你好,我是朱涛。
前面几节课,我们学了一些Kotlin独有的特性,包括扩展、高阶函数等等。虽然我在前面的几节课当中都分别介绍了这些特性的实际应用场景,但那终归不够过瘾。因此,这节课我们来尝试将这些知识点串联起来,一起来写一个“单词词频统计程序”。
英语单词的频率统计,有很多实际应用场景,比如高考、研究生考试、雅思考试,都有对应的“高频词清单”,考生优先突破这些高频词,可以大大提升备考效率。那么这个高频词是如何统计出来的呢?当然是通过计算机统计出来的。只是,我们的操作系统并没有提供这样的程序,想要用这样的功能,我们必须自己动手写。
而这节课,我将带你用Kotlin写一个单词频率统计程序。为了让你更容易理解,我们的程序同样会分为三个版本。
在正式开始学习之前,我也建议你去clone我GitHub上面的TextProcessor工程:https://github.com/chaxiu/TextProcessor.git,然后用IntelliJ打开,并切换到 start 分支跟着课程一步步敲代码。
在正式开始写代码之前,我们先看看程序运行之后是什么样的,一起来分析一下整体的编程思路:
首先,我们的词频统计程序是一个类,“TextProcessorV1”,这是第一个版本的类名称。text是需要被统计的一段测试文本。
所以,我们很容易就能写出这样的代码结构:
class TextProcessorV1 {
fun processText(text: String): List<WordFreq> {
}
}
data class WordFreq(val word: String, val frequency: Int)
这段代码中,我们定义了一个方法processText,它接收的参数类型是String,返回值类型是List。与此同时,我们还定义了一个数据类WordFreq,它里面有两个属性,分别是word和对应的频率frequency。
所以,这个程序最关键的逻辑都在 processText 这个方法当中。
接下来我们以一段简短的英语作为例子,看看整体的统计步骤是怎样的。我用一张图来表示:
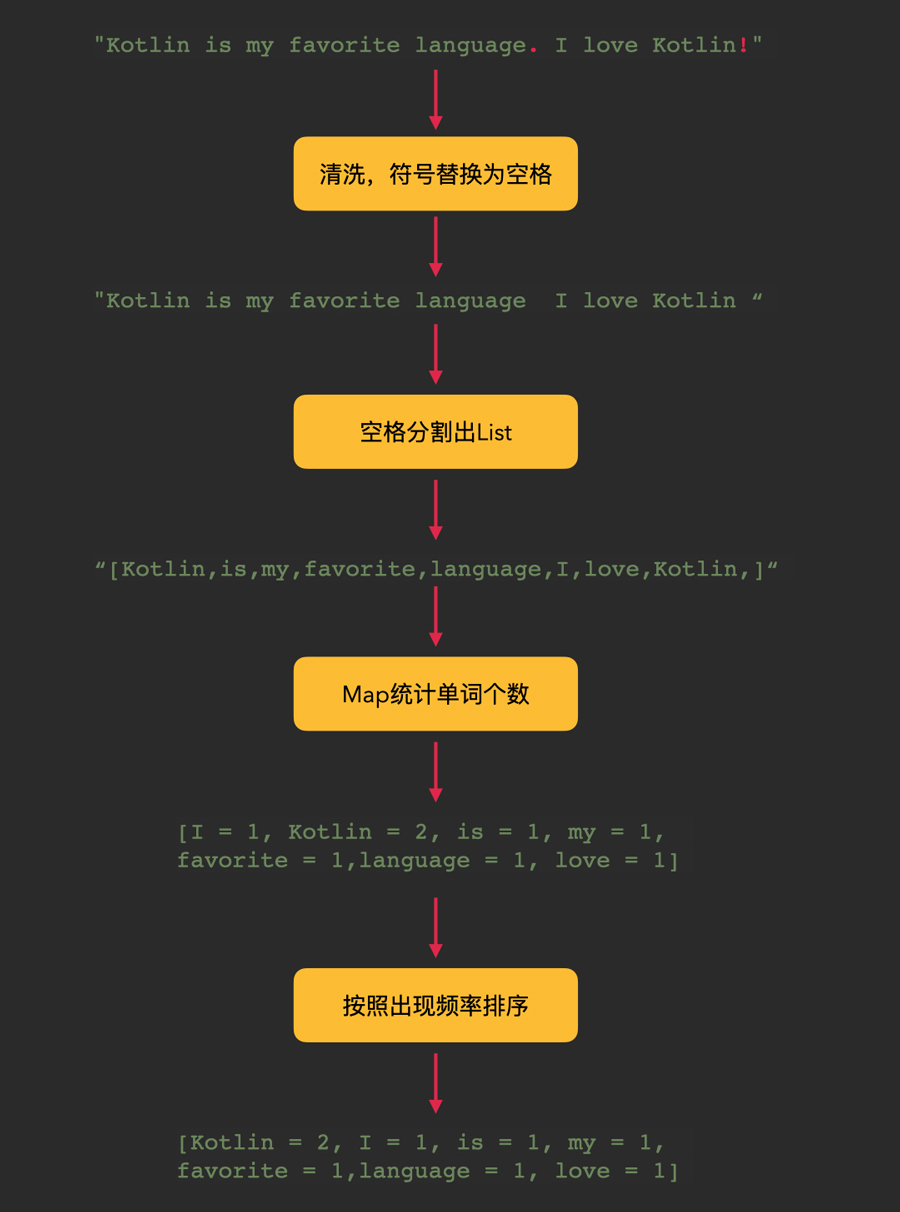
上面的流程图一共分为4个步骤:
经过以上分析,我们就能进一步完善processText()方法当中的结构了。
class TextProcessorV1 {
fun processText(text: String): List<WordFreq> {
// 步骤1
val cleaned = clean(text)
// 步骤2
val words = cleaned.split(" ")
// 步骤3
val map = getWordCount(words)
// 步骤4
val list = sortByFrequency(map)
return list
}
}
其中,步骤2的逻辑很简单,我们直接使用Kotlin标准库提供的 split() 就可以实现空格分割。其余的几个步骤1、3、4,则是由单独的函数来实现。所以下面,我们就来分析下clean()、getWordCount()、sortByFrequency()这几个方法该如何实现。
首先,是文本清洗的方法clean()方法。
经过分析,现在我们知道针对一段文本数据,我们需要将其中的标点符号替换成空格:
// 标点 标点
// 清洗前 ↓ ↓
"Kotlin is my favorite language. I love Kotlin!"
