你好,我是王磊,你也可以叫我Ivan。
今天,我想和你聊聊时间的话题。
“时光一去永不回,往事只能回味”,这种咏叹时光飞逝的歌曲,你一定听过很多。但是,在计算机的世界里,时间真的是一去不回吗?还真不一定。
还记得我在第2讲提到的TrueTime吗?作为全局时钟的一种实现形式,它是Google通过 GPS和原子钟两种方式混合提供的授时机制,误差可以控制在7毫秒以内。正是在这7毫秒内,时光是可能倒流的。
为什么我们这么关注时间呢?是穿越剧看多了吗?其实,这是因为分布式数据库的很多设计都和时间有关,更确切地说是和全局时钟有关。比如,我们在第2讲提到的线性一致性,它的基础就是全局时钟,还有后面会讲到的多版本并发控制(MVCC)、快照、乐观协议与悲观协议,都和时间有关。
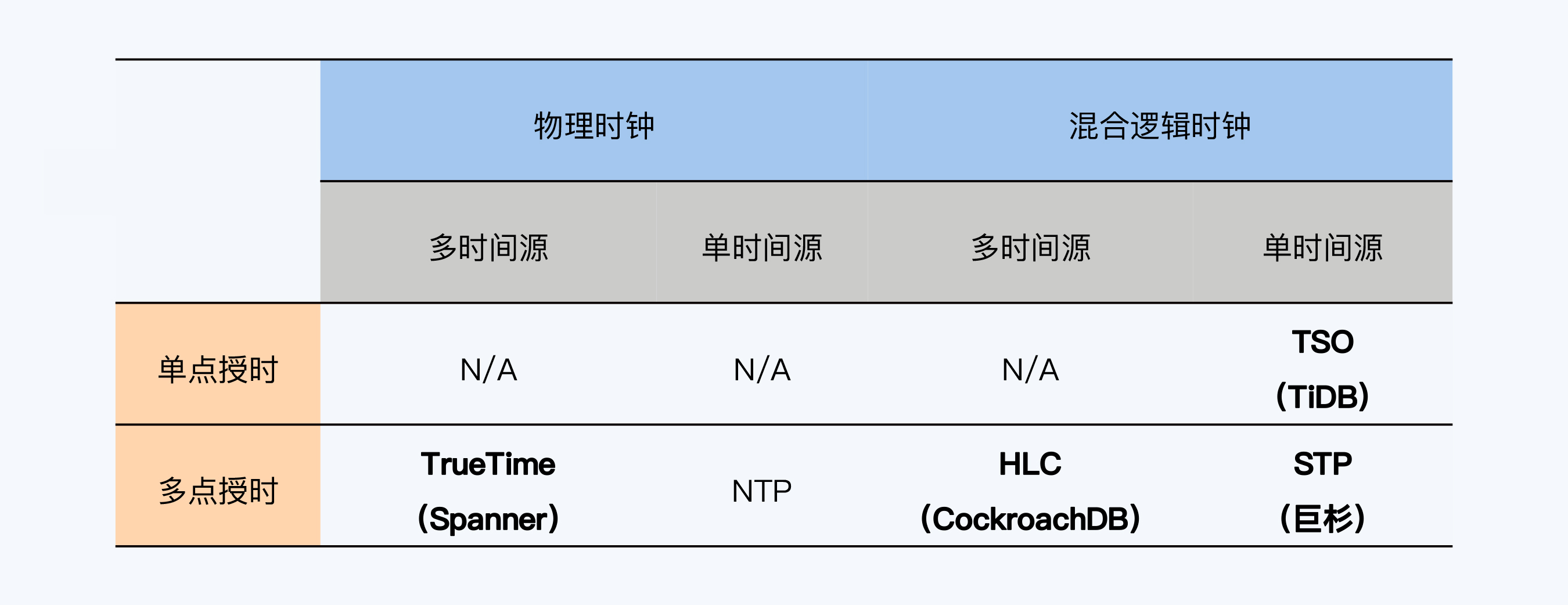
那既然有这么多分布式数据库,授时机制是不是也很多,很复杂呢?其实,要区分授时机制也很简单,抓住三个要素就可以了。
根据排列组合,一共产生了8种可能性,其中NTP(Network Time Protocol)误差大,也不能保证单调递增,所以就没有单独使用NTP的产品;还有一些方案在实践中则是不适用的(N/A)。因此常见的方案主要只有4类,我画了张表格,总结了一下。
Spanner采用的方案是TrueTime。它的时间源是GPS和原子钟,所以属于多时间源和物理时钟,同时它也采用了多点授时机制,就是说集群内有多个时间服务器都可以提供授时服务。
就像这一讲开头说的,TrueTime是会出现时光倒流的。例如,A、B两个进程先后调用TrueTime服务,各自拿到一个时间区间,如果在其中随机选择,则可能出现B的时间早于A的时间。不只是TrueTime,任何物理时钟都会存在时钟偏移甚至回拨。
单个物理时钟会产生误差,而多点授时又会带来整体性的误差,那TrueTime为什么还要这么设计呢?
