你好,我是海纳。
上节课,我们讲到,栈被操作系统安排在进程的高地址处,它是向下增长的。但这只是对栈相关知识的“浅尝辄止”。那我们今天这节课,就会跟着前面的脉络,让你可以更深刻地理解栈的运行原理。
栈是每一个程序员都很熟悉的话题,但你敢说你真的完全了解它吗?我相信,你在工作中肯定遇到过栈溢出(StackOverflow)的错误,比如在写递归函数的时候,当漏掉退出条件,或者退出条件不小心写错了,就会出现栈溢出错误。我们也经常听说缓冲区溢出带来的严重的安全问题,这在日常的工作中都是要避免的。
所以,今天这节课,我们继续深入探讨一下栈这个话题,我会带你基于“符合人的直观思维”,也就是函数的层面和CPU的机器指令层面,多角度来理解栈相关的概念。这样,你以后遇到与栈相关的问题的时候,才知道如何着手进行排查。最后,我们还会通过一个缓冲区溢出攻击栈的案例,看看我们在日常工作中如何提升代码的健壮度和安全性。
当我们在调用一个函数的时候,CPU会在栈空间(这当然是线性空间的一部分)里开辟一小块区域,这个函数的局部变量都在这一小块区域里存活。当函数调用结束的时候,这一小块区域里的局部变量就会被回收。
这一小块区域很像一个框子,所以大家就命名它为stack frame。frame本意是框子的意思,在翻译的时候被译为帧,现在它的中文名字就是栈帧了。
所以,我们可以说,栈帧本质上是一个函数的活动记录。当某个函数正在执行时,它的活动记录就会存在,当函数执行结束时,活动记录也被销毁。
不过,你要注意的是,在一个函数执行的时候,它可以调用其他函数,这个时候它的栈帧还是存在的。例如,A函数调用B函数,此时A的栈帧不会被销毁,而是会在A栈帧的下方,再去创建B函数的栈帧。只有当B函数执行完了,B的栈帧也被销毁了,CPU才会回到A的栈帧里继续执行。
我们举个例子说明一下,就很好理解了。你可以看一下这个代码:
#include <stdio.h>
void swap(int a, int b) {
int t = a;
a = b;
b = t;
}
void main() {
int a = 2;
int b = 3;
swap(a, b);
printf("a is %d, b is %d\n", a, b);
}
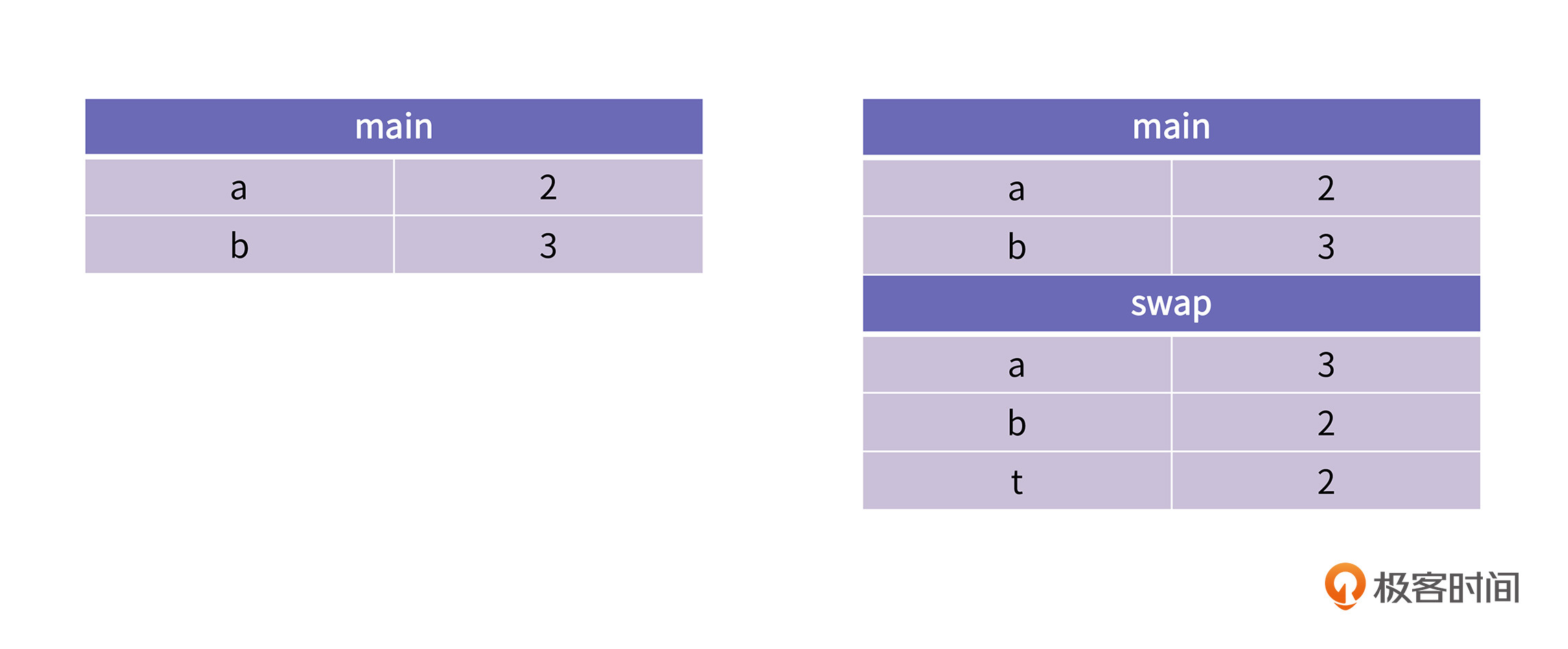
你可以看到,在swap函数中,a和b的值做了一次交换,但是在main函数里,打印a和b的值,a还是2,b还是3。这是为什么呢?从栈帧的角度,这个问题就非常容易理解:
