
你好,我是朱涛。今天我们来学习Kotlin协程的Context。
协程的Context,在Kotlin当中有一个具体的名字,叫做CoroutineContext。它是我们理解Kotlin协程非常关键的一环。
从概念上讲,CoroutineContext很容易理解,它只是个上下文而已,实际开发中它最常见的用处就是切换线程池。不过,CoroutineContext背后的代码设计其实比较复杂,如果不能深入理解它的设计思想,那我们在后面阅读协程源码,并进一步建立复杂并发结构的时候,都将会困难重重。
所以这节课,我将会从应用的角度出发,带你了解CoroutineContext的使用场景,并会对照源码带你理解它的设计思路。另外,知识点之间的串联也是很重要的,所以我还会带你分析它跟我们前面学的Job、Deferred、launch、async有什么联系,让你能真正理解和掌握协程的上下文,并建立一个基于CoroutineContext的协程知识体系。
前面说过,CoroutineContext就是协程的上下文。你在前面的第14~16讲里其实就已经见过它了。在第14讲我介绍launch源码的时候,CoroutineContext其实就是函数的第一个参数:
// 代码段1
public fun CoroutineScope.launch(
// 这里
// ↓
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {}
这里我先说一下,之前我们在调用launch的时候,都没有传context这个参数,因此它会使用默认值EmptyCoroutineContext,顾名思义,这就是一个空的上下文对象。而如果我们想要指定launch工作的线程池的话,就需要自己传context这个参数了。
另外,在第15讲里,我们在挂起函数getUserInfo()当中,也用到了withContext()这个函数,当时我们传入的是“Dispatchers.IO”,这就是Kotlin官方提供的一个CoroutineContext对象。让我们来回顾一下:
// 代码段2
fun main() = runBlocking {
val user = getUserInfo()
logX(user)
}
suspend fun getUserInfo(): String {
logX("Before IO Context.")
withContext(Dispatchers.IO) {
logX("In IO Context.")
delay(1000L)
}
logX("After IO Context.")
return "BoyCoder"
}
/*
输出结果:
================================
Before IO Context.
Thread:main @coroutine#1
================================
================================
In IO Context.
Thread:DefaultDispatcher-worker-1 @coroutine#1
================================
================================
After IO Context.
Thread:main @coroutine#1
================================
================================
BoyCoder
Thread:main @coroutine#1
================================
*/
可以看到,当我们在withContext()这里指定线程池以后,Lambda当中的代码就会被分发到DefaultDispatcher线程池中去执行,而它外部的所有代码仍然还是运行在main之上。
其实,Kotlin官方还提供了挂起函数版本的main()函数,所以我们的代码也可以改成这样:
// 代码段3
suspend fun main() {
val user = getUserInfo()
logX(user)
}
不过,你要注意的是:挂起函数版本的main()的底层做了很多封装,虽然它可以帮我们省去写runBlocking的麻烦,但不利于我们学习阶段的探索和研究。因此,后续的Demo我们仍然以runBlocking为主,你只需要知道Kotlin有这么一个东西,等到你深入理解协程以后,就可以直接用“suspend main()”写Demo了。
我们说回runBlocking这个函数,第14讲里我们介绍过,它的第一个参数也是CoroutineContext,所以,我们也可以传入一个Dispatcher对象作为参数:
// 代码段4
// 变化在这里
// ↓
fun main() = runBlocking(Dispatchers.IO) {
val user = getUserInfo()
logX(user)
}
/*
输出结果:
================================
Before IO Context.
Thread:DefaultDispatcher-worker-1 @coroutine#1
================================
================================
In IO Context.
Thread:DefaultDispatcher-worker-1 @coroutine#1
================================
================================
After IO Context.
