
你好,我是徐文浩。
在 Storm的论文里,我们看到Storm巧妙地利用了异或操作,能够追踪消息是否在整个Topology中被处理完了,做到了“至少一次(At Least Once)”的消息处理机制。然后,在 Kafka的论文里,我们又看到了,Kafka通过将消息处理进度的偏移量记录在ZooKeeper中的方法,使得整个消息队列非常容易重放。Kafka的消息重放机制和Storm组合,就使得At Least Once的消息处理机制不再是纸上谈兵。
然而,我们并不会满足于“至少一次”的消息处理机制,而是希望能够做到“正好一次(Exactly Once)”的消息处理机制。因为只有“正好一次”的消息处理机制,才能使得我们计算出来的数据结果是真正正确的。而一旦需要真的实现“正好一次”的消息处理机制,系统的“容错能力”就会变得非常重要。Storm的容错能力虽然比起S4已经有了一定的进步,但是实际上仍然非常薄弱。
所有的这些问题,伴随着Kappa架构设想的出现,为我们带来了新一代的流式数据处理系统。那么,接下来的几节课里,让我们步入现代流式数据处理系统,一起看看从Google的MillWheel、Dataflow,到开源的Apache Flink的系统是怎么回事儿。
在这节课里,我们会先看看在没有这些系统的时候,在实践上使用Storm时会遇到哪些实际的问题。其实也正是由于这些问题,催生了现代流式处理系统的诞生。在学完这节课之后,我希望你能够理解以下这三点:
在理解了这些问题之后,我们其实就已经开始逼近现代的流式数据处理系统了。只要能够解答好这些问题,我们就会有一个全新的系统了,而这样一个全新的系统究竟应该如何搭建,其实就是后续我们会详细讲解的MillWheel、Dataflow以及Flink的核心知识点了。
我们先来看一看,在有了Kafka和Storm之后,一个实际的流式数据处理系统是怎么样的。
最简单的,我们就采用一个进行广告点击率计算和计费的数据处理需求。我们的日志会是这样的格式:
这里的日志,只是一个最简化的模型。在实际的广告系统中,会有上百个字段,比如我们还会记录IP地址,以分辨用户所在的地理位置等等。不过,有了这个最简单的日志格式,我们已经可以做两个最常见的广告数据的流式处理了。
那么根据这两个需求,我们就可以很容易地基于Kafka和Storm,搭建起一个我们需要的流式数据处理系统。
首先,前端的应用服务器,会把产生的广告日志发送给一个负载均衡。然后通过负载均衡,均匀而随机地发送给Kafka不同的Broker服务器。下游有一个Storm集群,里面有一个Topology,同时完成了广告计费,以及广告的点击率统计的工作。
这个Topology,就只有简单的两层。
在向下游发送数据的时候,都是采用字段分组的方式。发给AdsCtrBolt的,是按照广告ID进行分组,发给ClientSpentBolt的,则是按照广告客户ID进行分组。这样,所有相同广告的日志,都会发送到同一个AdsCtrBolt里;而所有相同广告客户的日志,也都会发送给同一个ClientSpentBolt。
广告ID=>(展示次数,点击次数,广告花费) 的Map。然后定时把这个表输出到外部的数据库里,比如HBase或者Bigtable这样的数据库。也就是,它会每分钟输出一次对应广告ID的点击率信息。最后,整个Storm的Topology,是开启了AckerBolt的,也就是我们会确保所有的消息能够至少被处理一次。
