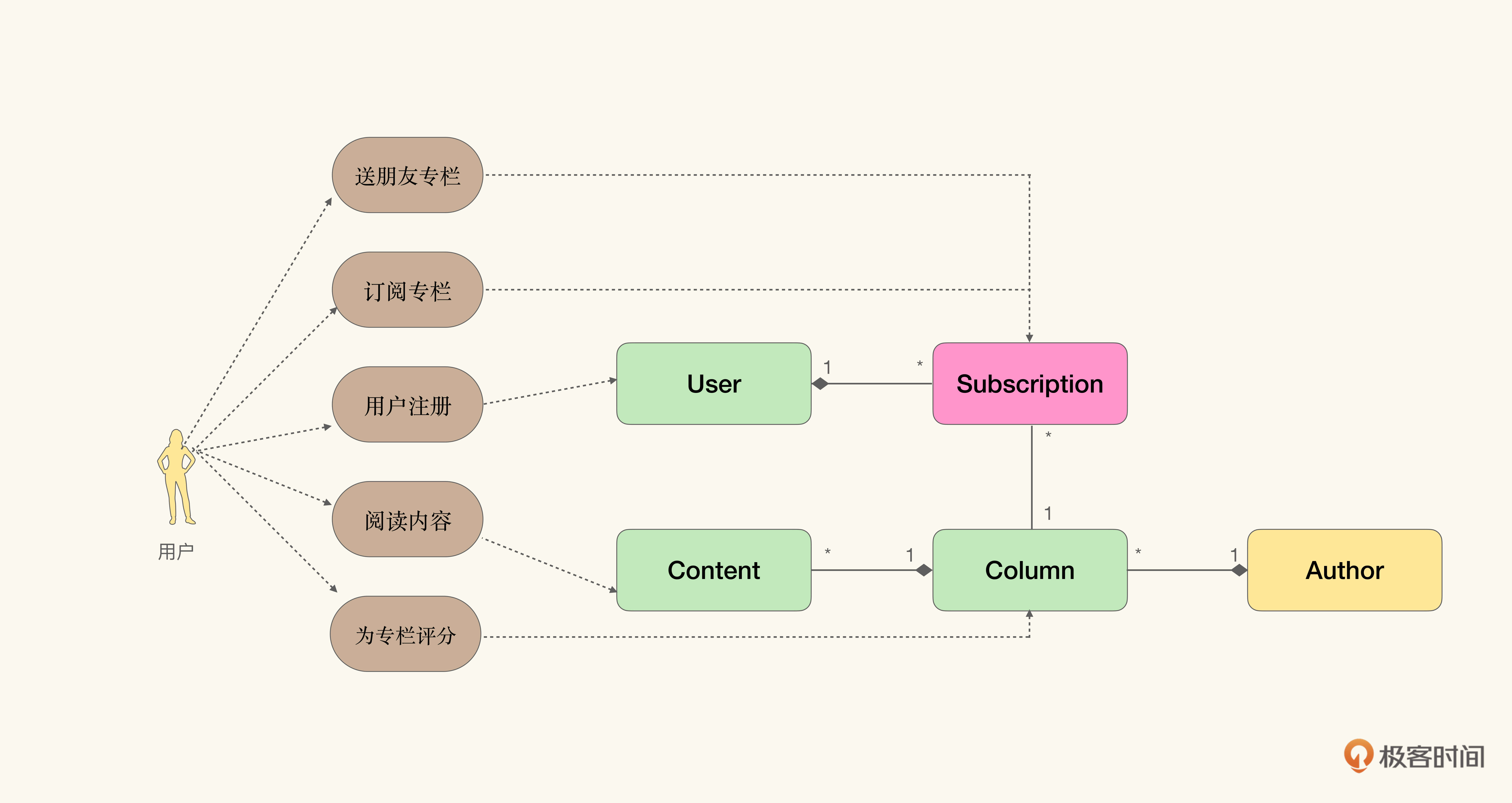
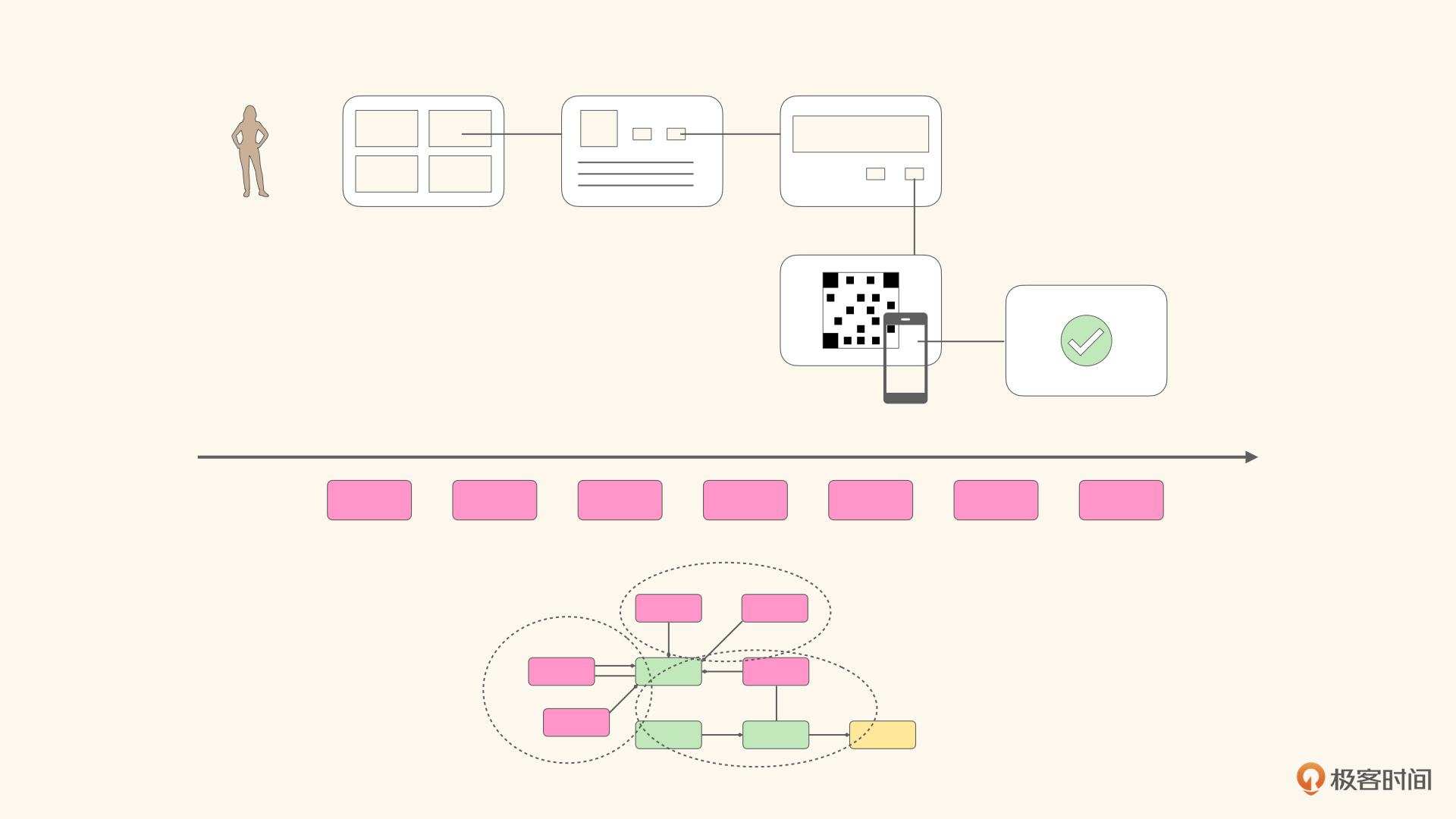
或许对于简单的流程来说,催化剂方法已经足够了。但如果订阅专栏流程本身就包含很多步骤,那么展开的信息就不足以帮助业务方作出有益的决定了。如下图所示的流程,就是从专栏列表中挑选心仪专栏,查看详情后通过手机购买的过程。
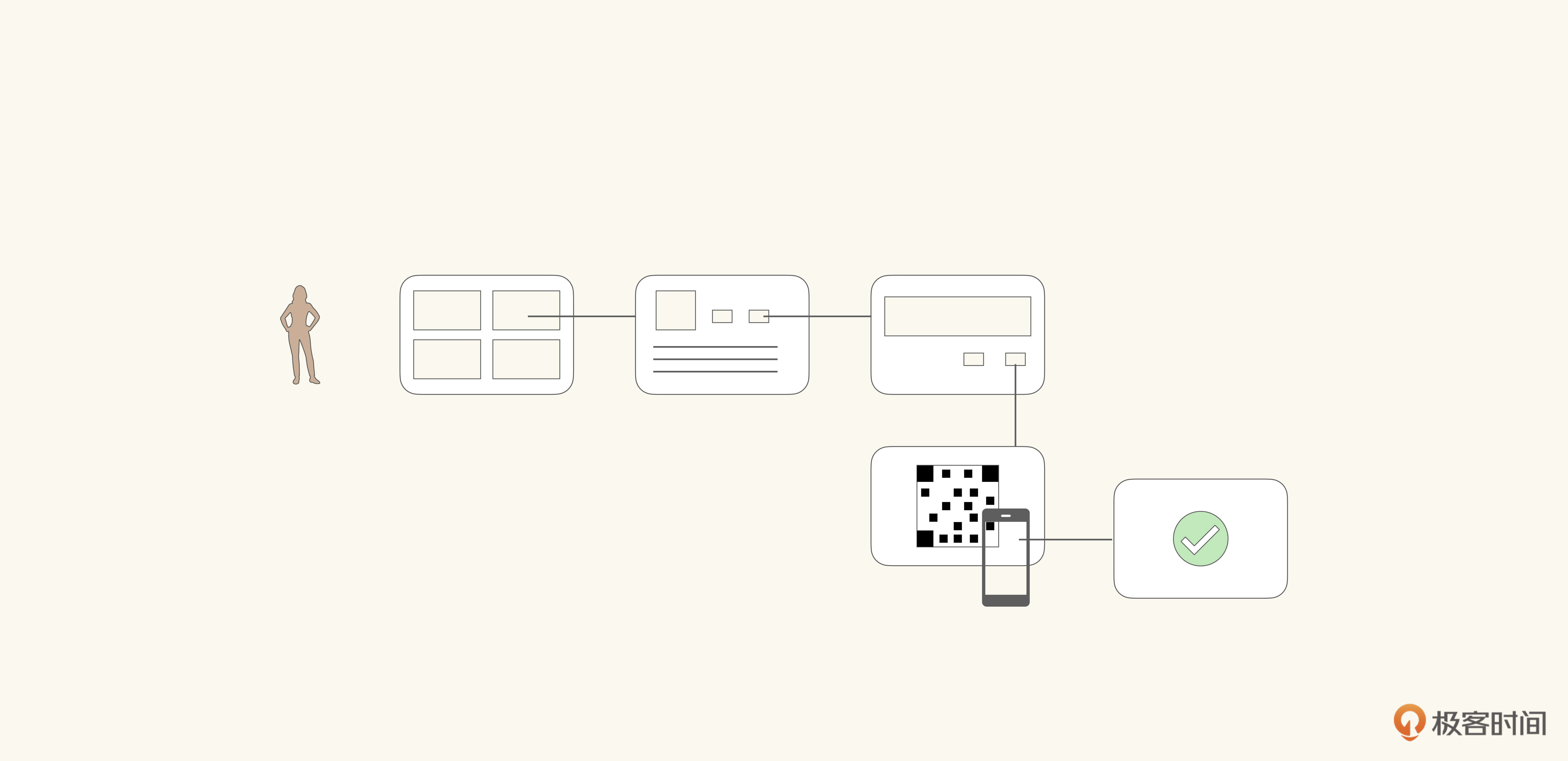
那你肯定会有疑问了。如果只有一个交互对象,业务方仍然不知道在具体的步骤中,接触到了哪些领域模型,以及在具体的步骤中,领域模型所包含的信息是否能够支撑业务的实现。那么我们要怎样展开业务流程,才能让它以恰当的粒度自然地融入领域模型呢?
你好,我是徐昊。今天我们来聊聊事件建模法(Event-based modeling)。
对于大多数人而言,业务建模中最难的一步并不是获得模型,而是说服业务方接受模型作为统一语言。虽然我们上节课讲到可以把角色-目标-实体法当作一种共创方法,但在实际操作的过程中,角色-目标-实体法仍然存在收集-建模-说服这三步。那么,有没有一种方法,可以在讨论的过程中更自然地完成模型共创呢?
答案是肯定的。事件建模法就是这样一种更易于模型共创的方法。不同于原味面向对象范式关注实体之间的关联与交互,事件建模法通过事件捕捉系统中信息的改变,再发掘触发这些改变的源头,然后通过这些源头发现背后参与的实体与操作,最终完成对系统的建模。
目前有两种比较有代表性的事件建模法,一种是目前DDD社区热捧的事件风暴法(Event Storming),另一种是我从Peter Coad的彩色建模中演化出的四色建模法。这节课我们先来学习事件风暴法,下节课我再展开讲解四色建模法。
不过在学习这两种具体的建模方法之前,我们有必要先了解事件建模法的两个基本原则,分别是通过事件表示交互和通过时间线划分不同事件。
在催化剂方法中,我们将交互直接以对象的形式引入到了领域模型中。这虽然在一定程度上展开了隐藏在领域模型中的业务维度,但是在多数情况下,结果的粒度仍嫌太粗。这也是为什么催化剂方法只能用于简单项目,或是项目的初始阶段。
