你好,我是王磊,你也可以叫我Ivan。
今天是课程正文的最后一讲,时间过得好快呀。在基础篇和开发篇,课程安排追求的是庖丁解牛那样的风格,按照第4讲提到的数据库基本架构,来逐步拆解分布式数据库系统。在介绍每一个关键部件时,我会去关联主流产品的设计,分析背后的理论依据什么,工程优化的思路又是什么。
这样做的好处是能够将抽象理论与具体产品对应起来,更容易理解每个设计点。但它也有一个缺点,就是产品特性被分散开来,不便于你了解整体产品。
为了弥补这个遗憾,今天这一讲,我会把视角切换到产品方向,为你做一次整体介绍。当然对于具体特性,这里我不再重复,而是会给出前面课程的索引。所以,你也可以将这一讲当作一个产品版的课程索引,让你在二刷这门课程时有一个崭新的视角。
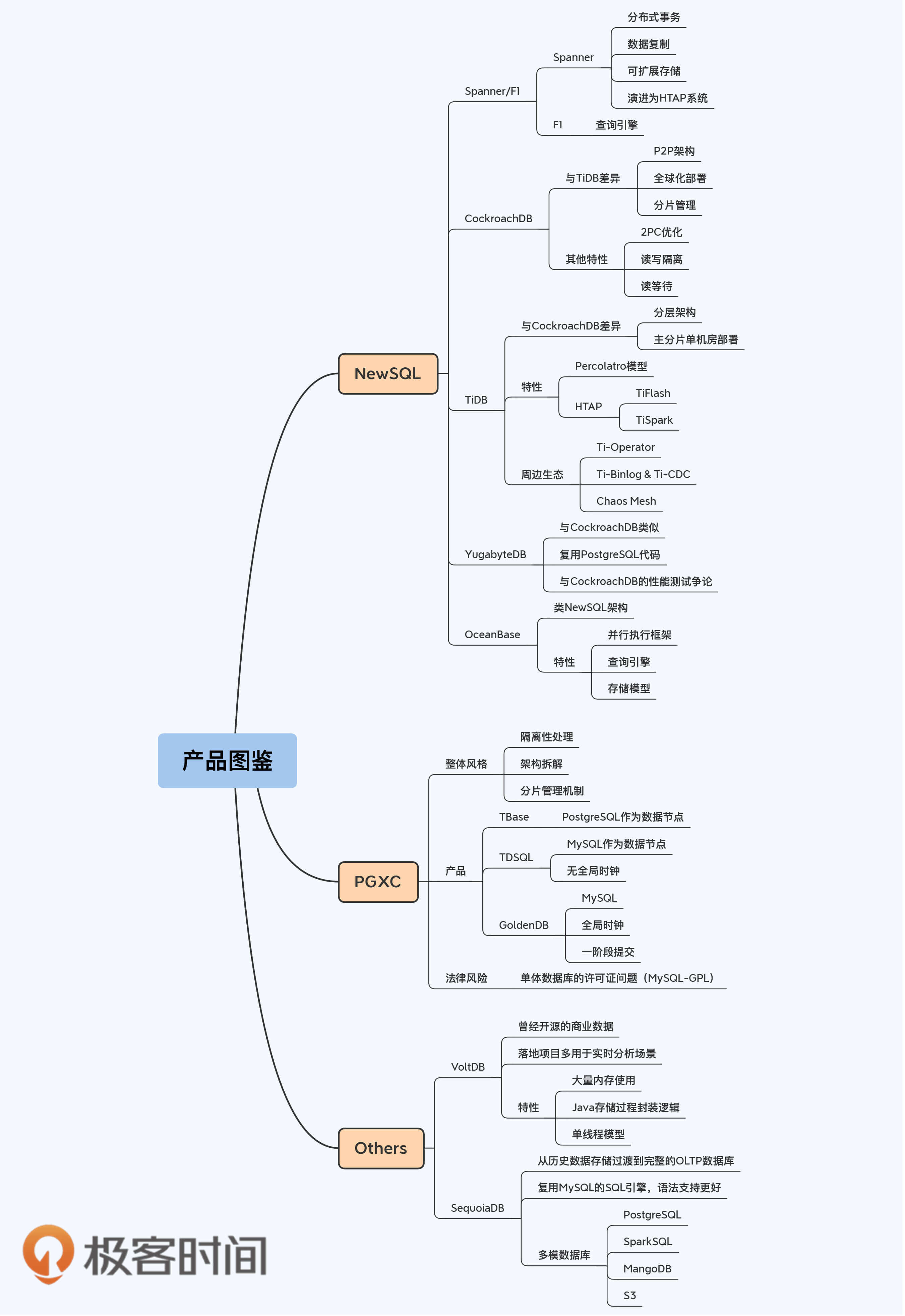
分布式数据库产品,从架构风格上可以分为PGXC和NewSQL这两个大类,以及另外一些小众些的产品。
既然要说分布式数据库产品,第一个必须是Google的Spanner。严格来说,是Spanner和F1一起开创了NewSQL风格,它是这一流派当之无愧的开山鼻祖。
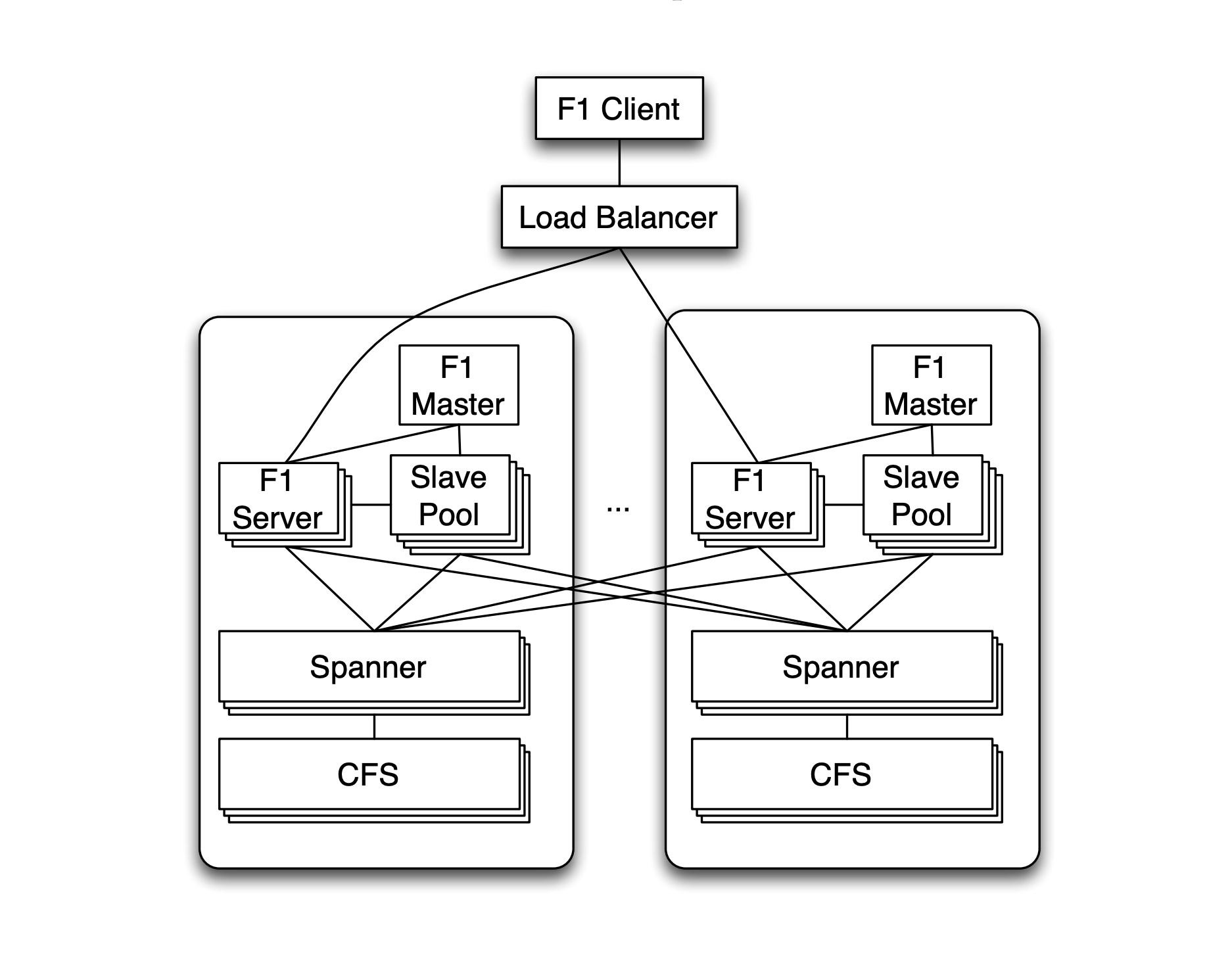
在2012年Google论文“F1: A Distributed SQL Database That Scales”中首先描述了这个组合的整体架构。
其中F1主要作为SQL引擎,而事务一致性、复制机制、可扩展存储等特性都是由Spanner完成的,所以我们有时会忽略F1,而更多地提到Spanner。
Google在2012年的另一篇论文 “Spanner: Google’s Globally-Distributed Database”中介绍了Spanner的主要设计。
Spanner架构中的核心处理模块是Spanserver,下面是它的架构图。
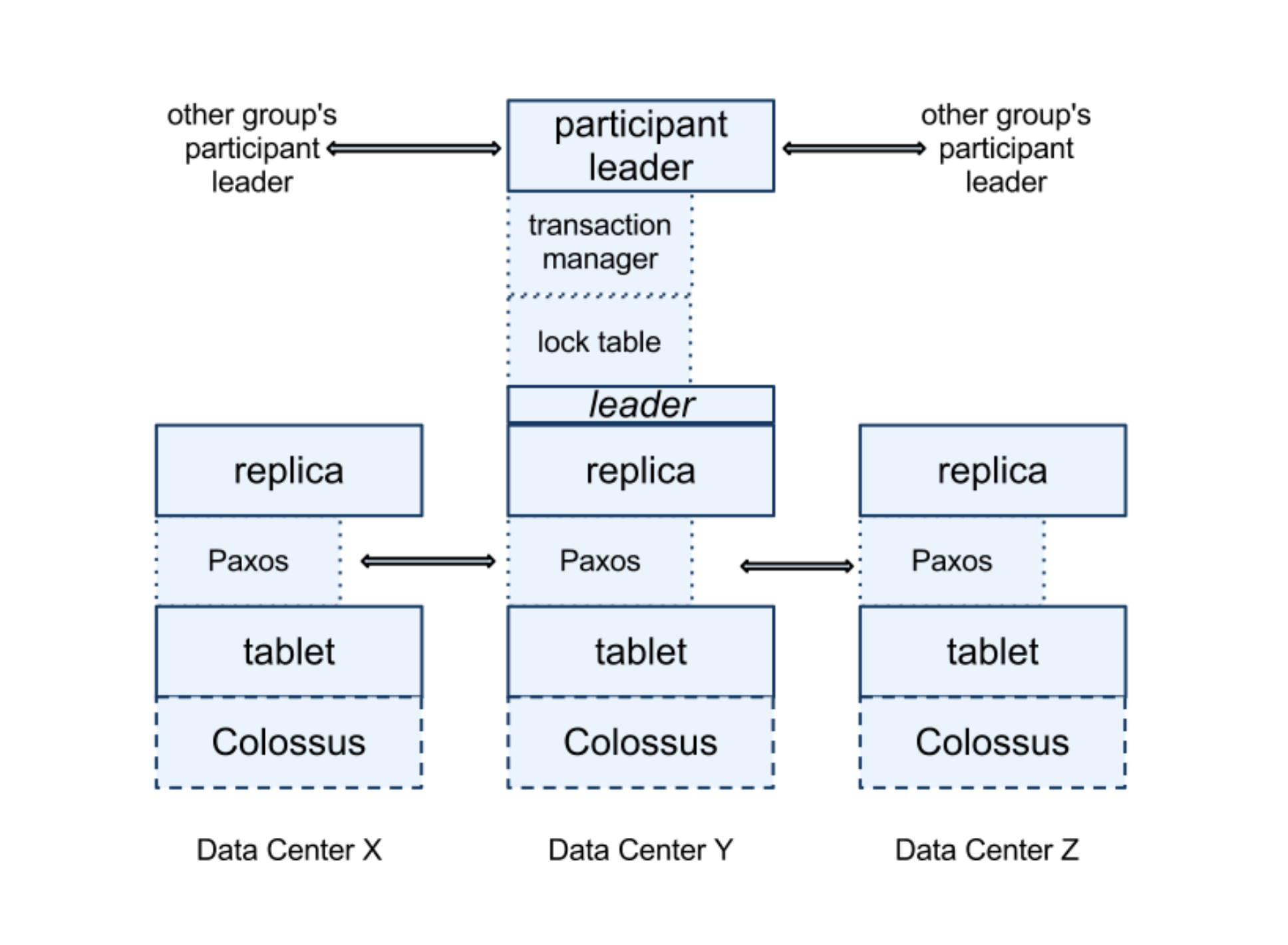
从图中我们可以看到,Spanserver的核心工作有三部分:
