你好,我是李江。
上一节课我们一起讨论了帧内预测。帧内预测主要是通过当前编码块它的相邻的已经编码完成的像素预测得到预测块,从而达到减少空间冗余的目的。我们知道在视频编码时主要需要去除4个冗余,包括:空间冗余、时间冗余、视觉冗余和信息熵冗余。那么这节课我们接着之前的课程,继续讲讲如何减少时间冗余。
提醒一下,这节课难度比较高,涉及的知识点又很多,建议你多看几遍。我也会尽量简化过程,把基本的原理讲清楚。你在这里打好了基础,再去学习更高阶的内容就轻松多了。
我们已知,视频在1秒钟内有很多帧图像,其通过帧率来表示。一般来说帧率为24fps或者30fps,也就是指,1秒钟会有多达24帧或者30帧图像。
但是其实在自然状态下,人或者物体的运动速度在1秒钟之内引起的画面变化并不大,且自然运动是连续的。所以前后两帧图像往往变化比较小,这就是视频的时间相关性。帧间预测就是利用这个特点来进行的。通过在已经编码的帧里面找到一个块来预测待编码块的像素,从而达到减少时间冗余的目的。
那么在正式讲解之前,还有三点我需要特别强调一下。
第一,在帧内预测中,我们是在当前编码的图像内寻找已编码块的像素作为参考像素计算预测块。而帧间预测是在其他已经编码的图像中去寻找参考像素块的。这正是帧内预测和帧间预测的区别。
第二,帧间预测是可以在多个已经编码的图像里面去寻找参考像素块的,我们称之为多参考。多参考和单参考(只在一帧图像里面寻找参考像素块)其实底层的原理是一样的,只是多参考需要多搜索几个参考图像去寻找参考块而已,所以我们讲解的时候就使用单参考讲解。这样既可以简化过程,你也可以更容易掌握帧间编码的基本原理。
第三,帧间预测既可以参考前面的图像也可以参考后面的图像(如果参考后面的图像,后面的图像需要提前先编码,然后再编码当前图像)。只参考前面图像的帧我们称为前向参考帧,也叫P帧;参考后面的图像或者前面后面图像都参考的帧,我们称之为双向参考帧,也叫做B帧。B帧相比P帧主要是需要先编码后面的帧,并且B帧一个编码块可以有两个预测块,这两个预测块分别由两个参考帧预测得到,最后加权平均得到最终的预测块。P帧和B帧的底层逻辑基本是一样的。同样为了简化过程,我们这节课以P帧为例子来讲解底层逻辑。
好了,接下来我们就以H264标准为基础来聊聊P帧的帧间编码过程吧。就从最基础的块大小开始讲起。
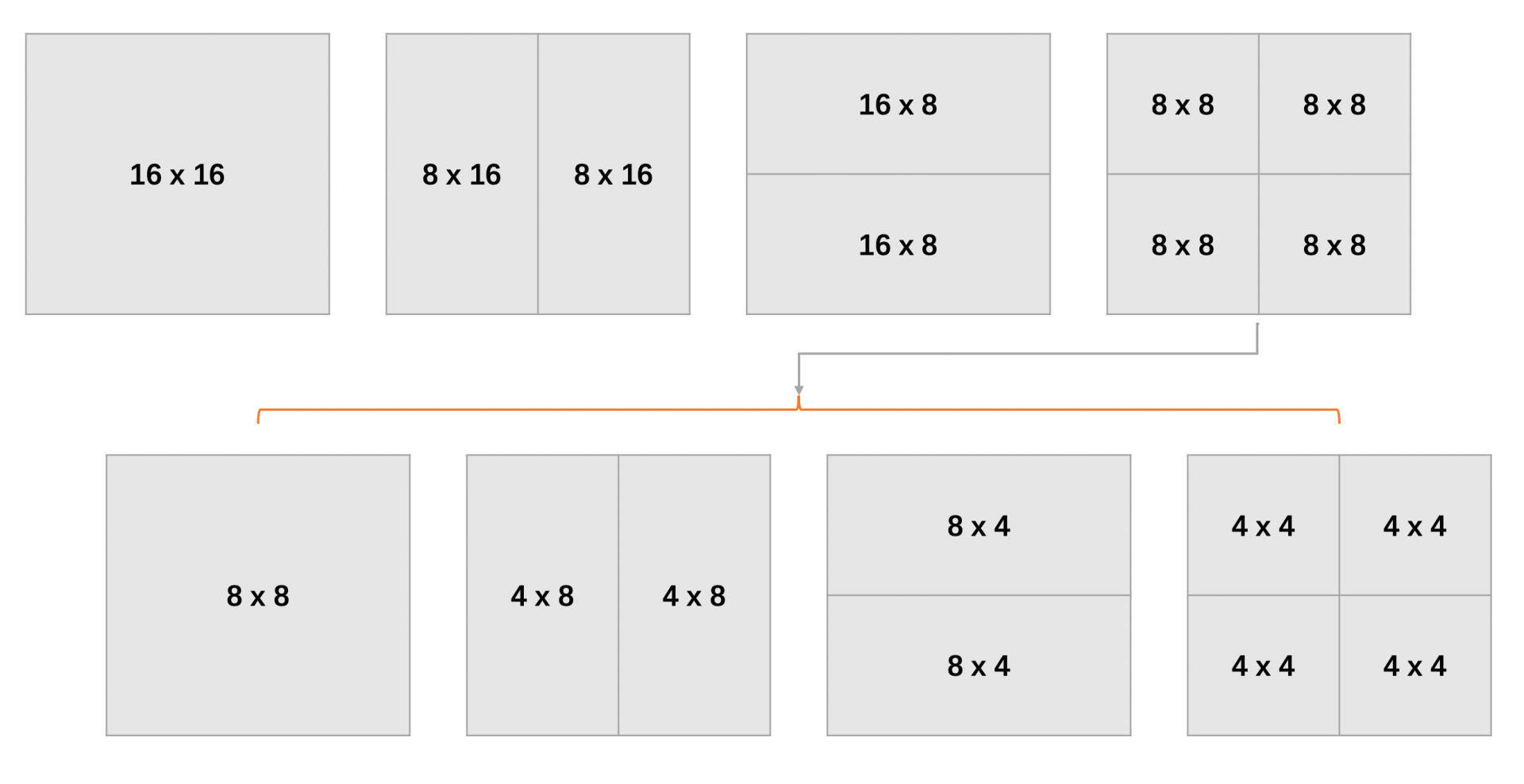
上节课,我们讲到了帧内预测有亮度16 x 16、亮度4 x 4和色度8 x 8这几种块。类似地,在帧间预测也一样有不同的块和子块大小。相比帧内预测,帧间预测的块划分类型要多很多。宏块大小16 x 16,可以划分为16 x 8,8 x 16, 8 x 8三种,其中8 x 8可以继续划分成8 x 4,4 x 8和4 x 4,这是亮度块的划分。在YUV 4:2:0中,色度块宽高大小都是亮度块的一半。亮度宏块的划分方式如下图所示:
在帧间预测中,我们会在已经编码的帧里面找到一个块来作为预测块,这个已经编码的帧称之为参考帧。在H264标准中,P帧最多支持从16个参考帧中选出一个作为编码块的参考帧,但是同一个帧中的不同块可以选择不同的参考帧,这就是多参考。
通常在RTC场景中,比如WebRTC中,P帧中的所有块都参考同一个参考帧。并且一般会选择当前编码帧的前一帧来作为参考帧。为什么呢?
