
你好,我是徐文浩。
通过上节课的学习,现在你已经知道MapReduce的编程模型是怎么回事儿了。对于开发者来说,你只需要写一个Map函数和一个Reduce函数,就能完成数据处理过程。具体这些任务用了多少服务器,遇到了失败是怎么解决的,你并不需要关心。
不过,要想学习如何搭建和改进分布式系统,了解MapReduce的底层原理必不可少。今天,我们就一起来看看MapReduce的框架干了什么。MapReduce这个“保姆”,为什么可以让你不需要处理复杂的分布式架构的问题。
要想让写Map和Reduce函数的人不需要关心“分布式”的存在,那么MapReduce框架本身就需要解决好三个很重要的问题:
而谷歌在论文里面,也通过第三部分的“MapReduce的实现”,以及第四部分的“MapReduce的完善”,很好地回答了怎么解决这三个问题。下面,我们就来具体看看,论文里是怎么讲的。
一个MapReduce的集群,通常就是之前的分布式存储系统GFS的集群。在这个集群里,本身会有一个调度系统(Scheduler)。当我们要运行一个MapReduce任务的时候,其实就是把整个MapReduce的任务提交给这个调度系统,让这个调度系统来分配和安排Map函数和Reduce函数,以及后面会提到的master在不同的硬件上运行。
在MapReduce任务提交了之后,整个MapReduce任务就会按照这样的顺序来执行。
第一步,你写好的MapReduce程序,已经指定了输入路径。所以MapReduce会先找到GFS上的对应路径,然后把对应路径下的所有数据进行分片(Split)。每个分片的大小通常是64MB,这个尺寸也是GFS里面一个块(Block)的大小。接着,MapReduce会在整个集群上,启动很多个MapReduce程序的复刻(fork)进程。
第二步,在这些进程中,有一个和其他不同的特殊进程,就是一个master进程,剩下的都是worker进程。然后,我们会有M个map的任务(Task)以及R个reduce的任务,分配给这些worker进程去进行处理。这里的master进程,是负责找到空闲的(idle)worker进程,然后再把map任务或者reduce任务,分配给worker进程去处理。
这里你需要注意一点,并不是每一个map和reduce任务,都会单独建立一个新的worker进程来执行。而是master进程会把map和reduce任务分配给有限的worker,因为一个worker通常可以顺序地执行多个map和reduce的任务。
第三步,被分配到map任务的worker会读取某一个分片,分片里的数据就像上一讲所说的,变成一个个key-value对喂给了map任务,然后等Map函数计算完后,会生成的新的key-value对缓冲在内存里。
