你好,我是李兵。
相信你在使用JavaScript的过程中,经常会遇到栈溢出的错误,比如执行下面这样一段代码:
function foo() {
foo() // 是否存在堆栈溢出错误?
}
foo()
V8就会报告栈溢出的错误,为了解决栈溢出的问题,我们可以在foo函数内部使用setTimeout来触发foo函数的调用,改造之后的程序就可以正确执行 。
function foo() {
setTimeout(foo, 0) // 是否存在堆栈溢出错误?
}
如果使用Promise来代替setTimeout,在Promise的then方法中调用foo函数,改造的代码如下:
function foo() {
return Promise.resolve().then(foo)
}
foo()
在浏览器中执行这段代码,并没有报告栈溢出的错误,但是你会发现,执行这段代码会让整个页面卡住了。
为什么这三段代码,第一段造成栈溢出的错误,第二段能够正确执行,而第三段没有栈溢出的错误,却会造成页面的卡死呢?
其主要原因是这三段代码的底层执行逻辑是完全不同的:
这是因为,V8执行这三种不同代码时,它们的内存布局是不同的,而不同的内存布局又会影响到代码的执行逻辑,因此我们需要了解JavaScript执行时的内存布局。
这节课,我们从函数特性入手,来一步步延伸出通用的函数调用模型,进而来分析不同的函数调用方式是如何影响到运行时内存布局的。
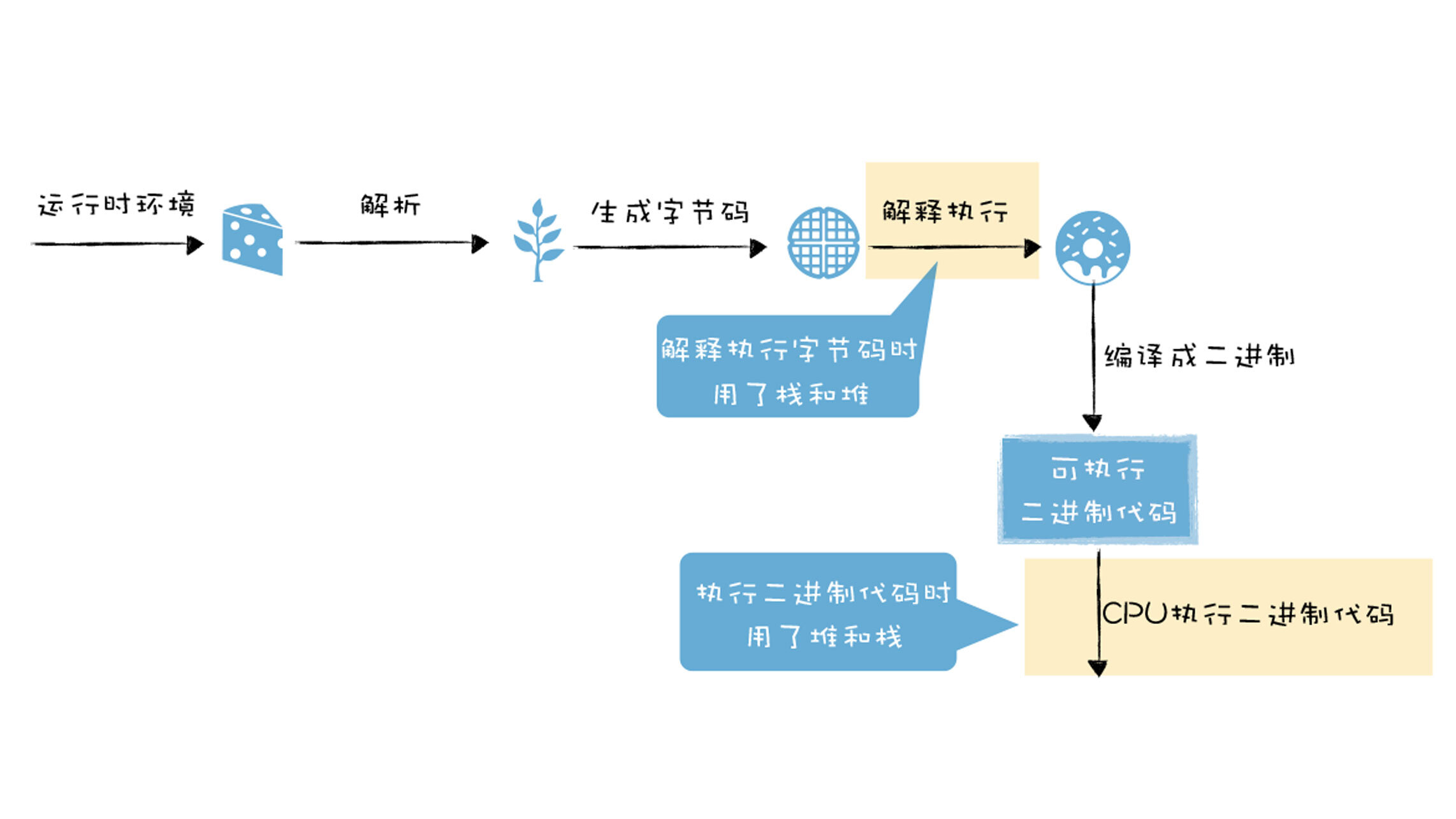
下图是本文的主要内容在编译流水线中的位置,因为解释执行和直接执行二进制代码都使用了堆和栈,虽然它们在执行细节上存在着一定的差异,但是整体的执行架构是类似的。
