从今天起,我们不再单独介绍推荐算法的原理,而是开始进入一个新的模块——工程篇。
在工程实践的部分中,我首先介绍的内容是当今最热门的信息流架构。
信息流是推荐系统应用中的当红炸子鸡,它表现形式有很多:社交网络的动态信息流、新闻阅读的图文信息流、短视频信息流等等。
如果要搭建一个自己的信息流系统,它应该是怎么样的呢?今天,我就来带你一探信息流架构的究竟。
信息流,通常也叫作feed,这个英文词也很有意思,就是“喂”给用户的意思。
传统的信息流产品知识简单按照时间排序,而被推荐系统接管后的信息流逐渐成为主流,按照兴趣排序,也叫作“兴趣feed”。
所以我们通常提到信息流,或者兴趣feed,其实都是在说同一个话题。
这里温馨提示一下:如果要搜索feed相关的技术文章,你应该用“Activity Stream”作为关键词去搜,而不应该只用“feed”搜索,Activity Stream之于feed,就好比多潘立酮之于吗丁啉,前者是行话,后者是通俗说法。
要实现一个信息流,整体逻辑上是比较清楚的。可以划分为两个子问题。
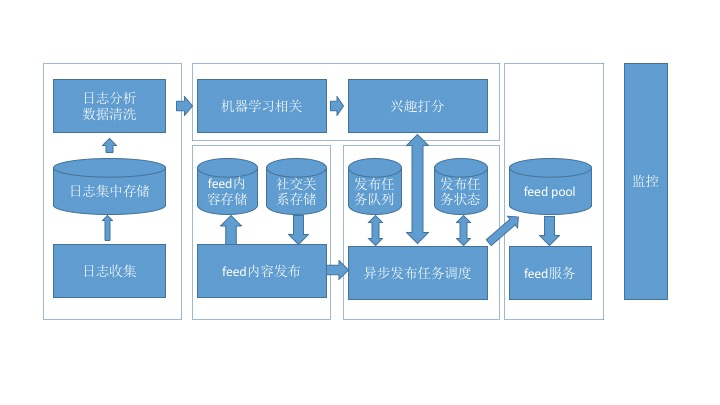
我这里先给出一个整体的框架,然后再分别详谈。
这张架构图划分成几个大的模块:日志收集、内容发布、机器学习、信息流服务、监控。这里分别介绍一下:
信息流的基本数据有三个:用户(User)、内容(Activity)和关系(Connection)。
用户不用说,就是区别不同用户的身份ID,我来说一说其他的两种。
用于表达Activity的元素有相应的规范,叫作Atom,你可以参考它并结合产品需求,定义出自己的信息流数据模型来。
根据Atom规范的定义,一条Activity包含的元素有:Time、Actor、Verb、Object、Target、Title、Summary。下面详细解释一下这些元素。
举个例子: 2016年5月6日23:51:01(Time)@刑无刀(Actor) 分享了(Verb) 一条微博(Object) 给 @极客时间 (Target)。把前面这句话去掉括号后的内容就是它的Title,Summary暂略。
除了上面的字段外,还有一个隐藏的ID,用于唯一标识一个Activity。社交电商Etsy在介绍他们的信息流系统时,还创造性地给Activity增加了Owner属性,同一个Activity可以属于不同的用户,相当于考虑了方向。
互联网产品里处处皆连接,有强有弱,好友关系、关注关系等社交是较强的连接,还有点赞、收藏、评论、浏览,这些动作都可以认为是用户和另一个对象之间建立了连接。有了连接,就有信息流的传递和发布。
定义一个连接的元素有下面几种。
如果把建立一个连接视为一个Activity模型的话,From就对应Activity中的Actor,To就对应Activity中的Object。
连接的发起从From到To,内容的流动从To到From。Connection和Activity是相互加强的,这是蛋和鸡的关系:有了Activity,就会产生Connection,有了Connection,就可以“喂”(feed)给你更多的Activity。
在数据存储上可以选择的工具有下面的几种:
Activity存储可以采用MySQL、Redis、Cassandra等;
Connection存储可以采用MySQL;
User存储可以采用MySQL。
用户登录或者刷新后,信息流是怎么产生的呢?我们把动态内容出现在受众的信息流中这个过程称为Fan-out,直觉上是这样实现的:
上面这个步骤别看简单,在一个小型的社交网络上,通常很有效,而且Twitter早期也是这么做的。这就是江湖行话说的“拉”模式(Fan-out-on-load),即:信息流是在用户登录或者刷新后实时产生的。这里有一个示意图,你可以点击查看。
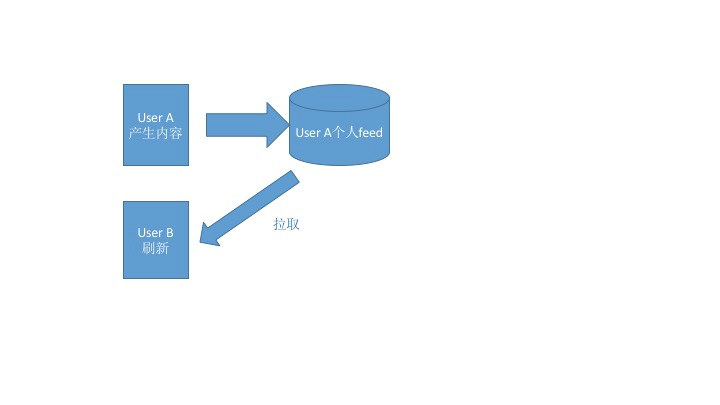
