你好,我是陈磊。
课程到现在,我们已经一起从接口测试思维的训练,走到了接口测试技术的训练,随着学习的不断深入,你应该也有了一个自己的测试框架,虽然这个框架可能还很简陋。但是任何事情不管多晚开始,都好于从未开始,因此学到现在,你已经迈出了接口测试以及其测试技术的第一步。
做任何事情,从零到一都需要莫大的勇气和坚定的决心,在这个过程中,你要将自己挪出舒适区,进入一个陌生的领域,这确实很难。但如果你和我一起走到了这一节课,那么我要恭喜你,你已经完成了接口测试从零到一的转变,后续从一到无穷大,你只需要随着时间去积累经验就可以了。
如果把接口测试比喻成要炒一盘菜的话,那么我在之前的全部课程中,重点都是在讲解如何完成接口测试,也就是教你如何炒菜。我也教过你如何解决接口测试的需求,为你提供了解决问题的能力和手段,这也就是在帮你建造一个设备齐全的厨房,帮你一起完成接口测试任务 。
有了精致的厨房后,我也告诉了你要怎么制作顶级的厨具,也就是接口测试的技术方法和实践方式。这些厨具既有锅碗瓢盆,也有刀勺铲叉,这里的锅碗瓢盆就是你的测试框架,刀勺铲叉就是你使用框架完成的测试脚本,这其中既包含了单接口的测试脚本,也包含了业务逻辑多接口测试脚本。
那么如果想炒菜你还需要准备什么呢?毫无疑问那就是菜,所谓“巧妇难为无米之炊”,即使你有高超的手艺,有世界顶级的厨具,但如果没有做菜的原材料,那也没办法把菜做出来,就算是世界顶级大厨,也无法完成这样的任务。
今天我就顺着这个思路,和你讲讲菜的准备,也就是接口测试的数据准备工作。
随着你不断封装自己的测试框架,你的框架就始终处于等米下锅这样一种的状态,而米就是测试数据。我在之前的课程中,都是将测试数据直接写在代码里,赋值给一个变量,然后通过接口测试逻辑来完成测试。
说到这,我还是把我们之前用过的”战场“这个系统拿出来,看一看它“选择武器”这个接口测试脚本(你可以回到04中查看),虽然你现在对怎么撰写、怎么封装类似的接口脚本都已经烂熟于心,但我们还是先看一下它的代码段:
# uri_login存储战场的选择武器
uri_selectEq = '/selectEq'
# 武器编号变量存储用户名参数
equipmentid = '10003'
# 拼凑body的参数
payload = 'equipmentid=' + equipmentid
response_selectEq = comm.post(uri_selectEq,params=payload)
print('Response内容:' + response_selectEq.text)
这就是你通过自己的Common类改造后的测试框架,但是现在,它还不能是算是一个完美的框架,为什么呢?
这是因为,你现在的参数都是直接通过equipmentid变量赋值的,在做测试的时候,你还需要不断修改这个参数的赋值,才能完成接口的入参测试,这不是一种自动化的测试思路。
因此,你需要将数据封装,通过一种更好的方式,将数据存储到一种数据存储文件中,这样代码就可以自行查找对应的参数,然后调取测试框架执行测试流程,接着再通过自动比对返回预期,检验测试结果是否正确。
这样做有两个好处。
怎么样,看到这些好处,你是不是也想马上给你的框架加上数据处理的部分了呢?
现在我们就马上开始动手,为你的框架加上参数类。
首先,你先要定义一种参数的存储格式。那么我想问你的是,要是让你选择把数据储存在一个文件中,你会选择什么格式的文件呢?