在main函数执行的时候,main的栈帧里存在变量a和b。当main在调用swap方法的时候,会在main的帧下面新建swap的栈帧。swap的帧里也有局部变量a和b,但是明显这个a、b与main函数里的a、b没有任何关系,不管对swap的帧里的a/b变量做任何操作都不会影响main函数的栈帧。
接下来,我们再通过一个递归的例子来加深对栈的理解。由于递归执行的过程会出现函数自己调用自己的情况,也就是说,一个函数会对应多个同时活跃的记录(即栈帧)。所以,理解了递归函数的执行过程,我们就能更加深刻地理解栈帧与函数的关系。
我们先看一下最经典的递归问题:汉诺塔。汉诺塔问题是这样描述的:有三根柱子,记为A、B、C,其中A柱子上有n个盘子,从上到下的编号依次为1到n,且上面的盘子一定比下面的盘子小。要求一次只能移动一只盘子,且大的盘子不能压在小的盘子上,那么将所有盘子从A移到C总共需要多少步?
这道题的详细分析过程是一种递归推导的过程,不是我们这节课的重点,如果你对解法感兴趣的话,可以自己查找相关资料。我们这里,重点来讲解递归程序执行的过程中,栈是怎么样变化的,这样可以帮助我们理解栈的基本工作原理。
你先看一下汉诺塔问题的求解程序:
#include <stdio.h>
void move(char src, char dst, int n) {
printf("move plate %d form %c to %c\n", n, src, dst);
}
void hanoi(char src, char dst, char aux, int n) {
if (n == 1) {
move(src, dst, 1);
return;
}
hanoi(src, aux, dst, n-1);
move(src, dst, n);
hanoi(aux, dst, src, n-1);
}
int main() {
hanoi('A', 'C', 'B', 5);
}
这段代码可以打印出借由B柱子将5个盘子从A搬移到C的所有步骤。这个的核心是hanoi函数,在深入分析代码的执行过程之前,我们可以先从符合直观思维的角度尝试理解hanoi函数。
hanoi函数有四个参数。第一个src代表要搬的起始柱子(开始时是A),第二个代表目标柱子(开始时是C),第三个代表可以借用的中间的那个柱子(开始时是B),第四个参数代表一共要搬的盘子总数(开始时是5)。
