你好,我是王磊,你也可以叫我Ivan。
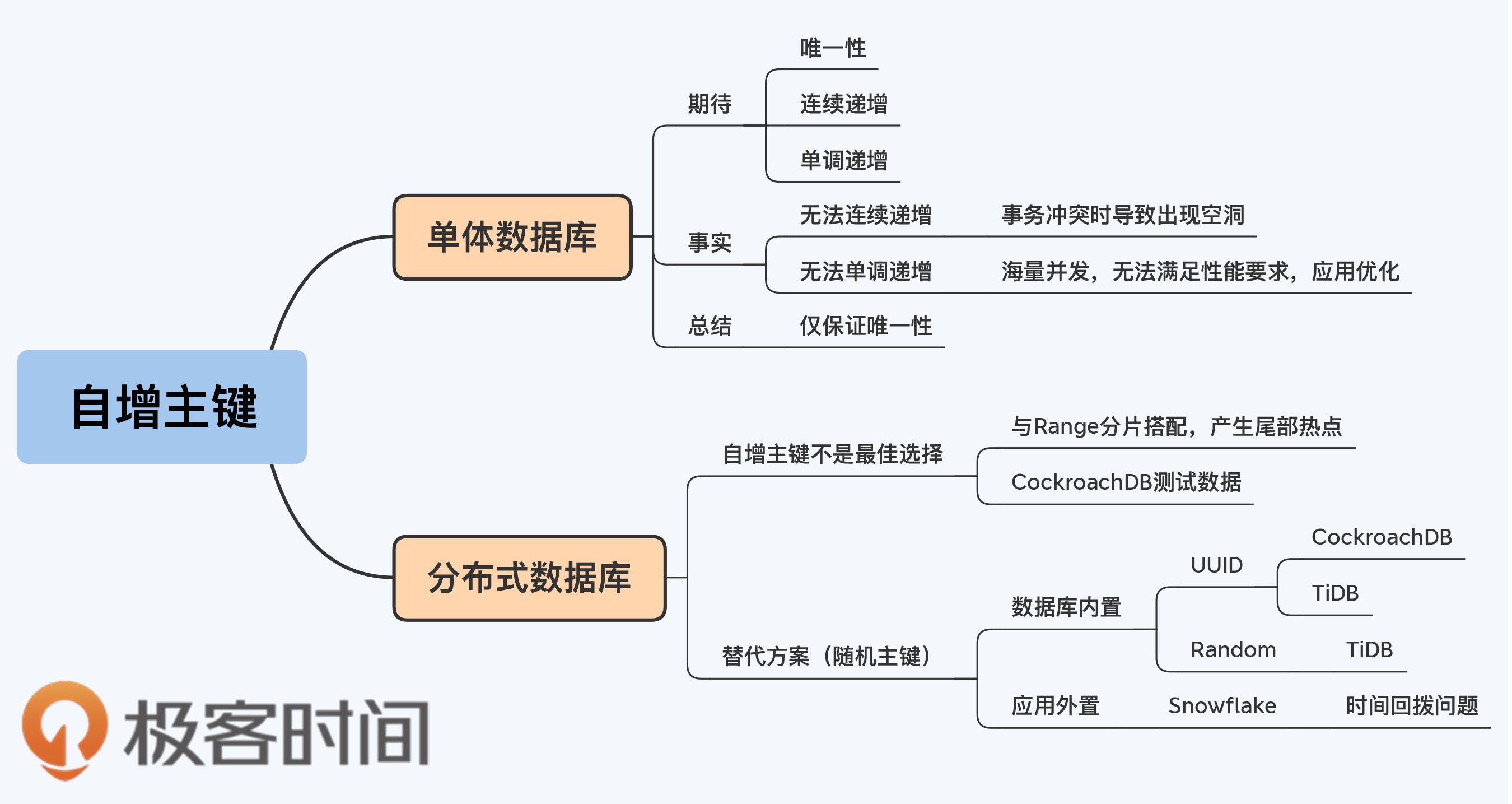
有经验的数据库开发人员一定知道,数据库除了事务处理、查询引擎这些核心功能外,还会提供一些小特性。它们看上去不起眼,却对简化开发工作很有帮助。
不过,这些特性的设计往往是以单体数据库架构和适度的并发压力为前提的。随着业务规模扩大,在真正的海量并发下,这些特性就可能被削弱或者失效。在分布式架构下,是否要延续这些特性也存在不确定性,我们今天要聊的自增主键就是这样的小特性。
虽然,我对自增主键的态度和第16讲提到的存储过程一样,都不推荐你使用,但是原因各有不同。存储过程主要是工程方面的原因,而自增主键则是架构上的因素。好了,让我们进入正题吧。
自增主键在不同的数据库中的存在形式稍有差异。在MySQL中,你可以在建表时直接通过关键字auto_increment来定义自增主键,例如这样:
create table ‘test’ (
‘id’ int(16) NOT NULL AUTO_INCREMENT,
‘name’ char(10) DEFAULT NULL,
PRIMARY KEY(‘id’)
) ENGINE = InnoDB;
而在Oracle中则是先声明一个连续的序列,也就是sequence,而后在insert语句中可以直接引用sequence,例如下面这样:
create sequence test_seq increment by 1 start with 1;
insert into test(id, name) values(test_seq.nextval, ' An example ');
自增主键给开发人员提供了很大的便利。因为,主键必须要保证唯一,而且多数设计规范都会要求,主键不要带有业务属性,所以如果数据库没有内置这个特性,应用开发人员就必须自己设计一套主键的生成逻辑。数据库原生提供的自增主键免去了这些工作量,而且似乎还能满足开发人员的更多的期待。