// 空格 空格
// 清洗后 ↓ ↓
"Kotlin is my favorite language I love Kotlin "
那么对于这样的逻辑,我们很容易就能写出以下代码:
fun clean(text: String): String {
return text.replace(".", " ")
.replace("!", " ")
.trim()
}
这样的代码对于前面这种简单文本是没问题的,但这样的方式存在几个明显的问题。
第一个问题是普适性差。在复杂的文本当中,标点符号的类型很多,比如“,”“?”等标点符号。为了应对这样的问题,我们不得不尝试去枚举所有的标点符号:
fun clean(text: String): String {
return text.replace(".", " ")
.replace("!", " ")
.replace(",", " ")
.replace("?", " ")
.replace("'", " ")
.replace("*", " ")
.replace("#", " ")
.replace("@", " ")
.trim()
}
那么随之而来的第二个问题,就是很容易出错,因为我们可能会遗漏枚举的标点符号。第三个问题则是性能差,随着枚举情况的增加,replace执行的次数也会增多。
因此这个时候,我们必须要换一种思路,正则表达式就是一个不错的选择:
fun clean(text: String): String {
return text.replace("[^A-Za-z]".toRegex(), " ")
.trim()
}
上面的正则表达式的含义就是,将所有不是英文字母的字符都统一替换成空格(为了不偏离主题,这里我们不去深究正则表达式的细节)。
这样,数据清洗的功能完成以后,我们就可以对文本进行切割了,这个步骤通过split()就能实现。在经过分割以后,我们就得到了单词的列表。接下来,我们就需要进行词频统计getWordCount()了。
在getWordCount()这个方法当中,我们需要用到Map这个数据结构。如果你不了解这个数据结构也不必紧张,我制作了一张动图,描述getWordCount()的工作流程。
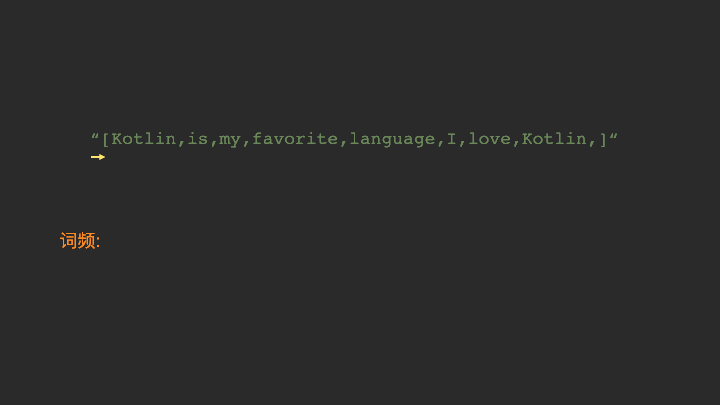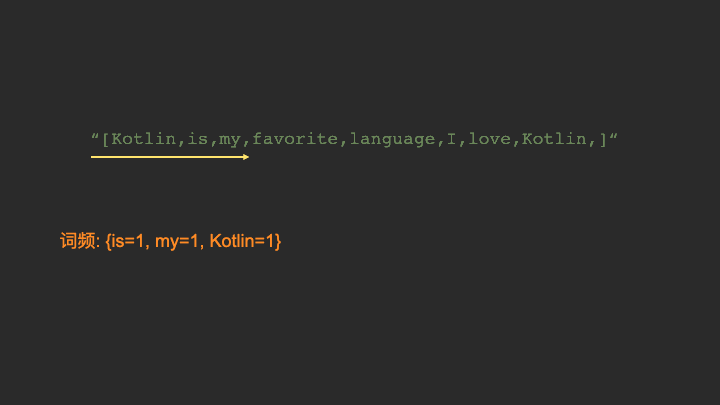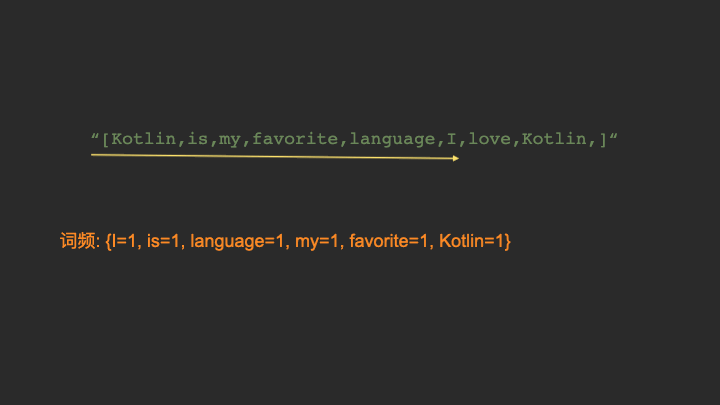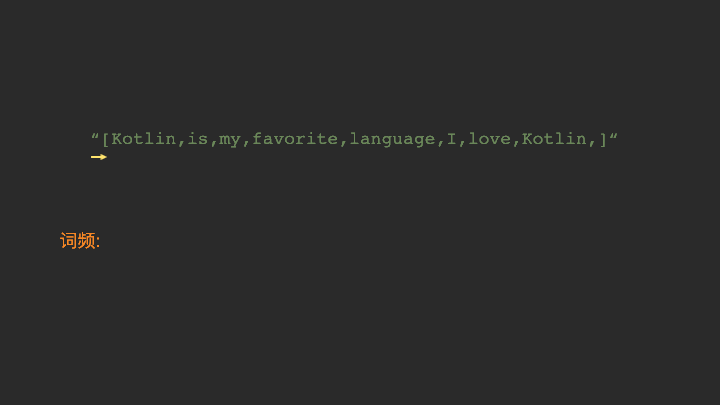
看过上面的Gif动图以后,相信你对词频统计的实现流程已经心中有数了。其实它就是跟我们生活中做统计一样,遇到一个单词,就把这个单词的频率加一就行。只是我们生活中是用本子和笔来统计,而这里,我们用程序来做统计。
