你好,我是Rocky。
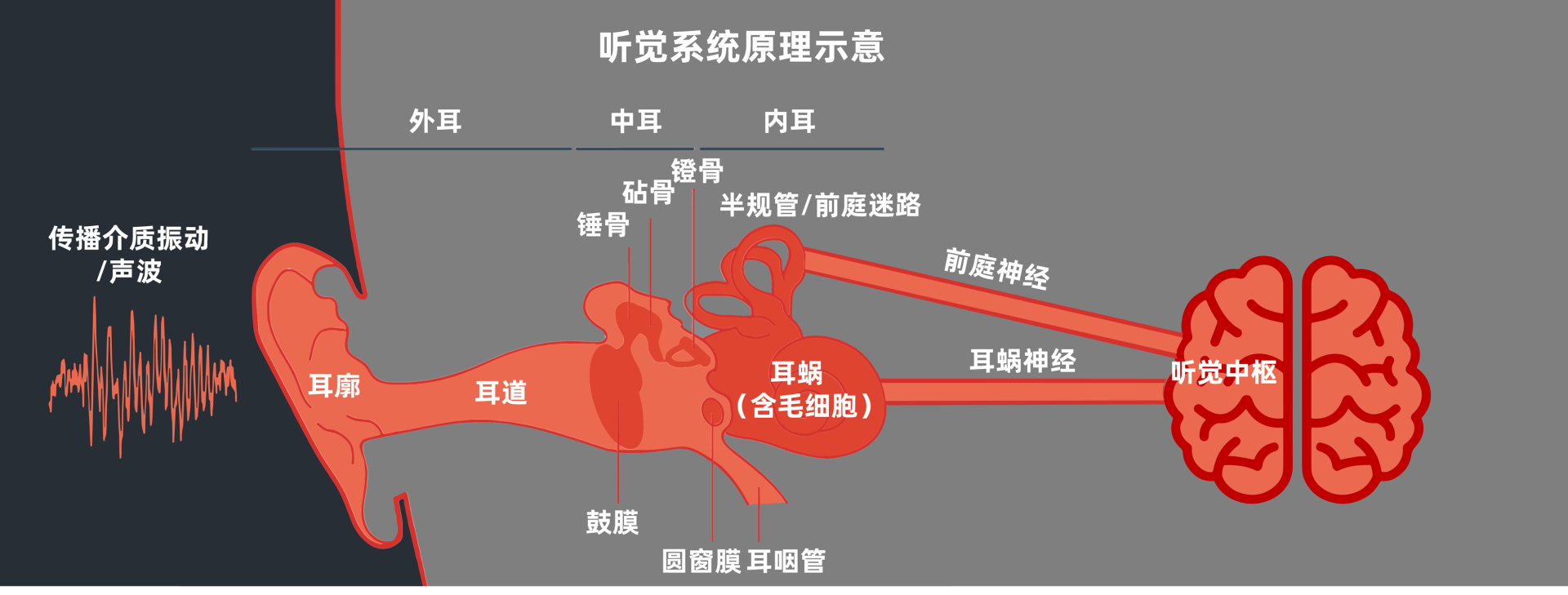
今天我们来谈谈声音设计背后的人因道理。人类大约11%的信息通过听觉系统获得。声音由声源的振动引发传播介质的振动,通过人耳传音系统到达内耳,经过听觉毛细胞把声波转换为生物电信号,再传到大脑的听觉中枢,然后我们才真正听到外界的各种声音。
声音的传播和光的传播不同。光在宇宙中传播不需要依赖介质,但声音必须依赖介质。比如在太空中没有空气(也就是没有声音传播的介质),两个宇航员如果不依赖特殊的通信设备,即便再近,扯着嗓子喊也听不到对方的声音。
我们对声音的频率很敏感,正常的年轻人能够在20赫兹~20千赫的频率范围内听到声音。我们对400~1000赫兹的声音频率最敏锐,因为这正是婴儿啼哭的频率范围。和视觉类似,我们的听觉在动物界也是普普通通。狗能听到40赫兹~50千赫,鲸鱼可以听到20赫兹~100千赫。
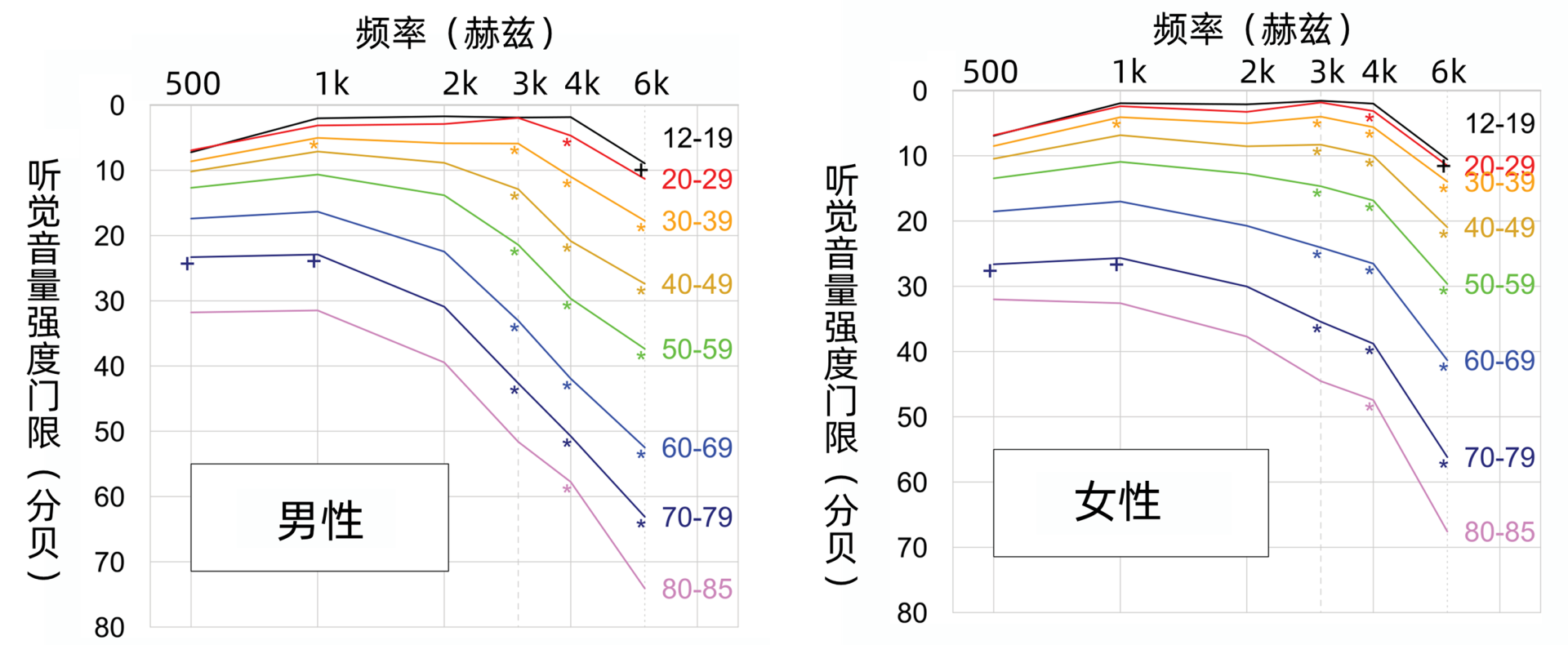
人类耳朵听觉范围的频率上限会随年龄的上升而下降,一旦超过45岁后就变得非常明显。也就是说年轻人可以听到的高频率声音,年龄较大的人不一定听得到(高于2千赫兹的高频音尤为明显)。所以年龄大的人会对鸟叫声等高频音不敏感。
有一种专门的产品叫蚊音器,把某种高频音调到一定分贝以下,这样只有年轻人才会听得到。下图就是不同年龄段的人在听不同频率的声音时,对应的音量阈值的变化。很明显频率越高,年龄大的人音量强度阈值越高,高于2k的声音尤为明显。
