
你好,我是建元。
音频在采集、处理、压缩、传输、播放等过程中,不可避免的会对音频的质量产生影响。这节课我们就一起来看一下,音频质量是如何进行评价的。
你是否还记得,在之前我们讲音频编码封装的时候,讲过有损编码和无损编码。对于有损编码,有的人听上去几乎和无损一致,有的人却能听出差别。再比如降噪算法,降噪算法可能会对人声产生损伤、也可能有残余噪声影响听感。因此,评判一个降噪算法的好坏也需要一套综合的音频评价体系。
其实音频的评价方法主要有两种。一种是主观评价,即组织足够数量的人来听被测音频样本,并给每个被测样本打分,最后根据测试人打分的高低来评判音频质量的好坏。主观测试是音频评价的黄金准则,这样的评价是最符合人的实际听感的。但是主观评测费时费力,在算法迭代、研发等中间过程中不一定是最经济的方案。
另一种测试方法是客观测试,即通过数学方式计算出一些音频质量评价所需要的指标,比如信噪比(SNR)、频谱差异等。然后综合这些指标去拟合一个主观分数。这样就可以通过数学计算而不是人来给出一个音频质量的评价。
但无论是主观测试还是客观测试,都需要遵守一套严格的测试评价标准,来保证音频质量评价的准确性。那么下面我们先来看看主观评价有哪些可用的方法。
在介绍主观测试方法前,先介绍一个组织:ITU(国际电信联盟)。ITU是联合国下属的一个专门机构,负责电信、通话等相关标准的制定。其中的无线电通信组(ITU-R)和远程通信标准化组织(ITU-T)为了统一国际的音频质量评价方法制定了一系列的主、客观评价方法。按照ITU的评价方法,你的音频算法或者系统的评价结果才会比较有公信力。好了,下面就让我们以ITU主观评价方法中的MUSHRA为例来介绍一下如何做音频主观评价。
MUSHRA(Multi-Stimulus Test with Hidden Reference and Anchor,多激励隐藏参考基准测试方法)属于ITU-R BS.1534中的推荐测试方法。它最早被用于流媒体与通信的相关编码的主观评价,现在也被广泛应用于心理声学相关研究中的音质主观评价。其测试的特点主要是在测试语料中混入无损音源作为参考(上限),全损音源作为锚点(下限),通过双盲听测试,对待测音源和隐藏参考音源与锚点进行主观评分。
所谓“双盲”就是测试人和提供测试的人都不知道自己要听的是哪段语料,这个在测试环节中很重要。比如,如果你提前告诉测试人“你的算法会让声音中的风声不那么刺耳”之类的暗示,或者在测试的时候双号为无损语料,单号为测试语料,这样的操作都会让测试结果不具有参考性。
MUSHRA的分数是0到100分,按照从高到低的听感描述,如表1所示:
测试规范中有很多测试细节,这里我罗列一下。为了保证测试的有效性,主要需要注意以下4点:
参考的标准音频和被测试音频间隔测试,连续重复4次;
音频源采用15~20s;
一次完整的测试时间不应超过15~20min;
测试成员:专家成员最少10人,非专家20人。
这里我解释一下为什么要注意这些细节。
这里举一个用MUSHRA给不同语音合成算法打分的例子,具体如图1所示。图中的REF就是无损的音源,Anchor35就是我们说的锚点(预估只有35分)。这里还把无损音频的采样位深调为8bit,标记为8bit μ-law REF。而其它则是代表不同的语音合成算法。
