你好,我是朱涛。
学完基础篇以后,相信现在你对Kotlin的基础语法和特性都有了全面的认识。那么从今天开始,我们就要进入一个新的模块,一起来学习Kotlin当中最重要、最难学,也是最受期待的特性——协程。
协程是Kotlin对比Java的最大优势,这也是我说协程是Kotlin中最重要特性的主要原因。虽说Java也在计划着实现自己的协程:Loom,不过这个毕竟还处于相当初级的阶段。而Kotlin的协程,可以帮我们极大地简化异步、并发编程、优化软件架构。通过协程,我们不仅可以提高开发效率,还能提高代码的可读性,由此也就可以降低代码出错的概率。
不过,遗憾的是,Kotlin协程在业界的普及率并不高。因为,你如果对协程没有足够的认识,贸然在生产环境里使用协程,一定会遇到各种各样的问题,并要为之付出昂贵的代价(典型的反面例子就是滥用GlobalScope,导致大量的计算资源浪费以及出现生命周期错乱的问题)。
Kotlin的协程就是这样,表面上看,它的语法很简单,但行为模式却让人难以捉摸。举个简单的例子,同样是5行代码,普通的程序,这5行代码的运行顺序一般会是1、2、3、4、5;但对于协程来说,代码执行顺序可能会是1、4、5、3、2这样错乱的。如果我们不能在脑子里建立协程的思维模型,那我们将很难理解协程的行为模式。
所以说,协程也是一个典型的“易学难精”的框架。
如果你之前尝试过自学Kotlin协程,你一定会跟我有相似的体会:要记住协程的几个API很容易,困难的是形成一套完整的协程知识体系。不过,我想告诉你的是:形成知识体系也不算什么,更难的是建立一个具体的协程思维模型,来辅助自己理解协程背后的运行机制;甚至,建立协程思维模型也没什么了不起,更难的是理解协程背后的设计理念。
换句话说,如果我们能站在Kotlin协程设计者的角度,去评判、欣赏它背后的设计理念,并且能体会到协程设计的精妙之处,那才算是达到了最高的境界。
那么,学习Kotlin协程,到底意味着什么呢?
其实,学习协程,相当于一次编程思维的升级。协程思维,它与我们常见的线程思维迥然不同,当我们能够用协程的思维来分析问题以后,线程当中某些棘手的问题在协程面前都会变成小菜一碟。因此,我们相当于多了一种解决问题的手段。
另外,学习Kotlin协程,也相当于为我们打开了一扇新世界的大门,当我们对Kotlin协程有了透彻的认识以后,再去看C#、Python、Dart、JS、Golang、Rust、C++20、Java Loom当中的“类协程”概念,就会觉得无比亲切。这时候我们就会发现:原来协程的世界是如此广阔。
到这里,相信你已经认识到了Kotlin协程的重要性,也知道了学习协程的好处了。
不过,在正式开始学习Kotlin协程之前,我想先给你打一剂“预防针”:这个部分的学习难度会比前面基础篇更大,虽然我还是会尽量用简单直白的方式来向你介绍协程,但由于它本身是一种颠覆性的技术,因此,刚开始肯定是会有些难以接受的。在这里,我也建议你在遇到问题的时候多思考,并去反复琢磨和理解课程当中的知识点与示例代码。
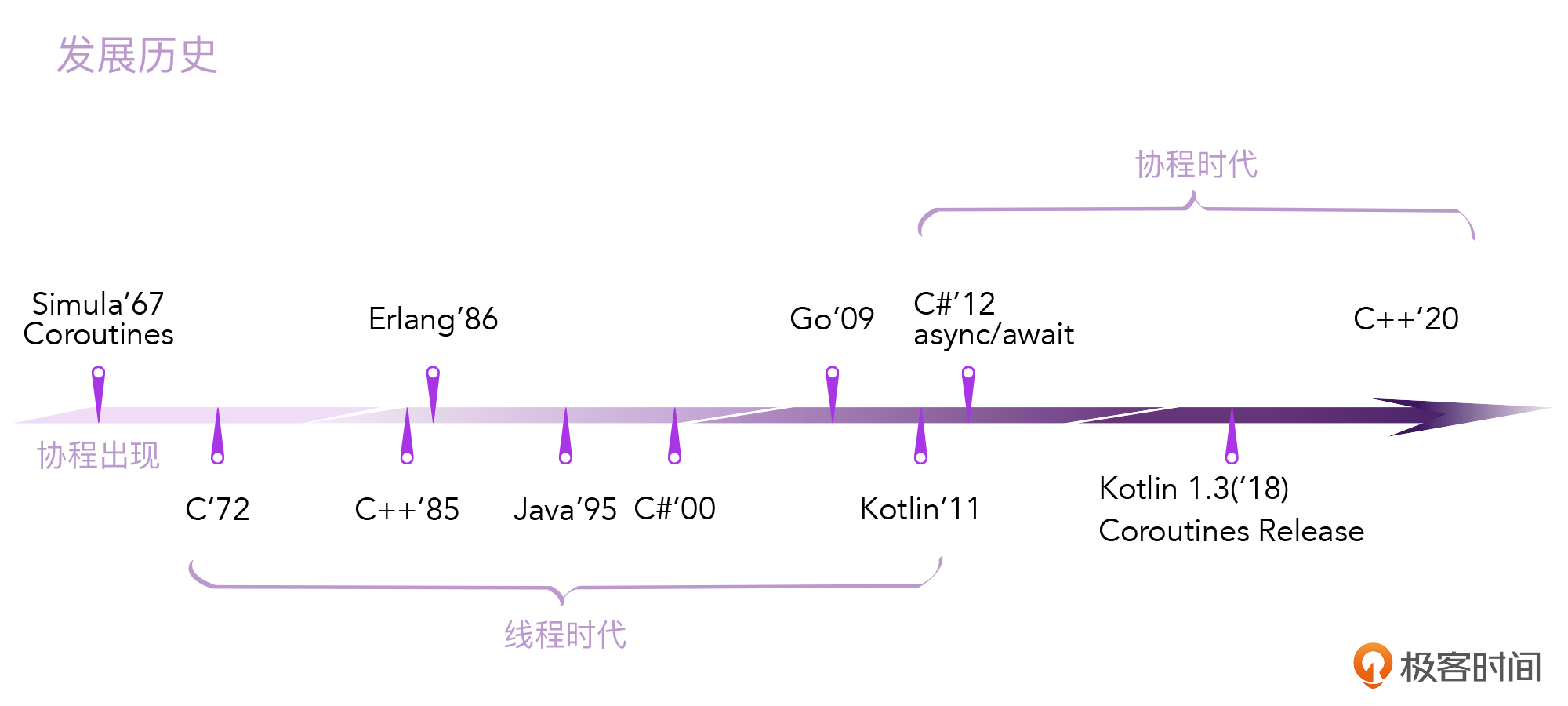
好,接下来,我们先来了解一下协程的发展史,这会有助于我们理解协程到底是个什么东西。
Kotlin的协程,是2017年初在1.1版本加入进来的,那时协程还只是实验性的(Experimental);等到2018年底,Kotlin更新到1.3版本的时候,协程才成为Kotlin的正式特性;接着又过了一年,到2019年Kotlin协程才推出Flow相关的API。我们常说Kotlin是一门年轻的语言,那么Kotlin协程这个特性,就更加显得年轻了。毕竟从它正式推出到现在,也才三年多。
虽然Kotlin协程很年轻,但“协程”这个概念本身并不年轻。早在1967年的 Simula语言当中,就已经出现了协程。不过,在之后的几十年里,协程并没有被推广开,后续涌现出的C、C++、Java之类的语言,更多的是使用线程来进行异步和并发。直到2012年左右,C#重新拾起了协程这个特性,实现了async、await、yield。之后,JavaScript、Python、Kotlin等语言才继续跟进实现了对应的协程。
很多人在刚开始接触协程的时候,都觉得协程很难学,因为从学校一路学习C、Java过来以后,我们只知道线程是什么,对协程根本没有任何概念。
其实,如果要用简单的语言来描述协程的话,我们可以将其称为:“互相协作的程序”。