在第5讲和第12讲,我们还介绍了基于全局时钟的数据一致性管理机制和处理时间误差的“写等待机制”。
我们都知道,软件架构会随着业务发展而演进,2017年,Google又发表了两篇新论文,介绍了Spanner和F1的最新变化。它们从原来的“金牌组合”走向了“单飞”模式。
Spanner的论文是“Spanner: Becoming a SQL System”。就像论文名字所说的,Spanner完善了SQL功能,这样就算不借助F1,也能成为一个完整的数据库。
这篇论文用大量篇幅介绍了SQL处理机制,同时在系统定位上相比2012版有一个大的变化,强调了兼容OLTP和OLAP,也就是HTAP。对应的,Spanner在存储层的设计也从2012版中的CFS切换到了Ressi。Ressi是类似PAX的行列混合数据布局(Data Layout),我们在第18讲专门谈了对HTAP未来发展的看法,并对各种不同的数据布局进行了分析。
F1的新论文是“F1 Query: Declarative Querying at Scale”。这一版论文中F1不再强调和Spanner的绑定关系,而是支持更多的底层存储。非常有意思的是,F1也声称自己可以兼顾OLTP和OLAP。
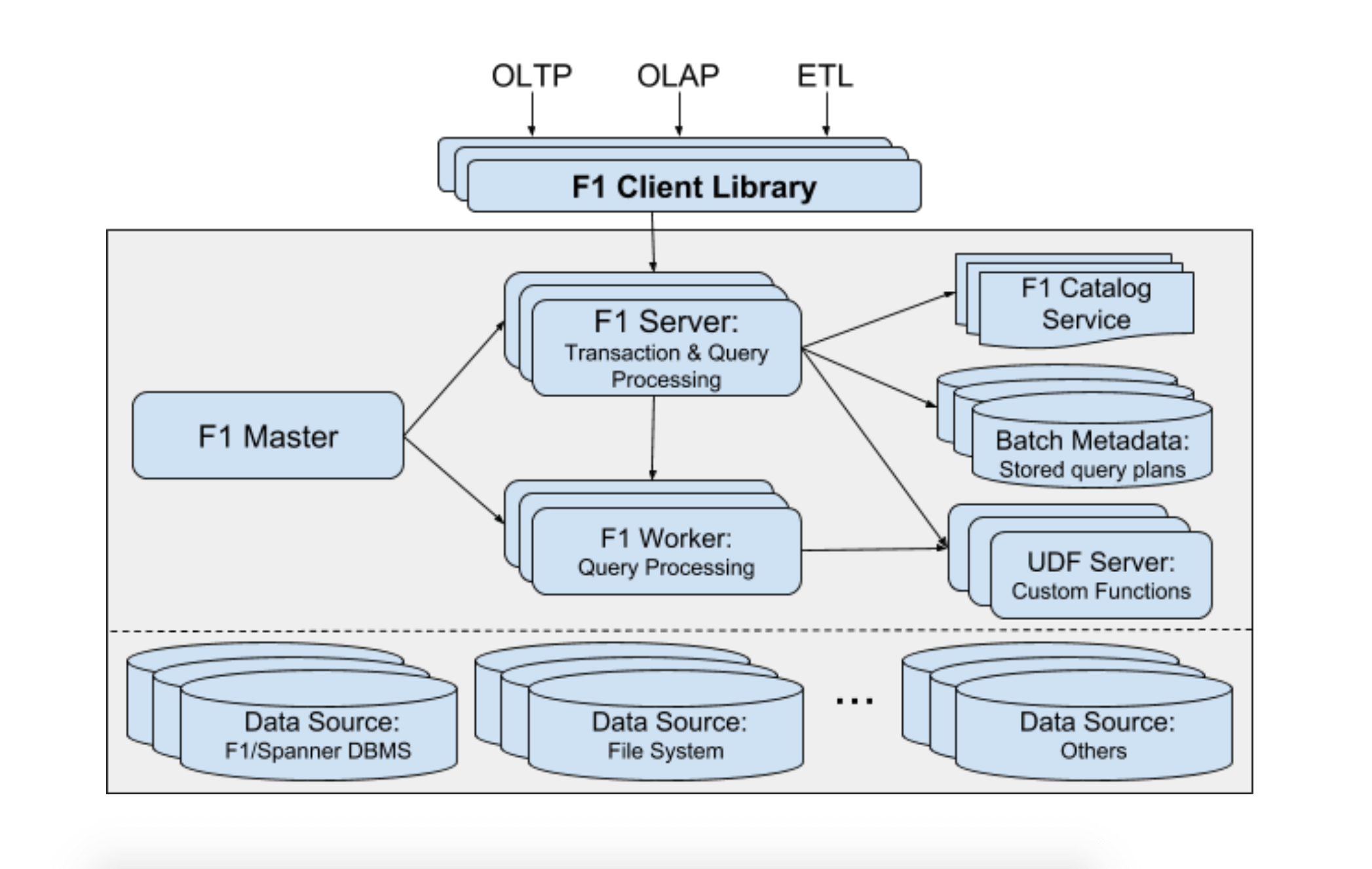
这个架构中还有一个我们很感兴趣的点,就是F1通过UDF Server来实现存储过程的支持。我们在第16讲中对此进行了简单的探讨。
按照时间顺序,在Spanner之后出现的NewSQL产品是CockroachDB。CockroachDB和TiDB、YugabyteDB都公开声称设计灵感来自Spanner,所以往往会被认为是同构的产品。尤其是CockroachDB和TiDB,经常会被大家拿来比较。但是,从系统架构上看,这两个产品有非常大的差别。让我们先从CockroachDB角度来总结下。
最大的差别来自架构的整体风格。CockroachDB采用了标准的P2P架构,这是一个非常极客的设计。只有P2P架构能够做到绝对的无中心,这意味着只要损坏的节点不超过总数一半,那么集群就仍然可以正常工作。因此,CockroachDB具有超强的生存能力,而这也很符合产品名称的语义。