代码的第13行的意义是,如果要从A搬5个盘子到C,可以先将4个盘子搬到B上,然后第14行代表将第5个盘子从A搬到C,第15行代表把B上面的4个盘子搬到C上去。第8行的判断是说当只搬一个盘子的时候,就可以直接调用move方法。
以上就是递归程序的设计思路。下面我们再具体分析这个代码的执行过程。为了简便起见,我们选择n=3进行分析。
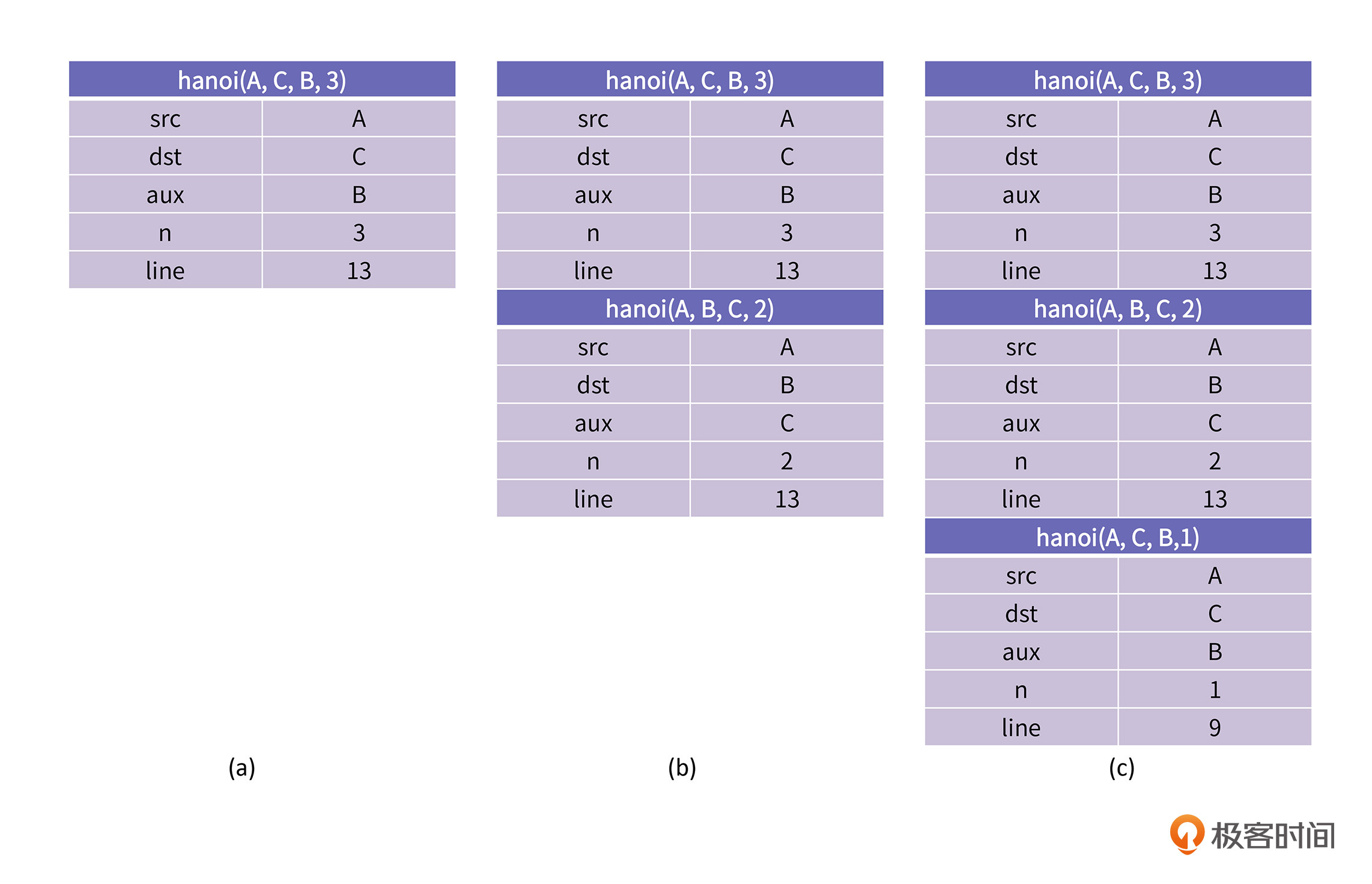
可以看到,当程序在执行hanoi(A, C, B, 3)时,CPU会为其创建一个栈帧,这一帧里记录着变量src、dst、aux和n。
此时n为3,所以,代码可以执行到第13行,然后就会调用执行hanoi(A, B, C, 2)。这代表着将2个盘子从A搬到B,同样CPU也会为这次调用创建一个栈帧;当这一次调用执行到第13行时,会再调用执行hanoi(A, C, B, 1),代表把一个盘子从A搬到C。不过,由于这一次调用n为1,所以会直接调用move函数,打印第一个步骤“把盘子1从A搬到C”。
接下来,程序就会回到hanoi(A, B, C, 2)的栈帧,继续执行第14行,打印第二个步骤”把盘子2从A搬到B”。然后再执行第15行,也就是执行hanoi(C, B, A, 1)。这一步的栈帧变化,你可以看下面这张图。
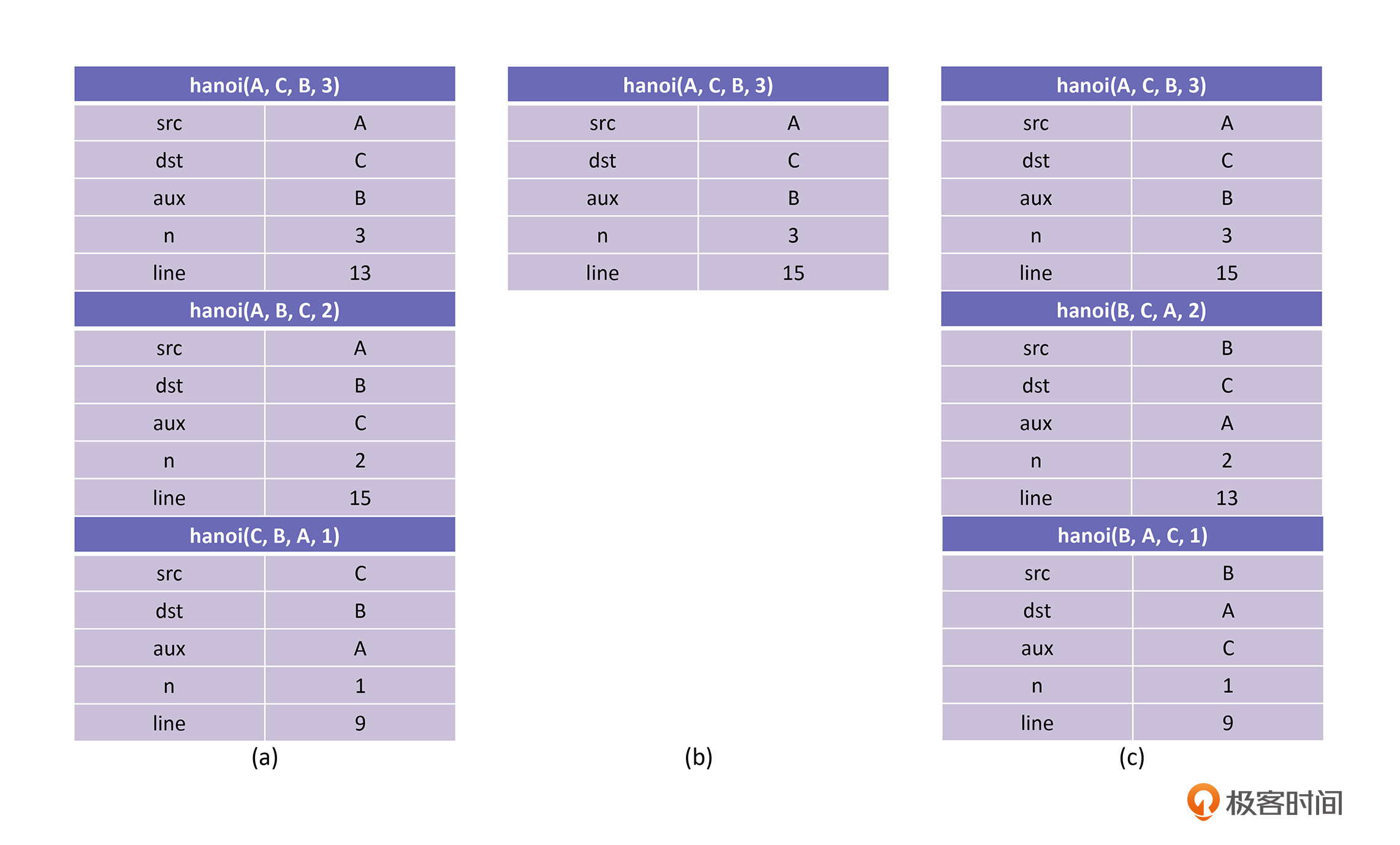
我们看到,在调用hanoi(C, B, A, 1)的时候,由于n等于1,所以就会打印第三个步骤“把盘子1从C搬到B”,此时hanoi(C, B, A, 1)就执行完了。
那么接下来,程序就退回到hanoi(A, B, C, 2)的第15行的下一行继续执行,也就是函数的结束,这就意味着hanoi(A, B, C, 2)也执行完了。这个时候,程序就会回退到最高的一层hanoi(A, C, B, 3)的第14行继续执行。这一次就打印了第四个步骤“把盘子3从A搬到C”,此时的栈帧如上图(b)所示。
然后,程序会执行第15行,再次进入递归调用,创建hanoi(B, C, A, 2)的栈帧。当它执行到第13行时,就会再创建hanoi(B, A, C, 1)的栈帧,此时栈的结构如上图(c)所示。由于n等于1,这一次调用就会打印第五个步骤“把盘子1从B搬到A”。
再接着就开始退栈了,回到hanoi(B, C, A, 2)的栈帧,继续执行第14行,打印第六个步骤“把盘子2从B搬到C”。然后执行第15行,也就是hanoi(A, C, B, 1),此时n等于1,直接打印第七个步骤“把盘子1从A搬到C”。接下来就执行退栈,这一次每一个栈帧都执行到了最后一行,所以会一直退到main函数的栈帧中去。退栈的过程比较简单,你自己思考一下就好了。