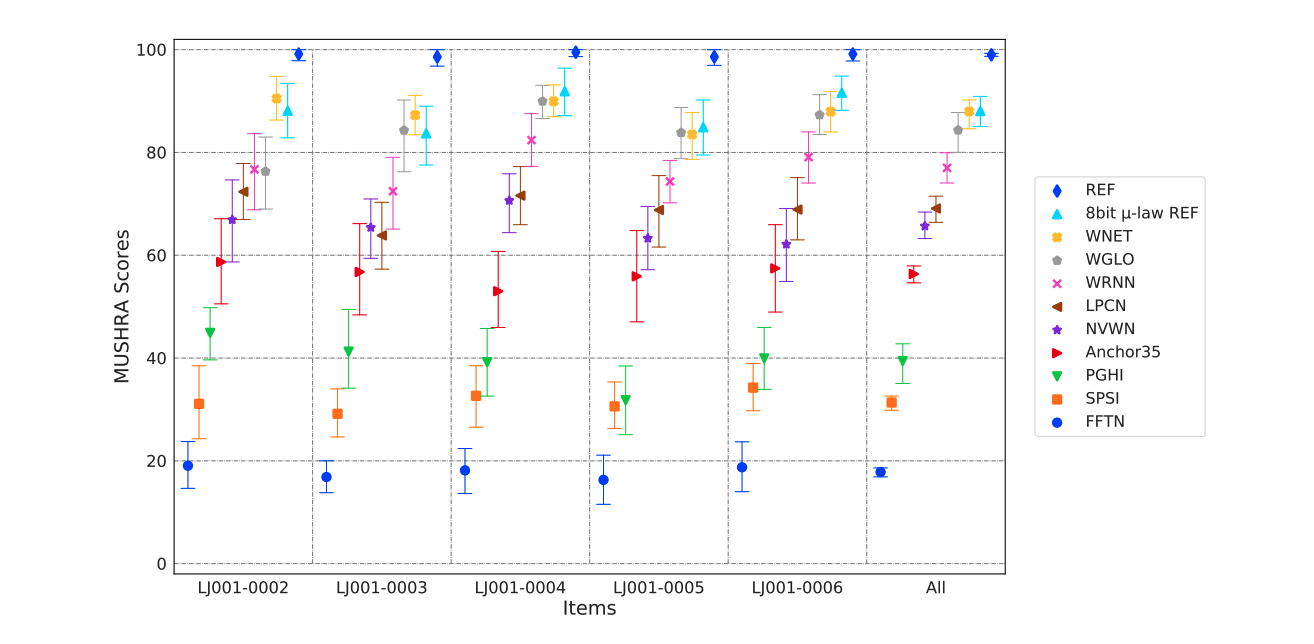")
我们可以看到WNET的分数最高很接近无损音源,这代表这种算法的语音生成质量最好。锚点一般是质量很差的音频,在图1中甚至有些算法的分数比锚点还低,这代表他们的生成效果极差。这些极差的算法甚至还抬高了锚点的分数,我们可以看到Anchor35最后的MUSHRA评分在50~60分之间。
为了方便人们测试使用,GitHub上有基于Web版的MUSHRA 自动打分工具,你可以自行下载使用。
MUSHRA方法的测试面比较广,可以用于编/解码器,语音合成,甚至是耳机测评。除了MUSHRA,在ITU中还有其它一些针对不同场景的音频测评标准,比如ITU-T评价标准中的ITU-T P.800《语音质量的主观评价方法》,也就是我们常说的MOS(Mean Option Scores,平均意见分),以及ITU-T P.830《电话和宽带数字语音编码器的主观评价方法》、ITU-T P.805《对话质量的主观评价》等。ITU-R主观评价标准中的ITU-R BS.1116 《音频系统中小损伤主观评价方法》、ITU-R BS.1285 《音频系统中小损伤主观评价的预选方法》等。如果你有兴趣可以上ITU官网自行查看。
主观评价的缺点是:人少了、执行不规范都会带来测试偏差。那么有没有什么客观评价的方法,可以给出可复现又贴近主观评价的结果呢?下面我就来为你介绍一下符合这些要求的客观评价方法。
客观评价主要包括有参考评价和无参考评价。所谓有参考评价就是除了测试音频以外,还需要同时给出一个参考音频做为基准,通过计算测试音频和参考音频的区别来拟合出音频的主观得分。而无参考的客观评价则不需要参考音频,直接根据音频的频谱能量分布、连续性等指标来评分。
我们先来看一下有参考的客观评价方法。在2001年,ITU-T P.862标准定义了有参考客观评价算法PESQ(Perceptual Evaluation of Speech Quality,语音质量感知评价),该算法主要用来评估窄带(8kHz 采样率)及宽带(16kHz采样率)下的编解码损伤。该算法在过去的二十年中,被广泛的应用于通信质量的评定。
随着技术的发展,PESQ的应用范围变得越来越窄,于是在2011年,P.863标准定义了一套更全面、更准确的有参考客观评价算法POLQA。相比PESQ,POLQA可评估的带宽更广,对噪声信号和延时的鲁棒性更好,其语音质量评分也更接近于主观的评分。
PESQ算法已经开源,而POLQA你需要购买一套专门的设备和授权才能使用。所以目前做一些日常的测试中,PESQ还是用的比较多的方法。这里我们主要介绍一下PESQ算法的基本原理。PESQ算法的处理步骤如图2所示:

图2中待测系统就是你的音频系统或者算法,比如一个编/解码器。为了消除系统延迟的影响,首先,将参考信号和系统处理后的信号经过相同的预处理后进行时间对齐;然后,进行听觉变换把音频信号转化为频谱信号;接着,再对能量谱逐帧进行差异处理;最后,取时间平均得到PESQ分数。如果发现有的音频片段差异特别巨大,则表明存在对齐错误,需要对没对齐的片段进行再对齐。