为了帮你弄清楚普通的程序(Routine)与协程(Coroutine)之间的差异,我们来看一个具体的例子。
fun main() {
val list = getList()
printList(list)
}
fun getList(): List<Int> {
val list = mutableListOf<Int>()
println("Add 1")
list.add(1)
println("Add 2")
list.add(2)
println("Add 3")
list.add(3)
println("Add 4")
list.add(4)
return list
}
fun printList(list: List<Int>) {
val i = list[0]
println("Get$i")
val j = list[1]
println("Get$j")
val k = list[2]
println("Get$k")
val m = list[3]
println("Get$m")
}
/* 运行结果:
Add 1
Add 2
Add 3
Add 4
Get1
Get2
Get3
Get4
*/
以上代码非常简单,程序会先运行getList(),然后再运行printList()。从运行的结果我们可以看出来,程序是按照顺序执行的,这没什么特别的。这就是一个典型的普通程序的例子。
下面让我们来看一个协程的例子。
// 看不懂代码没关系,目前咱们只需要关心代码的执行结果
fun main() = runBlocking {
val sequence = getSequence()
printSequence(sequence)
}
fun getSequence() = sequence {
println("Add 1")
yield(1)
println("Add 2")
yield(2)
println("Add 3")
yield(3)
println("Add 4")
yield(4)
}
fun printSequence(sequence: Sequence<Int>) {
val iterator = sequence.iterator()
val i = iterator.next()
println("Get$i")
val j = iterator.next()
println("Get$j")
val k = iterator.next()
println("Get$k")
val m = iterator.next()
println("Get$m")
}
/*
输出结果:
Add 1
Get1
Add 2
Get2
Add 3
Get3
Add 4
Get4
*/
这段代码做的事情和前面的代码其实差不多,只是我们是借助了Kotlin当中的Sequence来实现的。这次,我们从程序的运行结果会发现,getSequence()与printSequence()这两个函数,它们是交替执行的。为了方便你理解,我用一张图来描述它们之间的调用顺序。
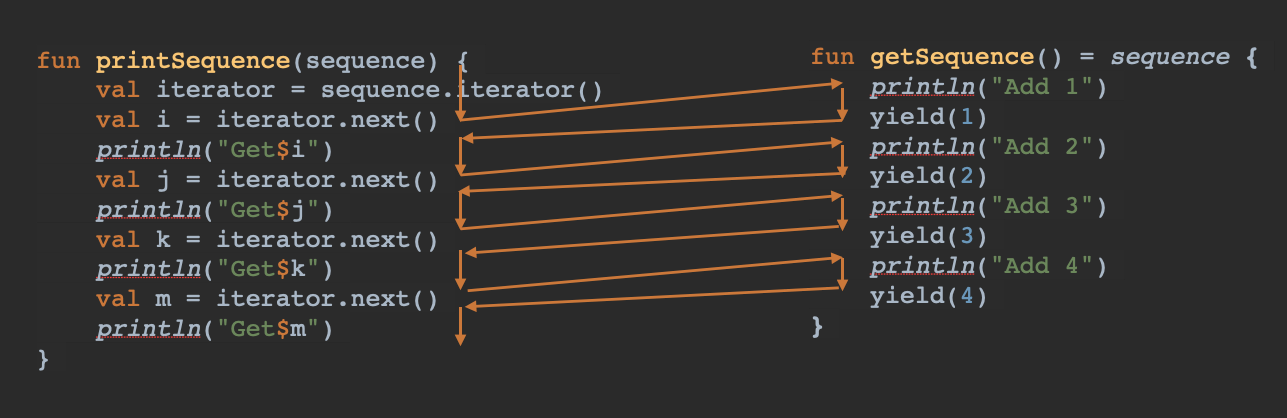
这段程序,给人的感觉就像是两位彬彬有礼的绅士,每个人执行一会代码以后,就会让出执行权给对方,让对方执行一会。这样的运行模式,就好像两个人在协作一样。
而对应的,前面的getList()和printList()的执行流程则完全不一样,getList()执行完以后,才会轮到printList()来执行。
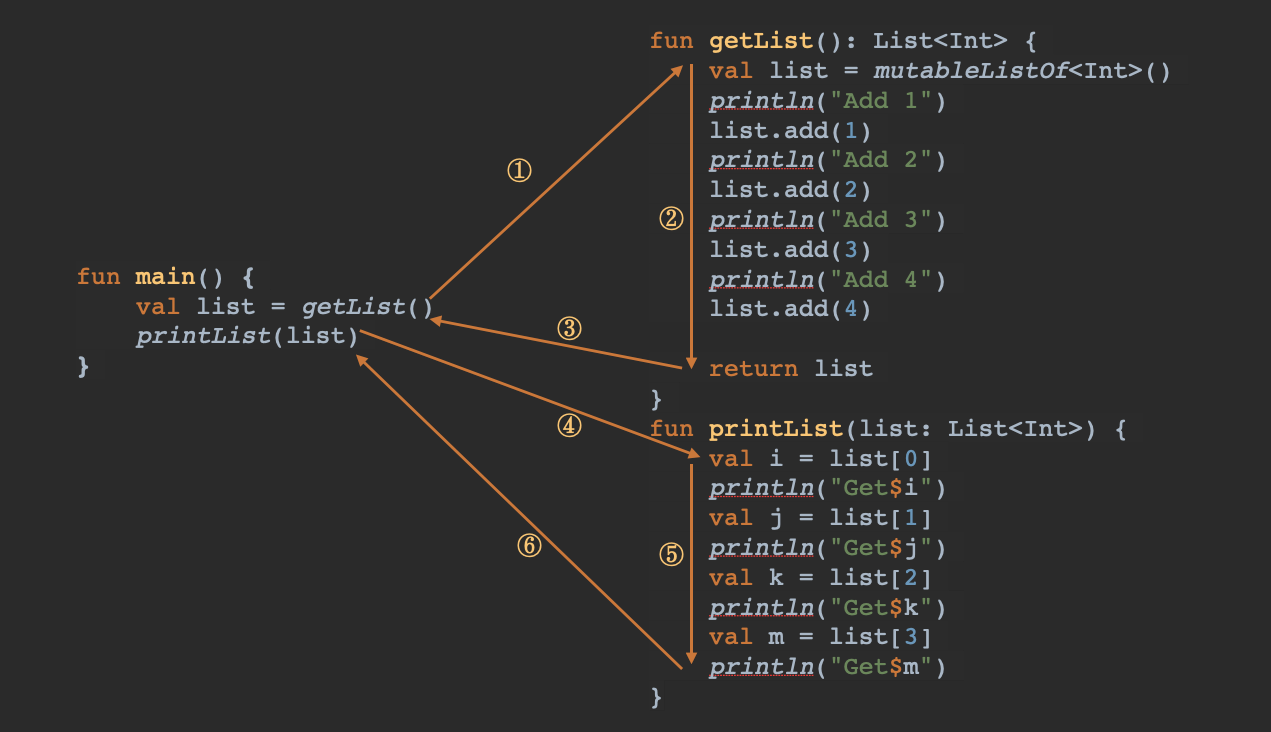
这两种迥然不同的代码运行方式,其实就是协程与普通程序之间最大的差异。
除了yield以外,我们也可以借助Kotlin协程当中的Channel来实现类似的代码模式:
// 看不懂代码没关系,目前咱们只需要关心代码的执行结果
fun main() = runBlocking {
val channel = getProducer(this)
testConsumer(channel)
}
fun getProducer(scope: CoroutineScope) = scope.produce {
println("Send:1")
send(1)
println("Send:2")
send(2)
println("Send:3")
send(3)
println("Send:4")
send(4)
}
