你好,我是宫文学。
在上一节课里,我们已经实现了一个简单的虚拟机。不过,这个虚拟机也太简单了,实在是不够实用啊。
那么,今天这节课,我们就来增强一下当前的虚拟机,让它的特性更丰富一些,也为我们后续的工作做好铺垫,比如用C语言实现一个更强的虚拟机。
我们在这一节课有两项任务要完成:
首先,要支持if语句和for循环语句。这样,我们就能熟悉与程序分支有关的指令,并且还能让虚拟机支持复杂一点的程序,比如我们之前写过的生成斐波那契数列的程序。
第二,做一下性能比拼。既然我们已经完成了字节码虚拟机的开发,那就跟AST解释器做一些性能测试,看看性能到底差多少。
话不多说,开干!首先,我们来实现一下if语句和for循环语句。而实现这两个语句的核心,就是要支持跳转指令。
if语句和for循环语句,有一个特点,就是让程序根据一定的条件执行不同的代码。这样一个语法,比较适合我们人类阅读,但是对于机器执行并不方便。机器执行的代码,都是一条条指令排成的直线型的代码,但是可以根据需要跳转到不同的指令去执行。
针对这样的差异,编译器就需要把if和for这样结构化编程的代码,转变成通过跳转指令跳转的代码,其中的关键是计算出正确的跳转地址。
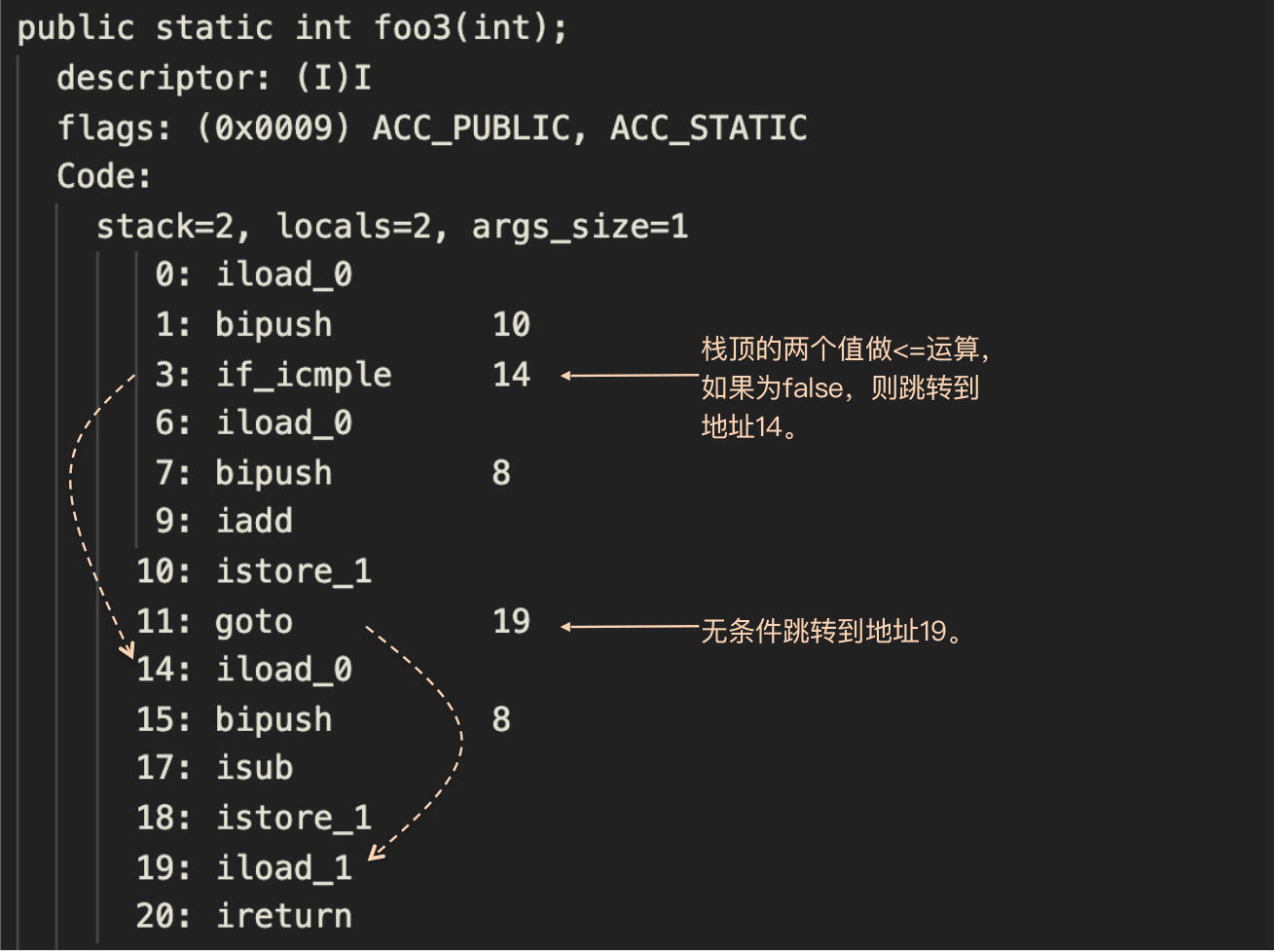
我们举个例子来说明一下,下面是我用Java写的一个示例程序,它有一个if语句。
public static int foo3(int a){
int b;
if (a > 10){
b = a + 8;
}
else{
b = a - 8;
}
return b;
}
我们先用javac命令编译成.class文件,然后再用javap命令以文本方式显示生成的字节码:
我主要是想通过这个示例程序,给你展现两条跳转指令。
一条是if_icmple,它是一条有条件的跳转指令。它给栈顶的两个元素做<=(less equal,缩写为le)运算。如果计算结果为真,那么就跳转到分支地址14。

