你好,我是宫文学。
在上一节课,我们比较全面地分析了怎么用集合运算的算法思路实现类型计算。不过,在实际的语义分析过程中,我们往往需要综合运用多种技术。
不知道你还记不记得,我们上一节课举了一个例子,里面涉及了数据流分析和类型计算技术。不过这还不够,今天这节课,我们还要多举几个例子,来看看如何综合运用各种技术来达到语义分析的目的。在这个过程中,你还会加深对类型计算的理解、了解常量折叠和常量传播技术,以及实现更精准的类型推导。
好,我们首先接着上一节课的思路,看一看怎么把数据流分析与类型计算结合起来。
我们再用一下上节课的示例程序foo7。在这个程序中,age的类型是number|null,age1的类型是string|number。我们先让age=18,这时候把age赋给age1是合法的。之后又给age赋值为null,然后再把age赋给age1,这时编译器就会报错。
function foo7(age : number|null){
let age1 : string|number;
age = 18; //age的值域现在变成了一个值类型:18
age1 = age; //OK
age = null; //age的值域现在变成了null
age1 = age; //错误!
console.log(age1);
}
在这个过程中,age的值域是动态变化的。在这里,我用了“值域”这个词。它其实跟类型是同一个意思。我这里用值域这个词,是强调动态变化的特征。毕竟,如果说到类型,你通常会觉得变量的类型是不变的。如果你愿意,也可以直接把它叫做类型。
你马上就会想到,数据流分析技术很擅长处理这种情况。具体来说,就是在扫描程序代码的过程中,某个值会不断地变化。
提到数据流分析,那自然我们就要先来识别它的5大关键要素了。我们来分析一下。
首先是分析方向。这个场景中,分析方向显然是自上而下的。
第二,是数据流分析针对的变量。在这个场景中,我们需要分析的是变量的值域。所以,我用了一个varRanges变量,来保存每个变量的值域。varRanges是一个map,每个变量在里面有一个key。
varRanges:Map<VarSymbol, Type> = new Map();
第三,我们要确定varRanges的初始值。在这个例子中,每个变量的值域的初始值就是它原来的类型。比如age一开始的值域就是number|null。
第四,我们要确定转换函数,也就是在什么情况下,变量的值域会发生变化。在当前的例子中,我们只需要搞清楚变量赋值的情况就可以了。如果我们要在变量声明中进行初始化,那也可以看做是变量赋值。
在变量赋值时,如果=号右边的值是一个常量,那么变量的值域都会变成一个值对象,这种情况我们已经在前一节课分析过了。
那如果=号右边的值不是常量,而是另一个变量呢?比如下面一个例子foo10,x的类型是number|string,y的类型是string。然后把y赋给x。我相信你也看出来,现在x的值域就应该跟y的一样了,都是string。
function foo10(x : number|string, y : string){
x = y; //x的值域变成了string
if (typeof x == 'string'){ //其实这个条件一定为true
println("x is string");
}
}
研究一下这个例子,你会发现通过赋值操作,我们把x的值域收窄了。在TypeScript的文档中,这被叫做"Narrowing"。翻译成汉语的话,我们姑且称之为“窄化”吧。
不过,除了赋值语句,还有其他情况可以让变量的值域窄化,包括使用typeof运算符、真值判断、等值判断、instanceof运算符,以及使用类型断言等等。其中最后两种方法,涉及到对象,我们目前还没有支持对象特性,所以先不讨论了。我们就讨论一下typeof运算符、真值判断和等值判断这三种情况。
首先讨论一下typeof运算符。其实在前面的例子foo10中,我们就使用了typeof运算符。typeof是一个类型运算符,它能返回代表变量类型的字符串。不过它的结果只有少量几个值,包括number、string、boolean、object、undefined、symbol和bigint。
我们再举一个例子foo11,看看typeof是如何影响变量的值域的。
function foo11(x : number|string){
let y: string;
if (typeof x === 'string'){ //x的值域变为string
y = x; //OK。
}
}
你可以看到,在示例程序foo11中,x原来的类型是number|string。但在if条件中,我们用typeof进行了类型的检测,只有当x的类型是string的时候,才会进入if块。所以,在if块中,我们用x给string类型的变量y赋值是没有错的。
在使用typeof的表达式中,你可以用四个运算符:===、!==、==和!=。其中===和==的效果是一样的,只不过前者的性能更高。同样,!==和!=也是等价的。
接着,我们看看真值判断。什么是真值判断呢?我们还是举一个例子,这样理解起来更直观一些。
function foo12(x : string|null){
let y: string;
if (x){ //x的值域变为string & !""