那么,根据这个流程,我们就可以写出以下这样的频率统计的代码了,这里面主要用了一个Map来存储单词和它对应频率:
fun getWordCount(list: List<String>): Map<String, Int> {
val map = hashMapOf<String, Int>()
for (word in list) {
// ①
if (word == "") continue
val trim = word.trim()
// ②
val count = map.getOrDefault(trim, 0)
map[trim] = count + 1
}
return map
}
上面的代码一共有两处需要注意,我们一个个看:
这样,通过Map这个数据结构,我们的词频统计就实现了。而因为Map是无序的,所以我们还需要对统计结果进行排序。
那么到这里,我们就又要将无序的数据结构换成有序的。这里我们选择List,因为List是有序的集合。但由于List每次只能存储单个元素,为了同时存储“单词”与“频率”这两个数据,我们需要用上前面定义的数据类WordFreq:
fun sortByFrequency(map: Map<String, Int>): MutableList<WordFreq> {
val list = mutableListOf<WordFreq>()
for (entry in map) {
if (entry.key == "") continue
val freq = WordFreq(entry.key, entry.value)
// ①
list.add(freq)
}
// ②
list.sortByDescending {
it.frequency
}
return list
}
这部分的排序代码其实思路很简单:
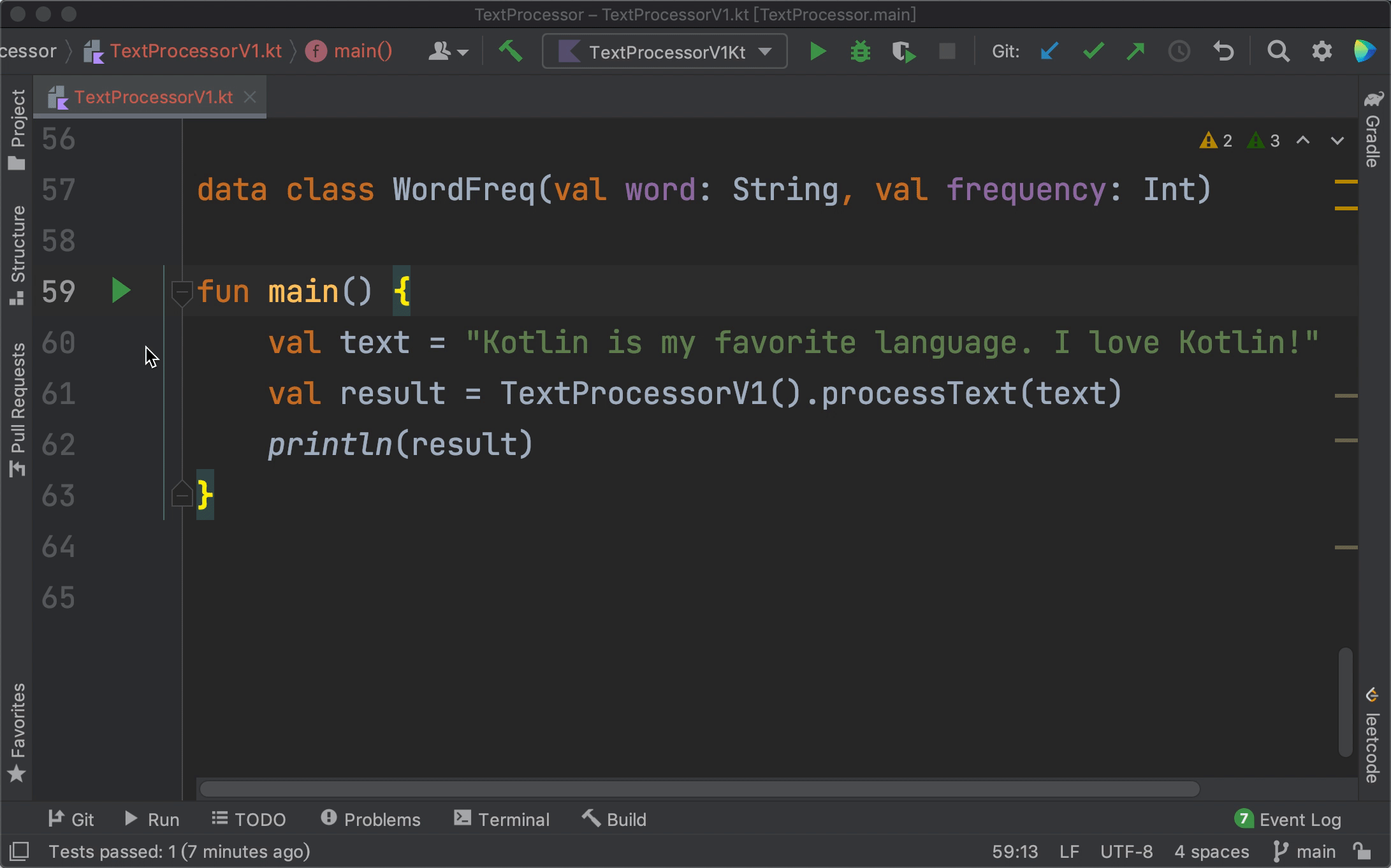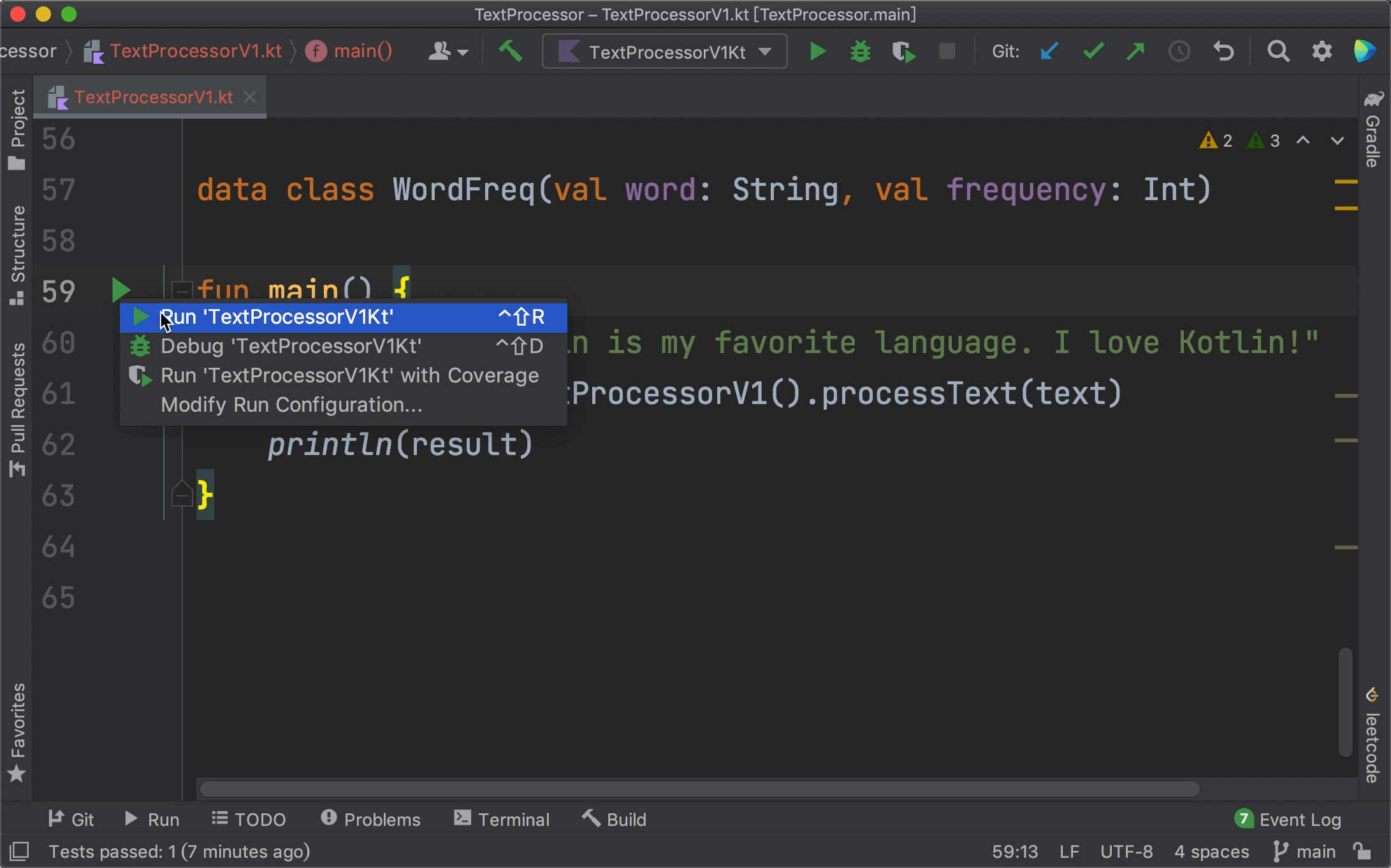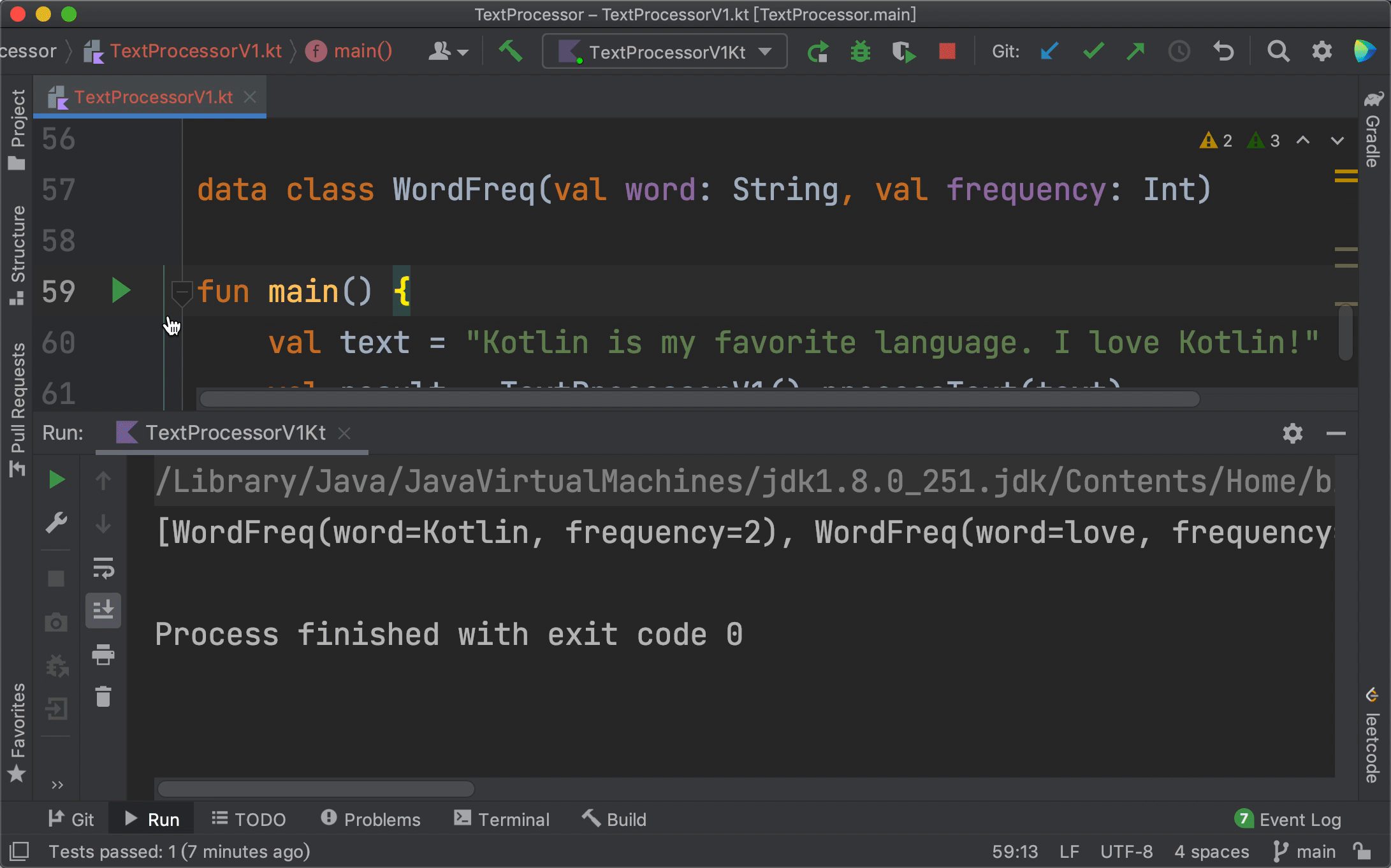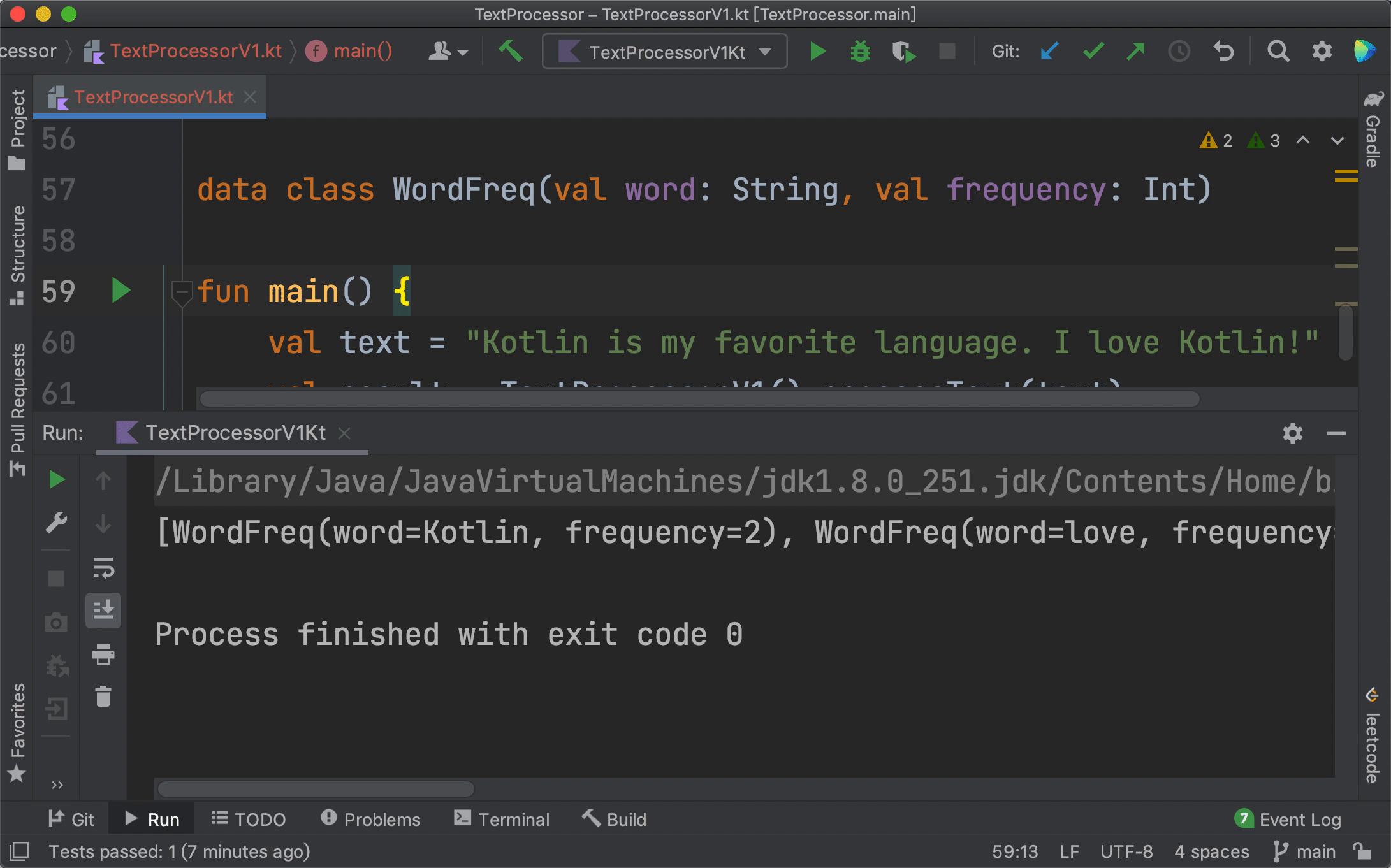
到这里,我们的1.0版本就算是完成了,按照惯例,我们可以写一个单元测试来看看代码运行结果是否符合预期。
由于我们的测试文本很简单,我们一眼就能分析出正确的结果。其中单词“Kotlin”出现的频率最高,是2次,它会排在result的第一位。所以,我们可以通过断言来编写以上的测试代码。最终单元测试的结果,也显示我们的代码运行结果符合预期。
这时候,你也许会想:测试的文本数据太短了,如果数据量再大一些,程序是否还能正常运行呢?
