
你好,我是徐文浩。
Spanner在设计时候的目标之一,就是需要保障外部一致性(external consistency)。而这个外部一致性,其实也就是我们之前说过的可线性化(Linearizability)。通过上节课的学习,现在我们已经知道了,这是一个非常有挑战的目标。其中最大的挑战,在于不同服务器的时钟的差异。
Spanner采用了两个主要的策略来解决这个问题,第一个是通过原子钟和GPS时钟,尽可能地缩短服务器之间的时钟差异。另一个,则是在实现分布式事务的时候,把时钟差异考虑进去,实际的事务提交会进行一定的等待,确保数据写入一定是考虑了最大误差和参与者最快的时钟下,才会实际提交事务。
那么,今天我们这节课,就会深入来讲解Spanner的这个分布式事务具体是怎么实现的。并且在这个过程中,我们会深入探讨分布式事务的可串行化和可线性化两个概念的差异在哪里。在学完这节课之后,我希望你能够收获两点:
在之前讲解Chubby、Megastore和Spanner的过程中,我们既提过“可串行化”,也提过“可线性化”的概念。这两个概念,在分布式数据库里非常容易混淆,为了能够在讲解Spanner的事务实现的时候更加清晰,我先带你来梳理一下这个概念。
可串行化是一个数据库事务隔离性的一个概念,它本身和分布式系统没有关系。它的定义是,一个事务的集合S,可串行化是该集合中事务的一个满足全序关系的排列。换句话说,可串行化,相当于在外部看起来,这些事务是按照某一个顺序,一个一个执行下来的。
这个属性,主要是为了解决数据库里,在有并发事务存在的情况下,数据库应该做到什么样的隔离保障。还是回到我们之前的转账例子里:
这两个事务如果都执行成功,只可能事务一先执行完,再执行事务二。而不是在事务一执行的同时,李四的账户里钱已经增加了,但是张三的钱还没有扣除的时候,事务二就开始执行了。同样的,我们也支持先执行事务二再执行事务一,但是事务二会先失败,而事务一会执行成功。
但是,在可串行化的情况下,我们仍然完全有可能遇到事务一已经执行完成了,事务二再提交,但是执行失败的问题。事务二失败的原因是,它读到的仍然是事务一执行完成前的数据快照,认为李四的账户余额不足。
这种情况,在分布式的系统下很有可能发生。事务一已经提交完成了,但是因为系统是分布式的,还没有同步到所有的副本。事务二只能读到旧的数据快照,但是为了确保事务的隔离性是可串行化的,我们不能让事务二提交完成。