第二个重要差异是全球化部署。CockroachDB采用了混合逻辑时钟(HLC),所以能够在全球物理范围下做到数据一致性。这一点对标了Spanner的特性,不同之处是Spanner的TrueTime是依赖硬件的,而HLC机制完全基于软件实现。我在第5讲对它的设计做了深入的分析,而对于HLC的理论基础Lamport时钟,我在第2讲中也做了介绍。
第三个点则是分片管理机制的不同。因为整体架构的差异,CockroachDB在分片管理上也跟TiDB有明显的区别,我们在第6讲中做了介绍。
另外,我还在第10讲介绍了CockroachDB的2PC优化,第11讲介绍了CockroachDB的读写隔离策略,第12讲介绍了如何用读等待方式解决时间误差问题。
2020年,CockroachDB发表的论文“CockroachDB: The Resilient Geo-DistributedSQL Database”被SIGMOD收录。这篇论文对CockroachDB的架构设计做了比较全面的介绍,非常值得你仔细阅读。
TiDB也是对标Spanner的NewSQL数据库,因为开源的运行方式和良好的社区运营,它在工程师群体中拥有很高的人气。
不同于CockroachDB的P2P架构,TiDB采用了分层架构,由TiDB、TiKV和PD三类角色节点构成,TiKV作为底层分布式键值存储,TiDB作为SQL引擎,PD承担元数据管理和全局时钟的职责。
与Spanner不同的是,底层存储TiKV并不能独立支持事务,而是通过TiDB协调实现,事务控制模型采用了Percolator。我们在第9讲和第13讲介绍了TiDB的事务模型。
作为与CockroachDB的另一个显著区别,TiDB更加坚定的走向HTAP,在原有架构上拓展TiSpark和TiFlash,在第18讲我们介绍了这部分的设计。同时,TiDB对于周边生态工具建设投入了大量资源,由此诞生了一些衍生项目:
第25讲、第26讲和第27讲的内容与上述项目具有直接的对应关系。这些项目的创立,丰富了TiDB的服务交付方式,也使TiDB的产品线变得更长。但是它们否都有很好的发展前景,还有待观察。
当然,TiDB架构也存在一些明显的缺陷,比如不支持全球化部署,这为跨地域大规模集群应用TiDB设置了障碍。
与CockroachDB一样,TiDB在2020年也发布了一篇论文“TiDB, A Raft-based HTAP Database”被VLDB收录,论文全面介绍了TiDB的架构设计,同样推荐你仔细阅读。
SIGMOD和VLDB是数据库领域公认的两大顶会,而TiDB和CockroachDB先后发表产品论文,颇有一时瑜亮的感觉。
YugabyteDB是较晚推出的NewSQL数据库,在架构上和CockroachDB有很多相似之处,比如支持全球化部署,采用混合逻辑时钟(HLC),基于Percolator的事务模型,兼容PostgreSQL协议。所以,课程中对CockroachDB的介绍会帮助你快速了解YugabyteDB。
为数不多的差异是,YugabyteDB选择直接复用PostgreSQL的部分代码,所以它的语法兼容性更好。
可能是由于高度的相似性,YugabyteDB与CockroachDB的竞争表现得更加激烈。YugabyteDB率先抛出了产品比对测试,证明自己处理性能全面领先,这引发了CockroachDB的反击,随后双方不断回应。我们在第17讲引用了这场论战中的部分内容。如果你想了解更多内容可以查看的相关博客。
从历史沿革看,OceanBase诞生的时间可以追溯到2010年,但是那时产品形态是KV存储,直到在1.0版本后才确立了目前的产品架构。OceanBase大体上也是P2P架构,但会多出一个Proxy层。
由于OceanBase是一款商业软件,所以对外披露的信息比较有限,我们的课程中在并行执行框架、查询引擎和存储模型三部分对OceanBase做了一些介绍,分别对应第20讲、第21讲和第22讲。期待OceanBase团队能够放出更多有价值的材料。
