
在这个AST中,我们用一个VariableDecl节点代表一个变量声明语句。如果这个变量声明语句带有初始化部分,那么我们就用一个单独的节点来表示用于初始化的表达式。
你好,我是宫文学。
到目前为止,我们的语言已经能够处理语句,也能够处理表达式,并且都能够解释执行了。不过,我们目前程序能够处理的数据,还都只是字面量而已。接下来,我们要增加一个重要的能力:支持变量。
在程序中声明变量、对变量赋值、基于变量进行计算,是计算机语言的基本功能。只有支持了变量,我们才能实现那些更加强大的功能,比如,你可以用程序写一个计算物体下落的速度和位置,如何随时间变化的公式。这里的时间就是变量,通过给时间变量赋予不同的值,我们可以知道任意时间的物体速度和位置。
这一节,我就带你让我们手头上的语言能够支持变量。在这个过程中,你还会掌握语义分析的更多技能,比如类型处理等。
好了,我们已经知道了这一节的任务。那么第一步要做什么呢?你可以想到,我们首先要了解与处理变量声明和初始化有关的语法规则。
在TypeScript中,我们在声明变量的时候,可以指定类型,这样有助于在编译期做类型检查:
let myAge : number = 18;
如果编译成JavaScript,那么类型信息就会被抹掉:
var myAge = 18;
不过,因为我们的目标是教给你做类型分析的方法,以后还要静态编译成二进制的机器码,所以我们选择的是TypeScript的语法。
此外,在上面的例子中,变量在声明的时候就已经做了初始化。你还可以把这个过程拆成两步。第一步的时候,只是声明变量,之后再给它赋值:
let myAge : number;
myAge = 18;
知道了如何声明变量以后,你就可以试着写出相关的语法规则。我这里给出一个示范的版本:
variableDecl : 'let' Identifier typeAnnotation? ('=' singleExpression)?;
typeAnnotation : ':' typeName;
学完了前面3节课,我相信你现在应该对阅读语法规则越来越熟悉了。接下来,就要修改我们的语法分析程序,让它能够处理变量声明语句。这里有什么关键点呢?
这里你要注意的是,我们采用的语法分析的算法是LL算法。而在02讲中,我们知道LL算法的关键是计算First和Follow集合。
首先是First集合。在变量声明语句的上一级语法规则(也就是statement)中,要通过First集合中的不同元素,准确地确定应该采用哪一条语法规则。由于变量声明语句是用let开头的,这就使它非常容易辨别。只要预读的Token是let,那就按照变量声明的语法规则来做解析就对了。
接下来是Follow集合。在上面的语法规则中你能看出,变量的类型注解和初始化部分都是可选的,它们都使用了?号。
由于类型注解是可选的,那么解析器在处理了变量名称后,就要看一下后面的Token是什么。如果是冒号,由于冒号是在typeAnnotation的First集合中,那就去解析一个类型注解;如果这个Token不是冒号,而是typeAnnotation的Follow集合中的元素,就说明当前语句里没有typeAnnotation,所以可以直接略过。
那typeAnnotation的Follow集合有哪些元素呢?我就不直说了,你自己来分析一下吧。
再往后,由于变量的初始化部分也是可选的,还要计算一下它的Follow集合。你能看出,这个Follow集合只有;号这一个元素。所以,在解析到变量声明部分的时候,我们可以通过预读准确地判断接下来该采取什么动作:
相关的实现很简单,你参考一下这个示例代码:
let t1 = this.scanner.peek();
//可选的类型标注
if (t1.text == ':'){
this.scanner.next();
t1 = this.scanner.peek();
if (t1.kind == TokenKind.Identifier){
this.scanner.next();
varType = t1.text;
t1 = this.scanner.peek();
}
else{
console.log("Error parsing type annotation in VariableDecl");
return null;