Thread:DefaultDispatcher-worker-1 @coroutine#1
================================
================================
BoyCoder
Thread:DefaultDispatcher-worker-1 @coroutine#1
================================
*/
这时候,我们会发现,所有的代码都运行在DefaultDispatcher这个线程池当中了。而Kotlin官方除了提供了Dispatchers.IO以外,还提供了Dispatchers.Main、Dispatchers.Unconfined、Dispatchers.Default这几种内置Dispatcher。我来分别给你介绍一下:
需要特别注意的是,Dispatchers.IO底层是可能复用Dispatchers.Default当中的线程的。如果你足够细心的话,会发现前面我们用的都是Dispatchers.IO,但实际运行的线程却是DefaultDispatcher这个线程池。
为了让这个问题更加清晰,我们可以把上面的例子再改一下:
// 代码段5
// 变化在这里
// ↓
fun main() = runBlocking(Dispatchers.Default) {
val user = getUserInfo()
logX(user)
}
/*
输出结果:
================================
Before IO Context.
Thread:DefaultDispatcher-worker-1 @coroutine#1
================================
================================
In IO Context.
Thread:DefaultDispatcher-worker-2 @coroutine#1
================================
================================
After IO Context.
Thread:DefaultDispatcher-worker-2 @coroutine#1
================================
================================
BoyCoder
Thread:DefaultDispatcher-worker-2 @coroutine#1
================================
*/
当Dispatchers.Default线程池当中有富余线程的时候,它是可以被IO线程池复用的。可以看到,后面三个结果的输出都是在同一个线程之上的,这就是因为Dispatchers.Default被Dispatchers.IO复用线程导致的。如果我们换成自定义的Dispatcher,结果就会不一样了。
// 代码段6
val mySingleDispatcher = Executors.newSingleThreadExecutor {
Thread(it, "MySingleThread").apply { isDaemon = true }
}.asCoroutineDispatcher()
// 变化在这里
// ↓
fun main() = runBlocking(mySingleDispatcher) {
val user = getUserInfo()
logX(user)
}
public fun ExecutorService.asCoroutineDispatcher(): ExecutorCoroutineDispatcher =
ExecutorCoroutineDispatcherImpl(this)
/*
输出结果:
================================
Before IO Context.
Thread:MySingleThread @coroutine#1
================================
================================
In IO Context.
Thread:DefaultDispatcher-worker-1 @coroutine#1
================================
================================
After IO Context.
Thread:MySingleThread @coroutine#1
================================
================================
BoyCoder
Thread:MySingleThread @coroutine#1
================================
*/
在上面的代码中,我们是通过asCoroutineDispatcher()这个扩展函数,创建了一个Dispatcher。从这里我们也能看到,Dispatcher的本质仍然还是线程。这也再次验证了我们之前的说法:协程运行在线程之上。
然后在这里,当我们为runBlocking传入自定义的mySingleDispatcher以后,程序运行的结果就不一样了,由于它底层并没有复用线程,因此只有“In IO Context”是运行在DefaultDispatcher这个线程池的,其他代码都运行在mySingleDispatcher之上。
另外,前面提到的Dispatchers.Unconfined,我们也要额外注意。还记得之前学习launch的时候,我们遇到的例子吗?请问下面4行代码,它们的执行顺序是怎样的?
// 代码段7
fun main() = runBlocking {
logX("Before launch.") // 1
launch {
logX("In launch.") // 2
delay(1000L)
logX("End launch.") // 3
}
logX("After launch") // 4
}
如果你理解了第14讲的内容,那你一定能分析出它们的运行顺序应该是:1、4、2、3。
但你要注意,同样的代码模式在特殊的环境下,结果可能会不一样。比如在Android平台,或者是如果我们指定了Dispatchers.Unconfined这个特殊的Dispatcher,它的这种行为模式也会被打破。比如像这样:
// 代码段8
fun main() = runBlocking {
logX("Before launch.") // 1
// 变化在这里
// ↓
launch(Dispatchers.Unconfined) {
logX("In launch.") // 2
delay(1000L)
logX("End launch.") // 3
}
logX("After launch") // 4
}
/*
输出结果:
================================
Before launch.