因为它也有两个显著的优势:首先是高可靠高性能,多时间源和多授时点实现了完全的去中心化设计,不存在单点;其次是支持全球化部署,客户端与时间服务器的距离也是可控的,不会因为两者通讯延迟过长导致时钟失效。
CockroachDB和YugabyteDB也是以高性能高可靠和全球化部署为目标,不过Truetime是Google的独门绝技,它依赖于特定硬件设备的思路,不适用于开源软件。所以,它们使用了混合逻辑时钟(Hybrid Logical Clock,HLC),同样是多时间源、多点授时,但时钟采用了物理时钟与逻辑时钟混合的方式。HLC在实现机制上也是蛮复杂的,而且和TrueTime同样有整体性的时间误差。
对于这个共性问题,Spanner和CockroachDB都会通过一些容错设计来消除时间误差,我会在第12讲中具体介绍相关内容。
其他的分布式数据库大多选择了单时间源、单点授时的方式,承担这个功能的组件在NewSQL风格架构中往往被称为TSO(Timestamp Oracle),而在PGXC风格架构中被称为全局事务管理器(Golobal Transcation Manager,GTM)。这就是说一个单点递增的时间戳和全局事务号基本是等效的。这种授时机制的最大优点就是实现简便,如果能够保证时钟单调递增,还可以简化事务冲突时的设计。但缺点也很明显,集群不能大范围部署,同时性能也有上限。TiDB、OceanBase、GoldenDB和TBase等选择了这个方向。
