你好,我是徐文浩。
在正式开始解读一篇篇论文之前,我想先让你来回答一个问题,那就是“大数据”技术到底是什么呢?处理100GB数据算是大数据技术吗?如果不算的话,那么处理1TB数据算是大数据吗?
“大数据”这个名字流行起来到现在,差不多已经有十年时间了。在这十年里,不同的人都按照自己的需要给大数据编出了自己的解释。有些解释很具体,来自于一线写Java代码的工程师,说用Hadoop处理数据就是大数据;有些解释很高大上,来自于市场上靠发明大词儿为生的演说家,说我们能采集和处理全量的数据就是大数据,如果只能采集到部分数据,或者处理的时候要对数据进行采样,那就不是大数据。
其实,要想学好大数据,我们需要先正本清源,弄清楚大数据在技术上到底涵盖了些什么。所以今天这节课,我就从大数据技术的核心理念和历史脉络这两个角度,来带你理解下什么是大数据技术。
通过理解这两点,你就会对大数据技术有一个全面的认识。而这个认识,一方面呢,能让你始终围绕着大数据技术的核心理念,去做好技术开发工作,不至于跑偏;而另一方面呢,它能帮你在学习后面每一个知识点的时候,都能和其他部分建立联系,帮你加深对大数据技术的理解。
好了,那么下面,我们就先来一起看看,大数据的核心理念是什么。
首先,让我们来看看Wikipedia里是怎么定义它的。“大数据”是指传统数据处理应用软件时,不足以处理的大的或者复杂的数据集的术语。换句话说,就是技术上的老办法行不通了,必须使用新办法才能处理的数据就叫大数据。不过,这个定义似乎也是一个很模糊的描述性的定义,并没有告诉我们到底哪些技术算是“大数据”技术的范畴。
那么,在我看来,其实“大数据”技术的核心理念是非常清晰的,基本上可以被三个核心技术理念概括。
第一个,是能够伸缩到一千台服务器以上的分布式数据处理集群的技术。
在“大数据”这个理念出现之前,传统的并行数据库技术就已经在尝试处理海量的数据了。比如成立于1979年的Teradata公司,就是专门做数据仓库的。从公司名字上,你也能看出来那个时候他们就想要处理TB级别的数据。但是,这些并行数据库的单个集群往往也就是几十个服务器。