而且随着项目的深入进行,它能提供的信息就变得相当有限了。我们回顾一下之前的催化剂模型,订阅专栏这个流程被表示为了一个交互对象。
或许对于简单的流程来说,催化剂方法已经足够了。但如果订阅专栏流程本身就包含很多步骤,那么展开的信息就不足以帮助业务方作出有益的决定了。如下图所示的流程,就是从专栏列表中挑选心仪专栏,查看详情后通过手机购买的过程。
那你肯定会有疑问了。如果只有一个交互对象,业务方仍然不知道在具体的步骤中,接触到了哪些领域模型,以及在具体的步骤中,领域模型所包含的信息是否能够支撑业务的实现。那么我们要怎样展开业务流程,才能让它以恰当的粒度自然地融入领域模型呢?
这里的难点有两个:第一个是恰当的粒度;第二个是融入领域模型。毕竟我们上节课已经讲过了,对于催化剂方法的一大诟病就是交互的对象难以直接与软件实现关联。
我们先来解决第二个问题,因为第一个问题的解法与它有关。第二个问题的核心困难在于该如何通过对象模型表达流程。如前面所讲,模型偏重于数据角度,描述了在不同业务维度下,数据将会如何改变,以及如何支撑对应的计算与统计。而业务维度中的流程、交互、功能点,则更关注行为。
那我们该怎么弥合数据与行为之间的差异呢?事件(Event)是一种行之有效的办法。
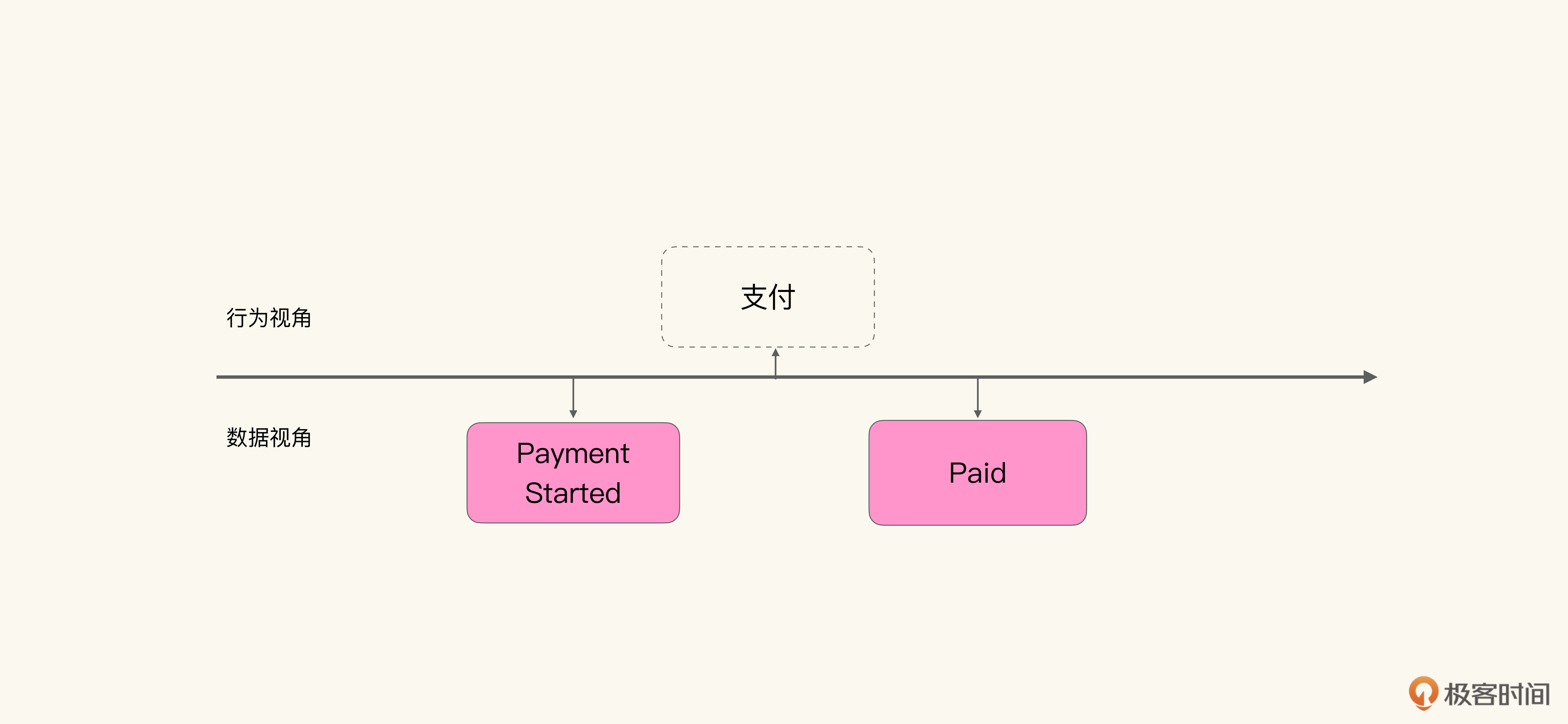
我们可以把事件看作行为的印记。比如支付这个行为。我们不需要直接描述支付这个行为,而是通过捕捉这个行为前后的事件:支付发起(Payment Started)和支付完成(Paid)。要知道,事件自身能表达的含义有限,但是将一系列事件按照发生顺序排列起来,就能还原发生过的行为。
因而事件发生的时间点就是事件最重要的属性。我们会在模型中画一条时间轴,并依据事件发生的时间点,按先后顺序将事件标记在时间轴上。这样的话,一前一后成对出现的支付发起与支付完成,就暗示着在两个事件之间,存在一个成功的支付行为:
接下来就可以根据事件去寻找背后的领域模型了。根据我自己的经验,我们可以按照记叙文六要素去想:时间、地点、人物、起因、经过和结果。
比如上面支付这个例子:
当我们再补全模型之间的关联,就能得到这样一个更完整的模型了:
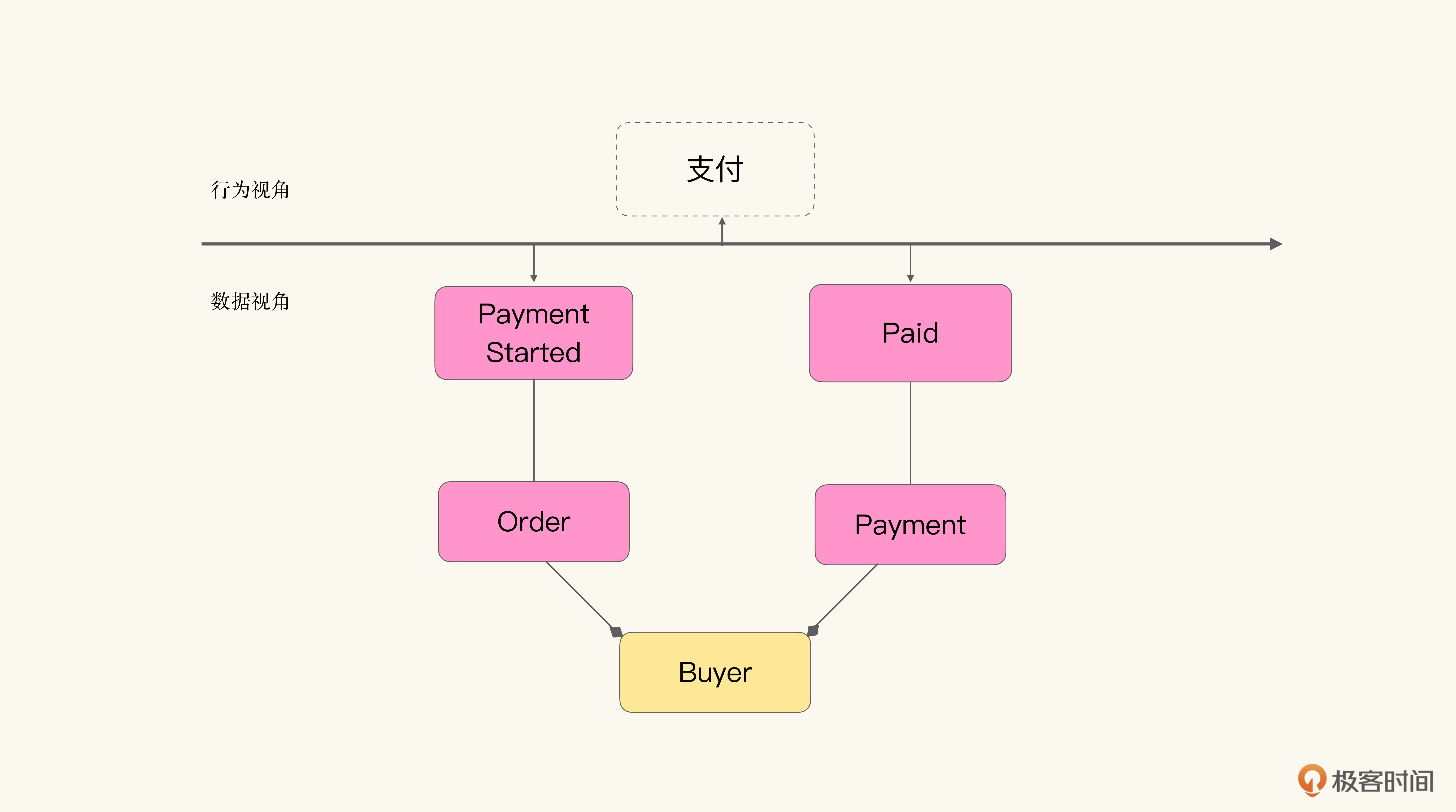
那么我们只需要根据交互流程或者是业务流程,寻找出对应的事件,并以事件为指引,就能找到事件背后的领域模型了。下面是一个示意图,表明这个过程和结果。
通过这个例子,我们可以看到事件建模法与其他面向对象建模法的差别,这些差异带来了三个优点。也正是这三个优点,使得事件建模法更容易与业务方完成模型共创。
第一,虽然看起来多出了一个额外的寻找事件环节,但对于大多数项目而言,建立业务流程或交互流程都是必需的。如果是从头开始的绿地项目(Greenfield),就需要建立流程以明确需求;如果是存量项目,从流程开始梳理功能也是必备的步骤。
那么在梳理流程的同时发现事件,或者是直接通过事件描述流程,都是惠而不费的操作。顺便说一句,目前更常见的做法是直接通过事件描述流程。这种做法也是一种预热,让业务方可以提前适应从数据角度来描述流程。
第二,通过记叙文六要素去寻找领域概念,很自然地就关联了业务维度,提高了业务方对统一语言的接受度。当我们按照“时间、地点、人物、起因、经过、结果”还原“领域情节”,从中去寻找业务概念的时候,这些业务概念很自然地就连带了业务的维度。
毕竟我们的大脑善于记忆情节,如果某个概念出现在有情节的场景中,那么我们的大脑不光会记住这个概念,还会记住与这个概念相关的情节。当我们回想或是再听到这个概念时,就会下意识地回忆起相关的情节。
那么对于通过领域情节获取的领域概念,业务方不光会记住领域概念,也会记住领域情节。这种连带记忆,让我们很自然地把业务维度展开到了模型里。
第三,事件建模对于最终得到的领域模型并没有什么额外的限制,不会因为我们使用了事件建模法,就得到奇怪的模型。它只是一种更自然地发现领域概念的方式。而领域概念与领域逻辑的组织,还是交由建模者自行掌控。
通过事件的记叙性,我们已经将流程性的业务维度在模型中展开了。但是如果事无巨细地将所有交互都转化为事件,那么对模型似乎会有较大的干扰。这也是我们之前提到的问题,到底怎么才能找到合适的粒度将业务维度展开到领域模型中?
