
而Java的log4j将日志分为以下七种日志级别:

你好,我是轩脉刃。
上面两节课,我们将环境变量和配置服务作为一个服务注册到容器中了。这样,在业务中就能很方便获取环境变量和配置了。不知道你有没有逐渐体会到这种“一切皆服务”思想的好处。
就像堆积积木,只要想好了一个服务的接口,我们逐步实现服务之后,这一个服务就是一块积木,之后可以用相同的思路实现各种服务的积木块,用它们来拼出我们需要的业务逻辑。这节课,我们就来实现另一个框架最核心的积木:日志服务。
实现一个框架的服务,我们习惯了要创建三个文件:接口协议文件 framework/contract/log.go、服务提供者 framework/provider/log/provider.go、接口实例framework/provider/log/service.go。
说到日志服务,最先冒出来的一定是三个问题:什么样的日志需要输出?日志输出哪些内容?日志输出到哪里?一个个来分析。
什么样的日志需要输出,这是个关于日志级别的问题。我们想要把日志分为几个级别?每个级别代表什么?这个日志级别其实在不同系统中有不同划分,比如Linux的syslog中将系统划分为以下八种日志级别:
而Java的log4j将日志分为以下七种日志级别:
其实仔细看,它们的日志级别差别都不大。比如都同意用Error级别代表运行时的错误情况,而Warn级别代表运行时可以弥补的错误、Info级别代表运行时信息、debug代表调试的时候需要打印的信息。
不同点就在是否有trace级别以及Error级别往上的级别定义。syslog没有trace级别,而在Error级别往上分别定义了Emergency级别、Alert级别、Critical级别。而log4j在ERROR上定义了两个级别FATAL和OFF,也同时保留了Trace级别。
在我看来,syslog和log4j的日志区分主要是由于场景不同。syslog比较偏向于操作系统的使用场景,它的分级语义更多是告诉我们系统的情况,比如Alert这个级别表示“系统有问题,需要立即采取行动”;而log4j的日志级别定义是从一个应用出发的,它的影响范围理论上会小一些,所以它很难定义比如像“需要立即采取行动”这样的级别。
所以,这里我们主要参考log4j的日志级别方法,并做了一些小调整,归并为下列七种日志级别:
在error级别之上,我们把导致程序崩溃和导致请求结束的错误拆分出来,分为panic和fatal两个类型来定义级别。而其他的error、warn、info、debug 都和其他的日志系统一致。另外也增加一个trace级别,当需要打印调用堆栈等这些比较详细的信息的时候,可以使用这种日志级别。
日志级别是按照严重顺序从下往上排列的。也就是说,如果我们设置了日志输出级别为info,那么info级别的日志及info级别往上,日志级别更高的warn、error、fatal、panic的日志,也需要被打印出来。
按照这个思路,我们在framework/contract/log.go中定义的接口协议如下:
package contract
import (
"context"
"io"
"time"
)
// 协议关键字
const LogKey = "hade:log"
type LogLevel uint32
const (
// UnknownLevel 表示未知的日志级别
UnknownLevel LogLevel = iota
// PanicLevel level, panic 表示会导致整个程序出现崩溃的日志信息
PanicLevel
// FatalLevel level. fatal 表示会导致当前这个请求出现提前终止的错误信息
FatalLevel
// ErrorLevel level. error 表示出现错误,但是不一定影响后续请求逻辑的错误信息
ErrorLevel
// WarnLevel level. warn 表示出现错误,但是一定不影响后续请求逻辑的报警信息
WarnLevel
// InfoLevel level. info 表示正常的日志信息输出
InfoLevel
// DebugLevel level. debug 表示在调试状态下打印出来的日志信息
DebugLevel
// TraceLevel level. trace 表示最详细的信息,一般信息量比较大,可能包含调用堆栈等信息
TraceLevel
)
...
// Log define interface for log
type Log interface {
// Panic 表示会导致整个程序出现崩溃的日志信息
Panic(ctx context.Context, msg string, fields map[string]interface{})
// Fatal 表示会导致当前这个请求出现提前终止的错误信息
Fatal(ctx context.Context, msg string, fields map[string]interface{})
// Error 表示出现错误,但是不一定影响后续请求逻辑的错误信息
Error(ctx context.Context, msg string, fields map[string]interface{})
// Warn 表示出现错误,但是一定不影响后续请求逻辑的报警信息
Warn(ctx context.Context, msg string, fields map[string]interface{})
// Info 表示正常的日志信息输出
Info(ctx context.Context, msg string, fields map[string]interface{})
// Debug 表示在调试状态下打印出来的日志信息
Debug(ctx context.Context, msg string, fields map[string]interface{})
// Trace 表示最详细的信息,一般信息量比较大,可能包含调用堆栈等信息
Trace(ctx context.Context, msg string, fields map[string]interface{})
// SetLevel 设置日志级别
SetLevel(level LogLevel)
...