而在2003年Google发表了GFS的论文之后,我们才第一次看到了单个集群里就可以有上千个节点。集群规模有了数量级上的变化,也就把数据处理能力拉上了一个新的台阶。因为集群可以伸缩到上千,乃至上万个节点,让我们今天可以处理PB级别的数据,所以微信、Facebook这样十亿级别日活的应用,也能不慌不忙地处理好每天的数据。
当然,这个数量级上的变化,也给我们带来了大量新的技术挑战。而解决了这些挑战的种种技术方案,就是我们的“大数据”技术。
第二个,是这个上千个节点的集群,是采用廉价的PC架构搭建起来的。
事实上,今天跑在数据中心里的各个大数据集群,用的硬件设备和我拿来写这节课的笔记本电脑本质上是一样的。可能数据中心里的CPU强一点、内存大一点、硬盘多一些,但是我完全可以用几台家里的电脑组一个一样的集群出来。
在“大数据”技术里,不需要使用“神威·太湖之光”这样的超算,也不用IBM的大型机或者Sun公司的SPARC这样的小型机,同样也不需要EMC的专用存储设备。“大数据”技术在硬件层面,是完全架设在开放的PC架构下的,这就让任何一个新创的公司,都能够很容易地搭建起自己的集群。
而且,由于不需要购买昂贵的专属硬件或者存储设备,所以大数据技术很容易地在大大小小的公司之间散播开来,任何一个有兴趣的程序员都可以用自己的PC开发、测试贡献代码,使得整个技术的生态异常繁荣。
最后一个,则是“把数据中心当作是一台计算机”(Datacenter as a Computer)。
要知道,“大数据”技术的目标,是希望对于开发者来说,TA意识不到自己面对的是一个一千台服务器的集群,而是一台虚拟的“计算机”。使用了部署好的大数据的各种框架之后,开发者能够像面对单台计算机编程一样去写自己的代码,而不需要操心系统的可用性、数据的一致性之类的问题。
所有的“大数据”框架,都希望就算没有“大数据”底层技术知识的工程师,也能很容易地处理海量数据。