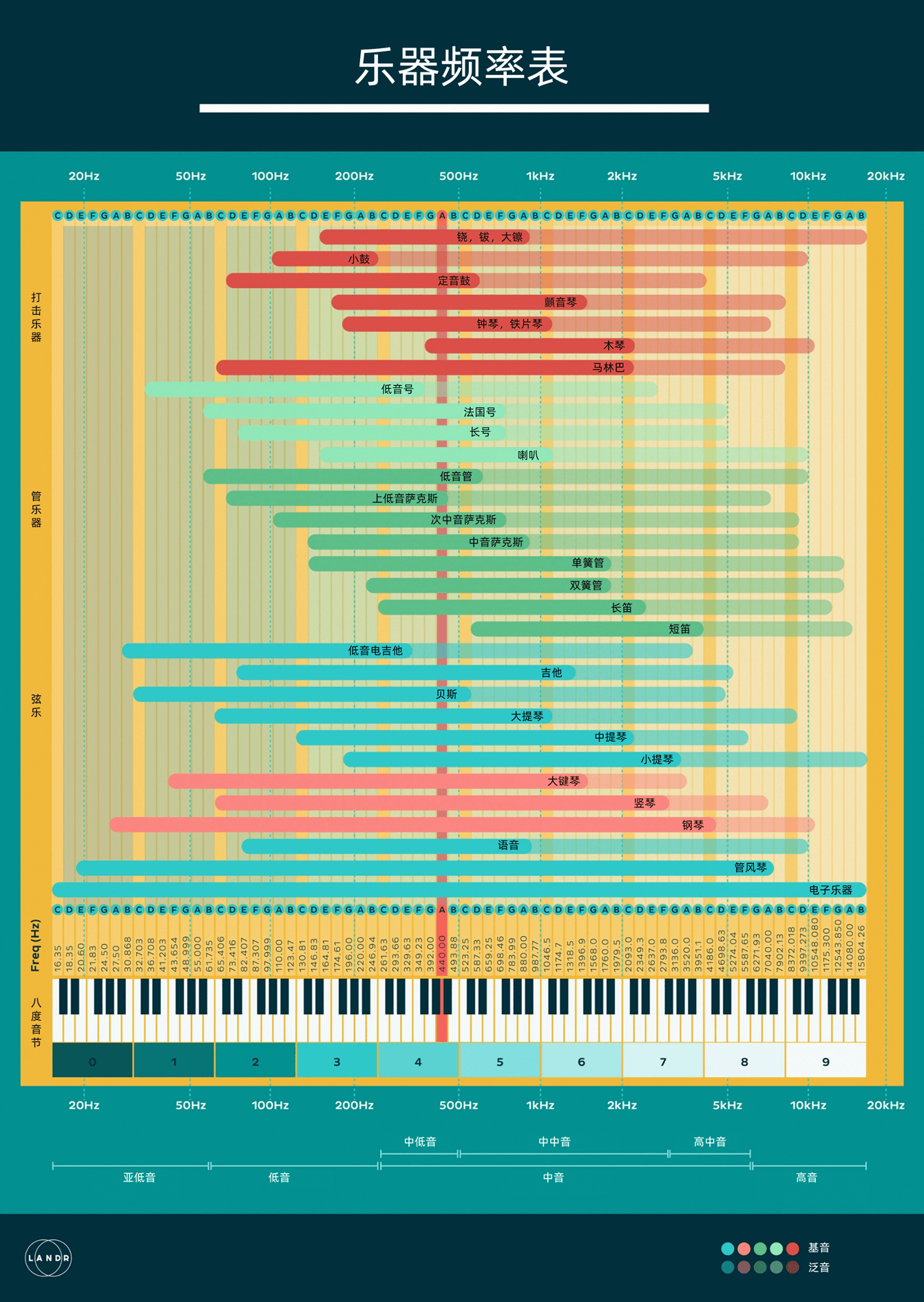
我以前在华为设计手机Jingle铃音时候尤其关注这个点。如果手机铃音要覆盖最大程度的用户,特别是如果你想让老人也能听得到的话,在选用音乐频率的时候,就要避免过度使用音域集中在高频段的乐器,比如木琴和笛子。
我需要尽量选择音域覆盖广泛的乐器,或者采取更安全一些手法直接选用中低音频段的乐器,通过提高音量来引起听者的注意。
下图就是乐器的频率表。每种色彩代表一种类型的乐器,深色是基音,浅色是对应的泛音。你可以重点看看基音的频率范围部分。
谈到音域的广覆盖,那就不得不提白噪声了。如果一段声音的响度在整个人的可听范围内均匀分布,这段声音就可以称为白噪声。如果把白噪声类比于视觉,那白噪声就会像下图里电视没信号的噪点一般。

大自然是最美妙的乐手。很多自然界的白噪声都能实现音域的广覆盖。比如雨声、海浪声、田野微风虫鸣。人工产品也存在白噪音,比如收音机FM广播在没信号时发出的沙沙声,或者夏日风扇的转动嗡嗡声。
因为稳定的白噪声能有效掩盖生活中那些尖锐、突然变化的声音(比如鼾声或者狗叫声),所以舒适自然的白噪声能使人快速入睡以及拥有更高质量的睡眠。特别是中低频段的白噪声,又称为“非常悦耳的噪声”,更加有助于让我们进入深度睡眠。下面我插入一段自然界海浪的白噪声,有兴趣你可以点击感受一下。
