
你好,我是轩脉刃。
上一节课,我们改造框架让它支持命令行工具了。这样业务开发者可以使用框架定义好的命令行工具来执行框架预设的一些行为,比如启动一个Web服务,也可以自己定义业务需要的命令行工具来执行业务行为,非常方便。
今天继续思考如何优化,因为业务在开发过程中,不可能每个命令都要手动操作,定时执行某个命令的需求应该是非常普遍的。比如设计一个定时扫描数据命令来发送统计报告,或者设计一个定时删除某些过期数据的命令。
那我们的框架是否能支持这个需求,如果要开发一个定时命令,能不能做到在业务中增加一行代码就行了?这节课我们就来挑战这个目标。
怎么做到计时执行这个事情呢?Golang有个标准库time,里面提供一个计时器timer的结构,是否可以使用这个timer来执行呢?我们先来看看timer是怎么使用的:
func main() {
timer := time.NewTimer(3 * time.Second) // 定一个计时器,3s后触发
select {
now <-timer.C: // 监听计时器中的事件
fmt.Println("3秒执行任务, 现在时间", now) //3s后执行
}
}
首先time.NewTimer会初始化一个计时器,这个计时器到定时时间后,就从C这个channel中返回一个时间Time。逻辑很简单。所以我们的main函数只需要监听timer.C这个channel,一旦有时间从这个channel中出来,就说明到计时器时间了。
知道如何定时执行了,接下来得结合实际业务场景考虑会存在什么问题了:如果有一堆定时任务,要怎么定时执行呢?
这个也难不倒我们:遍历所有的定时任务,计算出这些定时任务下一次要执行的时间,然后按照从近到远排序,用timer来设置一个定时器到最近的时间触发,然后等计时一到,开启一个Goroutine触发执行。触发之后再进行一轮计算,计算出所有定时任务下一次要执行的时间,再初始化一个定时器。
写一下大致的伪代码如下。
// Entity代表每个定时任务
entries := []Entry
// 计算每个定时任务时间
for _, entry := entries {
entry.Next = next(entry)
}
for {
// 根据Next时间排序
sortByTime(entries)
// 创建计时器
timer = time.NewTimer(entries.Early.Sub(time.Now()))
select {
case now = <-timer.C:
for _, entry := entries {
// 对已经到了时间的任务,执行
if entry.Next.Ok() {
go startJob(entry)
}
// 所有任务重新计算下个timer
entry.Next = next(entry)
}
}
}
其实我们刚才对定时执行任务的分析,就是开源定时执行库 cron 的核心实现。
cron库的作者 robfig 是一名资深的Golang开源贡献者,他最出名的两个作品cron库和Revel框架目前已经分别有了8.4k和12.4k的star数。cron库的Licence是基于MIT的,允许商用、允许私有化,目前最新的稳定版本为v3。
cron库可以实现多个定时任务的执行功能,核心原理正如刚才讲的那样,底层也是使用timer来进行每个定时任务的计算,但是细节实现远不止这些。我们看它的用法就能感受出来:
// 创建一个cron实例
c := cron.New()
// 每整点30分钟执行一次
c.AddFunc("30 * * * *", func() {
fmt.Println("Every hour on the half hour")
})
// 上午3-6点,下午8-11点的30分钟执行
c.AddFunc("30 3-6,20-23 * * *", func() {
fmt.Println(".. in the range 3-6am, 8-11pm")
})
// 东京时间4:30执行一次
c.AddFunc("CRON_TZ=Asia/Tokyo 30 04 * * *", func() {
fmt.Println("Runs at 04:30 Tokyo time every day")
})
// 从现在开始每小时执行一次
c.AddFunc("@hourly", func() {
fmt.Println("Every hour, starting an hour from now")
})
// 从现在开始,每一个半小时执行一次
c.AddFunc("@every 1h30m", func() {
fmt.Println("Every hour thirty, starting an hour thirty from now")
})
// 启动cron
c.Start()
...
// 在cron运行过程中增加任务
c.AddFunc("@daily", func() { fmt.Println("Every day") })
..
