你好,我是吴咏炜。
上一讲我们讨论了一些并发编程的基本概念,今天我们来讨论一个略有点绕的问题,C++ 里的内存模型和原子量。
C++98 的年代里,开发者们已经了解了线程的概念,但 C++ 的标准里则完全没有提到线程。从实践上,估计大家觉得不提线程,C++ 也一样能实现多线程的应用程序吧。不过,很多聪明人都忽略了,下面的事实可能会产生不符合直觉预期的结果:
对于上面的后一点,大部分开发者并没有意识到。原因有好几个方面:
举一个例子,假设我们有两个全局变量:
int x = 0;
int y = 0;
然后我们在一个线程里执行:
x = 1;
y = 2;
在另一个线程里执行:
if (y == 2) {
x = 3;
y = 4;
}
想一下,你认为上面的代码运行完之后,x、y 的数值有几种可能?
你如果认为有两种可能,1、2 和 3、4 的话,那说明你是按典型程序员的思维模式看问题的——没有像编译器和处理器一样处理问题。事实上,1、4 也是一种结果的可能。有两个基本的原因可以造成这一后果:
x = 1 还是先执行 y = 2 完全是件无关紧要的事:它们没有外部“可观察”的区别。y 的写入有可能先反映到主内存中去。之所以这个问题似乎并不常见,是因为常见的 x86 和 x86-64 处理器是在顺序执行方面做得最保守的——大部分其他处理器,如 ARM、DEC Alpha、PA-RISC、IBM Power、IBM z架构和 Intel Itanium 在内存序问题上都比较“松散”。x86 使用的内存模型基本提供了顺序一致性(sequential consistency);相对的,ARM 使用的内存模型就只是松散一致性(relaxed consistency)。较为严格的描述,请查看参考资料 [1] 和里面提供的进一步资料。虽说 Intel 架构处理器的顺序一致性比较好,但在多处理器(包括多核)的情况下仍然能够出现写读序列变成读写序列的情况,产生意料之外的后果。参考资料 [2] 中提供了完整的例子,包括示例代码。对于缓存不一致性问题的一般中文介绍,可以查看参考资料 [3]。
在多线程可能对同一个单件进行初始化的情况下,有一个双重检查锁定的技巧,可基本示意如下:
// 头文件
class singleton {
public:
static singleton* instance();
…
private:
static singleton* inst_ptr_;
};
// 实现文件
singleton* singleton::inst_ptr_ =
nullptr;
singleton* singleton::instance()
{
if (inst_ptr_ == nullptr) {
lock_guard lock; // 加锁
if (inst_ptr_ == nullptr) {
inst_ptr_ = new singleton();
}
}
return inst_ptr_;
}
这个代码的目的是消除大部分执行路径上的加锁开销。原本的意图是:如果 inst_ptr_ 没有被初始化,执行才会进入加锁的路径,防止单件被构造多次;如果 inst_ptr_ 已经被初始化,那它就会被直接返回,不会产生额外的开销。虽然看上去很美,但它一样有着上面提到的问题。Scott Meyers 和 Andrei Alexandrecu 详尽地分析了这个用法 [4],然后得出结论:即使花上再大的力气,这个用法仍然有着非常多的难以填补的漏洞。本质上还是上面说的,优化编译器会努力击败你试图想防止优化的努力,而多处理器会以令人意外的方式让代码走到错误的执行路径上去。他们分析得非常详细,建议你可以花时间学习一下。
在某些编译器里,使用 volatile 关键字可以达到内存同步的效果。但我们必须记住,这不是 volatile 的设计意图,也不能通用地达到内存同步的效果。volatile 的语义只是防止编译器“优化”掉对内存的读写而已。它的合适用法,目前主要是用来读写映射到内存地址上的 I/O 操作。
由于 volatile 不能在多处理器的环境下确保多个线程能看到同样顺序的数据变化,在今天的通用应用程序中,不应该再看到 volatile 的出现。
为了从根本上消除这些漏洞,C++11 里引入了适合多线程的内存模型。我们可以在参考资料 [5] 里了解更多的细节。跟我们开发密切相关的是:现在我们有了原子对象(atomic)和使用原子对象的获得(acquire)、释放(release)语义,可以真正精确地控制内存访问的顺序性,保证我们需要的内存序。
