我也把它们保存在栈桢里的位置画成了一张图,你可以看一下:
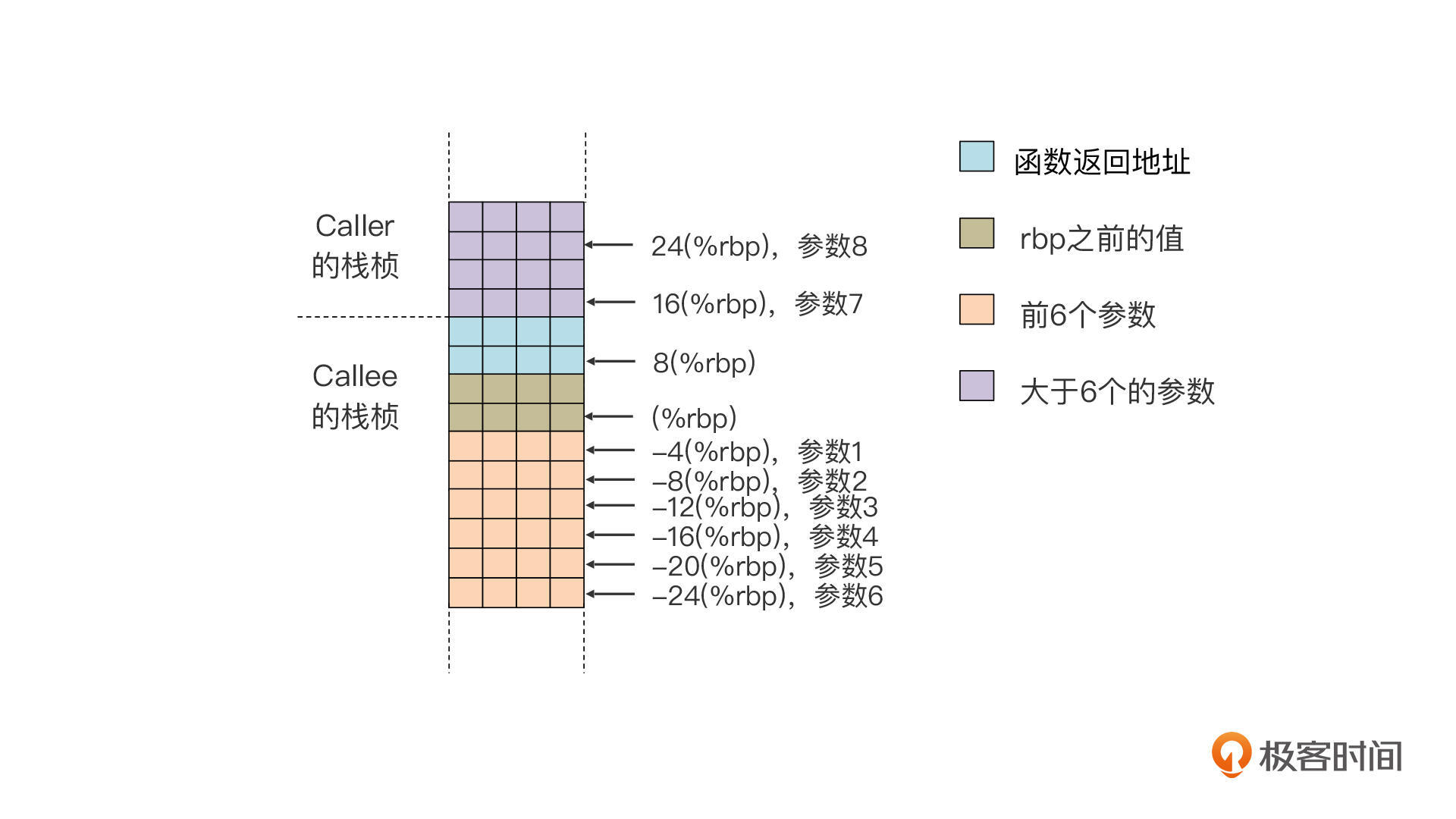
你可以看到,这里面的前6个参数的位置,都是从rbp的位置依次向下4个字节,也就是一个整数的位置。参数1是-4(%rbp),参数2是-8(%rbp),依此类推。
你好,我是宫文学。
在上一节课里,我们已经初步生成了汇编代码和可执行文件。不过,很多技术细节我还没有来得及给你介绍,而且我们支持的语言特性也比较简单。
那么,这一节课,我就来给你补上这些技术细节。比如,我们要如何把逻辑寄存器映射到物理寄存器或内存地址、如何管理栈桢,以及如何让程序符合调用约定等等。
好了,我们开始吧。先让我们解决逻辑寄存器的映射问题,这其中涉及一个简单的寄存器分配算法。
在上一节课,我们在生成汇编代码的时候,给参数、本地变量和临时变量使用的都是逻辑寄存器,也就是只保存了变量的下标。那么我们要怎么把这些逻辑寄存器对应到物理的存储方式上来呢?