这样我们就完成了一次汉诺塔的求解过程。在这个过程中呢,我们观察到,先创建的帧最后才销毁,后创建的帧最先被销毁,这就是先入后出的规律,也是程序执行时的活跃记录要被叫做栈的原因。
那么在这里呢,我还想让你做一个小练习。我想让你试着用我们上面分析栈变化的方法,来分析使用深度优先算法打印全排列的程序,这会让你更加深入地理解栈的运行规律,同时掌握深度优先算法的递归写法。
res = []
def make(n, level):
if n == level:
print(res)
return
for i in range(1, n+1):
if i not in res:
res.append(i)
make(n, level+1)
res.pop()
make(3, 0)
好了,前面递归的例子,是从人的直观思维的角度去理解栈,但是在CPU层面,机器指令又是怎样去理解栈的呢?我们还是通过一个例子来考察一下:
int fac(int n) {
return n == 1 ? 1 : n * fac(n-1);
}
这是一个使用递归的写法求阶乘的例子,源码是比较简单的,我们可以使用gcc对其进行编译,然后使用objdump对其反编译,观察它编译后的机器码。
# gcc -o fac fac.c
# objdump -d fac
然后你可以得到以下输出:
40052d: 55 push %rbp
40052e: 48 89 e5 mov %rsp,%rbp
400531: 48 83 ec 10 sub $0x10,%rsp
400535: 89 7d fc mov %edi,-0x4(%rbp)
400538: 83 7d fc 01 cmpl $0x1,-0x4(%rbp)
40053c: 74 13 je 400551 <fac+0x24>
40053e: 8b 45 fc mov -0x4(%rbp),%eax
400541: 83 e8 01 sub $0x1,%eax
400544: 89 c7 mov %eax,%edi
400546: e8 e2 ff ff ff callq 40052d <fac>
40054b: 0f af 45 fc imul -0x4(%rbp),%eax
40054f: eb 05 jmp 400556 <fac+0x29>
400551: b8 01 00 00 00 mov $0x1,%eax
400556: c9 leaveq