}
在接口中,我们针对七种日志级别设置了七个不同的方法,并且提供SetLevel方法,来设置当前这个日志服务需要输出的日志级别。
定义好了日志级别,下面该定义日志格式了。日志格式包括输出哪些内容、如何输出?
首先明确下需要输出的日志信息,不外乎有下面四个部分:
比如这就是一个完整的日志信息:
[Info] 2021-09-22T00:04:21+08:00 "demo test error" map[api:demo/demo cspan_id: parent_id: span_id:c55051d94815vbl56i2g trace_id:c55051d94815vbl56i20 user:jianfengye]
上面那条日志,日志级别为Info,时间为2021-09-21年15:40:03,时区为+08:00。简要信息demo test error 表示这个日志希望打印的信息,剩下的map表示的key、value为补充的日志上下文字段。
它对应的调用函数如下:
logger.Info(c, "demo test error", map[string]interface{}{
"api": "demo/demo",
"user": "jianfengye",
})
这里我额外说一下日志上下文字段。它是一个map值,来源可能有两个:一个是用户在打印日志的时候传递的map,比如上面代码中的api和user;而另外一部分数据是可能来自context,因为在具体业务开发中,我们很有可能把一些通用信息,比如trace_id等放在context里,这一部分信息也会希望取出放在日志的上下文字段中。
所以这里有一个从context中获取日志上下文字段的方法。在framework/contract/log.go中定义其为CtxFielder。
// CtxFielder 定义了从context中获取信息的方法
type CtxFielder func(ctx context.Context) map[string]interface{}
明确了打印哪些信息,更要明确这些信息按照什么输出格式输出。这个输出格式也是一个通用方法Fomatter,它的传入参数就是刚才的四个日志信息。
// Formatter 定义了将日志信息组织成字符串的通用方法
type Formatter func(level LogLevel, t time.Time, msg string, fields map[string]interface{}) ([]byte, error)
同时在log服务协议中增加了SetFormatter 和 SetCtxFielder的方法。
// Log 定义了日志服务协议
type Log interface {
...
// SetCtxFielder 从context中获取上下文字段field
SetCtxFielder(handler CtxFielder)
// SetFormatter 设置输出格式
SetFormatter(formatter Formatter)
...
}
已经解决了前两个问题,明确了日志的级别和输出格式,那日志可以输出在哪些地方?
其实我们在定义接口的时候,并不知道它会输出到哪里。但是只需要知道一定会输出到某个输出管道就可以了,之后在每个应用中使用的时候,我们再根据每个应用的配置,来确认具体的输出管道实现。
目前这个输出管道我们使用io.Writer来进行设置:
// Log 定义了日志服务协议
type Log interface {
...
// SetOutput 设置输出管道
SetOutput(out io.Writer)
}
日志接口协议文件就完成了,下面来实现日志的服务提供者,在framework/provider/log/provider.go中。
在编写服务提供者的时候,我们需要先明确最终会提供哪些服务。对于日志服务,按照我们平时的使用情况,可以分为四类:
这四种输出我们都各自定义一个服务,分别放在framework/provider/log/service/ 目录下的四个文件里:
那在服务提供者的Register注册服务实例方法中,我们设计成根据配置项“log.driver” ,来选择不同的实例化方法,默认为NewHadeConsoleLog 方法。
// Register 注册一个服务实例
func (l *HadeLogServiceProvider) Register(c framework.Container) framework.NewInstance {
if l.Driver == "" {
tcs, err := c.Make(contract.ConfigKey)
if err != nil {
// 默认使用console
return services.NewHadeConsoleLog
}
cs := tcs.(contract.Config)
l.Driver = strings.ToLower(cs.GetString("log.Driver"))
}
// 根据driver的配置项确定
switch l.Driver {
case "single":
return services.NewHadeSingleLog
case "rotate":
return services.NewHadeRotateLog
case "console":
return services.NewHadeConsoleLog
case "custom":
return services.NewHadeCustomLog
default:
return services.NewHadeConsoleLog
}
}
而上一节里面分析的,日志的几个配置:日志级别、输出格式方法、context内容获取方法、输出方法,都以服务提供者provider.go 中参数的方式提供。
// HadeLogServiceProvider 服务提供者
type HadeLogServiceProvider struct {
...