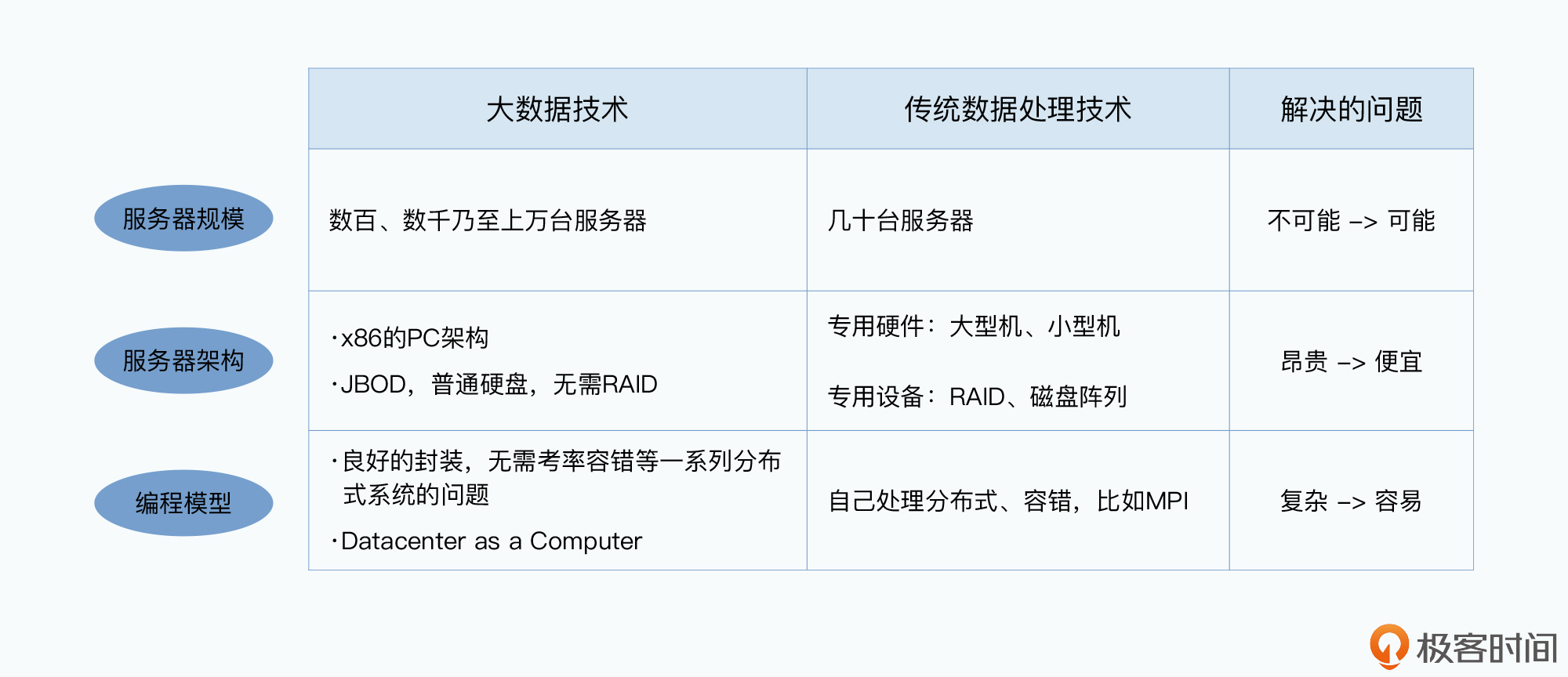
大型集群让处理海量数据变得“可能”;基于开放的PC架构,让处理海量数据变得“便宜”;而优秀的封装和抽象,则是让处理海量数据变得“容易”。这也是现在谁都能用上大数据技术的基础。可以说,这三个核心技术理念,真正引爆了整个“大数据”技术,让整个技术生态异常繁荣。
看到这里,你可能要问了,这三个核心技术理念是从哪里来的呢?这些理念当然不是“机械降神”,凭空出现的。
事实上,可以说整个“大数据”领域的蓬勃发展,都来自于Google这家公司遇到的真实需求。我们今天看到的“大数据”技术,十有八九,都来自于Google公开发表的论文,然后再演变成一个个开源系统,让整个行业受益。可以说,Google是“大数据”领域的普罗米修斯。
而在这个过程中,整个技术的发展也并不是一个直线上升的状态:
所以可以说,大数据技术的发展是一个非常典型的技术工程的发展过程,跟随这个脉络,我们可以看到工程师们对于技术的探索、选择过程,以及最终历史告诉我们什么是正确的选择。
那么接下来,我们就一起来看看整个“大数据技术”的历史脉络,一起来看看这一篇篇论文、一个个开源系统都是为什么会出现。
我认为,Google能成为散播大数据火种的人,是有着历史的必然性的。
作为一个搜索引擎,Google在数据层面,面临着比任何一个互联网公司都更大的挑战。无论是Amazon这样的电商公司,还是Yahoo这样的门户网站,都只需要存储自己网站相关的数据。而Google,则是需要抓取所有网站的网页数据并存下来。
而且光存下来还不够,早在1999年,两个创始人就发表了PageRank的论文,也就是说,Google不只是简单地根据网页里面的关键字来排序搜索结果,而是要通过网页之间的反向链接关系,进行很多轮的迭代计算,才能最终确认排序。而不断增长的搜索请求量,让Google还需要有响应迅速的在线服务。
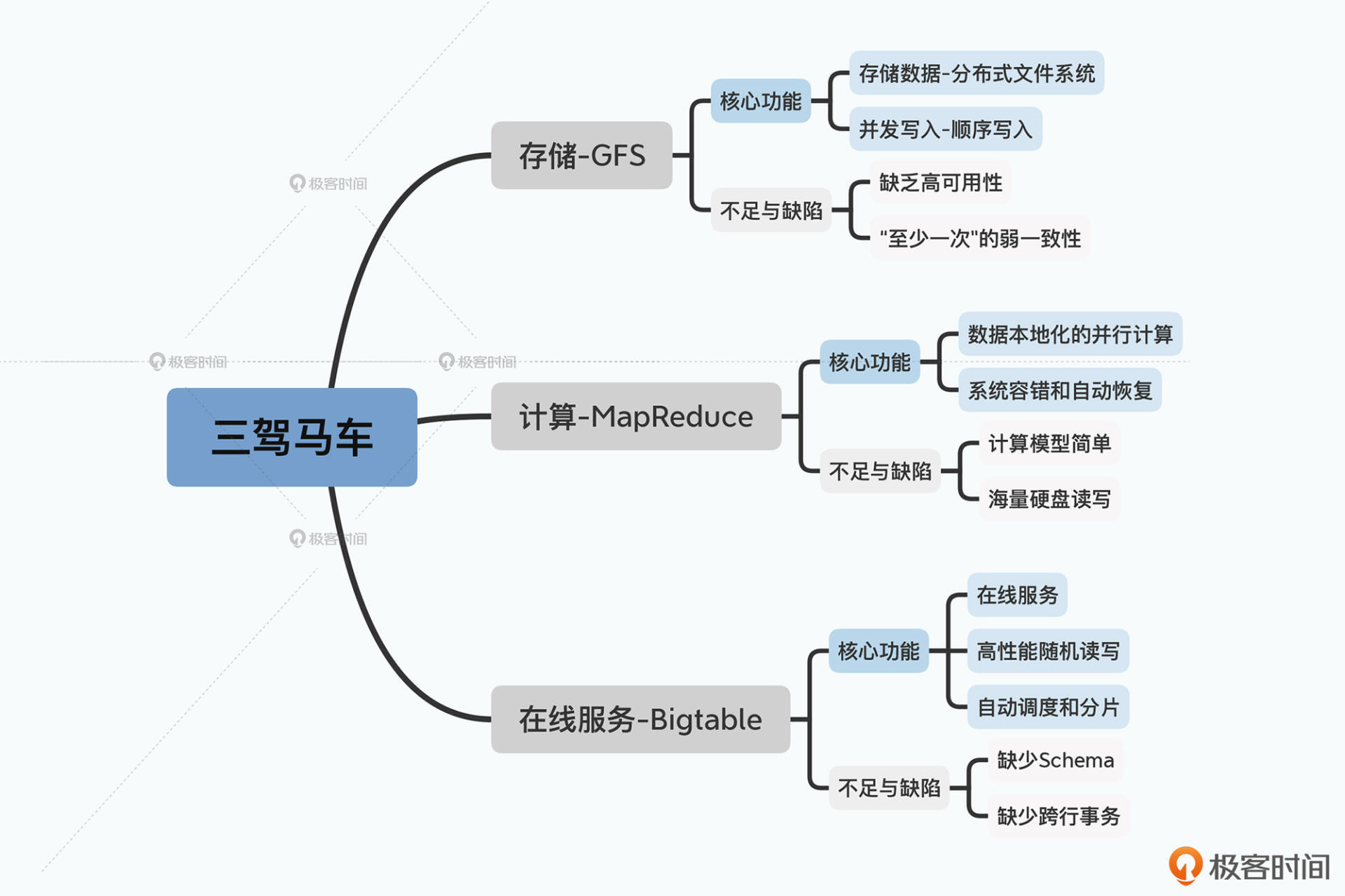