最后,还有一些小众的方案,比如巨杉的STP(SequoiaDB Time Protoco)。它采用了单时间源、多点授时的方式,优缺点介于HLC和TSO之间。
到这里,我已经介绍了4种方案在技术路线上大致的区别。其中TrueTime是基于物理设备的外部授时方案,所以Spanner直接使用就可以了,自身不需要做专门的设计。而对于其他3种方案,如果我们想要深入理解,那么还得结合具体的产品来看。
首先,我们从最简单的TSO开始。
最早提出TSO的,大概是Google的论文“ Large-scale Incremental Processing Using Distributed Transactions and Notifications”。这篇论文主要是介绍分布式存储系统Percolator的实现机制,其中提到通过一台Oracle为集群提供集中授时服务,称为Timestamp Oracle。所以,后来的很多分布式系统也用它的缩写来命名自己的单点授时机制,比如TiDB和Yahoo的Omid。
考虑到TiDB的使用更广泛些,这里主要介绍TiDB的实现方式。
TiDB的全局时钟是一个数值,它由两部分构成,其中高位是物理时间,也就是操作系统的毫秒时间;低位是逻辑时间,是一个18位的数值。那么从存储空间看,1毫秒最多可以产生262,144个时间戳(2^18),这已经是一个很大的数字了,一般来说足够使用了。
单点授时首先要解决的肯定是单点故障问题。TiDB中提供授时服务的节点被称为Placement Driver,简称PD。多个PD节点构成一个Raft组,这样通过共识算法可以保证在主节点宕机后马上选出新主,在短时间内恢复授时服务。