其实,我们可以让程序支持统计文件当中的单词词频,要实现这个功能也非常简单,就是利用我们在第6讲学过的扩展方法:
fun processFile(file: File): List<WordFreq> {
val text = file.readText(Charsets.UTF_8)
return processText(text)
}
从代码中我们可以看到,readText()就是Kotlin标准库里提供的一个扩展函数,它可以让我们非常方便地从文件里读取文本。增加这样一行代码,我们的程序就能够统计文件当中的单词频率了。
好,下面我们就一起来实现下第二个版本的词频统计程序。这里,我想先带你回过头来看看咱们1.0版本当中的代码:
class TextProcessorV1 {
fun processText(text: String): List<WordFreq> {
val cleaned = clean(text)
val words = cleaned.split(" ")
val map = getWordCount(words)
val list = sortByFrequency(map)
return list
}
}
是不是觉得咱们的代码实在太整齐了?甚至整齐得有点怪怪的?而且,我们定义的临时变量cleaned、words、map、list都只会被用到一次。
其实上面的代码,就是很明显地在用Java思维写Kotlin代码。这种情况下,我们甚至可以省略掉中间所有的临时变量,将代码缩减成这样:
fun processText(text: String): List<WordFreq> {
return sortByFrequency(getWordCount(clean(text).split(" ")))
}
不过,很明显的是,以上代码的可读性并不好。在开篇词当中,我曾提到过,Kotlin既有命令式的一面,也有函数式的一面,它们有着各自擅长的领域。而在这里,我们就完全可以借助函数式编程的思想来优化代码,就像下面这样:
fun processText(text: String): List<WordFreq> {
return text
.clean()
.split(" ")
.getWordCount()
.sortByFrequency { WordFreq(it.key, it.value) }
}
可以发现,这段代码从上读到下,可读性非常高,它也非常接近我们说话的习惯:我们拿到参数text,接着对它进行清洗clean(),然后对单词频率进行统计,最后根据词频进行排序。
那么,我们要如何修改1.0版本的代码,才能实现这样的代码风格呢?问题的关键还是在于clean()、getWordCount()、sortByFrequency()这几个方法。
我们一个个来分析。首先是text.clean(),为了让String能够直接调用clean()方法,我们必须将clean()定义成扩展函数:
// 原函数
fun clean(text: String): String {
return text.replace("[^A-Za-z]".toRegex(), " ")
.trim()
}
// 转换成扩展函数
fun String.clean(): String {
return this.replace("[^A-Za-z]".toRegex(), " ")
.trim()
}
从上面的代码中,我们可以清晰地看到普通函数转换为扩展函数之间的差异:

对应的,我们的getWordCount()方法也同样可以修改成扩展函数的形式。
private fun List<String>.getWordCount(): Map<String, Int> {
val map = HashMap<String, Int>()
for (element in this) {
if (element == "") continue
val trim = element.trim()
val count = map.getOrDefault(trim, 0)
map[trim] = count + 1
}
return map
}
你能看到,原本是作为参数的List,现在同样变成了接收者类型,原本的参数list集合变成了this。
最后是sortByFrequency(),我们很容易就能写出类似下面的代码:
private fun Map<String, Int>.sortByFrequency(): MutableList<WordFreq> {
val list = mutableListOf<WordFreq>()
for (entry in this) {
val freq = WordFreq(entry.key, entry.value)
list.add(freq)
}
list.sortByDescending {
it.frequency
}
return list
}
同样的步骤,将参数类型变成“接收者类型”,将参数变成this。不过,这里的做法并不符合函数式编程的习惯,因为这个方法明显包含两个功能:
因此针对这样的情况,我们应该再对这个方法进行拆分:
private fun <T> Map<String, Int>.mapToList(transform: (Map.Entry<String, Int>) -> T): MutableList<T> {
val list = mutableListOf<T>()
for (entry in this) {
val freq = transform(entry)
list.add(freq)
}
return list
}
在上面的代码当中,为了让Map到List的转换更加得灵活,我们引入了高阶函数,它的参数transform是函数类型的参数。那么相应的,我们的调用处代码也需要做出改变,也就是传入一个Lambda表达式:
fun processText(text: String): List<WordFreq> {
return text
.clean()
.split(" ")
.getWordCount()
.mapToList { WordFreq(it.key, it.value) }
.sortedByDescending { it.frequency }
}
看着上面的代码,我们几乎可以像读普通的英语文本一般地阅读上面的代码:首先是对text进行清理;然后使用split以空格形式进行分割;接着计算出单词的频率,然后再将无序的Map转换成List;最后对List进行排序,排序的依据就是词频降序。
至此,我们的2.0版本就算完成了。让我们再次执行一次单元测试,看看我们的代码逻辑是否正确:
单元测试的结果告诉我们,代码运行结果符合预期。接下来,我们就可以进行3.0版本的开发工作了。
在上一个版本当中,我们的mapToList被改造成了一个高阶函数。那到了这个版本,我们实际的代码量其实很少,只需要为mapToList这个高阶函数增加一个inline关键字即可。
// 增加inline关键字
// ↓
private inline fun <T> Map<String, Int>.mapToList(transform: (Map.Entry<String, Int>) -> T): MutableList<T> {
val list = mutableListOf<T>()
for (entry in this) {
val freq = transform(entry)
list.add(freq)
}
return list
}
到这里,我们3.0版本的开发工作其实就完成了。
但是你要清楚,虽然我们只花几秒钟就能增加这个inline关键字,可我们这么做的原因却比较复杂。这涉及到 inline关键字的实现原理。
不过,在正式研究inline之前,我们要先来了解下高阶函数的实现原理。由于Kotlin兼容Java 1.6,因此JVM是不懂什么是高阶函数的,我们的高阶函数最终一定会被编译器转换成JVM能够理解的格式。
而又因为,我们的词频统计代码略微有些复杂,所以为了更好地研究高阶函数的原理,这里我们可以先写一个简单的高阶函数,然后看看它反编译后的代码长什么样。
// HigherOrderExample.kt
fun foo(block: () -> Unit) {
block()
}
fun main() {
var i = 0
foo{
i++
}
}
以上代码经过反编译成Java后,会变成这样:
public final class HigherOrderExampleKt {
public static final void foo(Function0 block) {
block.invoke();
}
public static final void main() {
int i = 0
foo((Function0)(new Function0() {
public final void invoke() {
i++;
}
}));
}
}
可以看到,Kotlin高阶函数当中的函数类型参数,变成了Function0,而main()函数当中的高阶函数调用,也变成了“匿名内部类”的调用方式。那么,Function0又是个什么东西?
