
你好,我是宫文学。
我们现在的语言已经支持表达式、变量和函数了。可是你发现没有,到现在为止,我们还没有支持流程控制类的语句,比如条件语句和循环语句。如果再加上这两类语句的话,我们的语言就能做很复杂的事情了,甚至你会觉得它已经是一门比较完整的语言了。
那么今天,我们就来加上条件语句和循环语句。在这个过程中,我们会加深对作用域和栈桢的理解,包括跨作用域的变量引用、词法作用域的概念,以及如何在运行时访问其他作用域的变量。这些知识点会帮助你加深对计算机语言的运行机制的理解。
而这些理解和认知,会有助于我们后面把基于AST的解释器升级成基于字节码的解释器,也有助于我们理解编译成机器码后的运行时机制。
好了,首先我们先从语法层面支持一下这两种语句。
按照惯例,我们首先要写下新的语法规则,然后使用LL算法来升级语法分析程序。新的语法规则如下:
ifStatement
: If '(' expression ')' statement (Else statement)?
;
forStatement
:For '(' expression? ';' expression? ';' expression? ')' statement
;
statement:
: block
| functionDecl
| varaibleStatement
| expressionStatement
| returnStatement
| ifStatement
| forStatement
| emptyStatement
;
你从上面的语法可以得到这几个信息:
首先,if语句中,else部分是可选的。这样,我们在解析完if条件后面的语句以后,要去看看后面跟着的是不是’else’关键字,从而决定是否解析else后面的语句块。更具体的你可以参见parseIfStatement函数的代码。
第二,在for循环语句中,for括号里用分号分割的三个表达式都是可选的,在解析的时候也要根据Follow集合来判断是否需要解析这三个表达式。这点你具体可以参见parseForStatement函数的代码。
最后,从statement的语法规则中,我们也可以发现,我们的语言所支持的语句越来越多了,这也使得语言特性越来越丰富了。
现在,升级我们的语法解析程序,对你来说已经没有太大的困难了,你可以参照我的参考实现动手自己做一下。
不过,为了实现for语句,我们还有一个语言特性需要升级一下,这就是对一元运算的支持。
哪些是一元运算呢?比如,在for语句中,我们经常会使用下面的写法:
for(i = 0; i< 10; i++)
其中i++就是使用了一元运算。在这里,为了方便,我们干脆就让程序支持所有的一元运算!
一元运算符除了++以外,还有–、~、!等。甚至还有更复杂一点的情况,+号和-号除了作为二元运算符以外,还可以作为一元运算符使用,比如下面这个例子:
myAge = +myAge + -10;
你甚至可以将多个一元运算符叠加使用,比如我们把上面的例子修改一下,仍然和原来的计算结果相同:
myAge = + +myAge + - - -10;
注意了,这里面的两个+号或两个-号之间是留有空格的,否则就会被词法分析程序识别成++和–了。
上面的示例程序有一些负数,比如-10。在这里,-10是一个表达式,由一个符号和一个字面量构成,而不是把-10整体上作为一个字面量。
在第二节介绍词法分析的时候,我曾经留了个思考题,问像-3这样的负数,是识别成-号和3,还是把-3整体作为一个Token识别出来?
答案是前者。原因是,如果不这样处理,2-3这样的表达式就会识别错。在词法分析阶段,我们只需要把-号作为Token识别出来就行了,至于它是作为一元运算符还是二元运算符来使用,那就交给语法分析程序来处理吧!