400557: c3 retq
我们来分析一下这段汇编代码。
第1行是将当前栈基址指针存到栈顶,第2行是把栈指针保存到栈基址寄存器,这两行的作用是把当前函数的栈帧创建在调用者的栈帧之下。保存调用者的栈基址是为了在return时可以恢复这个寄存器。
第3行的作用呢,是把栈向下增长0x10,这是为了给局部变量预留空间。从这里,你可以看出来运行fac函数要是消耗栈空间的。
试想一下,如果我们不加n==1的判断,那么fac函数将无法正常返回,会出现一直递归调用回不来的情况,这样栈上就会出现很多fac的帧栈,会造成栈空间耗尽,出现StackOverflow。这里的原理是,操作系统会在栈空间的尾部设置一个禁止读写的页,一旦栈增长到尾部,操作系统就可以通过中断探知程序在访问栈末端。
第4行是把变量n存到栈上。其中变量n一开始是存储在寄存器edi中的,存储的目标地址是栈基址加上0x4的位置,也就是这个函数栈帧的第一个局部变量的位置。变量n在寄存器edi中是X86的ABI决定的,第一个整型参数一定要使用edi来传递。
第5行将变量n与常量0x1进行比较。在第6行,如果比较的结果是相等的,那么程序就会跳转到0x400551位置继续执行。我们看到,在这块代码里,0x400551是第13行,它把0x1送到寄存器eax中,然后返回,就是说当n==1时,返回值为1。
如果第5行的比较结果是不相等的,又会怎么办呢?那第6行就不会跳转,而是继续执行第7行。7、8、9这三行的作用,就是把n-1送到edi寄存器中,也就是说以n-1为参数调用fac函数。这个时候,调用的返回值在eax中,第11行会把返回值与变量n相乘,结果仍然存储在eax中。然后程序就可以跳转到0x400556处结束这次调用。
理解了fac函数的汇编指令以后,我们再重点讨论callq指令。
执行callq指令时,CPU会把rip寄存器中的内容,也就是call的下一条指令的地址放到栈上(在这个例子中就是0x40054b),然后跳转到目标函数处执行。当目标函数执行完成后,会执行ret指令,这个指令会从栈上找到刚才存的那条指令,然后继续恢复执行。
栈空间中的rbp、rsp,以及返回时所用的指令都是非常敏感的数据,一旦被破坏就会造成不可估量的损失。
不过,你在重现这个例子一定要注意,我们使用不同的优化等级,产生的汇编代码也是不同的。比如如果你用以下命令进行编译,得到的二进制文件中将不再使用rbp寄存器。
# gcc -O1 -o fac fac.c
至于这个结果,我这里就不再展示了,我想让你自己动手试一下,然后在留言区和我们分享。