我们还是先来梳理一下实现思路吧。
其实,我们接下来要实现的寄存器分配算法,是一个比较初级的算法。你如果用clang或gcc把一个C语言的文件编译成汇编代码,并且不带-O1、-O2这样的优化选项,生成出来的汇编代码就是采用了类似的寄存器分配算法。现在我们就来看看这种汇编代码在实际存储变量上的特点。
首先,程序的参数都被保存到了内存里。具体是怎么来保存的呢?你可以先看看示例程序param.c:
void println(int a);
int foo(int p1, int p2, int p3, int p4, int p5, int p6, int p7, int p8){
int x1 = p1*p2;
int x2 = p3*p4;
return x1 + x2 + p5*p6 + p7*p8;
}
int main(){
int a = 10;
int b = 12;
int c = a*b + foo(a,b,1,2,3,4,5,6) + foo(b,a,7,8,9,10,11,12);
println(c);
return 0;
}
这个示例程序所对应的汇编代码是param.s,我摘取了其中的一部分,这段代码展示了参数是如何被保存到内存的:
## 把参数值保存到内存
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl %edx, -12(%rbp)
movl %ecx, -16(%rbp)
movl %r8d, -20(%rbp)
movl %r9d, -24(%rbp)
在这个示例程序中,foo函数有8个参数。根据System V AMD64的ABI和C语言的调用约定,其中前6个参数是通过寄存器传递的,其他两个参数是通过栈桢传递的。
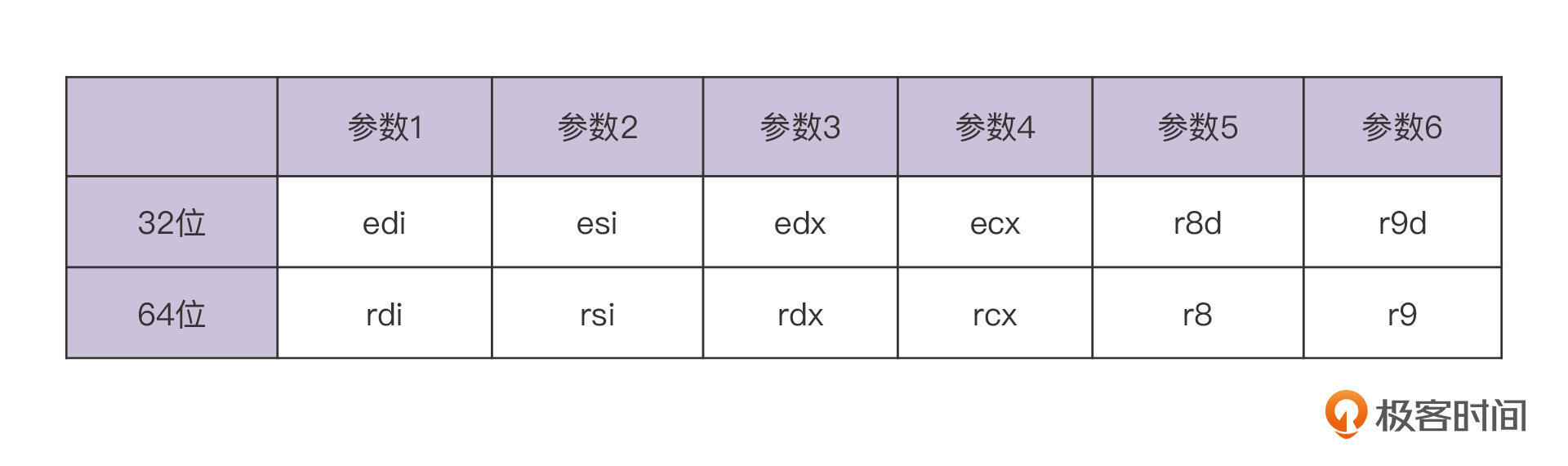
在汇编代码中,我们会发现这6个通过寄存器传递的参数,都先被保存到了栈桢中。这6个寄存器和参数的对应关系是这样的:
我也把它们保存在栈桢里的位置画成了一张图,你可以看一下:
你可以看到,这里面的前6个参数的位置,都是从rbp的位置依次向下4个字节,也就是一个整数的位置。参数1是-4(%rbp),参数2是-8(%rbp),依此类推。
而大于6个的参数,是保存在调用者的栈桢里的。其中参数7的地址是16(%rbp),也就是rbp指针往上16个字节。这里为什么要加上16个字节呢?这是因为,这16个字节中,有8个字节是返回地址,是由callq _foo指令压到栈里的,还有8个字节是rbp之前的值,是由pushq rbp压到栈里的。
好,到目前为止,我们就知道如何在汇编代码里访问每个参数了。你可以查看代码库里的lowerVars代码,它把每个参数转变成了一个内存地址类型的Oprand。
//处理参数
for (let varIndex:number = 0; varIndex<this.numTotalVars; varIndex++){
let newOprand:Oprand;
if (varIndex < this.numParams){
if (varIndex < 6){
//从自己的栈桢里访问。在程序的序曲里,就把这些变量拷贝到栈里了。
let offset = -(varIndex + 1) *4;
newOprand = new MemAddress(Register.rbp,offset);
}
else{
//从Caller的栈里访问参数
//+16是因为有一个callq压入的返回地址,一个pushq rbp又加了8位
let offset = (varIndex - 6)*8 + 16;
newOprand = new MemAddress(Register.rbp,offset);
}
}
...