那问题来了,如何保证新主产生的时间戳一定大于旧主呢?那就必须将旧主的时间戳存储起来,存储也必须是高可靠的,所以TiDB使用了etcd。但是,每产生一个时间戳都要保存吗?显然不行,那样时间戳的产生速度直接与磁盘I/O能力相关,会存在瓶颈的。
如何解决性能问题呢?TiDB采用预申请时间窗口的方式,我画了张图来表示这个过程。
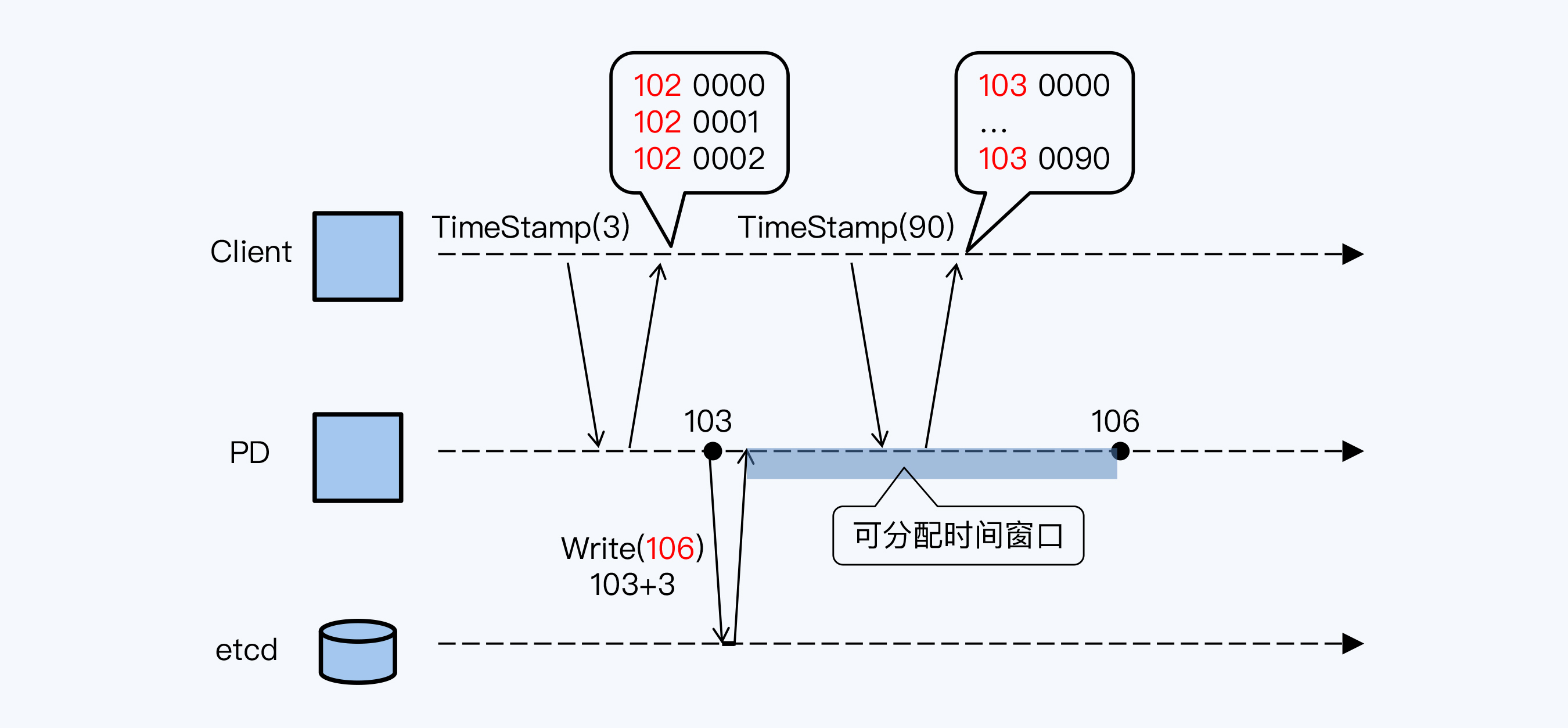
当前PD(主节点)的系统时间是103毫秒,PD向etcd申请了一个“可分配的时间窗口”。要知道时间窗口的跨度是可以通过参数指定的,系统的默认配置是3毫秒,示例采用了默认配置,所以这个窗口的起点是PD当前时间103,时间窗口的终点就在106毫秒处。。写入etcd成功后,PD将得到一个从103到106的“可分配时间窗口”,在这个时间窗口内PD可以使用系统的物理时间作为高位,拼接自己在内存中累加的逻辑时间,对外分配时间戳。
上述设计意味着,所有PD已分配时间戳的高位,也就是物理时间,永远小于etcd存储的最大值。那么,如果PD主节点宕机,新主就可以读取etcd中存储的最大值,在此基础上申请新的“可分配时间窗口”,这样新主分配的时间戳肯定会大于旧主了。
此外,为了降低通讯开销,每个客户端一次可以申请多个时间戳,时间戳数量作为参数,由客户端传给PD。但要注意的是,一旦在客户端缓存,多个客户端之间时钟就不再是严格单调递增的,这也是追求性能需要付出的代价。