这些期待是什么呢?我总结了一下,大概有这么三层:
但是,我接下来的分析可能会让你失望,因为除了最基本的唯一性,另外的两层期待都是无法充分满足的。
首先说连续递增。在多数情况下,自增主键确实表现为连续递增。但是当事务发生冲突时,主键就会跳跃,留下空洞。下面,我用一个例子简单介绍下MySQL的处理过程。
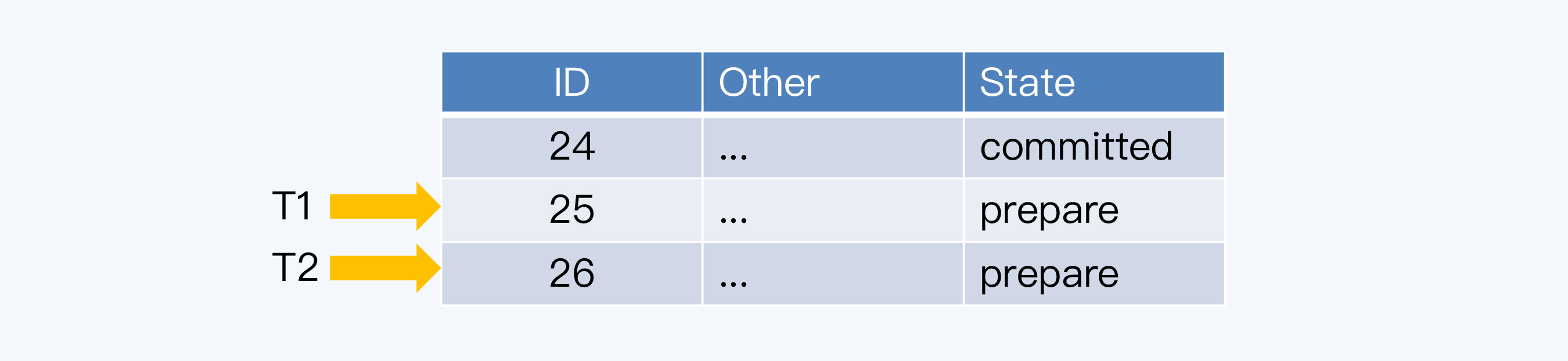
两个事务T1和T2都要在同一张表中插入记录,T1先执行,得到的主键是25,而T2后执行,得到是26。
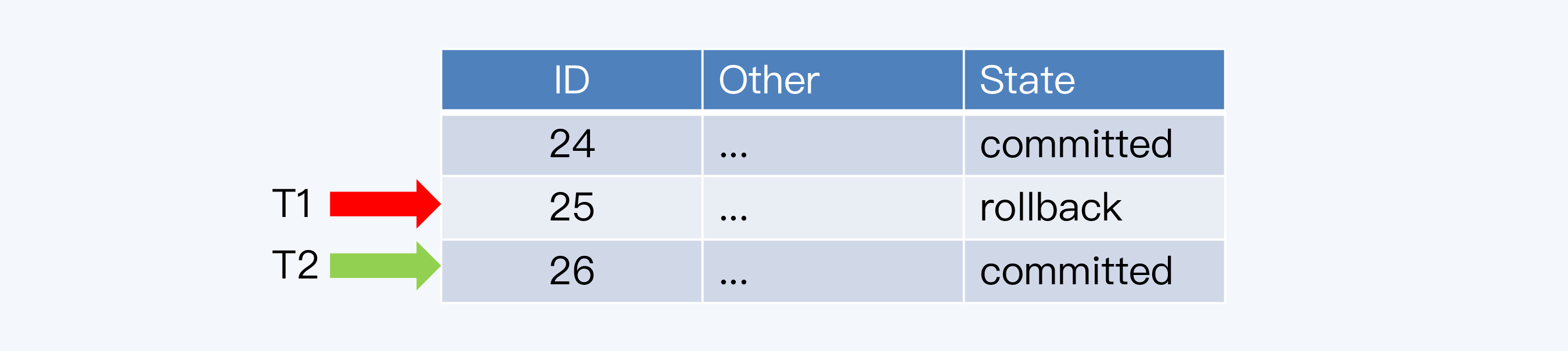
但是,T1事务还要操作其他数据库表,结果不走运,出现了异常,T1必须回滚。T2事务则正常执行成功,完成了事务提交。
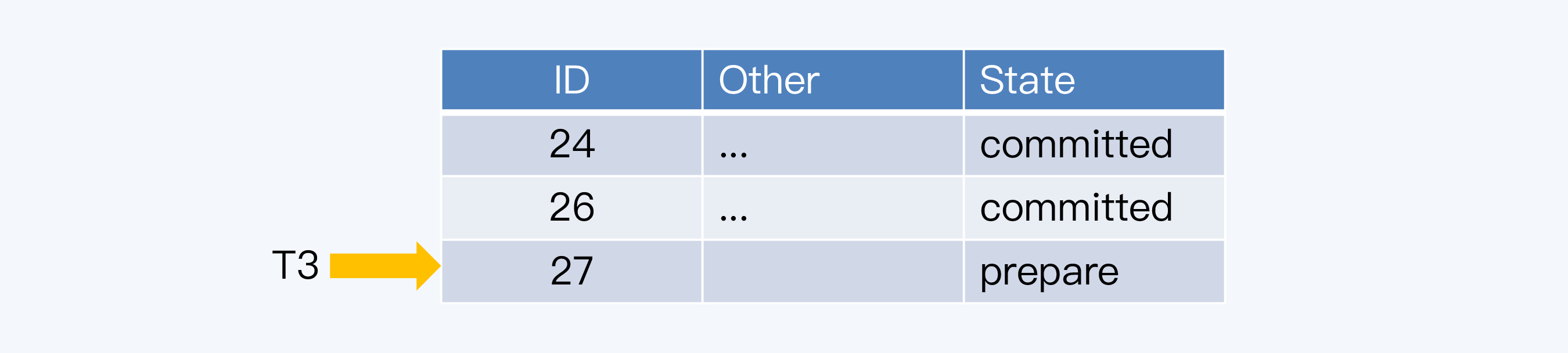
这样,在数据表中就缺少主键为25的记录,而当下一个事务T3再次申请主键时,得到的就是27,那么25就成了永远的空洞。
为什么不支持连续递增呢?这是因为自增字段所依赖的计数器并不是和事务绑定的。如果要做到连续递增,就要保证计数器提供的每个主键都被使用。
怎么确保每个主键都被使用呢?那就要等待使用主键的事务都提交成功。这意味着,必须前一个事务提交后,计数器才能为后一个事务提供新的主键,这个计数器就变成了一个表级锁。
显然,如果存在这么大粒度的锁,性能肯定会很差,所以MySQL优先选择了性能,放弃了连续递增。至于那些因为事务冲突被跳过的数字呢,系统也不会再回收重用了,这是因为要保证自增主键的单调递增。
看到这里你可能会想, 虽然实现不了连续递增,但至少能保证单调递增,也不错。那么,我要再给你泼一盆冷水了,这个单调递增有时也是不能保证的。
对于单体数据库自身来说,自增主键确实是单调递增的。但使用自增主键也是有前提的,那就是主键生成的速度要能够满足应用系统的并发需求。而在高并发量场景下,每个事务都要去申请主键,数据库如果无法及时处理,自增主键就会成为瓶颈。那么,这时只用自增主键已经不能解决问题了,往往还要在应用系统上做些优化。