suspend fun testConsumer(channel: ReceiveChannel<Int>) {
delay(100)
val i = channel.receive()
println("Receive$i")
delay(100)
val j = channel.receive()
println("Receive$j")
delay(100)
val k = channel.receive()
println("Receive$k")
delay(100)
val m = channel.receive()
println("Receive$m")
}
/*
输出结果:
Send:1
Receive1
Send:2
Receive2
Send:3
Receive3
Send:4
Receive4
*/
可见,以上代码中的getProducer()和testConsumer()之间,它们也是交替执行的。
所以,从广义上来讲,协程就代表了“互相协作的程序”。这样的标准,几乎适用于所有语言的协程。不管是Python的协程还是C#的协程,还是其他语言的协程,它们都是以这样的模式来实现的。而且,很多语言的协程都支持yield。理解了这一点以后,将来不管你是遇到Python的协程,还是其他语言的协程也好,相信你也可以很快地把Kotlin协程当中的概念迁移过去。
聊完广义的协程以后,我们再来看看Kotlin协程的另外两个概念:协程、协程框架。注意,这是两个不一样的概念,前者是代表了程序当中被创建的协程;后者,则是一个整体的框架。
在Kotlin当中,协程是一个独立的框架。跟Kotlin的反射库类似,协程并不是直接集成在标准库当中的。如果我们想要使用Kotlin的协程,就必须手动进行依赖:
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.0'
Kotlin官方之所以将协程作为一个单独的框架独立出来,也是为了减小标准库的体积,给开发者更多的灵活性。另外,Kotlin协程框架也是开源的,我们可以去GitHub上去浏览它的源代码。在这里,我们可以找到许多前沿的信息,也可以跟世界顶级的开发者交流。
业界一直有一种说法:Kotlin协程其实就是一个封装的线程框架。如果我们站在框架的层面来看的话,这种说法也有一定道理:协程框架将线程池进一步封装,对开发者暴露出统一的协程API。
不过,这种说法无法解释另一个语境下的问题,让我们来看一个代码例子。
// 代码中一共启动了两个线程
fun main() {
println(Thread.currentThread().name)
thread {
println(Thread.currentThread().name)
Thread.sleep(100)
}
Thread.sleep(1000L)
}
/*
输出结果:
main
Thread-0
*/
上面这段代码的逻辑很简单,就是在main函数当中启动了一个新的线程。“代码中一共启动了两个线程”,这句话的意思也很容易理解:main()函数本身会启动一个主线程main,然后在 thread{} 当中,又启动了一个新的线程“Thread-0”。所以,以上代码一共会启动两个线程。这没什么问题,关键是下一个例子:
// 代码中一共启动了两个协程
fun main() = runBlocking {
println(Thread.currentThread().name)
launch {
println(Thread.currentThread().name)
delay(100L)
}
Thread.sleep(1000L)
}
/*
输出结果:
main @coroutine#1
main @coroutine#2
这里要配置特殊的VM参数:-Dkotlinx.coroutines.debug
这样一来,Thread.currentThread().name就能会包含:协程的名字@coroutine#1
*/
在这段代码的注释当中,有这样一句话:代码中一共启动了两个协程。请问,这个语境下的“两个协程”,到底是什么?通过程序的输出结果,我们可以看到,main函数当中出现了两个协程,一个是“coroutine#1”,一个是“coroutine#2”。
那么,这里的“协程”,到底是什么呢?它看起来好像跟Java的线程有点类似,但又好像是两个完全不一样的东西。这其实就是很多初学者会困扰的地方。