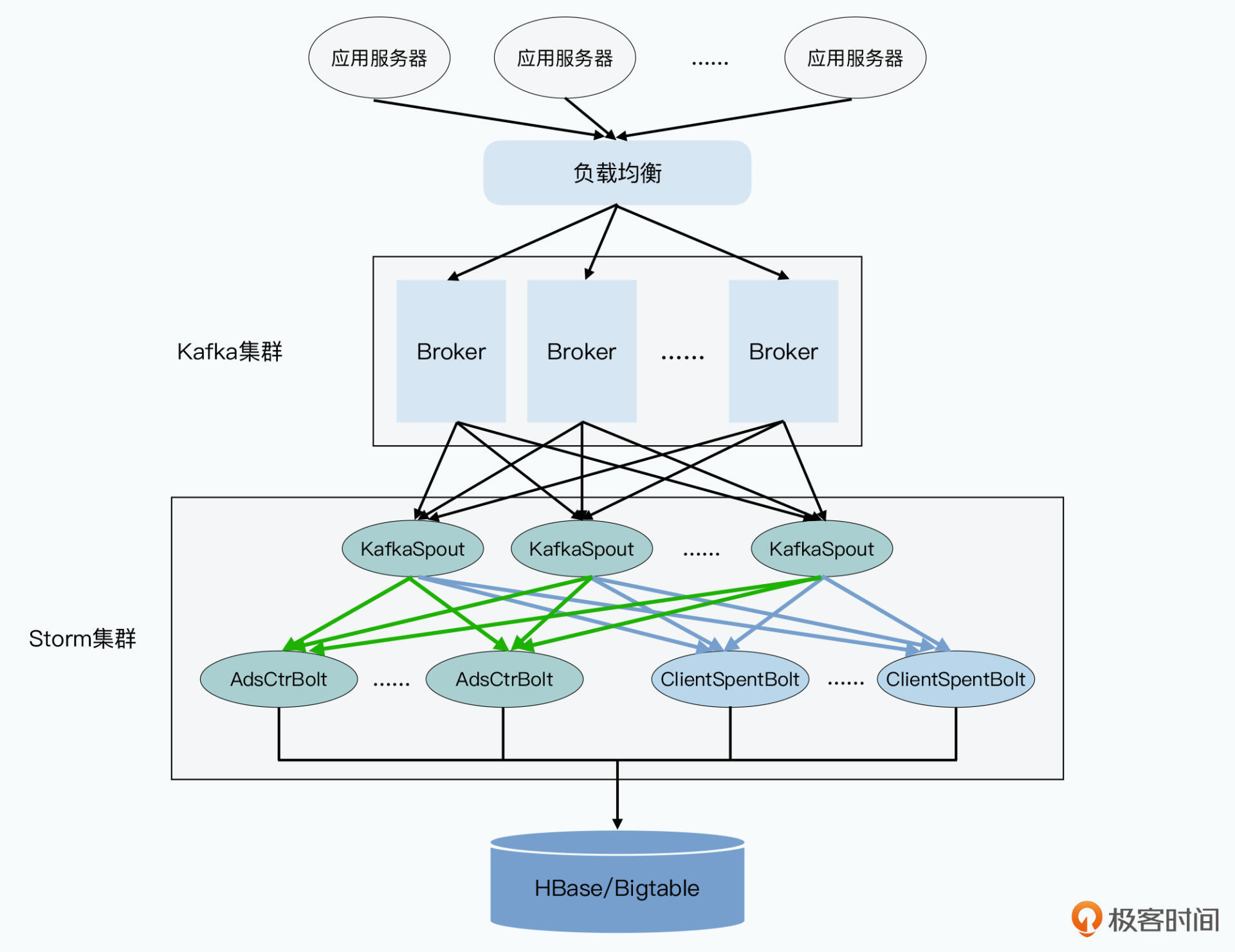
这样,一切看起来都很完美,我们简单地通过Kafka+Storm,就有了一条可以实时计算广告花费和广告点击率的数据流水线。当然,如果我们的系统非常稳定,没有任何软硬件故障的时候,事情也许是这样的。不过,在大数据领域,我们始终面临“出错”这个问题。而一旦出错,我们的麻烦就来了。
首先就是这个“至少一次”数据处理的特性,其实已经满足不了我们实际的业务需要了。随着时间的推移,我们已经把“广告计费”这样对于准确性要求很高的应用,也放到流式处理系统里来。
在我们这个应用场景里,可能某一个ClientSpentBlot写入外部数据库的时候,出现了比较高的延时。这个时候,Storm的“至少一次”的处理机制,会重发对应的消息。如果没有考虑这样重发的消息,那么我们就会在ClientSpentBolt里面,重复计算同一条日志的广告花费,这就意味着我们多扣了广告客户的预算,这显然是难以接受的。
而如果说,单条日志重发计费,可能对于最终计费的影响还很小。那么如果Storm的某一个KafkaSpout出现了硬件故障,挂掉了,我们就可能有一大批消息会重复计费了。
因为为了性能考虑,我们从Kafka拉取数据,不会是拉一条、处理一条,然后更新一次ZooKeeper上的偏移量。特别是ZooKeeper会受不了这么大的负载,它和Chubby一样,是用于实现一个粗粒度的分布式锁,而不是一个高性能的KV存储。所以,KafkaSpout会从Kafka拉一小批数据,然后发送出去,等到这一小批数据发送完了,并且下游都处理完了,才会变更一次ZooKeeper上的偏移量。
但是,只要其中有一条消息在下游还没有处理完的时候,KafkaSpout所在的服务器挂掉了,对应的偏移量没有更新。那么在容错机制下,重新启动在另一台服务器上的KafkaSpout,会重新再发送一遍这一批数据。而这个时候,我们就不只是重新对一条日志重复计费,而是需要对一大批日志重复计费。

要解决这个问题,一个很直观的思路,自然是对重复发送的日志或者消息进行去重。最简单的方式,就是在每一个Bolt里,我们维护一个这个Bolt已经处理完成的,所有的message-id的集合。那么,任何一条新的消息发送过来的时候,我们都去这个集合里看一看,这条消息是否已经处理过了,就能解决这个问题了。
不过,让每个Bolt都保留所有处理过的message-id的集合,显然会占用太多的内存了。因为在流式系统里,随着时间的推移,系统处理过的日志量在不断地增加,message-id的集合只会越来越大。所以,在工程实践上,我们可以做两个优化:

真正做到“正好一次”的数据处理,是现代流式数据处理的第一个目标。
BloomFilter的引入,使得我们用于计算的Bolt节点,其实有了“状态”。也就是说,它自身已经不是一个纯粹的函数了。事实上,不仅是为了做到“正好一次”的消息处理需要状态,我们本身的数据处理需求就需要状态。
比如,我们的AdsCtrBolt里,维护的那张 广告ID=>(展示次数,点击次数,广告花费) 的Map,也就是我们在Bolt里维护的状态。不过,需要维护状态又给我们带来了一个新的挑战,那就是系统的容错问题。