}
}
//可选的初始化部分
if (t1.text == '='){
this.scanner.next();
init = this.parseExpression();
}
//分号,结束变量声明
t1 = this.scanner.peek();
if (t1.text==';'){
this.scanner.next();
return new VariableDecl(varName, varType, init);
}
else{
console.log("Expecting ; at the end of varaible declaration, while we meet " + t1.text);
return null;
}
采用增强后的语法分析程序,去解析“let myAge:number = 18;”这条语句,就会形成下面的AST,这表明我们的解析程序是有效的:
在这个AST中,我们用一个VariableDecl节点代表一个变量声明语句。如果这个变量声明语句带有初始化部分,那么我们就用一个单独的节点来表示用于初始化的表达式。
好了,生成了这个AST,说明现在我们已经支持变量声明和初始化语句了。那么如何支持变量赋值语句呢?其实,在大多数语言中,我们把赋值运算看作是跟加减乘除一样性质的运算。myAge=18被看作是一个赋值表达式。你还可以把=换成+=、-=等运算符,形成像myAge += 2这样的表达式。如果这些表达式后面直接跟一个;号,那就变成了一个表达式语句了。
expressionStatement : singleExpression ';' ;
而在上一节,我们已经能够用运算符优先级算法来解析各种二元表达式。不过,赋值表达式跟加减乘数等表达式有一点不同:它是右结合的。比如,对于a=b=3这个表达式,是先把3赋值给b,再把b赋值给a。所以呢,对应的语法解析程序也要做一下调整,从而生成体现右结合的AST。
具体我们可以参照解析器的parseAssignment()方法的代码。由于赋值表达式的优先级比较低,按照自顶向下的解析原则,可以先解析赋值表达式。而赋值表达式的每个子节点,就是一个其他的二元表达式。所以,我们的语法规则可以大致修改成下面的样子:
singleExpression : assignment;
assignment : binary (AssignmentOp binary)*
binary: primary (BinaryOp primary)*
那现在,我们采用修改完毕的解析器,试着解析一下“a=b=c+3;”这个语句,会打印出下面这个AST:

讲到这里,其实我们与变量有关的语法分析工作就完成了。接下来的工作是什么呢?是实现一些有关的语义分析功能。
不知道你还记不记得,在第1节,我们曾经接触过一点语义分析功能。那个时候我们主要是在函数调用和函数声明之间做了链接。这个工作叫做“引用消解”(Reference Resolve),或者“名称消解”。
对于变量,我们也一样要做这种消解工作。比如下面的示例程序“myAge + 2”这个表达式中,必须知道这个myAge是在哪里声明的。
let myAge : number = 18;
let yourAge : number;
yourAge = myAge + 2;
请你回忆一下,在01讲里,我们是怎么实现引用消解的呢?是在AST的不同节点之间直接做了个链接。这个实现方式比较简单,但实际上不太实用。为什么呢?因为你每次在程序里遇到一个函数或者变量的话,都要遍历AST才能找到它的定义,这有点太麻烦了。
我有一个效率更高的方法,就是建立一个符号表(Symbol Table),用来保存程序中的所有符号。那什么是符号呢?符号就是我们在程序中自己定义对象,如变量、函数、类等等。它们通常都对应一个标识符,作为符号的名称。
采用符号表以后,我们可以在做语义分析的时候,每当遇到函数声明、变量声明,就把符号加到符号表里去。这样,如果别的地方还要使用该符号,我们就直接到符号表里去查就行了。
那这个符号表里要保存哪些信息呢?其实就是我们声明的那些对象的定义信息,比如:
你不要小看了这个符号表,符号表在整个编译过程中都有着重要的作用,它的生命周期可以横跨整个编译过程。有的编译器,在词法分析的时候就会先形成符号表,因为每个标识符肯定会对应一个符号。