到这里,我们已经从人的大脑的理解角度和机器指令的角度,让你加深了对栈和栈帧的理解。现在,我们就从理论转向实操,举一个通过缓冲区溢出来破坏栈的例子。通过这个例子,你就知道在平时的工作中,应该如何避免写出被黑客攻击的不安全代码。
下面这个测试是我精心构造的例子。因为是演示用的,所以我就把各种无关的代码去掉了,只保留了关键路径上的代码。你先看一下代码:
#include <stdio.h>
#include <stdlib.h>
#define BUFFER_LEN 24
void bad() {
printf("Haha, I am hacked.\n");
exit(1);
}
void copy(char* dst, char* src, int n) {
int i;
for (i = 0; i < n; i++) {
dst[i] = src[i];
}
}
void test(char* t, int n) {
char s[16];
copy(s, t, n);
}
int main() {
char t[BUFFER_LEN] = {
'w', 'o', 'l', 'd',
'a', 'b', 'a', 'b', 'a', 'b',
'a', 'b', 'a', 'b', 'a', 'b',
};
int n = BUFFER_LEN - 8;
int i = 0;
for (; i < 8; i++) {
t[n+i] = (char)((((long)(&bad)) >> (i*8)) & 0xff);
}
test(t, BUFFER_LEN);
printf("hello\n");
}
你可以用gcc编译器来编译上面这个程序:
gcc -O1 -o bad bad.c -g -fno-stack-protector
执行它,你可以看到,虽然在main函数里我们并没有调用bad函数,但它却执行了。最后运行结果是“Haha, I am hacked”。
我们首先来分析一下,这个程序为什么会有这样的运行结果。
当我们在调用test函数的时候,会把返回地址,也就是rip寄存器中的值,放到栈上,然后就进入了test的栈帧,CPU接着就开始执行test函数了。
test函数在执行时,会先在自己的栈帧里创建数组s,数组s的长度是16。此时,栈上的布局是这样的:
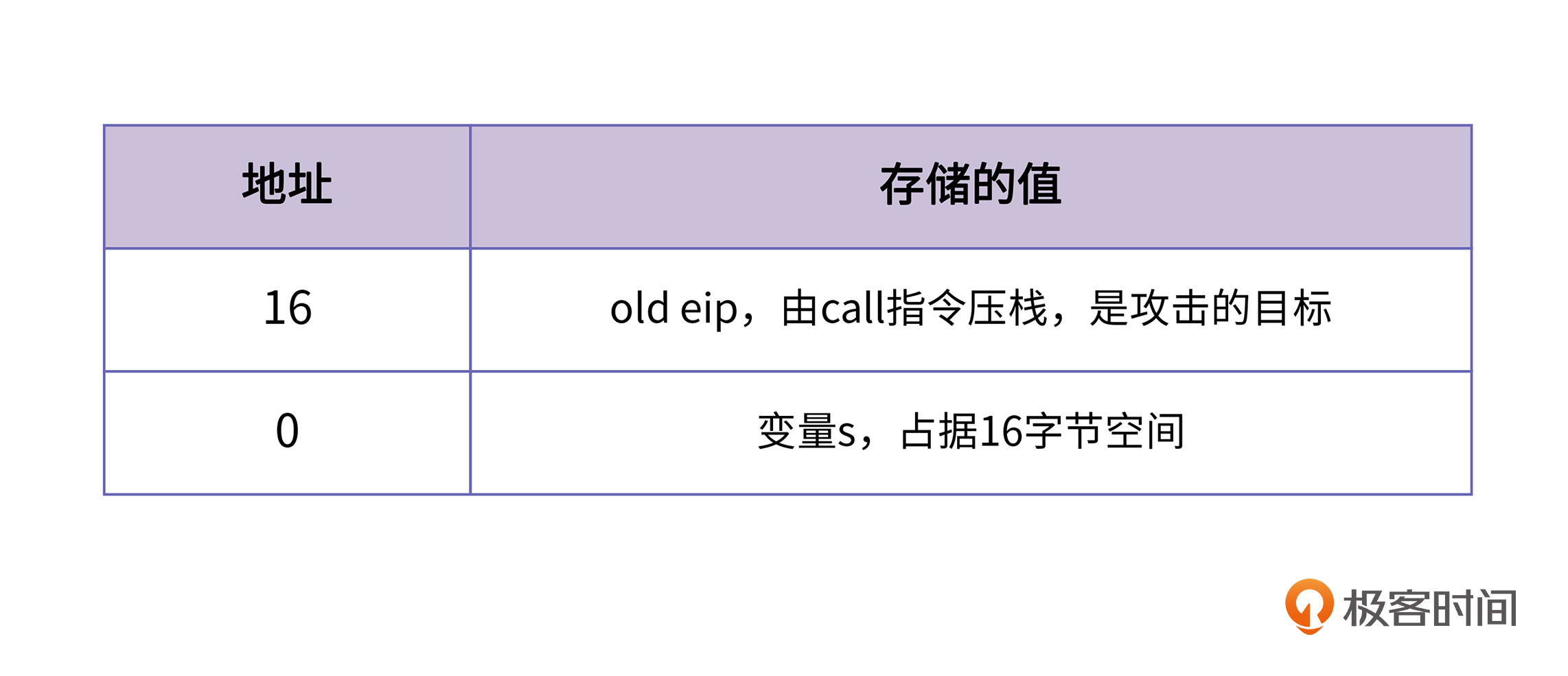