你可能会发现一个问题,为什么我们的源代码是>号,翻译成字节码却变成了<=号了呢?没错,虽然符号变了,但其实我们的语义并没有发生变化。
我给你分析一下,在源代码里面,程序用>号计算为真,就执行if下面的块;那就意味着如果>号计算为假,或者说<=号为真,则跳转到else下面的那个块,这两种说法是等价的。
但现在我们要生成的是跳转指令,所以用<=做判断,然后再跳转,就是比较自然了。具体你可以看看我们下文中为if语句生成代码的逻辑和相关的图,就更容易理解了。
你在字节码中还会看到另一个跳转指令,是goto指令,它是一个无条件跳转指令。
在计算机语言发展的早期,人们用高级语言写程序的时候,也会用很多goto语句,导致程序非常难以阅读,程序的控制流理解起来困难。虽然直到今天,C和C++语言里还保留了goto语句。不过,一般不到迫不得已,你不应该使用goto语句。
这种迫不得已的情况,我指的是使用goto语句实现一些奇特的效果,这些效果是用结构化编程方式(也就是不用goto语句,而是用条件语句和循环语句表达程序分支)无法完成的。比如,采用goto语句能够从一个嵌套很深的语句块,一下子跳到外面,然后还能再跳进去,接着继续执行!这相当于能够暂停一个执行到一半的程序,然后需要时再恢复上下文,接着执行。
我在说什么呢?这可以跟协程的实现机制关联起来,协程要求在应用层把一个程序停止下来,然后在需要的时候再继续执行。那么利用C/C++的goto语句的无条件跳转能力,你其实就可以实现一个协程库,如果你想了解得更具体一些,可以看看我之前的《编译原理实战课》。
总结起来,goto的这种跳转方式,是更加底层的一种机制。所以,在编译程序的过程中,我们会多次变换程序的表达方式,让它越来越接近计算机容易理解的形式,这个过程叫做Lower过程。而Lower到一定程度,就会形成线性代码加跳转语句的代码格式,我们有时候就会把这种格式的IR叫做“goto格式(goto form)”。
