你好,我是黄金。欢迎来到第三期复习课,今天我们来回顾复习下Bigtable这篇论文的知识点。
在Bigtable论文中提到,当年Google的很多产品都使用Bigtable存储数据,包括Web索引、谷歌地球、谷歌金融。不管是完成批处理,还是实时数据服务,Bigtable表现得都很好。也就是说,Bigtable不仅擅长顺序读写,也擅长随机读写。
徐老师在 08讲中,先是讲了为什么MySQL集群难以支撑百万级别的随机读写IOPS,主要的原因是可运维性差。第一,数据分区不灵活,导致随着数据规模的增长,有些分区数据多,有些分区数据少;第二,服务器扩容不灵活,扩容时要么需要移动大量数据,要么需要成倍增加服务器;第三,故障恢复时只能自动恢复主节点,不能自动恢复备份节点。
那么,Bigtable是如何解决这些运维问题的呢?
首先,为了应对数据规模的增长,我们需要把数据分配到不同的服务器,这个行为叫做分区。Bigtable的分区方式是为每个分区分配一段连续的行键(Row Key),每个分区管理固定大小的数据。当分区数据超过阈值时,比如128MB,分区就会自动分裂。之所以这样做,是因为数据分布可能是不均匀的,动态分区可以让数据在服务器上分布更均匀。