这是因为自然界的运动一般是连续的,同时在短时间之内的变化相对比较小,所以前面的帧通常是最接近当前编码帧的,并且两者的差距比较小。因此,我们比较容易从前一帧中找到一个跟当前编码块差距很小的块作为预测块,这样编码块减去预测块得到的残差块的像素值很多都是0,压缩效率是不是就很高了?
好了,选择好了参考帧之后,我们还有一个问题。虽然运动变化比较小,但是还是有变化啊,比如说下图中的场景。
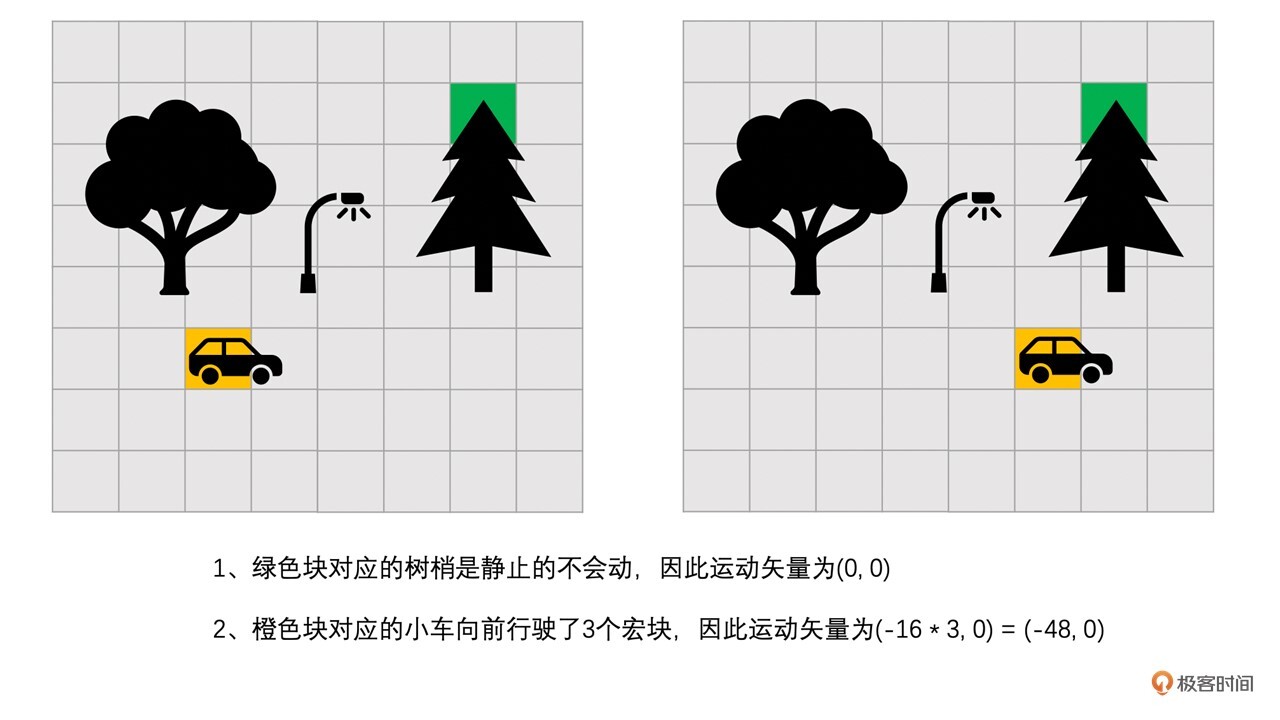
图中的小车在往前开,树是不动的。我们可以看到车相对于树的距离是变化的。那我们怎么来表示这个变化呢?