好了,刚才聊的关于goto语句的这些知识点,是为了加深大家对它的认识,希望能够对你的编程思想有所启发。
回到正题,现在我们已经对跳转指令有了基本的认识,那么我就把接下来要用到的跳转指令列出来,你可以看看下面这两张表:
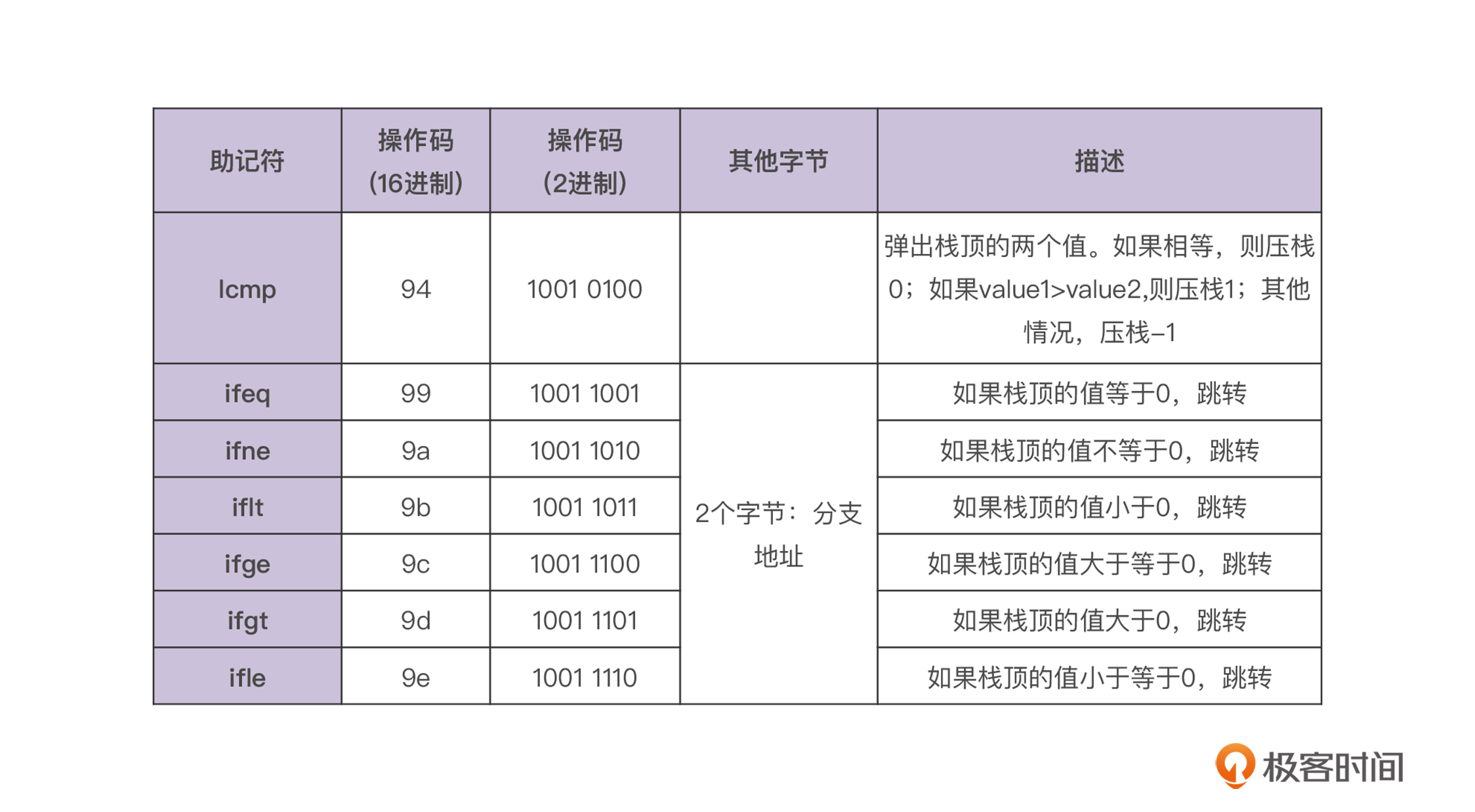
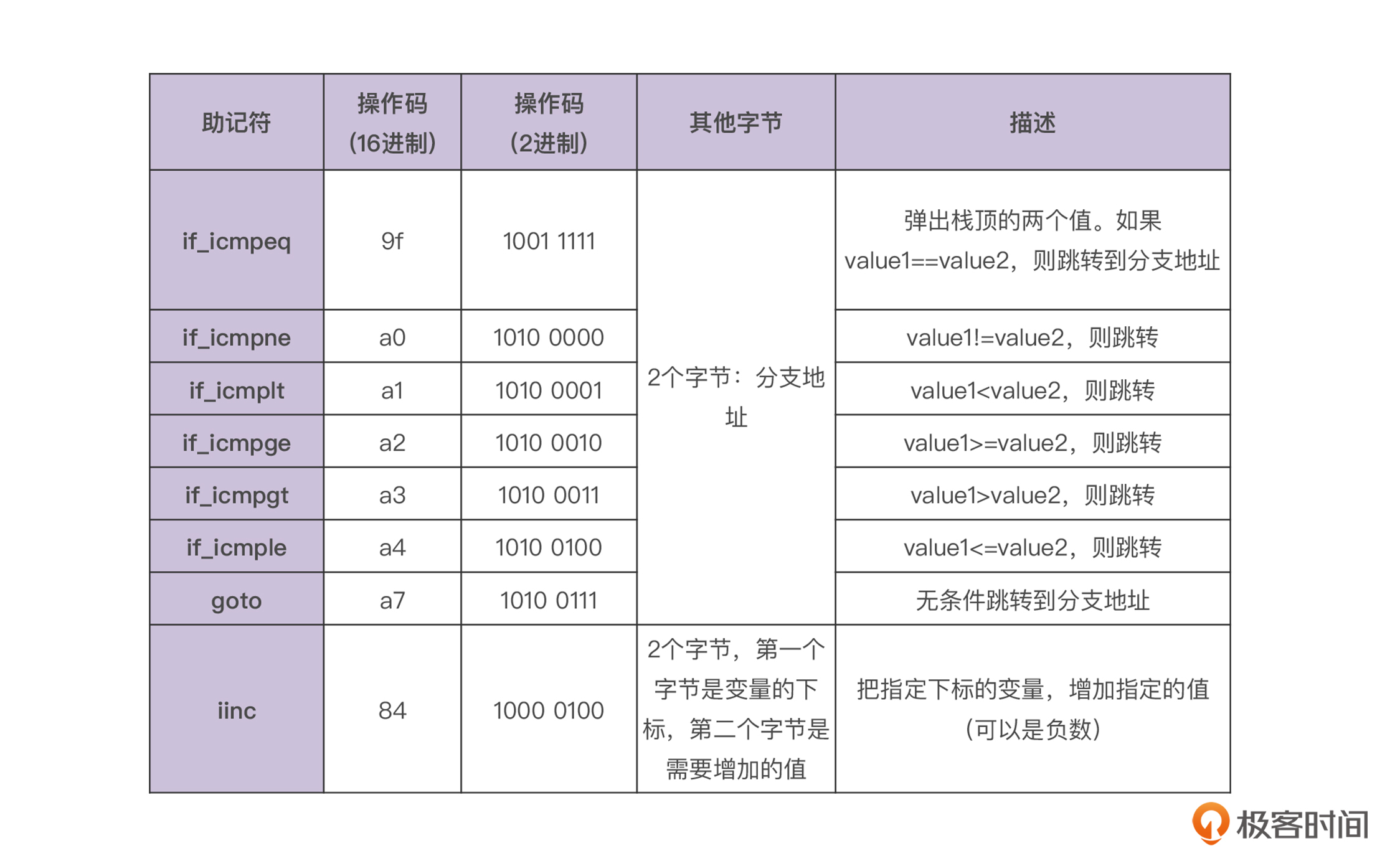
如果后面要增加对浮点数和对象引用的比较功能,我们可以再增加一些指令。但由于目前我们还是只处理整数,所以这些指令就够了。
接着,我们就修改一下字节码生成程序和虚拟机中的执行引擎,让它们能够支持if语句和for语句。
让if语句生成字节码的代码你可以参考visitIfStatement方法。在这个方法里,我们首先为if条件、if后面的块、else块分别生成了字节码。
//条件表达式的代码
let code_condition:number[] = this.visit(ifstmt.condition);
//if块的代码
let code_ifBlock:number[] = this.visit(ifstmt.stmt);
//else块的代码
let code_elseBlock:number[] = (ifstmt.elseStmt == null) ? []: this.visit(ifstmt.elseStmt);
接下来,我们要把这三块块代码拼接到一起,这就需要计算出每块代码的起始地址,以便跳转语句能够做出正确地跳转。比如,if块的起始位置是代码条件块的长度加3,这个3是我们生成的跳转指令的长度。
let offset_ifBlock:number = code_condition.length + 3; //if语句块的地址
let offset_elseBlock:number = code_condition.length + code_ifBlock.length + 6; //else语句块的地址