我相信你肯定和我的选择一样,用Excel。因为目前来看,Excel是在设计测试用例方面使用最多的一个工具,那么我们也就可以用Excel作为自己的参数存储文件。
但在动手之前,你也应该想到,你的参数文件类型不会是一成不变的Excel,未来你也有可能使用其他格式的参数文件,因此在一开始你还要考虑到参数类的扩展性,这样你就不用每多了一种参数文件存储格式,就写一个参数类,来完成参数的选取和调用了。
那么如何选取和调用参数呢?你可以看看我设计的参数类:
import json
import xlrd
class Param(object):
def __init__(self,paramConf='{}'):
self.paramConf = json.loads(paramConf)
def paramRowsCount(self):
pass
def paramColsCount(self):
pass
def paramHeader(self):
pass
def paramAllline(self):
pass
def paramAlllineDict(self):
pass
class XLS(Param):
'''
xls基本格式(如果要把xls中存储的数字按照文本读出来的话,纯数字前要加上英文单引号:
第一行是参数的注释,就是每一行参数是什么
第二行是参数名,参数名和对应模块的po页面的变量名一致
第3~N行是参数
最后一列是预期默认头Exp
'''
def __init__(self, paramConf):
'''
:param paramConf: xls 文件位置(绝对路径)
'''
self.paramConf = paramConf
self.paramfile = self.paramConf['file']
self.data = xlrd.open_workbook(self.paramfile)
self.getParamSheet(self.paramConf['sheet'])
def getParamSheet(self,nsheets):
'''
设定参数所处的sheet
:param nsheets: 参数在第几个sheet中
:return:
'''
self.paramsheet = self.data.sheets()[nsheets]
def getOneline(self,nRow):
'''
返回一行数据
:param nRow: 行数
:return: 一行数据 []
'''
return self.paramsheet.row_values(nRow)
def getOneCol(self,nCol):
'''
返回一列
:param nCol: 列数
:return: 一列数据 []
'''
return self.paramsheet.col_values(nCol)
def paramRowsCount(self):
'''
获取参数文件行数
:return: 参数行数 int
'''
return self.paramsheet.nrows
def paramColsCount(self):
'''
获取参数文件列数(参数个数)
:return: 参数文件列数(参数个数) int
'''
return self.paramsheet.ncols
def paramHeader(self):
'''
获取参数名称
:return: 参数名称[]
'''
return self.getOneline(1)
def paramAlllineDict(self):
'''
获取全部参数
:return: {{}},其中dict的key值是header的值
'''
nCountRows = self.paramRowsCount()
nCountCols = self.paramColsCount()
ParamAllListDict = {}
iRowStep = 2
iColStep = 0
ParamHeader= self.paramHeader()
while iRowStep < nCountRows:
ParamOneLinelist=self.getOneline(iRowStep)
ParamOnelineDict = {}
while iColStep<nCountCols:
ParamOnelineDict[ParamHeader[iColStep]]=ParamOneLinelist[iColStep]
iColStep=iColStep+1
iColStep=0
ParamAllListDict[iRowStep-2]=ParamOnelineDict
iRowStep=iRowStep+1
return ParamAllListDict
def paramAllline(self):
'''
获取全部参数
:return: 全部参数[[]]
'''
nCountRows= self.paramRowsCount()
paramall = []
iRowStep =2
while iRowStep<nCountRows:
paramall.append(self.getOneline(iRowStep))
iRowStep=iRowStep+1
return paramall