// 查看运行中的任务
inspect(c.Entries())
..
// 停止cron的运行,优雅停止,所有正在运行中的任务不会停止。
c.Stop()
这个例子充分展示了这个库的能力。
首先,它具有极其丰富的“时间描述语言”。我们可以通过和Linux的crontab一样的语法,定义五个星号来表示在一天中的某个时间点,时间点的维度可以是分钟、小时、日、月、星期,也可以将这五个星号替换为不同维度的值或者范围。前两个例子就很好地展示了在每小时30分的时候,和在上午3-6点、下午8-11点的每30分钟的时候执行的方法。
而第三个例子,它定义了日本东京时区的某个时间点来执行,这个已经超出了Linux的crontab能力了。看第四、五个例子,它还能通过符号@ 和非常语义化的hourly、every 1h30m 的描述语句,来表示从现在开始的时间计算。
或许你会好奇这种神奇的时间描述语言是怎么实现的?可以看cron源码的parser.go文件。它的本质就是将字符串解析成为一个包含秒、分、小时等时间数据的结构SpecSchedule。看下面的部分源码:(不是今天的重点,就不解释具体的字符串解析步骤了,有兴趣的同学可以自行查看完整源码)
// 用来表示调度时间的一个结构
type SpecSchedule struct {
// Dom表示dayOfMonth,每个月的第几天
// Dow表示dayOfWeek,每个星期的第几天
Second, Minute, Hour, Dom, Month, Dow uint64
// 时区
Location *time.Location
}
你会发现SpecSchedule 中有秒的时间字段,是的,这是我想介绍这个库的第二个强大能力:支持秒级别的定时。看下面的例子:
// 创建一个cron实例
c := cron.New(cron.WithParser(cron.NewParser(cron.SecondOptional | cron.Minute | cron.Hour | cron.Dom | cron.Month | cron.Dow | cron.Descriptor)))
// 每秒执行一次
c.AddFunc("* * * * * *", func() {
fmt.Println("Every hour on the half hour")
})
在初始化实例的时候使用NewParser,设置了允许定时字符串支持秒级别的选项cron.SecondOptional。这样,我们可以使用6个星号来表示在秒级别的时候调用一次。这个功能是很多第三方库,甚至Linux的crontab都做不到的。
除了这两个强大的能力之外,cron还支持动态增加定时任务、任务调用链等功能。不过这些功能暂时用不到,就不在这里介绍了。有兴趣的同学可以自己课后研究cron库的源码。
我们下一步就是要考虑如何将cron库应用在hade框架中了。
从使用角度开始思考,今天一开始我们说了,挑战只增加一行代码就能定时执行某个命令。那这个代码应该有两个参数,一是设置定时时间,二是定制执行的命令。就像这样:
// 每秒调用一次Foo命令
rootCmd.AddCronCommand("* * * * * *", demo.FooCommand)
第一个参数对应cron库中的“时间描述语言”,第二个参数对应我们的Command结构。
从刚才的两个使用小例子能看到,在cron库中,增加一个定时任务的AddFunc方法,有两个参数:时间描述语言、匿名函数。那么明显,AddCronCommand函数中核心要做的,就是将Command结构的执行封装成一个匿名函数,再调用cron的AddFunc方法就可以了。
这里还有一个需要先解决的问题,cron库需要初始化一个Cron对象,就是上面库例子中的cron.New方法创建的对象,这个Cron对象存放在哪里呢?
记得上一节课,我们将服务容器container存放在根Command中么,让所有的命令都可以通过Root() 方法获取到根Command,再获取到container。那这里也可以如法炮制,将初始化的Cron对象放在根Command中。
所以,在框架目录的framework/cobra/Command.go中,我们对Command结构进行修改:
type Command struct {
// Command支持cron,只在RootCommand中有这个值
Cron *cron.Cron
// 对应Cron命令的信息
CronSpecs []CronSpec
...