前面已经说过TrueTime依赖Google强大的工程能力和特殊硬件,不具有普适性。相反,HLC作为一种纯软的实现方式,更加灵活,所以在CockroachDB、YugabyteDB和很多分布式存储系统得到了广泛使用。
HLC不只是字面上的意思, TiDB的TSO也混合了物理时钟与逻辑时钟,但两者截然不同。HLC代表了一种计时机制,它的首次提出是在论文“Logical Physical Clocks and Consistent Snapshots in Globally Distributed Databases”中,CockroachDB和YugabyteDB的设计灵感都来自于这篇论文。下面,我们结合图片介绍一下这个机制。
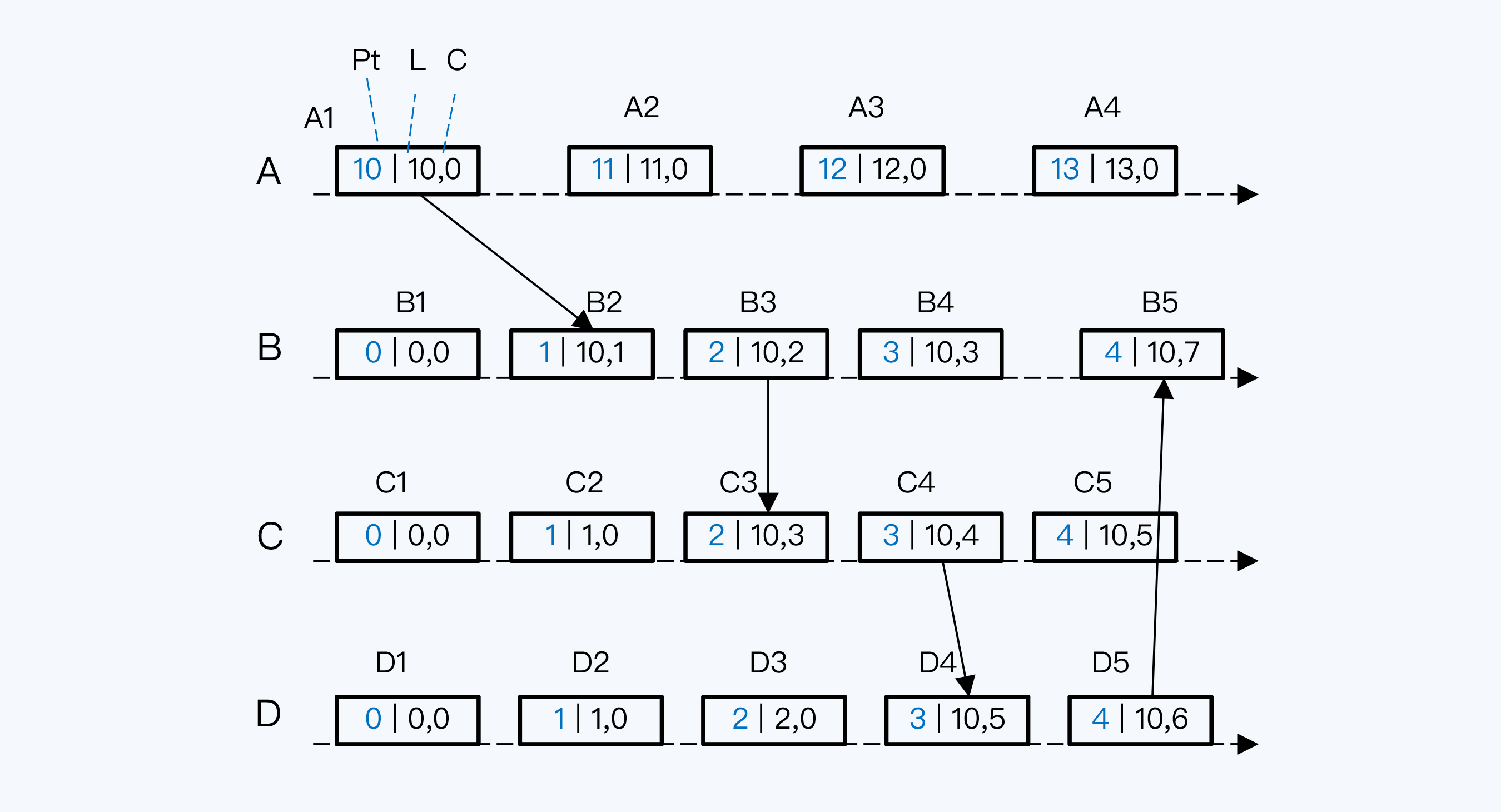
假如我们有ABCD四个节点,方框是节点上发生的事件,方框内的三个数字依次是节点的本地物理时间(简称本地时间,Pt)、HLC的高位(简称L值)和HLC的低位(简称C值)。
A节点的本地时间初始值为10,其他节点的本地时间初始值都是0。四个节点的第一个事件都是在节点刚启动的一刻发生的。首先看A1,它的HLC应该是(10,0),其中高位直接取本地时间,低位从0开始。同理,其他事件的HLC都是(0,0)。
然后我们再看一下,随着时间的推移,接下来的事件如何计时。
事件D2发生时,首先取上一个事件D1的L值和本地时间比较。L值等于0,本地时间已经递增变为1,取最大值,那么用本地时间作为D2的L值。高位变更了,低位要归零,所以D2的HLC就是(1,0)。