PGXC使用单体数据库作为数据节点,在架构上的创新远少于NewSQL,所以我们在课程内容上所占篇幅也较少,而且是作为一个整体风格进行介绍。在第3讲,我们从单体数据库的隔离级别引申到PGXC的隔离性协议。第4讲,我们详细拆解了PGXC的架构,也就是协调节点、数据节点、全局时钟和元数据管理等四个部分。第6讲,我们介绍了PGXC的分片机制。还有一些特性,例如数据复制是继承自单体数据库。事实上,有关单体数据库实现的说明都对了解PGXC有所帮助。
TBase是最标准的PGXC,采用PostgreSQL作为数据节点。但TBase推出的时间较晚,应用案例也相对较少。从一些宣传资料看,TBase更加强调HTAP的属性。但考虑到TBase与TDSQL都是腾讯出品,我认为这或许是出于商业策略的考虑,毕竟从架构本身看,TBase与TDSQL的差异是比较有限的。
TDSQL是腾讯公司内部最早的分布式数据库,它的数据节点选择了MySQL。我曾经提到过,TDSQL目前的主推版本并没有实现全局时钟,这意味着它在数据一致性上是存在缺失的。所以严格意义上说,它并不是分布式数据库,当然我们也可以通过一些公开信息了解到TDSQL在一致性方面的努力,相信完善这部分功能应该只是时间问题。
GoldenDB几乎是国内银行业应用规模最大的分布式数据库,和TDSQL同样在数据节点上选择了MySQL,但全局时钟节点的增加使它称为一个标准的PGXC架构。
GoldenDB对事务模型进行了改造,我们在第9讲介绍了它的分布式事务模型“一阶段提交”。
分库分表方案是一个长期流行的方案,有各种同质化产品,所以进一步演化出多少种PGXC风格的数据库很难历数清楚。借助单体数据库的优势,无疑会发展的更加快捷,但始终存在一个隐患。那就是单体数据库的许可证问题,尤其是那些选择MySQL作为数据节点的商业数据库。
MySQL采用的GPL协议,这意味着不允许修改后和衍生的代码作为商业化软件发布和销售,甚至是只要采用了开源软件的接口和库都必须开放源码,否则将面对很大的法律风险。
除了以上两种主流分布式数据库外,还有一些小众产品。虽然它们的使用不那么广泛也,但也很有特点。