Thread:main @coroutine#1
================================
================================
In launch.
Thread:main @coroutine#2
================================
================================
After launch
Thread:main @coroutine#1
================================
================================
End launch.
Thread:kotlinx.coroutines.DefaultExecutor @coroutine#2
================================
*/
以上代码的运行顺序就变成了:1、2、4、3。这一点,就再一次说明了Kotlin协程的难学。传了一个不同的参数进来,整个代码的执行顺序都变了,这谁不头疼呢?最要命的是,Dispatchers.Unconfined设计的本意,也并不是用来改变代码执行顺序的。
请你留意“End launch”运行的线程“DefaultExecutor”,是不是觉得很乱?其实Unconfined代表的意思就是,当前协程可能运行在任何线程之上,不作强制要求。
由此可见,Dispatchers.Unconfined其实是很危险的。所以,我们不应该随意使用Dispatchers.Unconfined。
好,现在我们也了解了CoroutineContext的常见应用场景。不过,我们还没解释这节课的标题,什么是“万物皆为Context”?
所谓的“万物皆为Context”,当然是一种夸张的说法,我们换成“万物皆有Context”可能更加准确。
在Kotlin协程当中,但凡是重要的概念,都或多或少跟CoroutineContext有关系:Job、Dispatcher、CoroutineExceptionHandler、CoroutineScope,甚至挂起函数,它们都跟CoroutineContext有着密切的联系。甚至,它们之中的Job、Dispatcher、CoroutineExceptionHandler本身,就是Context。
我这么一股脑地告诉你,你肯定觉得晕乎乎,所以下面我们就一个个来看。
在学习launch的时候,我提到过如果要调用launch,就必须先有“协程作用域”,也就是CoroutineScope。
// 代码段9
// 注意这里
// ↓
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {}
// CoroutineScope 源码
public interface CoroutineScope {
public val coroutineContext: CoroutineContext
}
如果你去看CoroutineScope的源码,你会发现,它其实就是一个简单的接口,而这个接口只有唯一的成员,就是CoroutineContext。所以,CoroutineScope只是对CoroutineContext做了一层封装而已,它的核心能力其实都来自于CoroutineContext。
而CoroutineScope最大的作用,就是可以方便我们批量控制协程。
// 代码段10
fun main() = runBlocking {
// 仅用于测试,生成环境不要使用这么简易的CoroutineScope
val scope = CoroutineScope(Job())
scope.launch {
logX("First start!")
delay(1000L)
logX("First end!") // 不会执行
}
scope.launch {
logX("Second start!")
delay(1000L)
logX("Second end!") // 不会执行
}
scope.launch {
logX("Third start!")
delay(1000L)
logX("Third end!") // 不会执行
}
delay(500L)
scope.cancel()
delay(1000L)
}
/*
输出结果:
================================
First start!
Thread:DefaultDispatcher-worker-1 @coroutine#2
================================
================================
Third start!
Thread:DefaultDispatcher-worker-3 @coroutine#4
================================
================================
Second start!
Thread:DefaultDispatcher-worker-2 @coroutine#3
================================
*/
在上面的代码中,我们自己创建了一个简单的CoroutineScope,接着,我们使用这个scope连续创建了三个协程,在500毫秒以后,我们就调用了scope.cancel(),这样一来,代码中每个协程的“end”日志就不会输出了。
这同样体现了协程结构化并发的理念,相同的功能,我们借助Job也同样可以实现。关于CoroutineScope更多的底层细节,我们会在源码篇的时候深入学习。
那么接下来,我们就看看Job跟CoroutineContext的关系。
如果说CoroutineScope是封装了CoroutineContext,那么Job就是一个真正的CoroutineContext了。
// 代码段11
public interface Job : CoroutineContext.Element {}
public interface CoroutineContext {
public interface Element : CoroutineContext {}
}
上面这段代码很有意思,Job继承自CoroutineContext.Element,而CoroutineContext.Element仍然继承自CoroutineContext,这就意味着Job是间接继承自CoroutineContext的。所以说,Job确实是一个真正的CoroutineContext。
所以,我们写这样的代码也完全没问题:
// 代码段12
fun main() = runBlocking {
val job: CoroutineContext = Job()
}
不过,更有趣的是CoroutineContext本身的接口设计。
// 代码段13
public interface CoroutineContext {
public operator fun <E : Element> get(key: Key<E>): E?
