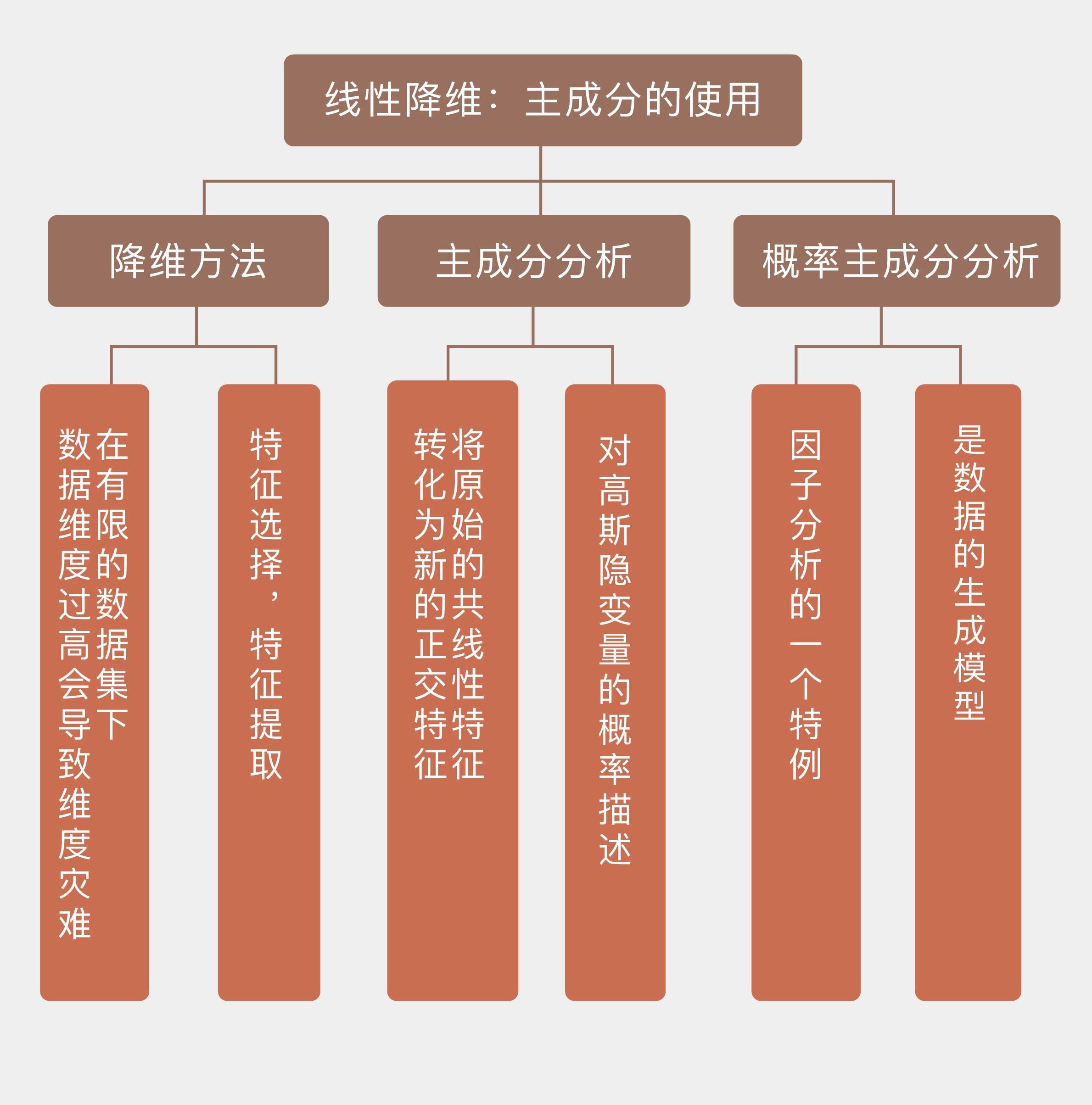
不同方差的主成分示意图,2点钟方向的主成分方差较大,11点钟方向的主成分方差较小(图片来自维基百科)
在前一篇文章中,我以岭回归和LASSO为例介绍了线性回归的正则化处理。这两种方法都属于收缩方法(shrinkage method),它们能够使线性回归的系数连续变化。但和岭回归不同的是,LASSO可以将一部分属性的系数收缩为0,事实上起到了筛选属性的作用。
和LASSO这种间接去除属性的收缩方法相对应的是维度规约。维度规约这个听起来个高大上的名称是数据挖掘中常用的术语,它有一个更接地气的同义词,就是降维(dimensionality reduction),也就是直接降低输入属性的数目来削减数据的维度。
对数据维度的探讨来源于“维数灾难”(curse of dimensionality),这个概念是数学家理查德·贝尔曼(Richard Bellman)在动态优化问题的研究中提出的。
发表于《IEEE模式分析与机器智能汇刊》(IEEE Transactions on Pattern Analysis and Machine Intelligence)第1卷第3期的论文《维数问题:一个简单实例(A Problem of Dimensionality: A Simple Example)》在数学上证明了当所有参数都已知时,属性维数的增加可以让分类问题的错误率渐进为0;可当未知的参数只能根据数量有限的样本来估计时,属性维数的增加会使错误率先降低再升高,最终收敛到0.5。
这就像一群谋士七嘴八舌在支招,当领导的要是对每个人的意见都深入考虑再来拍板的话,这样的决策也没什么准确性可言了。
维数灾难深层次的原因在于数据样本的有限。当属性的维数增加时,每个属性每个可能取值的组合就会以指数形式增长。对于二值属性来说,2个属性所有可能的取值组合共有4种,可每增加一个属性,可能的组合数目就会翻番。
一般的经验法则是每个属性维度需要对应至少5个数据样本,可当属性维数增加而样本数目不变时,过少的数据就不足以体现出属性背后的趋势,从而导致过拟合的发生。当然,这只是维数灾难的一种解释方式,另一种解释方式来源于几何角度的数据稀疏性,这里暂且按下不表。
在数据有限的前提下解决维数灾难问题,化繁为简的降维是必经之路。降维的对象通常是那些“食之无味,弃之可惜”的鸡肋属性。食之无味是因为它们或者和结果的相关性不强,或者和其他属性之间有较强的关联,使用这样的属性没有多大必要;弃之可惜则是因为它们终究还包含一些独有的信息,就这么断舍离又会心有不甘。
如果像亚历山大剑斩戈尔迪之结一般直接砍掉鸡肋属性,这种“简单粗暴”的做法就是特征选择(feature selection)。另一种更加稳妥的办法是破旧立新,将所有原始属性的信息一点儿不浪费地整合到脱胎换骨的新属性中,这就是特征提取(feature extraction)的方法。
无论是特征选择还是特征提取,在“人工智能基础课”中都有相应的介绍。
