我们懂得了原理,知道了实际推荐系统需要考虑哪些元素之后。正当你摩拳擦掌之际,如果发现要先从挖地基开始,你整个人可能是崩溃的。
但是事实上你没必要这样做也不应该这样做。大厂研发力量雄厚,业务场景复杂,数据量大,自己从挖地基开始研发自己的推荐系统则是非常常见的,然而中小厂职工们则要避免重复造轮子。这是因为下面的原因。
既然要避免重复造轮子,就要知道有哪些轮子。
有别于介绍一个笼统而大全的“推荐系统”轮子,我更倾向于把粒度和焦点再缩小一下,介于最底层的编程语言API和大而全的”推荐系统”之间,本文按照本专栏的目录给你梳理一遍各个模块可以用到的开源工具。
这里顺带提一下,选择开源项目时要优先选择自己熟悉的编程语言、还要选有大公司背书的,毕竟基础技术过硬且容易形成社区、除此之外要考虑在实际项目中成功实施过的公司、最后还要有活跃的社区氛围。
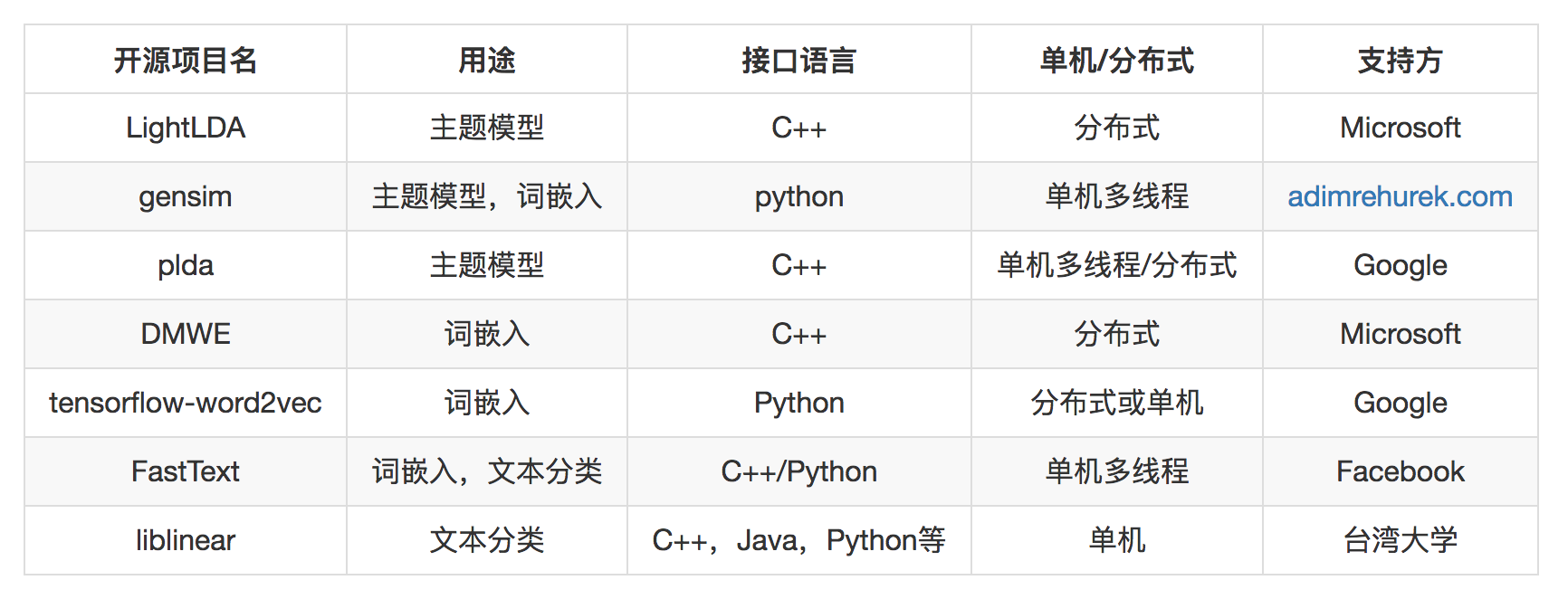
基于内容的推荐,主要工作集中在处理文本,或者把数据视为文本去处理。文本分析相关的工作就是将非结构化的文本转换为结构化。主要的工作就是三类。
可以做这三类工作的开源工具有下面的几种。
由于通常我们遇到的数据量还没有那么大,并且分布式维护本身需要专业的人和精力,所以请慎重选择分布式的,将单机发挥到极致后,遇到瓶颈再考虑分布式。