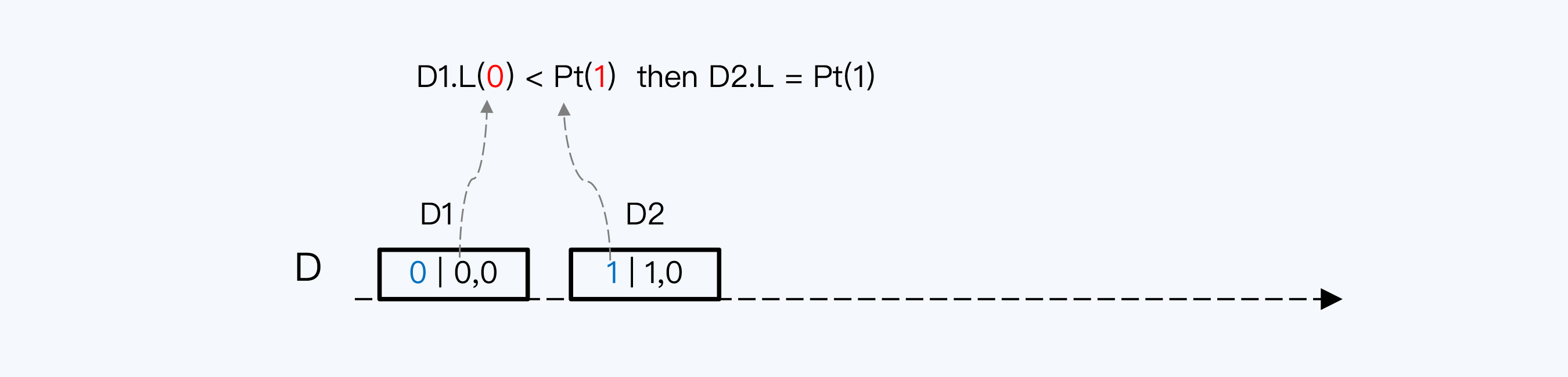
如果你看懂了D2的计时逻辑就会发现,D1其实是一样的,只不过D1没有上一个事件的L值,只能用0代替,是一种特殊情况。
如果节点间有调用关系,计时逻辑会更复杂一点。我们看事件B2,要先判断B2的L值,就有三个备选:
这三个值分别是0、1和10。按照规则取最大值,所以B2的L值是10,也就是A1的L值,而C值就在A1的C值上加1,最终B2的HLC就是(10,1)。
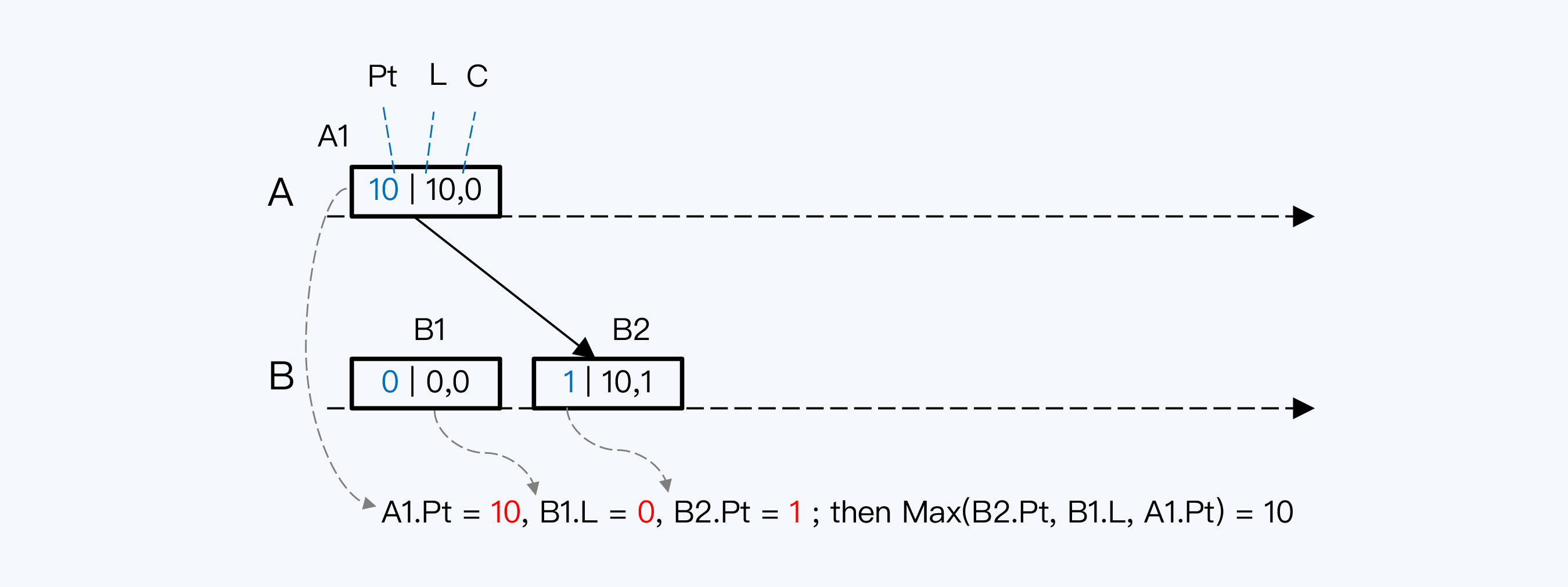
B3事件发生时,发现当前本地时间比B2的L值还要小,所以沿用了B2的L值,而C值是在B2的C值上加一,最终B3的HLC就是(10,2)。

论文中用伪码表述了完整的计时逻辑,我把它们复制在下面,你可以仔细研究。
Initially l:j := 0; c:j := 0
Send or local event
l’:j := l:j;
l:j := max(l’:j; pt:j);
If (l:j=l’:j) then c:j := c:j + 1
Else c:j := 0;
Timestamp with l:j; c:j
Receive event of message m
l’:j := l:j;
l:j := max(l’:j; l:m; pt:j);
If (l:j=l’:j=l:m) then c:j := max(c:j; c:m)+1