今天我要换个角度,先从刚刚介绍过的岭回归说起。假设数据集中有$N$个样本,每个样本都有$p$个属性,则数据矩阵$\bf X$的维度就是$N \times p$。将中心化处理后,也就是减去每个属性平均值的$\bf X$进行奇异值分解(singular value decomposition)可以得到
$$ {\bf X} = {\bf U} {\bf D} {\bf V}^T $$
其中的$\bf U$和$\bf V$分别是$N \times p$维和$p \times p$维的正交矩阵,其各自的所有列向量可以张成一个子空间;$\bf D$则是对角矩阵,对角线上的各个元素是数据矩阵$\bf X$按从大到小顺序排列的奇异值(singular value)$d_j$。可以证明,岭回归求出的最优系数可以写成$\hat \beta = ({\bf X}^T {\bf X} + \lambda {\bf I}) ^ {-1} {\bf X}^T {\bf y}$。将$\bf X$的奇异值分解代入岭回归的预测输出中,就可以得到:
$$ {\bf X} {\hat \beta} = \sum\limits_{j = 1}^p {\bf u}_j \dfrac{d^2_j}{d^2_j + \lambda}{\bf u}^T_j {\bf y}$$
其中的${\bf u}_j$是矩阵$\bf U$的列向量,也是$\bf X$的列空间的一组正交基,而岭回归计算出的结果正是将训练数据的输出$\bf y$投影到以${\bf u}_j$为正交基的子空间上所得到的坐标。除了空间变换之外,岭回归的收缩特性也有体现,那就是上式中的系数。当正则化参数$\lambda$一定时,奇异值$d_j$越小,它对应的坐标被衰减地就越厉害。
除了经历不同的收缩外,奇异值$d_j$还有什么意义呢?$d_j$的平方可以写成对角矩阵$\bf D$的平方,利用奇异值分解又可以推导出${\bf D}^2$和数据矩阵$\bf X$如下的关系
$$ {\bf X}^T{\bf X} = {\bf V} {\bf D}^2 {\bf V}^T $$
这个表达式实际上就是矩阵的特征分解(eigen decomposition):等式左侧的表达式实际上就是数据的协方差矩阵(covariance matrix)乘以维度$N$,$\bf V$中的每一列$v_j$都是协方差矩阵的特征向量,${\bf D}^2$中的每个对角元素$d^2_j$则是对应的特征值。如果你对主成分分析还有印象,就不难发现每一个${\bf X}{\bf v}_j$都是一个主成分(principal component),第$j$个主成分上数据的方差就是$d^2_j / N$。
解释到这儿,就能够看出岭回归的作用了:岭回归收缩系数的对象并非每个单独的属性,而是由属性的线性组合计算出来的互不相关的主成分,主成分上数据的方差越小,其系数收缩地就越明显。
数据在一个主成分上波动较大意味着主成分的取值对数据有较高的区分度,也就是上一季中提到的“最大方差原理”。反之,数据在另一个主成分上方差较小就说明不同数据的取值较为集中,而聚成一团的数据显然是不容易区分的。岭回归正是通过削弱方差较小的主成分、保留方差较大的主成分来简化模型,实现正则化的。