VoltDB一度也是开源数据库,但在2019年正式闭源,变为纯商业化产品。而同时,VoltDB在国内也没有建立完备的服务支持体系,这在很大程度上影响到它的推广。另外,VoltDB虽然支持OLTP场景,但在国内的落地项目中多用于实时分析场景,例如金融反欺诈等。
VoltDB的主要特点是完全基于内存的分布式数据库,使用存储过程封装业务逻辑,采用单线程方式简化了事务模型。我们在第16讲对VoltDB做了简单介绍。
巨杉数据库(SquoiadDB)在早期并不支持完整事务,所以应用场景主要是归档数据和影像数据存储,而后从3.0版本开始逐步过渡到完整的OLTP分布式数据库。我们在第4讲介绍了巨杉的全局时钟实现方式,就是它在完善事务一致性方面的重大进展。
巨杉的架构其实跟MySQL架构非常相似,也分为SQL引擎和存储引擎上下两层。巨杉在上层直接复用了MySQL的SQL引擎,下层则使用自己的分布式存储引擎替换了InnoDB。这种架构设计意味着巨杉可以非常好地兼容MySQL语法,就像YugabyteDB兼容PostgreSQL那样。
巨杉支持的还不只MySQL,事实上它已经逐渐发展为一款多模数据库,同时兼容MySQL、PostgreSQL、SparkSQL,并支持Json类型数据部分兼容MongoDB,和S3对象存储等。
那么,今天的课程就到这里了,让我们梳理一下这一讲的要点。
2012年Google发表的两篇论文奠定了Spanner/F1作为NewSQL数据库开山鼻祖的地位。因为其中存储引擎、复制机制、分布式事务都在Spanner中实现,所以大家有时会略去F1。而后,Spanner演进为一个自带SQL引擎的完整数据库,并且同时兼顾OLAP和OLTP场景。
CockroachDB与TiDB都是Github上非常热门的项目,设计灵感均来自Spanner。虽然两者在部分设计上采用了相同的策略,例如引入RocksDB、支持Raft协议等,但在很多重要特性上仍有很大差距,例如全球化部署、时钟机制、分片管理、HTAP支持程度等。