我们知道,大部分高级语言都不约而同地采用栈这种结构来管理函数调用,为什么呢?这与函数的特性有关。通常函数有两个主要的特性:
我们可以看下面这段C代码:
int getZ()
{
return 4;
}
int add(int x, int y)
{
int z = getZ();
return x + y + z;
}
int main()
{
int x = 5;
int y = 6;
int ret = add(x, y);
}
观察上面这段代码,我们发现其中包含了多层函数嵌套调用,其实这个过程很简单,执行流程是这样的:
具体的函数调用示意图如下:

通过上述分析,我们可以得出,函数调用者的生命周期总是长于被调用者(后进),并且被调用者的生命周期总是先于调用者的生命周期结束(先出)。
在执行上述流程时,各个函数的生命周期如下图所示:

因为函数是有作用域机制的,作用域机制通常表现在函数执行时,会在内存中分配函数内部的变量、上下文等数据,在函数执行完成之后,这些内部数据会被销毁掉。所以站在函数资源分配和回收角度来看,被调用函数的资源分配总是晚于调用函数(后进),而函数资源的释放则总是先于调用函数(先出)。如下图所示:

通过观察函数的生命周期和函数的资源分配情况,我们发现,它们都符合后进先出(LIFO)的策略,而栈结构正好满足这种后进先出(LIFO)的需求,所以我们选择栈来管理函数调用关系是一种很自然的选择。
关于栈,你可以结合这么一个贴切的例子来理解,一条单车道的单行线,一端被堵住了,而另一端入口处没有任何提示信息,堵住之后就只能后进去的车子先出来(后进先出),这时这个堵住的单行线就可以被看作是一个栈容器,车子开进单行线的操作叫做入栈,车子倒出去的操作叫做出栈。