由此一来,面对存储、计算和在线服务这三个需求,Google就在2003、2004以及2006年,分别抛出了三篇重磅论文。也就是我们常说的“大数据”的三驾马车:GFS、MapReduce和Bigtable。
GFS的论文发表于2003年,它主要是解决了数据的存储问题。作为一个上千节点的分布式文件系统,Google可以把所有需要的数据都能很容易地存储下来。
然后,光存下来还不够,我们还要基于这些数据进行各种计算。这个时候,就轮到2004年发表的MapReduce出场了。通过借鉴Lisp,Google利用简单的Map和Reduce两个函数,对于海量数据计算做了一次抽象,这就让“处理”数据的人,不再需要深入掌握分布式系统的开发了。而且他们推出的PageRank算法,也可以通过多轮的MapReduce的迭代来实现。
这样,无论是GFS存储数据,还是MapReduce处理数据,系统的吞吐量都没有问题了,因为所有的数据都是顺序读写。但是这两个,其实都没有办法解决好数据的高性能随机读写问题。
因此,面对这个问题,2006年发表的Bigtable就站上了历史舞台了。它是直接使用GFS作为底层存储,来做好集群的分片调度,以及利用MemTable+SSTable的底层存储格式,来解决大集群、机械硬盘下的高性能的随机读写问题。
下图就展示了Google的三驾马车针对这三类问题的技术优缺点,你可以参考下。
到这里,GFS、MapReduce和Bigtable这三驾马车的论文,就完成了“存储”“计算”“实时服务”这三个核心架构的设计。不过你还要知道,这三篇论文其实还依赖了两个基础设施。
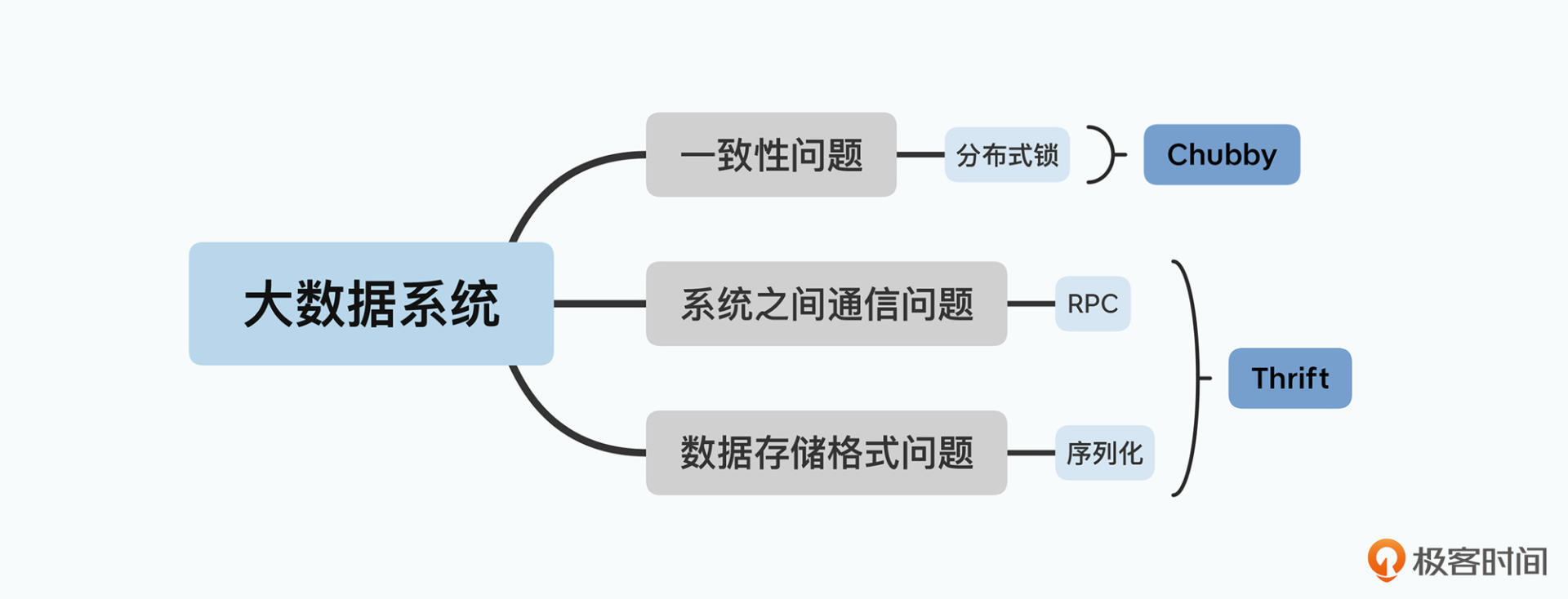
第一个是为了保障数据一致性的分布式锁。对于这个问题,Google在发表Bigtable的同一年,就发表了实现了Paxos算法的Chubby锁服务的论文(我会在基础知识篇“分布式锁Chubby”这一讲中为你详细解读这篇论文)。