public interface Function0<out R> : Function<R> {
public operator fun invoke(): R
}
Function0其实是Kotlin标准库当中定义的接口,它代表没有参数的函数类型。在Functions.kt这个文件当中,Kotlin一共定义了23个类似的接口,从Function0一直到Function22,分别代表了“无参数的函数类型”到“22个参数的函数类型”。
好,现在,我们已经知道Kotlin高阶函数是如何实现的了,接下来我们看看使用inline优化过的高阶函数会是什么样的:
// HigherOrderInlineExample.kt
/*
多了一个关键字
↓ */
inline fun fooInline(block: () -> Unit) {
block()
}
fun main() {
var i = 0
fooInline{
i++
}
}
和前面的例子唯一的不同点在于,我们在foo()函数的定义处增加了一个inline关键字,同时,为了区分,我们也改了一下函数的名称。这个时候,我们再来看看它反编译后的Java长什么样:
public final class HigherOrderInlineExampleKt {
// 没有变化
public static final void fooInline(Function0 block) {
block.invoke();
}
public static final void main() {
// 差别在这里
int i = 0;
int i = i + 1;
}
}
为了看得更加清晰,我们将有无inline的main()放到一起来对比下:

所以你能发现,inline的作用其实就是将inline函数当中的代码拷贝到调用处。
而是否使用inline,main()函数会有以下两个区别:
为了验证这一猜测,我们可以使用JMH(Java Microbenchmark Harness)对这两组代码进行性能测试。JMH这个框架可以最大程度地排除外界因素的干扰(比如内存抖动、虚拟机预热),从而判断出我们这两组代码执行效率的差异。它的结果不一定非常精确,但足以说明一些问题。
不过,为了不偏离本节课的主题,在这里我们不去深究JMH的使用技巧,而是只以两组测试代码为例,来探究下inline到底能为我们带来多少性能上的提升:
// 不用inline的高阶函数
fun foo(block: () -> Unit) {
block()
}
// 使用inline的高阶函数
inline fun fooInline(block: () -> Unit) {
block()
}
// 测试无inline的代码
@Benchmark
fun testNonInlined() {
var i = 0
foo {
i++
}
}
// 测试无inline的代码
@Benchmark
fun testInlined() {
var i = 0
fooInline {
i++
}
}
最终的测试结果如下,分数越高性能越好:
Benchmark Mode Score Error Units
testInlined thrpt 3272062.466 ± 67403.033 ops/ms
testNonInlined thrpt 355450.945 ± 12647.220 ops/ms
从上面的测试结果我们能看出来,是否使用inline,它们之间的效率几乎相差10倍。而这还仅仅只是最简单的情况,如果在一些复杂的代码场景下,多个高阶函数嵌套执行,它们之间的执行效率会相差上百倍。
为了模拟复杂的代码结构,我们可以简单地将这两个函数分别嵌套10个层级,然后看看它们之间的性能差异:
// 模拟复杂的代码结构,这是错误示范,请不要在其他地方写这样的代码。
@Benchmark
fun testNonInlined() {
var i = 0
foo {
foo {
foo {
foo {
foo {
foo {
foo {
foo {
foo {
foo {
i++
}
}
}
}
}
}
}
}
}
}
}
@Benchmark