let offset_nextStmt:number = offset_elseBlock + code_elseBlock.length; //if语句后面跟着下一个语句的地址
计算出每块代码的起始地址后,接下来我们就说说如何生成跳转指令。
在前面Java生成的字节码中,我们看到编译器对于“a>10”生成了一条“if_icmple”指令。但我为了生成代码的逻辑更简单,采用了另一个实现思路。也就是先对a>10做计算,如果结果为真,就在栈顶放一个1,否则就放一个0。
接下来,我们再生成一条ifeq指令,根据栈顶的值是1还是0来做跳转。那么这个ifeq指令就要占据3个字节,其中操作码占1个字节,操作数占两个字节。我的算法生成了两条指令,你也可以思考一下如何能够像Java编译器那样只生成一条指令。
计算好偏移量以后,我们就可以把condition块、if块和else块的代码拼接成完整的if语句的代码了:
//条件
code = code.concat(code_condition);
//跳转:去执行else语句块
code.push(OpCode.ifeq);
code.push(offset_elseBlock>>8);
code.push(offset_elseBlock);
//条件为true时执行的语句
code = code.concat(code_ifBlock);
//跳转:到整个if语句之后的语句
code.push(OpCode.goto);
code.push(offset_nextStmt>>8);
code.push(offset_nextStmt);
//条件为false时执行的语句
code = code.concat(code_elseBlock);
你也看到了,在示例代码中,我们生成了两个跳转指令,分别是ifeq指令和goto指令,这样就能保证所有语句块之间正确的跳转关系。
那到这里,是不是就大功告成了,为if语句生成了正确的字节码了呢?