为了支持一元运算,我们需要把与表达式相关的语法规则升级一下:
expression: assignment;
assignment: binary (assignmentOp binary)* ;
binary: unary (binOp unary)* ;
unary: primary | prefixOp unary | primary postfixOp ;
primary: StringLiteral | DecimalLiteral | IntegerLiteral | functionCall | '(' expression ')' ;
prefixOp = '+' | '-' | '++' | '--' | '!' | '~';
postfixOp = '++' | '--';
在我们升级后的语法规则中,二元表达式能够分解成一元表达式,而一元表达式,又分成下面这三种情况。
第一种情况下,一元表达式就是一个基础表达式。
第二种情况是一个右递归的语法规则,可以由一个前缀一元运算符再加一个一元表达式组成,所以我们前面的“+ +myage”的表达式是正确的。
第三种情况,是一个基础表达式后面再跟上后缀一元运算符。后缀一元运算只有++和–两个,并且是不允许递归的,也就是说,像“myage++ ++”这样的表达式就是错误的。
具体解析一元表达式的代码你可以参见parseUnary函数。
我们可以试着用支持一元运算符的解析器解析下面的示例程序,这个示例程序中有很多个+号和-号,你第一眼看上去可能很难判断出它们分别属于哪个语法成分。
//示例代码:example_unary.ts
let myAge:number = 18;
myAge = + +myAge++ + - - -10;
println("myAge="+myAge);
但基于我们的语法规则,我们的解析器能够准确地分析出每个+号或-号所属的语法成分。比如,对于第二个语句,我们的解析器输出的AST是下图这个样子的,其中1个+号属于加法表达式,有两个+号和3个-号的都属于前缀一元运算符,而++号则属于后缀运算符。
那到此为止,我们的语法分析功能就升级完毕了。接下来,我们顺着已经养成的习惯,继续来看看这两个语句在语义方面有没有带来新的内容。
你会发现,在程序里用上if语句和for语句以后,一个直观的表现就是出现了很多的语句块,而这些语句块是能够影响作用域的。我们把这些语句块所构成的作用域,叫做块作用域。
在早期的JavaScript版本是不支持块作用域的,比如,在下面的程序中,我们在块的外面仍然可以访问变量i,并且打印出i的值。
function foo(){
{
var i = 4;
}
console.log(i);
}
foo();
但在ES6版本以后,JavaScript也支持了块作用域。你可以用let关键字在块中声明变量,这个变量的作用域仅限于当前块,如果从作用域外面访问,编译器就会报错。
function foo(){
{
let i = 4;
}
console.log(i); //报编译错误
}
foo();
在这种情况下,即使是块中变量的名称与块外的变量名相同也没关系。你看,在下面这个示例程序中,if语句块中的myAge和外面的myAge就是两个不同的变量,甚至类型都不相同。
function bar() {
let myAge = 18;
if (myAge < 30) {
let myAge = '';
myAge = 'young';
console.log("myAge, inside: " + myAge);
}
console.log("myAge, outside: " + myAge);
}
这个程序是可以正常运行的,在if块的内部和外部,都可以正常的打印myAge的值,但使用的是两个不同作用域中的变量。
你也看到了,块作用域的机制使得我们在语句块中使用变量名称的时候可以更加自由,不用担心在块中声明的变量会影响到块外面,从而减少了程序出错的概率,也让程序员在书写逻辑的时候更加自由。