YugabyteDB与CockroachDB具有更大的相似性,导致两者间的竞争更加激烈。OceanBase作为阿里的一款自研软件,整体风格上接近于NewSQL,所以很多设计在原理上完全相同的。但由于商用软件的关系,开放的资料上远少于其他NewSQL数据库。
PGXC数据库是从分库分表方案上发展而来,而这一步跨越的关键就是通过全局时钟支持更严格的数据一致性和事务一致性。PGXC具有架构稳定的优势,往往被视为更稳妥的方案,但单体数据库的软件许可证始终是PGXC架构商业数据库一个很大的法律隐患。
VoltDB和巨杉数据库是小众一些的数据库,在设计上采用了较为独特的方式,从而也带来了差异化的特性。
课程的最后,我们来看下思考题。今天,我们简要总结了课程中提到的各类分布式数据库的特点。但是近年来,学术界对分布式数据库的研究非常活跃,工业实践的热潮也日益高涨,短短的30讲真的难以历数。所以,我的问题是,除了上面提到的数据库之外,你还了解哪些有特点的分布式数据库吗?提示一下,在课程中出现过的至少还有两种。
欢迎你在评论区留言和我一起讨论,我会在答疑篇和你继续讨论这个问题。如果你身边的朋友想快速了解分布式数据库都有哪些产品,你可以把今天这一讲分享给他,可能会帮他更高效的锁定产品,期待你的朋友们也一起加入我们的讨论。
Bart Samwel et al: F1 Query: Declarative Querying at Scale
David F. Bacon et al: Spanner: Becoming a SQL System
Dongxu Huang et al.: TiDB, A Raft-based HTAP Database
Jeff Shute et al.: F1: A Distributed SQL Database That Scales
James C. Corbett et al.: Spanner: Google’s Globally-Distributed Database
Rebecca Taft et al.: CockroachDB: The Resilient Geo-DistributedSQL Database
评论