第四步,这些缓冲了的key-value对,会定期地写到map任务所在机器的本地硬盘上。并且按照一个分区函数(partitioning function),把输出的数据分成R个不同的区域。而这些本地文件的位置,会被worker传回给到master节点,再由master节点将这些地址转发给reduce任务所在的worker那里。
第五步,运行reduce任务的worker,在收到master的通知之后,会通过RPC(远程过程调用)来从map任务所在机器的本地磁盘上,抓取数据。当reduce任务的worker获取到所有的中间文件之后,它就会将中间文件根据Key进行排序。这样,所有相同Key的Value的数据会被放到一起,也就是完成了我们上一讲所说的混洗(Shuffle)的过程。
第六步,reduce会对排序后的数据执行实际的Reduce函数,并把reduce的结果输出到当前这个reduce分片的最终输出文件里。
第七步,当所有的map任务和reduce任务执行完成之后,master会唤醒启动MapReduce任务的用户程序,然后回到用户程序里,往下执行MapReduce任务提交之后的代码逻辑。
其实,以上整个MapReduce的执行过程,还是一个典型的Master-Slave的分布式系统。map和reduce所在的worker之间并不会直接通信,它们都只和master通信。另外,像是map的输出数据在哪里这样的信息,也是告诉master,让master转达给reduce所在的worker。reduce从map里获取数据,也是直接拿到数据所在的地址去抓取,而不是让reduce通过RPC,调用map所在的worker去获取数据。
如果你熟悉MapReduce的开源实现Hadoop的话,你会发现Hadoop 1.0的实现,其实和MapReduce的论文不太一样。在Hadoop里,每一个MapReduce的任务并没有一个独立的master进程,而是直接让调度系统承担了所有的worker的master的角色,这就是Hadoop 1.0里的JobTracker。
在Hadoop 1.0里,MapReduce论文里面的worker就是TaskTracker,用来执行map和reduce的任务。而分配任务,以及和TaskTracker沟通任务的执行情况,都由单一的JobTracker来负责。
这个设计,也导致了只要服务器数量一多,JobTracker的负载就会很重。所以早年间,单个Hadoop集群能够承载的服务器上限,被卡在了4000台。而且JobTracker也成为了整个Hadoop系统很脆弱的“单点”。

所以之后在Hadoop 2.0,Hadoop社区把JobTracker的角色,拆分成了进行任务调度的Resource Mananger,以及监控单个MapReduce任务执行的Application Master,回到了和MapReduce论文相同的架构。