在车流量较大的场景中,就会发生反复地入栈、栈满、出栈、空栈和再次入栈,一直循环。你可以参看下图:

了解了栈的特性之后,我们就来看看栈是如何管理函数调用的。
首先我们来分析最简单的场景:当执行一个函数的时候,栈怎么变化?
当一个函数被执行时,函数的参数、函数内部定义变量都会依次压入到栈中,我们结合实际的代码来分析下这个过程,你可以参考下图:

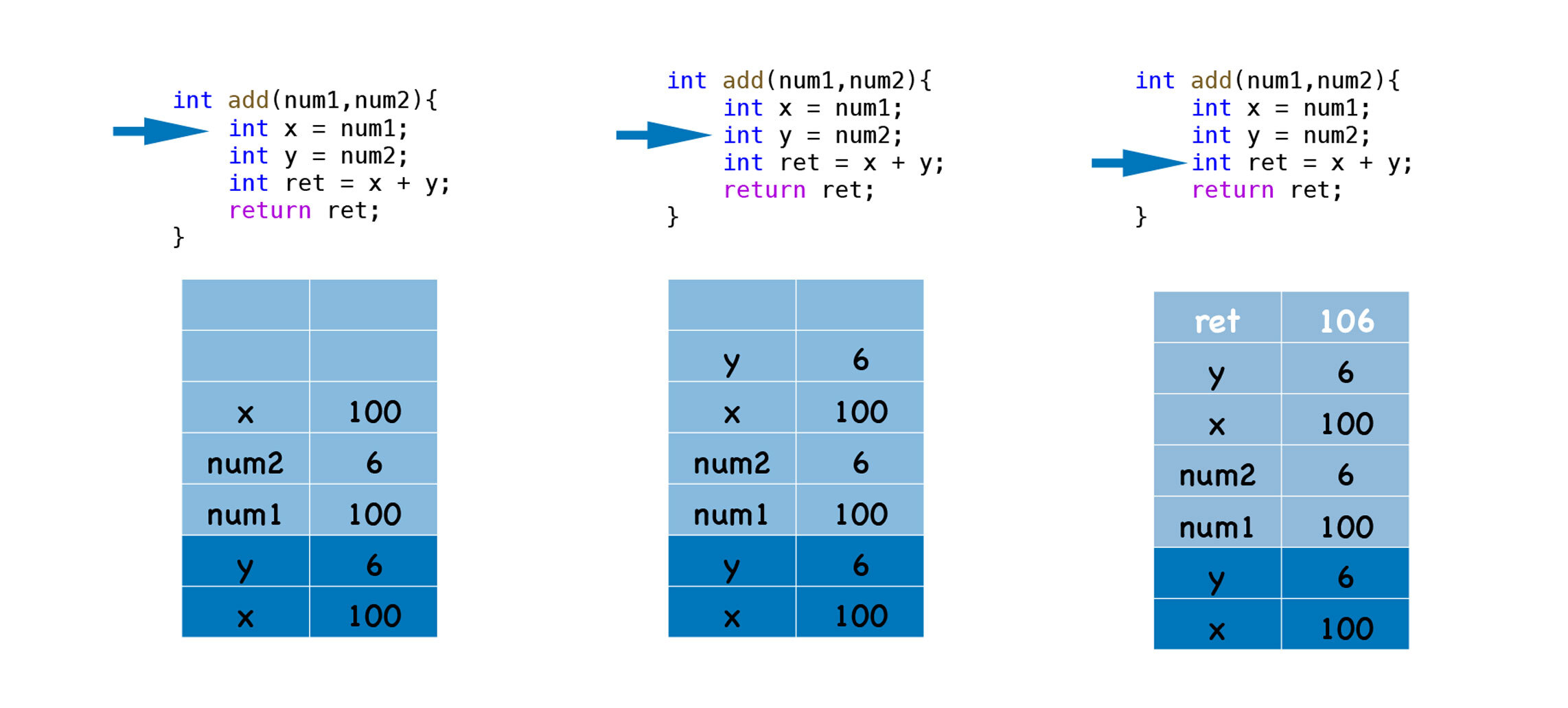
上图展示的是一段简单的C代码的执行过程,可以看到:
你会发现,函数在执行过程中,其内部的临时变量会按照执行顺序被压入到栈中。
了解了这一点,接下来我们就可以分析更加复杂一点的场景了:当一个函数调用另外一个函数时,栈的变化情况是怎样的?我们还是先看下面这段代码:
int add(num1,num2){
int x = num1;
int y = num2;
int ret = x + y;
return ret;
}
int main()
{
int x = 5;
int y = 6;
x = 100;
int z = add(x,y);
return z;
}
观察上面这段代码,我们把上段代码中的x+y改造成了一个add函数,当执行到int z = add(x,y)时,当前栈的状态如下所示:

接下来,就要调用add函数了,理想状态下,执行add函数的过程是下面这样的:
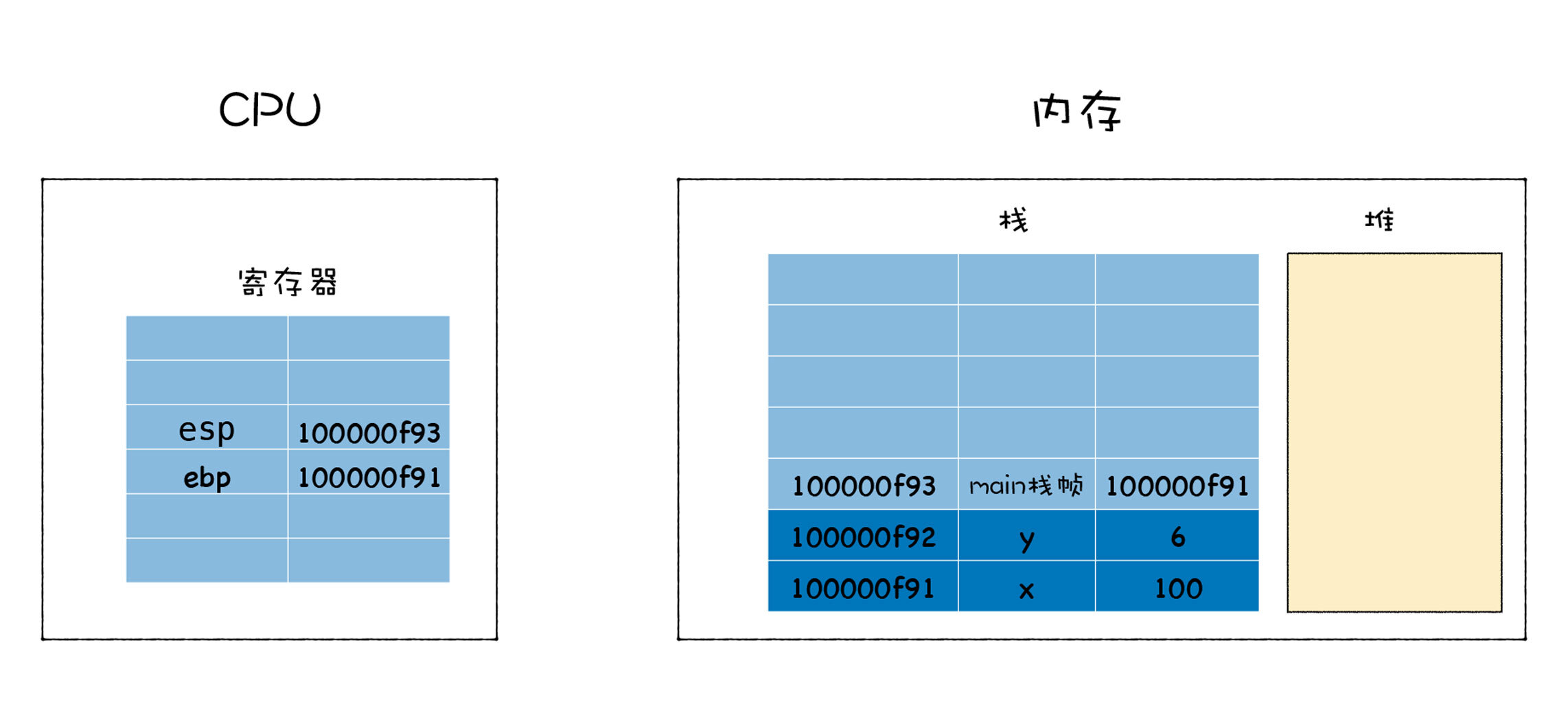