或者从编码的角度来讲,右边图像中橙色块的内容跟左边图像中橙色块的内容基本一样。很明显,如果以左边图像为参考帧的话,那么左边图像中的橙色块就是最合适的预测块,但是左右两幅图像橙色块的位置很明显又不同,而这种不同是因为图像中的小车的运动引起的。因此,为了表示这种变化,我们用运动矢量来表示编码帧中编码块和参考帧中的预测块之间的位置的差值。
比如说上面两幅图像中,小车从前一幅图像中的(32,80)的坐标位置,变化到当前图像(80,80)的位置,向前行驶了48个像素。很明显,如果我们选用(32,80)这个块作为当前(80,80)这个编码块的预测块的话,是不是就可以得到全为0像素的残差块了?这是因为小车本身是没有变化的,变化的只是小车的位置。
这个位置变化我们怎么表示呢?我们用运动矢量来表示。我们称(32 - 80, 80 - 80)也就是(-48, 0)为运动矢量。我们先把运动矢量编码到码流当中,这样解码端只要解码出运动矢量,使用运动矢量就可以在参考帧中找到预测块了,我们再解码出残差(如果有的话),残差块加上预测块就可以恢复出图像块了。
好了,这就是参考帧和运动矢量。可是还有一个问题:因为我们通过人眼能够看到小车在两幅图像的位置,所以我们可以在参考帧中找到一个与当前编码块相似的块作为预测块,但是编码器怎么找到这个预测块呢?它们又没有眼睛。这就是运动搜索算法应该解决的问题啦。我们接下来就来聊聊运动搜索是怎么做的。
从前面的讨论我们知道,运动搜索的目标就是在参考帧中找到一个块,称之为预测块,且这个预测块与编码块的差距最小。从计算机的角度来说就是,编码块跟这个预测块的差值,也就是残差块的像素绝对值之和(下面我们用SAD表示残差块的像素绝对值之和)最小。
现在是不是目标就清晰很多了。比如说当前编码块大小是16 x 16,那我们就先去参考帧中找到一个个16 x 16的块作为预测块,并用当前编码块减去预测块求得残差块,然后用我们经常做的绝对值求和操作得到两者之间的差距,最后选择差距最小的预测块作为最终的预测块。
所以,我们运动搜索的方法就很简单了,就是从参考帧中第一个像素开始,将一个个16 x 16大小的块都遍历一遍。我们总是可以找到差距最小的块。这种方法我们称之为全搜索算法。
全搜索算法一定可以搜索到最相似的预测块。但是你有没有发现这种方法有一个特别大的缺点就是需要逐个像素去遍历每一个块,非常费时间。由于帧间预测中每一个16 x 16的宏块还可以划分成上面讲的多种不同的子块大小,每一个子块也需要做一遍运动搜索。如果采用这种运动搜索算法的话,那编码一帧的时间将会非常长。
那有没有速度快一点的搜索算法呢?答案肯定是有的。下面我就来介绍一下常用的两种快速运动搜索算法。
在讲述快速算法之前我先说明一下,搜索算法中每一个搜索的点都是搜索块的左上角像素点。比如说菱形和六边形搜索的几个点都指的是以该点为左上角像素点的块。如果所搜块大小为16x16,则指的是以该点为左上角像素点的16x16的块。
(1)从搜索的起始点开始,以起始点作为菱形的中心点。首先以该中心点为左上角像素的16 x 16的块作为预测块,求得残差块并求得像素绝对值之和,也就是SAD。之后对菱形4个角的4个点分别做同样的操作求得SAD值。得到最小的SAD值,最小SAD值对应的点就是当前最佳匹配点。
(2)如果最佳匹配点是菱形的中心点,那我们就找到了预测块了,搜索结束。
(3)如果最佳匹配点不是菱形的中心点,则用以当前最佳匹配点为中心点的菱形继续搜索,重复之前的步骤直到菱形的中心点为最佳匹配点。