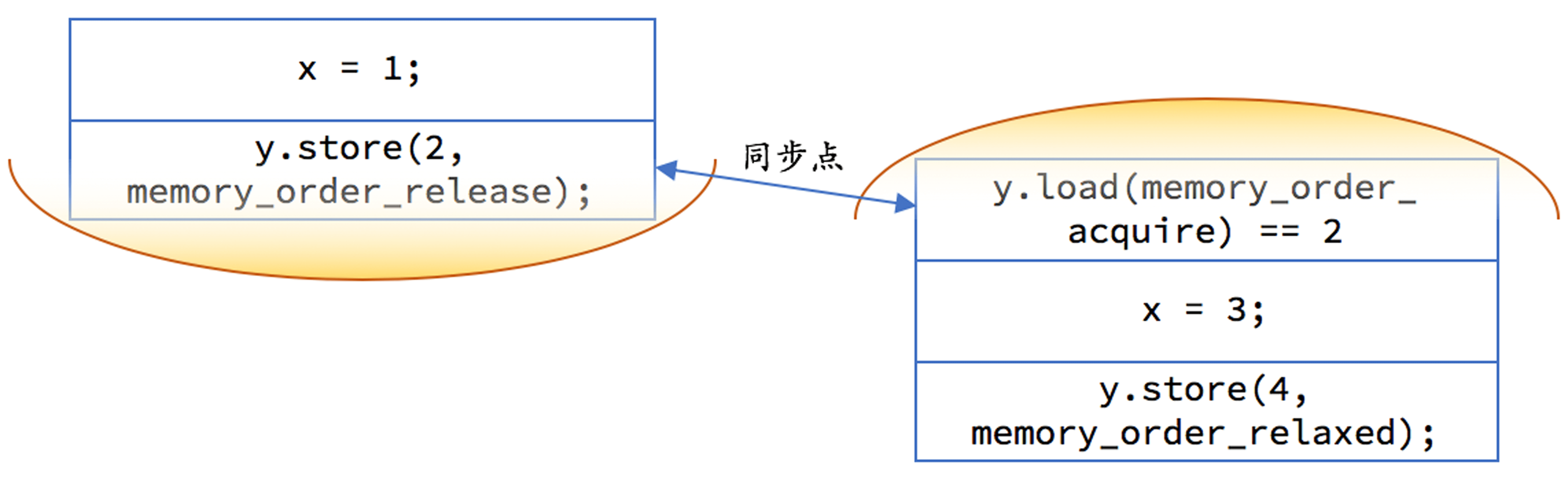
拿刚才的那个例子来说,如果我们希望结果只能是 1、2 或 3、4,即满足程序员心中的完全存储序(total store ordering),我们需要在 x = 1 和 y = 2 两句语句之间加入内存屏障,禁止这两句语句交换顺序。我们在此种情况下最常用的两个概念是“获得”和“释放”:
具体到我们上面的第一个例子,我们需要把 y 声明成 atomic<int>。然后,我们在线程 1 需要使用释放语义:
x = 1;
y.store(2, memory_order_release);
在线程 2 我们对 y 的读取应当使用获得语义,但存储只需要松散内存序即可:
if (y.load(memory_order_acquire) ==
2) {
x = 3;
y.store(4, memory_order_relaxed);
}
我们可以用下图示意一下,每一边的代码都不允许重排越过黄色区域,且如果 y 上的释放早于 y 上的获取的话,释放前对内存的修改都在另一个线程的获取操作后可见:
事实上,在我们把 y 改成 atomic<int> 之后,两个线程的代码一行不改,执行结果都会是符合我们的期望的。因为 atomic 变量的写操作缺省就是释放语义,读操作缺省就是获得语义(不严格的说法,精确表述见下面的内存序部分)。即
y = 2 相当于 y.store(2, memory_order_release)y == 2 相当于 y.load(memory_order_acquire) == 2但是,缺省行为可能是对性能不利的:我们并不需要在任何情况下都保证操作的顺序性。
另外,我们应当注意一下,acquire 和 release 通常都是配对出现的,目的是保证如果对同一个原子对象的 release 发生在 acquire 之前的话,release 之前发生的内存修改能够被 acquire 之后的内存读取全部看到。
刚才是对 atomic 用法的一个非正式介绍。下面我们对 atomic 做一个稍完整些的说明(更完整的见 [6])。
C++11 在 <atomic> 头文件中引入了 atomic 模板,对原子对象进行了封装。我们可以将其应用到任何类型上去。当然对于不同的类型效果还是有所不同的:对于整型量和指针等简单类型,通常结果是无锁的原子对象;而对于另外一些类型,比如 64 位机器上大小不是 1、2、4、8(有些平台/编译器也支持对更大的数据进行无锁原子操作)的类型,编译器会自动为这些原子对象的操作加上锁。编译器提供了一个原子对象的成员函数 is_lock_free,可以检查这个原子对象上的操作是否是无锁的。
原子操作有三类:
<atomic> 头文件中还定义了内存序,分别是:
memory_order_relaxed:松散内存序,只用来保证对原子对象的操作是原子的memory_order_consume:目前不鼓励使用,我就不说明了memory_order_acquire:获得操作,在读取某原子对象时,当前线程的任何后面的读写操作都不允许重排到这个操作的前面去,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见memory_order_release:释放操作,在写入某原子对象时,当前线程的任何前面的读写操作都不允许重排到这个操作的后面去,并且当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见memory_order_acq_rel:获得释放操作,一个读‐修改‐写操作同时具有获得语义和释放语义,即它前后的任何读写操作都不允许重排,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见,当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见memory_order_seq_cst:顺序一致性语义,对于读操作相当于获取,对于写操作相当于释放,对于读‐修改‐写操作相当于获得释放,是所有原子操作的默认内存序(除此之外,顺序一致性还保证了多个原子量的修改在所有线程里观察到的修改顺序都相同;我们目前的讨论暂不涉及多个原子量的修改)atomic 有下面这些常用的成员函数:
store)load)store,写入对象到原子对象里,第二个可选参数是内存序类型load,从原子对象读取内置对象,有个可选参数是内存序类型is_lock_free,判断对原子对象的操作是否无锁(是否可以用处理器的指令直接完成原子操作)exchange,交换操作,第二个可选参数是内存序类型(这是读‐修改‐写操作)compare_exchange_weak 和 compare_exchange_strong,两个比较加交换(CAS)的版本,你可以分别指定成功和失败时的内存序,也可以只指定一个,或使用默认的最安全内存序(这是读‐修改‐写操作)fetch_add 和 fetch_sub,仅对整数和指针内置对象有效,对目标原子对象执行加或减操作,返回其原始值,第二个可选参数是内存序类型(这是读‐修改‐写操作)++ 和 --(前置和后置),仅对整数和指针内置对象有效,对目标原子对象执行增一或减一,操作使用顺序一致性语义,并注意返回的不是原子对象的引用(这是读‐修改‐写操作)+= 和 -=,仅对整数和指针内置对象有效,对目标原子对象执行加或减操作,返回操作之后的数值,操作使用顺序一致性语义,并注意返回的不是原子对象的引用(这是读‐修改‐写操作)有了原子对象之后,我们可以轻而易举地把[第 2 讲] 中的 shared_count 变成线程安全。我们只需要包含 <atomic> 头文件,并把下面这行
long count_;
修改成
std::atomic_long count_;
即可(atomic_long 是 atomic<long> 的类型别名)。不过,由于我们并不需要 ++ 之后计数值影响其他行为,在 add_count 中执行简单的 ++、使用顺序一致性语义略有浪费。更好的做法是将其实现成:
void add_count() noexcept
{
count_.fetch_add(
1, std::memory_order_relaxed);
}
注意,macOS 上在使用 Clang 时似乎不支持对需要加锁的对象使用 is_lock_free 成员函数,此时链接会出错。而 GCC 在这种情况下,需要确保系统上装了 libatomic。以 CentOS 7 下的 GCC 7 为例,我们可以使用下面的语句来安装:
sudo yum install devtoolset-7-libatomic-devel
然后,用下面的语句编译可以通过:
g++ -pthread test.cpp -latomic
Windows 下使用 MSVC 则没有问题。
上一讲我们已经讨论了互斥量。今天,我们只需要补充两点:
lock)具有获得语义unlock)具有释放语义有了目前讲过的这些知识,我们终于可以实现一个真正安全的双重检查锁定了:
// 头文件
class singleton {
public:
static singleton* instance();
…
private:
static mutex lock_;
static atomic<singleton*>
inst_ptr_;
};
// 实现文件
mutex singleton::lock_;
atomic<singleton*>
singleton::inst_ptr_;
singleton* singleton::instance()
{
singleton* ptr = inst_ptr_.load(
memory_order_acquire);
if (ptr == nullptr) {
lock_guard<mutex> guard{lock_};
ptr = inst_ptr_.load(
memory_order_relaxed);
if (ptr == nullptr) {
ptr = new singleton();
inst_ptr_.store(
ptr, memory_order_release);
}
}
return inst_ptr_;
}
有个小地方注意一下:为了和 inst_ptr_.load 语句对称,我在 inst_ptr_.store 时使用了释放语义;不过,由于互斥量解锁本身具有释放语义,这么做并不是必需的。
在结束这一讲之前,我们来检查一下并发对编程接口的冲击。回想我们之前讲到标准库里 queue 有下面这样的接口:
template <typename T>
class queue {
public:
…
T& front();
const T& front() const;
void pop();
…
}
我们之前还问过为什么 pop 不直接返回第一个元素。可到了并发的年代,我们不禁要问,这样的接口设计到底明智吗?