第二个是数据怎么序列化以及分布式系统之间怎么通信。Google在前面的论文里都没有提到这一点,所以在基础知识篇的“通过Thrift序列化:我们要预知未来才能向后兼容吗?”我们会一起来看看Facebook在2007年发表的Thrift的相关论文。
小知识:实际上,Bigtable的开源实现HBase,就用了Thrift作为和外部多语言进行通信的协议。Twitter也开源了elephant-bird,使得Hadoop上的MapReduce可以方便地使用Thrift来进行数据的序列化。
可以说,GFS、MapReduce和Bigtable这三驾马车是为整个业界带来了火种,但是整个大数据领域的进化才刚刚开始。事实上,不管是GFS也好,MapReduce也好,还是Bigtable也好,在那个时候,它们都还是很糙的系统设计。
这里,我们先来看下MapReduce,作为一个“计算”引擎,它开始朝着以下方式进化。
补充:作为存储的GFS,Google并没有公开后续的Colossus系统的论文,而且GFS要优化的一致性问题,其实在从BigTable到Spanner的进化过程中,就已经被彻底讲清楚了,所以在课程里我们就先按下不表了。
首先是编程模型。MapReduce的编程模型还是需要工程师去写程序的,所以它进化的方向就是通过一门DSL,进一步降低写MapReduce的门槛。
虽然Google发表了Sawzall,Yahoo实现了Pig,但是在这个领域的第一阶段最终胜出的,是Facebook在2009年发表的Hive。Hive通过一门基本上和SQL差不多的HQL,大大降低了数据处理的门槛,从而成为了大数据数据仓库的事实标准。
其次是执行引擎。Hive虽然披上了一个SQL的皮,但是它的底层仍然是一个个MapReduce的任务,所以延时很高,没法当成一个交互式系统来给数据分析师使用。于是Google又在2010年,发表了Dremel这个交互式查询引擎的论文,采用数据列存储+并行数据库的方式。这样一来,Dremel不仅有了一个SQL的皮,还进一步把MapReduce这个执行引擎给替换掉了。
