
你好,我是徐文浩。
通过过去几篇论文的解读,相信现在你已经深入掌握好了大数据系统的基本知识。而在Google的这些论文发表之后,整个工业界也行动起来了。很快,我们就有了开源的GFS和MapReduce的实现Hadoop,以及Bigtable的实现HBase。
这些系统,的确帮助我们解决了很多海量数据处理的问题。并且这些系统设计得也还算易用,作为工程师,我们基本不太需要对分布式系统本身有深入地了解,就能够使用它们。
不过,这些系统都还很原始和粗糙,随便干点什么都很麻烦。所以自然而然地,工程师们就会通过封装和抽象,来提供更好用的系统。这次的系统,不再是来自于Google,而是Facebook了,它的名字叫做Hive。
Facebook在2009年发表了Hive的论文《Hive: a warehousing solution over a map-reduce framework》,并把整个系统开源。而在2010年,Facebook又把这篇论文丰富了一下,作为《Hive-a petabyte scale data warehouse using hadoop》发表出来。这两篇论文其实内容上基本是一致的,后一篇的内容会更完整、详细一些,你可以按照自己的需要有选择性地阅读。
Hive基于Hadoop上的HDFS和MapReduce,提供了一个基本和SQL语言一致的数据仓库方案。我们今天就来深入剖析一下Hive的论文,看看Facebook是怎么基于Hadoop搭建这个数据仓库的。在学完这节课之后,你会理解到这样两个关键点:
那接下来,就和我一起来读一读Hive的论文吧。
在Hive论文的摘要和概述中,其实已经把Hive系统的设计目标讲得非常清楚了。
对于Facebook当时的数据体量来说,如果使用商业的关系型数据库,面临的瓶颈是计算时间,可能一个每日生成的数据报表一天都跑不完,或者一个临时性的分析任务(ad-hoc)也需要等待很长时间。从这个角度来看,我们等不起机器的时间。
而如果用Hadoop和MapReduce来实现,系统的伸缩性的确是没有问题了。通过拥有大量节点的Hadoop集群,这些任务都能比较快地跑完。但是,撰写MapReduce的程序就变成了一个麻烦事儿。
这是因为,MapReduce提供的编程模型和接口仍然太“底层”(low-level)了。即使做一个简单的URL访问频次的统计,你也需要通过写一段代码来完成。而不少分析师并不擅长写程序,稍微复杂一些的统计逻辑,可能需要好几个MapReduce任务,花上个几天时间。从这个角度来看,我们等不起人的时间。
所以针对这两个瓶颈问题,Hive的解法和思路也很明确,那就是通过一个系统,我们可以写SQL来执行MapReduce任务。这样,分析师只需要花上几分钟写个SQL,而Hadoop再通过十几分钟运行这个SQL。最好还能有个Web界面而不需要命令行,我们就可以鱼和熊掌兼得,做出既快又好的数据分析工作。
其实,我在MapReduce的论文解读里,已经给过一个例子。一个通过Group By关键字进行统计的SQL,和一个MapReduce任务,是等价的。
SELECT URL, COUNT(*) FROM url_visit_logs GROUP BY URL ORDER BY URL
你可以回头看一下第6讲里面对于MapReduce任务的讲解。
但是,从原始的MapReduce任务,到SQL语言之间,其实有很多鸿沟。