对于系统的“计算节点”的容错很容易,我们只要在另外一台服务器上,重新启动一个Bolt就好了。但是这个时候,我们之前维护在Bolt内存里的 广告ID=>(展示次数,点击次数,广告花费) 的状态就已经丢失了。如果我们是每一分钟输出一次数据给HBase/Bigtable里的话,这意味着我们经常会丢掉一分钟的数据。
事实上,不仅仅是针对容错问题,我们需要考虑恢复Bolt里的状态,对于系统的可扩展性,我们同样需要考虑恢复Bolt里的状态。Storm的论文里,我们的并行度是部署Topology的时候预先设定好的。但是,这样的系统,很难进行动态的扩容。
如果我们的广告业务越来越红火,意味着上游的日志越来越多。这个时候,我们其实希望调整每一层并行度,通过增加并行度,使得我们系统仍然能够在线水平扩展。
但是,要调整并行度,意味着两点:
广告ID=>(展示次数,点击次数,广告花费) 的状态,也需要能够拆分。这个时候,S4的设计反而显得更合理,那就是每一个PE都对应着一个Key了。这样,我们需要迁移的状态,就和对应的计算函数是绑定在一起的了。Bolt会被拆分和迁移,并且在迁移的过程中,我们需要能够保留状态信息,这意味着我们的状态需要能够持久化下来。我们需要能够把这些状态,也更新到一个稳定的外部存储中去。当我们的节点挂掉,在其他服务器上恢复计算能力的时候,需要把这些状态信息重新读取回来。
并且,这个能力,也使得我们去调度计算变得更容易了,我们可以动态地在线上增加系统的并行度。而不是采用部署一个新系统再把老系统下线,这样运维成本更高的模式。

通过把各个计算节点的中间状态持久化,使得系统在容错情况下,仍然能够做到“正好一次”的数据处理,并且能够在线上动态扩容、调度计算,是现代流式数据处理的第二个目标。
除了重复发送的消息去重,Bolt的中间状态需要持久化之外,其实我们前面的Topology还有一个问题没有解决好,这个问题就是“时间问题”。
我们在前面Storm的Topology里,很简单地用一句“每分钟”输出一次广告点击率,概括了AdsCtrBolt的逻辑。这个“每分钟”的时间,依靠的是Storm内建的一个叫做TickTuple的机制。Storm可以在系统层面设置一个时间间隔参数,根据这个参数,Storm会按照固定的时间间隔,向每一个Bolt和Spout发送一个特殊的TickTuple。我们的Bolt只需要每当接收到这个TickTuple的时候,把当前计算出来的状态信息输出出去就好了。
但是,这个处理逻辑有一个问题,就是我们用消息传输到AdsCtrBolt的时间,替代了对应的广告曝光和点击发生的时间。也就是我们用处理时间(Processing Time)替代了事件时间(Event Time)。这样,我们计算出来的点击率,乃至计费信息,会和实际情况有差异。
而且,这个差异情况,在很多场景下我们是无法容忍的。
一种情况是和业务需求相关,比如我们的广告客户,设置了广告预算都在11月份花完。那么,在11月30日晚上11点59分59秒发生的广告点击,实际被处理的时候很有可能已经是12月1日了。这样,我们的广告客户会看到,他并没有在12月份分配任何广告预算,但是我们的系统却让他在12月1日有了花费,这显然会引起客户的不满。
另一种情况,则是和我们对于日志的重放相关。无论是系统故障,还是我们修改了数据分析逻辑,当我们要通过重放Kafka里的日志,重新计算统计数据的时候,现在的逻辑会造成更大的麻烦。因为所有的日志都是在短时间内重放,所以我们会把过去几小时,甚至是几天的数据,都统计在最近几分钟内,我们的统计数据不是有一些小小的误差,而是完全错误的。