不同方差的主成分示意图,2点钟方向的主成分方差较大,11点钟方向的主成分方差较小(图片来自维基百科)
看到这里你可能就想到了:既然主成分都已经算出来了,与其用岭回归兜一个圈子,莫不如直接使用它们作为自变量来计算线性回归的系数,这种思路得到的就是主成分回归(principal component regression)。
主成分回归以每个主成分${\bf z}_j = {\bf X} {\bf v}_j$作为输入计算回归参数。由于不同的主成分是两两正交的,因此这个看似多元线性回归的问题实质上是多个独立的简单线性回归的组合,每个主成分的权重系数可以表示为
$$ \hat \theta_m = \dfrac{<{\bf z}_m, {\bf y}>}{<{\bf z}_m, {\bf z}_m>} $$
其中$<>$表示内积运算。需要注意的是这里的$\bf y$和数据矩阵的每一列${\bf x}_j$都要做去均值的处理,主成分回归的常数项就是$\bf y$,也就是所有数据输出结果的均值$\bar y$。
当主成分回归中使用的主成分数目等于数据的属性数目$p$时,主成分回归和岭回归的结果是一致的。可如果放弃方差最小的若干个主成分,得到的就是约化的回归结果,从而更加清晰地体现出主成分分析的思想。
主成分分析是典型的特征提取方法,它和收缩方法的本质区别在于将原始的共线性特征转化为人为生成的正交特征,从而带来了数据维度的约简和数据压缩的可能性。数字图像处理中的特征脸方法是主成分回归最典型的应用之一。
所谓“特征脸”(eigenface)实际上就是用于人脸识别的主成分。用特征脸方法处理的人脸图像都具有相同的空间维度,假定图像的像素数目都是$100 \times 100$,那么每一个像素点都是一个属性,数字图像就变成了10000维空间中的一个点。可一般数字图像慢变特性决定了这10000个特征之间具有很强的关联,直接处理的话运算量较大不说,还未必有好的效果,可谓事倍功半。

根据AT&T Laboratories Cambridge Facedatabase人脸数据库生成的特征脸
图片来自https://www.bytefish.de/blog/eigenfaces/
引入主成分分析后,情况就不一样了。主成分分析可以将10000个相互关联的像素维度精炼成100~150个特征脸,再用这些特征脸来重构相同形状的人脸图像。
上图是真实计算出的一组特征脸图像,如果是晚上一个人在家玩手机的话,那这组惊悚的特征脸很可能让你吓得不轻。可如果你能想明白一个问题:这只是一组被打成正方形的10000多维的相互正交的主成分,而原始图像让它们碰巧具有了人脸的轮廓,这些人不人鬼不鬼的东西就没有那么恐怖了。
这些主成分可以用来分解任意一张面孔,说不定我的一寸照片就可以表示成$27% \times Ef_1 + 6% \times Ef_2 + 49% \times Ef_3 + \cdots + 34% \times Ef_{16}$的组合呢。