然后,正是由于每个分区负责的行键区间不固定,就需要一个组件帮助客户端在发起请求时,找到行键所在的数据分区。这个组件需要让集群中的所有节点达成共识,确定哪个区间的数据在哪个分区上,由哪台服务器提供服务。它的名字就是Chubby,在后续的论文解读课上我们还会深入学习,目前只需要知道它是用来在集群中对某件事达成共识。
另外,Bigtable中还分离了存储模块和在线服务,采用不同的方法应对扩容和故障恢复。Bigtable的分区数据叫做Tablet,存储在GFS上,很自然地具备了扩容和容灾的特性。而负责处理读写请求的在线服务是Tablet Server,Tablet Server支持动态增加和删除,Bigtable会把Tablet合理地分配给存活的Tablet Server。
我们应该也知道,MySQL的容灾方式是为主服务指定一个备份服务,主服务挂了就切到备份服务上,但是如果这个备份服务也挂了就麻烦了,我们没有更多的备份服务顶上,所以服务器一旦发生故障,运维人员需要及时处理。
而Bigtable的容灾方式是为主服务指定一个备份服务池,主服务挂了就从备份服务池中选一个服务作为主服务,如果这个备份服务也挂了,就从池子里再选一个。这种容灾方式,让运维人员可以更从容地处理故障。
了解了Bigtable的可运维性,接着再让我们一起回顾下Bigtable的数据模型。