public operator fun plus(context: CoroutineContext): CoroutineContext {}
public fun minusKey(key: Key<*>): CoroutineContext
public fun <R> fold(initial: R, operation: (R, Element) -> R): R
public interface Key<E : Element>
}
从上面代码中的get()、plus()、minusKey()、fold()这几个方法,我们可以看到CoroutineContext的接口设计,就跟集合API一样。准确来说,它的API设计和Map十分类似。
所以,我们完全可以把CoroutineContext当作Map来用。
// 代码段14
@OptIn(ExperimentalStdlibApi::class)
fun main() = runBlocking {
// 注意这里
val scope = CoroutineScope(Job() + mySingleDispatcher)
scope.launch {
// 注意这里
logX(coroutineContext[CoroutineDispatcher] == mySingleDispatcher)
delay(1000L)
logX("First end!") // 不会执行
}
delay(500L)
scope.cancel()
delay(1000L)
}
/*
输出结果:
================================
true
Thread:MySingleThread @coroutine#2
================================
*/
在上面的代码中,我们使用了“Job() + mySingleDispatcher”这样的方式创建CoroutineScope,代码之所以这么写,是因为CoroutineContext的plus()进行了操作符重载。
// 代码段15
// 操作符重载
// ↓
public operator fun <E : Element> plus(key: Key<E>): E?
你注意这里代码中的operator关键字,如果少了它,我们就得换一种方式了:mySingleDispatcher.plus(Job())。因为,当我们用operator修饰plus()方法以后,就可以用“+”来重载这个方法,类似的,List和Map都支持这样的写法:list3 = list1+list2、map3 = map1 + map2,这代表集合之间的合并。
另外,我们还使用了“coroutineContext[CoroutineDispatcher]”这样的方式,访问当前协程所对应的Dispatcher。这也是因为CoroutineContext的get(),支持了操作符重载。
// 代码段16
// 操作符重载
// ↓
public operator fun <E : Element> get(key: Key<E>): E?
实际上,在Kotlin当中很多集合也是支持get()方法重载的,比如List、Map,我们都可以使用这样的语法:list[0]、map[key],以数组下标的方式来访问集合元素。
还记得我们在第1讲提到的“集合与数组的访问方式一致”这个知识点吗?现在我们知道了,这都要归功于操作符重载。实际上,Kotlin官方的源代码当中大量使用了操作符重载来简化代码逻辑,而CoroutineContext就是一个最典型的例子。
如果你足够细心的话,这时候你应该也发现了:Dispatcher本身也是CoroutineContext,不然它怎么可以实现“Job() + mySingleDispatcher”这样的写法呢?最重要的是,当我们以这样的方式创建出scope以后,后续创建的协程就全部都运行在mySingleDispatcher这个线程之上了。
那么,Dispatcher到底是如何跟CoroutineContext建立关系的呢?让我们来看看它的源码吧。
// 代码段17
public actual object Dispatchers {
public actual val Default: CoroutineDispatcher = DefaultScheduler
public actual val Main: MainCoroutineDispatcher get() = MainDispatcherLoader.dispatcher
public actual val Unconfined: CoroutineDispatcher = kotlinx.coroutines.Unconfined
public val IO: CoroutineDispatcher = DefaultIoScheduler
public fun shutdown() { }
}
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {}
public interface ContinuationInterceptor : CoroutineContext.Element {}
可以看到,Dispatchers其实是一个object单例,它的内部成员的类型是CoroutineDispatcher,而它又是继承自ContinuationInterceptor,这个类则是实现了CoroutineContext.Element接口。由此可见,Dispatcher确实就是CoroutineContext。
除了上面几个重要的CoroutineContext之外,协程其实还有一些上下文是我们还没提到的。比如CoroutineName,当我们创建协程的时候,可以传入指定的名称。比如:
// 代码段18
@OptIn(ExperimentalStdlibApi::class)
fun main() = runBlocking {
val scope = CoroutineScope(Job() + mySingleDispatcher)
// 注意这里
scope.launch(CoroutineName("MyFirstCoroutine!")) {
logX(coroutineContext[CoroutineDispatcher] == mySingleDispatcher)
delay(1000L)
logX("First end!")