拉模式就是当用户访问时,信息流服务才会去相应的发布源拉取内容到自己的feed区来,这是一个阻塞同步的过程。“拉”模式的好处也显而易见,主要有下面两种。
但是也有很大的不足:
与“拉”模式对应,还有一个“推”模式(Fan-out-on-write)。我在文稿里放了一张图,你可以点击查看。
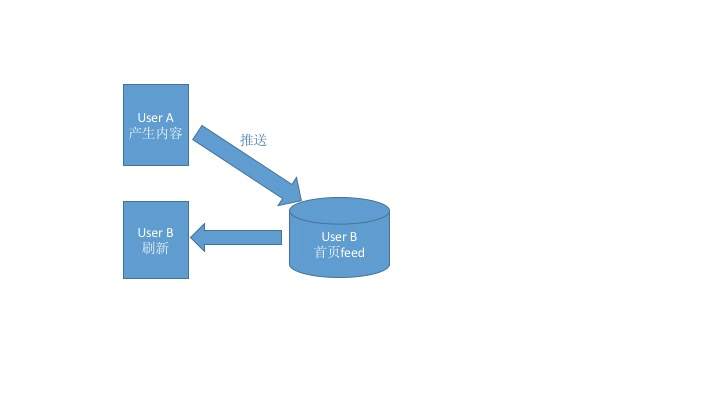
当一个Actor产生了一条Activity后,不管受众在不在线,刷没刷新,都会立即将这条内容推送给相应的用户(即和这个Actor建立了连接的人),系统为每一个用户单独开辟一个信息流存储区域,用于接收推送的内容。如此一来,当用户登录后,系统只需要读取他自己的信息流即可。
“推”模式的好处显而易见:在用户访问自己的信息流时,几乎没有任何复杂的查询操作,所以服务可用性较高。
“推”模式也有一些不足。
既然两者各有优劣,那么实际上就应该将两者结合起来,一种简单的结合方案是全局的:
还有一种结合方案是分用户的,这是Etsy的设计方案:
在中小型的社交网络上,采用纯推模式就够用了,结合的方案可以等业务发展到一定规模后再考虑。
对于信息流的产生和存储可以选择的工具有:
信息流的排序,要避免陷入两个误区:
第一个误区“没有目标”意思就是说,设计排序算法之前,一定要先弄清楚为什么要对时间序重排?希望达到什么目标?只有先确定目标,才能检验和优化算法。
第二个误区是“人工量化”,也就是我们通常见到的产品同学或者运营同学要求对某个因素加权、降权。这样做很不明智,主要是不能很好地持续优化。
目前信息流采用机器学习排序,以提升类似互动率,停留时长等指标,这已经成为共识。比如说提高互动率则需要下面几个内容。
首先,定义好互动行为包括哪些,比如点赞、转发、评论、查看详情等;
其次,区分好正向互动和负向互动,比如隐藏某条内容、点击不感兴趣等是负向的互动。
基本上到这里就可以设计成一个典型的二分类监督学习问题了,对一条信息流的内容,在展示给用户之前,预测其获得用户正向互动的概率,概率就可以作为兴趣排序分数输出。
能产生概率输出的二分类算法都可以用在这里,比如贝叶斯、最大熵、逻辑回归等。
互联网常用的是逻辑回归(Logistic Regression),谁用谁知道,用过的都说好;也有Facebook等大厂采用了逻辑回归加梯度提升树模型(又称GBDT)来对信息流排序,效果显著。
如今大厂都已经转向深度学习了,但我还是建议小厂或者刚起步的信息流先采用线性模型。
对于线性模型,一个重要的工作就是特征工程。信息流的特征有三类:
排序模型在实际使用时,通常做成RPC服务,以供发布信息流时调用。
信息流是一个数据驱动的系统,既要通过历史数据来寻找算法的最优参数,又要通过新的数据验证排序效果,所以搭建一个数据流管道就是大家翘首期盼的。
这个管道中要使用的相关数据可能有:
对于一个从零开始的信息流,没必要做到在线实时更新排序算法的参数,所以数据的管道可以分成三块:
像Pinterest早期的管道也差不多就是这样。
在离线训练优化模型时,关注模型的AUC是否有提升,线上AB测试时关注具体的产品目标是否有提升,比如互动率等,同时还要根据产品具体形态关注一些辅助指标。
另外,互动数据相比全部曝光数据,数量会小得多,所以在生成训练数据时需要对负样本(展示了却没有产生互动的样本)进行采样,采样比例也是一个可以优化的参数。
固定算法和特征后,在0.1~0.9之间遍历对比实验,选择最佳的正负比例即可。经验比例在2:3左右,即负样本略大于正样本,你可以用这个比例做启发式搜索。
今天我逐一梳理了实现一个通用信息流的关键模块,及其已有的轮子,从而能最大限度地降低开发成本。
这些对于一个中小型的社交网络来说已经足够,当你面临更大的社交网络,会有更多复杂的情况出现,尤其是系统上的。
所以,壮士,请好自为之,时刻观察系统的监控、日志的规模。
你在了解了典型的信息流架构之后,可以说一说Facebook这样的社交网络feed,和头条这样的资讯信息流之间的差别和共同点吗?欢迎给我留言。