而在2015年,谷歌发布了Borg这个集群管理系统的论文的时候,大家发现谷歌早在2003~2004年,就已经有了独立的集群管理系统Borg,也就是MapReduce里面所提到的调度系统。在后面的资源调度模块中,我们也会专门解读Borg这个调度系统的论文,以及被认为是Borg后继者和开源实现Kubernetes的论文。
MapReduce的容错机制非常简单,可以简单地用两个关键词来描述,就是重新运行和写Checkpoints。
对于worker节点的失效,MapReduce框架解决问题的方式非常简单。就是换一台服务器重新运行这个worker节点被分配到的所有任务。master节点会定时地去ping每一个worker节点,一旦worker节点没有响应,我们就会认为这个节点失效了。
于是,我们会重新在另一台服务器上,启动一个worker进程,并且在新的worker进程所在的节点上,重新运行所有失效节点上被分配到的任务。而无论失效节点上,之前的map和reduce任务是否执行成功,这些任务都会重新运行。因为在节点ping不通的情况下,我们很难保障它的本地硬盘还能正常访问。
对于master节点的失效,事实上谷歌已经告诉了我们,他们就任由master节点失败了,也就是整个MapReduce任务失败了。那么,对于开发者来说,解决这个问题的办法也很简单,就是再次提交一下任务去重试。
因为master进程在整个任务中只有一个,它会失效的可能性很小。而MapReduce的任务也是一个用户离线数据处理的任务,并不是一个实时在线的服务,失败重来通常也没有什么影响,只是晚一点拿到数据结果罢了。
虽然在论文发表的时候,谷歌并没有实现对于master的失效自动恢复机制,但他们也给出了一个很简单的解决方案,那就是让master定时把它里面存放的信息,作为一个个的Checkpoint写入到硬盘中去。
那么我们动一下脑筋,我们可以把这个Checkpoint直接写到GFS里,然后让调度系统监控master。这样一旦master失效,我们就可以启动一个新的master,来读取Checkpoints数据,然后就可以恢复任务的继续执行了,而不需要重新运行整个任务。
worker和master的节点失效,以及对应的恢复机制,通常都是来自于硬件问题。但是在海量数据处理的情况下,比如在TB乃至PB级别的数据下,我们还会经常遇到“脏数据”的问题。
这些数据,可能是日志采集的时候就出错了,也可能是一个非常罕见的边界情况(edge-case),我们的Map和Reduce函数正好处理不了。甚至有可能,只是简单的硬盘硬件的问题带来的错误数据。
那么,对于这些异常数据,我们固然可以不断debug,一一修正。但是这么做,大多数时候都是划不来的,你很可能为了一条数据记录,由于Map函数处理不了,你就要重新扫描几TB的数据。