首先就是序列化和类型信息,基于SQL的数据库,有明确的表结构,每个字段的类型也都是明确的。而原先的MapReduce里,是没有明确的字段以及字段类型的定义的。所以,填补这个鸿沟的第一步,就是先要在数据的输入输出部分加上类型系统。
Google的MapReduce论文里,把对于输入数据的解析,完全交给了开发MapReduce程序的用户自己。对于开发者来说,输入就是一行字符串。而到了Hadoop这个开源系统,这一部分稍微进化了一下,Hadoop把针对输入输出的解析从MapReduce的业务程序里面抽离了出来。
在Hadoop里,你可以自定义一系列的InputFormat/OutputFormat,以及对应RecordReader/RecordWriter的实现。这些接口,把通过MapReduce读写HDFS上的文件内容,以及进行序列化和反序列化的过程单独剥离出来了。这样,开发人员在实现具体的map和reduce函数的时候,只需要关心业务逻辑就好了,因为在map和reduce函数里输入输出的key和value,都是已经包含了类型的Java对象了。
public class ExampleMapper extends Mapper<CustomKey, CustomValue, CustomKey, IntWritable>{
@Override
protected void map(CustomKey key, CustomValue value, Mapper.Context context) {
context.write(key,value.getIntValue());
}
}
在Hadoop里,通过InputFormat/OutputFormat,分离了序列化和map/reduce函数,简化了工程师的工作。
而Hive则很好地利用了这个Hadoop的这个功能特性。对于Hive的使用者来说,不再有“输入文件”和“输入文件的格式”这样的概念了,它读取的直接是Hive里的一张“表”(Table),拿到的“格式”,也是和数据库概念里面一样的“行”(Row)。通过InputFormat解析拿到的一个key-value对,其实就是一“行”数据。
不过,既然是一张数据库表,那么Hive需要的也不是key-value对,而是“行”里面的一个个预先已经定义好的“列”(Column)。所以,Hive在拿到key-value对之后,会再通过论文里所说的SerDer,也就是序列化器Serializer和反序列化器Deserializer,变成一个实际的Row对象,里面包含了一个个Column的值。
对于所有这些列,Hive支持以下这些类型:
而在这些常见的类型之外,Hive和我们之前讲解过的Thrift一样,还支持结构化的类型,包括数组(list)、关联数组(associated-array),以及自定义的结构体(struct)。
这些支持就让Hive的使用变得更加地灵活,这也就类似于现在的MySQL支持JSON字段一样,使得我们每一行数据可以支持更复杂的结构。
比如说,我们在一节课里,可能会有两篇推荐阅读的文章链接,我们就可以通过一个List的结构存储下来。这一点其实和Bigtable类似,在Hive里我们一样会选择用一张“宽表”,把一个对象的所有字段都通过一张表存下来。
在大数据领域,表通常不会轻易通过数据库里的“外键”进行多张表的关联,而是都会用这种“宽表”的形式,主要原因是表和表之间的Join操作很有可能要跨越不同的服务器,这会带来比较高的成本和比较差的性能。