白噪声还有一个很管用的用途,那就是能让哭泣的婴儿快速安静下来。婴儿在子宫里听到的持续不断的呼呼声,是羊水、血液流动和心跳声混杂在一起的自然白噪音。在出生后,婴儿一旦听到类似的白噪声,会迅速找回在母亲子宫里面的那种安全感。我们家老大在刚出生的时候,一哭闹,我就会立即打开嗡嗡的吹风机,宝宝会瞬间停止哭泣。
你可以考虑在环境空间设计中,有针对性地使用白噪声。比如针对相对安静的空间(咖啡厅、高档西餐厅、奢侈品店、酒店大堂)播放白噪声的背景音,那就有助于营造舒适宁静的氛围。
考虑到白噪声的这种特点,如果你要设计一种起床闹铃的铃音,一定得避免用白噪声。如果你用潺潺流水、林中虫鸣或者小鸟的欢歌当闹铃的话,这种起床闹铃不仅叫不醒人,反而会让人更好地睡个回笼觉。
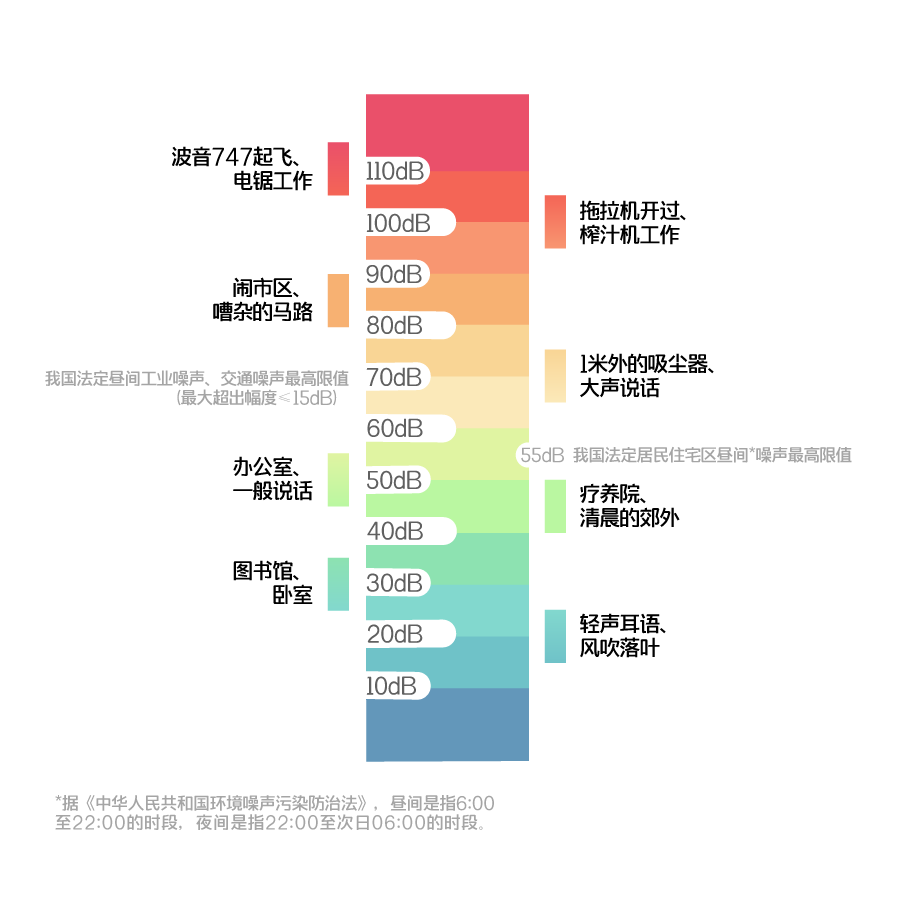
除了频率外,能够衡量声音的另一个维度就是强度。人能感觉到的声音强度范围在0~130分贝,超过130分贝人耳就会产生痛觉。
其实根本不需要达到这个强度。一般情况下60分贝以上就属于吵闹范围,声音到了70分贝我们就可以认为它开始干扰正常的谈话,使人感到心烦意乱而且开始损害听力神经。
人体所能承受的音量在80分贝以下。如果人长期在80分贝以上的环境中生活,就会出现头痛、记忆力减弱甚至失眠等症状。当人耳听到的音量达到100分贝时,时间较长的情况下会造成不可恢复性的听力损伤。长时间受120分贝以上音量的刺激,听觉细胞就会受到永久性的破坏,严重者还会造成听力丧失。
耳机最高音量不能超过120分贝。我们国家环境噪声污染防治法定义,55分贝是昼间住宅区噪音最高阈值,70分贝是昼间工业噪声最高阈值。