比如,对于Oracle数据库,常见的优化方式就是由Sequence负责生成主键的高位,由应用服务器负责生成低位数字,拼接起来形成完整的主键。
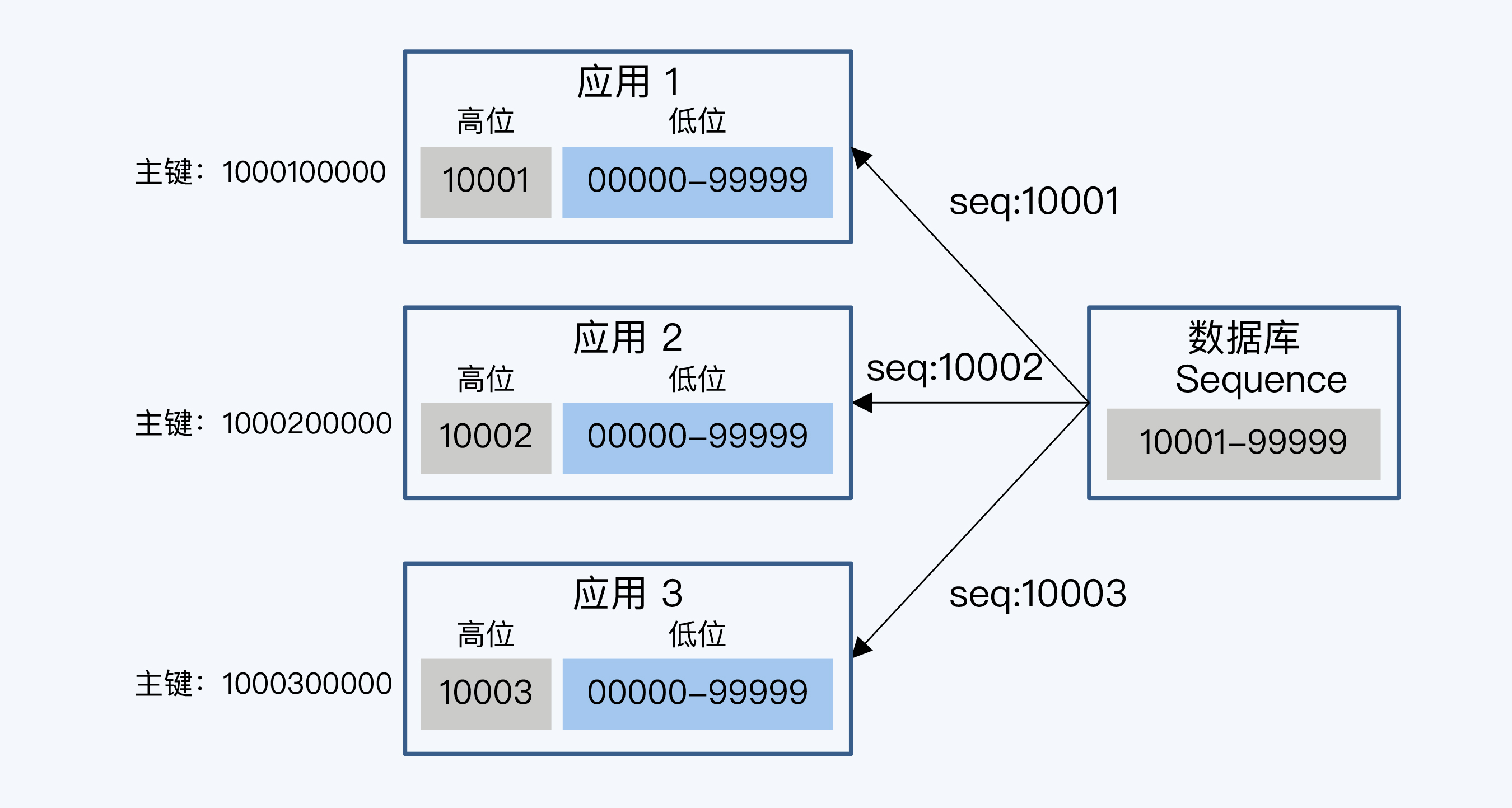
图中展示这样的例子,数据库的Sequence 是一个5位的整型数字,范围从10001到99999。每个应用系统实例先拿到一个号,比如10001,应用系统在使用这5位为作为高位,自己再去拼接5位的低位,这样得到一个10位长度的主键。这样,每个节点访问一次Sequence就可以处理99999次请求,处理过程是基于应用系统内存中的数据计算主键,没有磁盘I/O开销,而相对的Sequence递增时是要记录日志的,所以方案改进后性能有大幅度提升。
这个方案虽然使用了Sequence,但也只能保证全局唯一,数据表中最终保存的主键不再是单调递增的了。
因为,几乎所有数据库中的自增字段或者自增序列都是要记录日志的,也就都会产生磁盘I/O,也就都会面临这个性能瓶颈的问题。所以,我们可以得出一个结论:在一个海量并发场景下,即使借助单体数据库的自增主键特性,也不能实现单调递增的主键。
对于分布式数据库,自增主键带来的麻烦就更大了。具体来说是两个问题,一是在自增主键的产生环节,二是在自增主键的使用环节。
首先,产生自增主键难点就在单调递增。如果你已经学习过第5讲就会发现,单调递增这个要求和全局时钟中的TSO是很相似的。你现在已经知道,TSO实现起来比较复杂,也容易成为系统的瓶颈,如果再用作主键的发生器,显然不大合适。
其次,使用单调递增的主键,也会给分布式数据库的写入带来问题。这个问题是在Range分片下发生的,我们通常将这个问题称为 “尾部热点”。
我们先通过一组性能测试数据来看看尾部热点问题的现象,这些数据和图表来自CockroachDB官网。