会不会在我们正在访问 front() 的时候,这个元素就被 pop 掉了?
事实上,上面这样的接口是不可能做到并发安全的。并发安全的接口大概长下面这个样子:
template <typename T>
class queue {
public:
…
void wait_and_pop(T& dest)
bool try_pop(T& dest);
…
}
换句话说,要准备好位置去接收;然后如果接收成功了,才安安静静地在自己的线程里处理已经被弹出队列的对象。接收方式还得分两种,阻塞式的和非阻塞式的……
那我为什么要在内存模型和原子量这一讲里讨论这个问题呢?因为并发队列的实现,经常是用原子量来达到无锁和高性能的。单生产者、单消费者的并发队列,用原子量和获得、释放语义就能简单实现。对于多生产者或多消费者的情况,那实现就比较复杂了,一般会使用 compare_exchange_strong 或 compare_exchange_weak。讨论这个话题的复杂性,就大大超出了本专栏的范围了。你如果感兴趣的话,可以查看下面几项内容:
在这一讲里,我们讨论了 C++ 对并发的底层支持,特别是内存模型和原子量。这些底层概念,是在 C++ 里写出高性能并发代码的基础。
在传统 PC 上开发的程序员,应当比较少接触具有松散或弱内存一致性的系统,但原子量和普通变量的区别还是很容易在代码中表现出来的。请你尝试一下多个线程对一个原子量和一个普通全局变量做多次增一操作,观察最后的结果。
在 Intel 处理器架构上,唯一可见的重排是多处理器下的写读操作。大力推荐你尝试一下参考资料 [2] 中的例子(Windows 和 Linux 下可直接运行;macOS 下需要使用我的修改版本或备用下载链接来覆盖下载代码中的 gcc/ordering.cpp),并修改预定义宏。另外一种改法就是把代码中的 X、Y 的类型改成 atomic_int,重排也就消失了。
如果遇到任何特别问题,欢迎留言与我交流。
[1] Wikipedia, “Memory ordering”. https://en.wikipedia.org/wiki/Memory_ordering
[1a] 维基百科, “内存排序”. https://zh.wikipedia.org/zh-cn/内存排序
[2] Jeff Preshing, “Memory reordering caught in the act”. https://preshing.com/20120515/memory-reordering-caught-in-the-act/
[3] 王欢明, 《多处理器编程:从缓存一致性到内存模型》. https://zhuanlan.zhihu.com/p/35386457
[4] Scott Meyers and Andrei Alexandrescu, “C++ and the perils of double-checked locking”. https://www.aristeia.com/Papers/DDJ_Jul_Aug_2004_revised.pdf
[5] cppreference.com, “Memory model”. https://en.cppreference.com/w/cpp/language/memory_model
[5a] cppreference.com, “内存模型”. https://zh.cppreference.com/w/cpp/language/memory_model
[6] cppreference.com, “std::atomic”. https://en.cppreference.com/w/cpp/atomic/atomic
[6a] cppreference.com, “std::atomic”. https://zh.cppreference.com/w/cpp/atomic/atomic
[7] 吴咏炜, nvwa. https://github.com/adah1972/nvwa
[8] Cameron Desrochers, moodycamel::ConcurrentQueue. https://github.com/cameron314/concurrentqueue
[9] 陈皓, 《无锁队列的实现》. https://coolshell.cn/articles/8239.html