你好,我是葛俊。今天,我来跟你聊聊研发过程中的Git代码分支管理和发布策略。
在前面两篇文章中,我们讨论了持续开发、持续集成和持续部署的整个上线流程。这条流水线针对的是分支,因此代码的分支管理便是基础。能否找到适合自己团队的分支管理策略,就是决定代码质量,以及发布顺畅的一个重要因素。
Facebook有几千名开发人员同时工作在一个大代码仓,每天会有一两千个代码提交入仓 ,但仍能顺利地进行开发,并发布高质量的产品。平心而论,Facebook的工程水平的确很高,与他们的分支管理息息相关。
所以在今天这篇文章中,我会先与你详细介绍Facebook的分支管理策略,以及背后的原因;然后,与你介绍其他的常见分支管理策略;最后,向你推荐如何选择适合自己的分支策略。
Facebook的分支管理策略,是一种基于主干的开发方式,也叫作Trunk-based。在这种方式中,用于开发的长期分支只有一个,而用于发布的分支可以有多个。
首先,我们先看看这个长期存在的开发分支。
这个长期存在的开发分支,一般被叫作trunk或者master。为方便讨论,我们统一称它为master。也就是说,所有的开发人员基于master分支进行开发,提交也直接push到这个分支上。
在主干开发方式下,根据是否允许存在短期的功能分支(Feature Branch),又分为两个子类别:主干开发有功能分支和主干开发无功能分支。Facebook做得比较纯粹,在主代码仓中,基本上禁止功能分支。
另外,在代码合并回master的时候,又有rebase和merge两种选择。Facebook选择的是rebase(关于这样选择的原因,我会在后面与你详细介绍)。所以,Facebook的整个开发模式非常简单,步骤大概如下。
第一步,获取最新代码。
git checkout master
git fetch
git rebase origin/master
第二步,本地开发,然后执行
git add
git commit
产生本地提交。
第三步,推送到主代码仓的master分支。
git fetch
git rebase origin/master
git push
在rebase的时候,如果有冲突就先解决冲突,然后使用
git add
git rebase --continue
更新自己的提交,最后重复步骤3,也就是重新尝试推送代码到主代码仓。
看到这里,你可能对这种简单的分支方式有以下两个问题。
问题1:如果功能比较大,一个代码提交不合适,怎么办?
解决办法:这种情况下,第二步本地开发的时候可以产生多个提交,最后在第三步一次性推送到主仓的master分支。