Kotlin的协程,它要比线程更加抽象,因为Java的线程,我们起码可以找到Thread的源代码,同时,线程也是操作系统当中的一个概念,所以理解起来并不困难。而Kotlin的协程则没有类似的知识点可以建立关联。所以,我自己在学习Kotlin协程的时候,做法就是建立起协程的思维模型(Mental Model)。
很多人可能不太理解思维模型到底是什么,它在有些语境下,也被称为心智模型。人为了理解真实世界的运作规律,会自然而然地在脑子里建立起对应的模型。举个例子,我们为了理解公司内部的组织架构,经常会在脑子里建立一个类似这样的树状思维模型:
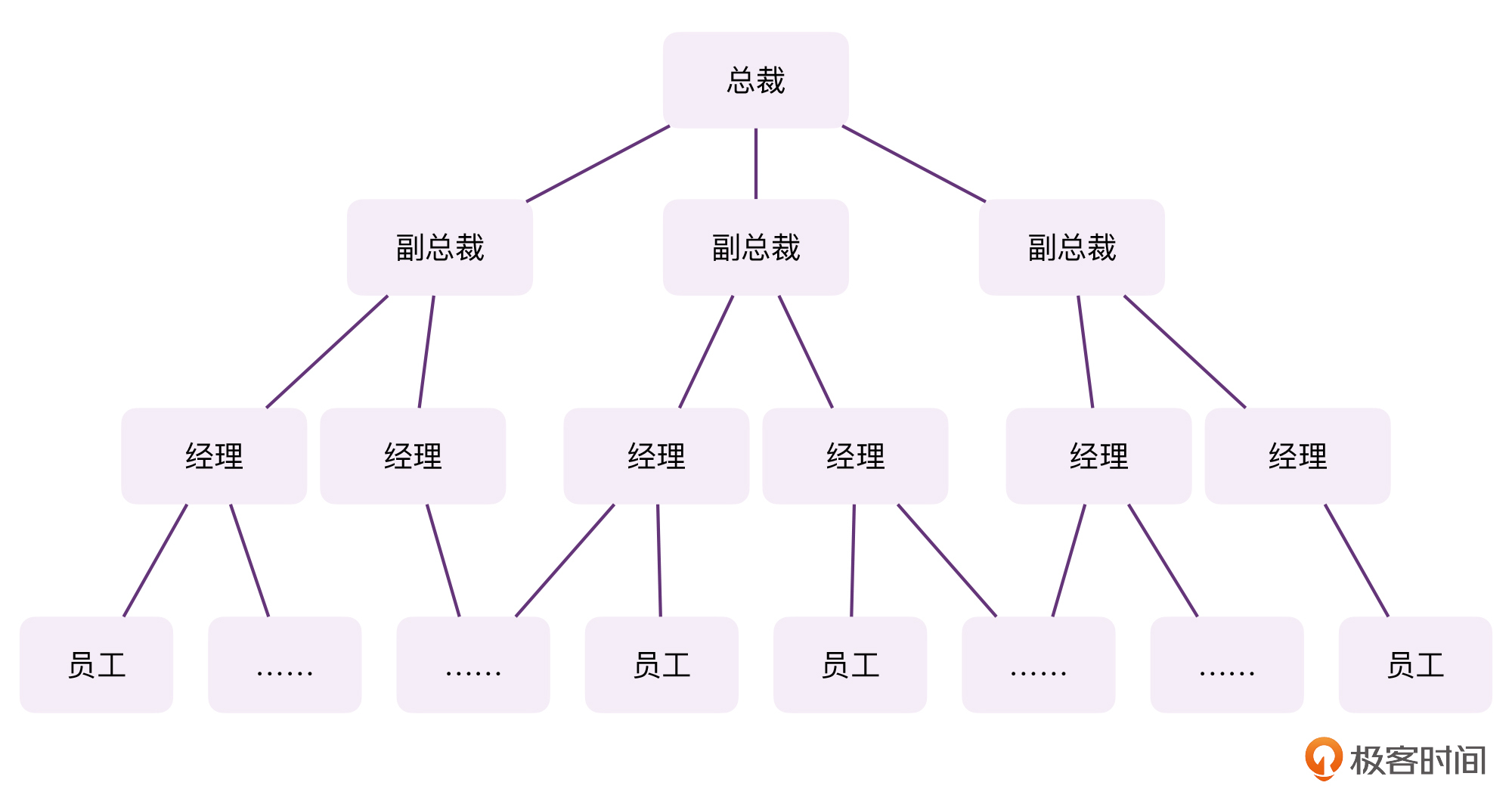
那么,我们该如何为Kotlin的协程建立思维模型呢?其实,Kotlin的协程,我们可以将其想象成一个“更加轻量的线程”。
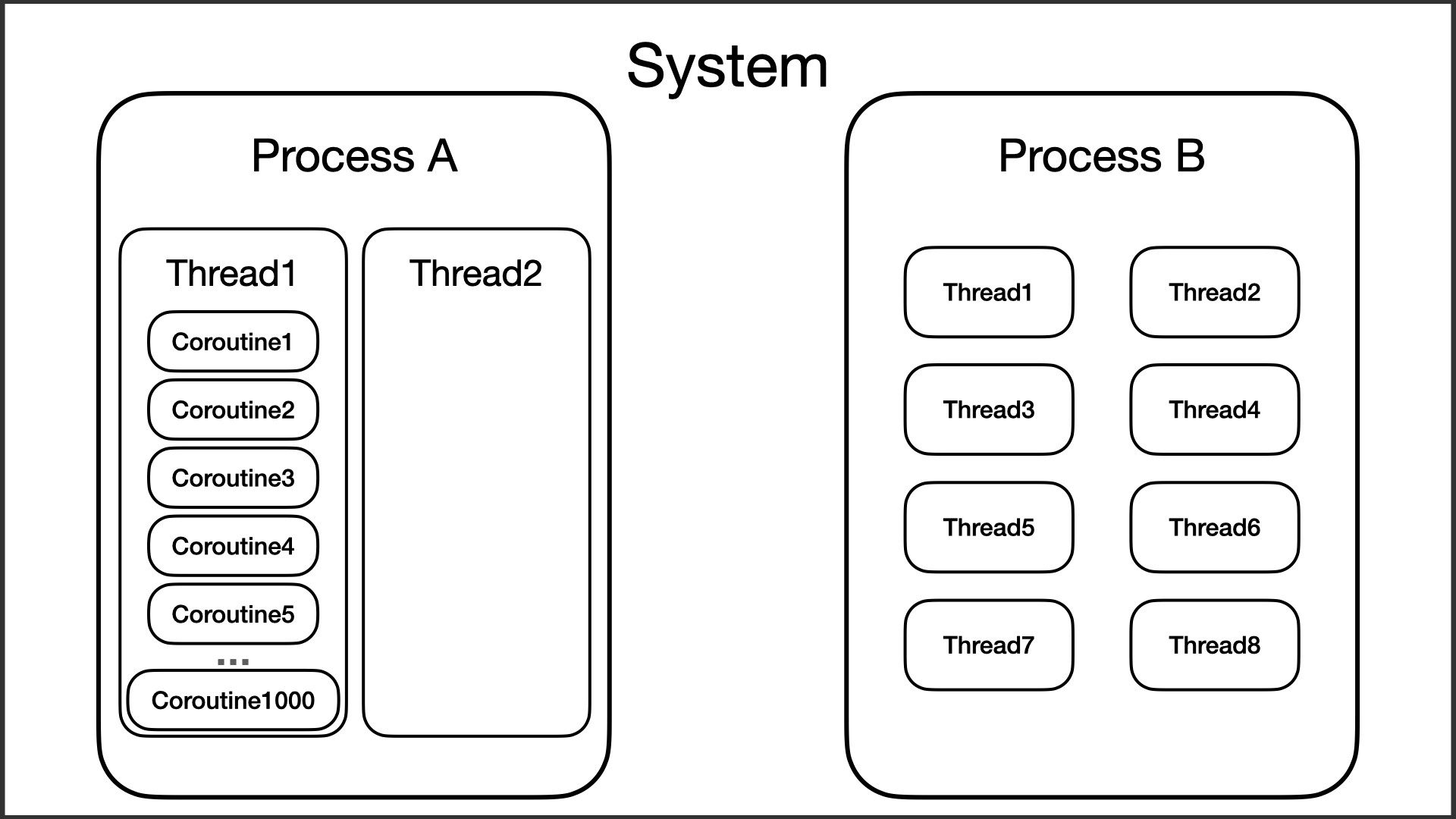
从包含关系上看,协程跟线程的关系,有点像线程与进程的关系,毕竟协程不可能脱离线程运行。所以,协程可以理解为运行在线程当中的、更加轻量的Task。
那么,协程的轻量,到底意味着什么呢?我们可以先来看一段这样的代码:
// 仅用作研究,工作中别这么写
fun main() {
repeat(1000_000_000) {
thread {
Thread.sleep(1000000)
}
}
Thread.sleep(10000L)
}
/*
输出结果:
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at kotlin.concurrent.ThreadsKt.thread(Thread.kt:42)
at kotlin.concurrent.ThreadsKt.thread$default(Thread.kt:20)
*/
在上面的代码中,我们尝试启动10亿个线程,这样的代码运行在大部分的机器上都是会因为内存不足等原因而异常退出的。而如果我们将代码改用协程来实现的话,结果会怎样呢?
// 仅用作研究,工作中别这么写
fun main() = runBlocking {
repeat(1000_000_000) {
launch {
delay(1000000)
}
}
delay(10000L)
}
/*
运行结果:
正常
*/
在这段代码中,我们启动了10亿个协程。由于协程是非常轻量的,所以代码不会因为内存不足而异常退出。
注意:虽然协程非常轻量,但在工作当中,我们也应该尽量避免写出类似上面这样的代码。
另外,协程虽然运行在线程之上,但协程并不会和某个线程绑定,在某些情况下,协程是可以在不同的线程之间切换的。我们可以来看看下面的代码:
fun main() = runBlocking(Dispatchers.IO) {
repeat(3) {
launch {
repeat(3) {
println(Thread.currentThread().name)
delay(100)
}
}
}
delay(5000L)
}
/*
输出结果:
DefaultDispatcher-worker-3 @coroutine#2
DefaultDispatcher-worker-2 @coroutine#3
DefaultDispatcher-worker-4 @coroutine#4
DefaultDispatcher-worker-1 @coroutine#2 // 线程切换了
DefaultDispatcher-worker-4 @coroutine#4
DefaultDispatcher-worker-2 @coroutine#3
DefaultDispatcher-worker-2 @coroutine#2 // 线程切换了
DefaultDispatcher-worker-1 @coroutine#4
DefaultDispatcher-worker-4 @coroutine#3
*/
以上代码的运行结果是随机的,这里以我运行的结果来分析的话,可以看到,“coroutine#2”的三次执行,每一次都在不同的线程上。第一次,它在“worker-3”执行,第二次在“worker-1”执行,第三次在“worker-2”执行。
这时候,我们就可以进一步更新脑海中的思维模型了。
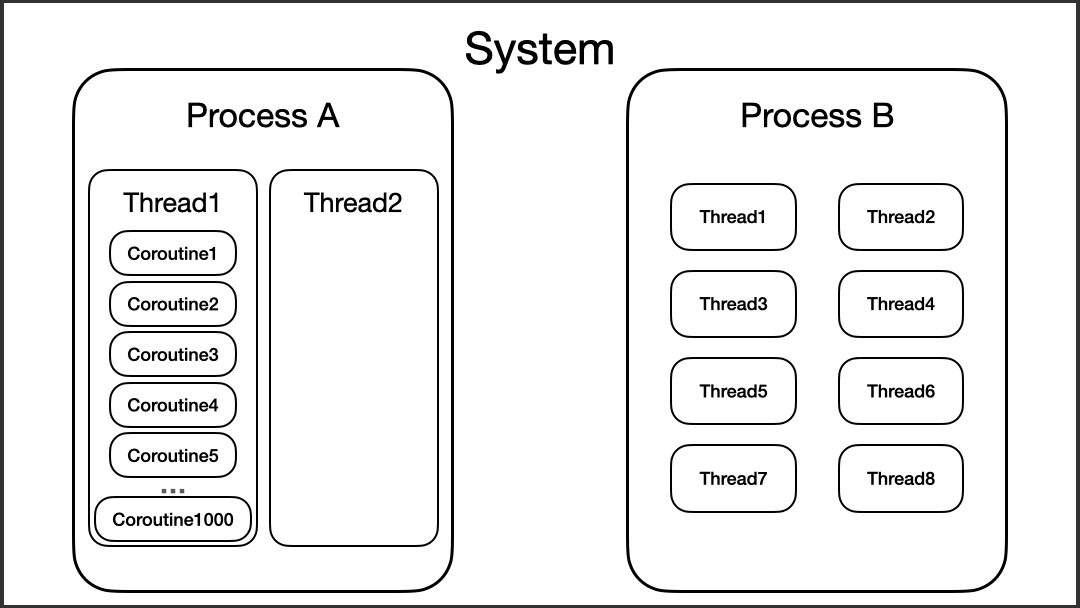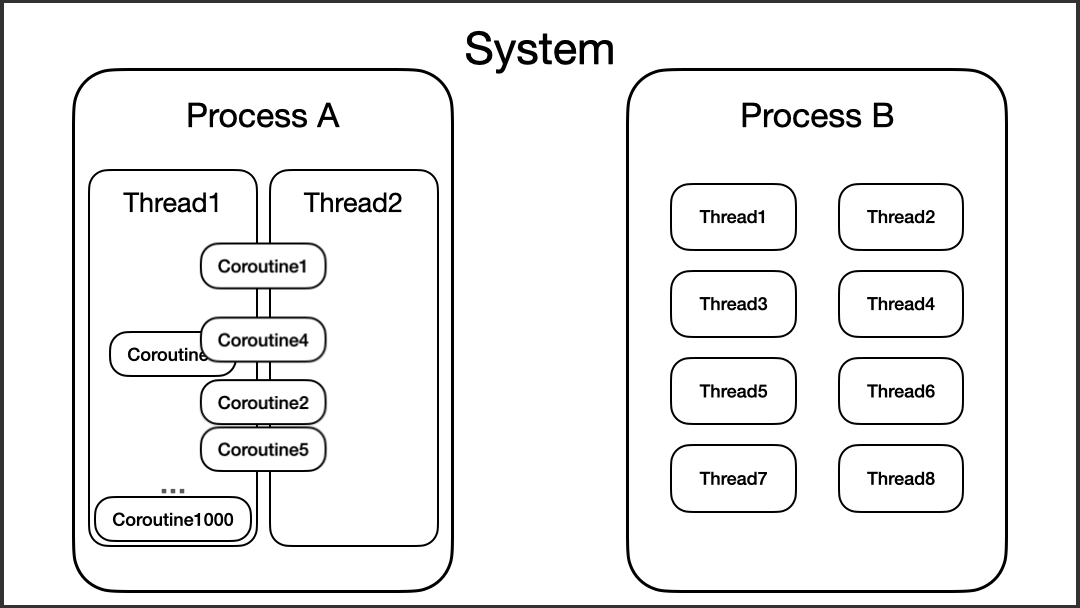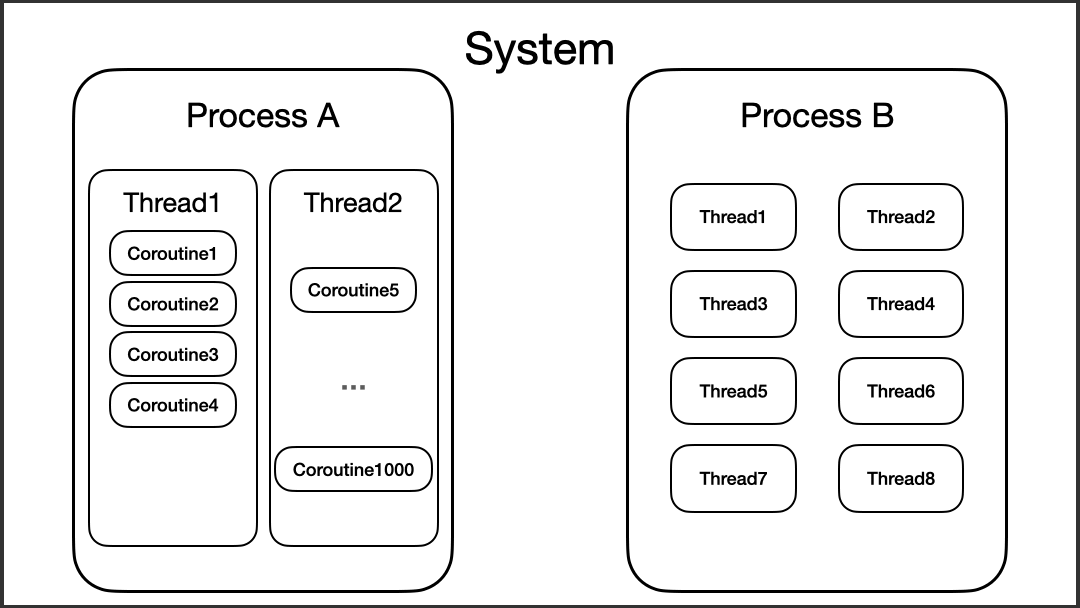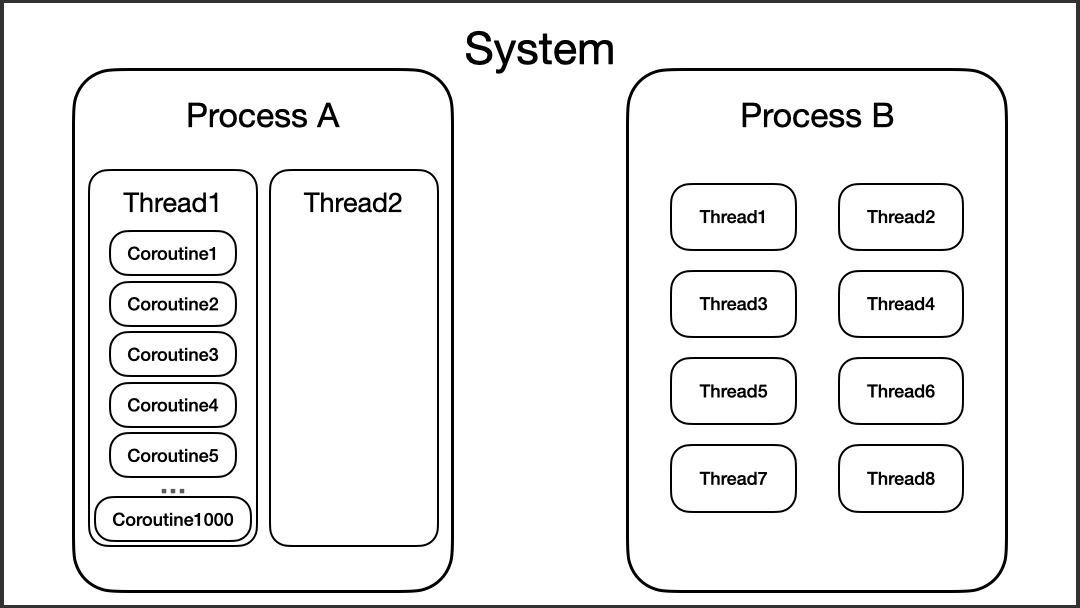
