
你好,我是相辉。
我们要知道,在一个商业体里,用户从来都不是只有一副面孔。他们可能来自不同的需求场景,也可能来自不同的时间地点;可能是新用户或是老用户,也可能只是随便逛逛,或者可能是我们的铁杆粉丝。
就拿瑜伽产品来说,用户往往就会有三大类需求:瘦身塑形、心灵情绪、自我控制。那么,如果我们只是把用户描述成铁板一块,就会导致在描绘用户画像的时候,丢失了太多的细节。如果我们不能清晰地用一种办法把不同需求的用户进行细分化建模,并针对不同的用户制定不同的运营动作,我们就很难知道如何制定体验策略,如何细化体验设计。
在当今数据工具早已经发展得相对成熟的情况下,我们应该好好掌握它,并用它来理解和分析用户需求,以此把握好产品的细节与真实情况。
那么今天这节课,我们就来学会构建用户数据模型的方法,用结构化的思维方式理解我们产品中用户群的数据模型。
任何事情都是从无到有发展出来的,我们需要通过五步建立起数据模型,分别是抽象用户、还原场景、分层策略、模拟认知、拓展网络。接下来我们就依次来看一下。
我们在面对任何一个用户群体的时候,第一步就是要将众多用户的行为数据和画像数据,按照某种逻辑进行抽象和划分。因为单靠很多零散的数据其实是没有用的,我们只有按照某种逻辑将数据整合,以此描述用户具体的性质,才能真正描绘用户画像及其行为模式。
而抽象的标准,就是我们是否能够用一种模型或多种模型,将生态内的不同用户画像按照这个抽象逻辑区分开。
我给你打个比方吧。莎士比亚说,一千个人心中有一千个哈姆雷特。但如果我们将哈姆雷特按照某种标准进行分类,比如从“哈姆雷特是否善良”这个角度来看,那么人群自然而然地就可以分成善良、不善良、说不好这三种答案。所以一千个人心中,可能就变成了几类不同的哈姆雷特。
那么,我们面对自己的商业体也是一样的,我们需要用几个标准,梳理出用户的各种数据信息,并按照他们的特点,还原成不同的标签。
我举个例子。以前我和团队在梳理顺风车的车主画像时,会根据四个核心的划分标准来做:安全分、质量分、频率分、里程积累。
从这四个维度,我们就可以区分车主的层级,以此发现不同层级的车主都有哪些不同的生活特点。比如说:
此外,我们还发现了一个可怕的问题,就是核心贡献GMV的成熟车主都是老车主,并且他们还在不断流失。这也就说明了,我们当时产品的生态可能并没有那么健康。
后来,我们就按照这四个维度和用户出行的时间与间歇度,划分出了以上这几大类车主的典型画像,从而找到了他们的交易行为特点,以此区分地看待我们整个生态中,用户使用产品的真实状况。
所以,通过抽象用户行为数据去观测自己商业体的时候,你就能清晰地看到产品的用户分布和GMV构成。有的时候,一个GMV表现很好的业务,有可能已经老去甚至是即将死亡了,因为它所有贡献GMV的用户,都已经到了产品生命周期的末端。分层用户数据模型,就是我们发现业务问题与机会的重要利器。
仅仅有数据分层画像是远远不够的,我们还要将数据分层画像还原成用户的场景,把一张张画像变成一个个有血有肉的人。