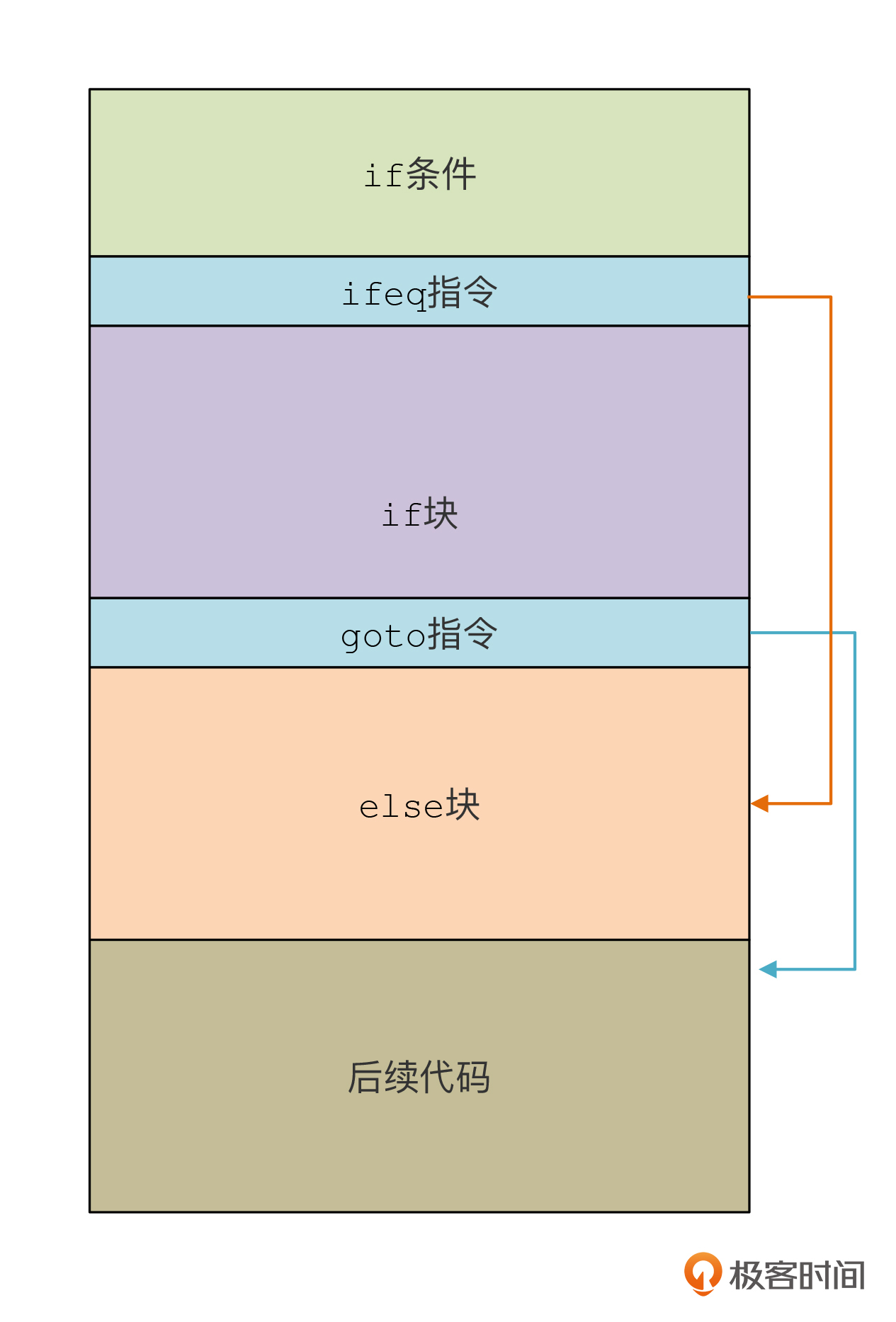
不是的。你仔细体会一下,是不是有点什么不对劲?哪里不对劲呢?
你看,在我们生成的跳转指令中,一定要设置好正确的跳转地址,否则代码就错误了。可是,在if块和else块的代码中可能也包含了跳转指令呀。现在你把if语句中的各个块拼成了一个整体的字节码数组,那么各个块中包含的跳转指令的地址就错了呀。原来的跳转地址,都是基于各自的字节码数组中的位置,现在拼成一个新数组,这个位置也就变了。
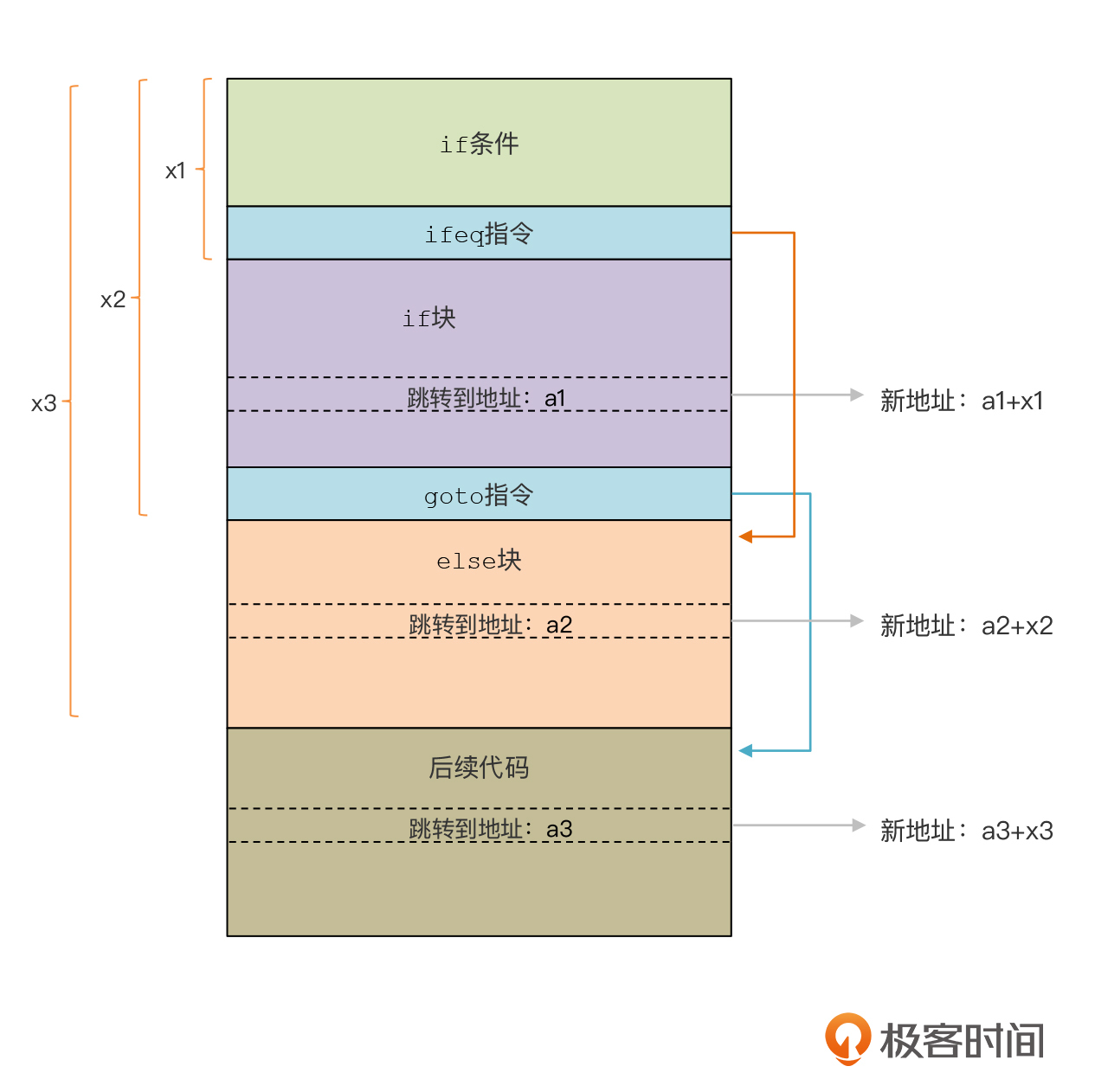
所以,这些跳转指令的跳转地址,都需要做一下调整,加上我们计算出来的偏移量,来保证整体的跳转不出问题。
this.addOffsetToJumpOp(code_ifBlock, offset_ifBlock);
this.addOffsetToJumpOp(code_elseBlock, offset_elseBlock);
其实,这个调整跳转指令地址的过程,是每次做代码拼接的时候都会被调用的。比如,当前if语句生成的代码,在上一级的AST节点中做拼接的时候,也需要做地址的调整,这样就会保证为函数最终生成的字节码中,每个跳转指令的地址都是正确的。
实现完了If语句,你可以再实现一下for循环语句。for循环语句的实现思路也是差不多的,都是先生成各个部分的代码,然后再正确地拼接到一起。