}
除了在根Command结构中放入Cron实例,我还放入了一个CronSpecs的数组,这个数组用来保存所有Cron命令的信息,为后续查看所有定时任务而准备。
思考清楚了这些,我们就能开始动手写AddCronCommand这个函数了。
先获取根Command,判断是否已经初始化了Cron实例,如果没有,就要初始化。接着,补充Cron命令的信息到CronSpecs数组中。最后封装一个匿名函数,在这个匿名函数中,我们将要执行的Command进行封装。
// AddCronCommand 是用来创建一个Cron任务的
func (c *Command) AddCronCommand(spec string, cmd *Command) {
// cron结构是挂载在根Command上的
root := c.Root()
if root.Cron == nil {
// 初始化cron
root.Cron = cron.New(cron.WithParser(cron.NewParser(cron.SecondOptional | cron.Minute | cron.Hour | cron.Dom | cron.Month | cron.Dow | cron.Descriptor)))
root.CronSpecs = []CronSpec{}
}
// 增加说明信息
root.CronSpecs = append(root.CronSpecs, CronSpec{
Type: "normal-cron",
Cmd: cmd,
Spec: spec,
})
// 制作一个rootCommand
var cronCmd Command
ctx := root.Context()
cronCmd = *cmd
cronCmd.args = []string{}
cronCmd.SetParentNull()
cronCmd.SetContainer(root.GetContainer())
// 增加调用函数
root.Cron.AddFunc(spec, func() {
// 如果后续的command出现panic,这里要捕获
defer func() {
if err := recover(); err != nil {
log.Println(err)
}
}()
err := cronCmd.ExecuteContext(ctx)
if err != nil {
// 打印出err信息
log.Println(err)
}
})
}
这里有几个细节需要注意一下。
封装匿名函数的时候,要记得保证这个匿名函数不会抛出异常,因为在cron中,匿名函数是开启一个Goroutine来执行的,而在Golang中,每个Goroutine都是平等的,任何一个Goroutine出现panic,都会导致整个进程中止。
另外在匿名函数中,封装的并不是传递进来的Command,而是把这个Command做了一个副本,并且将其父节点设置为空,让它自身就是一个新的根节点;然后调用这个Command的Execute方法。
这么做主要是因为我在调试过程中发现,cobra库在执行任意一个Command的Execute系列方法时,都会从根Command开始,根据参数进行遍历查询。这是因为我们是通过定时器进行调用的,这个定时器调用并没有真正的控制台,如果希望找到这个cronCmd,直接调用其Execute命令就行。
所以在上面的代码里,复制了一个当前Command结构的cronCmd,并且将其设置为根Command,就是SetParentNull() 函数,将其上游设置为空,就可以直接在定时器启动的时候调用这个cronCmd的ExecuteCrontext了。
好了,现在完成了cron的初始化和回调,下面要解决启动cron的时机了。
上一节课我们将main函数修改为一个命令行调用,还将启动Web服务设计为一个子命令。那么类比到这里,启动cron服务也应该改造成为一个子命令。所以定义一个二级命令cron,五个三级命令start、stop、restart、list、state。
~: ./hade cron
定时任务相关命令
Usage:
hade cron [flags]
hade cron [command]
Available Commands:
list 列出所有的定时任务
restart 重启cron常驻进程
start 启动cron常驻进程
state cron常驻进程状态
stop 停止cron常驻进程
Flags:
-h, --help help for cron
Use "hade cron [command] --help" for more information about a command.