// 日志级别
Level contract.LogLevel
// 日志输出格式方法
Formatter contract.Formatter
// 日志context上下文信息获取函数
CtxFielder contract.CtxFielder
// 日志输出信息
Output io.Writer
}
默认提供两种输出格式,一种是文本输出形式,比如上面举的那个例子,
[Info] 2021-09-22T00:04:21+08:00 "demo test error" map[api:demo/demo cspan_id: parent_id: span_id:c55051d94815vbl56i2g trace_id:c55051d94815vbl56i20 user:jianfengye]
另外一种是JSON输出形式,如下:
{"api":"demo/demo","cspan_id":"","level":5,"msg":"demo1","parent_id":"","span_id":"c54v0tt9481537jasreg","timestamp":"2021-09-21T22:47:19+08:00","trace_id":"c54v0tt9481537jasre0","user":"jianfengye"}
这两种输出除了格式不同,其中的内容应该是相同的。具体使用起来,文本输出更便于我们阅读,而JSON输出更便于机器或者程序阅读。
在实现文件夹framework/provider/log/formatter/ 里,我们增加两个文件json.go和text.go表示两种格式输出,对应的TextFormatter和JsonFormatter是对应的文本格式输出方法,
这里就贴出text.go的具体实现,很简单,其他的差别不大,可以参考GitHub。
// TextFormatter 表示文本格式输出
func TextFormatter(level contract.LogLevel, t time.Time, msg string, fields map[string]interface{}) ([]byte, error) {
bf := bytes.NewBuffer([]byte{})
Separator := "\t"
// 先输出日志级别
prefix := Prefix(level)
bf.WriteString(prefix)
bf.WriteString(Separator)
// 输出时间
ts := t.Format(time.RFC3339)
bf.WriteString(ts)
bf.WriteString(Separator)
// 输出msg
bf.WriteString("\"")
bf.WriteString(msg)
bf.WriteString("\"")
bf.WriteString(Separator)
// 输出map
bf.WriteString(fmt.Sprint(fields))
return bf.Bytes(), nil
}
再回到 framework/provider/log/provider.go,定义服务提供者的Params方法。比如获取格式化方法Formatter,我们就设定成,先判断在初始化的时候,是否定义了服务提供者;如果没有,再判断配置项log.formatter是否指定了格式化方法 json/text,设置最终的Formatter,并且传递实例化的方法。
// Params 定义要传递给实例化方法的参数
func (l *HadeLogServiceProvider) Params(c framework.Container) []interface{} {
// 获取configService
configService := c.MustMake(contract.ConfigKey).(contract.Config)
// 设置参数formatter
if l.Formatter == nil {
l.Formatter = formatter.TextFormatter
if configService.IsExist("log.formatter") {
v := configService.GetString("log.formatter")
if v == "json" {
l.Formatter = formatter.JsonFormatter
} else if v == "text" {
l.Formatter = formatter.TextFormatter
}
}
}
if l.Level == contract.UnknownLevel {
l.Level = contract.InfoLevel
if configService.IsExist("log.level") {
l.Level = logLevel(configService.GetString("log.level"))
}
}
// 定义5个参数
return []interface{}{c, l.Level, l.CtxFielder, l.Formatter, l.Output}
}
至于日志服务提供者的其他几个方法(Register、Boot、IsDefer、Name),就不在这里说明了,可以参考GitHub上的代码。
最后就到具体的日志服务的实现了。上面我们说,针对四种不同的输出方式,定义了四个不同的服务实例,这四个不同的服务实例都需要实现前面定义的日志服务协议。如果每个实例都实现一遍,还是非常麻烦的。这里可以使用一个技巧:类型嵌套。
我们先创建一个通用的服务实例HadeLog,在HadeLog中存放通用的字段,比如上述日志服务提供者传递的五个参数:container、level、ctxFielder、formatter、output。
在 provider/log/services/log.go中定义这个结构:
// HadeLog 的通用实例
type HadeLog struct {
// 五个必要参数
level contract.LogLevel // 日志级别
formatter contract.Formatter // 日志格式化方法
ctxFielder contract.CtxFielder // ctx获取上下文字段
output io.Writer // 输出
c framework.Container // 容器
}
接着在通用实例中,使用这几个必要的参数,就能实现日志协议的所有接口了,这里展示了Info方法是怎么打印信息的:
// Info 会打印出普通的日志信息
func (log *HadeLog) Info(ctx context.Context, msg string, fields map[string]interface{}) {
log.logf(contract.InfoLevel, ctx, msg, fields)
}
// logf 为打印日志的核心函数
func (log *HadeLog) logf(level contract.LogLevel, ctx context.Context, msg string, fields map[string]interface{}) error {
// 先判断日志级别
if !log.IsLevelEnable(level) {
return nil
}
// 使用ctxFielder 获取context中的信息
fs := fields
if log.ctxFielder != nil {
t := log.ctxFielder(ctx)
if t != nil {
for k, v := range t {
fs[k] = v
}
}
}
...