好了,到目前为止,我们已经扩展了字节码编译器的功能,让它能够为if语句和for循环语句正确地生成字节码了。接下来,我们再扩展一下字节码解释器的功能,让它能够正确地运行这些跳转指令就行了。
对于ifeq、ifneq、if_cmplt等跳转指令,解释器的处理逻辑差不多都是一样的。它在遇到这些指令的时候,都会计算一下栈顶的值是否符合跳转条件。如果符合,就计算出一个新的指令地址并跳转过去。否则,就顺序执行下一条指令就可以了。
case OpCode.ifeq:
byte1 = code[++codeIndex];
byte2 = code[++codeIndex];
//如果栈顶的值是0,那么就计算一个新的指令地址,以便跳转过去
if(frame.oprandStack.pop() == 0){
codeIndex = byte1<<8|byte2;
opCode = code[codeIndex];
}
//否则,就继续执行下一条指令
else{
opCode = code[++codeIndex];
}
在增加了对跳转指令的支持以后,我们就完成了对虚拟机的升级工作。现在,我们已经拥有两个运行时了,一个是AST解释器,一个是字节码虚拟机。在我们启动字节码虚拟机的设计之前,我们曾经希望它能提升程序运行的性能。那现在是否达到了这个目标呢?让我们测试一下吧!