比如,我曾经研究过书店的用户,当时我按照用户到店时间、书籍消费、活动消费、咖啡消费、店中店消费等维度,将用户行为层次进行了抽离,发现了不同的用户特点:

所以,通过用户数据的分类,我们其实会发现每一类用户,都是行为习惯相近且需求也相近的,他们就隶属于一个用户场景。另外,在这个书店的例子中,我们还发现,在还原每一类用户场景的同时,也会看到不同的书店,需求比重也不是很相同,而且居民区的店、商业区的店、学生区的店、旅游区的店,用户的画像也都不太一样。
那么这样,我们就可以通过数据,来还原真实用户的生活场景,然后伴随着对每个场景里各类用户的研究,就可以进行更好的、精细的场景设计和优化运营。
就拿刚才书店的例子来说,我们立刻就做了亲子会员、办公会员,以及偏重咖啡消费的会员体系,结合更加贴近书店的其他权益。这样紧密围绕书店的场景,一套付费会员的权益体系就设计出来了,并且根据后续的用户持续消费的数据表现,也看到它的增长十分良好。
所以,每种商业体,我们都可以用几个数据维度将用户分类,并且一旦分类,我们不仅可以发现产品生态的健康度,还可以发现和还原用户的生活场景,以此帮我们找到最该要撬动的那群人是谁。
在知晓了用户画像和场景以后,最关键的就是要开始选择我们的运营动作是什么了。只有根据不同的用户画像和场景准确形成决策,才是有效果的分层数据画像和场景还原。
还是之前顺风车的例子,基于多种用户画像,我们就可以针对不同用户群制定分层运营的策略。比如说:
因此,我们要利用好现代的数据工具,而不再是粗糙地给予统一的策略,用霰弹枪来打单点。当我们动态地根据不同层次的用户,做好分层的动态策略的时候,那么也是产品得到的效果最好、投入的成本最低的状态。
每个用户都有自己的文化背景和成长路径,所以每类用户对我们产品的认知也是不同的。
在我多个领域的工作经历当中,我发现了一个有趣的现象:企业自己认为自己是谁,与用户认为企业是谁,往往存在着错位的问题。
这就造成了企业的很多品牌和传播,打不到用户的痛点或者爽点上。比如还是前面顺风车的例子,在这个业务上线两年以后,还是有好多用户认为顺风车就是便宜的快车。
另外,也有企业会觉得自己很多的业务架构都非常清楚,但用户其实根本分不清他们业务之间的区别。比如我曾经在某二手电商就遇到过,用户根本分不清楚什么是寄卖、自营、C2C等等。
而不同的用户,在一个生态里,所在乎的东西也不太一样。在我经历过的电商社区的运营中,我就发现往往是新用户会更在乎优惠,但老用户会更在乎荣誉,比如电商社区里的认可度或者曝光度等等。
所以说,根据不同的用户场景和画像,还原不同用户的真实诉求,从而建立不同的用户认知模型,是我们做好用户沟通的基础。
我们需要把用户的现状、需求,以及对产品的认知价值点建立成模型,以此指导我们进行品牌交付的策略,对不同的人说不同的话。而要建立用户认知度的模型,我们可以通过采用反复的活动效果测试、问卷测试、焦点小组等工作,来接触用户,看看用户的背景是怎样的、他们是如何看待我们的产品的,以及我们的宣传和用户感知有没有产生什么偏差等等。