让我们来做个小结:
另外,协程对比线程还有一个特点,那就是非阻塞(Non Blocking),而线程则往往是阻塞式的。这个概念有点抽象,我们来看个具体的例子:
fun main() {
repeat(3) {
Thread.sleep(1000L)
println("Print-1:${Thread.currentThread().name}")
}
repeat(3) {
Thread.sleep(900L)
println("Print-2:${Thread.currentThread().name}")
}
}
/*
输出结果:
Print-1:main
Print-1:main
Print-1:main
Print-2:main
Print-2:main
Print-2:main
*/
在上面的代码里有两个repeat,第一个repeat当中,我们每次调用sleep()方法,让线程休眠1秒钟,而第二个repeat当中,我们每次只休眠0.9秒。由于线程的sleep()方法是阻塞式的,所以程序的执行流程是线性的。也就是说,“Print-1”会连续输出三次,然后“Print-2”会连续输出三次。即使Print-2休眠的时间更短。
让我们来看看协程代码的表现有哪些不一样:
fun main() = runBlocking {
launch {
repeat(3) {
delay(1000L)
println("Print-1:${Thread.currentThread().name}")
}
}
launch {
repeat(3) {
delay(900L)
println("Print-2:${Thread.currentThread().name}")
}
}
delay(3000L)
}
/*
输出结果:
Print-2:main @coroutine#3
Print-1:main @coroutine#2
Print-2:main @coroutine#3
Print-1:main @coroutine#2
Print-2:main @coroutine#3
Print-1:main @coroutine#2
*/
在上面的代码中,我们用协程实现了类似的逻辑,但这次的执行结果却完全不一样。可以看到,Print-2和Print-1是交替输出的,“coroutine#2”、“coroutine#3”这两个协程是并行的(Concurrent)。同时,由于协程的delay()方法是非阻塞的,所以,即使Print-1会先执行delay(1000L),但它也并不会阻塞Print-2的delay(900L)的运行。
而如果我们将代码中的delay修改成sleep,程序的运行结果就会不一样。
fun main() = runBlocking {
launch {
repeat(3) {
Thread.sleep(1000L)
println("Print-1:${Thread.currentThread().name}")
}
}
launch {
repeat(3) {
Thread.sleep(900L)
println("Print-2:${Thread.currentThread().name}")
}
}
delay(3000L)
}
/*
输出结果:
Print-1:main @coroutine#2
Print-1:main @coroutine#2
Print-1:main @coroutine#2
Print-2:main @coroutine#3
Print-2:main @coroutine#3
Print-2:main @coroutine#3
*/
由此可见,Kotlin协程的“非阻塞”其实只是语言层面的,当我们调用JVM层面的Thread.sleep()的时候,它仍然会变成阻塞式的。与此同时,这也意味着我们在协程当中应该尽量避免出现阻塞式的行为。尽量使用delay,而不是sleep。
那么,我们该如何理解Kotlin协程的“非阻塞”?答案是:挂起和恢复。这两个能力也是协程才拥有的特殊能力,普通的程序是不具备的。
挂起和恢复,初学者看到这两个概念可能会比较陌生。它俩的字面意思我们都能看懂,但当发生在程序世界里之后,就无法理解了,因为我们根本就看不见,也摸不着。那怎么办呢?