// 将日志信息按照formatter序列化为字符串
if log.formatter == nil {
log.formatter = formatter.TextFormatter
}
ct, err := log.formatter(level, time.Now(), msg, fs)
if err != nil {
return err
}
// 如果是panic级别,则使用log进行panic
if level == contract.PanicLevel {
pkgLog.Panicln(string(ct))
return nil
}
// 通过output进行输出
log.output.Write(ct)
log.output.Write([]byte("\r\n"))
return nil
}
可以看到,Info打印最终调用logf 方法,而logf方法的实现步骤也很清晰,简单梳理一下:
HadeLog其他方法的实现和Info大同小异,这里就不展示所有代码了。实现了基础的HadeLog实例,接下来,就实现对应的四个不同输出类型的实例HadeConsoleLog、HadeSingleLog、HadeRotateLog、HadeCustomLog。
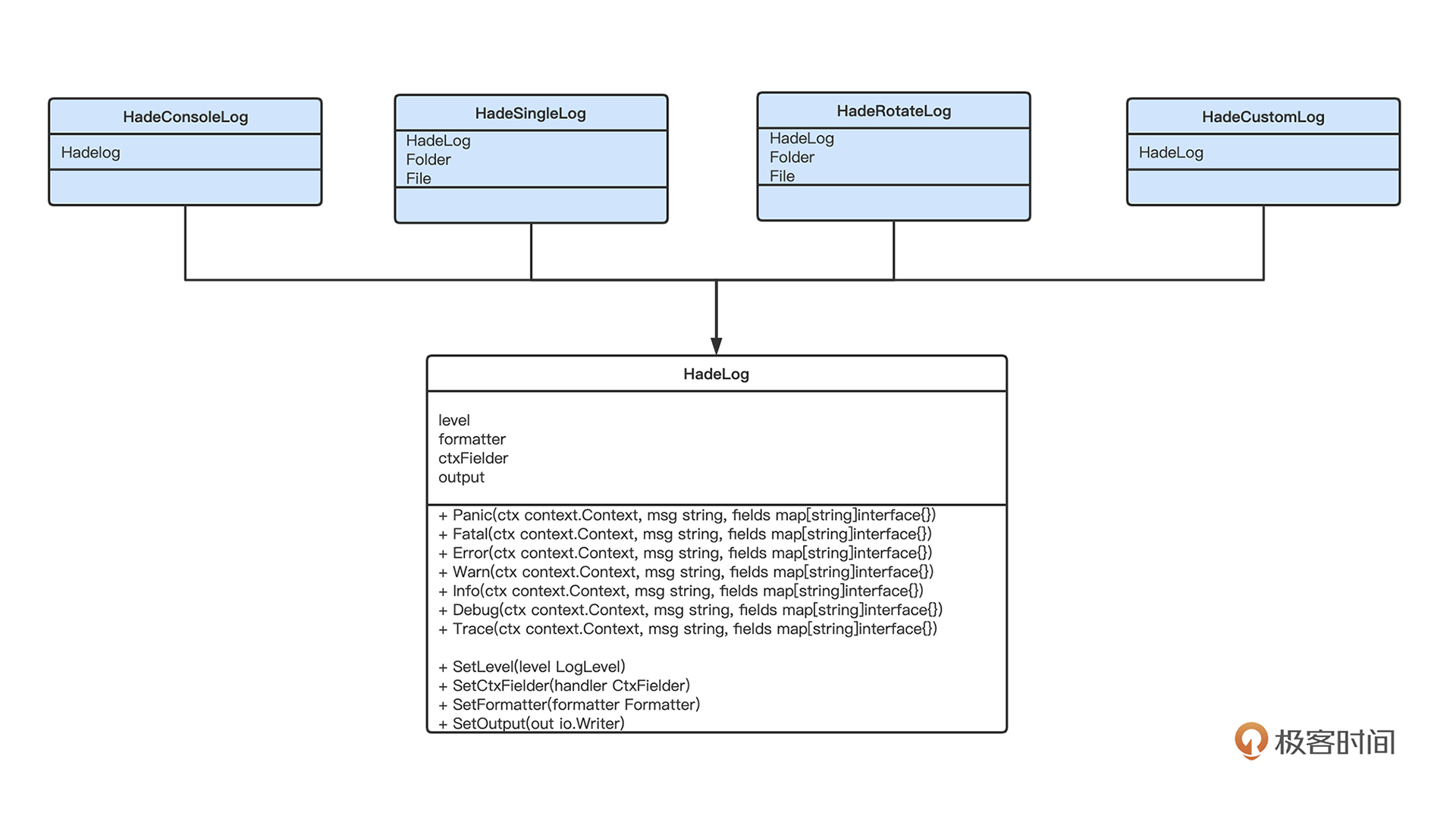
这里四个具体实例使用类型嵌套的方式,就能自动拥有HadeLog已经实现了的那些方法。
比如在 framework/provider/log/service/console.log 中,使用类型嵌套实现 HadeConsoleLog:
// HadeConsoleLog 代表控制台输出
type HadeConsoleLog struct {
// 类型嵌套HadeLog
HadeLog
}
相当于 HadeConsoleLog 就已经实现了日志服务协议了。我们唯一要做的就是在实例化HadeConosoleLog的时候,将基础HadeLog中的通用字段进行填充。比如 HadeConsoleLog 最重要就是将输出类型output设置为控制台os.stdout:
// NewHadeConsoleLog 实例化HadeConsoleLog
func NewHadeConsoleLog(params ...interface{}) (interface{}, error) {
c := params[0].(framework.Container)
level := params[1].(contract.LogLevel)
ctxFielder := params[2].(contract.CtxFielder)
formatter := params[3].(contract.Formatter)
log := &HadeConsoleLog{}
log.SetLevel(level)
log.SetCtxFielder(ctxFielder)
log.SetFormatter(formatter)
// 最重要的将内容输出到控制台
log.SetOutput(os.Stdout)
log.c = c
return log, nil
}
四种输出文件其实都大同小异,这里就挑选一个最复杂的带有日志切割的HadeRotateLog来讲解。
Golang中日志切割有个非常好用的 file-rotatelogs,这个库的使用方法也不复杂,最核心的就是一个初始化操作New:
func New(p string, options ...Option) (*RotateLogs, error)
它有两个参数,第一个参数p是带目录的日志地址,可以允许有通配符代表日期的日志文件名。这里的通配符符合Linux的strftime的定义,具体哪个通配符代表日期、小时、分钟等可以参考strftime的文档说明。而第二个参数是Option数组,表示这个切割日志的一些配置,比如多久切割一次日志文件、切割后的日志文件保存多少天等。
使用很简单,直接看我们对HadeRotateLog的具体实现。大致思路就是先定义结构,再实现初始化方法,在初始化方法中,我们实例化file-rotatelogs的初始化操作New。