这五个三级命令中最核心的就是启动cron的命令,我们就详细讲解这个命令,其他的大同小异,你可以课后对照GitHub补充。
在./hade cron start 这个命令中,必须要考虑的有两个问题:
首先,我们希望使用cron的三级命令对某个进程进行管理。想达到这个目的,获取这个被管理进程的PID,并放入指定文件中非常重要,只有这样,才能在不同命令之间,通过获取这个PID,来查询或者停止这个进程。
解决方案倒不难。获取当前进程,我们可以使用标准库osos.GetPid() 。而PID的存放目录,之前在第12节课中定义服务目录的时候,有一个runtimeFolder是存放当前运行状态文件的,可以把cron进程的PID存放在这个目录中。
其次,在启动常驻进程的时候,我们可能以直接挂起进程的方式启动,也可能以后台deamon的方式启动,所以对于start 的命令最好能支持两种形态。这两种形态可以通过一个参数进行区分,在文件framework/command/cron.go中增加deamon参数:
// start命令有一个deamon参数,简写为d
cronStartCommand.Flags().BoolVarP(&cronDeamon, "deamon", "d", false, "start serve deamon")
直接挂起的逻辑比较简单,就是直接调用cron的Run函数:
c.Root().Cron.Run()
那么如何以deamon方式后台运行一个命令呢?或许你的第一反应是直接进行系统调用fork行不行?但是要告诉你,不行。
因为在Golang中,fork可以启动一个子进程,但是这个子进程是无法继承父进程的调度模型的。Golang的调度模型是在用户态的runtime中自己进行调度的,而系统调用fork出来的子进程默认只会有单线程。所以在Golang中尽量不要使用fork的方式来复制启动当前进程。
这里,实际上希望能fork出一个同样有运行到当前代码Go环境的进程。
另一个办法是使用os.StartProcess 来启动一个进程,执行当前进程相同的二进制文件以及当前进程相同的参数。同时,由于二进制文件相同,还要为启动的子进程单独配置一个环境变量,这样在生成二进制文件的代码中,就能根据环境变量区分是主进程还是子进程。
这里整个启动子进程的方法在开源社区已经有封装好的了——开源库 go-daemon。这个开源库目前star数有1.5k,采用MIT的licence,是现在比较流行的将进程deamon化的库了。它的原理和上面分析的是一样的,我们看下使用思路。
这个库会初始化一个daemon.Context结构,在这个结构中可以设置子进程的参数、环境变量、PID生成的文件、输出日志生成的文件、权限等。然后调用一个Reborn方法启动一个子进程,这个Reborn除了error之外,还有一个返回值os.Process,如果非空,代表当前为父进程,能从这个方法获取子进程信息,如果为空,代表当前为子进程。
现在启动cron命令的两个实现关键点都考虑清楚了。
结合我们当前的需求,要启动一个子进程,命令为:./hade cron start --deamon=true,这个子进程会运行cron.Run,子进程PID写入runtimeFolder目录下,子进程日志打印在logFolder目录下。而父进程打印成功信息,直接返回,不做任何操作。
代码framework/command/cron.go 中的 cronStartCommand 核心逻辑如下:
// deamon 模式
if cronDeamon {
// 创建一个Context
cntxt := &daemon.Context{
// 设置pid文件
PidFileName: serverPidFile,
PidFilePerm: 0664,
// 设置日志文件
LogFileName: serverLogFile,
LogFilePerm: 0640,
// 设置工作路径
WorkDir: currentFolder,
// 设置所有设置文件的mask,默认为750
Umask: 027,
// 子进程的参数,按照这个参数设置,子进程的命令为 ./hade cron start --deamon=true
Args: []string{"", "cron", "start", "--deamon=true"},
}
// 启动子进程,d不为空表示当前是父进程,d为空表示当前是子进程
d, err := cntxt.Reborn()
if err != nil {
return err
}
if d != nil {
// 父进程直接打印启动成功信息,不做任何操作
fmt.Println("cron serve started, pid:", d.Pid)
fmt.Println("log file:", serverLogFile)
return nil
}
// 子进程执行Cron.Run
defer cntxt.Release()
fmt.Println("deamon started")
gspt.SetProcTitle("hade cron")
c.Root().Cron.Run()
return nil
}
整体实现可以参考GitHub中当前章节的分支。