这其中FastText的词嵌入和Word2vec的词嵌入是一样的,但FastText还提供分类功能,这个分类非常有优势,效果几乎等同于CNN,但效率却和线性模型一样,在实际项目中久经考验。LightLDA和DMWE都是微软开源的机器学习工具包。
基于用户、基于物品的协同过滤,矩阵分解,都依赖对用户物品关系矩阵的利用,这里面常常要涉及的工作有下面几种。
可以做这些工作的开源工具有下面几种。
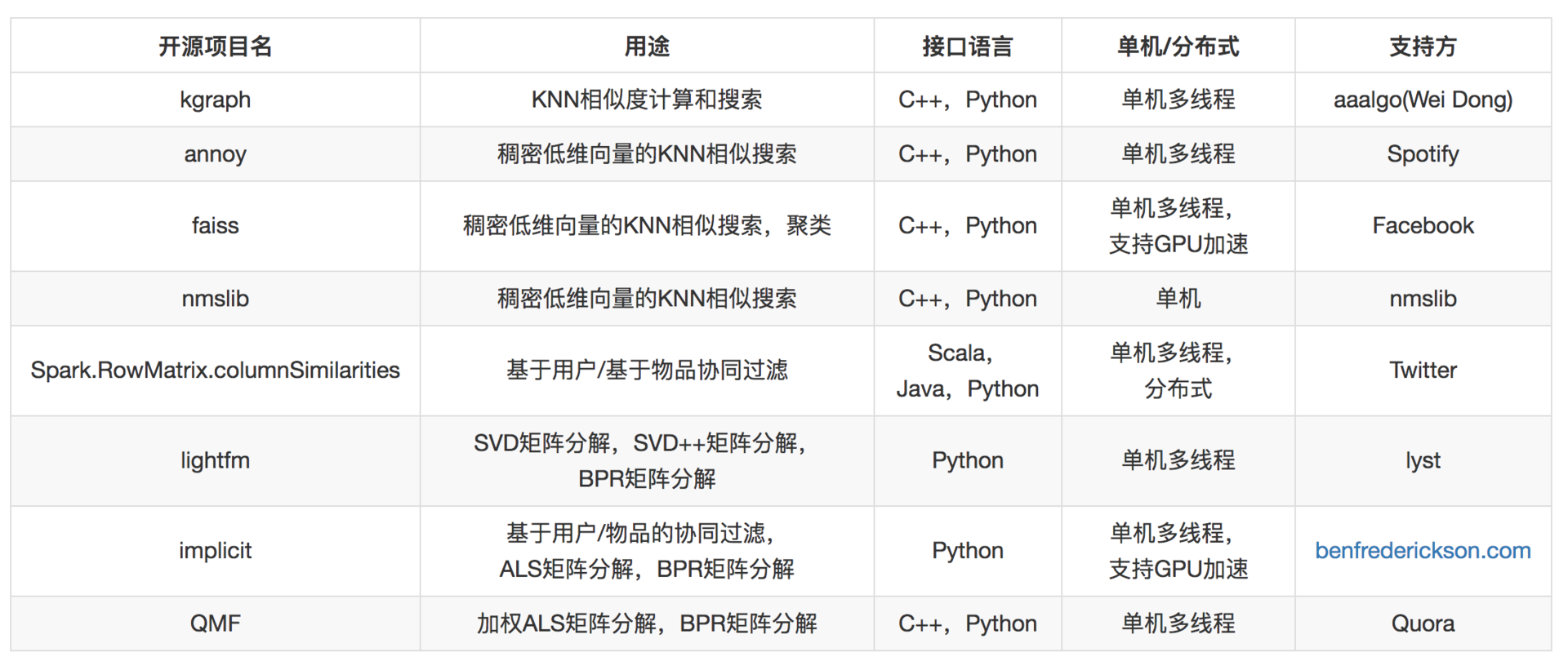
这里面的工作通常是这样:基础协同过滤算法,通过计算矩阵的行相似和列相似得到推荐结果。
矩阵分解,得到用户和物品的隐因子向量,是低维稠密向量,进一步以用户的低维稠密向量在物品的向量中搜索得到近邻结果,作为推荐结果,因此需要专门针对低维稠密向量的近邻搜索。
同样,除非数据量达到一定程度,比如过亿用户以上,否则你要慎重选择分布式版本,非常不划算。
模型融合这部分,有线性模型、梯度提升树模型。
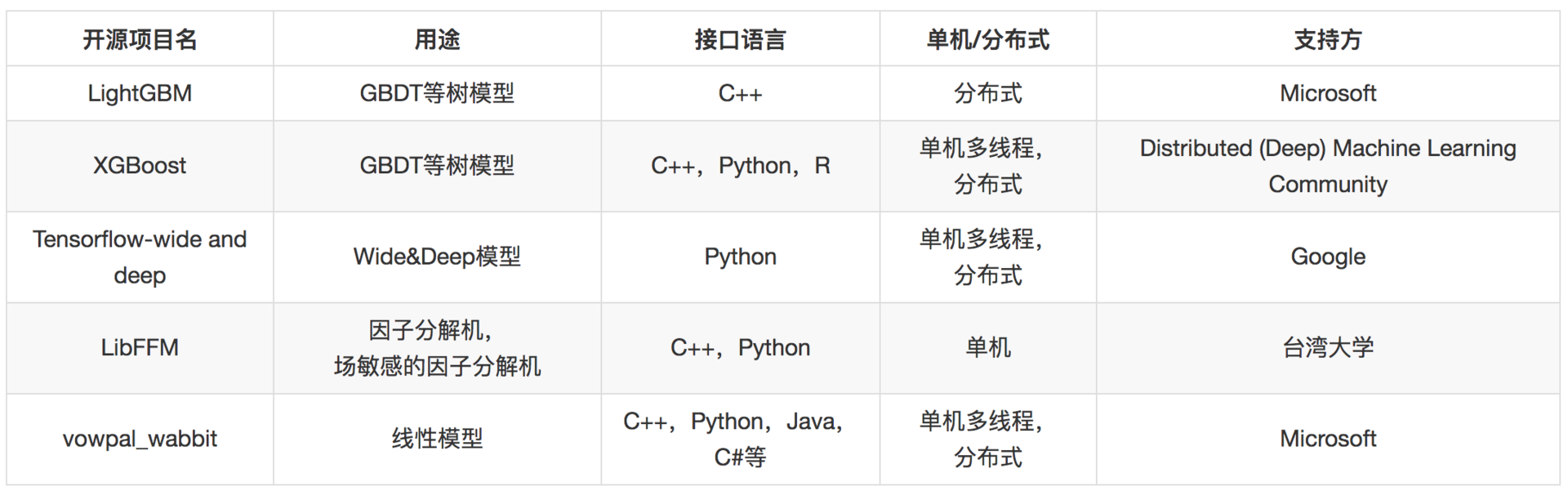
线性模型复杂在模型训练部分,这部分可以离线批量进行,而线上预测部分则比较简单,可以用开源的接口,也可以自己实现。