婴儿的哭泣声可以很轻松达到80分贝以上,所以大多数父母一听到婴儿哭泣就会心神不宁。
你知道交响乐团在音乐厅的演奏分贝是多少吗?最高可以达到110至120分贝。很多乐器不仅仅音量高,而且频率也高。不难想象,音乐家们在这种环境中长期的排练和演出,听力都会受到不同程度的损伤。
对再好的白噪声而言,如果把它的音量强度提升到高分贝,一样会让你心神不宁。所以当你在使用白噪声的时候,记得把白噪声的强度控制在30~40dB,这样才能真正起到安静舒适的效果。
我以前在华为人因团队设计手机铃音的时候,还考虑过手机声音强度和环境音之间的关系。
当在安静的环境音背景下,来电铃音音量可以渐响并自动适当调低手机最高音量,避免突然响起铃音让人吓一跳。因为人在安静环境下,对音量的敏感度提升。而在背景相对喧杂的情况下,手机要自动提高来电铃音音量并调起振动模式,让人能尽快感知到打来的电话。
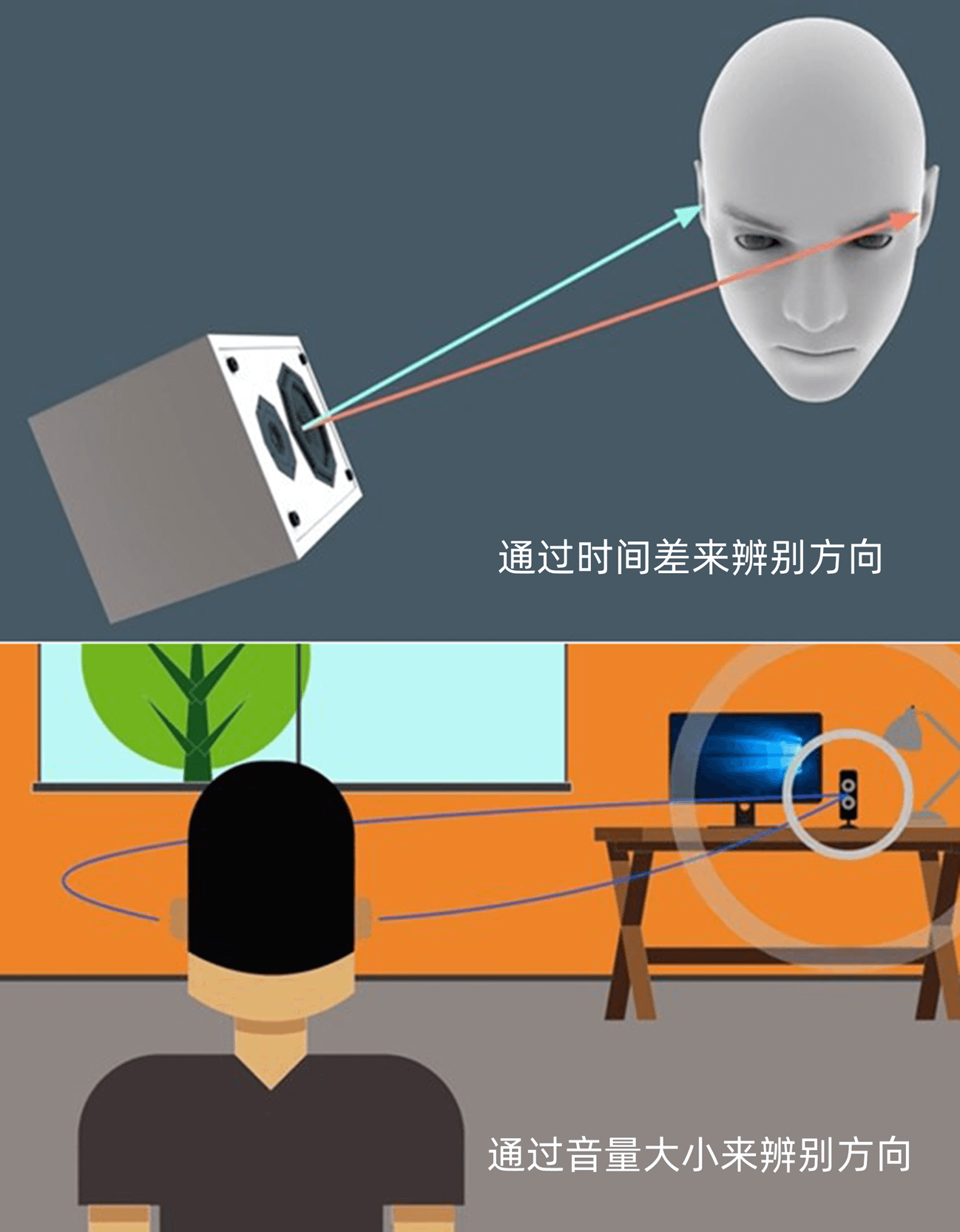
人的耳朵不仅仅可以听到声音,还可以辨别方向。这主要是因为我们的耳朵可以听出时间差和声级差。时间差是指声音抵达两只耳朵时间的前后差别,声级差则是两只耳朵听到声音强度的大小差别。
对于小于1500赫兹的声音,人一般通过时间差来感知方位。一旦声音频率超过1500赫兹(意味着声波波长小于人的头骨尺寸一半),左右耳就比较难辨别哪个是先到达的了。在这种情况下,我们大多依赖于声级差来辨别方位。也就是说当左右耳音量接近的时候,我们也感觉距离声源也在接近。