通过计算,我们可以知道返回地址是变量s的地址 + 16的地方,这就是我们要攻击的目标。我们只要在这个地方把原来的地址替换为函数bad的入口地址(第26至34行所做的事情),就可以改变程序的执行顺序,实现了一次缓冲区溢出。
简单地说,数组s的长度是16,理论上我们只能修改以s的地址开始、长度为16的数据。但是我们现在通过copy函数操作了大于16的数据,从而破坏了栈上的关键数据。也就是说我们针对函数调用的返回地址发起了一次攻击。所以,test函数的实现是不安全的。
其实这种缓冲区溢出,就是指通过一定的手段,来达成修改不属于本函数栈帧的变量的目的,而这种手段多是通过往字符串变量或者数组中写入错误的值而造成的。
有两种常见的手段可以对这一类攻击进行防御。
第一,对入参进行检查,尽量使用strncpy来代替strcpy。因为strcpy不对参数长度做限制,而strncpy则会做检查。比如上述例子中,如果我们对参数n做检查,要求它的值必须大于0且小于缓冲区长度,就可以阻击缓冲区溢出攻击了。
第二,可以使用gcc自带的栈保护机制,这就是-fstack-protector选项。你查gcc手册(在Linux系统使用“man gcc”就能查到)可以看到它的一些相关信息。
当-fstack-protector启用时,当其检测到缓冲区溢出时(例如,缓冲区溢出攻击)时会立即终止正在执行的程序,并提示其检测到缓冲区存在的溢出的问题。这种机制是通过在函数中的易被受到攻击的目标上下文添加保护变量来完成的。这些函数包括使用了alloca函数以及缓冲区大小超过8bytes的函数。这些保护变量在进入函数的时候进行初始化,当函数退出时进行检测,如果某些变量检测失败,那么会打印出错误提示信息并且终止当前的进程。
从4.8版本开始,gcc中的这个选项是默认打开的。如果我们在编译时,不加-fno-stack-protector,gcc就会给可执行程序增加栈保护的功能。这样的话,运行结果就会出现Segment Fault,导致进程崩溃。不过,你要知道,在遇到攻击时自己崩溃,相比起去执行攻击者的恶意代码,影响可就小多了。
这里,我们为了演示的方便,使用-fno-stack-protector关闭了这个选项。不过,在日常开发中,这个选项虽然使得栈的安全大大加强了,但它也有巨大的性能损耗。在一个实际的线上例子中,关闭这个选项可以提升8%至10%的性能。
当然这个选项也不是万能的,攻击者依然能通过精心构造数据来达成它的目标。所以在写代码的时候,你还是应该对缓冲区安全多加注意。