Bandit算法比较简单,自己实现不难,这里不再单独列举。至于深度学习部分,则主要基于TensorFlow完成。
存储、接口相关开源项目和其他互联网服务开发一样,也在对应章节文章列出,这里不再单独列出了。
这里也梳理一下有哪些完整的推荐系统开源项目,可以作为学习和借鉴。 所谓完整的推荐系统是指:包含推荐算法实现、存储、接口。
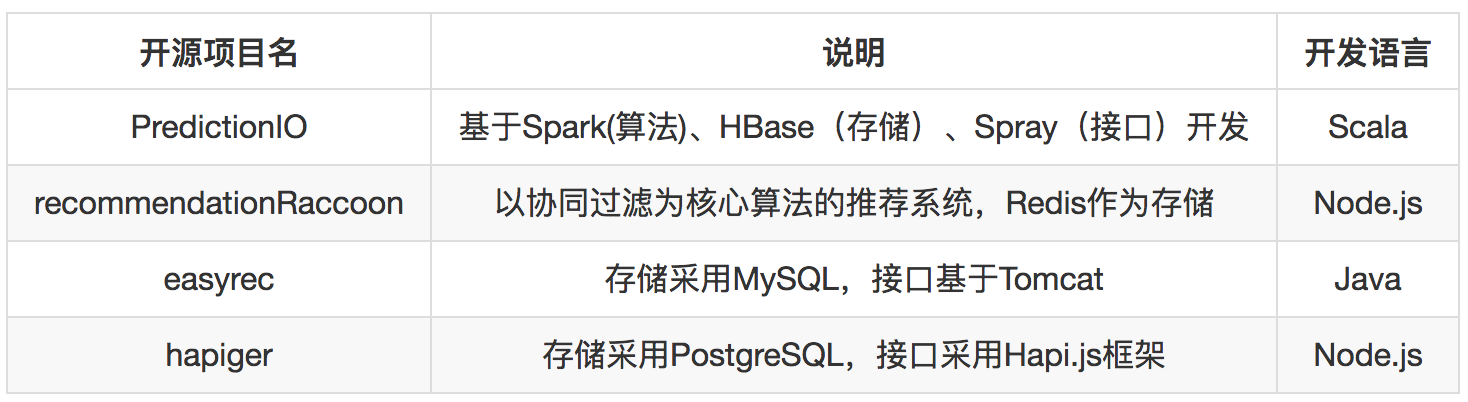
你可能注意到了,这里的推荐系统算法部分以Python和C++为主,甚至一些Python项目,底层也都是用C++开发而成。
因此在算法领域,以Python和C++作为开发语言会有比较宽泛的选择范围。
至于完整的推荐系统开源项目,由于其封装过于严密,比自己将大模块组合在一起要黑盒很多,因此在优化效果时,不是很理想,需要一定的额外学习成本,学习这个系统本身的开发细节,这个学习成本是额外的,不是很值得投入。
因此,我倾向于选择各个模块的开源项目,再将其组合集成为自己的推荐系统。这样做的好处是有下面几种。
当然,还是那句话,实际问题实际分析,也许你在你的情境下有其他考虑和选择。如果还有哪些开源项目,你觉得值得推荐,也欢迎留言分享。
评论