这本身是一个CockraochDB与YugabyteDB的对比测试。测试环境使用亚马逊跨机房的三节点集群,执行SQL insert操作时,YugabyteDB的TPS达到58,877,而CockroachDB的TPS是34,587。YugabyteDB集群三个节点上的CPU都得到了充分使用,而CockroachDB集群中负载主要集中在一个节点上,另外两个节点的CPU多数情况都处于空闲状态。
为什么CockroachDB的节点负载这么不均衡呢?这是由于CockroachDB默认设置为Range分片,而测试程序的生成主键是单调递增的,所以新写入的数据往往集中在一个 Range 范围内,而Range又是数据调度的最小单位,只能存在于单节点,那么这时集群就退化成单机的写入性能,不能充分利用分布式读写的扩展优势了。当所有写操作都集中在集群的一个节点时,就出现了我们常说的数据访问热点(Hotspot)。
图中也体现了CockroachDB改为Hash分片时的情况,因为数据被分散到多个Range,所以TPS一下提升到61,113,性能达到原来的1.77倍。
现在性能问题的根因已经找到了,就是同时使用自增主键和Range分片。在第6讲我们已经介绍过了Range分片很多优势,这使得Range分片成为一个不能轻易放弃的选择。于是,主流产品的默认方案是保持Range分片,放弃自增主键,转而用随机主键来代替。
随机主键的产生方式可以分为数据库内置和应用外置两种方式。当然对于应用开发者来说,内置方式使用起来会更加简便。
UUID(Universally Unique Identifier)可能是最经常使用的一种唯一ID算法,CockroachDB也建议使用UUID作为主键,并且内置了同名的数据类型和函数。UUID是由32个的16进制数字组成,所以每个UUID的长度是128位(16^32 = 2^128)。UUID作为一种广泛使用标准,有多个实现版本,影响它的因素包括时间、网卡MAC地址、自定义Namesapce等等。