不过,大部分现代的编译器,都是在语义分析阶段开始建立符号表的。在Java的字节码文件里,也是存在符号表的,也就是各个类、类的各个成员变量和方法的声明信息。对于C/C++这样的程序,如果要生成可调试的目标代码,也需要用到符号表。所以,在后面的课程中,我们会不断的跟符号表打交道。
初步了解了符号表以后,我们再回到引用消解的任务上来。首先,我们要建立符号表,这需要对AST做第一次遍历:
/**
* 把符号加入符号表。
*/
export class Enter extends AstVisitor{
symTable : SymTable;
constructor(symTable:SymTable){
super();
this.symTable = symTable;
}
/**
* 把函数声明加入符号表
* @param functionDecl
*/
visitFunctionDecl(functionDecl: FunctionDecl):any{
if (this.symTable.hasSymbol(functionDecl.name)){
console.log("Dumplicate symbol: "+ functionDecl.name);
}
this.symTable.enter(functionDecl.name, functionDecl, SymKind.Function);
}
/**
* 把变量声明加入符号表
* @param variableDecl
*/
visitVariableDecl(variableDecl : VariableDecl):any{
if (this.symTable.hasSymbol(variableDecl.name)){
console.log("Dumplicate symbol: "+ variableDecl.name);
}
this.symTable.enter(variableDecl.name, variableDecl, SymKind.Variable);
}
}
然后我们要基于符号表做引用消解,需要对AST再做第二次的遍历:
/**
* 引用消解
* 遍历AST。如果发现函数调用和变量引用,就去找它的定义。
*/
export class RefResolver extends AstVisitor{
symTable:SymTable;
constructor(symTable:SymTable){
super();
this.symTable = symTable;
}
//消解函数引用
visitFunctionCall(functionCall:FunctionCall):any{
let symbol = this.symTable.getSymbol(functionCall.name);
if (symbol != null && symbol.kind == SymKind.Function){
functionCall.decl = symbol.decl as FunctionDecl;
}
else{
if (functionCall.name != "println"){ //系统内置函数不用报错
console.log("Error: cannot find declaration of function " + functionCall.name);
}
}
}
//消解变量引用
visitVariable(variable: Variable):any{
let symbol = this.symTable.getSymbol(variable.name);
if (symbol != null && symbol.kind == SymKind.Variable){
variable.decl = symbol.decl as VariableDecl;
}
else{
console.log("Error: cannot find declaration of variable " + variable.name);
}
}
}
好了,现在我们通过新建符号表升级了我们的引用消解功能。有了符号表的支持,我们在程序中使用变量时,就可以直接从符号表里知道变量的类型,调用一个函数时,也能够直接从符号表里找到该函数的代码,也就是函数声明中的函数体。不过,还有一个语义分析功能也最好现在就实现一下,就是与类型处理有关的功能。