首先定义了 HadeRotateLog 的结构,其中嵌套了基础实例结构HadeLog,同时有这个结构特定的字段folder和file:
// HadeRotateLog 代表会进行切割的日志文件存储
type HadeRotateLog struct {
HadeLog
// 日志文件存储目录
folder string
// 日志文件名
file string
}
实例化的NewHadeRotateLog 先获取参数,然后从配置文件中获取参数属性folder、file、date_format、rotate_count、rotate_size、max_age、rotate_time,这些属性都和 file-rotatelogs 库实例化的Option参数一一对应。
所以这里也展示一下我们的log.yaml配置文件可配置的rotate:
driver: rotate # 切割日志
level: trace # 日志级别
file: coredemo.log # 保存的日志文件
rotate_count: 10 # 最多日志文件个数
rotate_size: 120000 # 每个日志大小
rotate_time: "1m" # 切割时间
max_age: "10d" # 文件保存时间
date_format: "%Y-%m-%d-%H-%M" # 文件后缀格式
再回到 NewHadeRotateLog,设置了这些配置属性之后,我们实例化 file-rotatelogs,得到了一个符合io.Writer的输出,将这个输出使用 SetOutput 设置到嵌套的 HadeLog 中即可。
// NewHadeRotateLog 实例化HadeRotateLog
func NewHadeRotateLog(params ...interface{}) (interface{}, error) {
// 参数解析
c := params[0].(framework.Container)
level := params[1].(contract.LogLevel)
ctxFielder := params[2].(contract.CtxFielder)
formatter := params[3].(contract.Formatter)
appService := c.MustMake(contract.AppKey).(contract.App)
configService := c.MustMake(contract.ConfigKey).(contract.Config)
// 从配置文件中获取folder信息,否则使用默认的LogFolder文件夹
folder := appService.LogFolder()
if configService.IsExist("log.folder") {
folder = configService.GetString("log.folder")
}
// 如果folder不存在,则创建
if !util.Exists(folder) {
os.MkdirAll(folder, os.ModePerm)
}
// 从配置文件中获取file信息,否则使用默认的hade.log
file := "hade.log"
if configService.IsExist("log.file") {
file = configService.GetString("log.file")
}
// 从配置文件获取date_format信息
dateFormat := "%Y%m%d%H"
if configService.IsExist("log.date_format") {
dateFormat = configService.GetString("log.date_format")
}
linkName := rotatelogs.WithLinkName(filepath.Join(folder, file))