}
接下来,我们再看看本地变量。在示例程序param.c中,有x1和x2两个本地变量,你可以阅读param.s,看看它们都是存在哪的。
我相信,经过这么多节课的训练,现在你阅读汇编代码应该越来越熟练了。在这个代码里,你可以看到x1实际上是存在-28(%rbp)的,而x2是存在-32(%rbp)的。也就是说,在栈桢里,它们是紧挨着参数的区域继续往下延伸的,你可以看看下面这张图。
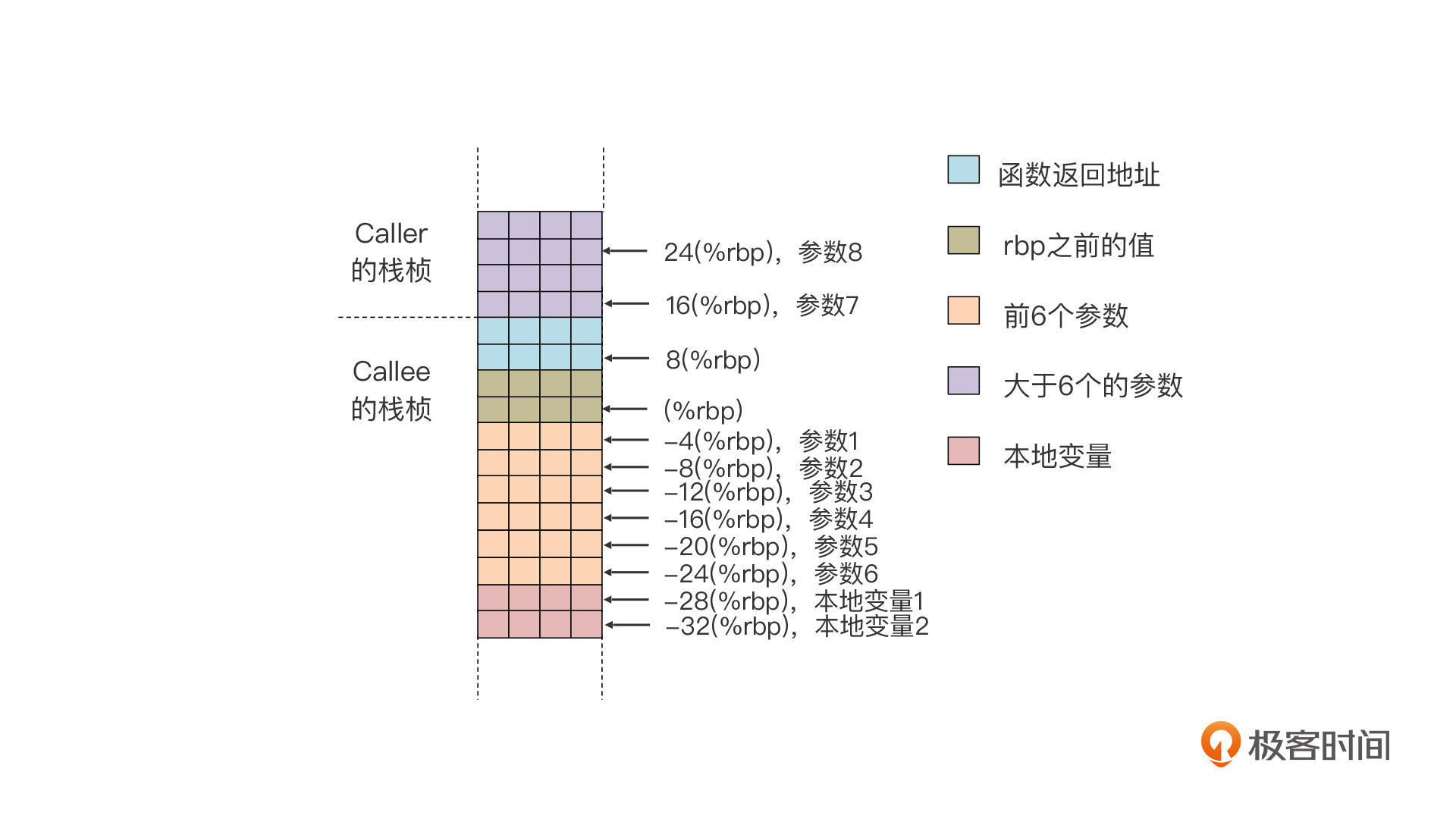
好了,现在对于参数和本地变量的保存,我们都搞清楚了,它们都是保存在内存的栈桢里的。那么临时变量呢?临时变量也保存在内存里吗?