看到这里,相信你也已经想到了,Hive的表的底层数据,其实就是以文件的形式存放在HDFS上的。而且存储的方式也非常直观,就是一张Hive的表,就占用一个HDFS里的目录,里面会存放很多个文件,也就是实际的数据文件。而通过Hive运行HQL,其实也是通过MapReduce任务扫描这些文件,获得计算的结果。
不过,通过MapReduce来执行SQL进行数据分析,有一个巨大的问题,就是每次分析都需要进行全表扫描。和MySQL不同,HDFS上的这些文件可没有什么索引,而Hive要一直到0.6.0版本才会加上基于列存储的RCFile格式。对于一开始的Hive版本来说,你可以认为所有的数据,都是用类似于CSV这样的纯文本的格式存储下来的。
而随着时间的累积,我们的数据会越来越多。可能一开始每天只有100GB的访问日志,作为一张表存放在Hive里了,但是3个月过去之后,这张表就变成了9TB的大小。即使我们只是要访问过去一天的数据,也都必须扫描这9TB的数据。这样的效率,我们当然是无法接受的。
自然而然地,Hive采用了一个数据库里面常用的解决办法,也就是分区(Partition)。Hive里的分区非常简单,其实就是把不同分区的文件,放到表的目录所在的不同子目录下。
论文里举的例子就是按照日期和所在的国家进行分区的情况,通过在表的目录里添加两层目录结构,并分别通过 ds=20090101和ctry=CA标注出来。这样一来,当我们执行的SQL的查询条件,有日期或者国家的过滤条件的时候,就可以不用再扫描表目录下所有的子目录了,而是只需要筛选出符合条件的那些子目录就好了。
/wh/T/ds=20090101/ctry=CA
/wh/T/ds=20090101/ctry=US
/wh/T/ds=20090102/ctry=CA
/wh/T/ds=20090102/ctry=US
……
/wh/T/ds=20091231/ctry=CA
/wh/T/ds=20091231/ctry=US
通过两层目录结构,我们如果按照国家或者日期过滤数据进行分析的时候,读取的文件数量就可以大大减少。
FROM (SELECT a.status, b.school, b.gender
FROM status_updates a JOIN profiles b
ON (a.userid = b.userid and
a.ds='2009-03-20')
) subq1
论文中的这段子查询,会根据
ds='2009-03-20'这个查询条件自动只获取
ds=2009-03-20这个分区,也就是子目录里的文件。
而在分区之外,Hive还进一步提供了一个分桶(Bucket)的数据划分方式。
在分区之后的子目录里,Hive还能够让我们针对数据的某一列的Hash值,取模之后分成多个文件。这个分桶,虽然不能让我们在分析查询数据的时候,快速过滤掉数据不进行检索,但是却提供了一个采样分析的功能。
比如,我们按照日志的log id分成100个桶,那么我们可以很容易地在分析数据的时候,指定只看5个桶的数据。这样,我们就有了一个采样5%的数据分析功能。
这样的数据采样,可以帮助数据分析师快速定性地判断问题,等到有了一些初步结论之后,再在完整的数据集上运行,获得更精确的结果。
/wh/T/ds=20090101/ctry=CA/000000_0