fun testInlined() {
var i = 0
fooInline {
fooInline {
fooInline {
fooInline {
fooInline {
fooInline {
fooInline {
fooInline {
fooInline {
fooInline {
i++
}
}
}
}
}
}
}
}
}
}
}
注意:以上的代码仅仅只是为了做测试,请不要在其他地方写类似这样的代码。
Benchmark Mode Score Error Units
testInlined thrpt 3266143.092 ± 85861.453 ops/ms
testNonInlined thrpt 31404.262 ± 804.615 ops/ms
从上面的性能测试数据我们可以看到,在嵌套了10个层级以后,我们testInlined的性能几乎没有什么变化;而当testNonInlined嵌套了10层以后,性能也比1层嵌套差了10倍。
在这种情况下,testInlined()与testNonInlined()之间的性能差异就达到了100倍,那么随着代码复杂度的进一步上升,它们之间的性能差异会更大。
我在下面这张Gif动图里展示了它们反编译成Java的代码:
我们能看到,对于testNonInlined(),由于foo()嵌套了10层,它反编译后的代码也嵌套了10层函数调用,中间还伴随了10次匿名内部类的创建。而testInlined()则只有简单的两行代码,完全没有任何嵌套的痕迹。难怪它们之间的性能相差100倍!
看到这,你也许会有这样的想法:既然inline这么神奇,那我们是不是可以将“词频统计程序”里的所有函数都用inline来修饰?
答案当然是否定的。事实上,Kotlin官方只建议我们将inline用于修饰高阶函数。对于普通的Kotlin函数,如果我们用inline去修饰它,IntelliJ会对我们发出警告。而且,也不是所有高阶函数都可以用inline,它在使用上有一些局限性。
举个例子,如果我们在processText()的前面增加inline关键字,IntelliJ会提示一个警告:
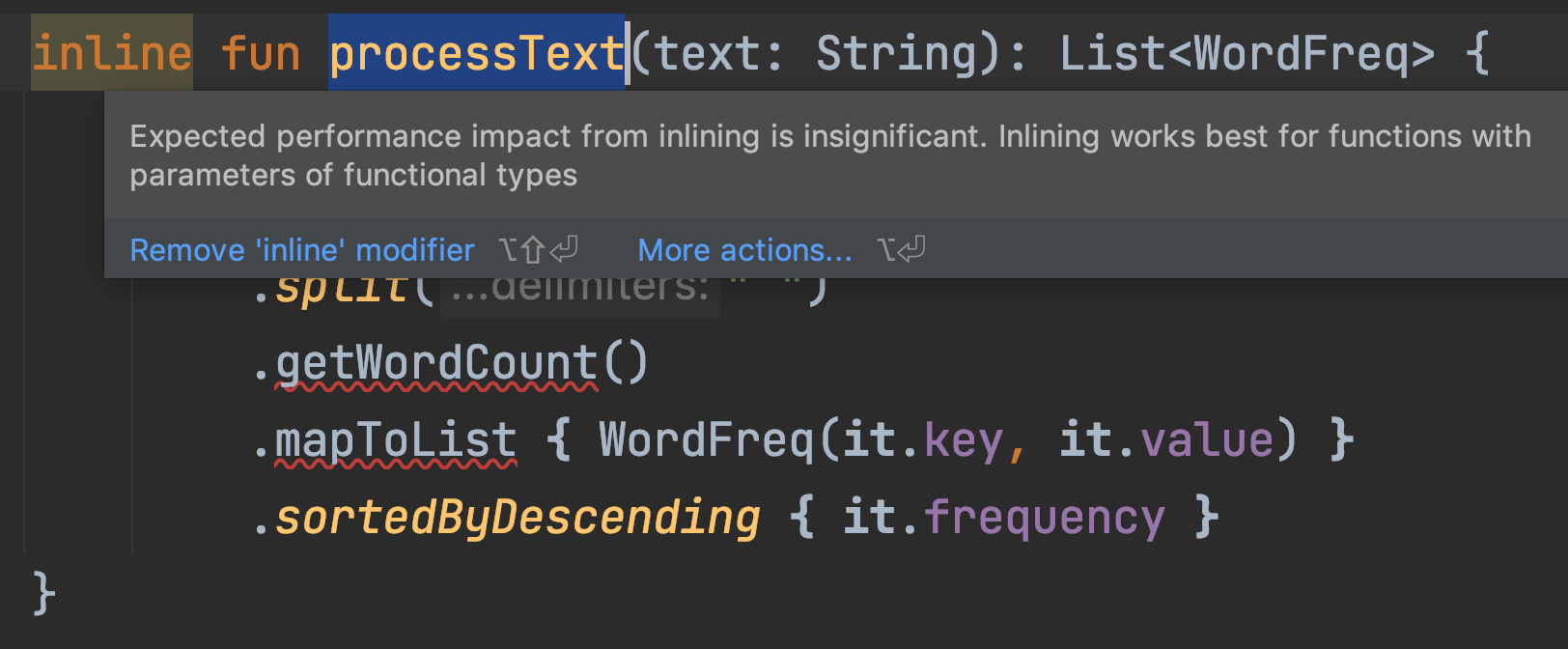
这个警告的意思是:“对于普通的函数,inline带来的性能提升并不显著,inline用在高阶函数上的时候,才会有显著的性能提升”。
另外,在processText()方法的内部,getWordCount()和mapToList()这两个方法还会报错:
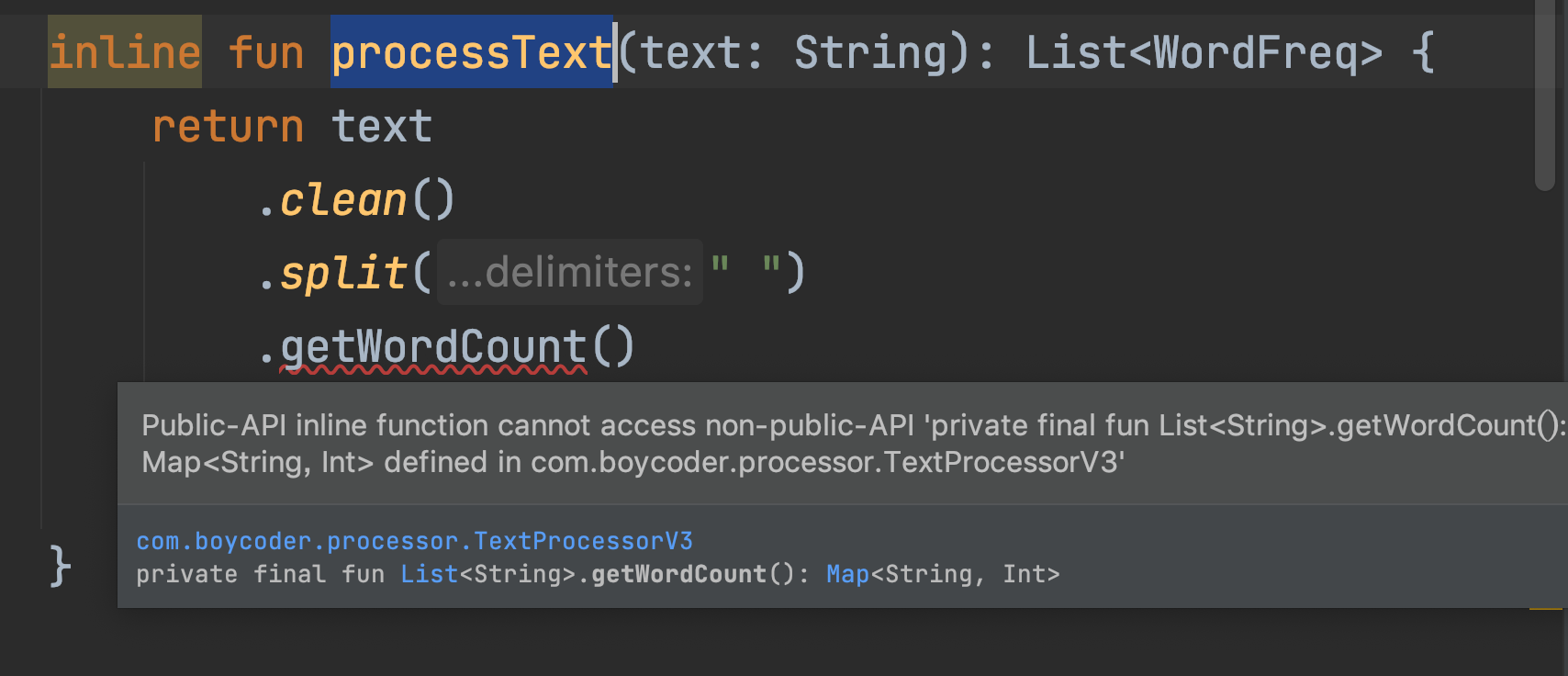
出现这个报错的原因是:getWordCount()和mapToList()这两个函数是私有的,无法inline。为什么呢?
前面我们提到过:inline的作用其实就是将inline函数当中的代码拷贝到调用处。由于processText()是公开的,因此它会从外部被调用,这意味着它的代码会被拷贝到外部去执行,而getWordCount()和mapToList()这两个函数却无法在外部被访问。这就是导致编译器报错的原因。
所以,inline虽然可以为我们带来极大的性能提升,但我们不能滥用。在使用inline的时候,我们还需要时刻注意它的实现机制,有时候,稍有不慎就会引发问题。
除此之外,在第3讲中我们曾提到:Kotlin编译器一直在幕后帮忙做着翻译的好事,那它有没有可能“好心办坏事”?
这个问题,现在我们就能够回答了:Kotlin编译器是有可能好心办坏事的。如果我们不够了解Kotlin的底层细节,不够了解Kotlin的语法实现原理,我们就可能会用错某些Kotlin语法,比如inline,当我们用错这些语法后,Kotlin在背后做的这些好事,就可能变成一件坏事。
最后,让我们来做个简单的总结。
经过这节课的实战演练之后,相信你一定感受到了Kotlin函数式风格的魅力。在日后不断地学习、实操中,我也希望,你可以把Kotlin函数式的代码应用到自己的开发工作当中,并且充分发挥出Kotlin简洁、优雅、可读性强的优势。
咱们的词频统计程序其实还有很多可以优化和提升的地方,请问你能想到哪些改进之处?欢迎你在评论区分享你的思路,我们下节课再见。
评论