事件建模法有一个巧妙的办法解决了这个问题:引入多条时间线。一种常见的做法是,引入一条名叫领域事件的时间线,其上发生的都是对领域模型有重要意义和影响的事件。那么之前的时间线也就相应地被称作交互事件时间线:
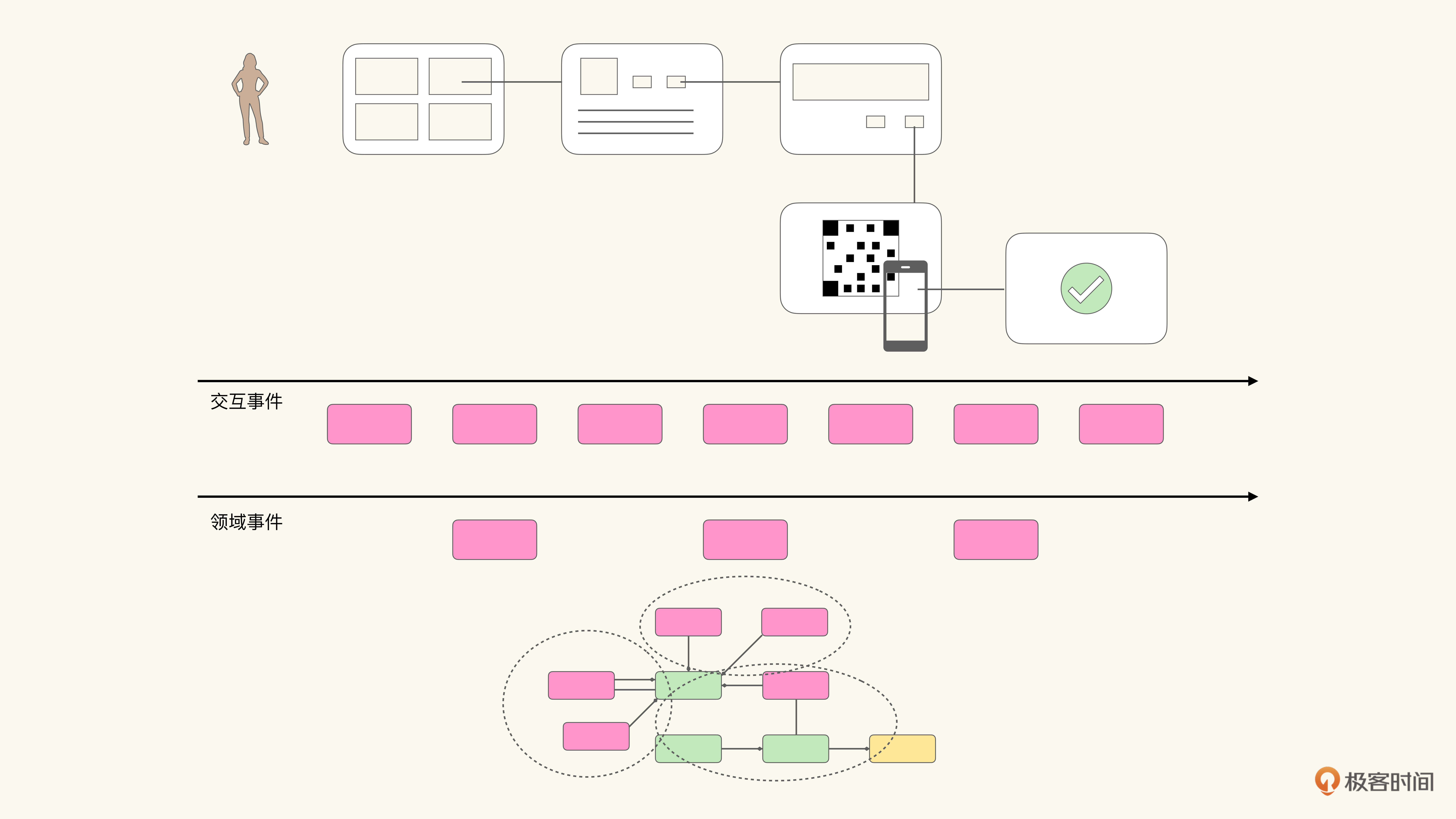
交互事件我们很容易理解,也就是通过交互流程产生的事件,那么什么是领域事件呢?领域事件其实指的就是发生在领域中且值得注意的事件。而领域事件通常意味着领域对象状态的改变,因此这也是我们判断一个事件是否是领域事件的重要依据。能引起领域对象变更的就是领域事件,否则就是交互事件。
比如前面例子的两个事件:支付发起和支付完成。支付发起不会引起领域对象的变更,而支付完成则意味着会增加一个支付凭证。那么如果在这两个事件中去区分的话,我们更有理由选择支付完成作为一个领域事件,而将支付发起看作交互事件。
还有一个办法也可以用来判断某个事件是否是领域事件,就是能否将这个事件看作某个领域逻辑的等价接口。如果我们把订单上下文和支付上下文单拿出来看:
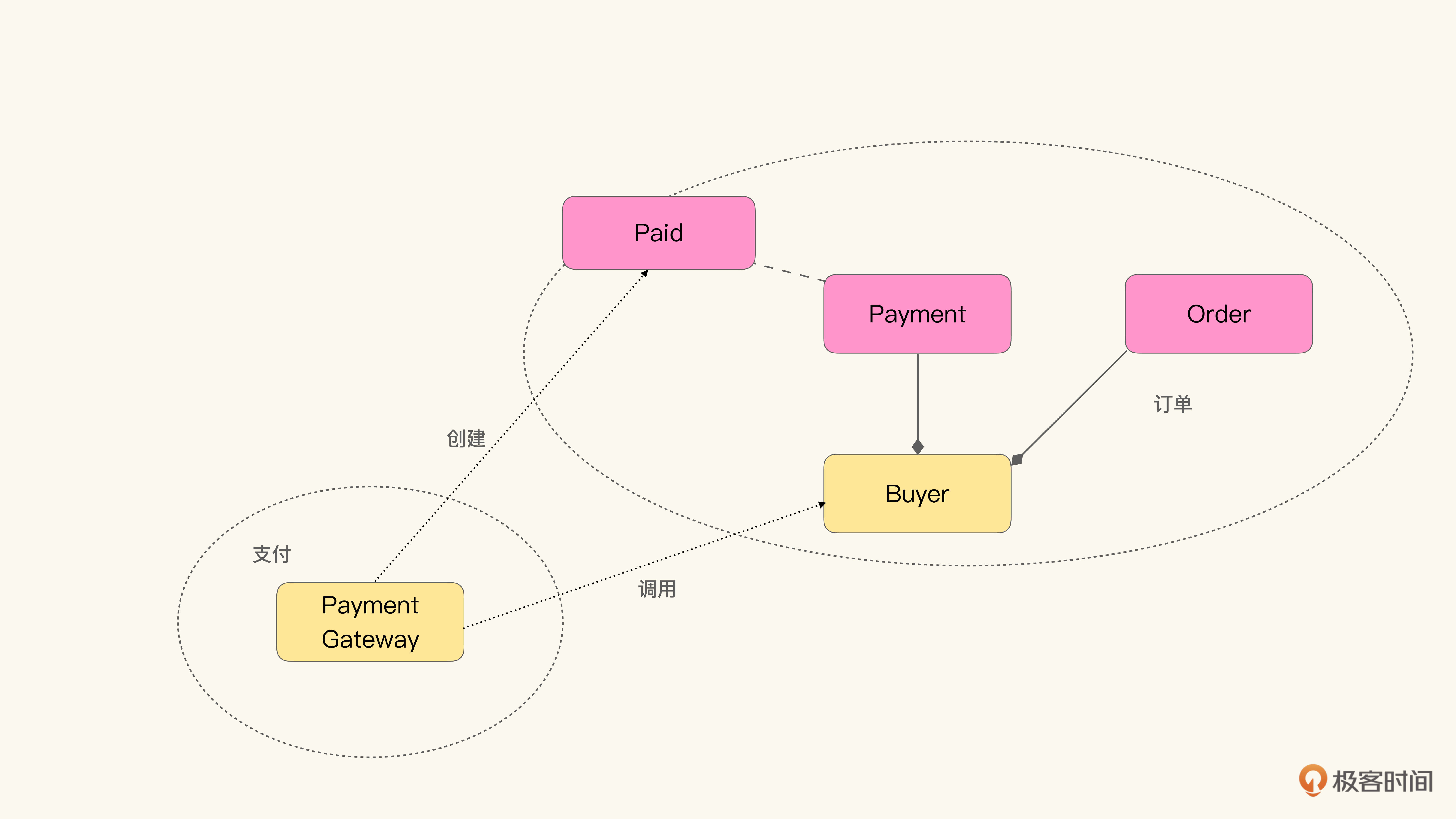
当支付完成的时候,支付网关希望通知订单上下文构建支付凭证。因为支付凭证(Payment)被角色买家(Buyer)聚合,那么支付网关需要调用Buyer的逻辑构建凭证。而如果把订单上下文当作一个整体,还可以发送事件支付完成(Paid)到订单上下文,通知订单上下文构建支付凭证。这时发到上下文上的事件就和聚合根的行为接口等价了。因而可以起到这种等价作用的事件,就是领域事件。
按照这两个办法过滤出的领域事件,在逻辑上就是一个恰当的粒度,可以帮助我们将业务中的流程维度在领域模型上展开。