相比JavaScript,TypeScript的一个重要特性,就是可以清晰地指定类型,这能够在编译期进行类型检查,减少程序的错误。比如,在下面的程序中,myAge是number类型的。这时候,如果你把一个字符串赋值给myAge,TypeScript编译器就会报错:
let myAge:number;
myAge = "Hello";
运行TypeScript编译器,报错信息如下:

那么,如何检查程序中的类型是否匹配呢?这需要用到一种叫做属性计算的技术。它其实就是给AST节点附加一些属性,比如类型等。然后通过一些AST节点的属性,去计算另一些节点的属性。
其实,对表达式求值的过程,就可以看做是属性计算的过程,这里的属性就是表达式的值。我们通过遍历AST,可以通过叶子节点的值逐步计算更上层节点的值。
类似的技术还可以用于计算类型。比如,对于myAge = "Hello"这个表达式对应的AST节点,我们可以设置两个属性:一个属性是type_req,也就是赋值操作中,左边的变量所需要的类型;另一个属性是type,也就是=号右边的表达式实际的类型。
所谓类型检查,就是检查这两个类型是否匹配就可以了。其中,type_req可以通过查符号表获得,也就是在声明myAge时所使用的类型。而=号右边表达式的type属性,可以像计算表达式的值一样,自底向上逐级计算出来。
对于当前例子来说,我们一下子就能知道“Hello”字面量是字符串型的。如果是一个更复杂一点的表达式,比如"Hello"+3 * 5,它的类型就需要自底向上的逐级计算得到。这种自下而上逐级计算得到的属性,我们把它叫做综合属性(Synthesized Attribute)。
还有一个与综合属性相对应的概念,叫继承属性(Inherited Attribute),它是指从父节点或者兄弟节点计算出来的属性,这里我举一个例子来帮助你理解一下。
其实在解释器执行“a+3”和“a=3”这两个表达式的时候,对这两个变量a的操作是不一样的。对于“a+3”,只需要取出a的值就行了。而对于“a=3”,则需要给a赋一个新的值。a如果在赋值符号的左边,我们就叫它左值,其他情况就叫右值。
为了让解释器顺利地运行,我们在遍历AST的时候,需要知道当前的这个变量是左值还是右值。所以,我就给表达式类型的AST节点添加了一个isLeftValue的属性。这个属性呢,是一个典型的继承属性,因为它的值是通过上级节点计算得到的。当变量是赋值运算符的第一个子节点的时候,它是个左值。
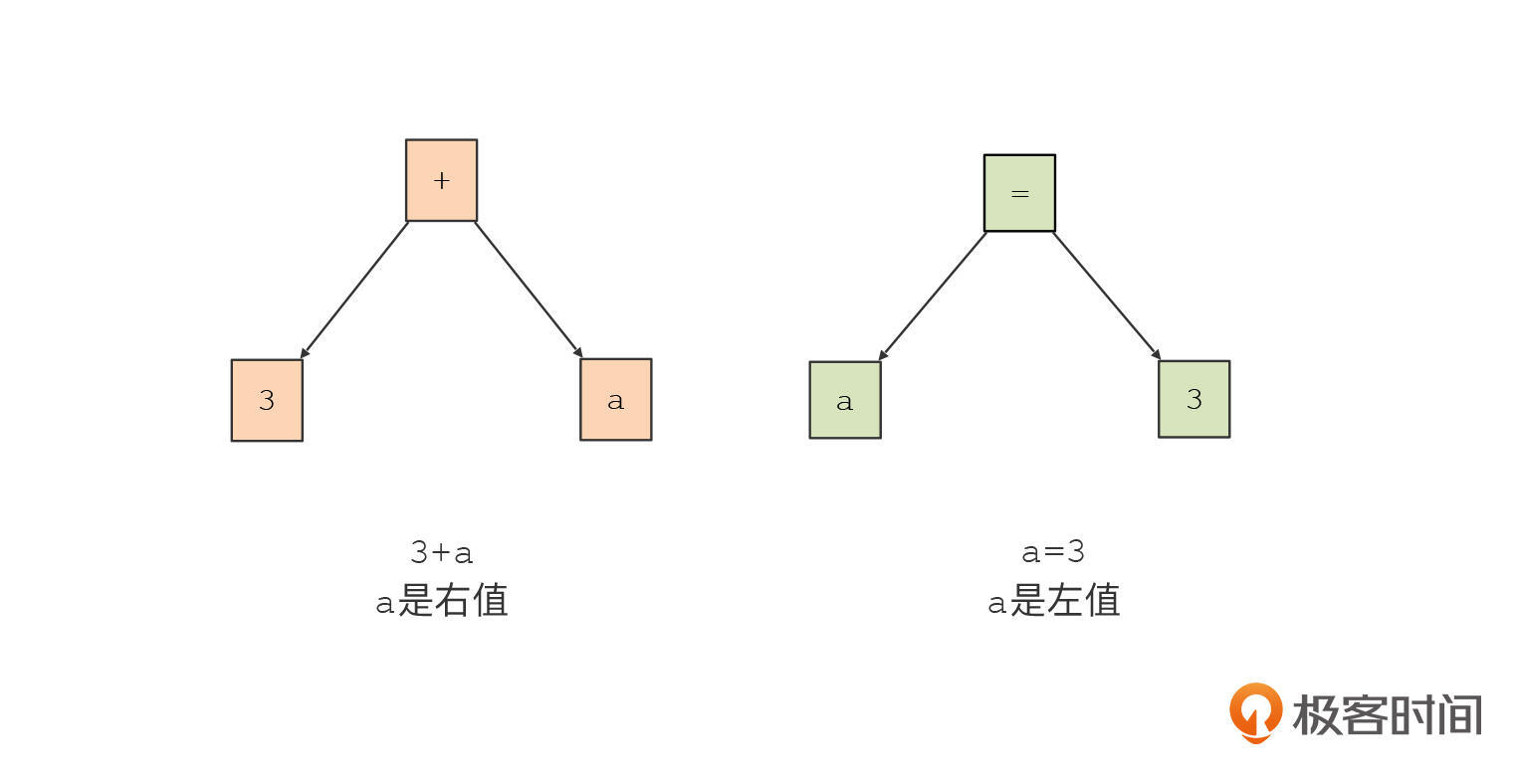
现在我们再回到类型计算。知道了类型检查的思路,我们其实还可以再进一步,进行类型的推断。
在类型声明的语法规则中,我们会发现typeAnnotation是可选的。当你不显式规定类型的情况下,其实TypeScript是可以根据变量初始化部分的类型,来进行类型推论的。比如下面的例子中,myAge的类型可以被自动推断出来是number,这样第二个赋值语句就会被报错。
let myAge = 18;
myAge = "Hello";
好了,现在我们已经做了引用消解和类型处理这两项关键的语义分析工作。不过,要保证一个程序正确,还要做很多语义分析工作。
语义分析的工作其实比较多和杂的。语言跟语言的差别,很多情况下也体现在语义方面。对于我们当前的语言功能,还需要去做的语义分析功能包括:
实际上,在JavaScript语言的标准(ECMAScript语言规格2015版)中,大量的内容都是对语义的规定,比如下面的截图中,就是对+号运算符的语义规定。

不过,这些语义分析和处理工作通常并不复杂,大部分都可以通过遍历AST来实现。我也给出了参考实现,你可以查阅相关的代码。
做完语义分析工作以后,我们基本上就能够保证程序的正确性了。接下来,我们要对解释器做一下提升,让它也能够支持变量声明和赋值。
让目前的解释器支持变量,其实比较简单,我们只需要有一个机制能够保存变量的值就可以了。
在我的参考实现里,我用了一个map的数据结构来保存每个变量的值。解释器可以从map里查找一个变量的值,也可以更新某个变量的值,具体你可以看下面这些代码:
**
* 遍历AST,并执行。
*/
class Intepretor extends AstVisitor{
//存储变量值的区域
values:Map<string, any> = new Map();
/**
* 变量声明
* 如果存在变量初始化部分,要存下变量值。
*/
visitVariableDecl(variableDecl:VariableDecl):any{
if(variableDecl.init != null){
let v = this.visit(variableDecl.init);
if (this.isLeftValue(v)){
v = this.getVariableValue((v as LeftValue).variable.name);
}
this.setVariableValue(variableDecl.name, v);
return v;
}
}
/**
* 获取变量的值。
* 这里给出的是左值。左值既可以赋值(写),又可以获取当前值(读)。
* @param v
*/
visitVariable(v:Variable):any{
return new LeftValue(v);
}
//获取变量值
private getVariableValue(varName:string):any{
return this.values.get(varName);
}
//设置变量值
private setVariableValue(varName:string, value:any):any{
return this.values.set(varName, value);
}
//检查是否是左值
private isLeftValue(v:any):boolean{
return typeof (v as LeftValue).variable == 'object';
}
//省略其他部分...
}
这样,通过引入一个简单的map,我们的程序在每一次引用变量时,都能获得正确的值。当然,这个机制目前是高度简化的。我们在后面会持续演化,引入栈帧等进一步的概念。
好了,现在我们的功能又得到了提升,你可以编写几个程序试一下它的能力。我编写了下面的一个程序,你可以试试看它的运行结果是什么。
/**
* 示例程序,由play.js解析并执行。
* 特性:对变量的支持。
*/
//那年才18
let myAge:number = 18;
//转眼10年过去
myAge = myAge + 10;
println("myAge is: ");
println(myAge);
今天这节课,我们为了让程序支持变量,分别升级了语法分析、语义分析和解释器。通过这种迭代开发方式,我们可以让语言的功能一点点的变强。
在今天的旅程中,我希望你能记住下面这几个关键点:
首先,我给你演示了如何增加新的语法规则,在这里你要继续熟悉如何用EBNF来书写语法规则。然后,我也给你说明了如何通过计算First和Follow集合来使用LL算法,你要注意EBNF里所有带?号或者 * 号、+号的语法成分,都需要计算它的Follow集合,以便判断到底是解析这个语法成分,还是跳过去。通过这样一次次的练习,你会对LL算法越来越熟练。
在语义分析部分,我们引入了符号表这个重要的数据结构,并通过它简化了引用消解机制。我们在后面的课程还会深化对符号表的理解。
另外,与类型有关的处理也很重要。你可以通过属性计算的方式,实现类型的检查和自动推断。你还要记住,语义分析工作的内容是很多的,建立符号表、引用消解和类型检查是其中的重点工作,但还有很多其他语义分析工作。
最后,解释器如果要支持变量,就必须要能够保存变量在运行时的值。我们是用了一个map数据结构来保存变量的值,在后面的课程里,我们还会升级这个机制。
不过,我们现在只能在顶层代码里使用变量。如果在函数里使用,还有一些问题,比如作用域和局部变量的机制、函数传参的机制、返回值的机制等等。我们会在下一节去进一步升级我们的语言,让它的功能更强大。
今天的思考题,我想问下你,在变量声明的语法规则中,你能否计算出typeAnnotation的Follow集合都包含哪些元素?欢迎在留言区给我留言。
感谢你和我一起学习,如果你觉得这节课讲得还不错,也欢迎分享给更多感兴趣的朋友。我是宫文学,我们下节课见。