问题2:如果需要多人协同一个较大的功能,怎么办?
解决办法:这种情况下,Facebook采用的是使用代码原子性、功能开关、API版本等方法,让开发人员把功能拆小尽快合并到master分支。
比如,一个后端开发者和一个前端开发者合作一个功能,他们的互动涉及10个API接口,其中两个是在已有接口上做改动,另外8个是新增接口。
这两名开发者的合作方式是:
这就保证了,在不使用功能分支的情况下,这两个开发者可以直接在master分支上合作,并能够不被阻塞地尽快提交代码。当然了,这种合作方式,可以扩展到更多的开发者。
以上就是开发分支的情况。接下来,我再与你讲述发布分支和策略。
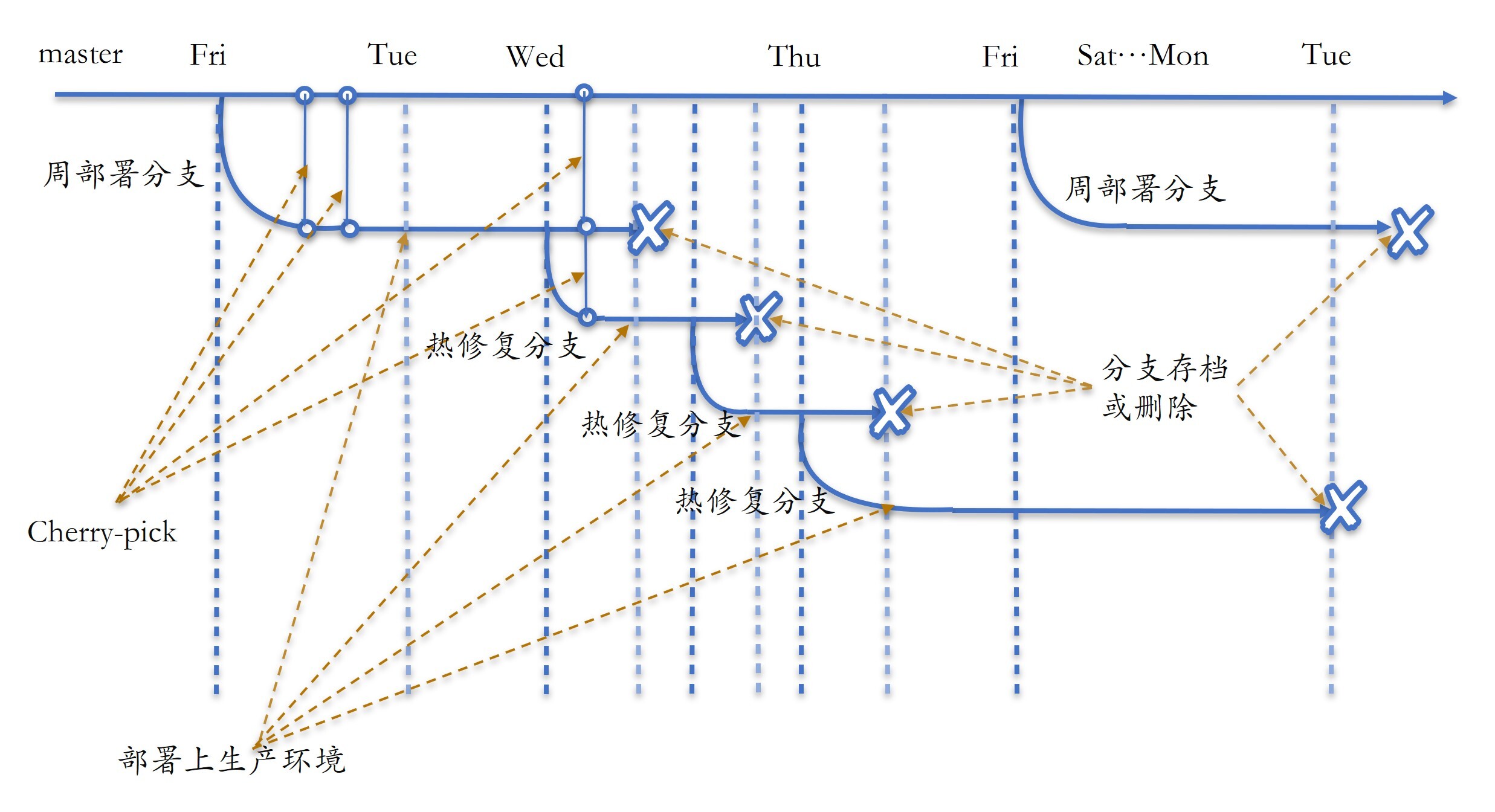
基于主干开发模式中,在需要发布的时候会从master拉出一条发布分支,进行测试、稳定。在发布分支发现问题后,先在master上修复,然后cherry-pick到发布分支上。分支上线之后,如果需要长期存在,比如产品线性质的产品,就保留。如果不需要长期存在,比如SaaS产品,就直接删除。Facebook采用的方式是后者。
具体来说,部署包括3种:有每周一次的全量代码部署、每天两次的日部署,以及每天不定次数的热修复部署。日部署和热修复部署类似,我们下面详细介绍周部署和热修复部署。
每次周部署代码的时候,流程如下所示。
第一步,从master上拉出一个发布分支。
git checkout -b release-date-* origin/master
第二步,在发布分支进行各种验证。
第三步,如果验证发现问题,开发者提交代码到master,然后用cherry-pick命令把修复合并到发布分支上:
git cherry-pick <fix-sha1> # fix-sha1 是修复提交的commit ID
接着继续回到第二步验证。
验证通过就发布当前分支。这个发布分支就成为当前生产线上运行版本对应的分支,我们称之为当前生产分支,同时将上一次发布时使用的生产分支存档或者删除。
在进行热修复部署时,从当前生产分支中拉出一个热修复分支,进行验证和修复。具体步骤为:
第一步,拉出一个热修复分支。
git checkout -b hotfix-date-* release-date-*
第二步,开发人员提交热修复到master,然后cherry-pick修复提交到热修复分支上。
git cherry-pick <fix-sha1>
第三步,进行各种验证。
第四步,验证中发现问题,回到第二步重新修复验证。验证通过就发布当前热修复分支,同时将这个热修复分支设置为当前的生产分支,后面如果有新的热修复,就从这个分支拉取。