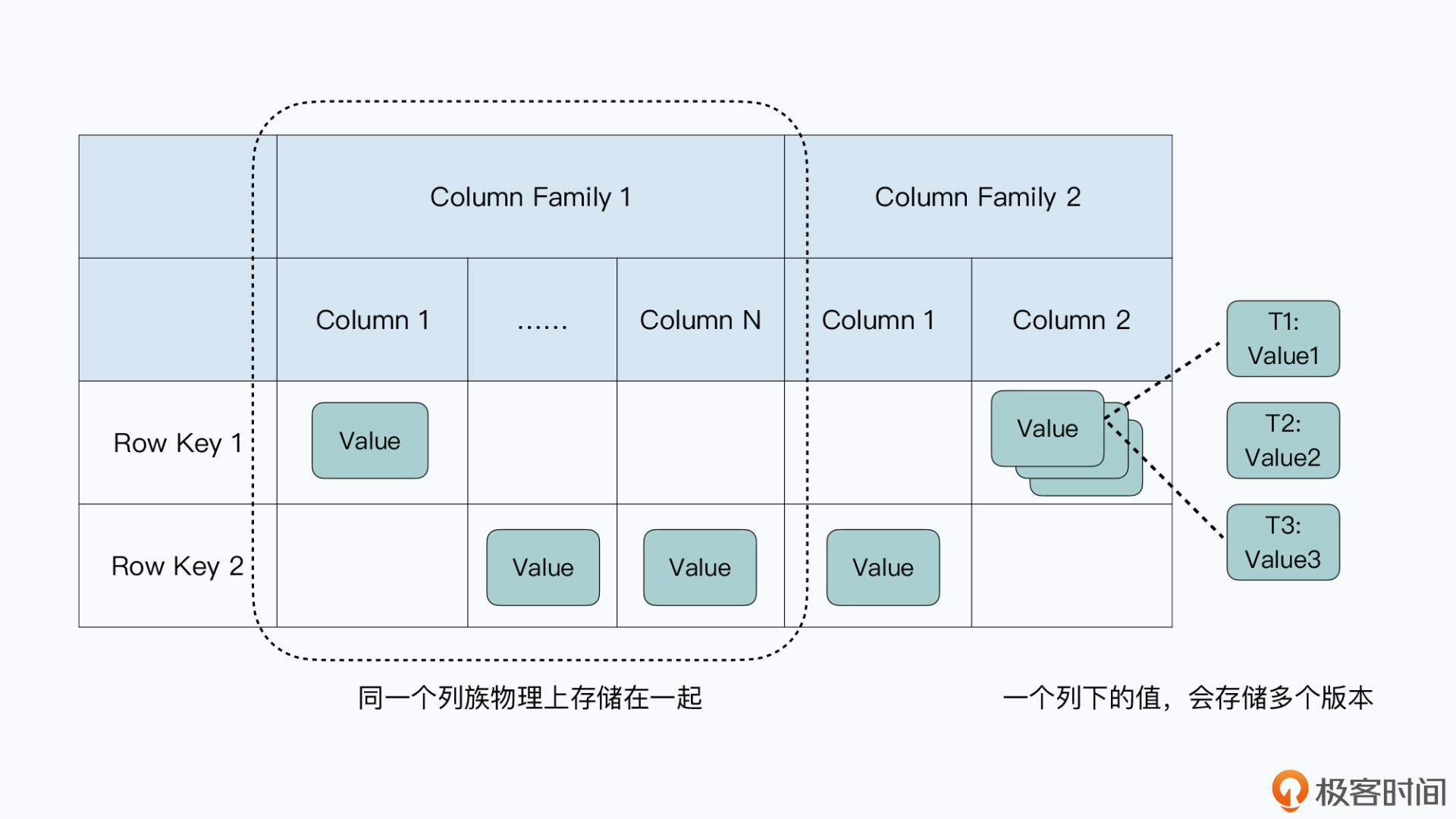
Bigtable是一个有序的稀疏表。每一条数据有一个行键,通过行键可以原子性地读写一条数据。一条数据包含了多个列族,不同行数据的同一列族内,可以定义不同的列。每一个列不仅可以保存值,而且可以保存多个版本,每个版本包含了一个时间戳。
Bigtable的数据是按行键的字段顺序排列的,采用动态行键范围分区,分区被称为Tablet。刚开始在Bigtable里,一张表只有一个分区,随着数据越写越多,分区会一分为二,新分区的边界按数据密度划分,以保证两个分区的数据量大致相同。而如果一个分区的数据删除太多,就会和它相邻的分区合并,新的分区负责原来两个分区行键范围的数据。
Bigtable的列族是把一组相关的列在物理上放在一起存储,不同的列族会通过逻辑组织在一起。当读写操作只涉及某个列族时,Bigtable只需要处理这个列族对应的物理表即可。列族不同于列式存储,因为列族不是按列分开存储的,而是把多个相关的列打包到一起存储,并且允许每一行有不同的具体列。
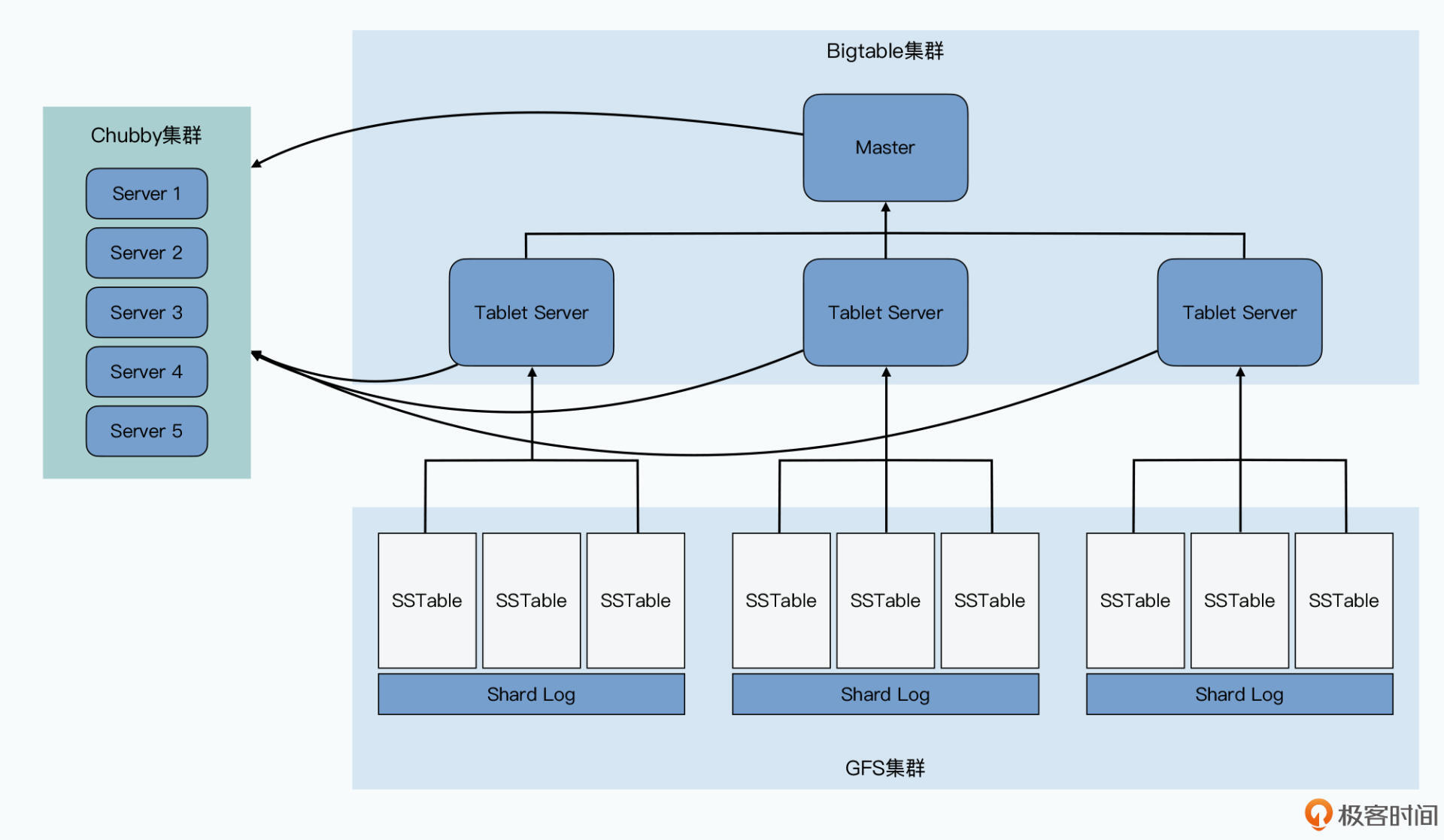
纵观整个Bigtable的系统架构,主要是由4个组件组成的,它们分别是:
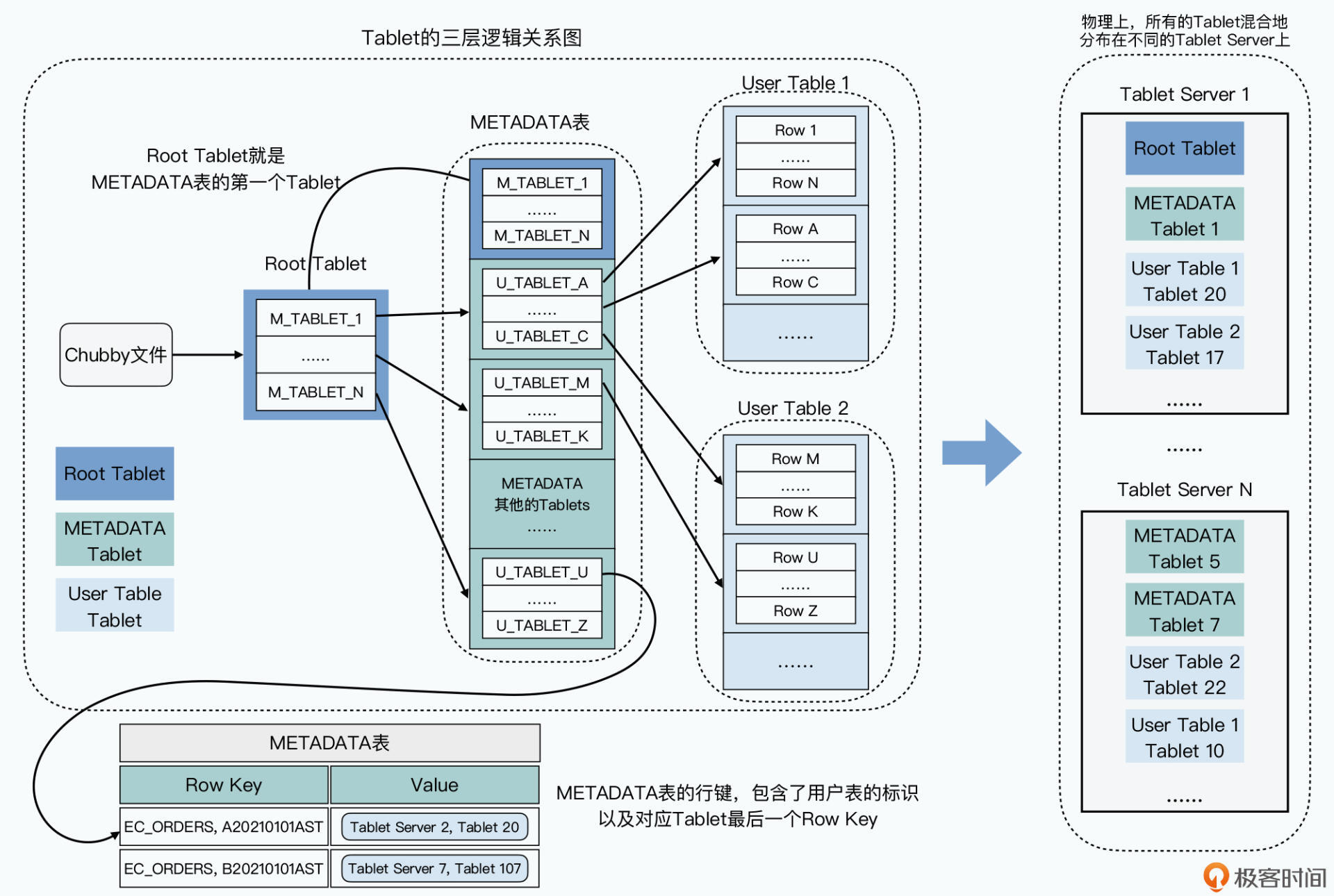