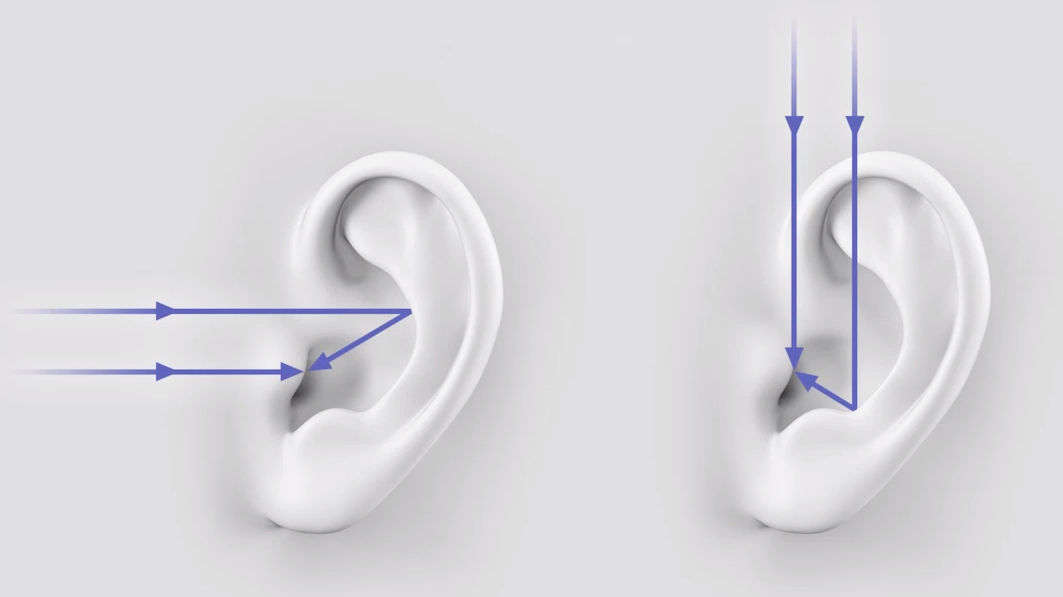
来自不同方向的声音会通过耳廓反射,或着通过绕过耳廓来进入耳道,从而让我们辨别出声音是来源于前后还是来源于上下。你可以参考一下下面这幅示意图,这就是我们通过耳廓进一步辨别声音的方位的大概原理。利用人体进一步感知声音的能力又被称为人体滤波效应。
在空间音响的环绕立体声设计上,四周的音响会给我们带来非常棒的沉浸式体验。但是对于头戴设备而言,营造环绕立体声就会成为非常大的挑战。
我们的耳机只有左右两个扬声器,如何实现环绕立体声的效果呢?那就要模拟左右耳间时间差、声级差和人体滤波效应,再通过耳机进行重放来实现3D环绕沉浸式效果。我下面给一段3D音的Demo,你可以戴上耳机感受一下。
好的耳机其实最好还要有跟踪头部运动的能力。当用户头部转动的时候,能够利用头戴耳机中的加速传感器或者陀螺仪,去重新计算双耳与模拟声源的相对位置变化,从而调整左右耳朵的声音。
比如当模拟的声音在距离人脸前面几十厘米的位置时,那么我们向左转头,右耳的音量就会大于左耳的音量,而且左耳的声音能比右耳的声音有一个时间差。
我对这种技术的未来看好。但是当前这种技术严重依赖于系统处理性能。这种双耳音频渲染是密集计算型的,不仅仅要实时跟踪头部运动角度和速度的数据,还要根据这些预测去迅速重新渲染音频流,让人几乎感觉不到这种处理的延迟才行。
如果是AR/VR虚拟图像,再考虑到声音与动态视频图像的渲染引擎配合,更是难上加难。所以我们在当前的技术局限上要做好用户体验,就要走一些取巧的方法。