除了能够划分交互事件与领域事件之外,我们还可以通过引入时间线帮助我们细化事件与上下文的关系,这是一种很有效的建模技巧。特别是当涉及跨多子域协同的时候,按子域分离时间线可以帮助我们更好地理解子域间的交互:
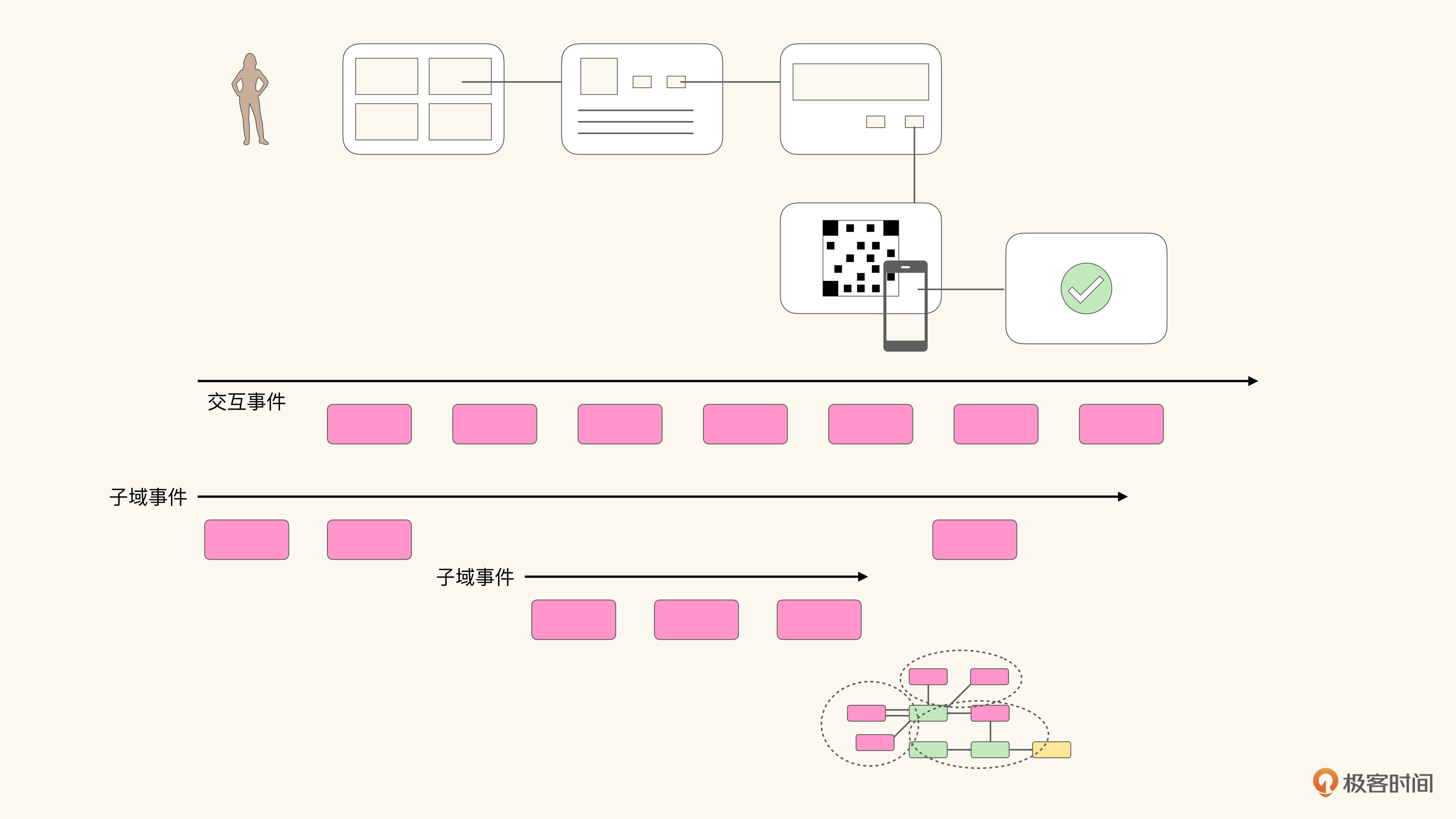
凡可归类为事件建模的建模方法在底层逻辑上都是类似的,都是通过寻找事件,以及事件背后的领域概念,完成对领域概念的挖掘和建模。
不同方法之间的差异就在于两点:以何种逻辑发现事件;事件如何与模型结合。抓住了这两点差异,我们就能很好地理解不同的事件建模法了。事件建模法是一种元方法(Meta Methodology),当你熟练使用之后,可以根据业务需要发明自己的方法。当然在那之前,你还需要参考学习别人是如何使用事件建模的,然后来构造自己的建模法。
接下来,我们就看一下事件风暴法(Event Storming)。它是目前最为流行的事件建模法了。请你着重体会我刚才说的这两点差异,看看它是以何种逻辑发现事件的,事件又是如何与模型结合的。
事件风暴是意大利人Alberto Brandolini在2012年创造的一种事件建模方法。在形式上,事件风暴是一种互动式建模工作坊,通过将不同背景的项目参与方汇聚一堂,集思广益,从而形成有效的模型。这也是事件风暴名称的由来——因为它本质上就是一种头脑风暴(Brainstorming),按照欧美人士习惯的俏皮式命名法,将头脑(Brain)改成其建模法的关键元素事件(Event)从而得名。
从建模方法上来看,事件风暴是一种事件建模法。它以响应式编程(Reactive Programming)作为范式,通过事件、命令与策略之间的响应关系,组织逻辑。事件风暴内各主要概念的相互关联如下图所示:
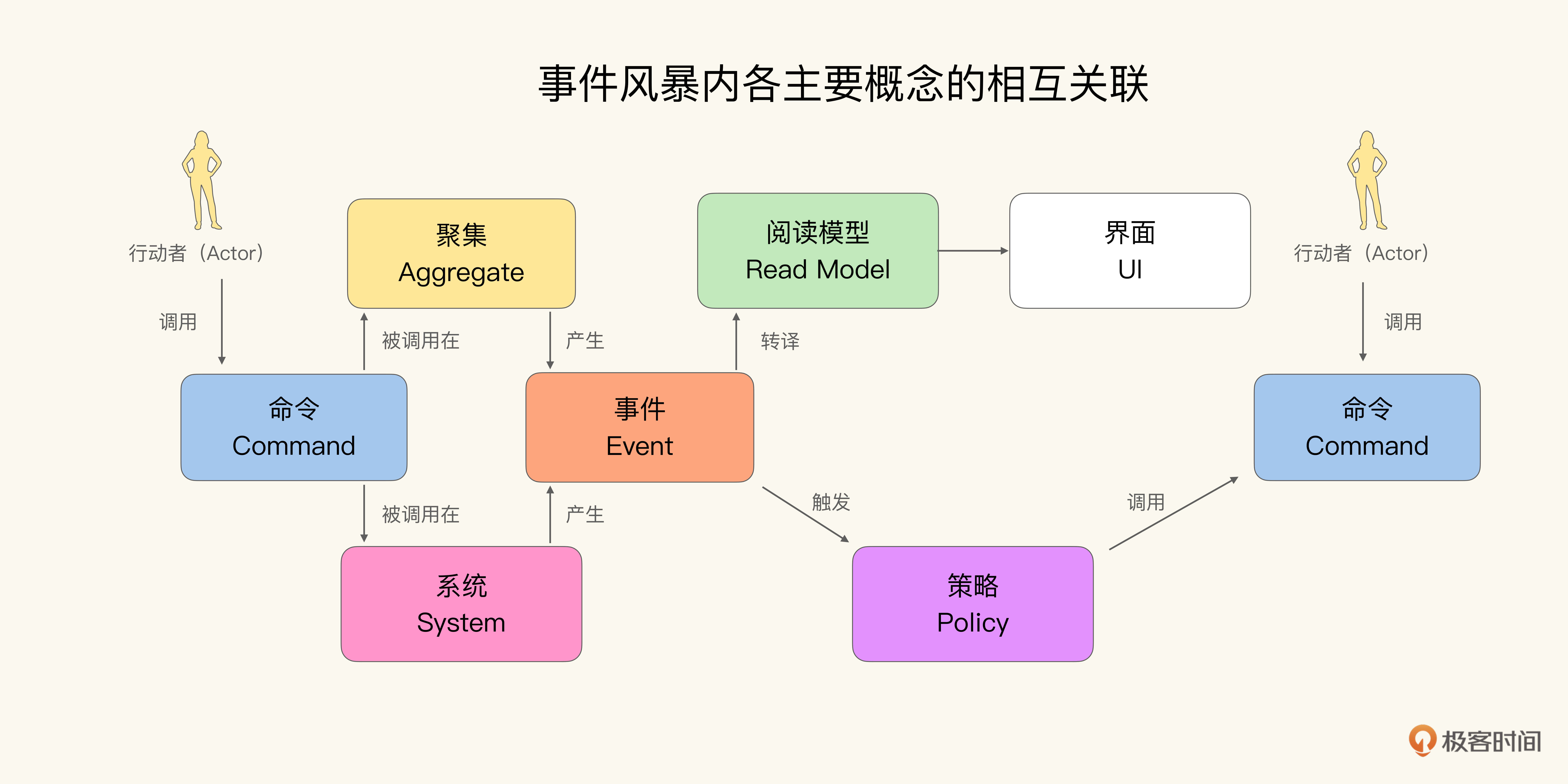
乍一看这张图里有很多概念,大部分应该可以望文生义,但为了明晰概念,我还是解释一下:
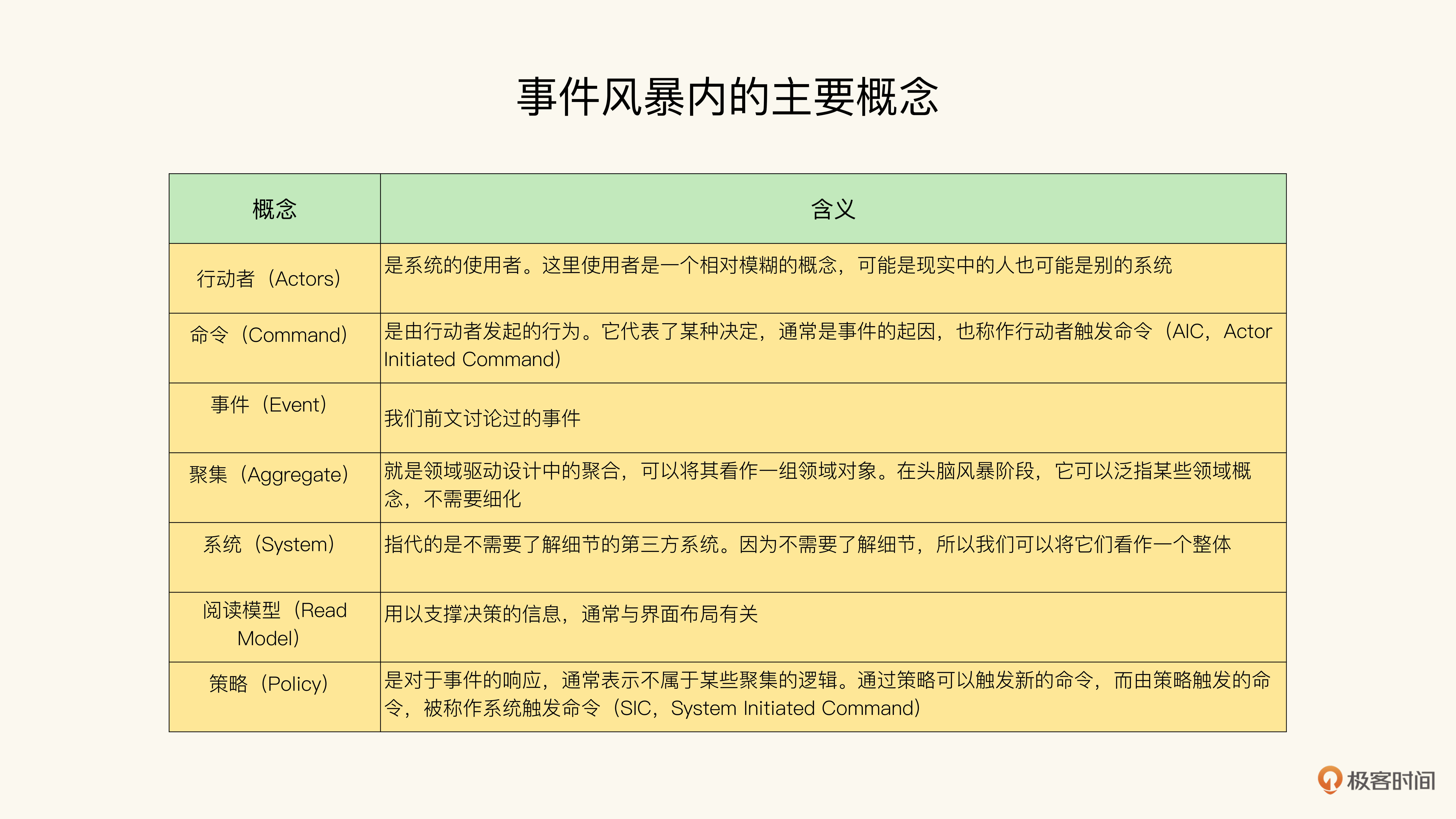
对于图中如此多的颜色我也要多说一句,事件风暴法是一种头脑风暴的形式,头脑风暴自然离不开3M便条纸(Post-It)。而我们尽可能多地通过色彩的维度来表示不同概念,是头脑风暴的一个窍门。因此,事件风暴法推荐使用7种不同的颜色,来表示这7个不同的概念。
事件风暴建模的整体流程是这样的:
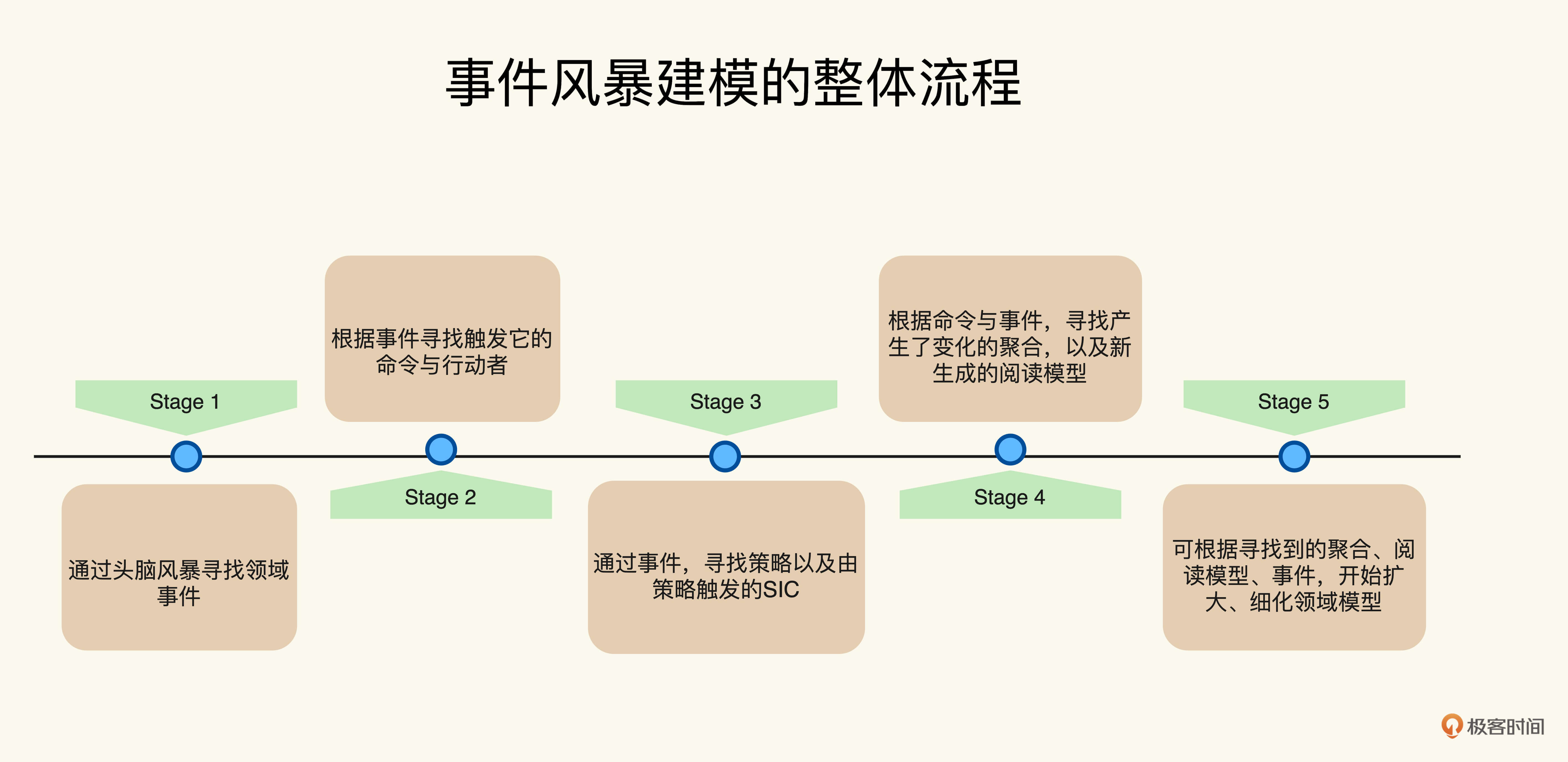
可以看到,事件风暴法的建模流程遵循事件建模的大体框架,它的特点就在于通过头脑风暴发现事件,再依赖触发与响应寻找事件间的关系,通过聚合与阅读模型寻找领域模型。下面让我们仍然以极客时间专栏订阅为例,展示一下事件风暴建模法的大致过程。
我们的场景是这样的:用户发现了想看的内容,但是因为没有订阅专栏看不了,于是下单订阅专栏,完成支付之后,再次访问之前内容,就能看到了。
首先我们从事件入手,根据上面的流程,很容易就能通过头脑风暴得到关键的领域事件:内容请求(Content Requested)、访问拒绝(Access Denied)、订单确认(Order Placed)、订单支付(Order Paid)、内容被访问(Content Viewed)。
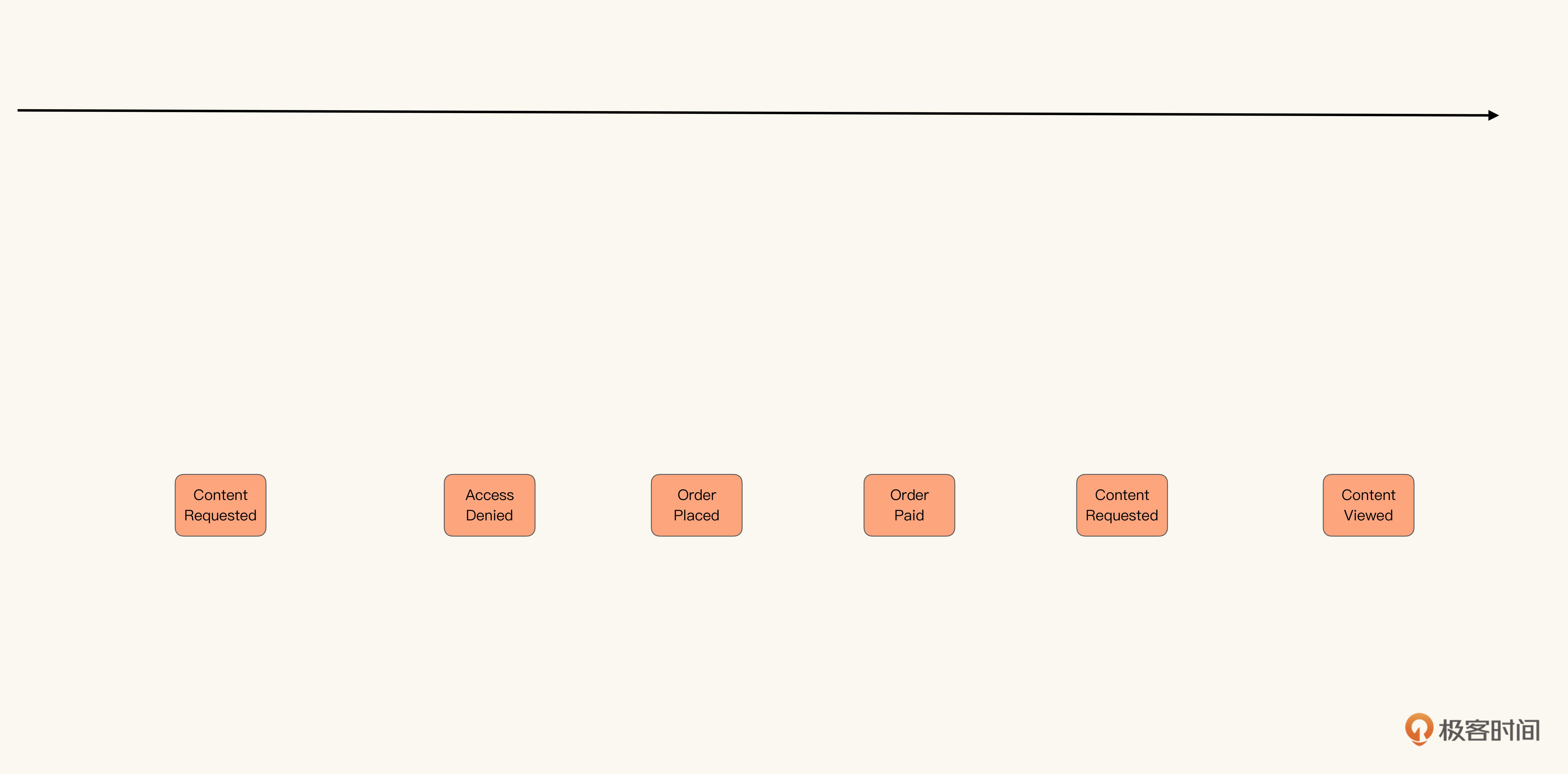
这里我们不难发现一个规律,事件都是以“名词 + 动词被动式”表示的。在寻找到事件之后,我们需要判断哪些是AIC,哪些是SIC。AIC由命令触发,而SIC则由策略触发。在上面这些事件里,访问拒绝和内容被访问是SIC,其他都是AIC。我们可以根据这个,寻找到它们各自对应的触发源:
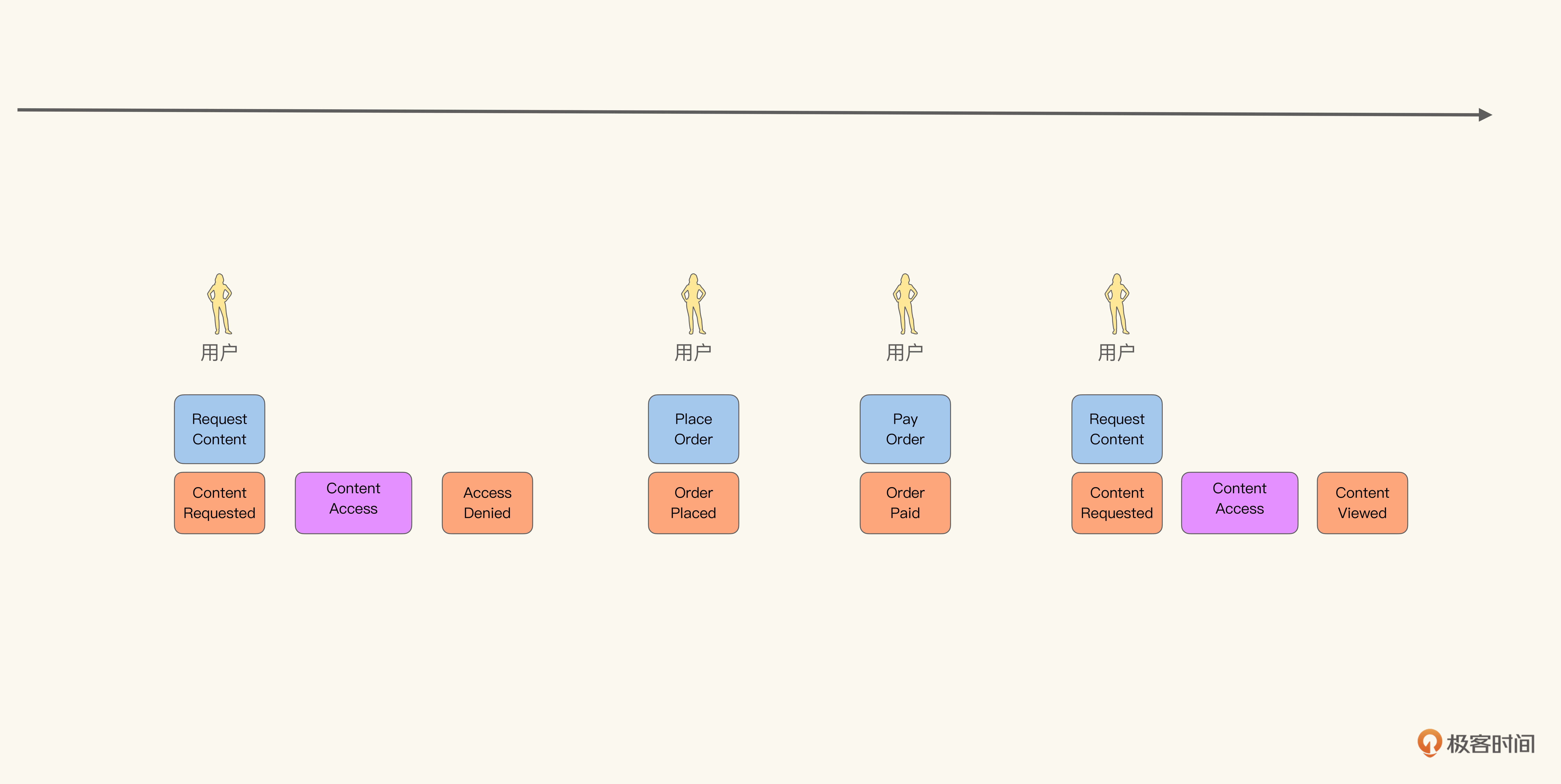