y = x; //OK。
}
}
在这个例子中,x的类型是string|null。但在if语句中,通过判断x是否为真,把x=null这个选项去掉了,这样就可以把x赋给string类型的y了。
这里,我还要给你补充点背景知识。在TypeScript/JavaScript中,我们其实可以把其他类型的值放入需要boolean值的地方,比如string、number、object等,它们会被自动转化成boolean值。不过,其中有一些值会被转化成false,它们是:0、NaN、“” (空字符串)、0n (bigint类型中的0)、null,以及undefined。
除此之外的值,转化为boolean值以后都是true。所以,在上面foo12示例程序的if条件中,x是true,那它就不可能是null值了,也不可能是空字符串。这样,最后的形成的值域就是string & !“”。
最后,我们再看看等值判断。其实我们在上一节就见过等值判断的例子,我们把那个例子程序再拿过来看一下。
function foo9(age : number|null){
if (age == 18 || age == 81){ //age的值域现在是 18|81
console.log("18 or 81");
}
else{ //age的值域是 !18 & !81 & (number | null)
console.log("age is empty!")
}
}
在这个例子中有一个if语句,其中的条件表达式会生成一个值域,“18|81”。而对于else块,则需要先把“18|81”取补集,然后再跟age原来的值域求交集。
好了,现在我们就分析完了数据流分析中的第四个要素,也就是转换函数。接下来我们看看最后一个要素,就是汇聚函数。
什么时候需要用到汇聚函数呢?对于if语句来说,如果程序在if块和else块中都修改了某个变量的值域,那在if语句后面,变量的值域就需要做汇聚。我们还是通过一个例子来说明一下。
在下面的例子foo13中有一个if语句。在这个if语句中,if块和else块分别都有一个对y赋值的语句。在if块中赋值语句是y=x。在这里,x的值域是number,所以y的值域也是number。在else块中,赋值语句是y = 18,那y的值域就是18。
function foo13(x : number|null){
let y:number|string;
let z:number;
if (x != null){ //x的值域是number
y = x; //y的值域是number
}
else{
y = 18; //y的值域是18
} //if语句之后,y的值域是number
z = y; //OK
return z;
}
那么,在退出if语句的时候,y的值域应该是什么呢?你稍微分析一下就能看出来,这里应该取两个分支的并集,也就是number。所以把y赋给z是可以的。
你可以把这个例子稍微修改一下,把else块中的赋值语句改为y = “eighteen”。那当退出if语句以后,y的值域是number|“eighteen”。这样你再把y赋给z,编译器就会报错。
function foo14(x : number|null){
let y:number|string;
let z:number;
if (x != null){ //x的值域是number
y = x; //y的值域是number
}
else{
y = "eighteen"; //y的值域是18
} //if语句之后,y的值域是number|"eighteen"
z = y; //编译器报错!