最后是多轮迭代问题。在MapReduce这个模型里,一个MapReduce就要读写一次硬盘,而且Map和Reduce之间的数据通信,也是先要落到硬盘上的。这样,无论是复杂一点的Hive SQL,还是需要进行上百轮迭代的机器学习算法,都会浪费非常多的硬盘读写。
于是和Dremel论文发表的同一年,来自Berkeley的博士生马泰·扎哈里亚(Matei Zaharia),就发表了Spark的论文,通过把数据放在内存而不是硬盘里,大大提升了分布式数据计算性能。
所以到这里,你可以看到,围绕MapReduce,整个技术圈都在不断优化和迭代计算性能,Hive、Dremel和Spark分别从“更容易写程序”“查询响应更快”“更快的单轮和多轮迭代”的角度,完成了对MapReduce的彻底进化。
好了,花开两朵,各表一枝。看完了MapReduce这头,我们再来看看Bigtable那一头。
作为一个“在线服务”的数据库,Bigtable的进化是这样的:

我在这里放了一张图,你可以看到在大数据领域里,MapReduce和Bigtable是怎么通过前面说的节点一步步进化下去的。实际上,如果说MapReduce对应的迭代进行,是在不断优化OLAP类型的数据处理性能,那么Bigtable对应的进化,则是在保障伸缩性的前提下,获得了更多的关系型数据库的能力。
这样,从MapReduce到Dremel,我们查询数据的响应时间就大大缩短了。但是计算的数据仍然是固定的、预先确定的数据,这样系统往往有着大到数小时、小到几分钟的数据延时。
所以,为了解决好这个问题,流式数据处理就走上了舞台。
首先是Yahoo在2010年发表了S4的论文,并在2011年开源了S4。而几乎是在同一时间,Twitter工程师南森·马茨(Nathan Marz)以一己之力开源了Storm,并且在很长一段时间成为了工业界的事实标准。和GFS一样,Storm还支持“至少一次”(At-Least-Once)的数据处理。另外,基于Storm和MapReduce,南森更是提出了Lambda架构,它可以称之为是第一个“流批协同”的大数据处理架构。