/wh/T/ds=20090101/ctry=CA/000001_0
/wh/T/ds=20090101/ctry=CA/000002_0
……
/wh/T/ds=20090101/ctry=CA/000098_0
/wh/T/ds=20090101/ctry=CA/000099_0
如果分成100个桶,即使分区里的文件大小比一个Block小,仍然会根据桶拆分成多个文件。
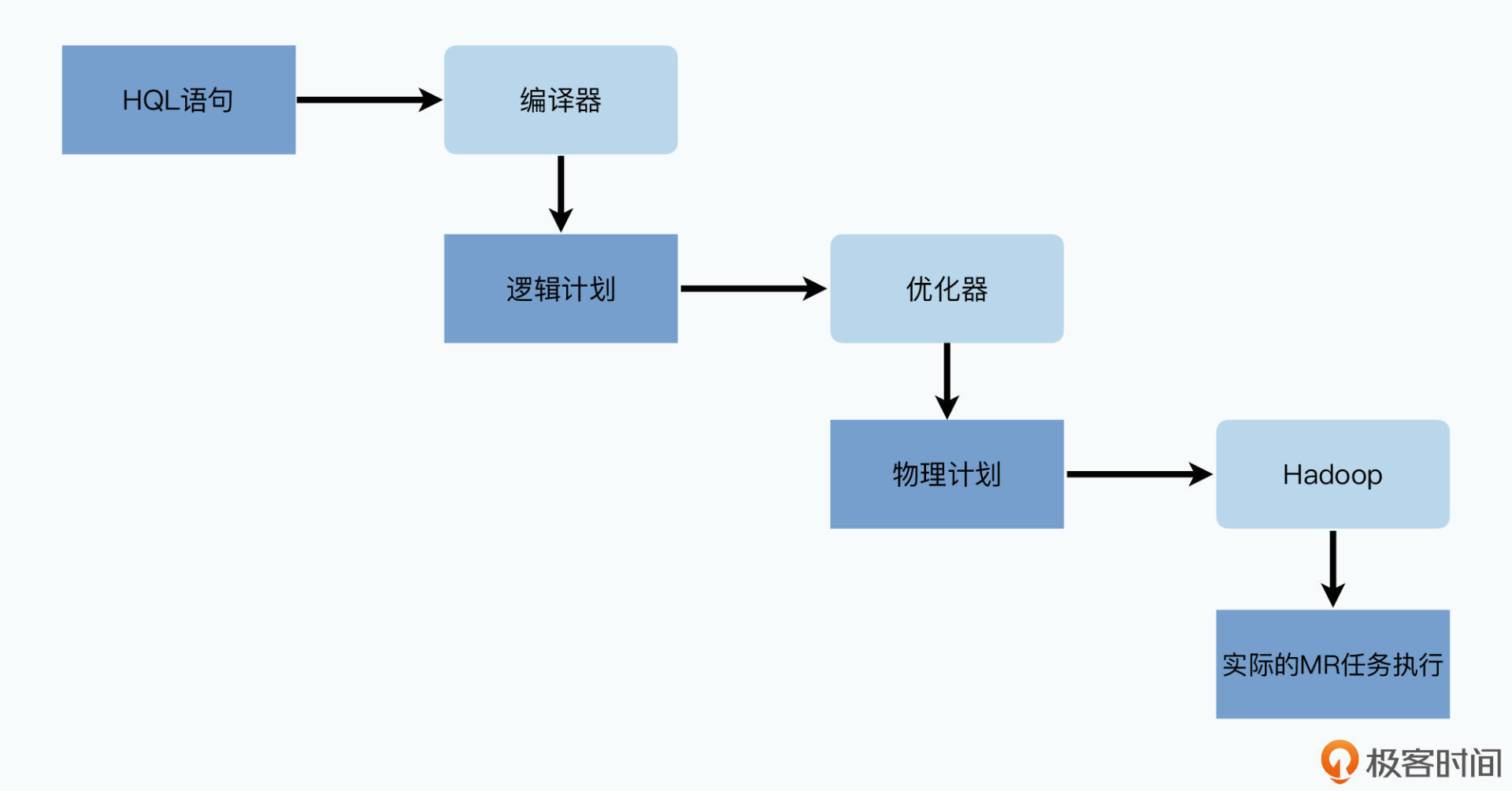
前面我们说过,数据表的字段和类型会通过SerDer来解析确定,而数据的分区分桶其实就是通过目录和文件命名来区分的。所以,Hive的整个系统架构并不复杂,其实也就是三个部分。
第一部分:一系列的对外接口
Hive支持命令行、Web界面,以及JDBC和ODBC驱动。而JDBC和ODBC的驱动则是通过Hive提供的Thrift Service,来和实际的Hive服务通信。这些接口最终都把外部提交的HQL,交给了Hive的核心模块,也就是“驱动器”。
第二部分:驱动器
Hive的核心“驱动器”也不复杂,它其实并不需要提供任何分布式数据处理的功能,而只是做了把HQL语言变成一系列待执行的MapReduce的任务这件事情。最终的实际任务,是由Hadoop里的MapReduce计算框架做到的。这个驱动器主要也可以拆分成三个过程。
编译器会把HQL编译成一个逻辑计划(Logical Plan)。也就是解析SQL,SELECT里的字段需要通过map操作获取,也就是需要扫描表的数据。Group By的语句需要通过reduce来做分组化简,而Join则需要两个前面操作的结果的合并。当然,在逻辑计划里还没有MapReduce的概念,而是一个编译器里实际的抽象语法树(AST),树的每一个节点都是一个操作符。
优化器会拿到逻辑计划,然后根据MapReduce任务的特点进行优化,变成一个物理计划(Physical Plan)。
一个典型的例子是,我们有三张数据表A、B、C,分别存放了用户的基础信息、用户的标签,以及用户的支付数据,然后通过每张表里的user_id把这三张表Join在一起。如果按照逻辑计划直接一个个操作执行,那么我们会先A Join B,把结果输出出来变成一个中间结果X,然后再通过X Join C拿到最后的结果Y。
这个过程,每个Join都是一个MapReduce的任务,但是当优化器看到两个Join的key是相同的,就可以通过一个MapReduce,在Map端同时读入三个表,然后通过user_id进行Shuffle,并在Reduce里进行对应的数据提取处理。这样,我们就可以“优化”到只有一个MapReduce就能完成整个过程。
SELECT A.user_id, MAX(B.user_interests_score), SUM(C.user_payments)
FROM A
LEFT JOIN B on A.user_id = B.user_id
LEFT JOIN C on A.user_id = C.user_id
GROUP BY A.user_id

最后的物理计划,会通过一个执行引擎以及一个有向无环图(DAG),来按照顺序进行执行。执行引擎在这里就是Hadoop的MapReduce,未来,Hive还会扩展到使用Spark等其他的计算引擎里。
第三部分:Metastore