所以,MapReduce不仅为节点故障提供了容错机制,对于这些极少数的数据异常带来的问题,也提供了一个容错机制。MapReduce会记录Map或者Reduce函数,运行出错的具体数据的行号,如果同样行号的数据执行重试还是出错,它就会跳过这一行的数据。如果这样的数据行数在总体数据中的比例很小,那么整个MapReduce程序会忽视这些错误,仍然执行完成。毕竟,一个URL被访问了1万次还是9999次,对于搜素引擎的排序结果不会有什么影响。
聊完了MapReduce的容错处理,我们接着一起来看看MapReduce的性能问题。我们在前面说过,其实MapReduce的集群就是GFS的集群。所以MapReduce集群里的硬件配置,和GFS的硬件配置差不多,最容易遇到的性能瓶颈,也是100MB或者1GB的网络带宽。
既然网络带宽是瓶颈,那么优化的办法自然就是尽可能减少需要通过网络传输的数据。
在MapReduce这个框架下,就是在分配map任务的时候,根据需要读取的数据在哪里进行分配。通过前面GFS论文的学习,我们可以知道,GFS是知道每一个Block的数据是在哪台服务器上的。而MapReduce,会找到同样服务器上的worker,来分配对应的map任务。如果那台服务器上没有,那么它就会找离这台服务器最近的、有worker的服务器,来分配对应的任务。你可以参考下面给出的示意图:
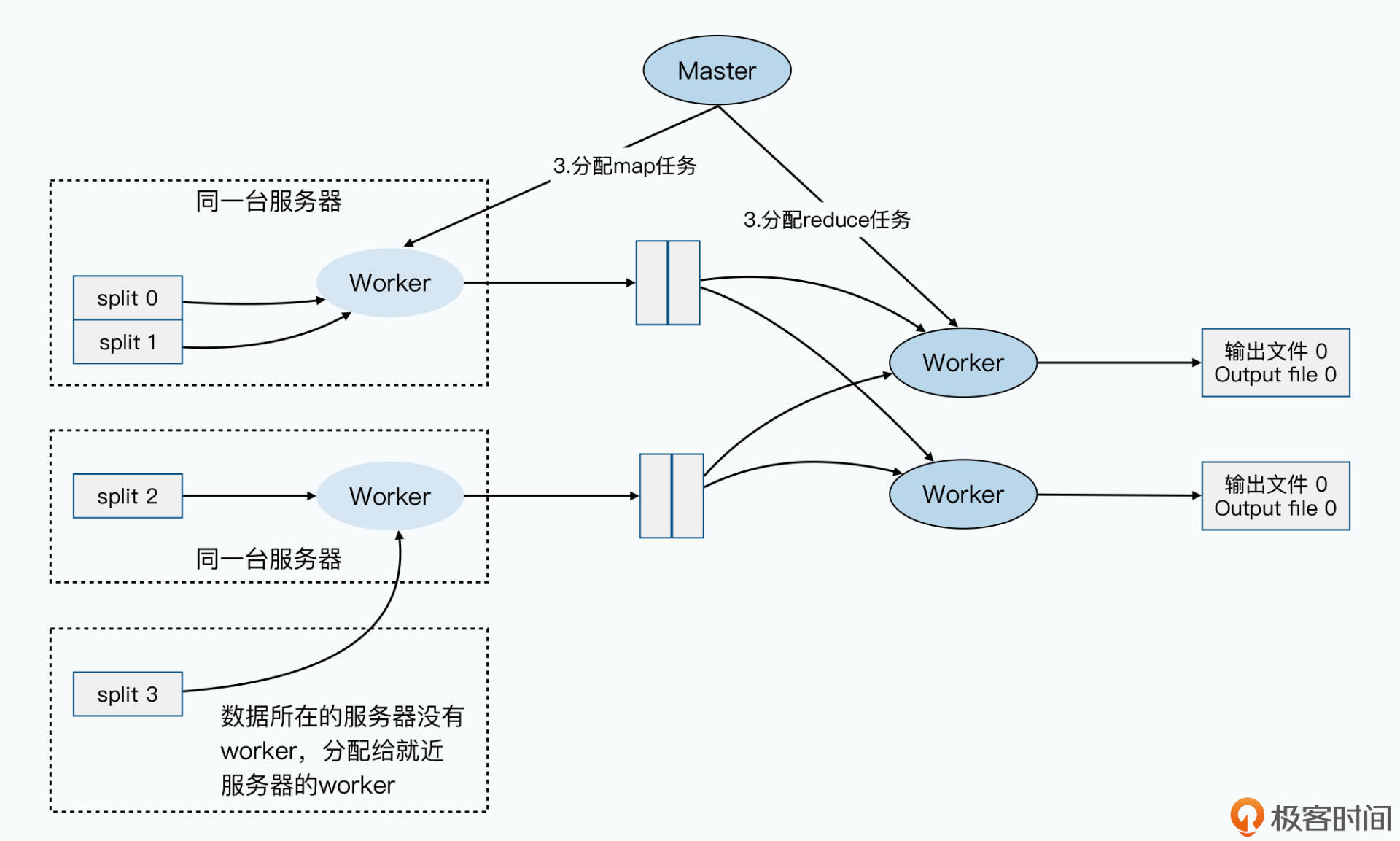
除此之外,由于MapReduce程序的代码往往很小,可能只有几百KB或者几MB,但是每个map需要读取的一个分片的数据是64MB大小。这样,我们通过把要执行的MapReduce程序,复制到数据所在的服务器上,就不用多花那10倍乃至100倍的网络传输量了。
这就好像你想要研究金字塔,最好的办法不是把金字塔搬到你家来,而是你买张机票飞过去。这里的金字塔就是要处理的数据,而你,就是那个分配过去的MapReduce程序。
除了Map函数需要读取输入的分片数据之外,Reduce所在的worker去抓取中间数据,一样也需要通过网络。那么要在这里减少网络传输,最简单的办法,就是尽可能让中间数据的数据量小一些。
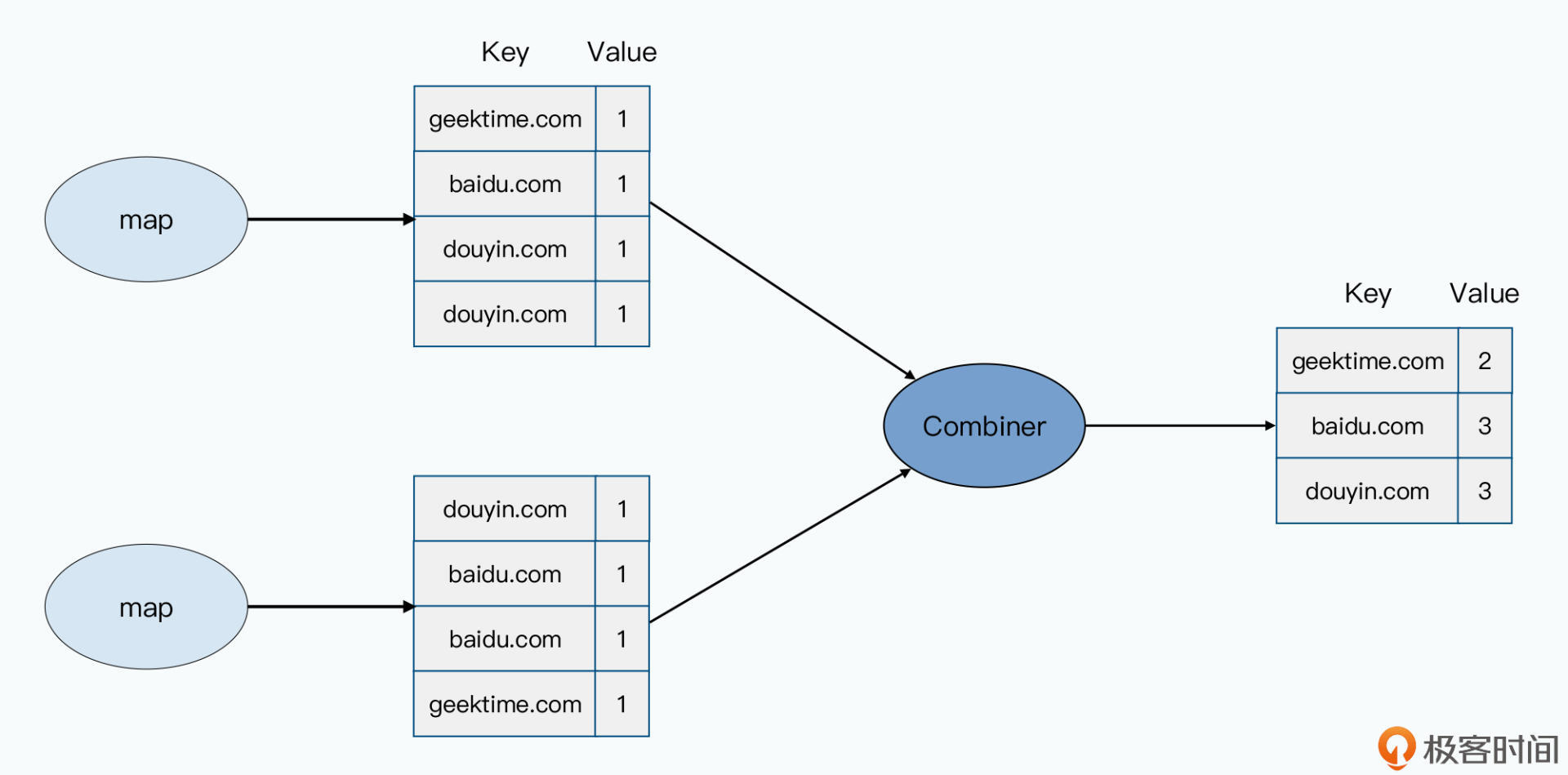
自然,在MapReduce的框架里,也不会放过这一点。MapReduce允许开发者自己定义一个Combiner函数。这个Combiner函数,会对在同一个服务器上所有map输出的结果运行一次,然后进行数据合并。
比如,在上一讲我留下的思考题里,如果你想要统计每个域名的访问次数,那么Map函数的输出结果,就会是一个域名+一次访问计数的1。
而对于用户会高频访问的网站,在map输出的中间结果里就会有很多条记录,比如用户访问了baidu.com、douyin.com这样的域名就会有大量的记录。这些记录的Key就是对应的baidu.com、douyin.com的域名,而value都是1。