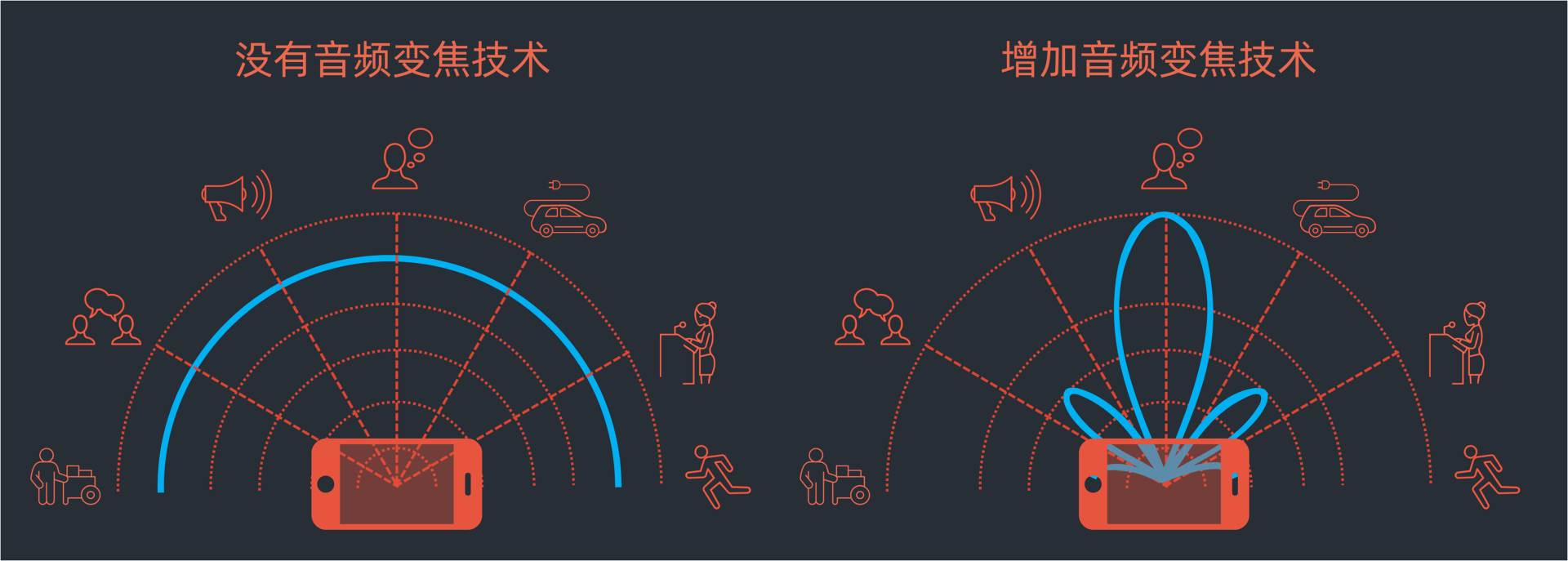
比如我们在很多华为手机里,就利用多枚立体收音麦克风和AI算法,实现了指向性麦克风收音。再配合上摄像头的焦距,当拉近远处的景物的时候,远处的声音也会逐渐被放大,同时还会消除掉不必要的噪音。把焦距拉远,随着画面景物越来越小,对应景物的声音也会随之变小。
通过以上的手法就实现了音频变焦。这种玩法就是在基于听觉的人因分析基础上,开发出的一种视觉和听觉的联觉体验。
在用户体验设计领域音效是非常重要的部分。自然的音效设计并不是说这个音效的声音是大自然的声音,我认为自然的音效要满足以下三点。
一个音效必须符合用户体验的目的,也就是说它必须有实用性。比如为什么iOS的键盘输入需要有打字音效?因为合理的打字音效会提升用户输入的效率。毕竟触摸屏没有机械键盘的触感反馈,而振动马达又无法精准代表每个字符是否输入成功。
符合预期还有一个重要的指标是最小的时延。你要遵守UI优先原则,任何界面的交互如果需要声音反馈,就要第一时间给出响应。声音和画面的不一致时间如果超出100ms,我们会很容易感觉到延迟。
考虑到很多场景的约束,我们还必须给所有的音效提供关闭的选项。因为很多人愿意选择长期的静音,以减少对外界和自己的打扰。

所有的音效的设计不能天马星空,必须与现实世界产生某种联系。
安全的音效设计是直接参照物理世界里类似对象操作的声音,但这样做可能会给人一种复古拟物化设计的印象。