前面对主成分分析的解释都是从降维的角度出发的。换个角度,主成分分析可以看成对高斯隐变量的概率描述。隐变量(latent variable)是不能直接观测但可以间接推断的变量,虽然数据本身处在高维空间之中,但决定其变化特点的可能只是有限个参数,这些幕后的操纵者就是隐变量,寻找隐变量的过程就是对数据进行降维的过程。
概率主成分分析(probabilistic principal component analysis)体现的就是高斯型观测结果和高斯隐变量之间线性的相关关系,它是因子分析(factor analysis)的一个特例。概率主成分分析的数学推导比较复杂,在这里不妨直接给出结论:
假定一组数据观测值构成了$D$维向量$\bf X$,另外一组隐变量构成了$Q$维向量$\bf Z$,两者之间的线性关系就可以表示为
$$ {\bf X} = {\bf W} {\bf Z} + \boldsymbol \mu + \boldsymbol \epsilon$$
其中关联矩阵$\bf W$是由标准正交基构成的矩阵,非零向量$\boldsymbol \mu$表示观测值的均值,$\boldsymbol \epsilon$则是服从标准多维正态分布$N({\bf 0}, \sigma^2{\bf I})$的各向同性的噪声。如果假设隐变量$\bf Z$具有多元标准正态形式的先验分布$p({\bf Z})$,去均值观测数据${\bf X}$的对数似然概率可以写成
$$ \log p({\bf X} | {\bf W}, \sigma^2) = - \dfrac{N}{2} \ln |{\bf C}| - \dfrac{1}{2} \sum\limits_{i = 1}^N {\bf x}_i^T {\bf C}^{-1} {\bf x}_i$$
其中${\bf C} = {\bf W}{\bf W}^T + \sigma^2{\bf I}$。计算可得,让似然概率取得最大值的参数值为$\hat {\bf W} = {\bf V}({\bf D}^ 2 - \sigma^2{\bf I}) ^ {1/2}$。根据这个$\hat {\bf W}$又可以计算出超参数$\sigma ^ 2$得最大似然估计值$\hat \sigma ^ 2 = \dfrac{1}{D - Q} \sum\limits_{j = Q + 1}^D d_j^2$,这说明噪声方差就是所有被丢弃的主成分方差的均值。而当$\boldsymbol \epsilon \rightarrow 0$时,概率主成分分析的线性系数$\hat {\bf W}$就会退化为经典的主成分分析中的$\bf V$。
除了似然概率外,根据正态分布的性质也可以计算出隐变量的后验概率$p({\bf Z} | {\bf X})$。令$\hat {\bf F} = \hat {\bf W}^T \hat {\bf W} + \hat \sigma^2 {\bf I}$,后验概率满足的就是以$\hat {\bf F} ^ {-1}\hat {\bf W} {\bf X}$为均值,$\sigma ^ 2 \hat {\bf F}^{-1}$为方差的正态分布。当$\boldsymbol \epsilon \rightarrow 0$时,隐变量的最优值就会收敛为经典主成分${\bf XV}$。