下面验证一下前面对定时任务的改造是否成功。先在业务app/console/command/demo/foo.go中创建一个Foo命令,它的执行行为就是打印一行字符“execute foo command”:
// FooCommand 代表Foo命令
var FooCommand = &cobra.Command{
Use: "foo",
Short: "foo的简要说明",
Long: "foo的长说明",
Aliases: []string{"fo", "f"},
Example: "foo命令的例子",
RunE: func(c *cobra.Command, args []string) error {
log.Println("execute foo command")
return nil
},
}
然后将这个FooCommand,通过AddCronCommand绑定到根Command中,并且设置其调用时间为每秒调用一次。
// 绑定业务的命令
func AddAppCommand(rootCmd *cobra.Command) {
// 每秒调用一次Foo命令
rootCmd.AddCronCommand("* * * * * *", demo.FooCommand)
}
启动三级命令行工具./hade cron start -d,看到控制台打印出了子进程PID信息,和日志存储地址。
使用tail命令查看日志,可以看到确实是每秒执行打印一次字符串:execute foo command

到这里,我们对框架的定时命令改造就完成了。
但现在的定时器还是单机版本的定时器,容灾性很低,如果有很多定时任务都挂载在一个进程中,一旦这个进程或者这个机器出现灾难性不可恢复,那么定时任务就直接无法运行了。
容灾性更高的是分布式定时器。也就是很多机器都同时挂载定时任务,在同一时间都启动任务,只有一台机器能抢占到这个定时任务并且执行,其他机器由于抢占不到定时任务,不执行任何操作。
我们的框架也能做到这个分布式定时器的功能。
这种分布式定时器如何实现呢?你第一个想到的是不是使用Redis?我们用Redis做一个分布式锁,然后所有进程去抢占这个锁。
还是这样思考问题就比较低层次了。在第十、十一章,我们花了大量的篇幅讲了面向接口编程的思想,这里就可以用到这个思想。先定义接口,这个接口的功能是一个分布式的选择器,当有很多节点要执行某个服务的时候,只选择出其中一个节点。这样不管底层是否用Redis实现分布式选择器,在业务层我们都可以不用关心。
在文件framework/contract/distributed.go 文件中。我们先定义接口Distributed。其中有一个分布式选举方法Select。它的参数有三个,serviceName 代表服务名字、appID代表节点的ID、holdTime表示这个选择结果持续多久,也就是在选举出来之后多久内有效。它返回两个值,selectAppID表示选举的结果,即最终哪个节点被选举出来了,另一个返回值error表示异常。
package contract
import "time"
// DistributedKey 定义字符串凭证
const DistributedKey = "hade:distributed"
// Distributed 分布式服务
type Distributed interface {
// Select 分布式选择器, 所有节点对某个服务进行抢占,只选择其中一个节点
// ServiceName 服务名字
// appID 当前的AppID
// holdTime 分布式选择器hold住的时间
// 返回值
// selectAppID 分布式选择器最终选择的App
// err 异常才返回,如果没有被选择,不返回err
Select(serviceName string, appID string, holdTime time.Duration) (selectAppID string, err error)
}
这里提到了一个appID是我们之前没有见过的,简单说明一下。appID是为每个当前应用起的唯一标识,它用Google的 uuid生成库 就可以很方便生成。它怎么通过服务容器获取呢?我们可以将appID作为服务容器中App服务的一个方法,这样就能从服务容器中获取App服务,再获取到appID了。
所以这里插一步来修改对应的 App 接口和其对应实现HadeApp,详细的修改点都以注释的形式写在下面代码中了。
在framework/contract/framework/contract/app.go中增加AppID的接口函数:
// App 定义接口
type App interface {
// AppID 表示当前这个app的唯一id, 可以用于分布式锁等
AppID() string
...
}
在framework/provider/app/service.go中也增加对AppID的实现:
// HadeApp 代表hade框架的App实现
type HadeApp struct {
...
appId string // 表示当前这个app的唯一id, 可以用于分布式锁等
}
// NewHadeApp 初始化HadeApp
func NewHadeApp(params ...interface{}) (interface{}, error) {
...