你的音效设计也可以是一种能产生类似联想的抽象隐喻,但这种隐喻要避免让用户去过多思考或者产生困惑。拿刚才苹果Mac电脑删除文件的音效为例,如果音效改成一种“咻”的飞船快速飞过声音也可以理解,但如果改成清脆的铃音,你一定会觉得非常突兀。
自然界的声音还有一个特点,那就是“相似而不相同”。我记得MIUI 10有一个通知音水滴音效。尽管是水滴声,但是能通过大量的采样素材和动态算法的加持,使得通知音效的水滴声产生上万种变化,能避免用户很快听腻的情况发生。
一个好的过渡或微交互声音应该比它的相关动画长0.3秒。音效时长比动效长一点儿,这是在模拟声音机械波的泛音特性,余音绕梁不绝于耳。如果动效没了声音就戛然而止,那就和现实世界不匹配了。
音效设计不能被滥用。很多反馈也可以通过视觉反馈的方式来传达,声音传达只是可选项。
特别是有些听觉反馈可能会造成负面的效果。当负面反馈音效声音发出,会公开告诉周围的人,这个家伙做了一些蠢事。比如有一次我带着孩子去紫竹院公园散步,进园扫健康码后提示无效码,随后系统发出了刺耳的告警音效。本来是公园二维码失效,却搞得好像游客犯了错误。人们对负向的或者错误的反馈的心理预期更希望是无音效的,仅有视觉反馈即可。
好的设计是尽可能简约。对应到音效设计上也是一样,音效要简明扼要,不要有过度复杂的音调、音色和音频变化。
音效设计中另一个你需要思考的关键点就是留白。因为人的大脑是被动接收声音信号,过多杂乱无序的声音会打乱大脑的注意力,形成声音污染。