我们仍然采用斐波那契数列的例子来做性能测试。这个例子的好处,就是随着数列的变大,所需要的计算量会指数级地上升,所以更容易比较出性能差异来。现在,我们用AST解释器和字节码虚拟机都来执行下面的代码:
function fibonacci(n:number):number{
if (n <= 1){
return n;
}
else{
return fibonacci(n-1) + fibonacci(n-2);
}
}
for (let i:number = 0; i< 26; i++){
println(fibonacci(i));
}
我让n依次取不同的数值,分别测量出两个运行时所花费的时间,做成了一个表格。
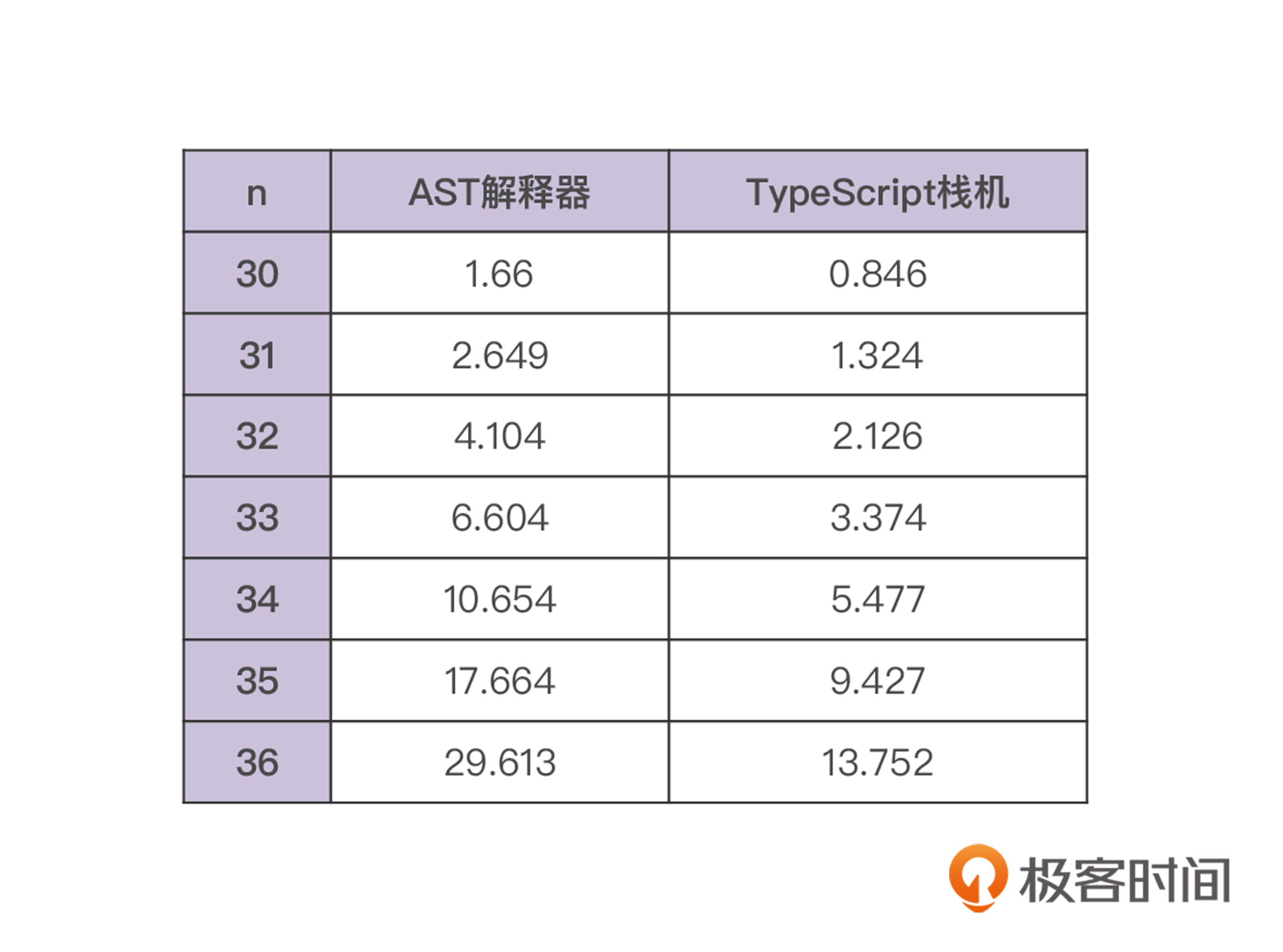
你可以从表格中看到,TypeScript栈机所花费的计算时间,基本上只是AST解释器的一半。所以,我们确实按照预期获得了性能上的提升。
如果把表格画成图表,就能更清晰地显示出运行速度变化的趋势。你能看出,这两条线都是指数上升的,并且栈机花费的时间始终只有AST解释器的一半。
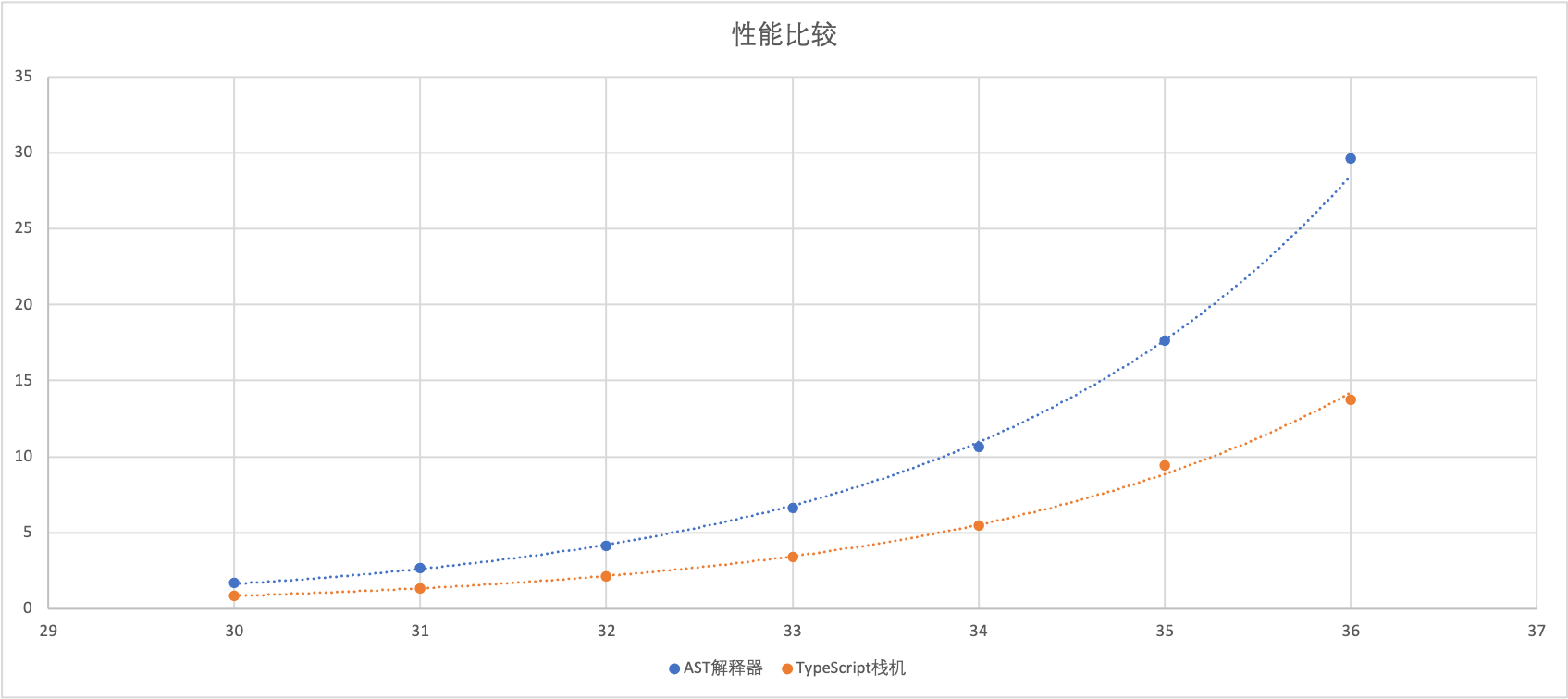
好了,我们的第一个版本的虚拟机已经完成了。在性能方面,也确实如我们所愿,获得了重大的提升,可以说比较圆满地完成了我们这节课的目标!