当执行到add函数时,会先把参数num1和num2压栈,接着我们再把变量x、y、ret的值依次压栈,不过执行这里,会遇到一个问题,那就是当add函数执行完成之后,需要将执行代码的控制权转交给main函数,这意味着需要将栈的状态恢复到main函数上次执行时的状态,我们把这个过程叫恢复现场。那么应该怎么恢复main函数的执行现场呢?
其实方法很简单,只要在寄存器中保存一个永远指向当前栈顶的指针,栈顶指针的作用就是告诉你应该往哪个位置添加新元素,这个指针通常存放在esp寄存器中。如果你想往栈中添加一个元素,那么你需要先根据esp寄存器找到当前栈顶的位置,然后在栈顶上方添加新元素,新元素添加之后,还需要将新元素的地址更新到esp寄存器中。
有了栈顶指针,就很容易恢复main函数的执行现场了,当add函数执行结束时,只需要将栈顶指针向下移动就可以了,具体你可以参看下图:


观察上图,将esp的指针向下移动到之前main函数执行时的地方就可以,不过新的问题又来了,CPU是怎么知道要移动到这个地址呢?
CPU的解决方法是增加了另外一个ebp寄存器,用来保存当前函数的起始位置,我们把一个函数的起始位置也称为栈帧指针,ebp寄存器中保存的就是当前函数的栈帧指针,如下图所示:

在main函数调用add函数的时候,main函数的栈顶指针就变成了add函数的栈帧指针,所以需要将main函数的栈顶指针保存到ebp中,当add函数执行结束之后,我需要销毁add函数的栈帧,并恢复main函数的栈帧,那么只需要取出main函数的栈顶指针写到esp中即可(main函数的栈顶指针是保存在ebp中的),这就相当于将栈顶指针移动到main函数的区域。
那么现在,我们可以执行main函数了吗?
答案依然是“不能”,这主要是因为main函数也有它自己的栈帧指针,在执行main函数之前,我们还需恢复它的栈帧指针。如何恢复main函数的栈帧指针呢?