而且,上面的示例程序在编译过程中会形成下面这个Scope结构。你会看到,每个Block都形成了自己的作用域,所有这些作用域构成了一个树状结构。每个作用域,可以看到在该作用域中声明的符号,以及上面各级的符号,但看不到兄弟作用域和下级作用域的符号。

你要注意,if语句的条件部分和if下面的块其实属于两个作用域。在if条件中的myAge变量,指的是外面的这个myAge,它是number型的,因此我们把它用在“myAge<30”这样一个条件表达式里。
读到这里,你可能产生一个疑问:在语句块中,如果在声明新的myAge之前,是否也可以像在if的条件表达式里那样来使用外部的myAge变量呢?我们可以试一下,把程序改成下面的样子,看看会产生什么结果。
function bar() {
let myAge = 18;
if (myAge < 30) {
myAge = 30;
let myAge = '';
myAge = 'young';
}
}
你会发现,如果我们用Typescript编译,编译器会报错,说块中的myAge在没有初始化的时候,就被访问了:
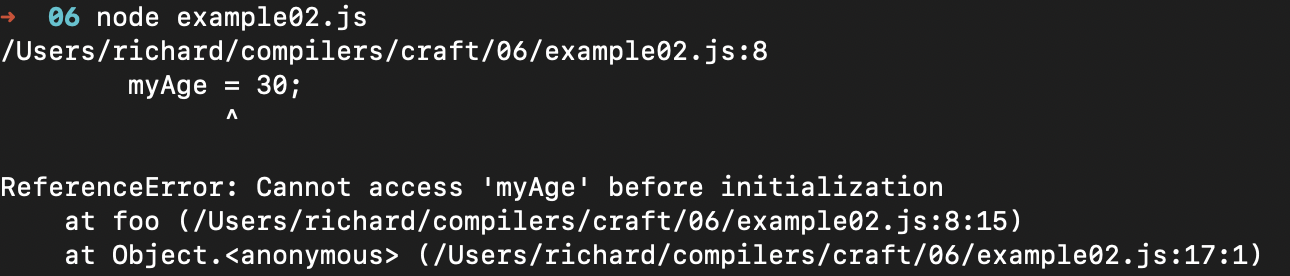
这个例子说明了,在TypeScript中,如果存在和外部同名的变量,那你只能引用块中声明的变量,是没有办法引用外部变量的,无论块中声明的变量的位置是靠前还是靠后。
那是不是所有的语言,对于块作用域都是这样规定的呢?不是的,你可以用不同的语言试验一下。
首先是Java语言。Java语言也支持块定义域,但不允许块中的变量与外部变量名称相同。
public static int bar(){
int myAge = 18;
if (myAge < 30) {
string myAge = "young"; //错误:变量名称重复
int yourAge = 20; //块中的变量
}
else{
int yourAge = 10; //第二个块中可以有同名的变量
}
return myAge + yourAge; //错误:找不到yourAge
}
再看看C语言。C语言允许在块中声明新的变量名称之前,引用外部的变量,也就是说,上面的示例代码如果用C语言改写一下,也是完全合法的。
void bar(){
int myAge = 18;
if (myAge < 30) {
myAge = 30; //给外层的myAge赋值
const char* myAge = "young"; //新声明一个myAge
printf("myAge=%s\n",myAge); //打印内层的myAge的值
}
printf("myAge=%d\n",myAge); //打印外层的myAge的值
}
那么,对于你日常使用的语言,在块作用域的语义上有什么不同呢?你也可以分析一下。
按照这节课对作用域的剖析方法,下次你再见到一段代码的时候,你可以迅速在大脑中划分出清晰的作用域的范围,形成作用域的树。作为语言的实现者,你也会对语言的特性有更加清晰的了解,这算是你学习这门课的额外收获吧!
那么,上面这些不同语言对于作用域的不同规定,会如何影响到语义分析程序呢?我们来看一下。
在前面的课程中,我们做语义分析的时候,分成了清晰的两个阶段:Enter阶段是建立符号表,Resolve阶段是去做引用消解。如果存在块内外变量同名的情况,在块中的变量引用,都会指向在块中声明的变量。
这种处理方法,对于C语言是不行的。使用上述方法,会导致第一个myAge引用的变量出错。也就是说,我们在做引用消解的时候,必须考虑语句的顺序,要注意我们在块中声明同名称的myAge之前,引用的实际是块外面的变量。
这就导致为C语言编写引用消解的程序要更复杂一些,建立符号表的工作和引用消解的工作必须是针对每一条语句同步去进行的。随着对每一个语句的扫描,符号表逐渐建立起来后,引用消解时总是指向最近的那一个声明。
我们现在的处理方法,用来处理Java程序,其实也是行不通的。在Java的块里,虽然不允许变量跟外部变量重名,但也必须是先声明后使用,所以也只能一边建符号表,一边做引用消解,这样才能发现在声明之前使用变量的错误。
那么,我们现在的处理方法,针对TypeScript或JavaScript(指ES6以上的版本)是不是就没有问题了呢?