appId := uuid.New().String()
return &HadeApp{baseFolder: baseFolder, container: container, appId: appId}, nil
}
// AppID 表示这个App的唯一ID
func (h HadeApp) AppID() string {
return h.appId
}
分布式服务Distributed的接口定义好,我们再回到它的具体实现。
这个具体实现就有很多方式了,Redis只是其中一种而已,而且Redis要到后面章节才能引入。这里就实现一个本地文件锁。当一个服务器上有多个进程需要进行抢锁操作,文件锁是一种单机多进程抢占的很简易的实现方式。在Golang中,其使用方法也比较简单。
多个进程同时使用os.OpenFile打开一个文件,并使用syscall.Flock带上syscall.LOCK_EX参数来对这个文件加文件锁,这里只会有一个进程抢占到文件锁,而其他抢占不到的进程从syscall.Flock函数中获取到的就是error。根据这个error是否为空,我们就能判断是否抢占到了文件锁。
释放文件锁有两种方式,一种方式是调用syscall.Flock带上syscall.LOCK_UN的参数,另外一种方式是抢占到锁的进程结束,也会自动释放文件锁。
来看分布式选择器的本地文件锁的具体实现,在代码framework/provider/distributed/service_local.go文件中:
// Select 为分布式选择器
func (s LocalDistributedService) Select(serviceName string, appID string, holdTime time.Duration) (selectAppID string, err error) {
appService := s.container.MustMake(contract.AppKey).(contract.App)
runtimeFolder := appService.RuntimeFolder()
lockFile := filepath.Join(runtimeFolder, "disribute_"+serviceName)
// 打开文件锁
lock, err := os.OpenFile(lockFile, os.O_RDWR|os.O_CREATE, 0666)
if err != nil {
return "", err
}
// 尝试独占文件锁
err = syscall.Flock(int(lock.Fd()), syscall.LOCK_EX|syscall.LOCK_NB)
// 抢不到文件锁
if err != nil {
// 读取被选择的appid
selectAppIDByt, err := ioutil.ReadAll(lock)
if err != nil {
return "", err
}
return string(selectAppIDByt), err
}
// 在一段时间内,选举有效,其他节点在这段时间不能再进行抢占
go func() {
defer func() {
// 释放文件锁
syscall.Flock(int(lock.Fd()), syscall.LOCK_UN)
// 释放文件
lock.Close()
// 删除文件锁对应的文件
os.Remove(lockFile)
}()
// 创建选举结果有效的计时器
timer := time.NewTimer(holdTime)
// 等待计时器结束
<-timer.C
}()
// 这里已经是抢占到了,将抢占到的appID写入文件
if _, err := lock.WriteString(appID); err != nil {
return "", err
}
return appID, nil
}
大概逻辑是先打开或者创建文件锁对应的文件,然后在这个文件上加上文件锁,加上锁的过程就是抢占的过程。对于没有抢占到的,文件中内容为抢占到的那个应用的ID,将应用ID返回;抢占到的,就写入自己的应用ID到文件中,并且通过一个新的Goroutine开启计时器,等待计时器结束后解开文件锁,并且删除文件锁对应的文件。
而这个分布式服务Distributed的服务提供者 framework/provider/distributed/provider_local.go 的逻辑就比较简单了,就是正常的实现serviceProvider的5个方法,这里就不赘述了,可以参考GitHub上的代码分支。
现在有了分布式选择器,就可以实现分布式调度了。我们为Command结构增加一个方法AddDistributedCronCommand,这个方法有四个参数:
它的实现和AddCronCommand差不多,唯一的区别就是在封装cron.AddFunc的匿名函数中,运行目标命令之前,要做一次分布式选举,如果被选举上了,才执行目标命令。所以来增加一个文件,在framework/cobra/hade_command_distributed.go 中,定义 AddDistributedCronCommand 方法:
// AddDistributedCronCommand 实现一个分布式定时器
// serviceName 这个服务的唯一名字,不允许带有空格
// spec 具体的执行时间
// cmd 具体的执行命令