我的做法还是:建立思维模型。
对于执行在普通线程当中的程序来说,如果我们站在CPU的角度上看,最终它会以类似这样的方式执行:
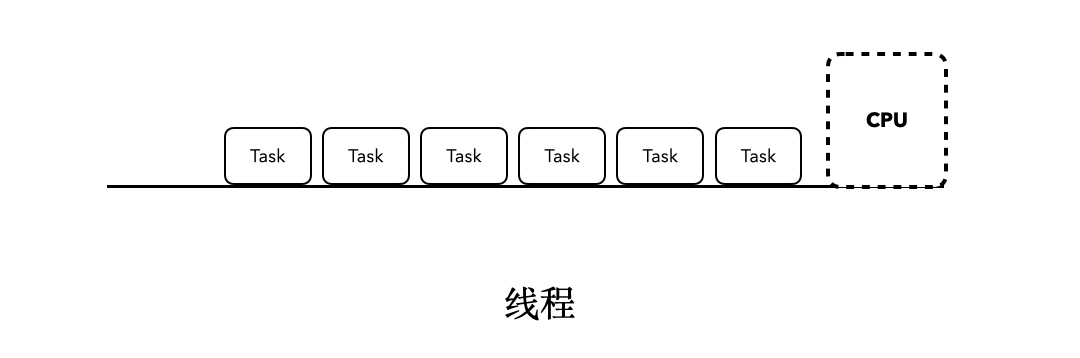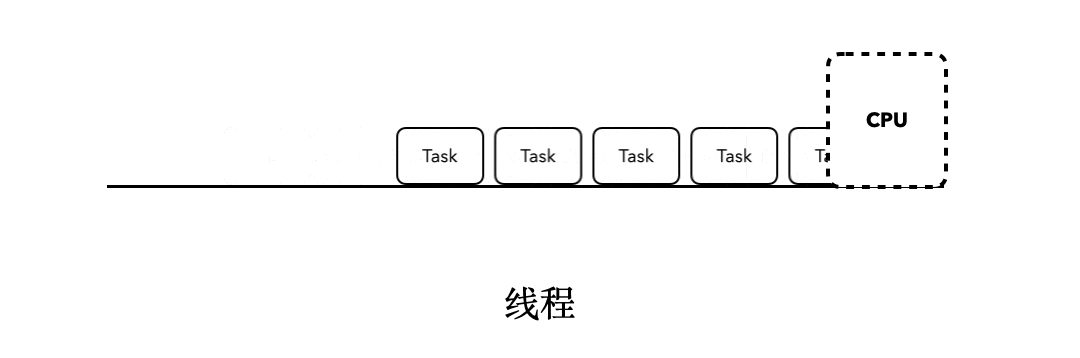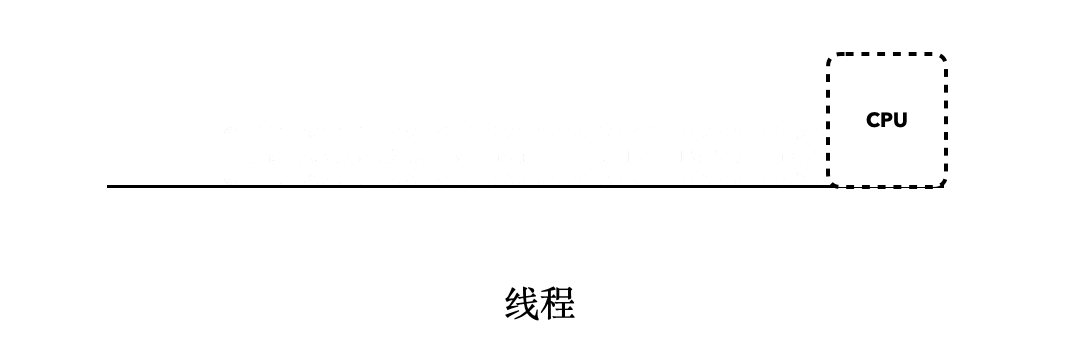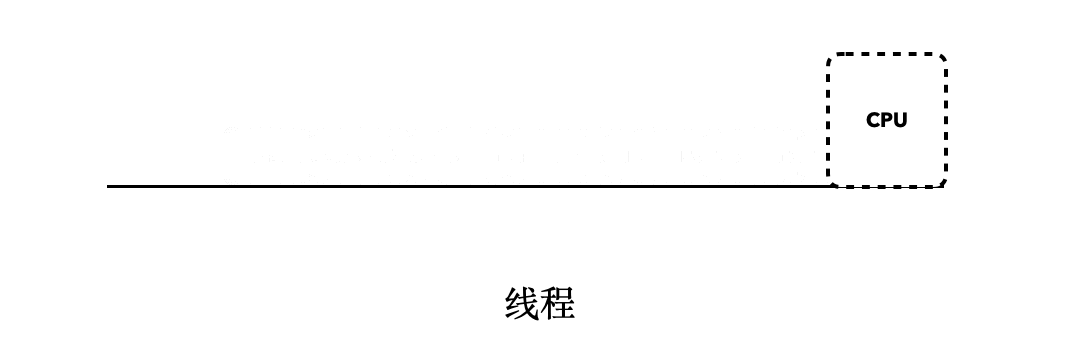
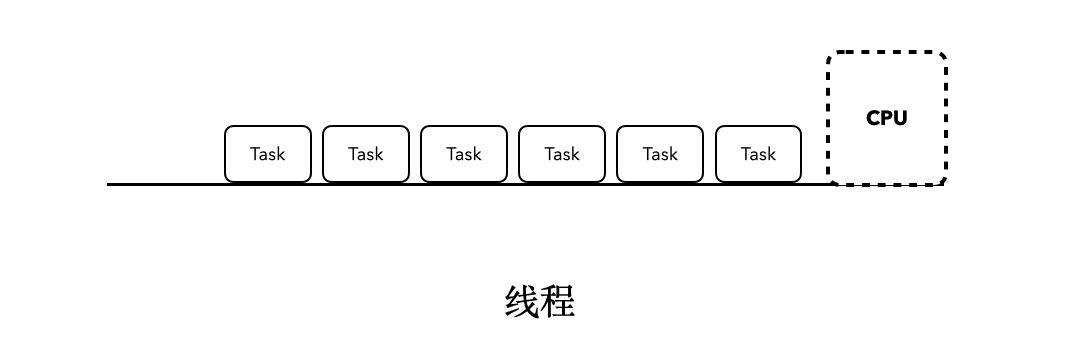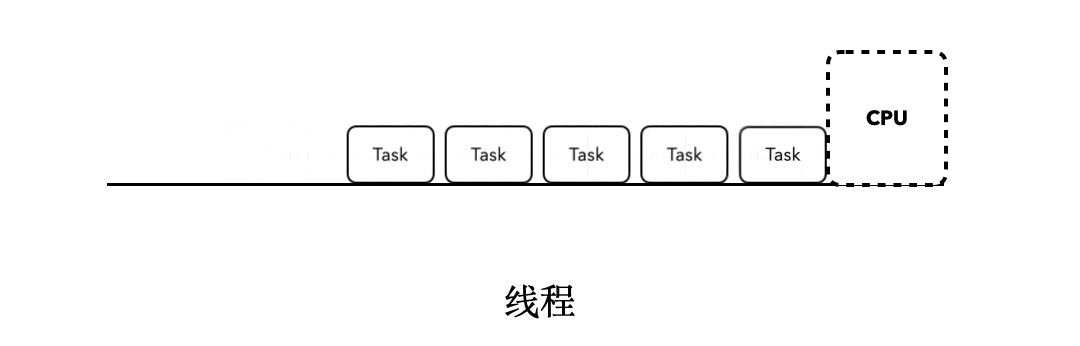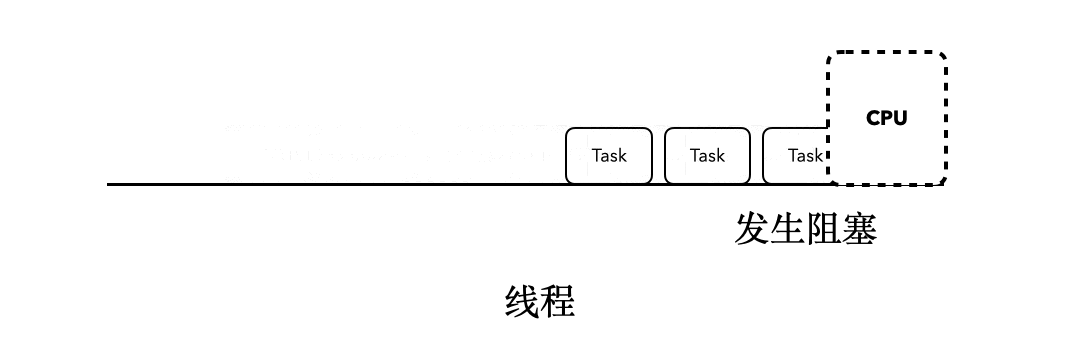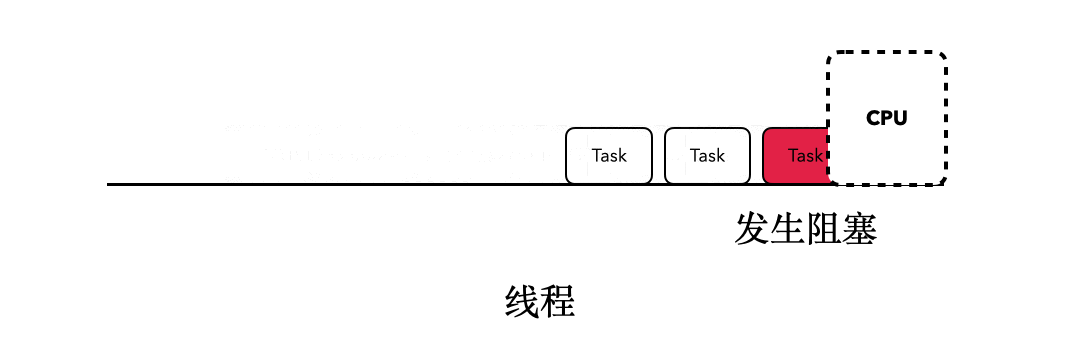
这时候,当某个任务发生了阻塞行为的时候,比如sleep,当前执行的Task就会阻塞后面所有任务的执行。就像下面这张动图所展示的一样:
那么,协程是如何通过挂起和恢复来实现非阻塞的呢?