在接口和驱动器之外,Hive最后一个模块则是Metastore,用来存储Hive里的各种元数据。无论是表的名称、位置、列的名称、类型都会存放在这里。这个Metastore,我们通常是使用中心化的关系数据库来进行存储的。
不要小看Metastore,Hive的所有数据表的位置、结构、分区等信息都在Metastore里。如果没有这个Metastore,Hive就更像Pig这样,只是一个方便运用的DSL。
而正是这个Metastore,让Hive成了一个完整的数据仓库解决方案。我们的驱动器里的各个模块,也需要通过Metastore里面的数据,来确定解析HQL的时候,是否所有字段都存在并且合法,以及确认最终执行计划的时候,从哪些目录读取数据。
到这里,我们可以看到,Hive在系统架构上并不复杂,核心模块其实就是一个HQL编译器+优化器。其余无论是数据存储还是分布式计算,仍然是依托于Hadoop,也就是GFS+MapReduce这两篇论文里的底层逻辑。不过,这也是大数据系统迭代中我们会看到的规律。在现实的工程界,很少有石破天惊、完全重新设计开发的新系统,而更多的是尽可能复用现有的成熟系统和成熟模块,在上面迭代、改进以及创新。

其实,把HQL编译成MapReduce来执行的创意并不新鲜,早在2006年,Google就已经发表了Sawzall的论文,而Apache Pig也在2008年9月11日就首次发布了。它们都是通过一门DSL来编译成MapReduce任务加以执行,从而完成数据分析工作。我在下面放了一小段示例代码,你可以看到,其实Pig这样的DSL也很容易进行数据的统计和分析。
A = LOAD '/data/logs/20090101/*' as (logid:string, uid:string, url:string);
B = GROUP A BY url;
C = FOREACH B GENERATE url, COUNT(*);
DUMP C;
通过简单的GROUP BY关键字,Pig一样可以快速进行分组的数据统计。
但是,相比于Hive,Pig缺了几个很重要的环节。
首先是没有选择SQL作为DSL。SQL其实是在大数据出现之前,大部分数据分析师日常使用的“标准”语言。对应的,市场上也围绕SQL有大量的BI类型的产品,进行各种可视化分析。
也因此,Facebook不仅为Hive提供了HQL的命令行界面和WebUI,还通过Thrift Server提供了JDBC和ODBC的接口。这些标准接口使得传统的BI数据分析工具,可以很容易地接入到Hive中来。而Facebook在持续开发Hive的过程中,一个很重要的关注点就是如何努力让Hive支持更多的SQL语义。
其次是没有提供一个足够好的“UI”。这个UI不只是一个Web界面,让你可以输入运行SQL,也包括我们前面说的JDBC/ODBC这样的驱动层。更重要的是,Hive通过Metastore这个元数据存储模块,统一管理了所有数据表的位置、结构、字段名称,以及SerDer的信息。
而当你去使用Pig的时候,这些都需要自己在Pig脚本里写。当分析师想要去看一看现在有哪些数据表,以及每个数据表是什么格式的时候,Hive就比Pig要方便许多。
当我们只有一两张数据表的时候,这个优势还不明显。而当我们像Facebook一样,有数百TB的数据、数不清的数据表的时候,这个Metastore变成一个不可或缺的部分了。