这是不行的。为什么呢?这是因为,X86指令集中加减乘除等指令和mov指令对内存地址的使用是有限制的。
怎么理解呢?我们分析一下x1=p1*p2这条语句来看看。在上节课中,我们已经知道这条语句在生成汇编代码时,需要用到一个临时变量t1,所以整条语句在逻辑上相当于下面这三条汇编代码:
movl p1, t1 #把p1拷贝到t1
imull p2, t1 #把p2乘到t1上
movl t1, x1 #把t1赋给x1
在这里,p1和p2都是内存地址。如果t1也是内存地址,我们假设它是-36(%rbp),那么这三条汇编代码就会变成:
movl -4(%rbp), -36(%rbp) #把p1拷贝到t1
imull -8(%rbp), -36(%rbp) #把p2乘到t1上
movl -36(%rbp), -4(%rbp) #把t1赋给x1
但是如果你用汇编器编译这三条代码,汇编器会报错。
这是为什么呢?因为x86中汇编代码的规则虽然比较宽松,在加减乘除等很多运算性指令里都支持使用内存地址作为操作数,但它只允许源操作数是内存地址,不允许目标操作数是内存地址。而mov指令支持目标操作数是内存地址,但这个时候源操作数必须是立即数或寄存器,不支持把数据从一个内存地址拷贝到另一个内存地址。
那么我们要怎么来修改这三条代码,让它变成合法的X86汇编代码呢?
很简单,我们只要给临时变量t1分配一个物理寄存器就可以了。你可以参考param.s的代码,它给t1分配了一个%ecx寄存器,完美地解决了这个问题:
movl -4(%rbp), %ecx #把p1拷贝到t1
mull -8(%rbp), %ecx #把p2乘到t1上
movl %ecx, -28(%rbp) #把t1赋给x1
所以,现在我们就清楚了:对于临时变量,我们都统一给它们分配寄存器就行了。
那进一步的问题又来了:我们给这些临时变量分配哪些寄存器呢?是先分配那些由Caller保护的寄存器,还是Callee保护的寄存器?用哪类寄存器的代价更低呢?这几个问题你可以先记着,自己想一会,后面你看看示例代码是如何实现的。
好了,现在我们已经给参数、本地变量和临时变量都分配了物理的存储方式。这个过程,我们叫做把变量做Lower处理的过程,你可以看一下lowerVars方法。
并且,基于我们上面这个分配方法,所有的二元计算都能生成正确的汇编代码。你可以在example.ts中写一些表达式计算的代码,然后再用make example命令做构建。这会生成汇编代码文件example.s和可执行文件example,你再看看它们能否正确地运行。
接下来,我们再研究一下如何实现函数的调用。
我们仍然用示例代码param.c来做研究。在示例代码中,我们用main函数调用了foo函数。由于foo函数的参数比较多,所以我建议你好好看一下param.s中传参的具体过程。
movl -8(%rbp), %edi ##参数1,变量a
movl -12(%rbp), %esi ##参数2,变量b
movl $1, %edx ##参数3
movl $2, %ecx ##参数4
movl $3, %r8d ##参数5
movl $4, %r9d ##参数6
movl $5, (%rsp) ##参数7
movl $6, 8(%rsp) ##参数8
...
callq _foo
根据我们目前掌握的参数传递的知识,这里的前6个参数赋给了6个寄存器,而第7和第8个参数,则是基于rsp,赋给(%rsp)和8(%rsp)这两个内存地址。而在被调用者中,访问这两个参数则是使用16(%rbp)和24(%rbp)。
