你好,我是徐文浩,一个还在创业的工程师。目前专注于帮助新兴市场的电商进行数字化转型和数字化管理。
其实在两年前,我就在极客时间上做了第一门课程《深入浅出计算机组成原理》。写那个课程的时候,我是希望能够帮助更多的工程师弄清楚计算机的底层原理,让大家在自己的知识体系中“储蓄”起这些知识,从而能在漫长的程序员职业生涯里收获学习知识的“利息”。
不过,掌握计算机底层的原理,只是成为一个优秀的程序员、架构师的一个“预科班”。在实际的工作中,光有底层原理并不足以解决各类的程序开发、架构设计,乃至于技术创新的挑战。所以这一次,我又带来了一个新的课程,也就是《大数据经典论文解读》。我希望通过这个课程,能够帮助所有做后端开发、大数据,乃至底层分布式系统的同学们,进一步地成为一个杰出的工程师。
2021年,正好是我就读上海交通大学计算机系的20周年。在这20年里,我有几个技术水平快速成长的阶段。其中有一段,就是从2010到2015这5年间,搭建广告算法平台。而这一段时间的前后,也正是今天的“大数据系统”快速发展的5年。整个行业从仅有Hadoop这样的离线批处理的数据系统,到逐步出现了Storm这样的流式系统、Kafka这样的分布式消息队列,还有Spark这样可以快速进行多轮迭代的分布式计算系统。
那么在这个过程中,一方面我也在学习使用这些开源框架,来处理各种各样的大数据问题。另一方面,这些开源框架一开始也并不完善,往往有这样那样的不足,所以我也要去研究框架的源码和它的路线图,不断地去打patch和做优化。而有些时候,看代码并不是最快的学习方式,我往往要追根溯源,去看启发了这些开源框架的原始论文。
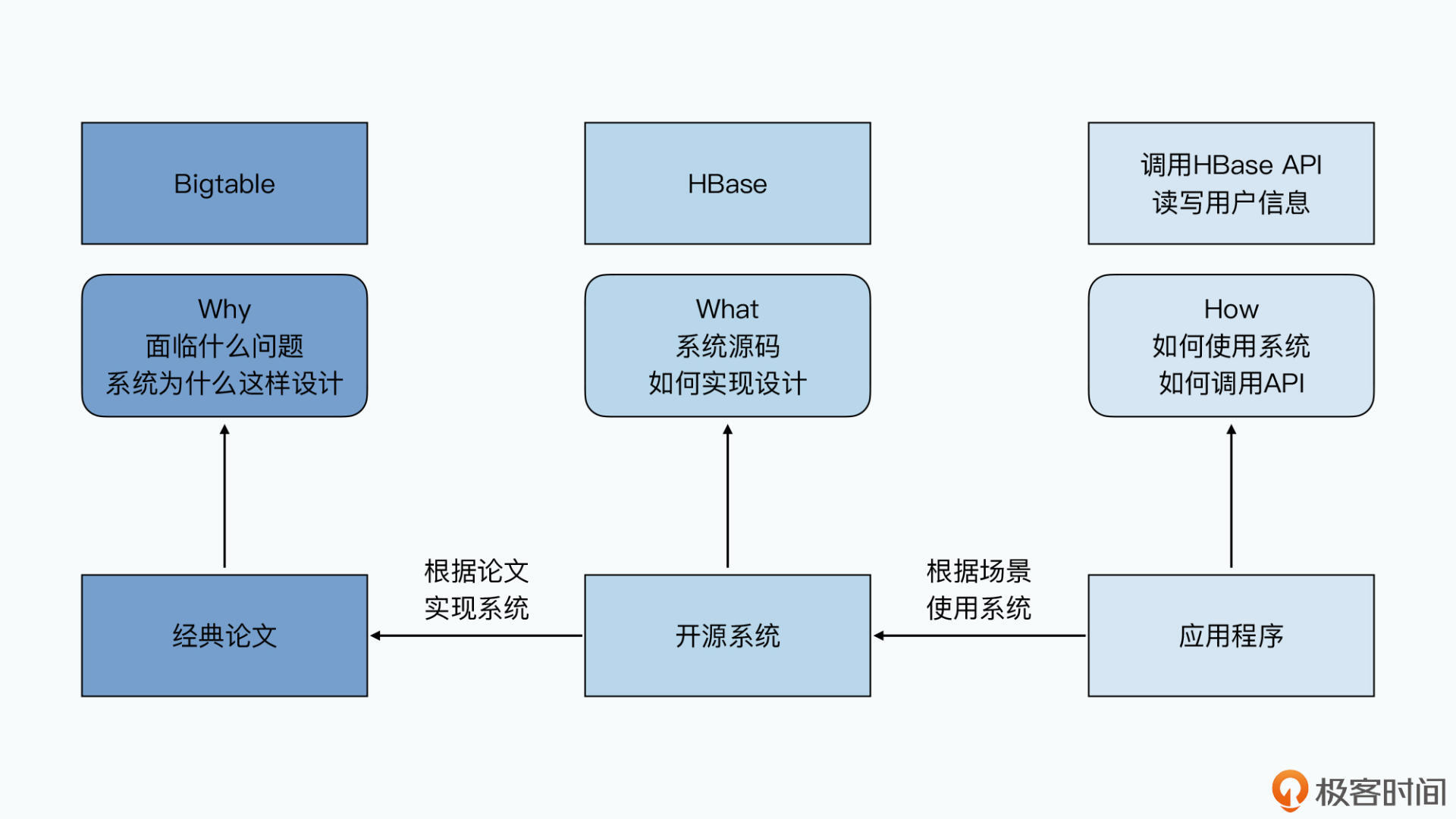
正是因为阅读了这些论文本身,给我自己打开了一扇新世界的窗。在研读这些论文的过程中,我了解到了各个大数据系统的来龙去脉,不仅知道了系统是怎么设计的,更搞清楚了系统为什么要这样设计。
在大数据的世界里,我们会使用某个开源框架,是了解到了How,毕竟谁学上两天都可以学会。而了解了开源框架的源码,是弄明白了What,让我们在遇到问题的时候,可以更高效地debug。那么,研读完它背后的论文,则是搞清楚了Why,这样,我们不仅可以参与到开源社区里,去帮助迭代改进这些框架,更可以在未来遇到新问题的时候,有更多的思路可以借鉴。
其实从我的角度来看,如果说搞清楚怎么用各类开源框架,是学会了武功中的基础“招式”。“招式”立刻就能用上,但是随着技术的发展,往往两三年就要更新迭代了。而看开源框架里的源码,是读到了对应武功“秘籍”。
掌握“秘籍”能让你对很多事情如何实现知根知底,但是随着技术范式的迁移,也会有兴衰起落。而阅读论文就是去理解武功对应的“心法”,可以让你不仅仅是只学会今时今日有用,而是能做到一辈子都受益。
那么在这门课程里,我为什么要选择大数据相关的论文呢?主要是有三个原因。
第一个原因,自然是我本身熟悉这个领域。在过去10年里,我仔细读过了这个领域大部分重要的论文,对基于这个领域的很多开源框架的源码,有不少也很熟悉,比如说HBase、Thrift、Kafka等等。也正是在研读这些论文的过程中,我对系统设计、计算机底层原理有了更深刻和清楚的认识,对于计算机科学第一次有了一种“融汇贯通”的感觉。