可串行化但是不可线性化的系统,很多时候是我们愿意容忍的,因为它至少确保了数据库里的数据的正确性。即使发生了前面事务失败的例子,我们仍然可以在应用操作层面,等待重试。
而可线性化是一个分布式系统中的概念。它的含义是,对单个对象上的操作,是“实时”的。也就是你对一个数据写入操作成功了,那么立刻去读取它,就会读到刚刚写入的值。
这个乍一听是理所当然的事情,其实无论是在单机环境下,还是分布式环境下都有可能被打破。在单机环境下,可能我们写入成功的数据还在CPU Cache里,没有同步到主内存,那么来自另外一个CPU的数据读取,可能就取不到这个值。
而在分布式环境下,这个问题尤其普遍。我们可能在上海的数据中心写入,1秒之后在广州的数据中心去读的时候,数据还没有同步过来,CAP理论里的一致性(Consistency)其实大部分情况下都是在探讨这个问题。其实多个CPU,你也可以把它看成是单机环境里的一个“微观”的分布式系统。
同时,可线性化完全可以和数据库事务的可串行化无关。比如前面的转账例子里,如果没有事务,我们完全可以让所有的账户变动过程变成这样:
从可线性化的角度来看,每个用户的单个账户的操作顺序都是满足了可线性化的。我们在第一步和第二步之间,只要读到李四的账户,是多了新转进去的400元就可以。但是因为没有事务支持,这样的操作顺序也满足不了我们实际的业务需求。
可线性化的本质,是需要我们在分布式系统上的操作符合常识。我们写入成功的数据,之后去读取,必须要能读取到刚刚写入的新数据,而不是有可能会读到一个旧版本的数据。即使写入和读取的动作,可能分别是从两个相聚几千公里的不同数据中心发起的。
如果做不到这一点,对应用开发人员来说,本来简单的逻辑会变得非常复杂,所有的业务逻辑,都需要去考虑因为网络延时或者时钟误差带来的紊乱。而我们本身设计分布式系统的一大目标,就是让应用开发人员不需要关心分布式的存在,那么不是“可线性化”的系统,显然做不到这一点。
不过,你需要注意,可线性化是针对单个对象上的操作。如果两个操作,或者是两个数据库事务,互相之间没有任何交集,那它们在系统里记录的事务的时间,是不需要保障先后顺序的。
比如,我们有这样两个事务:
这两个数据库事务之间,什么顺序都可以,因为两个事务之间没有共同操作的对象。而只有我们再有一个:
在事务三出现的情况下,我们才需要对事务一、二、三明确一个排列顺序。因为事务三操作的数据,既和事务一有交集,也和事务二有交集。所以事务一和二在这个情况下,是通过事务三关联起来,才会有明确的顺序。