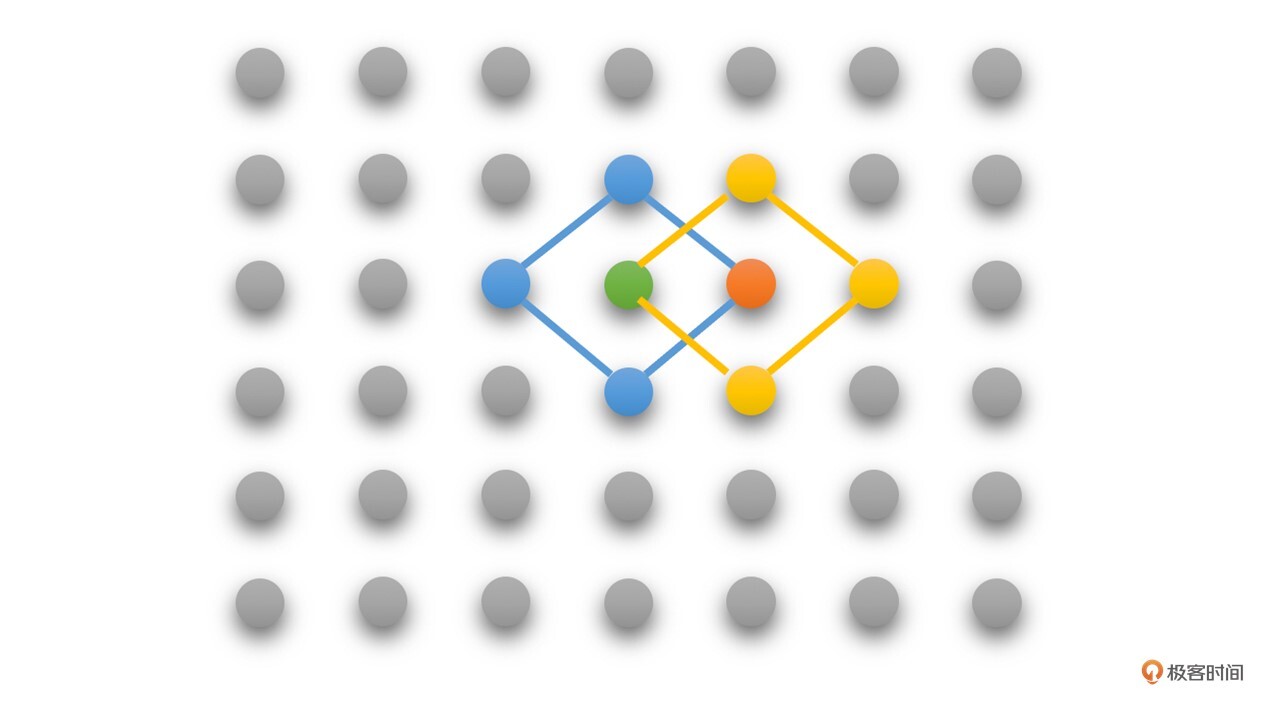
例如,上图中:
第一步,以绿色点(起点)为中心点,搜索绿色点和旁边蓝色线连接的4个点,得到的最佳匹配点为橙色点,非中心点。
第二步,再以橙色点为中心点,搜索橙色点和旁边黄色线连接的4个点,最佳匹配点是中心点橙色点,搜索完毕,橙色点为最佳匹配点。
(1)从搜索的起始点开始,以起始点作为六边形的中心点。求得中心点作为左上角像素的预测块的SAD值。之后对六边形的角上的6个点做同样的操作求得SAD值。得到最小的SAD值,而最小SAD值对应的点就是当前最佳匹配点。
(2)如果最佳匹配点是六边形的中心点,那我们就用以该点为中心点的菱形和正方形各进行一次精细化搜索。找到中心点、菱形的4个顶点和正方形4个顶点中SAD最小的点作为最佳匹配点。
(3)如果最佳匹配点不是六边形的中心点,则用以当前最佳匹配点为中心点的六边形继续搜索,重复之前的步骤直到中心点为最佳匹配点。
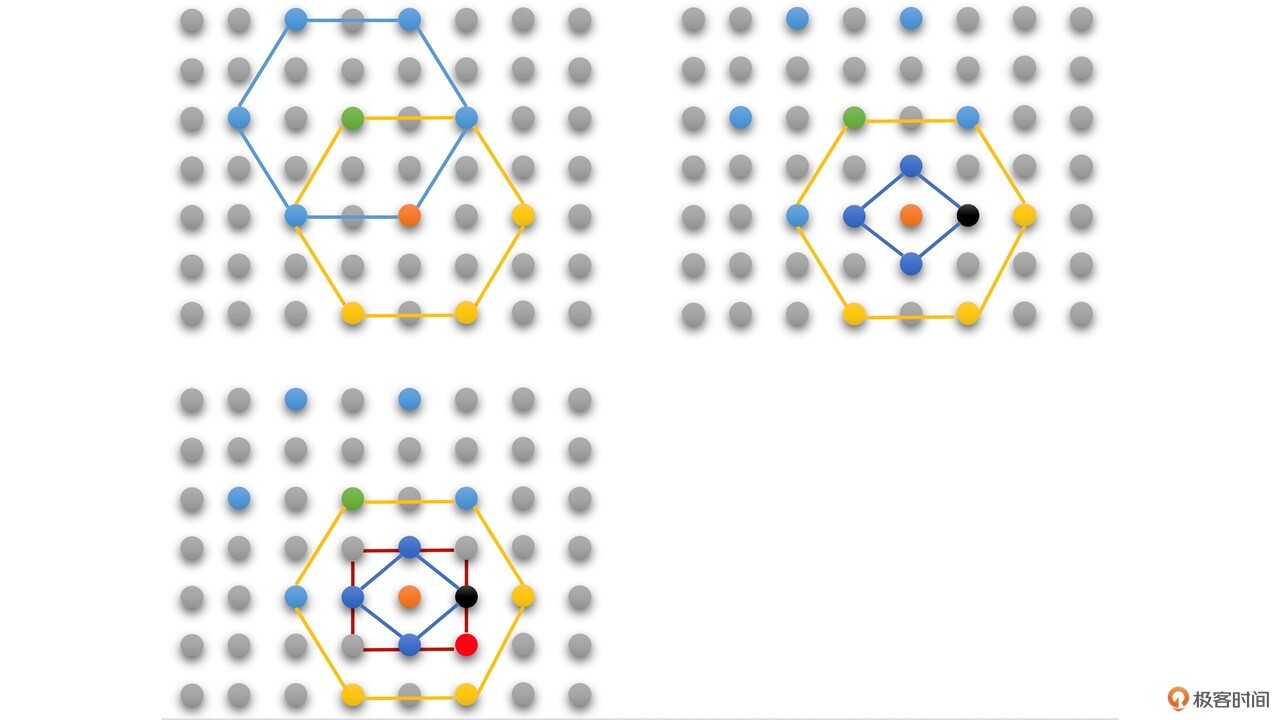
例如,上图中:
第一步,以绿色点(起点)为中心点,搜索中心点和旁边蓝色线连接的6个点,得到的最佳匹配点为橙色点,非中心点。
第二步,再以橙色点为中心点,搜索橙色点和旁边黄色线连接的6个点,最佳匹配点是是中心点橙色点。
第三步,再以橙色点为中心点,搜索橙色点和旁边蓝色线连接菱形的4个点,最佳匹配点为黑色点。
第四步,还是以橙色点为中心点,搜索旁边红色线连接的正方形的4个点,并与菱形搜索得到的最佳匹配点黑色点比较,找到最后的最佳匹配点为红色点,搜索完毕。
通过上面的快速搜索算法我们就能够得到编码块在参考帧中的最佳匹配点,以最佳匹配点为左上角像素的块就是预测块,并且预测块左上角像素在参考帧中的坐标(x1, y1)与编码块在当前编码帧中的坐标(x0, y0)的差值(x1 - x0, y1 - y0)就是运动矢量。
上面两种运动搜索算法都是以搜索形状的中心点为最佳匹配点结束的。但是还有一个问题我们没有解释,那就是搜索的起始点怎么确定呢?
其实搜索的起始点可以使用当前编码块的左边块、右边块、左上角块和右上角块的运动矢量预测得到。具体预测方法我们会在下面的运动矢量预测小节里面讲解。其总体的思路就是我们认为,一般一个块最大也就16 x 16的大小,而运动的物体一般远大于这个大小,所以相邻块的运动方向大多数是很相似的。因此,我们一般会通过相邻已经编码块的运动矢量来预测当前块的运动矢量。这个预测的运动矢量也经常用做搜索的起点。
有了快速运动搜索算法我们就不需要遍历整个参考帧的像素去寻找预测块了,这样速度可以快很多。但是必须要说明一下,就是快速搜索算法也有一个缺点,它搜索到的预测块不一定是全局最优预测块,也就是说不一定是最相似的块,有可能是局部最优预测块。
但是实验数据表明,快速搜索算法相比全搜索算法压缩性能下降非常小,速度却可以提升十几倍到几十倍。所以总的来说,我们可以认为快速搜索算法是远好于全搜索算法的,并且一般全搜索算法是不会实际使用的。
好了,经过上面的讨论,我们已经知道了运动搜索的具体思路了。但是我们还有一个疑问:如果一个物体运动了,比如小车向前行驶了48个像素点,那我们就可以通过运动矢量(-48,0)在参考帧中找到小车。我们前面也说了,小车的运动是连续的,如果小车向前行驶了48.5个像素点呢?又或者是向前行驶了48.25个像素点呢?运动矢量选择(-48.5, 0)或者(-48.25,0)吗?可是0.5个像素点是什么样的,0.25个像素点又是什么样的?图像上都没有这种像素点啊,怎么办呢?