并且,我在研读这些论文的时候,也破除了很多“迷信”,不再会有“这个很难,我很难学会”的想法。通过研读这些论文,我发现看似复杂精巧的系统架构,都是通过利用坚实的基础知识去解决面临的具体问题。而当你能够梳理清楚问题的核心挑战,并且有着坚实的计算机底层原理知识,你也就有了自己去思考、创新并做出更好的系统的能力了。事实上,有不少我原来团队里的同事,已经在开发TVM编译器、向量数据库这些非常有技术挑战和技术含量的系统,从应用、改进走向了真正的创新。
第二个原因,是这个领域可以说是过去20年计算机工程界,发展最迅速、产生影响最大的一个领域。事实上,很多看起来和“大数据”没有什么关系的开源系统,也是从“大数据”这个领域培育出来的。
2003年Google发表GFS论文的时候,大部分人可能还懵懵懂懂。而到了今天,即使是一个和“大数据”看起来没有什么关联的Web开发工程师,他所写的应用也跑在Kubernetes这样的容器管理和调度系统上。而Kubernetes正是从Borg这样调度GFS、MapReduce和Bigtable的系统逐步发展而来的。
所以,通过学习大数据相关的论文,我们就会对计算机工程的各个领域都有更加深刻的认知,这不仅仅是对于“大数据工程师”这样的职位有用,对于做各类后端开发和系统开发的工程师来说,都会有很大的帮助。
第三个原因,是大数据在今天仍然在蓬勃发展。尽管互联网用户的数量增长已经逐步停滞,但是我们存储和处理的数据量的增长,却并没有慢下来。而正是因为大数据领域的发展,使得无论是存储数据,还是处理数据的成本都在不断降低。
原来我们只用存储文本和图片,我们现在会存储和处理大量的高清视频文件;原来我们只用存储用户的各种数据,现在我们还会存储海量的物联网设备的数据。可以说,大数据这个领域,无论是从市场需求还是技术进步,仍然还会快速发展很长一段时间。
所以,站在2021年的今天,我们去研读“大数据”的这些经典论文,仍然是一件投入产出比很高的事情。无论是从技术精进,还是寻找更好的职业发展机会的角度,这都是一个不会错的选择。
说了那么多学习大数据论文的好处,但是我们应该怎么学呢?有些同学恐怕会心里打鼓。对于不是做大数据底层系统开发的同学,自己找篇论文读一读呢,也好像囫囵吞枣,没有吃到滋味儿就忘了是怎么回事儿。
那在网上随便一搜呢,虽然也能找到不少论文被人翻译成了中文,但是往往也只告诉你“是什么”,却没有办法让你理解“为什么”。这些翻译或者文章,常常给出的是“Bigtable系统是一个稀疏的、分布式的排序好的Map”,却让你没有办法理解为什么Bigtable是这样设计的。
而根据我的经验,之所以会出现这些问题,主要是有三个难点。
第一是缺少脉络。从GFS的论文发表起,到今天已经18年了,大数据这个领域在工程上也已经逐步完善了。今天Google用的也不是原始的GFS了,你关心或者使用的,可能也是Spanner这样极其先进的数据库系统。而如果你不是研究分布式数据库的博士生,一头扎进Spanner的论文,可能就完全看不懂。
罗马不是一天建成的,学习和研究的过程也要注意“勿在浮沙筑高台”。Spanner这样的数据库是从Bigtable、Megastore、Dremel这样的系统一步步发展过来的。因此,对于不是专门研究数据库的你来说,直接去读Spanner的论文,自然是阻碍重重,因为你缺少整个分布式数据库发展的脉络。