}
delay(500L)
scope.cancel()
delay(1000L)
}
/*
输出结果:
================================
true
Thread:MySingleThread @MyFirstCoroutine!#2 // 注意这里
================================
*/
在上面的代码中,我们调用launch的时候,传入了“CoroutineName(“MyFirstCoroutine!”)”作为协程的名字。在后面输出的结果中,我们得到了“@MyFirstCoroutine!#2”这样的输出。由此可见,其中的数字“2”,其实是一个自增的唯一ID。
CoroutineContext当中,还有一个重要成员是CoroutineExceptionHandler,它主要负责处理协程当中的异常。
// 代码段19
public interface CoroutineExceptionHandler : CoroutineContext.Element {
public companion object Key : CoroutineContext.Key<CoroutineExceptionHandler>
public fun handleException(context: CoroutineContext, exception: Throwable)
}
可以看到,CoroutineExceptionHandler的接口定义其实很简单,我们基本上一眼就能看懂。CoroutineExceptionHandler真正重要的,其实只有handleException()这个方法,如果我们要自定义异常处理器,我们就只需要实现该方法即可。
// 代码段20
// 这里使用了挂起函数版本的main()
suspend fun main() {
val myExceptionHandler = CoroutineExceptionHandler { _, throwable ->
println("Catch exception: $throwable")
}