就和视觉一样,人在同一时间内只能接受有限的内容。声音的使用是一把双刃剑,在什么场景下发声是需要你特别去思考设计的。举个例子,对调整音量的按钮来说,就没有必要设计任何音效了。因为音量的增加减少,本身就是非常明显的声音反馈,何必再叠加额外的音效呢?
好了,讲到这里,我们重新认识听觉的内容也就基本结束了。今天我带你从人因学的维度来理解了一下声音设计。
我们人类可以感知到声音的频率、强度,方向感。20赫兹至20千赫是正常年轻人能够听到的频率,但我们能听到的频率上限会随年龄的上升而下降。考虑到手机铃音的人群覆盖,我们就要避免用音域集中在高频段乐器(比如木琴和笛子)的音乐,尽量选择音域覆盖广泛或者偏中低频的乐器演奏的音乐。
白噪声是频率覆盖很广的声音,会给人带来轻松的感觉,有助于睡眠。你要避免在起床闹钟中使用白噪音。人能感觉到的声音强度范围在0~130分贝。你的铃音设计最好要能智能调整音量,才会更符合人的预期。
人可以通过左右耳间时间差、声级差和人体滤波效应来感受声音的方向。头戴设备就是通过模拟这些效应来实现3D环绕立体声。我还带你了解了一下音频变焦,它是结合视觉和听觉的一种联觉设计体验。
我们还谈到了自然的音效设计。自然的音效设计包括:1. 一定是符合用户预期的声音反馈;2. 能与现实世界建立联系的隐喻;3. 音效需要简约、留白。希望你在设计中能够注意这些要点,更科学地去考虑声音进行设计。
如果你来设计一个产品中某个交互的音效,你会怎么设计?在生活里有没有什么让你很讨厌的音效设计?期待你的分享。
评论