options := []rotatelogs.Option{linkName}
// 从配置文件获取rotate_count信息
if configService.IsExist("log.rotate_count") {
rotateCount := configService.GetInt("log.rotate_count")
options = append(options, rotatelogs.WithRotationCount(uint(rotateCount)))
}
// 从配置文件获取rotate_size信息
if configService.IsExist("log.rotate_size") {
rotateSize := configService.GetInt("log.rotate_size")
options = append(options, rotatelogs.WithRotationSize(int64(rotateSize)))
}
// 从配置文件获取max_age信息
if configService.IsExist("log.max_age") {
if maxAgeParse, err := time.ParseDuration(configService.GetString("log.max_age")); err == nil {
options = append(options, rotatelogs.WithMaxAge(maxAgeParse))
}
}
// 从配置文件获取rotate_time信息
if configService.IsExist("log.rotate_time") {
if rotateTimeParse, err := time.ParseDuration(configService.GetString("log.rotate_time")); err == nil {
options = append(options, rotatelogs.WithRotationTime(rotateTimeParse))
}
}
// 设置基础信息
log := &HadeRotateLog{}
log.SetLevel(level)
log.SetCtxFielder(ctxFielder)
log.SetFormatter(formatter)
log.folder = folder
log.file = file
w, err := rotatelogs.New(fmt.Sprintf("%s.%s", filepath.Join(log.folder, log.file), dateFormat), options...)
if err != nil {
return nil, errors.Wrap(err, "new rotatelogs error")
}
log.SetOutput(w)
log.c = c
return log, nil
}
本节课我们只是修改了框架目录中的日志服务相关的文件。文件目录:

所有代码都放在GitHub上的 geekbang/17 分支,欢迎比对查看。
我们这节课通过定义了日志级别、日志格式、日志输出,来实现了日志的级别,并且使用类型嵌套方法实现了四种本地日志输出方式。
回顾今天实现的日志服务,你会发现和其他服务的实现思路是差不多的。我们在一个服务中,实现了多个实现类,但是所有的实现类都实现了同样的服务接口,最后能让我们根据配置来决定这个服务使用哪个实现类,其中还使用了嵌套方式,能节省大量重复性的代码。
希望你能熟练掌握这种实现方式,因为我们的服务会越来越多,越上层的服务,比如数据库、缓存,它的具体实现就越是多种多样,到时候我们都可以用同样的套路来进行。
在微服务盛行的今天,全链路日志是非常重要的一个需求。全链路日志的需求本质就是在日志中增加trace_id、span_id 这样的链路字段。具体实现有三点:
你可以思考下这个功能应该怎么实现?
欢迎在留言区分享你的思考。感谢你的收听,如果觉得有收获,也欢迎把今天的内容分享给你身边的朋友,邀他一起学习。我们下节课见。