但是,UUID的缺点很明显,那就是键值长度过长,达到了128位,因此存储和计算的代价都会增加。
TiDB默认是支持自增主键的,对未声明主键的表,会提供了一个隐式主键_tidb_rowid,因为这个主键大体上是单调递增的,所以也会出现我们前面说的“尾部热点”问题。
TiDB也提供了UUID函数,而且在4.0版本中还提供了另一种解决方案AutoRandom。TiDB 模仿MySQL的 AutoIncrement,提供了AutoRandom关键字用于生成一个随机ID填充指定列。

这个随机ID是一个64位整型,分为三个部分。
AutoRandom可以保证表内主键唯一,用户也不需要关注分片情况。
雪花算法(Snowflake)是Twitter公司分布式项目采用的ID生成算法。

这个算法生成的ID是一个64位的长整型,由四个部分构成:
这样,根据数据结构推算,雪花算法支持的TPS可以达到419万左右(2^22*1000),我相信对于绝大多数系统来说是足够了。
但实现雪花算法时,有个小问题往往被忽略,那就是要注意时间回拨带来的影响。机器时钟如果出现回拨,产生的ID就有可能重复,这需要在算法中特殊处理一下。
那么,今天的课程就到这里了,让我们梳理一下这一讲的要点。
课程的最后,我们来看看今天的思考题。我们说如果分布式数据库使用Range分片的情况下,单调递增的主键会造成写入压力集中在单个节点上,出现“尾部热点”问题。因此,很多产品都用随机主键替换自增主键,分散写入热点。我的问题就是,你觉得使用随机主键是不是一定能避免出现“热点”问题呢?
欢迎你在评论区留言和我一起讨论,我会在答疑篇和你继续讨论这个问题。如果你身边的朋友也对分布式架构下如何设计主键这个话题感兴趣,你也可以把今天这一讲分享给他,我们一起讨论。
CockroachDB: Yugabyte vs CockroachDB: Unpacking Competitive Benchmark Claims
评论