通常的方法是在main函数中调用add函数时,CPU会将当前main函数的栈帧指针保存在栈中,如下图所示:
当函数调用结束之后,就需要恢复main函数的执行现场了,首先取出ebp中的指针,写入esp中,然后从栈中取出之前保留的main的栈帧地址,将其写入ebp中,到了这里ebp和esp就都恢复了,可以继续执行main函数了。
另外在这里,我们还需要补充下栈帧的概念,因为在很多文章中我们会看到这个概念,每个栈帧对应着一个未运行完的函数,栈帧中保存了该函数的返回地址和局部变量。
以上我们详细分析了C函数的执行过程,在JavaScript中,函数的执行过程也是类似的,如果调用一个新函数,那么V8会为该函数创建栈帧,等函数执行结束之后,销毁该栈帧,而栈结构的容量是固定的,所有如果重复嵌套执行一个函数,那么就会导致栈会栈溢出。
了解了这些,现在我们再回过头来看下这节课开头提到的三段代码。
第一段代码由于循环嵌套调用了foo,所以当函数运行时,就会导致foo函数会不断地调用foo函数自身,这样就会导致栈无限增,进而导致栈溢出的错误。
第二段代码是在函数内部使用了setTimeout来启动foo函数,这段代码之所以不会导致栈溢出,是因为setTimeout会使得foo函数在消息队列后面的任务中执行,所以不会影响到当前的栈结构。 也就不会导致栈溢出。关于消息队列和事件循环系统,我们会在最后一单元来介绍。
最后一段代码是Promise,Promise的情况比较特别,既不会造成栈溢出,但是这种方式会导致主线的卡死,这就涉及到了微任务,关于微任务在这里我们先不展开介绍,我会在微任务这一节来详细介绍。
好了,我们现在理解了栈是怎么管理函数调用的了,使用栈有非常多的优势:
虽然操作速度非常快,但是栈也是有缺点的,其中最大的缺点也是它的优点所造成的,那就是栈是连续的,所以要想在内存中分配一块连续的大空间是非常难的,因此栈空间是有限的。
因为栈空间是有限的,这就导致我们在编写程序的时候,经常一不小心就会导致栈溢出,比如函数循环嵌套层次太多,或者在栈上分配的数据过大,都会导致栈溢出,基于栈不方便存放大的数据,因此我们使用了另外一种数据结构用来保存一些大数据,这就是堆。
和栈空间不同,存放在堆空间中的数据是不要求连续存放的,从堆上分配内存块没有固定模式的,你可以在任何时候分配和释放它,为了更好地理解堆,我们看下面这段代码是怎么执行的:
struct Point
{
int x;
int y;
};
int main()
{
int x = 5;
int y = 6;
int *z = new int;