Elseif (l:j=l’:j) then c:j := c:j + 1
Elseif (l:j=l:m) then c:j := c:m + 1
Else c:j := 0
Timestamp with l:j; c:j
其中,对于节点J,l.j表示L值,c.j表示C值,pt.j表示本地物理时间。
在HLC机制下,每个节点会使用本地时钟作为参照,但不受到时钟回拨的影响,可以保证单调递增。本质上,HLC还是Lamport逻辑时钟的变体,所以对于不同节点上没有调用关系的两个事件,是无法精确判断先后关系的。比如,上面例子中的C2和D2有同样的HLC,但从上帝视角看,C2是早于D2发生的,因为两个节点的本地时钟有差异,就没有体现这种先后关系。HLC是一种松耦合的设计,所以不会去校正节点的本地时钟,本地时钟是否准确,还要靠NTP或类似的协议来保证。
巨杉采用了单时间源、多点授时机制,它有自己的全局时间协议,称为STP(Serial Time Protocol),是内部逻辑时间同步的协议,并不依赖于NTP协议。
下面是STP体系下各角色节点的关系。
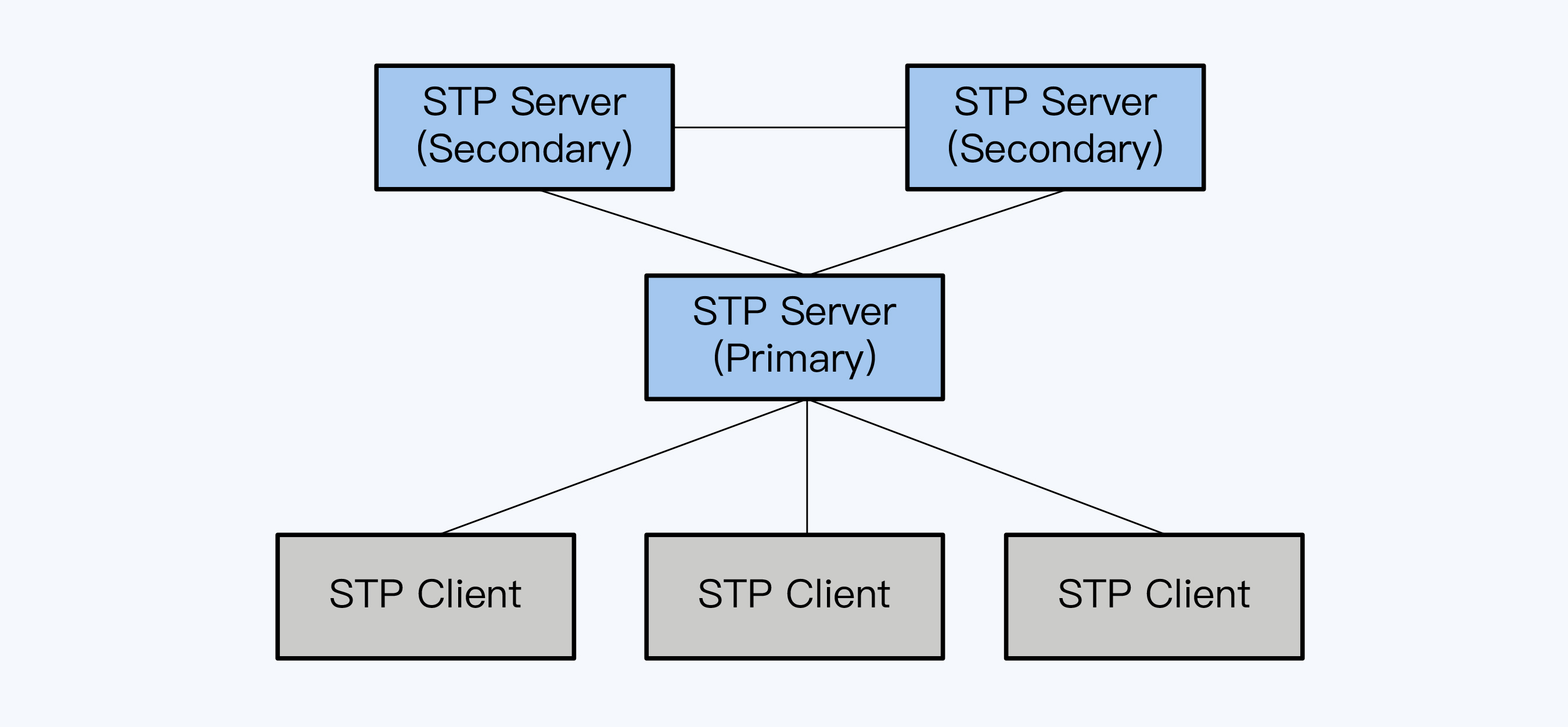
STP是独立于分布式数据库的授时方案,该体系下的各角色节点与巨杉的其他角色节点共用机器,但没有必然的联系。
STP下的所有角色统称为STP Node,具体分为两类:
巨杉数据库的其他角色节点,如编目节点(CATALOG)、协调节点(COORD)和数据节点(DATA)等,都从本地的STP Node节点获得时间。