而在Spanner这个数据库里,我们需要同时保障可串行化和可线性化。而可串行化和可线性化的组合,在分布式数据库领域里,被称之为严格串行化(Strict Serializability)。也就是在外部看来,事务是串行执行的,并且一旦一个事务执行成功,我们立刻去读取数据的话,无论是从分布式系统的哪个节点发起,我们一定能够读取到刚才的最新数据。
这个体验,其实就跟我们日常生活里的常识和体会一模一样了。你转账成功之后,告诉你远在千里之外的亲友,他去查看银行卡,就一定能看到银行卡里钱已经转进来了,而不是有可能需要等待网络数据的同步。
我们的数据库,不仅因为支持可串行化的事务隔离性,在内部看起来是一致的,对于所有外部使用数据库的人来说,也是一致并且正确的。这也是为什么Spanner说它自己是一个“外部一致”的数据库。
因为要支持严格串行化,解决时钟误差问题就对Spanner尤为重要。所以Spanner里的时间,并不是给出了一个简单的数字,来代表某一个时间点。而是通过一组叫做TrueTime API的接口,提供了一个有误差范围的“时间”概念。

首先,Spanner假设有一个绝对准确的时钟,这个时钟的每一个时间点,就是一个绝对时间。Spanner的论文里,对于任何一个事件的发生,都会有一个绝对的时间点,这个时间点,在论文里用$t_{abs}(e)$来表示。其中的e代表event,就是某一个事件,而$t_{abs}$则是绝对(absolute)时间(time)的意思。
我们任何一个服务器去获取当前的时间,是拿不到绝对时间的,而只能拿到一个 [earliest, latest] 这样的时间范围。同时,Spanner也简单封装了TT.after和TT.before这两个接口,可以拿来比较服务器获取到的时间和绝对时间$t_{abs}(e_{now})$的先后。
对于TrueTime API来说,它保障的是:
tt = TT.now()
tt.ealierst < $t_{abs}(e_{now})$ < tt.latest

Spanner为了要保障可线性化,本质上就是要确保任何一个在绝对时间t发生的数据读取,一定只能看到在t这个时间节点之前已经提交成功的数据写入,之后的数据写入它是看不到的。并且,只要是在绝对时间t之前已经提交成功的事务写入,它也一定要能看到,而不能有些看不到。
那么,Spanner是怎么通过自己的系统架构和这里的TrueAPI,做到这一点的呢?我们一起接着往下看。
我们先来看看Spanner支持的数据读写的事务类型:
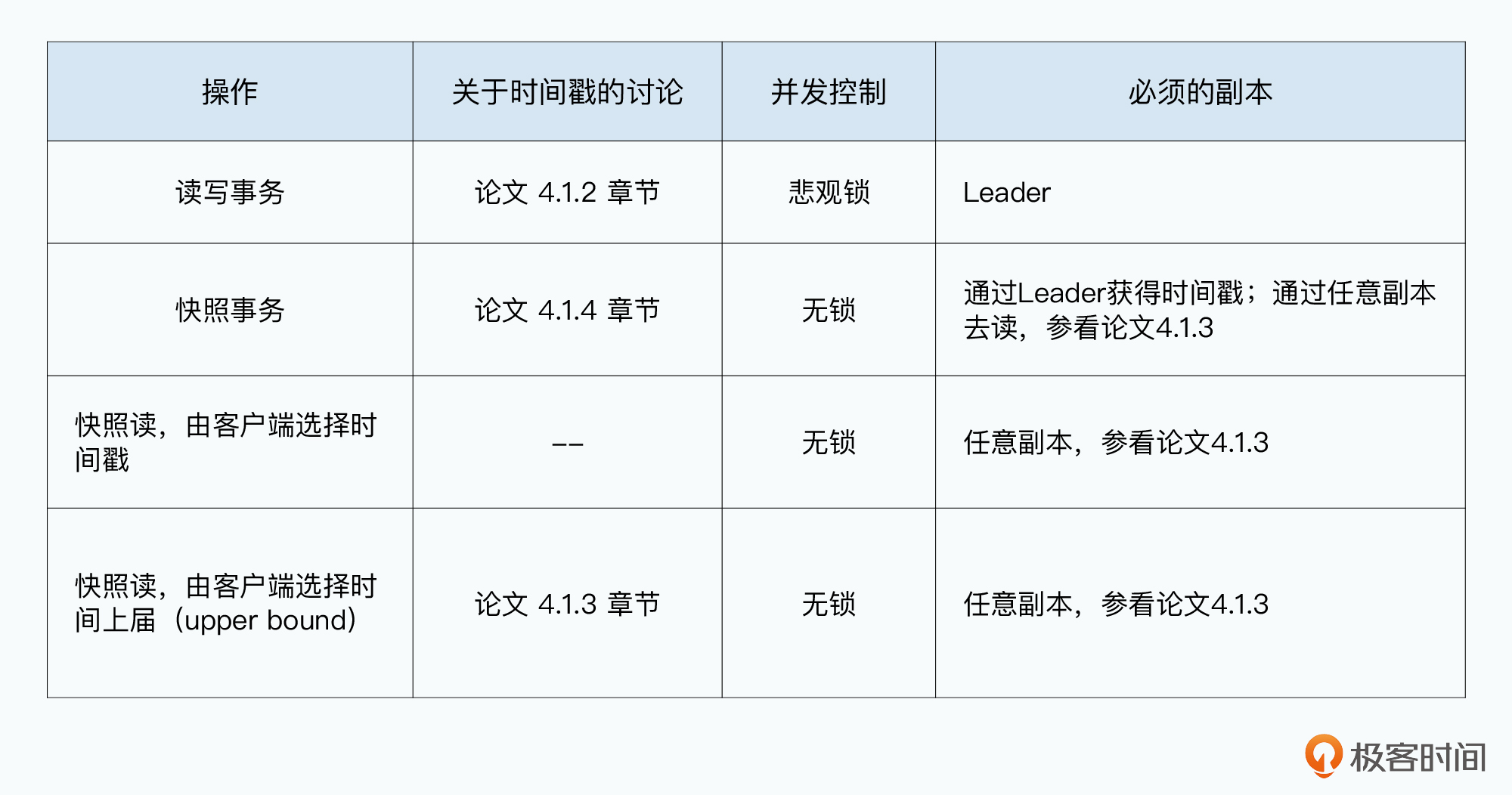
Spanner一共支持3种操作,分别是读写事务、快照读事务、以及普通的快照读。
其中,只有读写事务可以修改数据库里的数据,读写事务需要使用悲观锁,也就是对应的数据行一旦被锁,其他读写事务,是不能并发修改对应数据的。而所有的读数据都是无锁的,也就是无论是否有其他并发的读请求,或者有读写事务在进行,都不会影响数据的读取。
快照读事务,和普通的快照读,唯一的差异就在于这个快照的“时间戳”由谁来提供。如果是快照读事务,那么这个“时间戳”是由Spanner系统来提供的。而普通的快照读,则是由应用指定时间,Spanner里支持两种指定时间的方式,一个是客户端选择一个时间戳,另一种则是指定一个时间戳的上届(upper bound),让Spanner在这个上届之下,为客户端选择一个时间戳。
注意,我们这里说的时间戳,都是指一个绝对时间戳,而不是某一台服务器本地时钟的时间戳。
我们先来看一下Spanner的读写事务是怎么进行的。我们在上节课看过,Spanner的数据库事务面临的第一个挑战,就是一个事务写入的时间戳,到底应该是什么。Spanner的读写事务是这样的:
那么整个读写过程会是这样的:
第一步,客户端写入数据库的请求,会先到达分布式事务中的协调者。而且在Spanner里,这个协调者本身也是一个事务的参与者。
第二步,和一般的两阶段事务一样,协调者会向参与者的Paxos的Leader发起一个提交请求,也就是Prepare请求。这个时候,参与者会为要更新的数据获取一个写锁。参与者会为事务生成一个Prepare请求的时间戳,并且向Paxos里,写入一条Prepare请求的记录。这个时间戳,会比这个Paxos组之前分配给所有事务的时间戳都要晚。
也就是说,这个Paxos组,在分配时间戳的时候会保障单调递增,确保不会出现,后出现的请求时间戳早的情况。
第三步,协调者本身不会给自己发Prepare请求,它会等待所有的参与者,返回事务是否可以提交的应答。这些应答中,参与者会把分配给Prepare请求的时间戳,一并返回给协调者。这个时候,协调者会为这次事务生成一个事务提交的时间戳。这个时间戳,需要满足三个要求:
第四步,在有了这个时间戳之后,协调者会进行一个有条件的等待。它会等到TT.after(s),也就是在考虑误差的情况下,绝对时间一定已经晚于这个选择的事务提交时间之后,再提交事务。