我也画了一张图,给你展示了如何在Caller和Callee的栈桢中访问参数7和参数8:
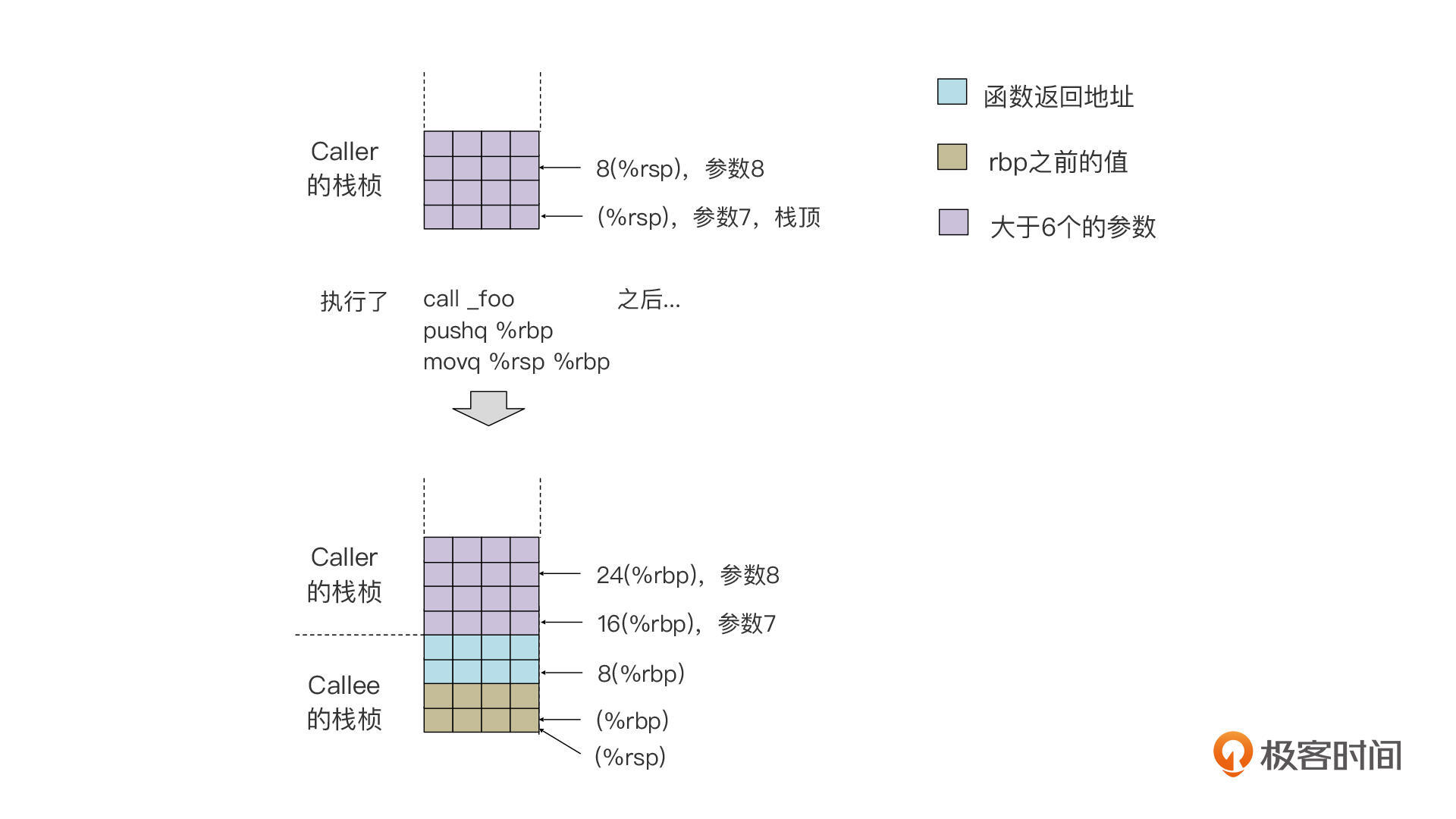
你要注意,这里每个参数都占用了8个字节,而不是像前面在Caller的栈桢里保存参数和本地变量那样,占用4个字节。你能不能想一想这是什么原因呢?
我估计你已经猜到了。这是因为在制定ABI的时候,要兼容尽量多的场景。这个规定,使得我们能够用同样的方式传递整型和长整型的参数,而长整型就需要占据8个字节。
你可以看看param_long.c及其对应的param_long.s汇编代码文件。你会发现,在这个示例文件中,我们把整型的参数改成了长整型,但是传递第7个和第8个参数的方法方式没有任何改变。在代码里访问这两个参数值的内存地址的表达方式,也是一样的。
好了,我们已经了解了函数调用中传参的过程了,具体实现你可以参见代码库中的lowerFunctionCall方法。那么现在我们是不是就可以调用callq指令来做函数调用了呢?还不行。为什么呢?因为我们还有一项重要的工作要做,就是保护好某些寄存器的值。
还记得吗?在函数调用的过程中,有些寄存器的值是由Caller负责保护的,而另一些寄存器的值是由Callee负责保护的,这是为了避免可能由于多方使用同一个寄存器,导致寄存器的值被破坏,从而导致计算错误的问题。
我们还是通过示例代码来分析一下寄存器的使用可能产生的冲突。你会看到,在param.c中有下面的一行代码:
int c = a*b + foo(a,b,1,2,3,4,5,6) + foo(b,a,7,8,9,10,11,12);
这行代码是我故意设计的,目的就是制造出寄存器使用上的冲突。整个计算过程大致可以分成下面这几步,其中涉及到t1、t2和t3三个临时变量。
t1 = a*b
t2 = foo(a,b,1,2,3,4,5,6)
t1 = t1 + t2
t3 = foo(b,a,7,8,9,10,11,12)
t1 = t1 + t3
c = t1
首先,我们需要计算表达式a*b,这个结果我们用t1表示,并把它映射到寄存器。在param.s里,这个寄存器是eax。
接着,我们需要调用foo()函数,假设返回值保存在t2中。这里要注意,根据ABI,foo()函数的返回是要保存到eax中的,所以t2和t1都要使用eax寄存器。为了防止t1的值被破坏,我们就必须先把它写到栈里去。
movl %eax, -20(%rbp) ## 4-byte Spill
callq _foo
movl -20(%rbp), %ecx ## 4-byte Reload
addl %eax, %ecx ## t1 = t1 + t2,把t2的值加到t1上
接下来,在调用foo函数以后,我们要把t1和t2相加。在此之前,我们又需要把t1从内存中恢复到寄存器里来。但这个寄存器不再是eax,因为现在t2已经占用了eax。所以,t1被装载到了ecx寄存器中。
再接着,我们还要再一次调用foo函数。在这次调用中,寄存器的使用再次产生了冲突,因为这次我们要用ecx来传递foo函数的第四个参数。那这又要怎么办呢?我们还是要把t1的值从ecx寄存器里保存到内存中,在调用完foo之后,再从内存恢复到寄存器。
movl %ecx, -24(%rbp) ## 4-byte Spill
...