接着在2011年,Kafka的论文也发表了。最早的Kafka其实只是一个“消息队列”,看起来它更像是Scribe这样进行数据传输组件的替代品。但是由于Kafka里发送的消息可以做到“正好一次”(Exactly-Once),所以大家就动起了在上面直接解决Storm解决不好的消息重复问题的念头。于是,Kafka逐步进化出了Kafka Streams这样的实时数据处理方案。而后在2014年,Kafka的作者Jay Krepson提出了Kappa架构,这个可以被称之为第一代“流批一体”的大数据处理架构。
看到这里,你会发现大数据的流式处理似乎没有Google什么事儿。的确,在流式数据处理领域,Google发表的FlumeJava和MillWheel的论文,并没有像前面的三驾马车或者Spanner的影响力那么大。
但是在2015年,Google发表的Dataflow的模型,可以说是对于流式数据处理模型做出了最好的总结和抽象。一直到现在,Dataflow就成为了真正的“流批一体”的大数据处理架构。而后来开源的Flink和Apache Beam,则是完全按照Dataflow的模型实现的了。
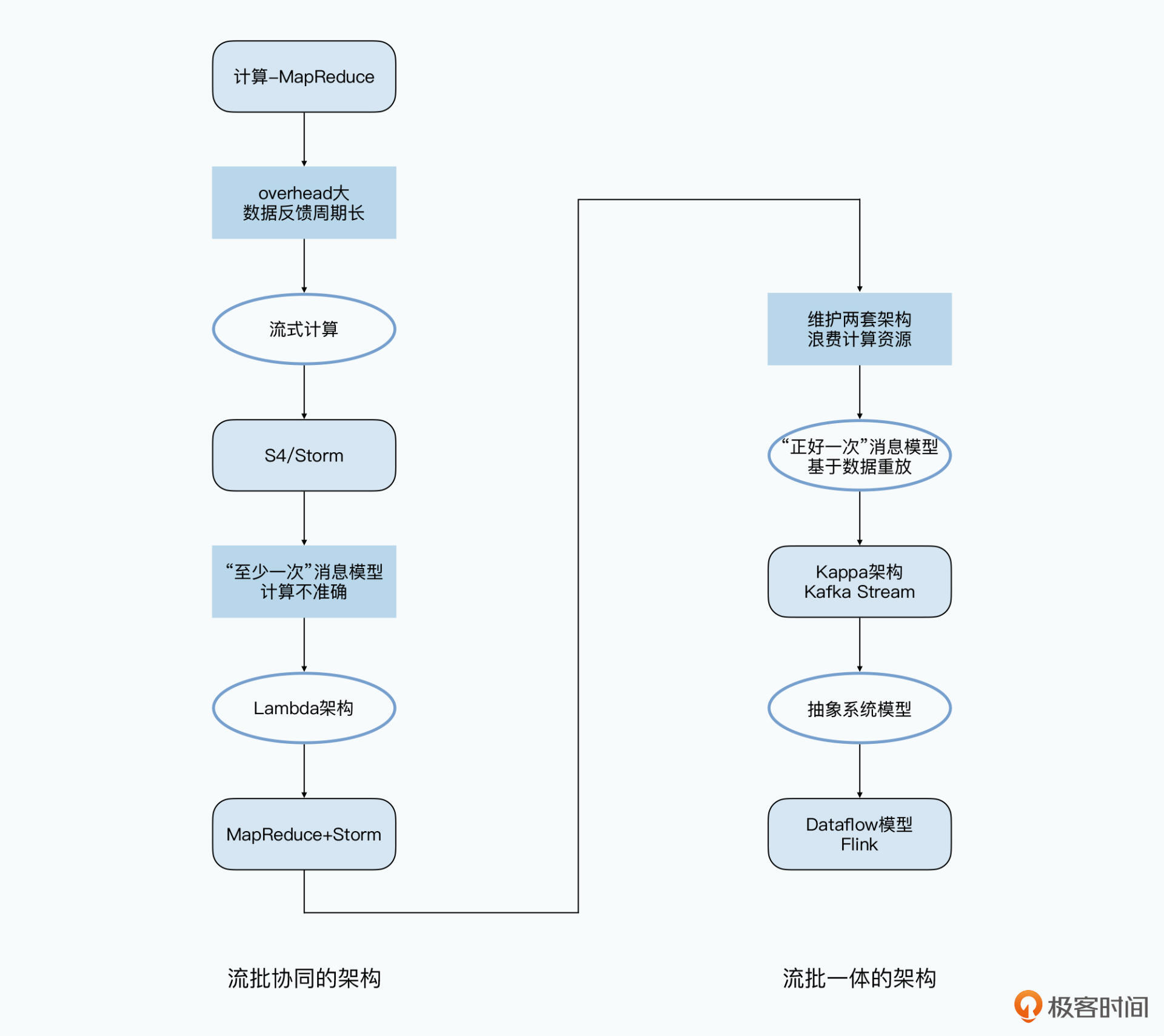
这里,我把这些论文的前后之间的脉络联系专门做了一张图,放在了下面。当你对某一篇论文感到困惑的时候,就可以去翻看它前后对应的论文,找到对应问题的来龙去脉。

到了现在,随着“大数据领域”本身的高速发展,数据中心里面的服务器越来越多,我们对于数据一致性的要求也越来越高。
那么,为了解决一致性问题,我们就有了基于Paxos协议的分布式锁。但是Paxos协议的性能很差,于是有了进一步的Multi-Paxos协议。
而接下来的问题就是,Paxos协议并不容易理解,于是就有了Raft这个更容易理解的算法的出现。Kubernetes依赖的etcd就是用Raft协议实现的,我们在后面的资源调度篇里,会一起来看一下Raft协议到底是怎么实现的,以及现代分布式系统依赖的基础设施是什么样子的。