当然,批量重放日志,不是一个常见的情况。但是,在硬件故障的情况下,部分前端应用服务器的日志没有及时进入Kafka,或者某些Kafka的Broker的部分日志,没有及时进入我们的Topology则是一个常见的情况。在这样的场景下,我们仍然会有大量的日志,出现少则数十秒,多则一两个小时的延误。这样计算出来的错误的统计数据,我们仍然接受不了。
一个合理的解决方案,就是我们需要使用实际的事件发生的时间(即Event Time),来进行相应的数据统计。但是这样一来,我们就面临两个新的问题。
第一个问题,是我们不能简单地维护 广告ID=>(展示次数,点击次数,广告花费) 这样一个映射关系了,而是需要一个 时间窗口=>[广告ID1=>(展示次数,点击次数,广告花费),广告ID2=>(展示次数,点击次数,广告花费) , ……] 这样一个三维多层的映射关系了。
第二个问题,是我们很难决策,什么时候应该将我们的统计结果,写入到外部的数据库里。因为在上节课里我们就看到过,上游发送过来的日志,并不是严格按照时间排序的。一个可行的方案,就要考虑很多因素,比如我们要加上这样几个判断条件和因素:
显然,要实现这些逻辑,我们使用Storm现有的内置机制是做不到的。
虽然我们还是可以通过像TickTuple这样的机制,定时提醒我们去检查是否应该把数据从Bolt内存里维护的Map,输出到外部的数据库里。但是,像是维护时间窗口的映射关系、统计最近日志的时间戳这些逻辑代码,我们仍然都需要自己来撰写。
而我们希望的仍然是,大数据应用的开发人员只需要撰写统计相关的业务逻辑代码,而不需要为了容错,或者考虑Kafka发送数据可能存在的延时,去写大量实现容错功能的代码。
我们希望能够把和时间窗口相关的,以及触发数据更新到外部数据库相关的处理机制,在流式处理框架中内建。而撰写流式数据处理逻辑的开发人员,不需要关心这些机制和容错问题,这个也就是现代流式数据处理的第三个目标。
好了,相信到这里,你对于流式数据处理面临的挑战应该已经清楚了。可以看到,面对这些挑战,我们原本以为已经非常优秀的Storm是远远不够的。
我们需要一个系统,能够达成三点目标:
在这节课里,我们已经给出了一些实践上的解决方案。但是,我们并不希望,自己在写Storm的Spout代码的时候,写上一大堆代码,来解决正好一次的数据处理、Spout中间状态的持久化,以及针对时间窗口的处理逻辑。因为这些问题,是流式数据处理的共性问题。
我们希望能有一个流式处理系统,帮助我们解决这些问题。作为应用开发人员,我们仍然只需要撰写业务代码。这个,也就是我们接下来会讲解的MillWheel、Dataflow以及Flink的系统会做到的事情。
那么,聊到现代流式数据处理,我们绕不开《Streaming System》这本书,目前国内也已经出版了影印版。当然,整本书的篇幅很长,我推荐你可以先去读一下作者写的两篇小短文Streaming 101和Streaming 102这两篇文章。
在“正好一次”的数据处理中,我们引入了BloomFilter,来减少对于内存的占用。但是,BloomFilter始终还是会存在误算的情况,这个可能会导致我们少计算对应的数据。那么,你能设计一组参数,估算一下BloomFilter可能会导致我们漏掉计算多少日志吗?
欢迎在留言区分享你的答案和思考,也欢迎你把今天的内容分享给更多的朋友。