这里有一张图片,描述了每周五拉取周部署分支,以及从周部署分支上拉取分支进行热修复部署的流程。
以上就是Facebook的代码分支管理和部署流程。
需要注意的是,这里描述的部署流程是Facebook转到持续部署之前采用的。但考虑到非常多的公司还没有达到持续部署的成熟度,所以这种持续交付的方式,对我们更有参考价值。
Facebook采用主干分支模式,最大的好处是可以把持续集成、持续交付做到极致,从而尽量提高master分支的代码质量。
解释这一好处之前,我想请你先看看下面这3个措施有什么共同效果:
其实,它们的共同效果就是:必须尽早将代码合入master分支,否则就需要花费相当长的时间去解决合并冲突。所以每个开发人员,都会尽量把代码进行原子性拆分,写好一部分就赶快合并入库。
我曾经有过一个有趣的经历。一天下午,我和旁边的同事在改动同一个API接口,实现两个不同的功能。我们关系很好,也都清楚对方在做什么,于是一边开玩笑一边像在比赛一样,看谁先写好代码完成自测入主库。结果是我赢了,他后来花了十分钟很小心地去解决冲突。
Facebook使用主干分支模式的好处,主要可以总结为以下两点:
比如,在一个代码仓中,有C000 ~ C120 的线性提交历史。我们知道一个测试在提交C100处都是通过的,但是在C120出了问题。我们可以依次checkout C101、C102,直到C120,每次checkout之后运行测试,总能找到第一个让测试失败的提交。
或者更进一步,我们可以先尝试C100和C120中间的提交C110。如果测试在那里通过了,证明问题提交在C111和C120之间,继续检查C115;否则就证明问题提交在C101和C110之间,继续检查C105。这就大大减少了检查次数。而这,正是软件算法中经典的折半查找。
事实上,Git本身就提供了一个命令git bisect支持折半查找。比如,在刚才的例子中,如果运行测试的命令行是 runtest.sh。那么,我们可以使用下面的命令来自动化这个定位流程:
> git checkout master # 使用最新提交的代码
> git bisect start
> git bisect bad HEAD # 告知 git bisect,当前commit是有问题的提交
> git bisect good C100 # 告知 git bisect,C100是没有问题的提交
> git bisect run bash runtest.sh # 开始运行自动化折半查找
...
Cxxx is the first bad commit # 查找到第一个问题提交
...