callq _foo
movl -24(%rbp), %ecx ## 4-byte Reload
addl %eax, %ecx ## t1 = t1 + t3, 把t3的值再加到t1上。
movl %ecx, -16(%rbp) ## c = t1
好了,通过上面这个例子的分析,我相信你已经对寄存器的冲突有了比较直观的了解。这里,我再带你总结一下可能发生冲突的场景:
那我们要如何保护这些寄存器呢?我们需要把它们的值写到栈桢里,之后再从栈桢里恢复。
注意,把一个临时变量t保存到内存的过程叫做Spill,也叫做溢出,我们在后面专门学习寄存器分配算法的时候会再次见到这个词汇。把t从内存再重新装载到寄存器的过程,叫做Reload。不过这里你也要注意,虽然新的寄存器不一定是原来那个寄存器,但编译器会知道,这还是原来那个临时变量t。
Spill和Reload的实现,你仍然可以参见lowerFunctionCall方法。
那么,到目前为止,我们已经往栈桢里放了很多数据,包括返回值地址、rbp的原值、参数,还有本地变量。而且,把临时变量溢出(Spill)到内存里也需要预留一些空间,调用函数时给函数传参也需要使用栈的空间。
那我们现在就再进一步,梳理一下栈桢里的内容,也来分析一下我们要怎么做好栈桢的维护。
你可以先看一下,采用我们目前的算法形成的栈桢结构是这样的:
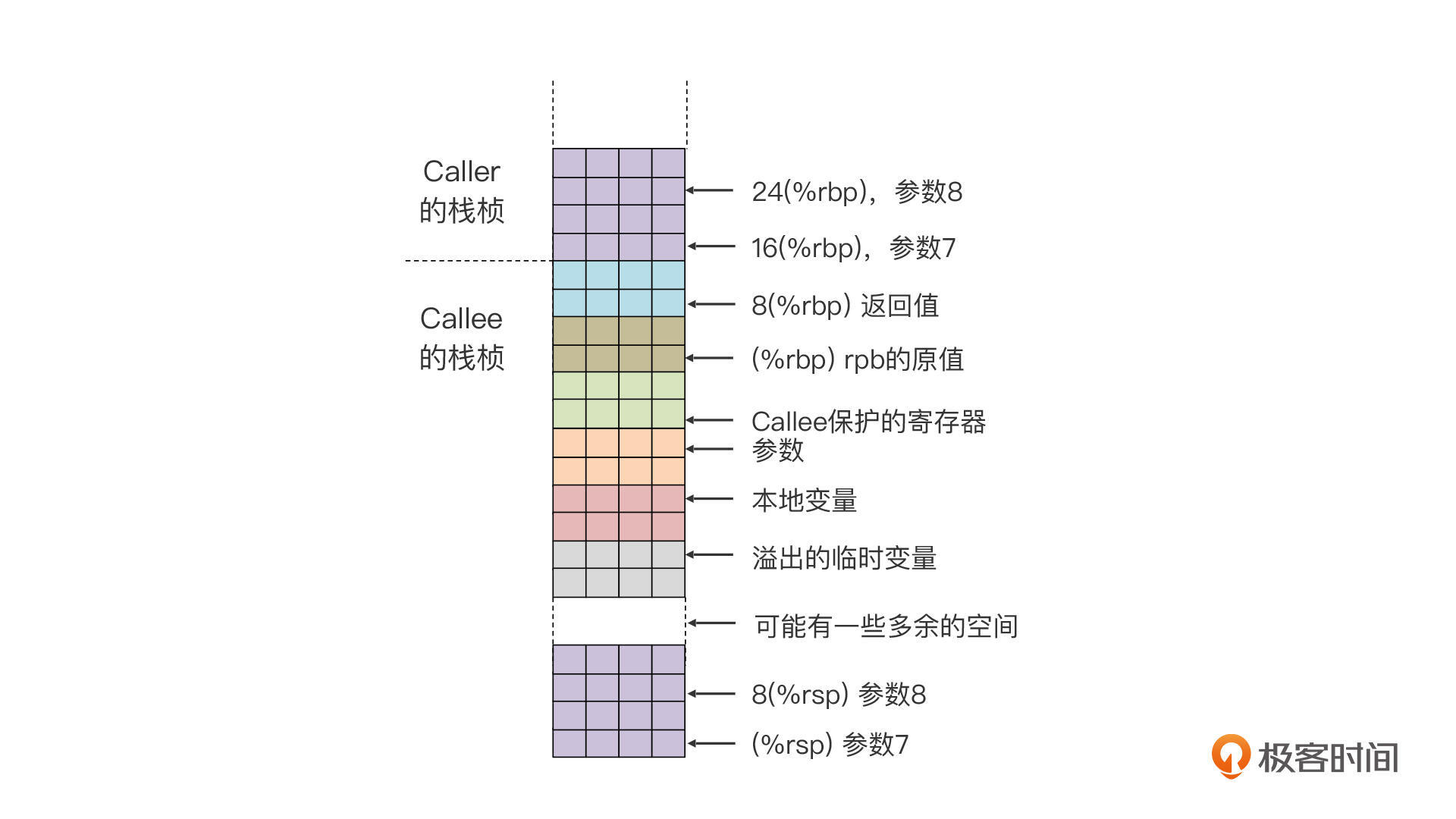
一个栈桢从上到下,依次是返回值、rbp原值、Callee保护的寄存器(目前我们的示例程序中还没有用到这些寄存器)、参数、本地变量、溢出到内存的临时变量。
然后你再从栈顶,也就是栈桢的最底下往上看,这里是我们在调用函数时,为超过6个的参数所保存的空间。
然后你还会注意到,在栈桢中间可能还有一些多余的空间。为什么会这样呢?
第一个原因,是这个函数可能会调用多个函数,而被调用的多个函数所需的参数数量是不同的,因此我们需要为参数最多的那个函数预留出足够的用于保存参数的空间。