我自己在很长一段时间里也是Pig的重度用户,我觉得对于开发人员来说,Pig更加灵活。但是历史证明,遵循一个主流标准,在使用上提供更好的UI,才能让一个产品更加发展壮大。即使大数据技术已经迭代过好几轮了,Hive仍然有着顽强的生命力,而Pig则已经慢慢消逝在历史的背影之中了。
不知道你有没有发现,这一讲的讲解顺序,其实类似于我之前在加餐中讲过的结构化阅读的方法。我们先是看了摘要和概述,理解了Hive是为了解决商业数据库的性能不足,以及由于MapReduce撰写数据分析程序太麻烦而诞生的。整个论文的结构也可以拆分成数据模型(Section III)、数据如何存储(Section IV)和Hive系统的整体架构(Section V)这三个部分。
数据模型里,Hive通过引入明确的类型系统和SQL-like的HQL,使得普通的熟悉SQL的分析师也可以快速分析海量数据。而整个系统的实现,则很好地复用了Hadoop的基础架构。
数据存储里,Hive的数据是直接放在HDFS上,通过HDFS上不同的目录和文件来做到分区和分桶。分区和分桶,使得Hive下很多的MapReduce任务可以减少需要扫描的数据,提升了整个系统的性能。
整体架构上,Hive其实是三个核心组件的组合,第一个是提供了HQL到MapReduce任务转换的Driver,它提供了编译器、优化器以及执行器;第二个是存储了表结构、分区、存储位置等这些元数据的Metastore;第三个,则是一系列对终端用户提供的UI组件,包括命令行、WebUI、JDBC/ODBC驱动以及下面的Thrift Server。
可以说,Hive并没有自己去实现任何分布式计算和分布式存储的底层工作,实际的所有计算和存储仍然是基于HDFS和MapReduce。完全复用HDFS和MapReduce,使得实现Hive不再是一个那么困难的工作了,而这个也是我们在系统设计中常见的一个进化过程。
并且,因为Hive只是作为一个底层计算引擎的“驱动”(Driver)出现,使得它可以去适配其他的计算引擎。这也是为什么,今天我们已经很少使用原始的MapReduce,而Hive还能够通过Hive on Spark这样使用更快的执行引擎的方式,来保持旺盛的生命力。
而通过实现SQL标准来实现OLAP的数据分析操作,就让Hive打败了Sawzall和Apache Pig这样的DSL系统,也让我们体会到了“标准”和用户群对于一个产品、一个项目的生命力的重要作用。
Hive这样通过SQL形式的语法,去运行MapReduce的想法并不难想到,但这也是整个大数据领域里至关重要的一步。通过HQL,大数据不再是工程师的专利,而是能够惠及到所有的数据分析人员了。
这一讲里,我并没有深入讲解HQL的编译和优化过程。想要深入理解这一部分,需要比较多的编译原理的基础知识,我建议你可以先学习一些编译原理的课程。
之后,如果你想了解HQL具体是怎么编译成MapReduce的执行计划,除了去阅读Hive的源码,还可以去看一看美团技术团队写的《Hive SQL的编译过程》这篇文章。
另外,你也可以去读一读Google在2006年发表的Sawzall这个DSL的论文,这也是思考如何通过DSL来替代撰写MapReduce代码的第一篇文章。
Hive可以通过目录结构来进行分区和分桶,使得最终执行的MapReduce需要扫描的数据变得很少。那么,如果我们把很多字段都去分区和分桶,是不是可以大大提升Hive的性能呢?我们如果这样操作,会有什么负面影响吗?
评论