在实际问题中,使用的主成分数目是个超参数,需要通过模型选择确定,而概率主成分分析对测试数据的处理就可以完成模型选择的任务。从重构误差的角度出发,经典主成分分析一般会让被选中的主成分的特征值之和占所有特征值之和的95%以上。在贝叶斯框架下,计算最优的主成分数目需要对所有未知的参数超参数进行积分,其过程非常复杂,在这里就不讨论了。
同其他隐变量模型一样,概率主成分分析也是个生成模型,其生成机制如下图所示。首先从服从一维正态分布的隐变量$z$中得到采样值$\hat z$,以${\bf w}z + \boldsymbol \mu$为均值的单位方差二维正态分布就是数据$\bf x$的似然分布,将先验分布与似然分布相乘,得到的就是最右侧的二维分布$p(\bf x)$了。
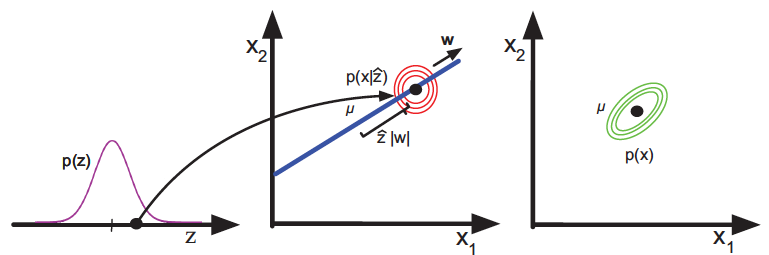
图片来自Machine Learning: A Probabilistic Perspective, 图12.1
在Scikit-learn中,主成分分析对应的类是PCA,它在decomposition的模块种。还是以英超数据集为例,对多元线性回归的数据进行主成分分析,可以得到10个主成分的方差,以及它们占总方差的比例:

英超数据集上所有主成分的方差及其比例
从结果中可以看出,方差最大的主成分占据了近4/5的总方差,前两个主成分的方差之和的比例则超过了90%。在对数据进行降维时,如果将方差的比例阈值设定为95%,保留的主成分数目就是2个,这说明2个主成分已经足以解释输出结果中90%的变化。
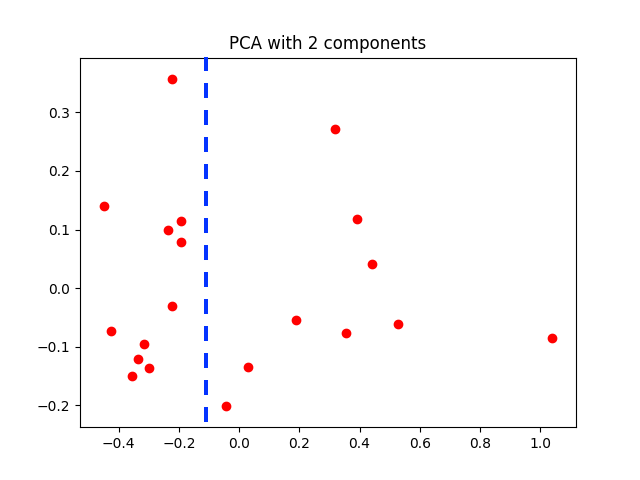
使用前两个主成分对英超数据集进行变换的结果
为了对主成分分析后的数据分布产生直观的认识,可以将变换后的数据点显示在低维空间中,以观察它们的集中程度。出于观察方便的考虑,在可视化时只选择了方差最大的前两个主成分,虽然这样做会造成较大的误差,但变换后的数据就可以在平面直角坐标系上显示出来,如上图所示。
可以看出,经过变换后的数据点依然分散在整个二维平面上,但根据它们在横轴上的取值已经可以近似地将数据划分为两个类别,其原因很可能是蓝线两侧的数据代表了两种类型的球队风格,就像来自两个高斯分布的随机数。
今天我和你分享了从岭回归到主成分回归的推导过程,以及作为降维方法和特征提取技术的主成分分析,其要点如下:
在有限的数据集下,数据维度过高会导致维数灾难;
降维的方法包括特征选择和特征提取;
主成分分析将原始的共线性特征转化为新的正交特征,从而实现特征提取;
概率主成分分析是因子分析的一种,是数据的生成模型。
在机器学习中,还有一种和主成分分析名字相似的方法,叫作独立成分分析(independent component analysis)。那么这两者之间到底有什么区别和联系呢?
你可以查阅资料加以了解,并在这里分享你的理解。