val scope = CoroutineScope(Job() + mySingleDispatcher)
val job = scope.launch(myExceptionHandler) {
val s: String? = null
s!!.length // 空指针异常
}
job.join()
}
/*
输出结果:
Catch exception: java.lang.NullPointerException
*/
不过,虽然CoroutineExceptionHandler的用法看起来很简单,但当它跟协程“结构化并发”理念相结合以后,内部的异常处理逻辑是很复杂的。关于协程异常处理的机制,我们会在第23讲详细介绍。
这节课的内容到这里就结束了,我们来总结一下吧。
另外我也画了一张结构图,来描述CoroutineContext元素之间的关系,方便你建立完整的知识体系。
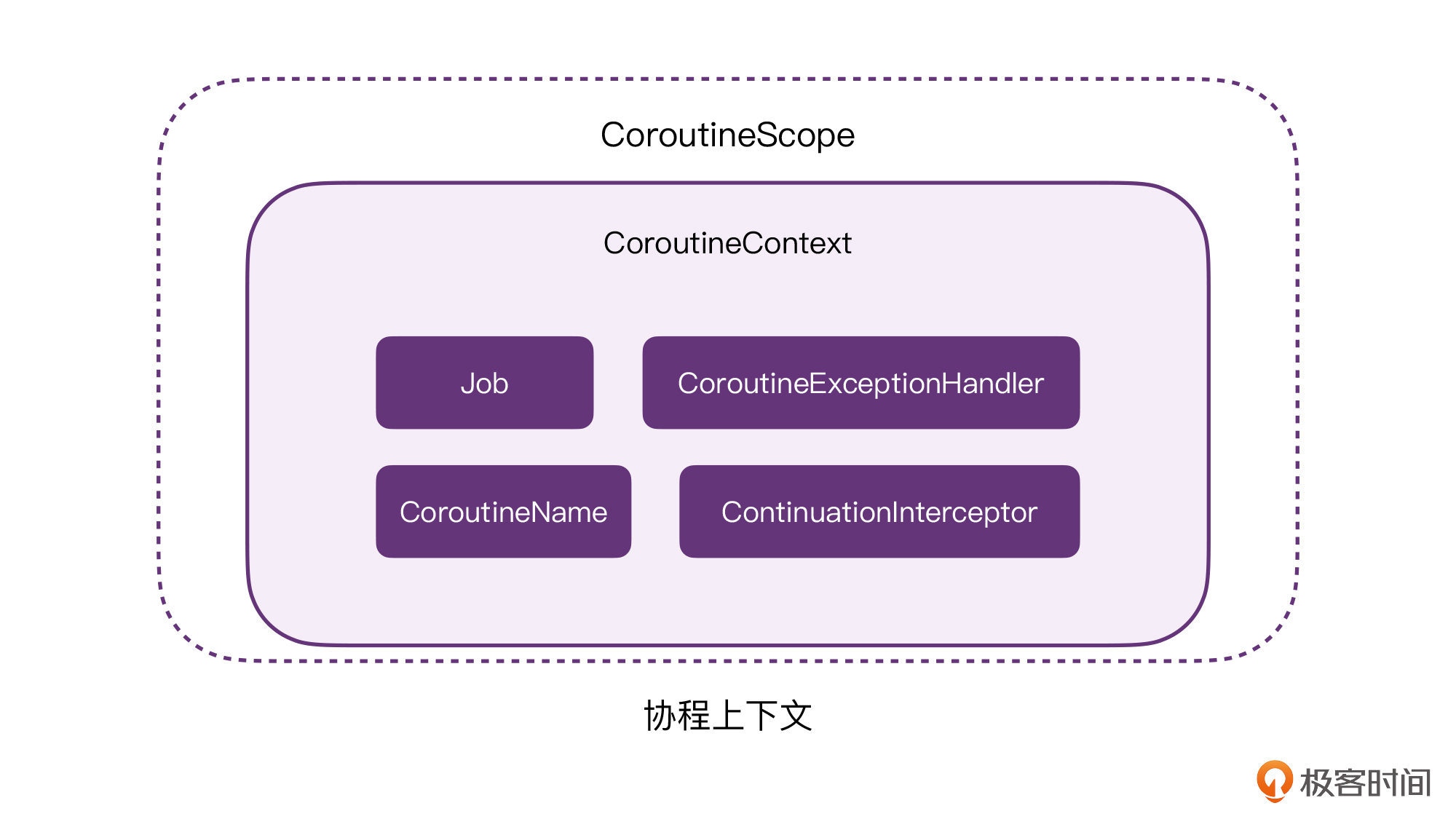
所以总的来说,我们前面学习的Job、Dispatcher、CoroutineName,它们本质上只是CoroutieContext这个集合当中的一种数据类型,只是恰好Kotlin官方让它们都继承了CoroutineContext这个接口。而CoroutineScope则是对CoroutineContext的进一步封装,它的核心能力,全部都是源自于CoroutineContext。
课程里,我提到了“挂起函数”与CoroutineContext也有着紧密的联系,请问,你能找到具体的证据吗?或者,你觉得下面的代码能成功运行吗?为什么?
// 代码段21
import kotlinx.coroutines.*
import kotlin.coroutines.coroutineContext
// 挂起函数能可以访问协程上下文吗?
// ↓
suspend fun testContext() = coroutineContext
fun main() = runBlocking {
println(testContext())
}
欢迎在留言区分享你的答案,也欢迎你把今天的内容分享给更多的朋友。