bisect run success
> git bisect reset # 结束git bisect。回到初始的HEAD
很方便吧。而如果历史不是线性的,也就是说如果提交使用了merge,那么我们就不能方便地定位出第一个问题提交了,更别说是折半查找了。
这种快速定位问题的能力,可以给CI/CD带来巨大好处。在持续交付过程中,我们常常没有足够的资源对每一个提交都进行检查。比如前面提过,Facebook的持续交付流水线就是每隔一段时间,对代码仓最后一个提交运行流水线的检查。如果发现问题,就可以通过上面这种方法自动化地找到问题提交,并自动产生Bug工单,分配给提交者。
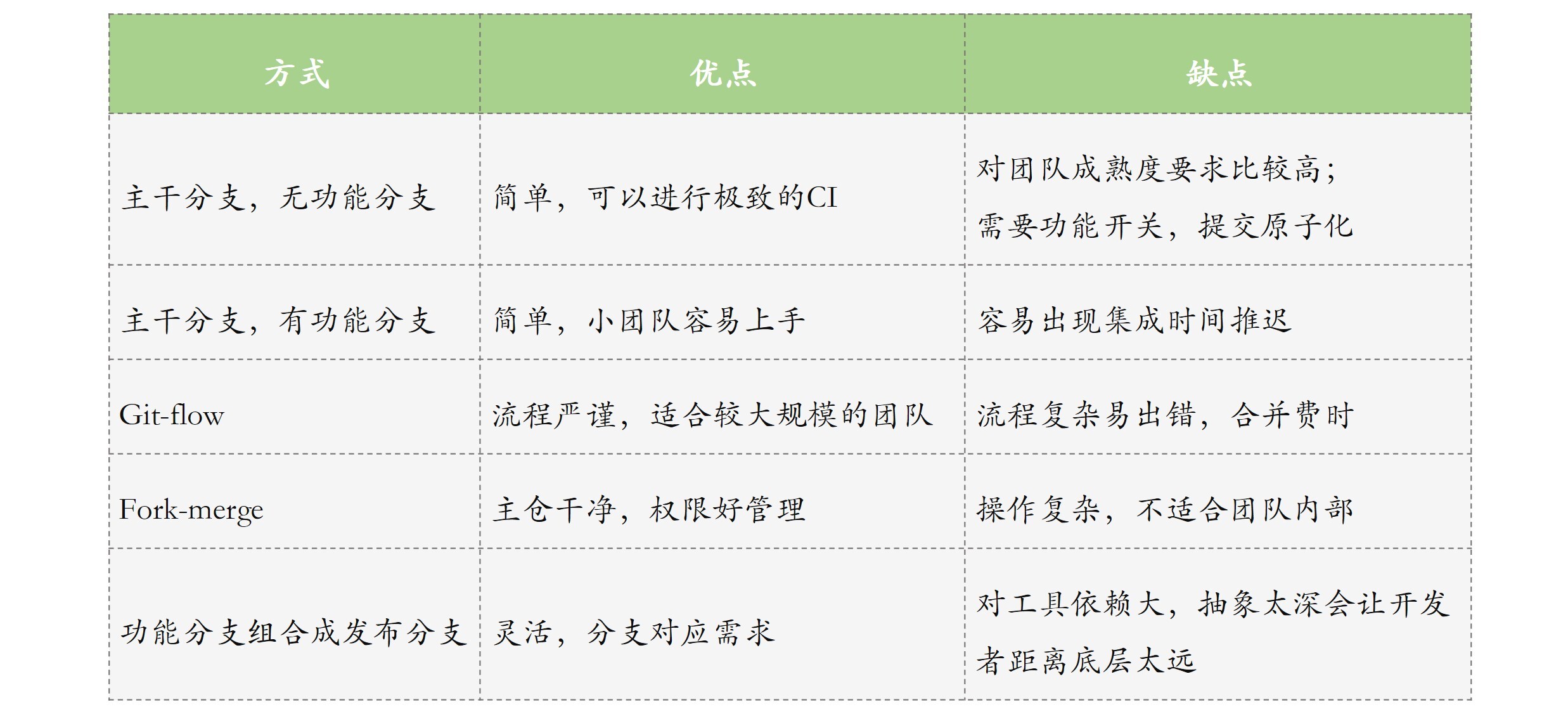
除了主干开发的分支管理策略,还有3种常用方式:
我在文中给出了链接供你参考。接下来,我们具体看看这几种方式。
Git-flow工作流有两个长期分支:一个是master,包含可以部署到生产环境的代码;另一个是develop,是一个用来集成代码的分支,开发新功能、新发布,都从develop里拉分支。此外,它还有3种短期分支,分别是新功能分支、发布分支、热修复分支,根据需要创建,当完成了自己的任务后就会被删除。
Git-flow工作流的特点是规定很清晰,对各种开发任务都有明确的规定和步骤。比如:
这种工作流,在前几年非常流行。它的好处是流程清晰,但缺点是:
Fork-merge是在GitHub、GitLab流行之后产生的,具体做法是:每个开发人员在代码仓服务器上有一个“个人”代码仓。这个“个人”代码仓实际上就是主代码仓的一个clone。开发者对主代码仓贡献代码的步骤如下:
看起来步骤繁琐,但实际上和主干开发方式很相似,也有一个长期的开发分支,就是主仓的master分支。不同之处在于,它提供了一种对主分支更严格、更方便的权限管理方式,即只有主仓管理者有权限推送代码。同时,主仓不需要有功能分支,功能分支可以存在fork仓中。所以,主仓干净便于管理。
这种方式对开源项目比较方便,但缺点是步骤繁琐,不太适用于公司内部。
除了上述方式之外,还有一种非常灵活,但对工具自动化要求很高的分支方式,即基于功能分支灵活产生发布分支的方式。这种方式的典型代表是阿里云效的“分支模式”。
具体方法是大量使用工具对分支的管理进行自动化,开发人员在web界面上自助产生针对功能的分支。编码完成后,通过web界面对分支组合、验证,并上线,上线之后分支再自动合入主库。
这种方式的好处是:
但这种方式的问题是,对工具的依赖比较高,没有一个系统的工具来自动化的话,基本做不起来。另外,这种方式会大量封装底层的实现,使开发人员不知道底层发生的问题,一旦出现问题就不太容易解决。
要找到适合自己团队的分支管理策略,我们先来对比下上面提到的几种方式的优缺点吧。
另外,要找到合适的代码分支管理策略,你还可以参考以下3个问题,根据答案帮助你进行选择。
问题1:如果提供功能分支让成员共享,在哪里建立这个分支?
如果团队不大,可以允许在主仓创建功能分支,不过注意定时删除不用的分支,避免影响Git的性能。如果团队比较大,可以考虑使用Fork-merge方式,在上面提到的“个人代码仓”里创建功能分支,从而避免污染主仓。
问题2:要不要使用Merge Commit?
代码在合并到主干的时候,可以选择rebase或者merge。使用rebase的好处是上边提到的方便定位问题。而使用merge的好处是,可以清晰地在分支里看到一个功能的所有提交,不像在rebase中,一个功能的提交往往是分散的。
问题3:团队成熟度如何?
单分支开发集成早,质量比较好,但对团队成员和流程自动化要求高。所以,如果你的团队比较小,或者比较成熟的话,可以考虑使用单分支,否则可以选择多分支开发模式,但要想办法把集成提前,同时逐步向单主干分支过渡。
总结来说,尽量减少长期分支的数量,代码尽早合并回主仓,方便使用CI/CD等方法保证主仓代码提交的质量,是选择分支策略的基本出发点。
首先,我分享了Facebook使用的单主干开发分支,以及通过临时发布分支进行部署的分支管理策略和部署方式。然后,我与你介绍了几种常见的分支管理策略,并给出了推荐的选择方法。
在Facebook工作时,我们一直使用这种主干分支开发方式。它强迫我们把代码进行原子化,尽量确保每一个提交都尽快合入master,并保证代码质量。一开始我不是很习惯,但习惯后我发现它的确很棒。
首先,因为你和你的合作开发者都需要尽快把代码拆小、入仓,这就帮助我们提高了功能模块化的能力。其次,因为master里面的提交一般都比较健康,并且是比较新的代码,所以很少会被不稳定的因素阻塞。最后,线性提交历史对开发者的日常工作也很有帮助。我们在开发的时候,常常会碰到一个本来工作得好好的API,在拉取到最新代码之后出现了问题。这时,我就可以使用这种方法找到第一个造成问题的提交,从而方便定位和解决问题。
一个流程设计、实施得好,对产品来说可以提高质量,对团队来说可以提高效能,对个人来说可以帮助成长。这就是一举三得。
感谢你的收听,欢迎你在评论区给我留言分享你的观点,也欢迎你把这篇文章分享给更多的朋友一起阅读。我们下期再见!
评论