大部分的语言当中都会存在一个类似“调度中心”的东西,它会来实现Task任务的执行和调度。如下图所示:
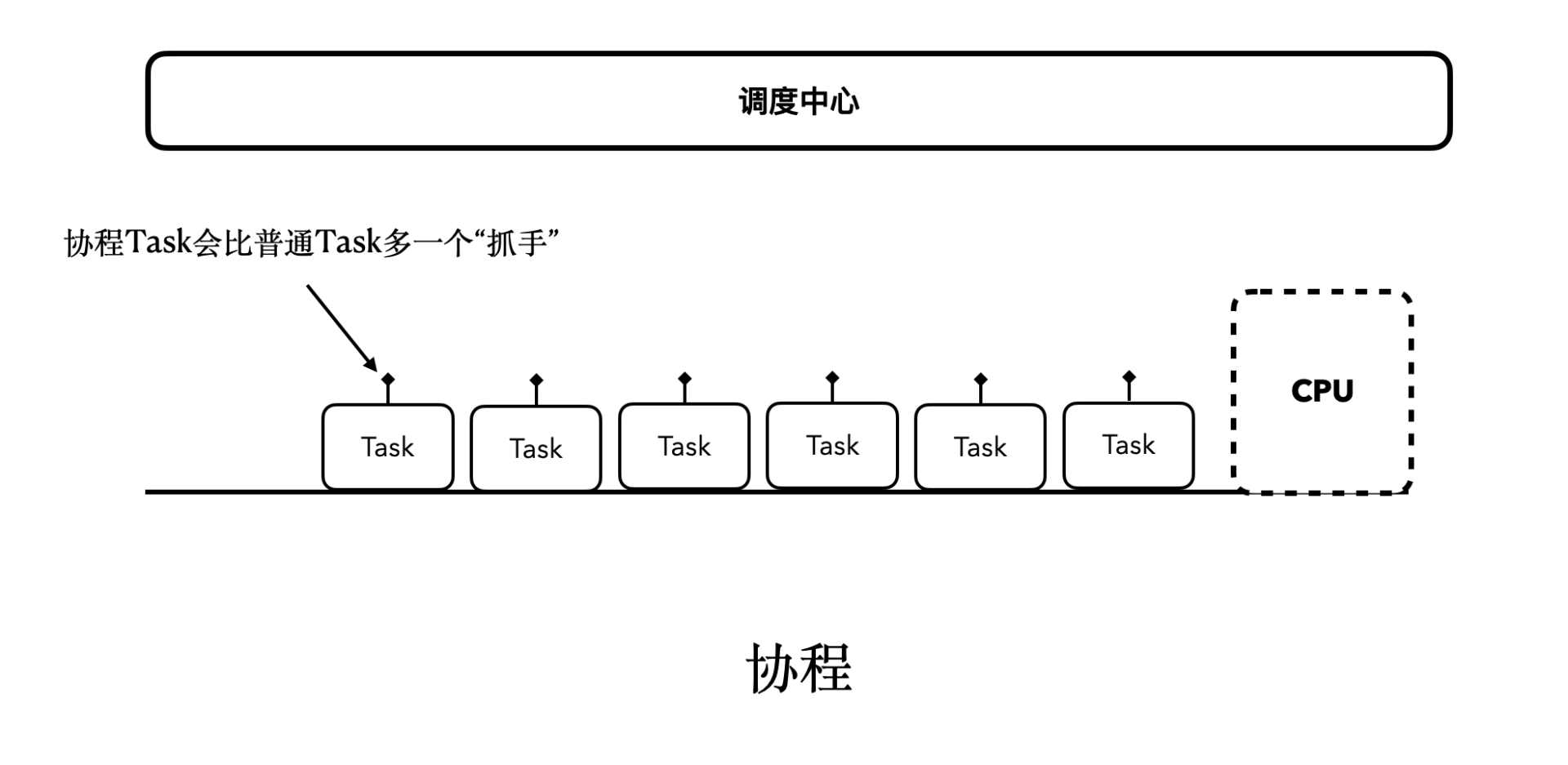
而协程除了拥有“调度中心”以外,对于每个协程的Task,还会多出一个类似“抓手”“挂钩”的东西,可以方便我们对它进行“挂起和恢复”。协程任务的总体执行流程,大致会像下图描述的这样:
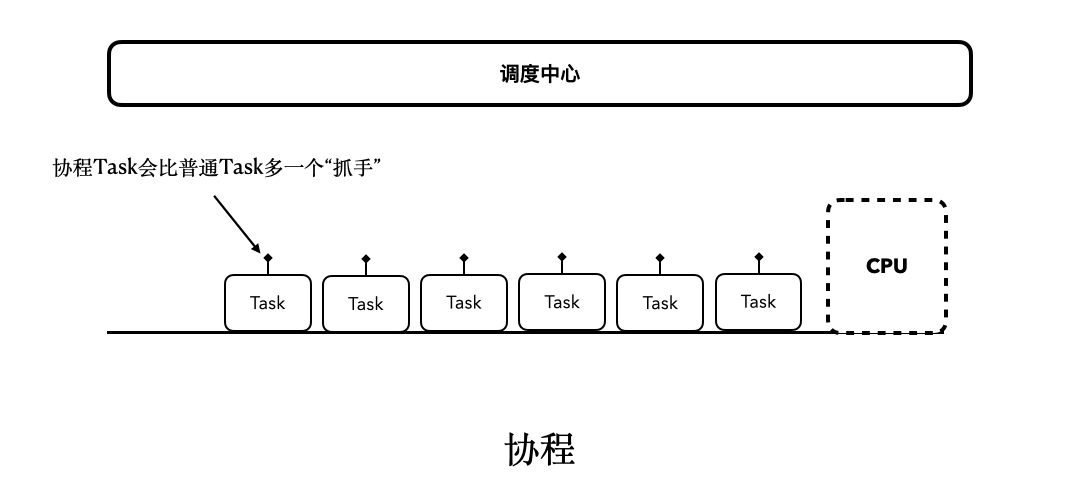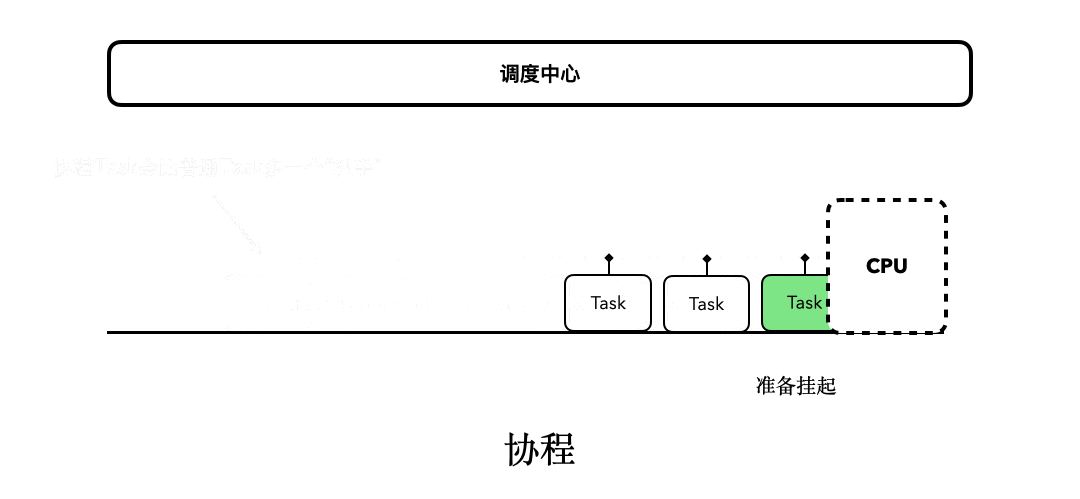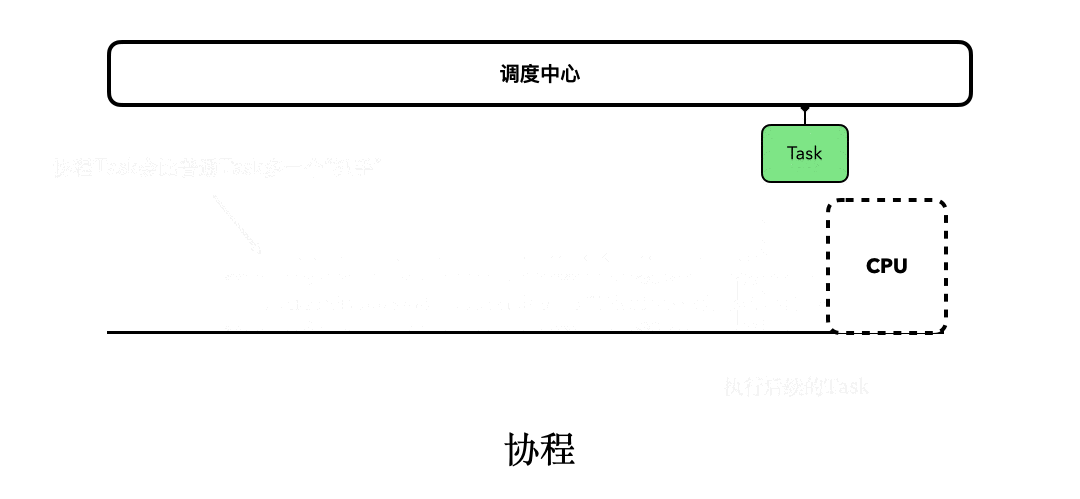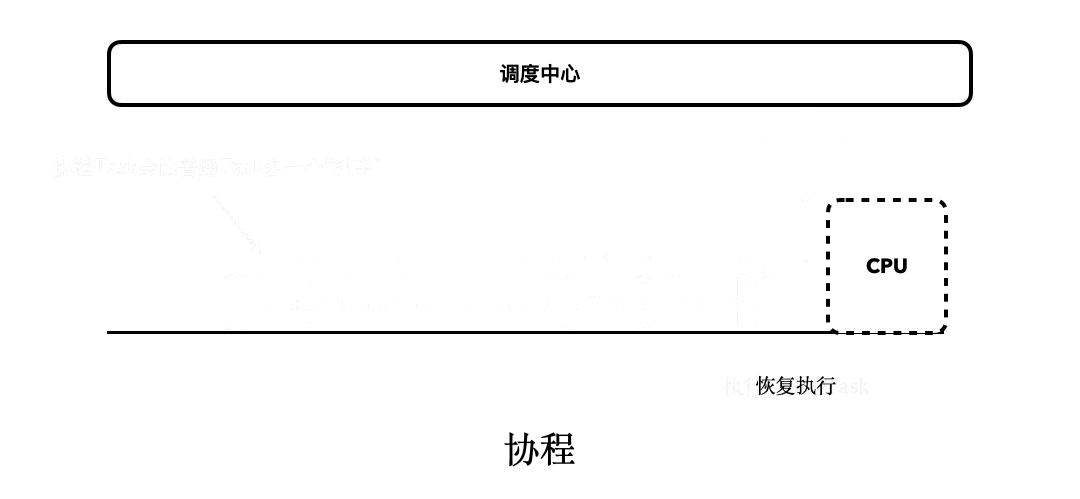
通过对比可以看出,线程的sleep之所以是阻塞式的,是因为它会阻挡后续Task的执行。而协程之所以是非阻塞式的,是因为它可以支持挂起和恢复。当Task由于某种原因被挂起后,后续的Task并不会因此被阻塞。
这时候,如果我们回过头再来看之前的代码,相信也会有新的体会:
fun main() = runBlocking {
launch {
repeat(3) {
delay(1000L)
println("Print-1:${Thread.currentThread().name}")
}
}
launch {
repeat(3) {
delay(900L)