由于采用动态行键范围分区,Bigtable需要维护行范围到分区的映射关系,以便客户端请求能够路由到正确的Tablet Server上。Bigtable采用了三层树状结构存储数据表的分区信息:
Bigtable会通过Chubby追踪Tablet Server。当新的Tablet Server添加到集群中的时候,会向Chubby注册自己,Chubby会通知Master有新的Tablet Server加入,Master会把其他Tablet Server管理的Tablet匀一部分,给新加入的Tablet Server。
Master会通过心跳定时检查Tablet Server的存活状态,如果Tablet Server在Chubby的注册信息不在了,则可以认为Tablet Server处于失效状态,Master会把这个Tablet Server负责的Tablet,分配给其他存活的Tablet Server。
而因为Bigtable集群只有一个Master服务,如果Master挂了,Chubby就会立即选举一个新的Master。由于读写操作只和Chubby、Tablet Server、Tablet有关,Master只负责调度Tablet和调整负载,所以单Master的架构并不会成为Bigtable的性能瓶颈。
Bigtable最耀眼的能力在于可以支撑每秒百万级别的随机读写。它主要是通过两个方法达成这个目标的:
我们先来看看Bigtable是如何把随机写变成顺序写的。
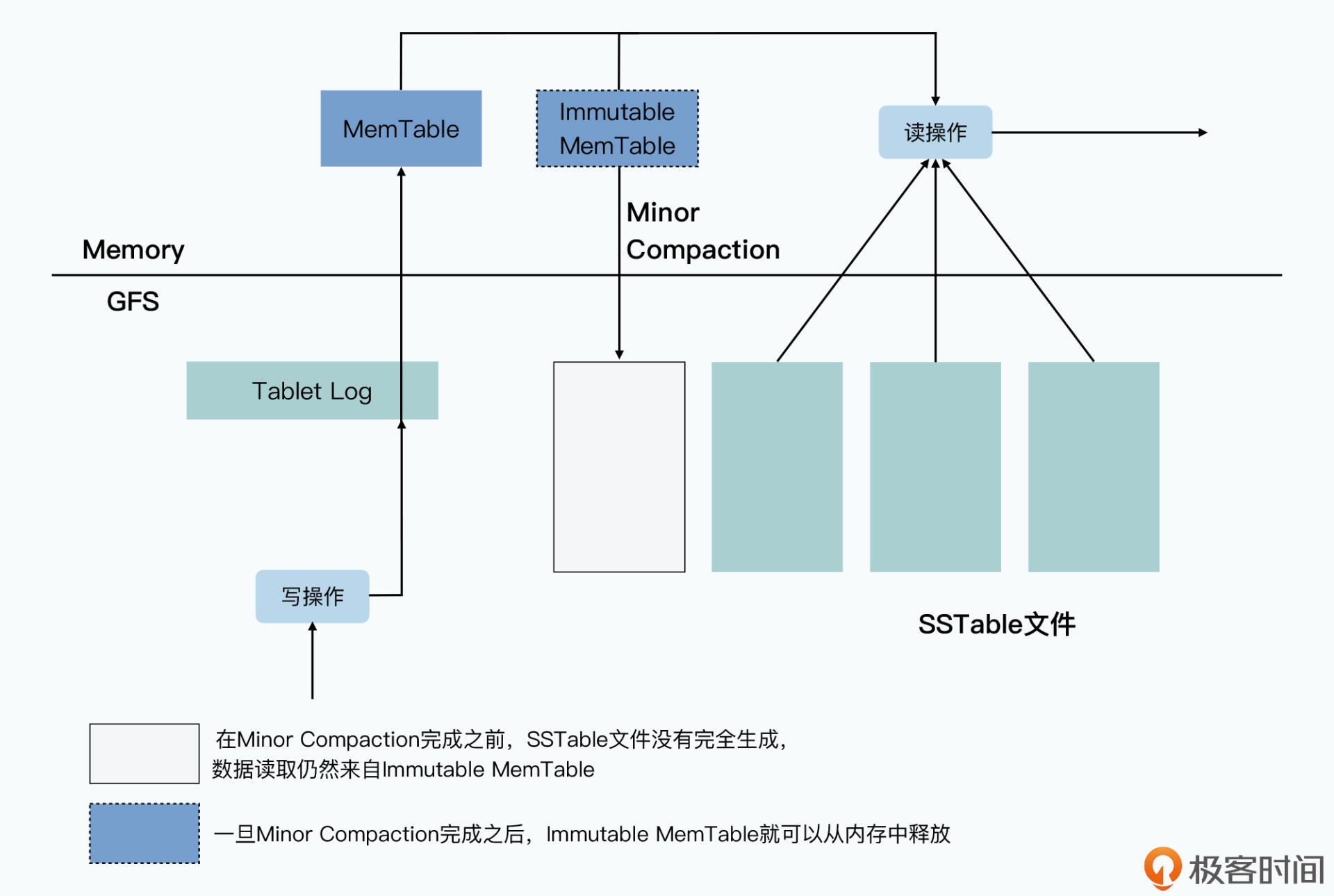
当客户端向Bigtable发起一次随机写请求,会通过三层树状结构的分区信息,找到对应的分区Tablet,以及处理写请求的Tablet Server。Tablet Server将这次写操作记录到Commit Log,然后变更内存表MemTable,当内存表大于某个阈值时,将其作为SSTable文件写入磁盘,并清理Commit Log。
接着我们再看看,Bigtable是如何通过内存表MemTable和SSTable文件,完成随机读操作的。
当客户端向Bigtable发起一次随机读操作,同样会通过三层树状结构的分区信息,找到对应的分区Tablet,以及处理读请求的Tablet Server。Table Server会先从内存表MemTable中查找数据,然后再通过SSTable文件的缓存查找数据,如果都找不到的话,它会再加载SSTable文件,从中查找。