其实没关系的,我们还是可以使用(-48,0)作为运动矢量,只是预测块中的小车位置与我们编码块中的小车位置会相差个0.5或者0.25个像素,得到的残差会大一些,压缩效率稍微低一些,问题也不大。
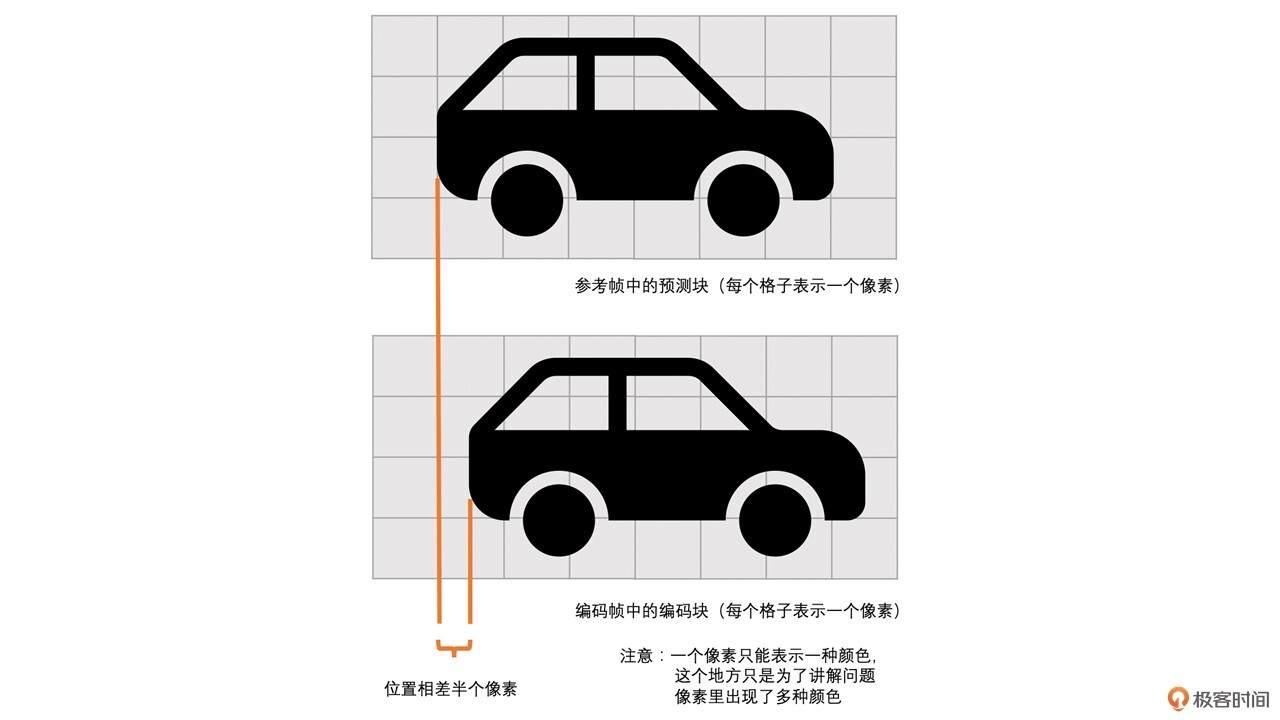
比如上面图中的小车,如果直接用编码块减去参考块的话,因为两个块中小车的位置没有完全重合,所以残差块不等于0。这样还是有残差的,因此压缩效率会低一些。
但是勤劳智慧的人类是不会停止前进的脚步的。为了能够解决这种半个像素或者1/4个像素的运动带来的压缩效率下降的问题,我们通过对参考帧进行半像素和1/4像素插值(统称为亚像素插值)的方式来解决。
什么意思呢?就是我们用插值的方式将半像素和1/4像素算出来,也当作一个像素,这样小车向前行驶48.5个像素也好,向前行驶48.25个像素也好,都是可以通过运动矢量找到比较准确的位置的。那亚像素插值具体怎么做呢?我们接下来看一下。
亚像素插值归根到底还是插值操作,我们在第3节课里面已经讨论过了一些插值算法。亚像素插值的思想跟前面课里的插值算法的思想是一样的,都是通过已经有的像素点经过一定的加权计算得到需要求得的像素。
在这里,已经有的像素就是整像素(就是图像本身有的像素称为整像素),需要插值求得的就是半像素和1/4像素。其中半像素通过整像素插值得到,1/4像素又是通过整像素和半像素插值得到的。因此,我们先通过整像素插值得到半像素,然后再通过半像素和整像素插值得到1/4像素。半像素的插值过程可以通过下面的图示表示:
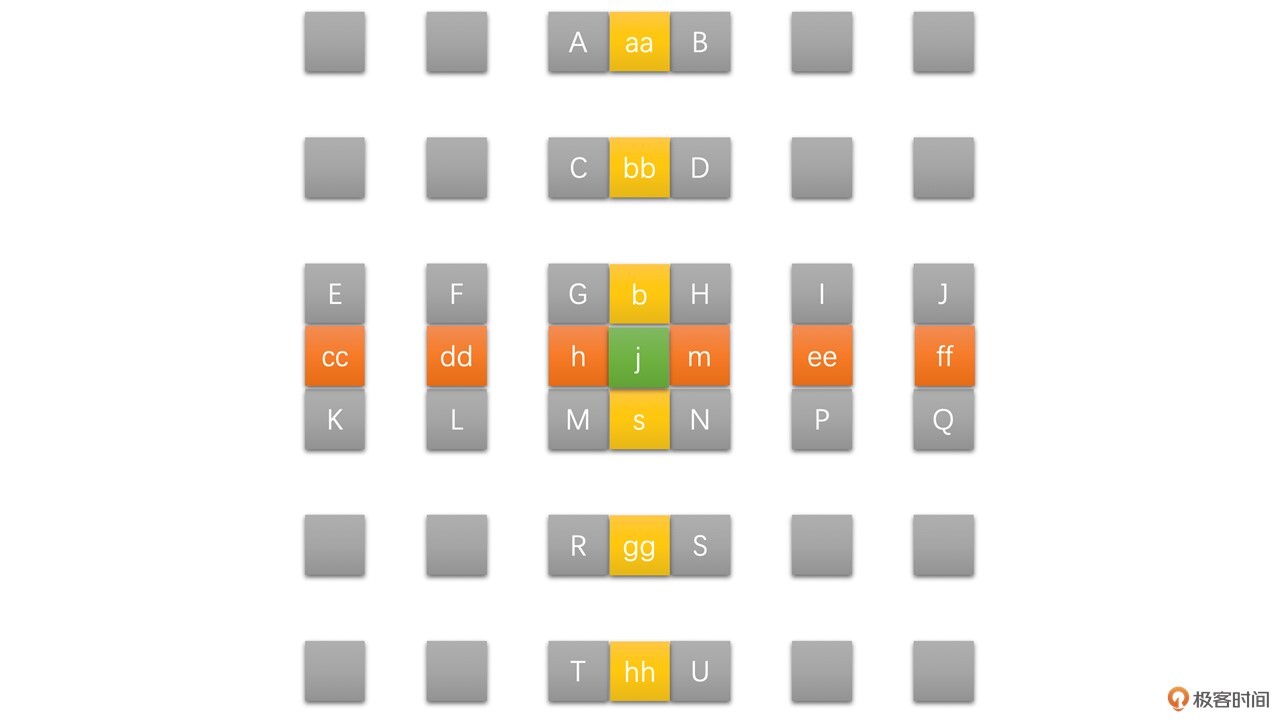
其中,灰色为整像素点,橙色为水平半像素,黄色为垂直半像素点,绿色为中心半像素点。
半像素点的插值是以6个整像素点使用六抽头插值滤波器计算得到的,滤波器权重系数为:(1/32, -5/32, 5/8, 5/8, -5/32, 1/32)。具体计算方法如下:

得到了半像素之后,1/4像素就比较简单,由整像素和半像素求平均值得到,其插值过程可以通过下图表示:
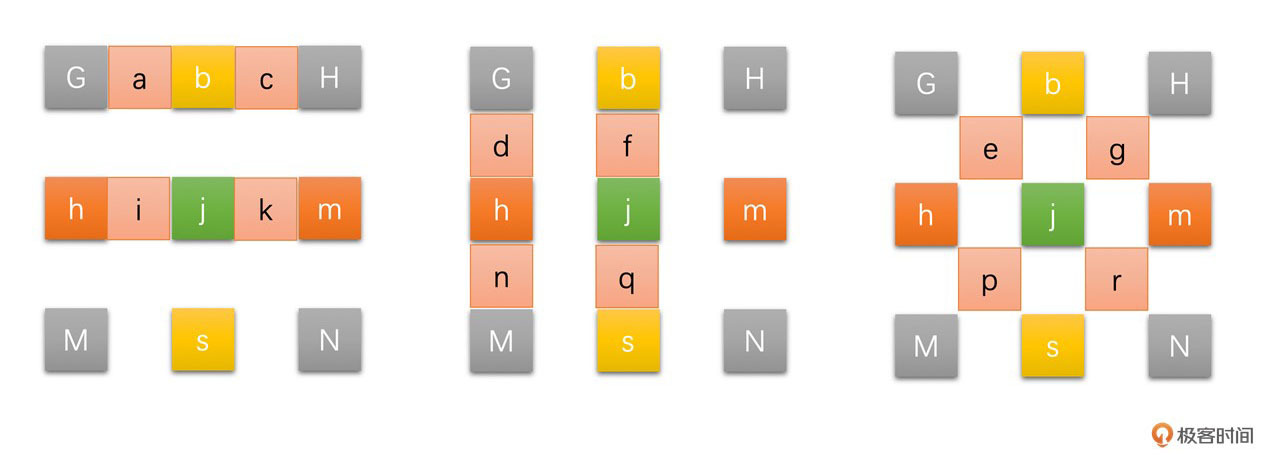
其中,红色点为1/4像素点,具体计算方法如下:

整个半像素和1/4像素的插值过程可以通过下图表示:
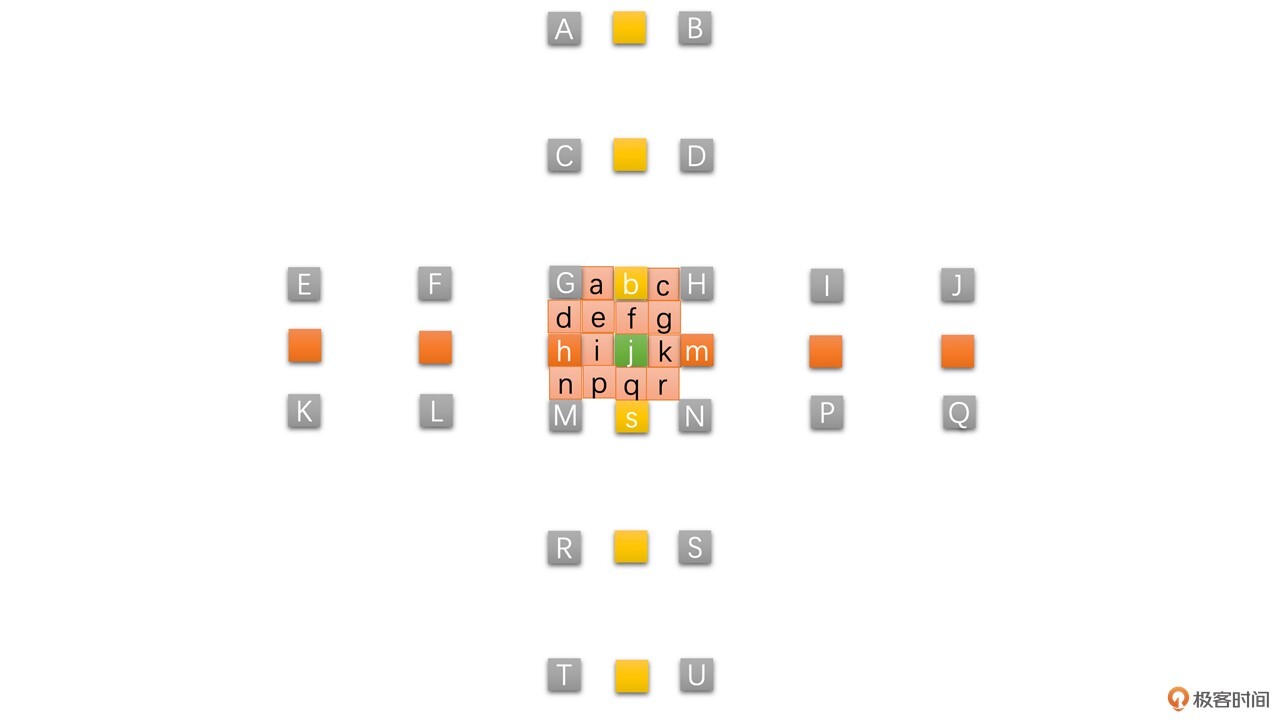
插值得到了所有的半像素和1/4像素之后,我们就可以用运动矢量表示0.5个像素和0.25个像素的移动了,就如之前小车向前行驶了48.5个像素。如果只是整像素的图像,那只能表示出向前行驶了48个像素或者49个像素,没办法表示48.5个像素。
我们用下面的几幅图像来直观地感受一下一个4x4的像素块的半像素图像和1/4像素图像的像素位置。首先来看一幅4x4的像素块的像素位置。

下面图中的红色的4x4像素表示水平半像素图像。

下面图中的红色的4x4像素表示垂直半像素图像。

下面图中的红色的4x4像素表示水平、垂直半像素图像。

下面图中的绿色的4x4像素表示水平1/4像素图像。
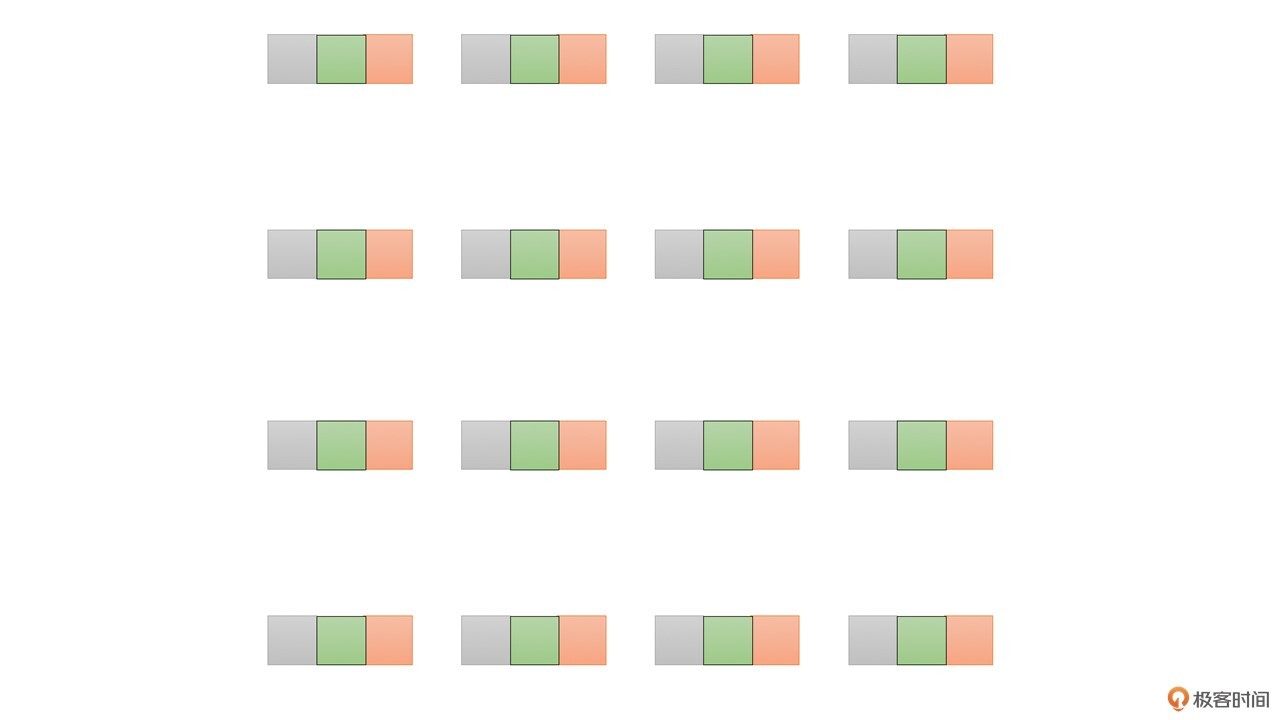
下面图中的绿色的4x4像素表示垂直1/4像素图像。

下面图中的绿色的4x4像素表示水平、垂直1/4像素图像。

有了上面的亚像素插值算法,前面的小车运行48.5个像素的问题就可以通过半像素插值在参考帧中插值得到一辆新的小车,从而就可以解决之前预测块和编码块位置不重合的问题。不过,还需要说明一下的就是,插值得到的小车跟原始的小车的对应像素点的像素值并不是完全一样的,毕竟插值得到的像素点是利用滤波算法加权平均得到的。
因此,半像素插值得到的预测块并不一定就比整像素预测块的残差小。只是我们多了很多个半像素预测块和1/4像素预测块的选择,所以我们可以在整像素预测块、半像素预测块和1/4像素预测块里面选择一个最好的。怎么选择呢?其实是在整像素运动搜索的基础上,再做一次精细化的亚像素运动搜索。下面我们就来讲讲亚像素运动搜索的过程是怎样的。
有了插值得到的亚像素,我们就可以进行亚像素精度的搜索了。一般搜索算法步骤如下:

相当于原先的运动矢量乘以了4,即原先1/4像素的0.25变成了1,0.5像素变成了2,1个像素则变成了4。这主要是因为我们不用小数形式来表示运动矢量。因为浮点型数据会有精度误差,所以我们通过乘以4把它变成整数。
