队列模式虽然都支持系统解耦,但它们在实现时采用的数据结构和方式并不相同。
首先,我们看一下它们实现解耦的数据结构。
然后,我们再看看它们实现解耦的方式。
对于消息队列模式,消息队列中心无需提前获取消费者信息,因此对消费者比较灵活,适合消费者为临时用户的场景;而发布订阅模式,需要消费者提前向消息中心订阅消息,也就是说消息中心需要提前获取消费者信息,比较适合消费者为长驻进程或服务的场景。
今天,我主要与你分享的是分布式通信技术中的消息队列模式。
首先,我通过用户注册的案例,与你介绍了什么是消息队列模式,以及它的好处。其中,消息队列模式中的核心是以一种具有先进先出特点的队列结构来存储数据,实现组件间的解耦和异步执行。
然后,我与你介绍了消息队列的基本原理,并以RocketMQ为例对其架构、核心组件和工作原理做了更深入的讲解,以帮助你进一步了解消息队列模型。
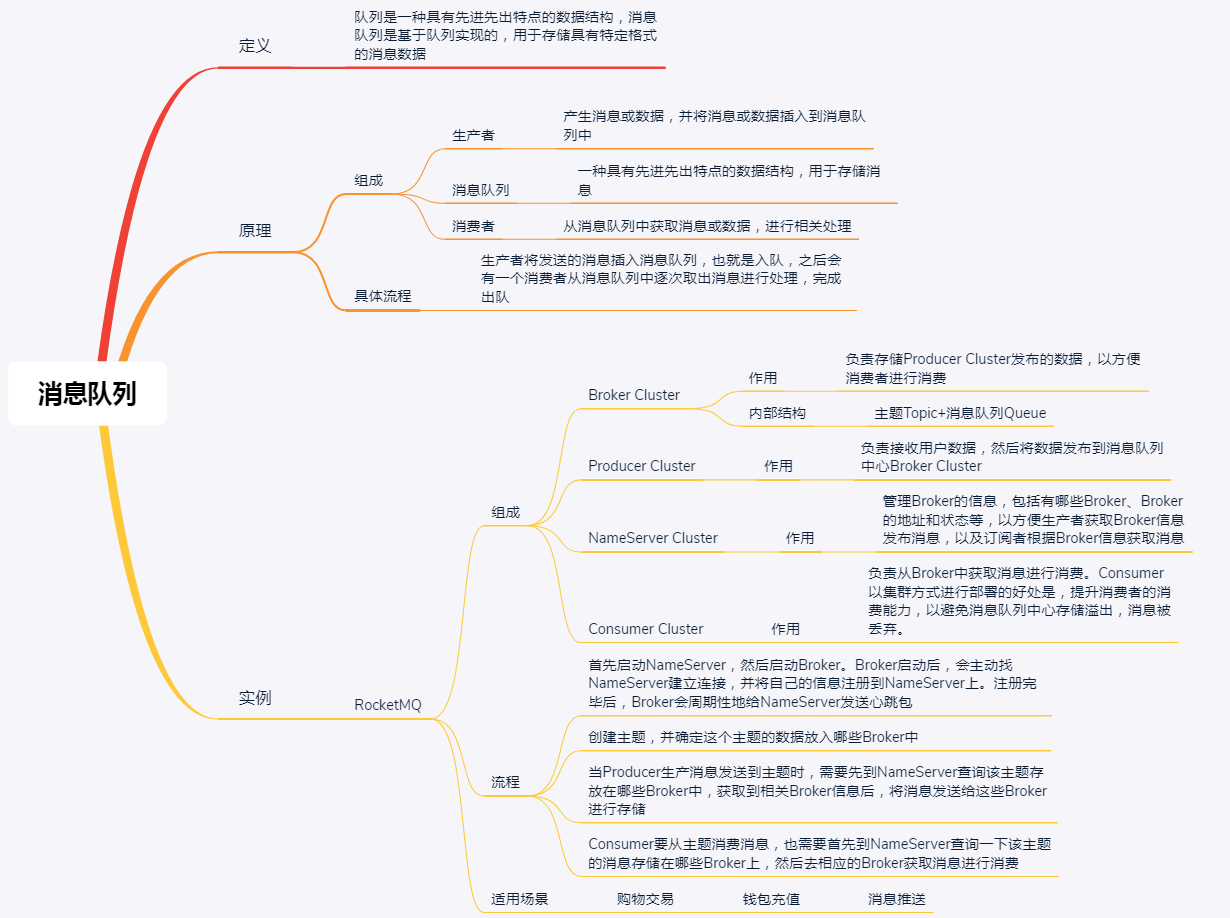
最后,我再通过一张思维导图来归纳一下今天的核心知识点吧。
加油,行动起来,试着将发布订阅和消息队列这两种通信模式用到你的业务场景中吧,相信你可以的。如果你需要进一步了解这两种通信模式对应的产品源码的话,相信你结合这两篇文章中讲述的原理,可以比较容易地开启你的源码之旅了。
消息队列模型中,消费者是主动去消息队列获取消息的,而消息队列需要保证多个消费者可以获取到消息,也就是说一个消费者获取消息后并不会删除该消息,那么如何保证同一个消息不被同一个消费者重复消费呢?
我是聂鹏程,感谢你的收听,欢迎你在评论区给我留言分享你的观点,也欢迎你把这篇文章分享给更多的朋友一起阅读。我们下期再会!
评论