然后,也正是因为数据中心里面的服务器越来越多,我们会发现原有的系统部署方式越来越浪费。
原先我们一般是一个计算集群独占一系列服务器,而往往很多时候,我们的服务器资源都是闲置的。这在服务器数量很少的时候确实不太要紧,但是,当我们有数百乃至数千台服务器的时候,浪费的硬件和电力成本就成为不能承受之重了。
于是,尽可能用满硬件资源成为了刚需。由此一来,我们对于整个分布式系统的视角,也从虚拟机转向了容器,这也是Kubernetes这个系统的由来。在后面的资源调度篇中,我们就会一起来深入看看,Kubernetes这个更加抽象、全面的资源管理和调度系统。
最后,我把在这个课程中会解读到的论文清单列在了下面,供你作为一个索引。
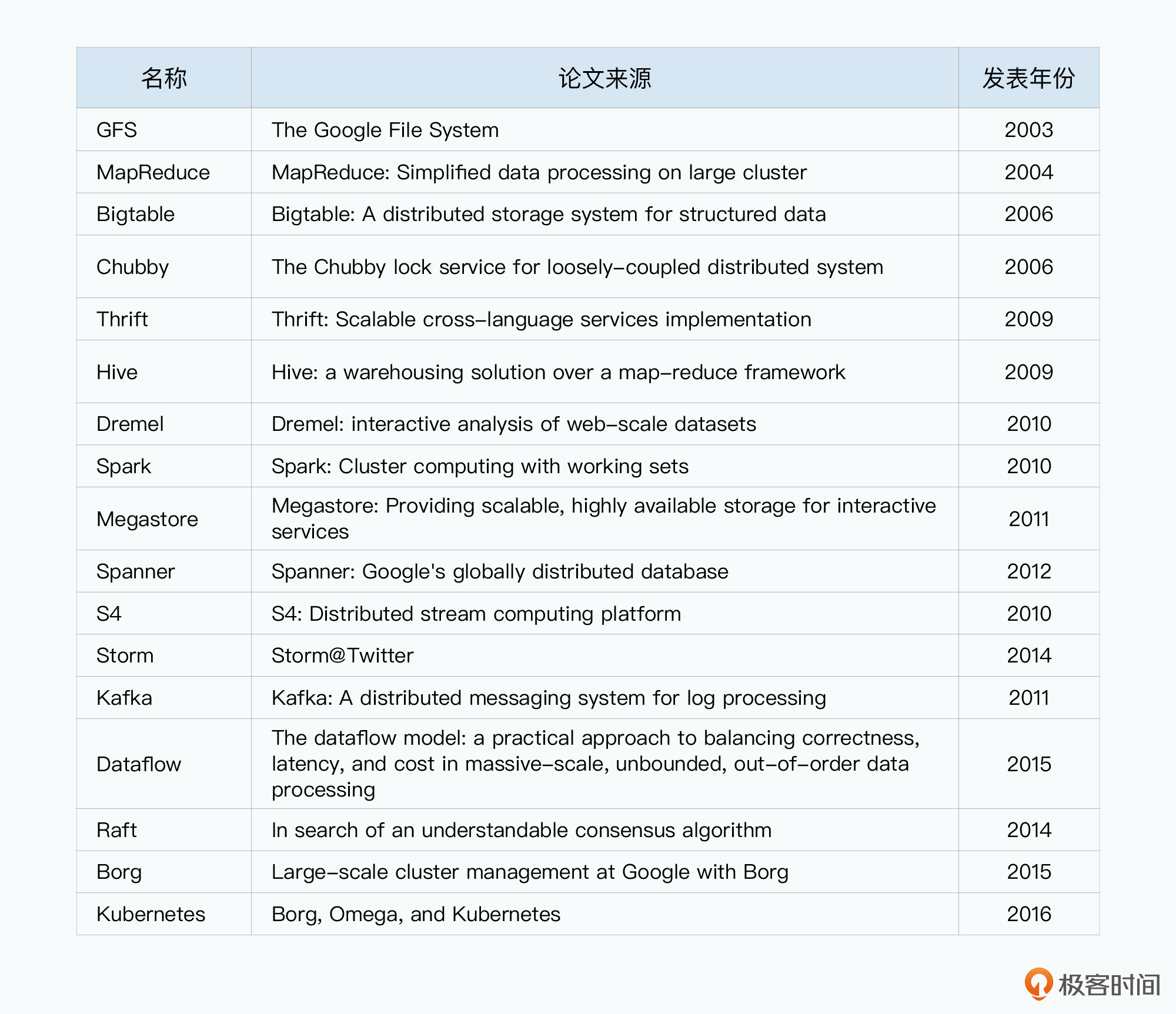
我在这节课里提到的这十几篇论文,其实只是2003到2015年这12年的大数据发展的冰山一角。
还有许许多多值得一读的论文,比如针对Bigtable,你就可以还去读一下Cassandra和Dynamo,这样思路略有不同的分布式数据的论文;针对Borg和Kubernetes,你可以去看看Mesos这个调度系统的论文又是什么样的。网上更有“开源大数据架构的100篇论文”这样的文章,如果你想深耕大数据领域,也可以有选择地多读一些其中的论文。
如果你觉得今天的这一讲学完后还不够过瘾,我推荐你可以读一下“Big Data: A Survey”这篇综述文章,可以让你更加深入“大数据”技术的全貌。另外,学完了这门课程之后,如果你还想更加深入地了解更多的大数据技术,你可以对着“Big Data: A Survey”这篇论文按图索骥,研读更多里面引用到的论文。
除了这些论文之外,你觉得还有哪些论文和开源框架,对于大数据领域的发展是有重要贡献的呢?你觉得它们主要是解决了什么样的重要问题?
欢迎留言和我分享你的思考和疑惑,你也可以把今天的内容分享给你的朋友,和他一起学习进步。
评论