第二个原因,是内存对齐。原来,在ABI中规定,如果这个函数要调用另一个函数,那么参数区的尾部应该是16字节对齐的。所以说,参数区的尾部也是两个栈桢之间的分界线。换句话说,在控制转移到函数入口的那一刻,(%rsp+8)的值是能够被16整除的。这里的8,是因为callq指令把8位的一个返回地址压到了栈里。
我建议你看看ABI文档中对栈桢的描述,我截取了一小段,你可以看看:

基于上面的原则,我们在为一个函数建立栈桢的时候,需要计算出rsp移动的量,以便确定正确的栈桢尺寸。在param.s的_main函数中,序曲和尾声部分各有一行指令,就是用来移动rsp指针的。
##序曲
pushq %rbp
movq %rsp, %rbp
subq $48, %rsp ##把栈桢扩展48个字节。整个栈桢的大小是48+16字节
##函数体
...
##尾声
addq $48, %rsp ##缩回栈桢
popq %rbp
retq
不过,刚才我们看的是main函数的栈桢的情况。但对于foo函数来说,它的栈桢会有所不同。
有什么区别呢?区别就在于,foo函数是叶子函数,也就是说它没有调用其他函数。在这个情况下,我们根本没有必要移动rsp指针来为栈桢申请内存。只要foo函数占用的内存不超过128个字节,我们直接使用红区(RedZone)就行了。它的栈桢结构如下图所示,这时rsp的值和rbp的值是相同的。
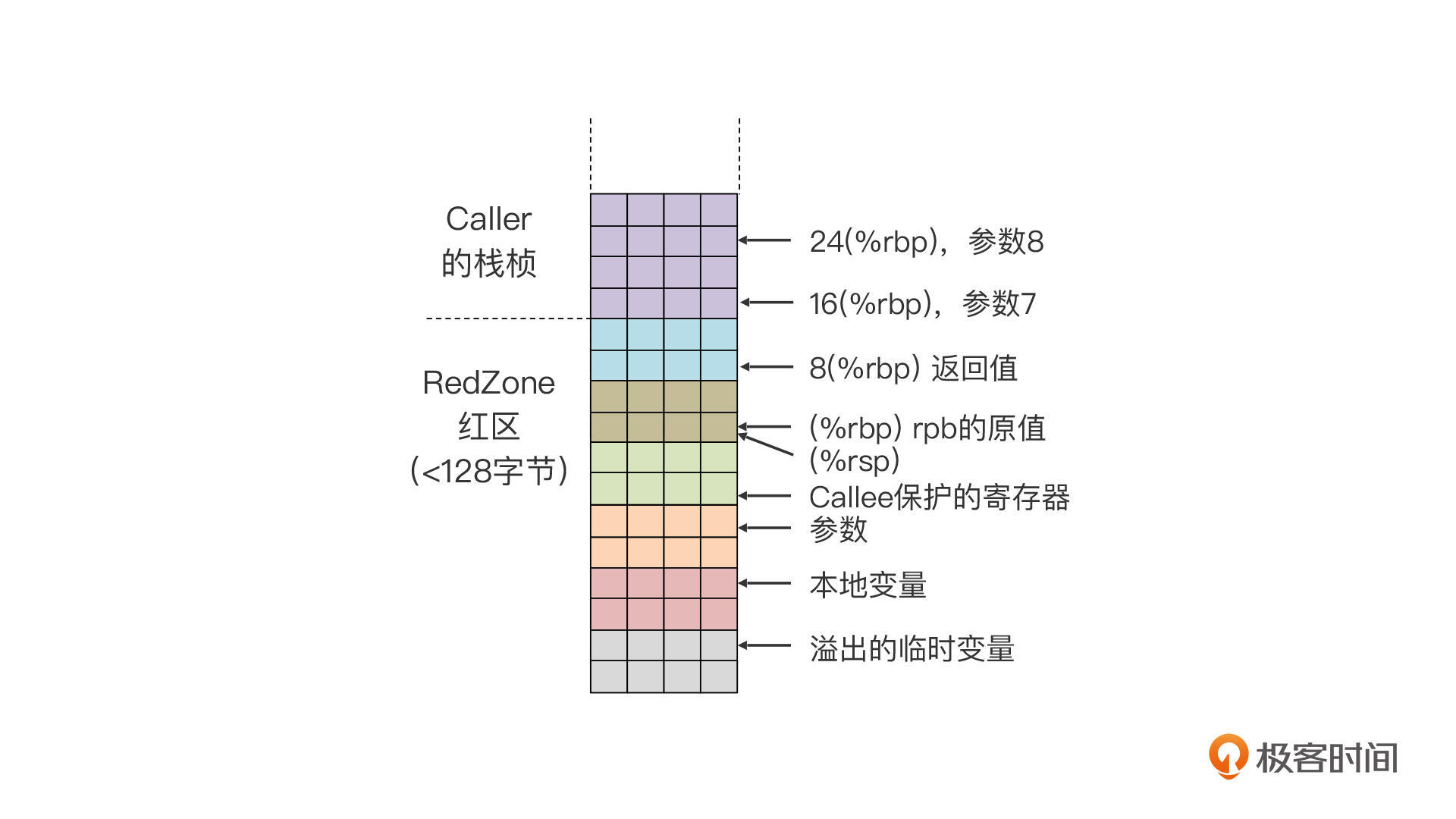
关于红区的知识点,我仍然建议你阅读ABI文档,我在这里也贴了一小段,供你参考。

现在,栈桢维护的原理,我们已经讲清楚了,至于具体的计算栈桢大小、维护栈桢的代码,你可以在代码库中的addPrologue和addEpilogue两个函数中看到。在这里,你要特别关注一下其中计算栈桢大小的相关代码,以此为线索你就能搞清楚整个栈桢的内存布局了。我相信,在明白原理之后,你再阅读这些代码,可以保持一条比较清晰的思路。