STP与 TSO一样都是单时间源,但通过增加更多的授时点,避免了单点性能瓶颈,而负副作用是多点授时就会造成全局性的时间误差,因此和HLC一样需要做针对性设计。
好了,今天的内容就到这里了,我们一起回顾下这节课的重点。
有关时间的话题我们就聊到这了。时间误差是普遍存在的,只不过长期在单体应用系统下开发,思维惯性让我们忽略了它,但随着分布式架构的普及,我相信更多的架构设计中都要考虑这个因素。我建议你收藏今天的内容,因为即使抛开分布式数据库不谈,这些设计依然是值得借鉴的。
最后,今天留给你的思考题还是关于时间的。在后续课程没有展开之前,我们不妨先来开放式地讨论一下,你觉得时间对于分布式数据库的影响是什么?或者你也可以谈谈在其他分布式系统中曾经遇到的关于时间的问题。
欢迎你在评论区留言和我一起讨论,我会在答疑篇回复这个问题。如果你身边的朋友也对全局时钟或者分布式架构下如何同步时间这个话题感兴趣,你也可以把今天这一讲分享给他,我们一起讨论。
Daniel Peng and Frank Dabek: Large-scale Incremental Processing Using Distributed Transactions and Notifications
Sandeep S. Kulkarni et al.: Logical Physical Clocks and Consistent Snapshots in Globally Distributed Databases
评论