其实还是有问题的,现在的算法没有办法检查出myAge在声明在前就被引用的错误,并像在Node.js里运行那样报错。
那要如何解决这个问题呢?其实只要把问题分析清楚了,解决起来也不是太难。
在我们的语义分析程序中,我们先用Enter类对AST做了一遍遍历,把包括变量的每个符号都正确地加入到了符号表中,也就是由Scope形成的一个层次数据结构。接下来,我们用RefResolver类对AST再做一次遍历,来建立引用消解,但在这次遍历中,我们用了一个临时的数据结构,来保存当前已经声明了的变量。
这样做的目的,是在引用消解的时候,我们既要看该变量是否属于该作用域,又要看当前该变量是否被声明了。如果该变量不属于当前作用域,那么我们就去引用外部作用域中的变量;而如果该变量属于当前作用域,那它必须在变量声明之后才能使用。
比如,对于下面程序中的"myAge = 30"这一行,编译器会认为这个myAge是块中声明的那个string类型的myAge,而不是外部作用域中的myAge。同时,由于目前块中的myAge还没有声明,如果提前使用它是错误的。
function bar() {
let myAge = 18;
if (myAge < 30) {
myAge = 30; //编译错误
let myAge = '';
myAge = 'young';
}
}
我们可以画一张图来表现当编译器遍历到“myAge=30;”这个语句的时候,相关内部状态信息的情况,以及编译器是如何决策的。

你看,在遍历AST的过程中,我们的语义分析程序会不断更新一个集合中的值,这个集合就是“已声明的变量”。同时,我们的语义分析程序还会知道当前作用域中变量的集合的值。对比这两个集合的值,程序就会发现那些在声明之间就被使用的变量,并报错。
这种随着程序的执行流程,去动态计算一些数据的值,并根据这些值来做分析的方法,叫做数流分析框架。数据流分析框架在做语义分析和代码优化的时候都很有用,我们后面还会见到它的更多用途。
好了,理解了原理,写代码就简单了,你可以参考RefResolver类中我给出的示例代码。
不过,关于引用消解,我还要再补充两个语义规则,这两个规则我们也要在算法中有所体现:
第一,在TypeScript中,函数的声明和引用的顺序是不受限制的。也就是说,完全可以声明在后,使用在前。所以,在引用消解程序中,处理变量的消解算法和函数的消解的算法是不同的。
第二,在同一个作用域中,不可以有名称相同的符号,变量和函数的名称也不可以冲突。所以,我在Scope类的设计中,使用了一个以名称为key,以符号为value的Map对象来保存该作用域中的符号,就隐含了名称唯一的要求。
好了,关于语义分析工作,我们就到这里。接下来,我们继续完成这节课的工作,让我们目前的解释器也能支持if语句和for语句。
首先看if语句。在解释器里,我们实现了visitIfStatement()方法,用于执行if语句。你可以看看下面的这个示例代码:
/**
* 执行if语句
* @param ifStmt
*/
visitIfStatement(ifStmt:IfStatement):any{
//计算条件
let conditionValue = this.needLeftValue(this.visit(ifStmt.condition));
//条件为真,则执行then部分
if (conditionValue){
return this.visit(ifStmt.stmt);
}
//条件为false,则执行else部分
else if (ifStmt.elseStmt !=null){
return this.visit(ifStmt.elseStmt);
}
}
这个逻辑是很清晰的。首先我们来计算if条件的值,如果为真,则执行if后面的语句或语句块;如果为假,则执行else后面的语句或语句块。
实现for循环的思路也差不多,遵循for语句的语义来运行就行了,你可以参考下面的示例代码:
/**
* 执行for语句
* @param forStmt
*/
visitForStatement(forStmt:ForStatement):any{
//执行init
if(forStmt.init !=null){
this.visit(forStmt.init);
}
//计算循环结束的条件
let notTerminate = forStmt.termination == null ? true : this.visit(forStmt.termination);
while(notTerminate){
//执行循环体
let retVal = this.visit(forStmt.stmt);
//处理循环体中的Return语句
if (typeof retVal == 'object' && ReturnValue.isReturnValue(retVal)){
// console.log("is ReturnValue!!")