提交事务的时候,作为一个参与者,它会在本地应用这个事务。作为协调者,它会向其他的参与者发起请求,让它们也提交事务。所有参与者写入的数据都有相同的时间戳,并且在事务应用完成之后,参与者会把对应的写锁释放掉。
第五步,在整个事务提交完成之后,协调者会返回结果给到客户端。

在这个机制下,当有两个并发的事务,需要写同一条记录的时候,我们能够确保它们写入事务的时间戳,是有明确的先后关系的。我们还是以上节课的转账例子来举例:
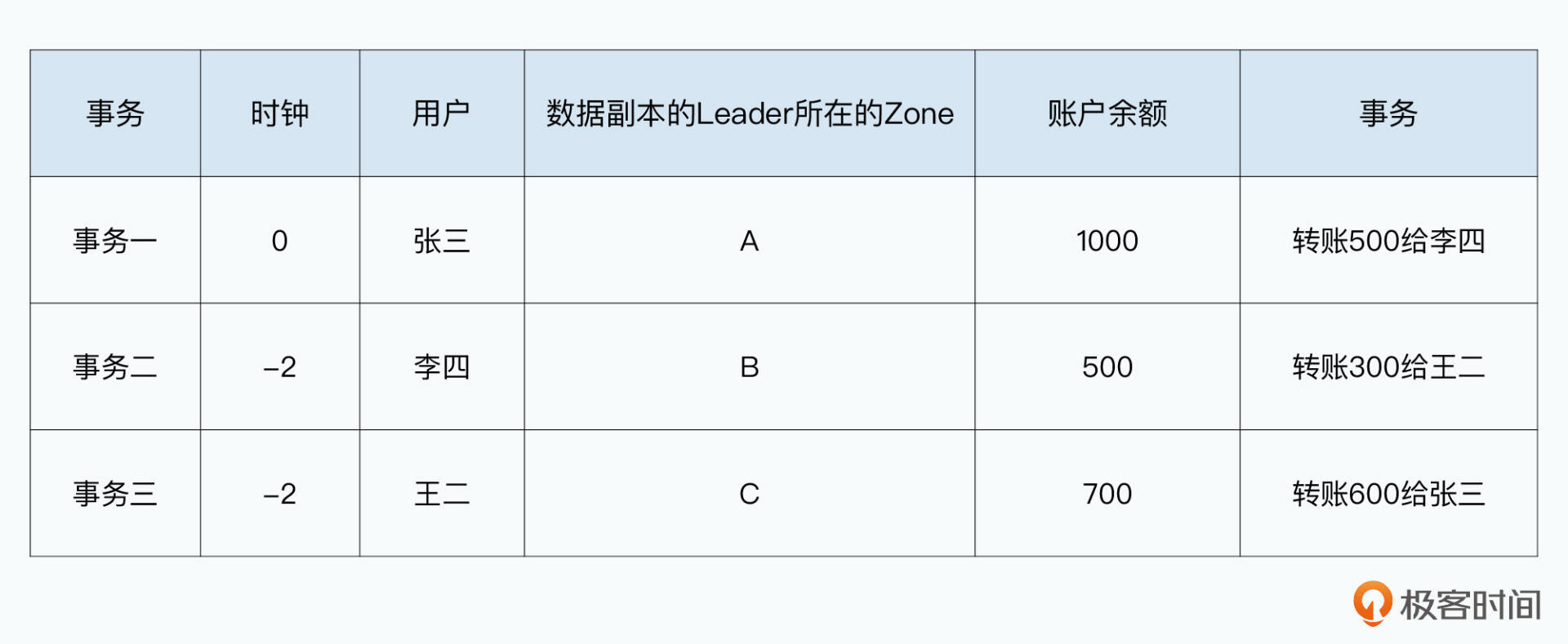
我们之前遇到的时间戳问题,在于事务二后执行的时候,因为B和C的时钟比A要快。所以,事务二执行的时候,提交的时间戳可能早于事务一。
但是在现在这个机制下,我们看到:
在Spanner的论文中,有一段很简短的证明,告诉我们如果两个事务牵涉到的Paxos组,是有交集的情况下,那么后提交的事务的时间戳,一定会晚于新提交的事务。我们可以在这里一起看一下。
然后根据大小比较的传递关系,我们就自然有$s_{1} \lt s_{2}$,也就是事务二记录的提交时间,是晚于事务一的。

可以看到,在这个读写事务的机制下,我们的事务有可能需要等待一段时间,而且这个时间是和我们的时钟误差相关的。时钟误差越小,我们需要等待的时间越短。这也是为什么Google需要在数据中心里,采用原子钟和GPS时钟,尽可能缩短不同服务器的时钟差异的核心原因。
既然我们已经能够保障,Spanner的事务写入的时候的时间戳没有问题。那么,下一个挑战就来自于数据库读了。因为Spanner允许从任何一个副本读取数据,所以我们就会面临另一个挑战,就是Paxos下,我们并不能保障每一个副本都拥有最新的数据。
因为数据的写入只需要多数通过就好了,我们完全可能因为网络分区、数据延时等问题,访问了一个没有最新版本数据的副本。那么这个时候,我们该怎么办呢?
Spanner是这样解决这个问题的。Spanner里的数据库读取,都会带上一个时间戳,如果客户端自己没有指定,那么系统会为它分配一个时间戳,这个时间戳我们记为$s_{read}$,这个值是由对应记录的Paxos组的Leader生成的。最简单直接的方式,就是使用Leader的TT.now().latest,也就是考虑时间误差下,当前可能的最晚时间。
而当一个读取数据的请求到达某一个数据副本的时候,这个副本需要回答一个问题,就是它本地的最新数据是什么版本的呢?它是可以直接返回本地的数据,还是要让这个读取请求,等待到它把数据同步完成?
