
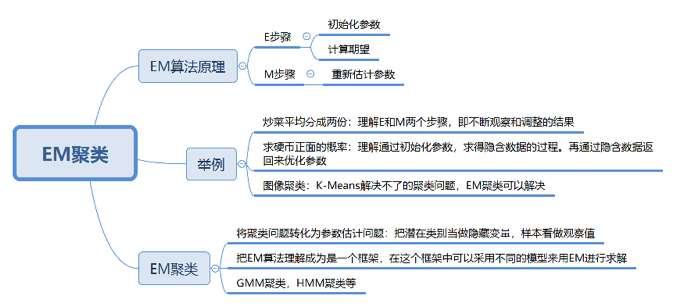
今天我来带你学习EM聚类。EM的英文是Expectation Maximization,所以EM算法也叫最大期望算法。
我们先看一个简单的场景:假设你炒了一份菜,想要把它平均分到两个碟子里,该怎么分?
很少有人用称对菜进行称重,再计算一半的分量进行平分。大部分人的方法是先分一部分到碟子A中,然后再把剩余的分到碟子B中,再来观察碟子A和B里的菜是否一样多,哪个多就匀一些到少的那个碟子里,然后再观察碟子A和B里的是否一样多……整个过程一直重复下去,直到份量不发生变化为止。
你能从这个例子中看到三个主要的步骤:初始化参数、观察预期、重新估计。首先是先给每个碟子初始化一些菜量,然后再观察预期,这两个步骤实际上就是期望步骤(Expectation)。如果结果存在偏差就需要重新估计参数,这个就是最大化步骤(Maximization)。这两个步骤加起来也就是EM算法的过程。
说到EM算法,我们先来看一个概念“最大似然”,英文是Maximum Likelihood,Likelihood代表可能性,所以最大似然也就是最大可能性的意思。
什么是最大似然呢?举个例子,有一男一女两个同学,现在要对他俩进行身高的比较,谁会更高呢?根据我们的经验,相同年龄下男性的平均身高比女性的高一些,所以男同学高的可能性会很大。这里运用的就是最大似然的概念。
最大似然估计是什么呢?它指的就是一件事情已经发生了,然后反推更有可能是什么因素造成的。还是用一男一女比较身高为例,假设有一个人比另一个人高,反推他可能是男性。最大似然估计是一种通过已知结果,估计参数的方法。
那么EM算法是什么?它和最大似然估计又有什么关系呢?EM算法是一种求解最大似然估计的方法,通过观测样本,来找出样本的模型参数。
再回过来看下开头我给你举的分菜的这个例子,实际上最终我们想要的是碟子A和碟子B中菜的份量,你可以把它们理解为想要求得的模型参数。然后我们通过EM算法中的E步来进行观察,然后通过M步来进行调整A和B的参数,最后让碟子A和碟子B的参数不再发生变化为止。
实际我们遇到的问题,比分菜复杂。我再给你举个一个投掷硬币的例子,假设我们有A和B两枚硬币,我们做了5组实验,每组实验投掷10次,然后统计出现正面的次数,实验结果如下:
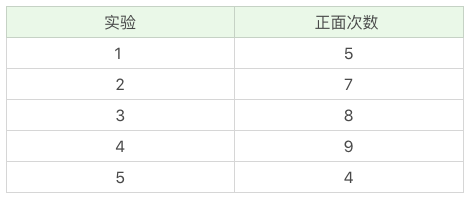
投掷硬币这个过程中存在隐含的数据,即我们事先并不知道每次投掷的硬币是A还是B。假设我们知道这个隐含的数据,并将它完善,可以得到下面的结果:
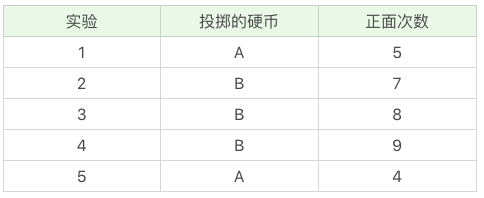
我们现在想要求得硬币A和B出现正面次数的概率,可以直接求得:
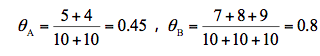
而实际情况是我不知道每次投掷的硬币是A还是B,那么如何求得硬币A和硬币B出现正面的概率呢?