return retVal;
}
//执行递增部分
if (forStmt.increment!=null){
this.visit(forStmt.increment);
}
//执行循环判断
notTerminate = forStmt.termination == null ? true : this.visit(forStmt.termination);
}
}
其中,循环的初始化部分在一开始执行的,而且只执行一次,接着我们就要计算循环的终止条件。如果不满足终止条件,则开始进入循环。每次循环,首先执行循环体,然后执行递增部分的语句,最后再检查一遍循环退出条件。
你可以写几个例子来测试if语句和for循环语句是否能正确运行。在这里,我提供了一个计算斐波那契数列的示例程序给你参考:
function fibonacci(n:number):number{
if (n <= 1){
return n;
}
else{
return fibonacci(n-1) + fibonacci(n-2);
}
}
for (let i:number = 0; i< 32; i++){
println(fibonacci(i));
}
这个程序不仅演示了if语句和for循环,还演示了函数的递归调用。运行这个程序,就会打印出一个斐波那契数列,如下图所示:
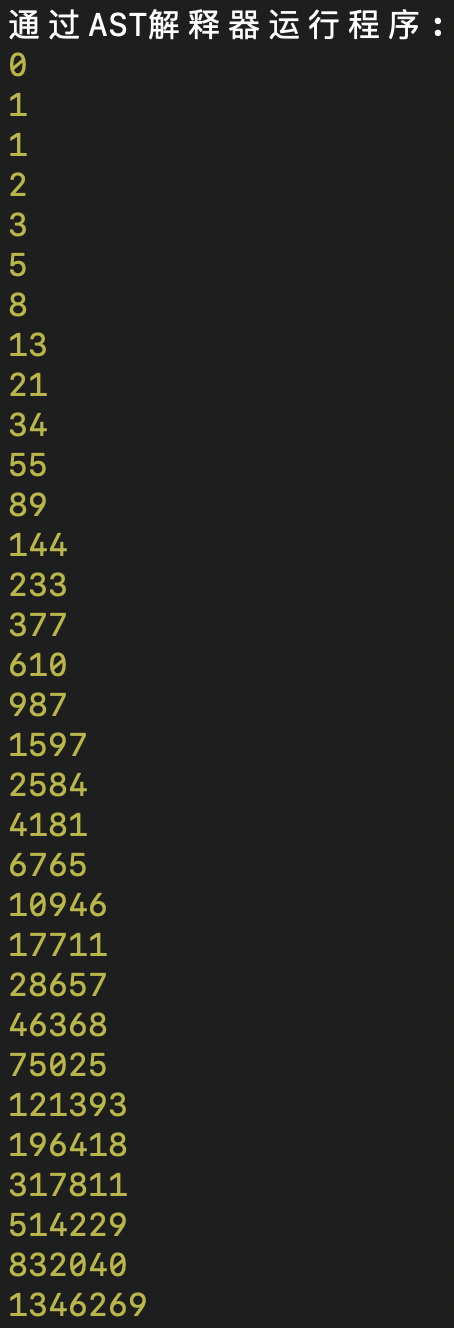
好了,到这里我们今天这节课就讲完了,我们来简单回顾一下。
这节课我们增加了对流程控制类语句的支持。在支持了if语句和for循环语句之后,我们的语言特性已经很丰富了,我们已经可以用这些特性编写很复杂的程序了,比如生成斐波那契数列的示例程序。
在这个过程中,最重要的知识点是对块作用域的理解。不同的语言在块作用域上的特性是不同的,所以我们要采用不同的算法来做引用消解。
TypeScript允许在块中声明新的变量覆盖外部作用域中的变量,块中所有该名称的变量都会引用这个新变量,但必须先声明再使用。TS的这个特点,就要求我们的算法要采用数据流分析框架,在遍历AST的过程中,知道某个变量在当前代码的位置是否已经被声明过了。你先把数据流分析框架记住,它非常有用,我们后面还会有很多场景要用到它。
此外,我们为了支持For循环,还增加了对一元运算符的支持。像++和–这样的运算符,在求值和未来生成字节码方面都有一些特殊性,你可以多注意示例代码对它们的处理。
今天的思考题,我想问一下,对于for循环语句来说,一般包含几层的作用域?为什么?你可以运行一个例子,看看打印出来的符号表的层次,验证一下你的想法,欢迎在留言区留言。
感谢你和我一起学习编程语言,也欢迎你将这门课分享给更多对编程语言感兴趣的朋友。我是宫文学,我们下节课见。