你会发现,命令的命名与事件正好相反,是“动词 + 名词”以表示对应事件的源头。策略的命名则按对应的业务逻辑命名即可。在这里我们称之为内容访问策略(Content Access Policy)。
确定了事件的源头,我们就可以开始寻找事件发生过程中,访问了哪些聚集,事件完成后生成了哪些阅读模型。
聚集在当前阶段并不需要细化为具体对象,可以泛指与某些功能有关的领域概念集合。比如在Pay Order-Order Paid这一组命令与事件中,我们可以知道它一定访问并修改了与订单(Order)相关的领域概念,那我们可以使用聚集Order泛指这些概念,而无须细化。
这个过程并不一定需要按照顺序,哪些事件对应的聚集比较明显,就可以先从它们入手。比如在上图中,与内容访问策略相关的阅读模型并不是非常明显,那不如先不考虑它,而是从其他更容易得出结论的部分入手:
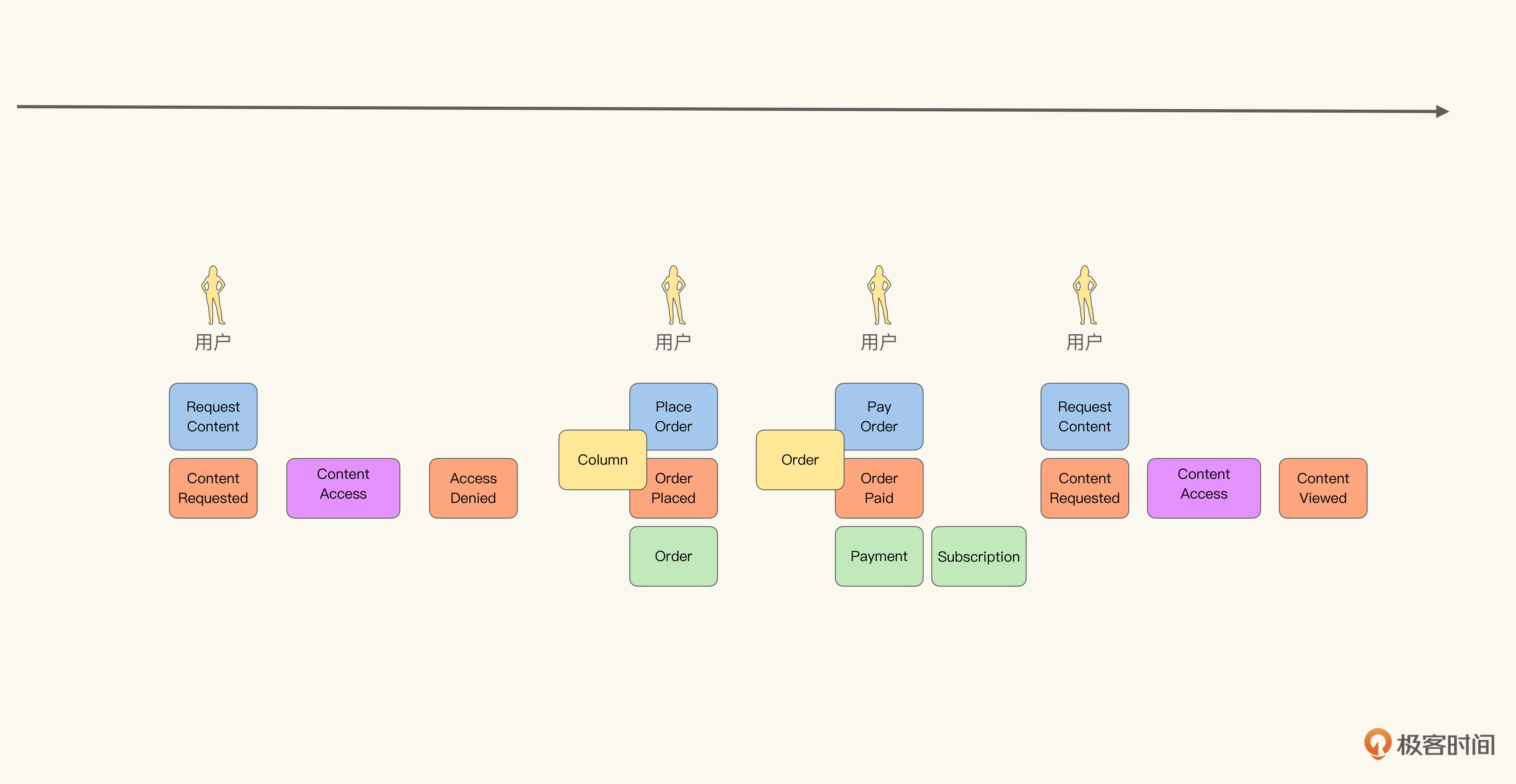
Place Order-Order Placed 产生的阅读模型是订单(Order),Pay Order-Order Paid产生的阅读模型是订阅(Subscription)和支付(Payment)。这里我们会发现阅读模型与聚合有重合的地方。订单在Pay Order-Order Paid中成了聚合,而在Place Order-Order Placed里成了阅读模型。
阅读模型是比聚合更为宽泛的概念,可以看作聚合的超集。它既可以是聚合,也可以是为特定界面或报表生成的特定数据信息。这种做法是随着NoSQL(Not Only SQL)兴起的一种反思——命令与查询职责分离(CQRS,Command Query Responsibility Separation)。