这里就需要采用EM算法的思想。
1.初始化参数。我们假设硬币A和B的正面概率(随机指定)是θA=0.5和θB=0.9。
2.计算期望值。假设实验1投掷的是硬币A,那么正面次数为5的概率为:
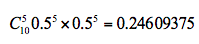
公式中的C(10,5)代表的是10个里面取5个的组合方式,也就是排列组合公式,0.5的5次方乘以0.5的5次方代表的是其中一次为5次为正面,5次为反面的概率,然后再乘以C(10,5)等于正面次数为5的概率。
假设实验1是投掷的硬币B ,那么正面次数为5的概率为:
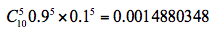
所以实验1更有可能投掷的是硬币A。
然后我们对实验2~5重复上面的计算过程,可以推理出来硬币顺序应该是{A,A,B,B,A}。
这个过程实际上是通过假设的参数来估计未知参数,即“每次投掷是哪枚硬币”。
3.通过猜测的结果{A, A, B, B, A}来完善初始化的参数θA和θB。
然后一直重复第二步和第三步,直到参数不再发生变化。
简单总结下上面的步骤,你能看出EM算法中的E步骤就是通过旧的参数来计算隐藏变量。然后在M步骤中,通过得到的隐藏变量的结果来重新估计参数。直到参数不再发生变化,得到我们想要的结果。
上面你能看到EM算法最直接的应用就是求参数估计。如果我们把潜在类别当做隐藏变量,样本看做观察值,就可以把聚类问题转化为参数估计问题。这也就是EM聚类的原理。
相比于K-Means算法,EM聚类更加灵活,比如下面这两种情况,K-Means会得到下面的聚类结果。

因为K-Means是通过距离来区分样本之间的差别的,且每个样本在计算的时候只能属于一个分类,称之为是硬聚类算法。而EM聚类在求解的过程中,实际上每个样本都有一定的概率和每个聚类相关,叫做软聚类算法。
你可以把EM算法理解成为是一个框架,在这个框架中可以采用不同的模型来用EM进行求解。常用的EM聚类有GMM高斯混合模型和HMM隐马尔科夫模型。GMM(高斯混合模型)聚类就是EM聚类的一种。比如上面这两个图,可以采用GMM来进行聚类。
和K-Means一样,我们事先知道聚类的个数,但是不知道每个样本分别属于哪一类。通常,我们可以假设样本是符合高斯分布的(也就是正态分布)。每个高斯分布都属于这个模型的组成部分(component),要分成K类就相当于是K个组成部分。这样我们可以先初始化每个组成部分的高斯分布的参数,然后再看来每个样本是属于哪个组成部分。这也就是E步骤。
再通过得到的这些隐含变量结果,反过来求每个组成部分高斯分布的参数,即M步骤。反复EM步骤,直到每个组成部分的高斯分布参数不变为止。
这样也就相当于将样本按照GMM模型进行了EM聚类。

EM算法相当于一个框架,你可以采用不同的模型来进行聚类,比如GMM(高斯混合模型),或者HMM(隐马尔科夫模型)来进行聚类。GMM是通过概率密度来进行聚类,聚成的类符合高斯分布(正态分布)。而HMM用到了马尔可夫过程,在这个过程中,我们通过状态转移矩阵来计算状态转移的概率。HMM在自然语言处理和语音识别领域中有广泛的应用。
在EM这个框架中,E步骤相当于是通过初始化的参数来估计隐含变量。M步骤就是通过隐含变量反推来优化参数。最后通过EM步骤的迭代得到模型参数。
在这个过程里用到的一些数学公式这节课不进行展开。你需要重点理解EM算法的原理。通过上面举的炒菜的例子,你可以知道EM算法是一个不断观察和调整的过程。
通过求硬币正面概率的例子,你可以理解如何通过初始化参数来求隐含数据的过程,以及再通过求得的隐含数据来优化参数。
通过上面GMM图像聚类的例子,你可以知道很多K-Means解决不了的问题,EM聚类是可以解决的。在EM框架中,我们将潜在类别当做隐藏变量,样本看做观察值,把聚类问题转化为参数估计问题,最终把样本进行聚类。
最后给你留两道思考题吧,你能用自己的话说一下EM算法的原理吗?EM聚类和K-Means聚类的相同和不同之处又有哪些?
欢迎你在评论区与我分享你的答案,也欢迎点击“请朋友读”,把这篇文章分享给你的朋友或者同事,一起来交流。