所以,每个副本会在本地维护一个称之为$t_{safe}$的值。只要请求带来的$s_{read}$比这个值小,那就说明本地副本的数据足够新,可以返回$s_{read}$这个时间节点下最新的数据快照。这个$t_{safe}$是这样取值的:
$$
t_{safe} = min(t_{safe}^{paxos},t_{safe}^{TM})
$$
不过这里问题来了,如果Paxos组里没有数据更新,我们的$t_{safe}$岂不是一直不会更新,我们的读请求就需要一直死等在那里?Spanner的系统并没有那么傻,它通过这样一个机制来解决这个问题。
首先,是每一个Paxos组的Leader,都会维护一个映射关系,叫做MinNextTS(n)。
这里的n,指的是第n次Paxos写入。看着这个映射函数的命名,相信你不难猜到它是什么意思。Min代表最小的,Next代表下一次,而TS自然是TimeStamp的缩写也就是时间戳。这个映射函数是给到我们,下一次Paxos写入,能够分配到的最小的时间戳。
所以每一次Paxos数据写入之后,我们都会生成这个时间戳,然后Paxos的Leader会把我们的 $t_{safe}^{paxos}$置为MinNextTS(n)-1,也就是下一次数据可以写入之前的时间节点。这样,会使得$t_{safe}^{paxos}$尽可能晚,使得它不容易小于$s_{read}$,导致数据读请求需要等待。
此外,Paxos的Leader即使在没有数据写入的情况下,也会默认每8秒钟更新一次MinNextTS(n),既然时间已经往后推移了,自然$t_{safe}^{paxos}$也会对应向后更新。
所以,即使在最坏的情况下,我们的Paxos组,也能够至少返回8秒前时间戳的数据读请求。
其实,在没有进行中的事务的情况下,我们的Leader分配$s_{read}$可以更简单一些。它不会去分配TT.now().latest,而是直接会拿到当前Paxos组最大写入的时间戳,直接用这个时间戳去获取数据就好了。否则,我们的请求多多少少都会阻塞等待,或者需要客户端去从其他副本读取,这样读取性能会变得差上不少。
好了,到这里,Spanner的论文我们就算是正式解读完了。在这节课里,我们先是回顾了“可串行化”和“可线性化”的概念。前者,想要解决的是数据库里的隔离性问题,后者则是想要解决分布式系统里的一致性问题。而Spanner则两个都要,也就是需要实现“严格串行化”。
Spanner实现严格串行化的方式,是引入了TrueTime API。通过这个API,任何一个服务器拿到的本地时间,不再是一个精确的时间戳,而是一个绝对时间的范围。而在Spanner的数据写入的过程中,选择的时间戳,也是要考虑所有的参与者的时钟,并在其中选择最晚的那一个。并且在提交的时候,也要考虑误差,确保事务写入的绝对时间,是晚于系统生成的时间戳的。
而在数据读取的时候,我们需要考虑对应的副本,不一定已经同步了最新的数据。所以所有的数据读取,都会带上一个时间戳。而每一个数据副本,也需要为一个本地的Paxos最新写入数据的时间戳。同时,读取数据也还要考虑当前是否有事务进行到一半。
在考虑了所有已经同步的数据和在进行中的事务中,选取出最早的时间戳,就是当前副本确定拥有的最新的更新了。通过对比本地副本的这个时间戳和读请求的时间戳,我们就能知道是否可以返回数据,还是需要等待本地副本进一步同步完数据才行。
Spanner的论文是非常重要的,对于分布式数据库系统也有很强的里程碑意义。它告诉全世界,一个强一致、高性能、全球分布式的数据库是完全可行的。在Spanner的论文之后,像TiDB、CockroachDB这些开源的数据库,也都跟随Spanner的脚步,以它为蓝本去实现支持完整ACID的分布式关系型数据库了。
可串行化和可线性化是数据库系统,以及分布式系统中一个非常重要的话题。我推荐你可以去读一读这一篇关于一致性模型的博客,对于可线性化和可串行化,以及每一个概念都有详细的解说。对应的各个概念的脑图,你也都可以点击进去,看看每个概念的详细解释。
在讲解Spanner的数据写入的时候,我们是直接把一个Paxos组看成是一个“单机”来处理的。一个Paxos组,需要自己保障生成出来的时间戳的单调递增。但是,实际上Paxos组也是有多个机器组成的分布式集群,而且这些机器之间,也是有时钟误差的。而且Paxos组里的Leader只拥有一个0~10秒的租约,这意味着Leader本身,会切换到另一台时钟不同的节点上去。
那么在读完论文之后,你能说说Spanner是如何处理和解决这里的时钟差异的吗?
欢迎在留言区分享你的答案和思考过程,也欢迎你把今天的内容,分享给更多的朋友,一起交流讨论。
评论