*z = 20;
Point p;
p.x = 100;
p.y = 200;
Point *pp = new Point();
pp->y = 400;
pp->x = 500;
delete z;
delete pp;
return 0;
}
观察上面这段代码,你可以看到代码中有new int、new Point这种语句,当执行这些语句时,表示要在堆中分配一块数据,然后返回指针,通常返回的指针会被保存到栈中,下面我们来看看当main函数快执行结束时,堆和栈的状态,具体内容你可以参看下图:
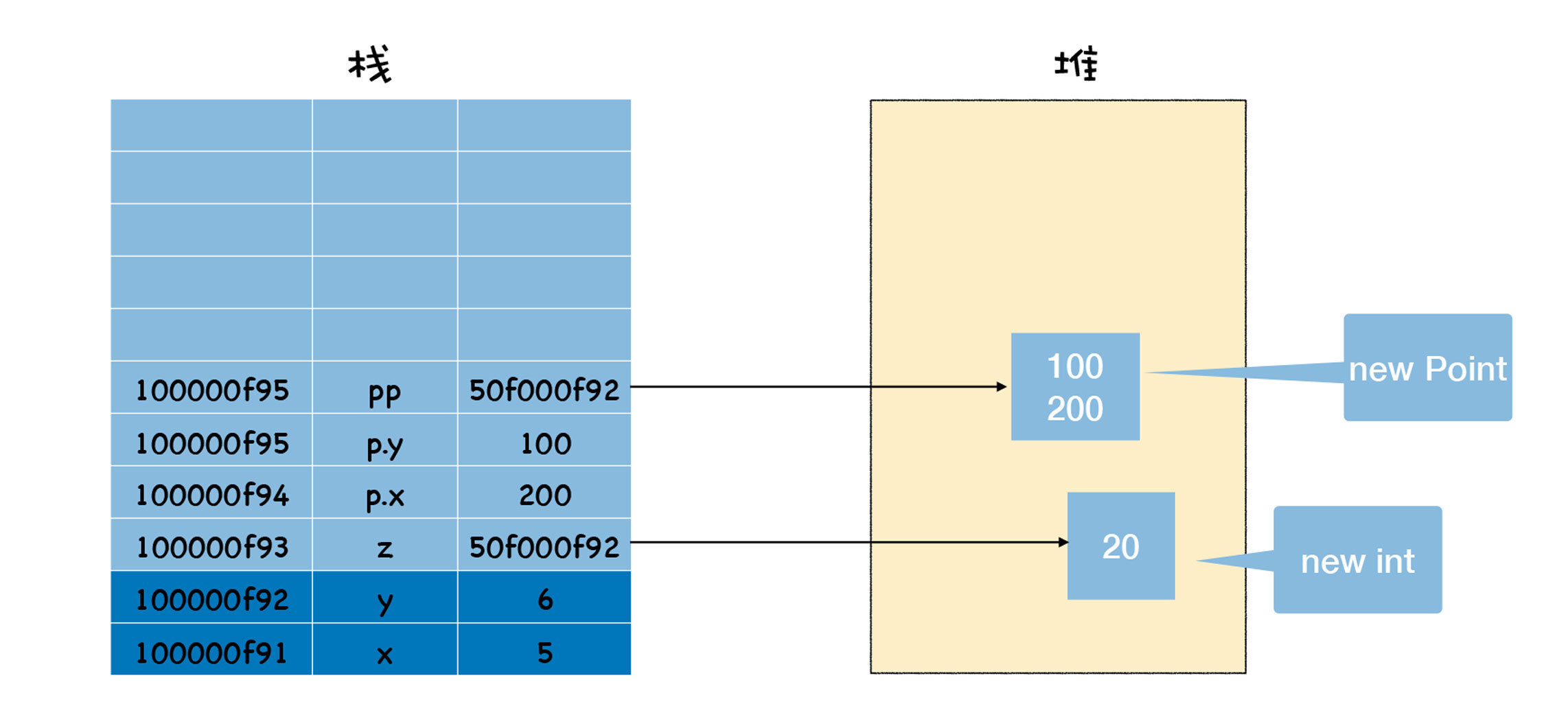
观察上图,我们可以发现,当使用new时,我们会在堆中分配一块空间,在堆中分配空间之后,会返回分配后的地址,我们会把该地址保存在栈中,如上图中p和pp都是地址,它们保存在栈中,指向了在堆中分配的空间。
通常,当堆中的数据不再需要的时候,需要对其进行销毁,在C语言中可以使用free,在C++语言中可以使用delete来进行操作,比如可以通过:
delete p;
delete pp;
来销毁堆中的数据,像C/C++这种手动管理内存的语言,如果没有手动销毁堆中的数据,那么就会造成内存泄漏。不过JavaScript,Java使用了自动垃圾回收策略,可以实现垃圾自动回收,但是事情总有两面性,垃圾自动回收也会给我们带来一些性能问题。所以不管是自动垃圾回收策略,还是手动垃圾回收策略,要想写出高效的代码,我们都需要了解内存的底层工作机制。
因为现代语言都是基于函数的,每个函数在执行过程中,都有自己的生命周期和作用域,当函数执行结束时,其作用域也会被销毁,因此,我们会使用栈这种数据结构来管理函数的调用过程,我们也把管理函数调用过程的栈结构称之为调用栈。
因为栈在内存中连续的数据结构,所以在通常情况下,栈都有最大容量限制,这也就意味着,函数的嵌套调用次数过多,就会超出栈的最大使用范围,从而导致栈溢出。
为了解决栈溢出的问题,我们可以使用setTimeout将要执行的函数放到其他的任务中去执行,也可以使用Promise来改变栈的调用方式,这涉及到了事件循环和微任务,我们会在后续课程中再来介绍。
你可以分析一下,在浏览器中执行这段代码,为什么不会造成栈溢出,但是却会造成页面的卡死?欢迎你在留言区与我分享讨论。
function foo() {
return Promise.resolve().then(foo)
}
foo()
感谢你的阅读,如果你觉得这一讲的内容对你有所启发,也欢迎把它分享给你的朋友。