既然只是对访问次数计数,我们自然就可以通过一个Combiner,把1万条相同域名的访问记录做个化简。把它们变成Key还是域名,Value就是有多少次访问的数值这样的记录就好了。而这样一化简,reduce所在的worker需要抓取的数据,就从1万条变成了1条。
实际上,不仅是同一个Map函数的输出可以合并,同一台服务器上多个Map的输出,我们都可以合并。反正它们都在一台机器上,合并只需要本地的硬盘读写和CPU,并不需要我们最紧缺的网络资源。
我就以域名的访问次数为例,它的数据分布一定有很强的头部效应,少量20%的域名可能占了80%的访问记录。这样一合并,我们要传输的数据至少可以减少60%。如果考虑一台16核的服务器,有16个map的worker运行,应该还能再减少80%以上。这样,通过一个中间的Combiner,我们要传输的数据一下子就下降了两个数量级,大大缓解了网络传输的压力。
你可以参考下面给出的示意图:
好,性能优化完了,最后我们来看一下MapReduce对于开发者的易用性。
虽然我们一直说,我们希望MapReduce让开发者意识不到分布式的存在。但是归根到底,map和reduce的任务都是在分布式集群上运行的,这个就给我们对程序debug带来了很大的挑战。无论是通过debugger做单步调试,还是打印出日志来看程序执行的情况,都不太可行。所以,MapReduce也为开发者贴心地提供了三个办法来解决这一点。
第一个,是提供一个单机运行的MapReduce的库,这个库在接收到MapReduce任务之后,会在本地执行完成map和reduce的任务。这样,你就可以通过拿一点小数据,在本地调试你的MapReduce任务了,无论是debugger还是打日志,都行得通。
第二个,是在master里面内嵌了一个HTTP服务器,然后把master的各种状态展示出来给开发者看到。这样一来,你就可以看到有多少个任务执行完了,有多少任务还在执行过程中,它处理了多少输入数据,有多少中间数据,有多少输出的结果数据,以及任务完成的百分比等等。同样的,里面还有每一个任务的日志信息。
另外通过这个HTTP服务器,你还可以看到具体是哪一个worker里的任务失败了,对应的错误日志是什么。这样,你就可以快速在线上定位你的程序出了什么错,是在哪台服务器上。我在《深入浅出计算机组成原理》的课程中,就举过一个我自己遇到的“单比特翻转”导致的问题。而对于产生这个问题根本原因的推断,就是通过查看MapReduce的任务日志,发现数据出错的worker总是在固定的一台服务器上。
最后一个,是MapReduce框架里提供了一个计数器(counter)的机制。作为开发者,你可以自己定义几个计数器,然后在Map和Reduce的函数里去调用这个计数器进行自增。所有map和reduce的计数器都会汇总到master节点上,通过上面的HTTP服务器里展现出来。
比如,你就可以利用这个计数器,去统计有多少输入日志的格式和预期的不一样。如果比例太高,那么多半你的程序就有Bug,没有兼容所有合法的日志。下图展示的就是在Hadoop里,通过JobTracker查看Task的执行情况,以及对应每个Task的日志:

这些机制看起来好像并不起眼,似乎和分布式计算框架的名头关系不大。但也正是这些易用的小功能,就让开发者在开发分布式数据处理任务的时候效率大增,不需要吭哧吭哧一台台服务器去翻日志来排查问题,可谓是功莫大焉。
MapReduce的论文到这里就讲解完了。和GFS一样,MapReduce的实现是比较简单的,就是一个典型的单master多worker组成的主从架构。在分布式系统容错上,MapReduce也采取了简单的重新运行、再来一次的方案。对于master这个单点可能出现的故障,谷歌在最早的实现里,根本就没有考虑失效恢复,而是选择了任由master失败,让开发人员重新提交任务重试的办法。
还有一点也和GFS一样,MapReduce论文发表时的硬件,用的往往是100MB或者1GB的网络带宽。所以MapReduce框架对于这一点,就做了不少性能优化动作。通过尽量让各个worker从本地硬盘读取数据,以及通过Combiner合并本地Map输出的数据,来尽可能减少数据在网络上的传输。
而为了方便开发人员去debug程序,以及监控程序的执行,MapReduce框架通过master内嵌的Web服务器,展示了所有worker的运行情况和日志。你还可以通过自定义的计数器,统计更多你觉得有价值的信息。
当然,MapReduce里还有备用任务(Backup Tasks)、自定义的Partitioner等更多的细节值得你去探索。这些就留给你去仔细研读论文,好好琢磨了。
尽管MapReduce框架已经作出了很多努力,但是今天来看,整个计算框架的缺陷还是不少的。在我看来,主要的缺陷有两个:
不过,随着时间的变迁,会有更多新一代的系统,像是Dremel和Spark逐步取代MapReduce,让我们能更容易地写出分布式数据处理程序,处理起数据也比原始的MapReduce快上不少。
对于分布式系统,我们总是希望增加机器就能够带来同比例的性能提升,但是这一点其实很难做到。
Storm的作者南森·马茨(Nathan Marz)在2010年就发表过一个很有意思的博文,告诉大家为什么优化MapReduce任务30%的运行时间,就会减少80%任务实际消耗的时间。这篇文章应该更加有助于你理解为什么我们说MapReduce的遗憾与缺陷中提到的额外开销(overhead)问题。我把这篇文章的链接放在这里,推荐你去阅读学习一下。
在用MapReduce处理数据的时候,因为数据不平衡,可能会使得MapReduce的任务运行得很慢。MapReduce论文里面给出的解决方法,是通过开发人员自己去实现一个分区函数。
不过,一旦需要开发人员自己思考如何分片,其实已经让我们要意识到这个“分布式”本身的存在了。那么,如果让你在MapReduce框架层面解决好这一个问题,你觉得有什么好办法吗?
评论