这节课,我们主要实现了对if语句和for循环语句的支持。在这个过程中,我们学习了一类新的指令,也就是跳转指令。你如果多接触几种指令集就会发现,包括物理CPU的指令集在内的各种指令集,都有跳转指令,并且名称也都差不多。所以,我们这里学到的知识,也有助于后面降低你学习汇编语言的难度。
在为跳转指令生成代码的时候,关键点是要正确地计算跳转地址,地址是相对于这个函数的字节码数组的开头位置的偏移量。只有在为整个函数都生成了字节码以后,我们才能计算出所有的基本块的准确起始地址。
最后,我们还对虚拟机的性能做了测试。现在的性能只提高了一倍,当生成的斐波那契数列比较大的时候,我还是觉得挺慢的。那么,我们能否有办法进一步提升虚拟机的性能呢?像JVM和V8这样的虚拟机,都是用C++写的。那么,如果采用C/C++这样的系统级语言写一个新版本的虚拟机,会不会获得性能上更大的提升呢?那么在下一节课,我们就动手实现一个C语言版本的虚拟机吧。
又来到了我们例行的思考题环节,我想问下,现在你对我们虚拟机的性能测试结果满意吗?你觉得我们还可以做哪些改进,来提升TypeScript版本的虚拟机的性能呢?欢迎在留言区留言。
感谢你和我一起学习,也欢迎你把这节课分享给更多对字节码虚拟机感兴趣的朋友。我是宫文学,我们下节课见。