通过上面的整像素运动搜索和亚像素精度运动搜索,我们就得到了最终的运动矢量了。有了运动矢量之后,我们需要将运动矢量的信息也编码到码流中,并且解码的时候直接取出来用就可以在参考帧中把预测块找出来了。那运动矢量是直接编码到码流中的吗?其实不是的。那是怎么做的呢?接下来我们就来讨论一下运动矢量的预测。
其实,运动矢量跟我们的编码块一样不是直接编码进去的,而是先用周围相邻块的运动矢量预测一个预测运动矢量,称为MVP。将当前运动矢量与MVP的残差称之为MVD,然后编码到码流中去的。解码端使用同样的运动矢量预测算法得到MVP,并从码流中解码出运动矢量残差MVD,MVP+MVD就是运动矢量了。
那运动矢量预测算法是怎样的呢?我们以16 x 16宏块为例通过下图来描述。
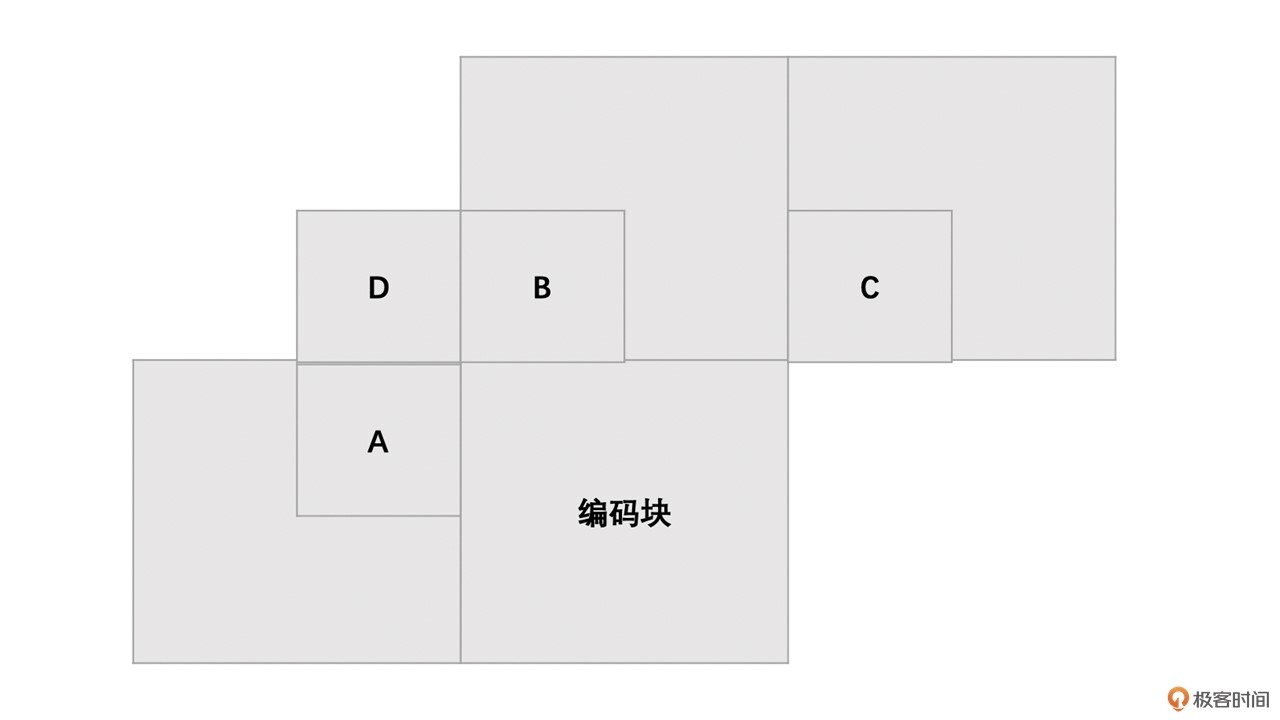
其步骤如下:
了解了运动矢量的预测算法之后,我们还需要介绍一种比较特殊的模式,也是经常会遇到的一种帧间模式,就是SKIP模式。它的定义是这样的,如果运动矢量就是MVP,也就是说MVD为(0,0),同时,残差块经过变换量化后系数也都是等于0,那么当前编码块的模式就是SKIP。
相比于SKIP模式,其它模式要不就是MVD不为0,要不就是量化后的残差系数不为0,或者两者都不为0。所以说SKIP模式是一种特例,由于MVD和残差块都是等于0,因此压缩效率特别高。
比如说P帧中的静止部分,前后两帧不会变化,运动矢量直接为0,而且残差块像素值本身因为几乎没有变化基本为0,只有少部分噪声引起的比较小的值,量化后更是全部变成了0。这种图像中的静止部分或者是图像中的背景部分大多数时候都是SKIP模式。这种模式非常省码率,且压缩效率非常高。因为需要编码的信息非常少,所以单独在这里跟你讨论一下。
好了,到这里基本的帧间编码的知识我们都有了,接下来我们再来总体过一下P帧宏块的模式选择的过程。
编码块帧间模式的选择其实就是参考帧的选择、运动矢量的确定,以及块大小(也就是块划分的方式)的选择,如果SKIP单独拿出来算的话就再加上一个判断是不是SKIP模式。我们主要是确定这4个东西。