那么,随着写操作次数的增加,Tablet下的SSTable会越来越多,从而就会影响读操作的性能。因此,Bigtable会把多个SSTable压实成一个SSTable,只保留对一个行键的最后几次操作,这个行为称为Major Compaction。它不仅能够节约硬盘空间,还能够提升读操作性能。
而除了Major Compaction之外,Bigtable还有一种Compaction,叫做Minor Compaction,它在内存表大于某个阈值时,会将其作为SSTable文件写入磁盘。它的作用是节约内存空间,同时减少内存表恢复时,需要读取的Commit Log大小。
另外,为了提高随机读的性能,Bigtable其实还做了很多优化。
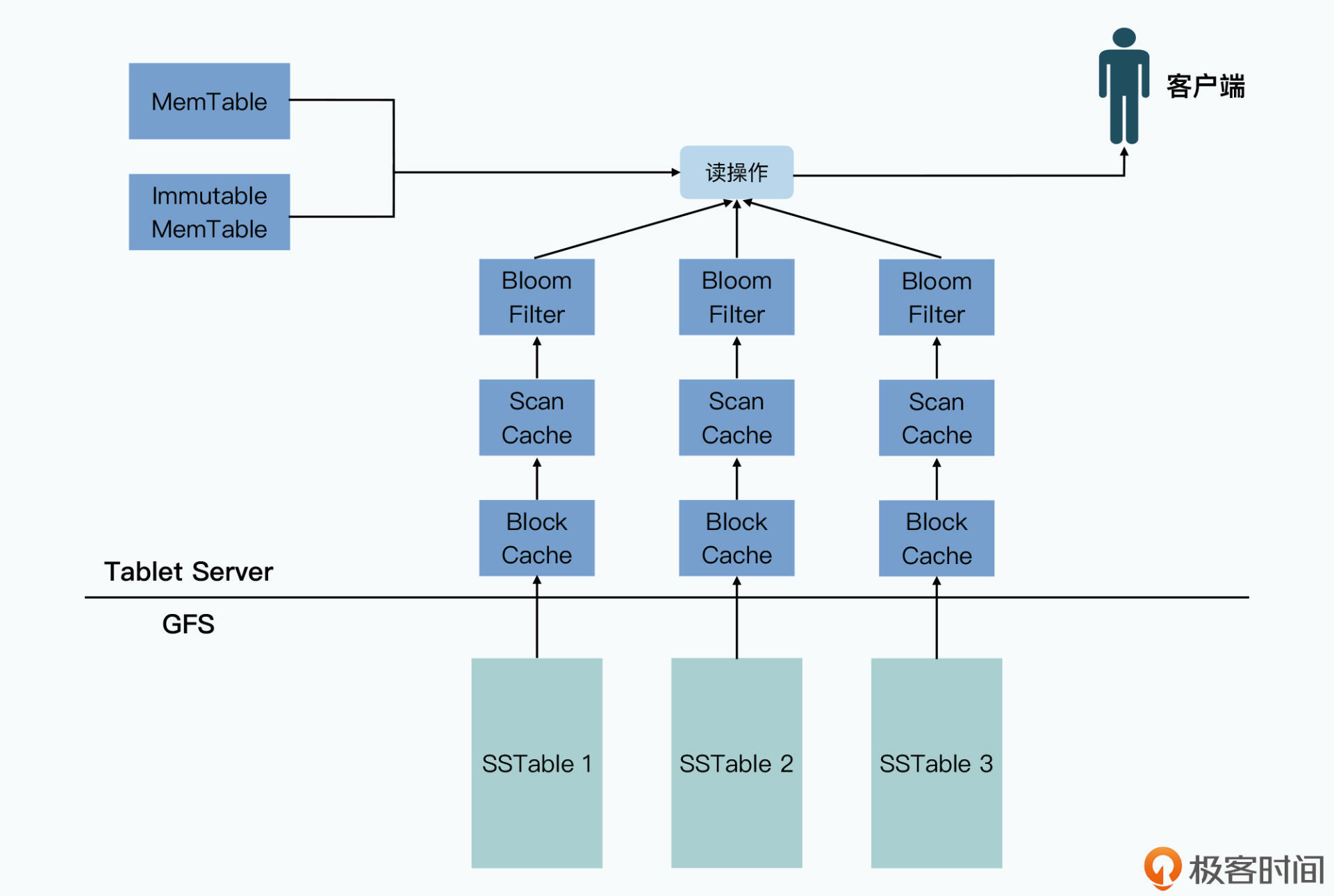
好了,到这里Bigtable论文的核心内容我们就复习完了。Bigtable主要有两个特点,第一个是具备良好的可运维性,服务器支持动态伸缩,数据分区支持动态划分,所有的服务出现故障后,在一定程度内都能自动恢复。第二个是能够支撑每秒百万级别的随机读写,主要的方法有两个,一是把随机写变成顺序写,二是尽可能从内存中读。
徐老师在 09 和 10讲都推荐了《数据密集型应用系统设计》这本书,如果你还没有开始阅读的话,我强烈建议你读起来。最近一有空我就会拿起这本书翻一翻,对于理解课程内容和拓展数据系统的知识非常有帮助,你也可以参考看看。