// holdTime 表示如果我选择上了,这次选择持续的时间,也就是锁释放的时间
func (c *Command) AddDistributedCronCommand(serviceName string, spec string, cmd *Command, holdTime time.Duration) {
root := c.Root()
// 初始化cron
if root.Cron == nil {
root.Cron = cron.New(cron.WithParser(cron.NewParser(cron.SecondOptional | cron.Minute | cron.Hour | cron.Dom | cron.Month | cron.Dow | cron.Descriptor)))
root.CronSpecs = []CronSpec{}
}
// cron命令的注释,这里注意Type为distributed-cron,ServiceName需要填写
root.CronSpecs = append(root.CronSpecs, CronSpec{
Type: "distributed-cron",
Cmd: cmd,
Spec: spec,
ServiceName: serviceName,
})
appService := root.GetContainer().MustMake(contract.AppKey).(contract.App)
distributeServce := root.GetContainer().MustMake(contract.DistributedKey).(contract.Distributed)
appID := appService.AppID()
// 复制要执行的command为cronCmd,并且设置为rootCmd
var cronCmd Command
ctx := root.Context()
cronCmd = *cmd
cronCmd.args = []string{}
cronCmd.SetParentNull()
// cron增加匿名函数
root.Cron.AddFunc(spec, func() {
// 防止panic
defer func() {
if err := recover(); err != nil {
log.Println(err)
}
}()
// 节点进行选举,返回选举结果
selectedAppID, err := distributeServce.Select(serviceName, appID, holdTime)
if err != nil {
return
}
// 如果自己没有被选择到,直接返回
if selectedAppID != appID {
return
}
// 如果自己被选择到了,执行这个定时任务
err = cronCmd.ExecuteContext(ctx)
if err != nil {
log.Println(err)
}
})
}
完成了实现逻辑,下面照例做验证。
我们将打印字符“execute foo command”的FooCommand 命令执行的服务名设置为 “foo_func_for_test”。设置为每5秒进行一次选举并产生结果,每次选举结果保留2秒钟:
// 绑定业务的命令
func AddAppCommand(rootCmd *cobra.Command) {
// 启动一个分布式任务调度,调度的服务名称为init_func_for_test,每个节点每5s调用一次Foo命令,抢占到了调度任务的节点将抢占锁持续挂载2s才释放
rootCmd.AddDistributedCronCommand("foo_func_for_test", "*/5 * * * * *", demo.FooCommand, 2*time.Second)
}
开启两个控制台,启动两个进程 ./hade cron start 。
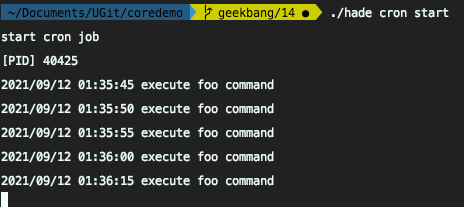
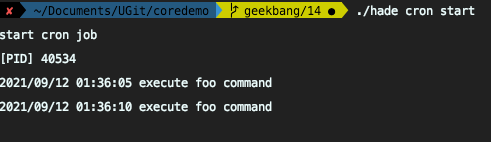
能看到36分00秒的任务是在PID为40425的进程执行,而36分05秒的任务是在PID为40653的进程执行。而且仿造容灾演练,关闭掉其中任何一个进程,剩余每5秒钟执行的任务,都会落在存活的那个进程中。
到这里,我们就为hade框架提供了分布式定时器的功能。这节课的所有代码都在GitHub上的 geekbang/14 分支。对应的目录结构截图如下:
今天内容有点多,对不太清楚的地方,你可以多看几遍慢慢理解。
我们先使用cron包来为框架增加了定时执行命令的功能。在实现过程中,介绍了在Golang中,如何启动一个当前二进制文件的子进程。这个启动子进程的方式非常重要,后续在多个命令行工具中还会使用到,得熟练掌握。
接着一起实现了分布式定时器的功能。在实现分布式定时器的功能中,你也能更深一步感受到前几节课说的面向接口编程和服务容器设计的好处。比如说我们实现分布式定时器需要appID,就去app服务中增加一个获取AppID的接口;需要分布式选举服务,就创建了一个分布式服务接口。非常方便。
本节课实现了cron的五个三级命令其中最重要的一个cron start。你可以思考并尝试写一下其他几个命令:
欢迎在留言区分享你的思考。如果你觉得有收获,也欢迎把今天的内容分享给身边的朋友,邀他一起学习。我们下节课见。