第二是缺少场景。如今整个行业的分工已经非常细化了,即使你正在使用某一个大数据系统,你也不会太了解它在你公司里面的全貌。也许你每天都在用HBase这个Bigtable的开源版本,同时也在使用一个MySQL集群。对于作为这些“大数据”系统的用户的你来看,似乎用起来没有什么本质差别,就是调用一个接口或者写两句SQL的问题。
但实际上,你所使用的HBase和MySQL集群背后,可能是一个巨大的基础设施团队或者DevOps团队。他们每天所做的优化和自动化动作在工作量上的差异,才是Bigtable的设计想要解决的主要问题。那么,如果你不理解论文里需要解决的问题背后,其面临的真实场景是什么,那你自然很难感同身受,也无法理解论文里设计的精妙之处。
第三是缺少联系。作为发表的论文,一般来说都很精炼,也就是10来页。所以论文里对于大部分问题的解释都很简短,而且也不会给你展示什么代码。
我们还是拿Bigtable举例子,论文里只会告诉你它的底层存储是SSTable。而你既不知道SSTable到底是什么、数据是怎么存储的,也不懂为什么Bigtable用上了它,就可以解决性能问题了。论文里并没有深入为你剖析某一个问题联系到的底层技术原理,所以你很容易会有一种“不明觉厉”的感觉。刚读完的时候,你觉得“这个设计真厉害”,可是让你和其他人解释,最后却会变成“其实我也不太明白”。
所以,考虑到这些问题,对于这个课程,我就给自己定了一个交付目标:这个课程不是为了给你翻译、讲解一下论文,而是要帮助你梳理整个大数据系统的发展脉络,还有在整个领域的系统不断往前迭代的过程中,所遇到的具体场景下的问题,以及深入解读其中重要的设计决策背后,能够联系到的计算机底层原理。
通过这些内容知识的讲解,你就能够把论文和论文之间联系起来,把论文和具体技术场景联系起来,把论文和计算机原理的底层知识点联系起来。更进一步,你会真正理解Why,而不是只知道What。
那么对于这个课程,我是怎么设计的呢?
在整个专栏的结构上,我会为你梳理各篇论文发表前后的关系和脉络,帮助你理解这些论文是怎么在一个个的迭代过程中,不断构建出更加优秀的系统的。所以,根据大数据论文的发表时间顺序,以及各篇论文的前后依赖关系,我把课程划分成了以下5个模块。
我们这一代的工程师,生活在一个最好的时代,有机会参与开源社区,更有机会开始进行底层系统级别的创新。特别是过去几年,越来越多的中国工程师参与、发起了各种各样的大数据开源项目,而这些机会在20年前其实是非常罕见的。
20年前,中国的工程师大部分都只有做应用开发的机会,甚至很多优秀科班出身的同学,也只能考个CCIE、MCSE这样的认证,做一些系统运维、技术支持的工作。
“三十八年过去,弹指一挥间。可上九天揽月,可下五洋捉鳖,谈笑凯歌还。世上无难事,只要肯登攀。”坚持学完一门课程并不容易,写完并写好一门课更难,希望你能和我一起,坚持走完这个旅程。在我看来,研读论文,进行工程上的创新和突破,是每一个优秀工程师的成年礼。
我希望这门课,不只是让你学习到了一些大数据的知识,更能够让你从系统架构、计算机底层原理层面,获得深入而长久的成长,能够帮助你走上通过研读论文,学习、成长乃至创新和突破的道路。
最后,我也希望你来讲一讲,你的大数据相关的体验。对你来说,大数据系统到底是什么呢?你有没有读过一些相关的论文呢?在之前的工作中,你用过哪些大数据系统?欢迎写在留言区,我们一起交流。
好了,接下来就让我们一起努力,开启学习之旅吧。
评论