PESQ的分数范围在0~4.5分,一般音质比较好的编/解码器,比如64kbps比特率的OPUS编解码器,可以达到4.5分,而分数越低则代表音质越差。比如OPUS的码率降到6kbps那PESQ可能就只有不到3的分数。
值得注意的是,PESQ最多只能评价16kHz采样率的音频。如果要评价一个采样率比较高的音频信号,比如音乐信号,POLQA会比较合适。POLQA最高可以支持48kHz采样率的全带音频的客观质量评价。购买一套POLQA设备的价格都是百万级的,为了方便使用,你还可以考虑一下使用例如ViSQOL 等开源算法,也可以支持48kHz的音频采样率。
有的时候我们可能无法获得参考音频,比如在打网络电话时,只有接收到的经过编/解码和网络传输的音频信号,没有远端的输入信号。这时候无参考音频质量评价方法就派上用场了。不需要参考信号,仅通过对输入信号本身或参数的分析即可得到一个质量评分。比较著名的无参考客观评价方法有ITU-T P.563、ANIQUE+、E-model、ITU-T P.1201等。
其中,ITU-T P.563于2004年提出,主要是面向窄带语音的质量评估;ANIQUE+于2006年提出,也是面向窄带语音,其评分准确度据作者称超过了PESQ,不过PESQ的测量不能反应网络的延时、丢包等,并不能完美适用于如今基于互联网传输的实时互动场景。E-model于2003年提出,不同于上述两种方法,这是一个基于VoIP链路参数的损伤定量标准,不会直接基于信号域进行分析。ITU-T P.1201系列于2012年提出,对于音频部分,该标准也不对音频信号直接进行分析,而是基于网络状态和信号状态对通信质量进行评分。
其实在实际使用中由于实时音频处理过程复杂,除了编解码器和网络对音频可能造成损伤,音频的处理步骤比如降噪、回声消除等步骤,也可能对音频的质量造成影响。现有的无参考音频质量评价还不能准确地反映音频的实际质量情况,或者说使用的时候还有很多限制,比如隐私问题无法获得音频信号或者音频链路的信息指标无法准确获得。所以无参考音频质量评价还有很多有待研究的地方。
好了,为了方便你记忆,这里我用图来总结一下音频质量评价的方法。
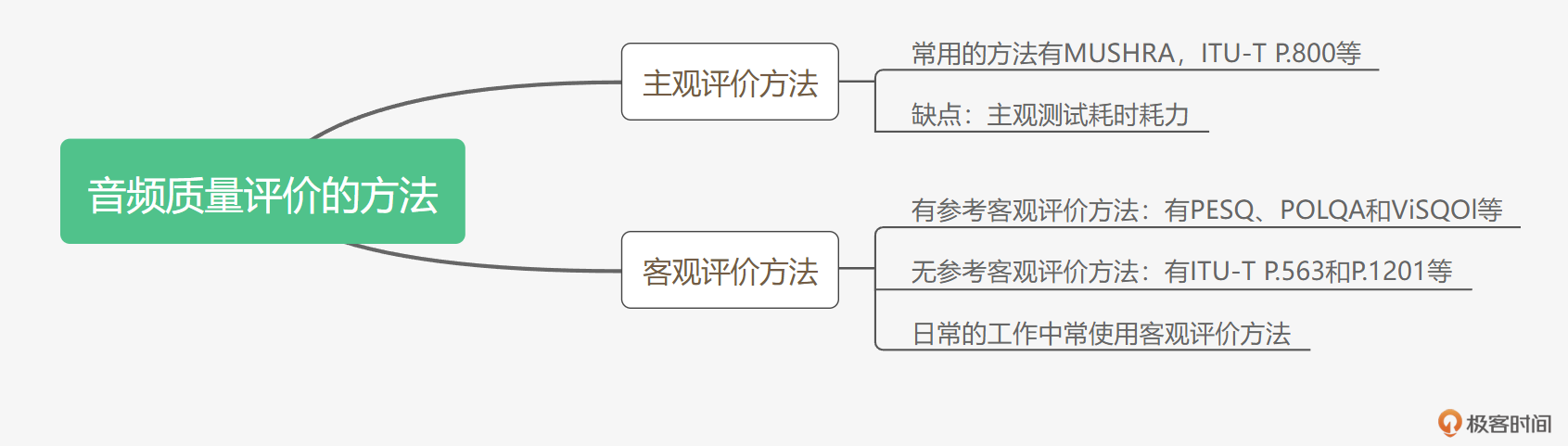
注意客观测试目前只能测量音频的损伤程度,比如我们平时在选择编解码器时不知道选择什么类型、多少码率,这时不妨跑一下PESQ或者VisQol看一下分数。而对于一些偏主观的测试类型,比如音乐听感、耳机效果等,则一般还是需要依靠主观测试。主观测试有时候也不需要你自己组织,你也可以采用众包等方式把测试分发出去。针对这种分发式的主观测试,最近的ITU-T P.808也有详细的测试流程和方法,如果你有兴趣,可以自行了解一下。
通过这节课的学习,你掌握了多少知识呢?我这里有一道思考题留给你。
如果我们想对一款在线通话App做实时通话质量打分,我们可以采用什么样的音频评价方法?
你可以把你的答案和感受写下来,分享到留言区,与我一起讨论。我们下节课再见。