println("Print-2:${Thread.currentThread().name}")
}
}
delay(3000L)
}
/*
输出结果:
Print-2:main @coroutine#3
Print-1:main @coroutine#2
Print-2:main @coroutine#3
Print-1:main @coroutine#2
Print-2:main @coroutine#3
Print-1:main @coroutine#2
*/
好了,到这里,我们今天的内容就差不多结束了。这节课我并没有给你介绍任何具体的协程API,而是先带你建立协程的思维模型,目的就是让你在这个过程中,真正理解协程的核心概念,并建立起一个清晰的认知,从而为后面API的学习打下基础。毕竟,磨刀不误砍柴工嘛!
那么在学完这节课之后,你也需要掌握以下几个要点:
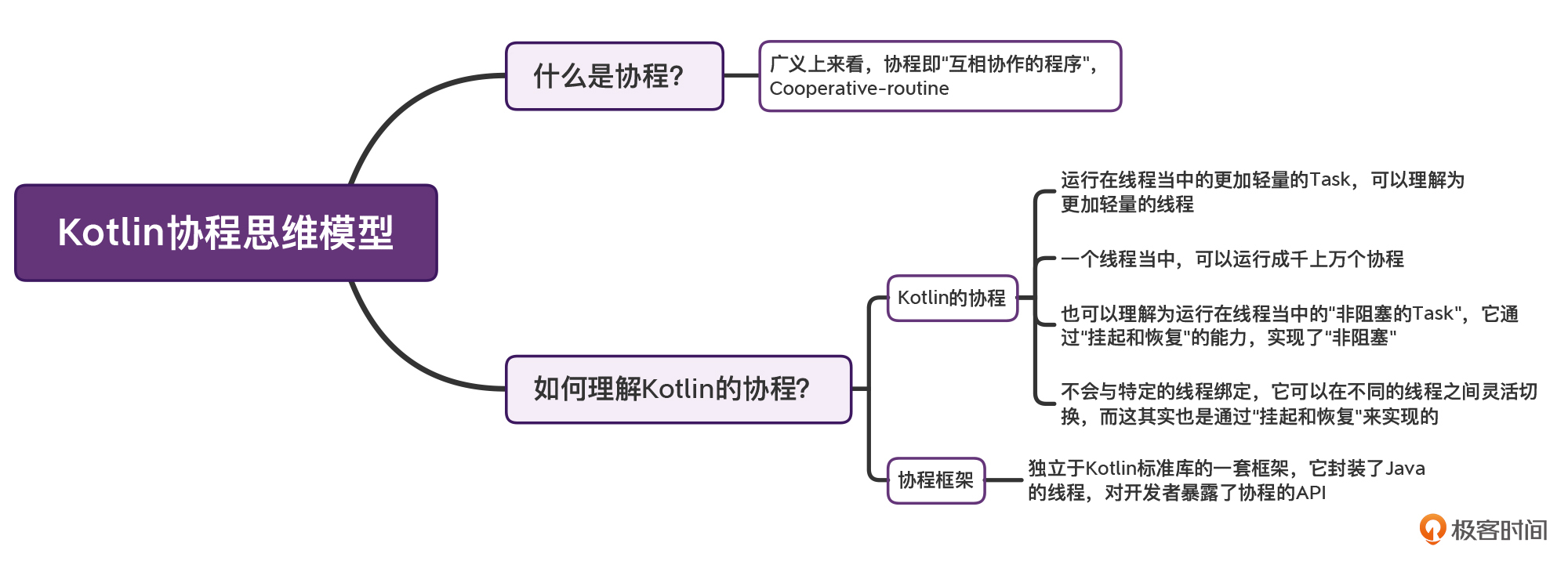
说实话,学习协程,真的不是一件容易的事情。如果这节课我不介绍协程的思维模型,一上来就介绍协程的API,你一定会觉得云里雾里、找不着方向。所以,也请你不要轻视这节课的重要性,一定要充分理解本节课的内容,再去学习后面的知识点。
下节课开始,我会正式介绍Kotlin协程相关的API,同时,也会进一步完善我们的协程思维模型。
有人说:协程会比线程更加高效,请问你认同这种说法吗?为什么? 欢迎在留言区分享你的看法和见解,也欢迎你把今天的内容分享给更多的朋友,我们一起交流探讨。
评论