好了,今天的内容就是这些,到今天这节课为止,我们的语言已经能够为表达式计算和函数调用等功能生成汇编代码和可执行文件了。那么今天这节课,我希望你记住下面几个关键的知识点:
首先,我们在采用简单的寄存器分配算法时,通常是把参数、本地变量都保存到栈桢里,但临时变量则要用使用寄存器,在这个过程中,我们加深了对x86指令的理解。像加减乘除等运算,目标操作数应该是寄存器,而对源操作数就没有这个要求了。另外,mov指令虽然在源操作数和目标操作数中都可以使用内存地址,但不能两个操作数都是内存地址。
第二,我们再次熟悉了函数调用的约定,也就是前6个参数用寄存器,超过6个的参数使用Caller的栈桢。不过这次,我们更细致地了解了从Caller和Callee中应该如何访问这些额外的参数。具体来说,在Caller中我们要基于rsp寄存器来寻址,但在Callee中则要基于rbp寄存器来寻址。
第三,在调用函数时,会发生寄存器使用冲突的情况,这个时候我们需要把保存在寄存器中的临时变量溢出到内存中,需要时再装载回来,而这两个操作使用的寄存器可能并不是同一个。
最后,我们总结了栈桢的内存布局设计,并指出了如何正确地移动栈顶指针rsp来申请内存。在这个过程中,栈桢要保证16字节内存对齐。而对于叶子函数,我们还可以直接使用RedZone,不用移动栈顶指针rsp。不过,这里要指出的是,对于这个内存布局,只有超过6个的额外参数的位置、返回地址的位置,还有内存对齐等少量内容是由ABI规定的,其他大部分栈桢空间都是语言的设计者自己决定如何使用的。
最后再补充一句,到目前为止,我在这节课提到的所有寄存器,都是与整数计算有关的寄存器。如果你要进行浮点数计算,使用的寄存器会是另外一组,我们在后面的课程里再详细介绍。
在这节课的示例代码中,我们看到临时变量首先使用的是Caller保护的寄存变量,比如eax,而不是Callee保护的。这又是什么道理呢?请你分析一下。
感谢你和我一起学习,也欢迎你把这节课分享给更多对生成本地代码感兴趣的朋友。我是宫文学,我们下节课见。