之前的讨论当中我们都是以当前编码帧的前一帧作为参考帧的,也就是说是单参考的,不涉及到参考帧的选择。其实,如果是多参考的话,编码块在选择参考帧的时候只需要遍历每一个参考帧进行块划分,然后再对每一个块进行运动搜索得到运动矢量就可以了。跟单参考相比就是多了一个参考帧遍历的操作。所以我们这里还是以单参考帧的方式来讲讲帧间模式的选择过程。
注意,帧间模式的选择大多数是看编码器的实现的,并且不同编码器实现都会不一样,所以我们只是讲讲其中一种模式选择的思路,具体的细节各个编码器都各不相同。具体选择过程如下:
(1)如果4个8 x 8子块的cost8x8之和小于16 x 16块的cost16x16的话,我们再分别对每一个8 x 8子块划分成4个4 x 4子块,同样分别进行运动搜索,得到每一个4 x 4子块的 cost4x4。
如果4个cost4x4之和小于cost8x8,则将8 x 8块划分成4 x 8和8 x 4两种子块分别求得cost4x8和cost8x4,再根据4个cost4x4、2个cost4x8和2个cost8x4的大小,选择最终的8x8划分的方式,并将对应的cost值更新到cost8x8。
否则不划分8 x 8子块。
(2)如果4个8 x 8子块的最新的cost8x8之和还是小于cost16x16的话,则再将16 x 16划分成两个8 x 16和16 x 8子块,并分别求得cost8x16和cost16x8,对比8x8、16x8、8x16 的cost值,并决定最终16 x 16块的划分方式。
(3)否则的话,不划分16 x 16的块。
好了,这节课到这里就要结束了。我们现在来回顾一下这节课的知识点。
我们通过一步步分析如何在参考帧中准确地找到预测块的方式,讲解了帧间预测中最重要的一些知识点。其主要包括以下5个方面:
参考文献:
https://blog.csdn.net/leixiaohua1020/article/details/45936267。
这篇文章中雷霄骅大神针对H264的帧间预测原理和x264中对应的代码做了非常详细地讲解。在这里非常感谢雷神对视频技术做出的贡献,以及无私地分享视频技术知识。雷神也是我学习视频技术路上的导师。在这里向雷神致敬。
学完了这节课,我有一个思考题留给你。P帧的第一个宏块的MVP怎么得到呢?
欢迎你在留言区和我分享你的思考和疑惑,你也可以把今天所学分享给身边的朋友,邀请他加入探讨,共同进步。下节课再见。