举个简单的例子,针对共享出行产品,对不同的用户来说,我们要制定不同的策略,对车主要讲赚油费,对乘客要讲经济实惠,对政府要讲环保安全,对合作伙伴要讲共赢合作等等。而在车主这类层级上,对白领车主要讲稳定安全,对职业车主要以教育为主,对新手要讲简单操作等等。
总而言之,不同的用户,认知也不同,我们要还原出他们对于产品的认知,从而基于认知,去指导我们的品牌和内容工作,以及端内设计的话语体系。
我们要知道,未来的广告和口碑只有带着人的温度,才会得到相对好的转化。每个用户都有自己的社交能力圈,如果我们的产品能打动不同层级的用户,那么就会获得不同范围的影响力。
所以,我们应当根据用户的影响力,来建立社交拉新能力的模型。比如说,目标用户群分别都是什么样的传播渠道,他们的拉新能力如何?他们传播出去的内容,有多少二次拉新?三次拉新?
另外,我们也要了解用户的社交能量。也就是说,我们要根据用户的转发、传播、点击、拉新、留存,来建立用户的社交模型,以及快速寻找到用户群中的那些种子用户的画像。
就好像蔚来汽车可以通过车主的转介绍率,来找到自己生态里的那些超级车主,以此对其进行重点服务。在蔚来汽车的生态里,每个车主都有自己的拉新记录,而且有几位车主都是为蔚来拉新上百位新车主的铁杆粉丝,他们也得到了相应的蔚来值以及重点的拉新回馈服务。在这个模型里,我们就能很清晰地知道,对哪一波车主进行重点回馈拉新服务效果是最好的。
把握了用户社交模型,我们就能迅速找到产品中的意见领袖。这将是未来产品流量影响力的重要线索。
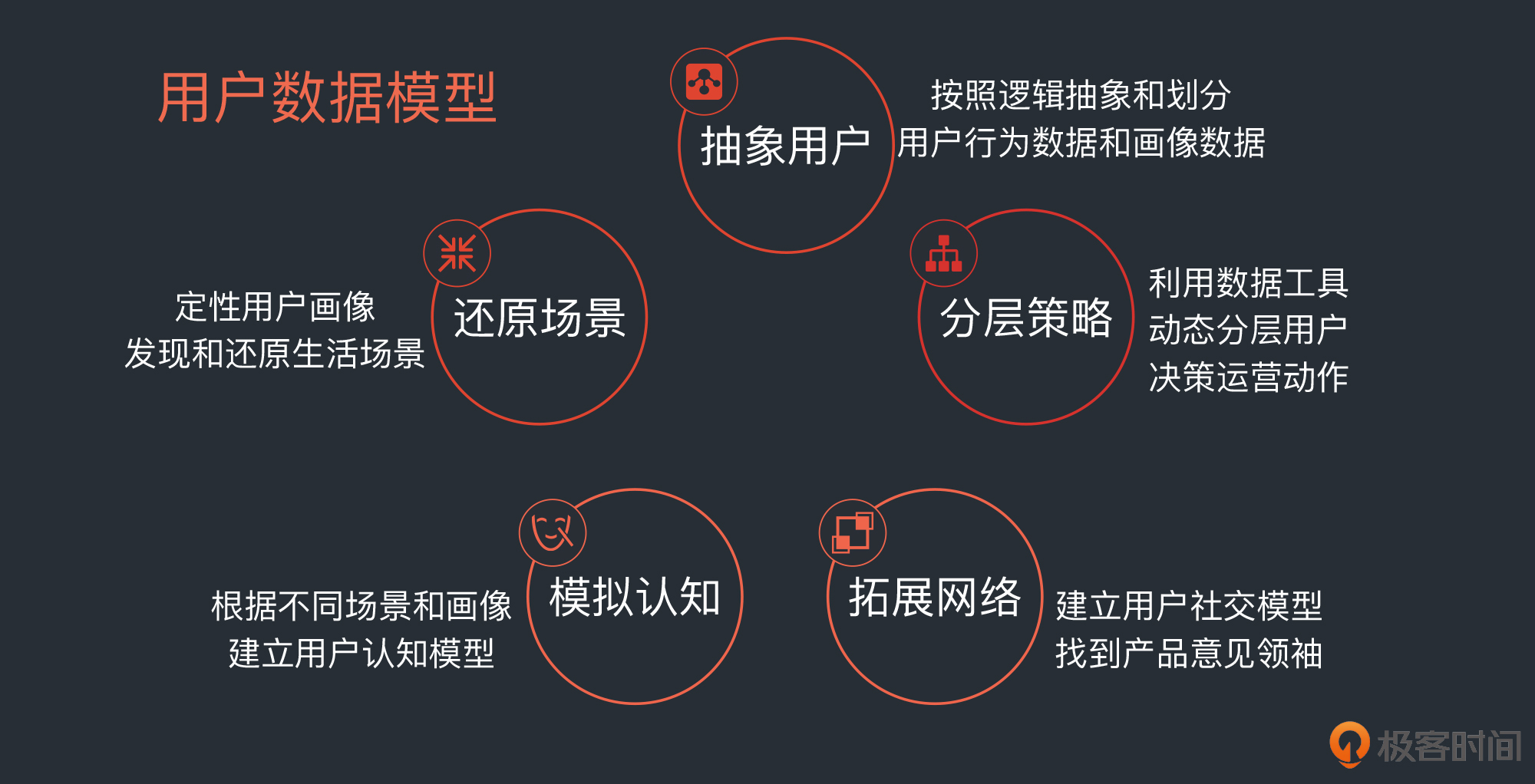
总结一下。今天我带你了解了用户数据分层的主要逻辑,你要掌握以下这五步建立用户数据模型的核心方法:
这样,你就拥有了一个基于数据的用户群像,并可以重新认识自己的用户群,为他们制定生活场景服务设计策略,制定合适高效的运营策略,并精准地寻找到用户群中的意见领袖,做好品牌工作。
在流量红利消失的时代,认清我们的用户都是如何组成的、我们的商业是否健康,都是必要的工作。我曾经接触过一个巨型的企业客户,他们在面对自己海量的用户时,不知道如何再进行用户活跃上的突破,于是花费了半年的时间认真做好数据中台,配合用户研究的手段,发现用户场景,一下子找到了很多新的机会。
从一个模糊的完整群像,到细化成几个关键人群的组合,并与数据进行有效结合,那么无论是定性的突破点,还是定量的效果衡量,我们就都能做到有的放矢了。
所以,既然有了数据工具,我们就要用起来,而不是像过去那样,一句“别这样做了,我们的用户不会喜欢”就给打发了。 如果真的有人这样说,这个时候,你就可以反问TA:“我们的用户有哪几群人,哪几个场景,哪几个阶段,你知道吗?”

请你思考一下,你的产品分别有哪几个场景的用户在用,他们的权重和画像是如何的?欢迎在评论区发表你的观点。
如果你的身边也有正在探索用户数据模型的朋友,也非常欢迎你把今天的内容分享给他,我们一起交流探讨。感谢你的阅读,我们下一讲再见。