这节课,我们一起学习了栈帧的作用,并通过汉诺塔程序的求解过程,来分析了栈帧的创建和销毁的过程,以此揭示了函数和栈帧的关系。栈帧就是函数的活动记录,当函数被调用时,栈帧创建,当函数调用结束后,栈帧消失。
在程序的执行过程中,尤其是递归程序的执行过程中,你可以清楚地观察到栈帧的创建销毁,满足后入先出的规律。这也是人们把管理函数的活跃记录的区域称为栈的原因。
除了用人的直观思维来理解栈帧之外,我还带你看了在汇编代码级别,栈帧是怎么真实地被创建和销毁的,或者说栈是怎么增长和收缩的。这会进一步加深你对栈的理解。
这节课的最后,我也通过一个缓冲区溢出的例子说明了,在栈空间内使用缓冲区的时候,你必须要十分小心,要避免恶意的输入对缓冲区进行越界读写,破坏栈的结构,从而导致关键数据被修改。我们演示了一个破坏了调用者返回地址的例子,以此来说明当返回地址被破坏以后,攻击者可以让程序的控制流转向我们不希望的地方。
很多人以为安全和攻击是做安全的同事才应该关心的问题,这个想法是不对的。要想提高软件的整体水平,每一个程序员都应该写出健壮而安全的代码。只有每一块砖都足够坚固,我们才有可能建成一个安全可靠的建筑物。
我们这节课前面讲的swap函数的例子,是很多新手会犯的错误。在C语言中,为了使swap可以交换main函数里的a/b两个变量的值,我们可以使用指针:
#include <stdio.h>
void swap(int* a, int* b) {
int t = *a;
*a = *b;
*b = t;
}
void main() {
int a = 2;
int b = 3;
swap(&a, &b);
printf("a is %d, b is %d\n", a, b);
}
或者在C++中,直接使用引用,引用可以看成是一个能自动解引用的指针:
#include <stdio.h>
void swap(int& a, int& b) {
int t = a;
a = b;
b = t;
}
void main() {
int a = 2;
int b = 3;
swap(a, b);
printf("a is %d, b is %d\n", a, b);
}
那么,我想请你从汇编代码层面思考,这是怎么做到的?(提示:要从“传入栈帧的参数到底是什么”这个角度去思考)另外,如果你对Java程序比较熟悉,你也可以思考一下Java能不能实现类似的功能?欢迎你在留言区和我交流你的想法,我在留言区等你。

好,这节课到这就结束啦。欢迎你把这节课分享给更多对计算机内存感兴趣的朋友。我是海纳,我们下节课再见!
评论