return z;
}
好了,到目前为止,我已经把数据流分析的5个要素都识别清楚了。思路清楚以后,你就可以去实现了。至于我的参考实现,你可以看一下TypeChecker。
在这里,我要再分享一点心得。你会发现,即使我们已经多次使用数据流分析技术了,每次我还要把5个要素都过一遍。这是因为,我们做研发的时候,有个思维框架很重要,它可以引导你的思路,避免一些思维盲区。
比如,我在类型计算中使用数据流分析的时候,一开始注意力被其他技术点吸引了,忘记了用整个分析框架检查一遍,结果就忘记了实现汇聚函数,这就会导致一些功能缺失。后来用框架一检查,马上就补上了这个功能。
好了,到这里,我们已经基本介绍清楚了如何使用数据流分析技术来做类型计算。不过,类型计算还可能受到其他技术的影响。接下来我就介绍一下常量折叠(Constant Folding)和常量传播(Constant Propagation)。常量折叠和常量传播的结果,会进一步影响到类型计算的结果。
我们还是先看一个例子来理解一下这两个概念。这个例子中有x1,x2和x3三个变量。我们首先给x2赋予常量10。接着,我们把x2+8赋给x3。从这里你能计算出,其实x3的值也是一个常量,它的值是18。
function foo15(x1:number|null):number{
let x2 = 10; //x2是常量10
let x3 = x2 + 8; //x3是常量18
if (x1 == x3 ){ //x1的值域是18
return x1; //OK!
}
return x2;
}
你看,执行到这里,我们其实在编译期就把x2+8的值计算出来。这样,在生成汇编代码的时候,我们就不需要进行相应的计算了,直接给x3赋值为18就行了。这个技术就叫做常量折叠。它能让一些常量的计算在编译期完成,这样就能提高程序在运行期的性能。
同时,在x3 = x2+8这行程序中,还有一个现象,叫做常量传播。什么意思呢?在这行中,x2的值已经是一个常量10了,它的常量值被传播到了x2+8这个表达式中,从而计算出了一个新的常量x3。
再接下来是一个if语句。这个时候,x3的值传播到了if条件中。这就影响到了x1的值域。现在x1的值域就变成18了。所以,当我们在if块中执行return x1的时候,代码是正确的,满足返回值必须是number的要求。
那常量传播具体怎么实现呢?
在PlayScript的实现中,我们给每个表达式都添加了一个constValue属性。通过遍历树的方式,就可以求出每个表达式的常量值,并记录到constValue属性。在生成目标代码的时候,就可以直接使用这个常量值,不需要在运行期做计算。
好了,现在我们已经了解了常量折叠和常量传播技术,也分析了它对类型计算的影响。
不过,到目前为止,对于类型计算的结果,我们都是用在类型检查的场景里。其实,类型计算的结果也能用于类型推导,能够提高类型推导的准确程度。而常量折叠和传播,也会在其中起到作用。
在之前PlayScript版本中,我们也实现了基本的类型推导功能。但那个时候,类型推导都是基于变量声明时的类型,而不是基于数据流分析来获得变量动态的值域,再根据这个值域做类型推导。基于变量声明进行推导的结果肯定是不够精准的。
同样,我们举个例子看一下。在这个例子中,变量a的类型是number|string,我们再给a赋值为“hello”,现在a的值域是“hello”。再然后呢,我们声明了一个变量b,并把变量a作为它的初始化值。
function foo16(a:number|string){
a = "hello"; //a的值域是"hello"
let b = a; //推导出b的类型是string
console.log(typeof b);
}
那么问题来了,现在b应该是什么类型呢?我给你两个候选答案,让你选一下:
选项1:b的类型a原来的类型是一样的,都是number|string。
选项2:b的类型是string,因为采用常量传播技术,我们已经知道a的值是“hello”了。
我估计你应该会选出正确的答案,就是选项2。其实,上面的“let b = a”这个语句,就等价于“let b = “hello””,所以你应该能够推导出b的类型是string。
不过,这里要注意,我们不能因为a当前的值域是“hello”,就推导出变量b的类型也是值类型“hello”,这就把变量b限制得太死了。TypeScript会采用“hello”的基础类型string。
类型推导还有更复杂一点的场景。比如,在下面的例子中,我们仍然用a来初始化变量b。不过,现在a的值域是10|null。
function foo17(a:number|string|null){
if(a == 10 || a == null){ //a的值域是10|null
let b = a; //推导出b的类型是number|null
if (b == "hello"){ //编译器报错!