def __getParamCell(self,numberRow,numberCol):
return self.paramsheet.cell_value(numberRow,numberCol)
class ParamFactory(object):
def chooseParam(self,type,paramConf):
map_ = {
'xls': XLS(paramConf)
}
return map_[type
上面这个代码看着很多,但你不需要完全看得懂,你只需要知道它解决问题的思路和方法就可以了,思路就是通过统一抽象,建立一个公共处理数据的方式。你可以设计和使用简单工厂类的设计模式,这样如果多一种参数存储类型,再添加一个对应的处理类就可以了,这很便于你做快速扩展,也可以一劳永逸地提供统一数据的处理模式。
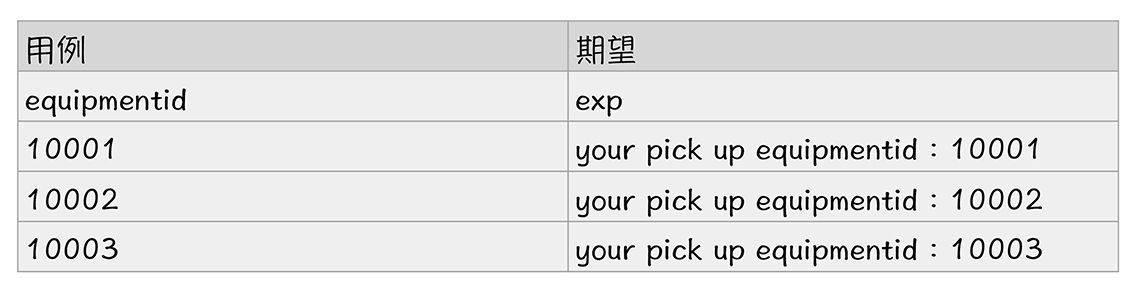
如果你的技术栈和我不一样,那么你只需要搜索一下你自己技术栈所对应的简单工厂类设计模式,然后照猫画虎地把上面的逻辑实现一下就可以了。接下来,你就可以把这次测试的全部参数都存到Excel里面了,具体内容如下图所示:
通过上面的参数类你可以看出,在这个Excel文件中,第一行是给人读取的每一列参数的注释,而所有的Excel都是从第二行开始读取的,第二行是参数名和固定的表示预期结果的exp。现在,我们使用ParamFactory类,再配合上面的这个Excel,就可以完成”战场“系统“选择武器”接口的改造了,如下面这段代码所示:
#引入Common、ParamFactory类
from common import Common
from param import ParamFactory
import os
# uri_login存储战场的选择武器
uri_selectEq = '/selectEq'
comm = Common('http://127.0.0.1:12356',api_type='http')
# 武器编号变量存储武器编号,并且验证返回时是否有参数设计预期结果
# 获取当前路径绝对值
curPath = os.path.abspath('.')
# 定义存储参数的excel文件路径
searchparamfile = curPath+'/equipmentid_param.xls'
# 调用参数类完成参数读取,返回是一个字典,包含全部的excel数据除去excel的第一行表头说明
searchparam_dict = ParamFactory().chooseParam('xls',{'file':searchparamfile,'sheet':0}).paramAlllineDict()
i=0
while i<len(searchparam_dict):
# 读取通过参数类获取的第i行的参数
payload = 'equipmentid=' + searchparam_dict[i]['equipmentid']
# 读取通过参数类获取的第i行的预期
exp=searchparam_dict[i]['exp']
# 进行接口测试
response_selectEq = comm.post(uri_selectEq,params=payload)
# 打印返回结果
print('Response内容:' + response_selectEq.text)
# 读取下一行excel中的数据
i=i+1
这样再执行你的测试脚本,你就可以看到数据文件中的三条数据,已经都会顺序的自动执行了。那么后续如果将它付诸于你自己的技术栈,以及自己的测试驱动框架比如Python的unittest、Java的Junit等,你就可以通过断言完成预期结果的自动验证了。
今天我们接口测试数据准备的内容就到这里了,在接口测试的工作中,作为“巧妇”的测试工程师,还是需要参数这个“米”来下锅的,虽然我们之前课程中的代码涉及到参数的处理,但是都很简单粗暴,一点也不适合自动化的处理方式,因此今天,我带你完成了参数类的封装。
有的时候,我们也把参数类叫做参数池,这也就是说参数是存放在一个池子中,那我们准备好的池子就是Excel。我相信未来你也会不断扩展自己参数池的种类,这有可能是由于测试接口的特殊需求,也有可能是由于团队技术栈的要求。因此,我们封装参数池是通过简单工厂设计模式来实现的,如果你的代码基础并不好,那么你可以不用搞清楚简单工厂设计模式是什么,只需要知道如何模拟上述代码,再进行扩展就可以了。
一个好用的测试框架既要有很好的可用性,也要有很好的扩展性设计,这样我们的私有接口测试武器仓库就会变成可以不断扩展的、保持统一使用方法的武器仓库,这样才能让你或者你的团队在面对各种各样的测试任务时,既可以快速适应不同接口测试的需求,又不需要增加学习的成本。
今天我们一起学习了参数类的设计,并且将它应用到”战场“系统的接口测试脚本中,后续我又告诉你为了能够完成代码的自动验证,你需要引入一些测试驱动框架,那么,你的技术栈是什么?你在你的框架中选取的测试驱动框架又是什么呢?你能将之前”战场“系统的全流程测试脚本通过参数类完成改造吗?我期待看到你的测试脚本。
我是陈磊,欢迎你在留言区留言分享你的观点,如果这篇文章让你有新的启发,也欢迎你把文章分享给你的朋友,我们一起沟通探讨。
评论