那么写入数据(Command)与查询数据(Query)一定要用同一个模型吗?原味面向对象的回答:是,应该一样。而越来越多的实践者则发现,分开可能更好。毕竟两者对于逻辑一致性的诉求不同,分开处理能得到更好的结果。因此在事件风暴建模法中,阅读模型是包含写入与查询的所有数据形态的总集,而聚合只是阅读模型中符合对象风格的子集。
当我们找到一些阅读模型后,再回过头去看之前留白不易处理的部分,就豁然开朗了。内容访问策略需要使用订阅阅读模型,决定了哪些内容对哪些用户可见:
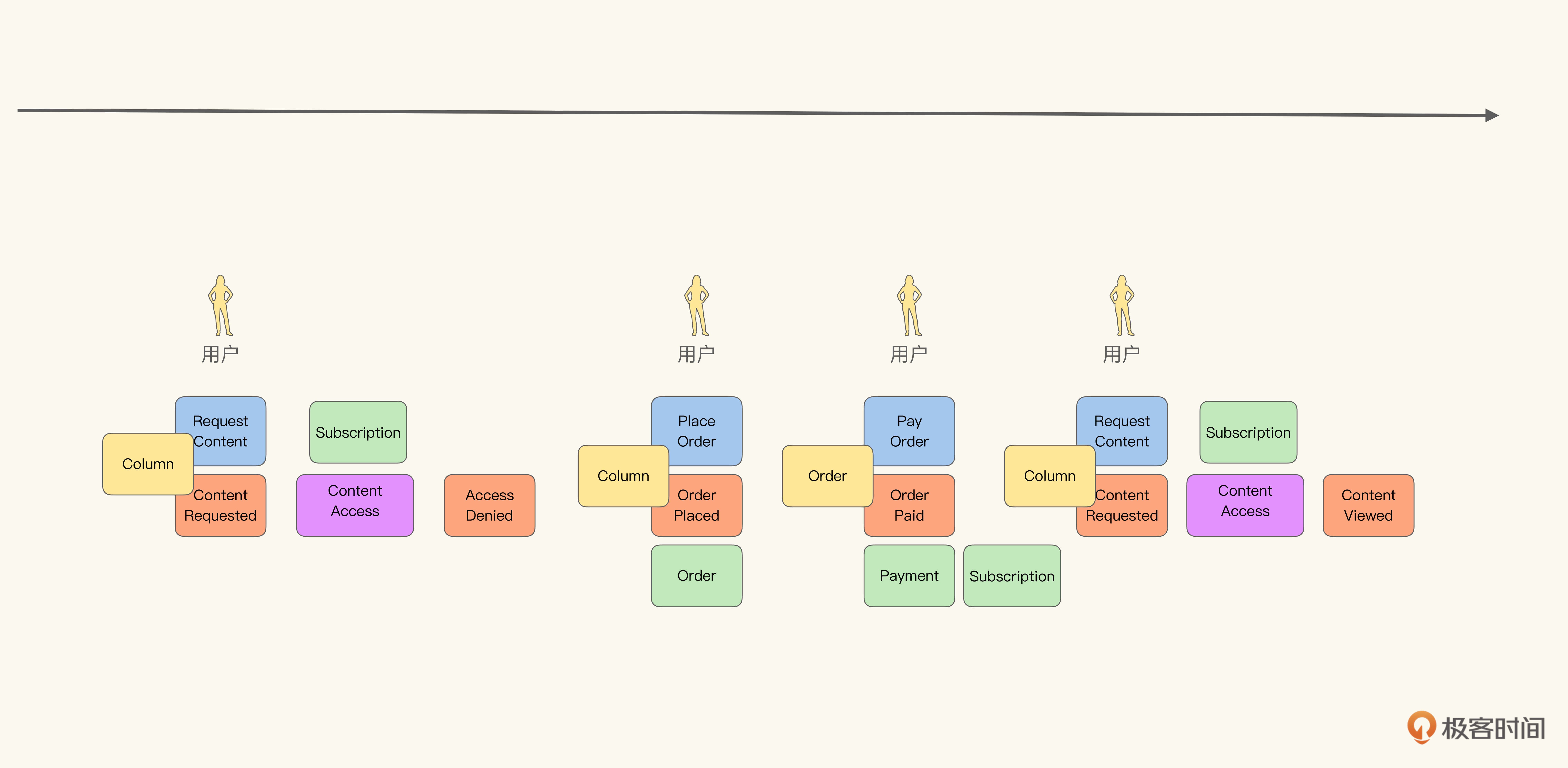
在获取了聚合和阅读模型之后,我们就可以开始细化领域模型了。这时候方法与原味对象方法就没有什么不同了,我就不再赘述了。
通过这个简单的例子,相信你对事件风暴法的基本流程已经有所了解了:它通过头脑风暴发现领域事件,以“对于事件的响应”为主要维度寻找事件间的关联;它通过阅读模型和聚集发现事件与领域模型之间的关联。不难发现,事件风暴法是一种简单明快的事件建模方法。
编辑小提示:为了方便读者间的交流学习,我们建立了微信读者群。想要加入的同学,戳此加入“如何落地业务建模”交流群>>>
这节课我们先讲述了事件建模法作为一类方法的共同性质,也就是通过事件表示行为,再根据事件顺序去组织业务逻辑。并总结了这么做的好处:通过记述性描述发掘需求,不知不觉间构造领域模型,并完成统一语言。
之后我们以事件风暴法为例子,看到了这些原则在具体方法中是如何应用的。那么下一节中,我们来讲解另外一种事件建模法——四色建模法,在那之前我希望你思考以下问题。
事件的表现形式只能是事件吗?既有事件又存在阅读模型不是一种冗余吗?除了“事件-响应”外,还有什么办法可以展开维度?

欢迎把你的思考和想法分享在留言区,我会和你交流讨论。同时,我也会把其中不错的回答进行置顶。我们下节课再见!
评论