console.log("whoops");
}
}
}
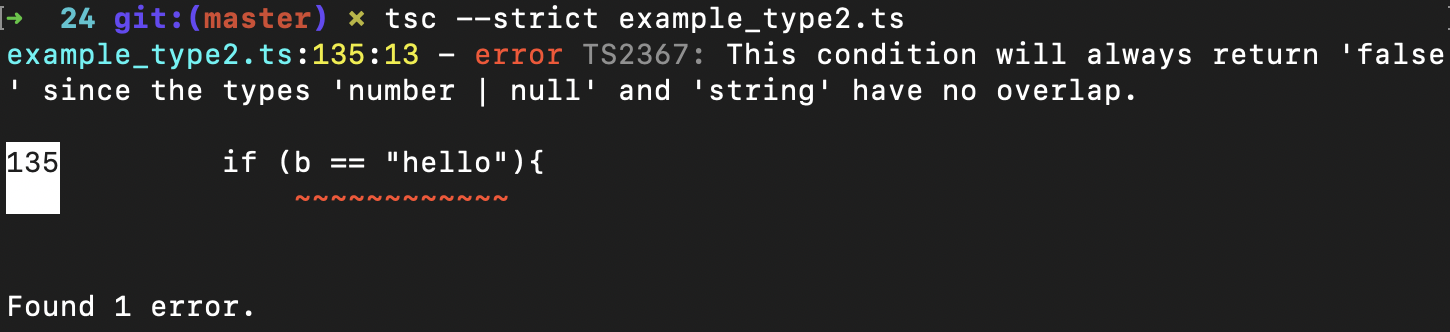
基于a的值域,编译器会把b的类型推导为number|null。所以,这个时候如果我们用b=="hello"让b跟字符串做比较,编译器就会报错,指出类型number|null和string之间没有重叠,所以不能进行==运算。
好了,通过刚才的分析,相信你对类型计算的在类型推导中的作用,也有了一些直观的了解。
今天的内容就是这些。在今天这节课,我希望你能在以下几个方面有所收获。
首先,我们采用数据流分析的框架,可以动态地计算变量在每行代码处的值域,或者叫做类型。通过变量赋值、typeof运算符、真值判断和等值判断等操作,变量的值域会不停地被窄化。不过,在多个条件分支汇聚的地方,又会通过求并集而把值域变宽。
第二,常量折叠技术能够在编译期提前计算出常量,这样我们就不需要在运行期再计算了,从而提高程序性能。而常数传播技术,能够把常数随着代码传播到其他地方,从而计算出更多的常量。这些传播出去的常量,还会让类型计算的结果更加准确。
第三,类型计算的结果不仅可以用于类型检查,还可以用于类型推导,让类型推导的结果更加准确。
今天这节课实现的功能,你仍然可以参考TypeUtil和TypeChecker的实现,并且运行example_type2.ts示例程序。
为了更好地支持类型计算的功能,我还给编译器增加了对typeof语法的支持。增加的新语法规则叫做typeOfExp。
primary: literal | functionCall | '(' expression ')' | typeOfExp ;
typeOfExp : 'typeof' primary;
另外,我还增加了对于===和!==的支持。现在你对于支持新的语法规则应该已经驾轻就熟了,所以我在这里就不多展开了。你可以去看看示例程序的源代码。
那么,对TypeScript的类型系统和其他编译器前端功能的实现,我们到此就告一个段落了。这些功能将会给我们后面实现编译器后端特性提供很好的支撑!
今天的思考题是关于类型推导的。如果b的值域是0 | 1 | true | false,那么在“let a = b”这样一个变量声明语句中,编译器推导出的a的类型应该是什么呢?
欢迎你把这节课分享给更多对编译器前端感兴趣的朋友。我是宫文学,我们下节课见。
1.这节课示例代码的目录;
2.这节课你仍然需要关注TypeChecker和TypeUtil的代码;
3.Parser中解析TypeOfExp的代码,非常简单;
4.测试程序仍然是放在example_types.ts中,不过例子更多了。你每次可以注释掉其他的例子,只运行其中的一个,测试编译器的行为。