你好,我是海纳。
上一节课,我们学习了MESI协议,我们了解到,MESI协议能够解决多核 CPU体系中,多个CPU之间缓存数据不一致的问题。但是,如果CPU严格按照MESI协议进行核间通讯和同步,核间同步就会给CPU带来性能问题。既要遵守协议,又要提升性能,这就对CPU的设计人员提出了巨大的挑战。
那严格遵守MESI协议的CPU会有什么样的性能问题呢?我们又可以怎么来解决这些问题呢?今天我们就来仔细分析一下。搞清楚了这些问题,你会对C++内存模型和Java内存模型有更加深入的理解,在分析并发问题时能够做到有的放矢。
我们上节课说过,MESI代表的是Modified、Exclusive、Shared、Invalid这四种缓存状态,遵守MESI协议的CPU缓存会在这四种状态之间相互切换。这种CPU缓存之间的关系是这样的:
从上面这张图你可以看到,Cache和主内存(Memory)是直接相连的。一个CPU的所有写操作都会按照真实的执行顺序同步到主存和其他CPU的cache中。
严格遵守MESI协议的CPU设计,在它的某一个核在写一块缓存时,它需要通知所有的同伴:我要写这块缓存了,如果你们谁有这块缓存的副本,请把它置成Invalid状态。Invalid状态意味着该缓存失效,如果其他CPU再访问这一缓存区时,就会从主存中加载正确的值。
发起写请求的CPU中的缓存状态可能是Exclusive、Modified和Share,每个状态下的处理是不一样的。
如果缓存状态是Exclusive和Modified,那么CPU一个核修改缓存时不需要通知其他核,这是比较容易的。
但是在Share状态下,如果一个核想独占缓存进行修改,就需要先给所有Share状态的同伴发出Invalid消息,等所有同伴确认并回复它“Invalid acknowledgement”以后,它才能把这块缓存的状态更改为Modified,这是保持多核信息同步的必然要求。
这个过程相对于直接在核内缓存里修改缓存内容,非常漫长。这也就会导致,某个核请求独占时间比较长。
那怎么来解决这个问题呢?
CPU的设计者为每个核都添加了一个名为store buffer的结构,store buffer是硬件实现的缓冲区,它的读写速度比缓存的速度更快,所有面向缓存的写操作都会先经过store buffer。
不过,由于中文材料中经常将cache和buffer都翻译成缓冲,或者缓存,很容易混淆概念,所以在这里,我想强调一下cache和buffer的区别。
cache这个词,往往意味着它所存储的信息是副本。cache中的数据即使丢失了,也可以从内存中找到原始数据(不考虑脏数据的情况),cache存在的意义是加速查找。
但是buffer更像是蓄水池,你可以理解成它是一个收作业的课代表,课代表会把所有同学的作业都收集齐以后再一次性地交到老师那里。buffer中的数据没有副本,一旦丢失就彻底丢失了。store buffer也是同样的道理,它会收集多次写操作,然后在合适的时机进行提交。
增加了store buffer以后的CPU缓存结构是这样的:
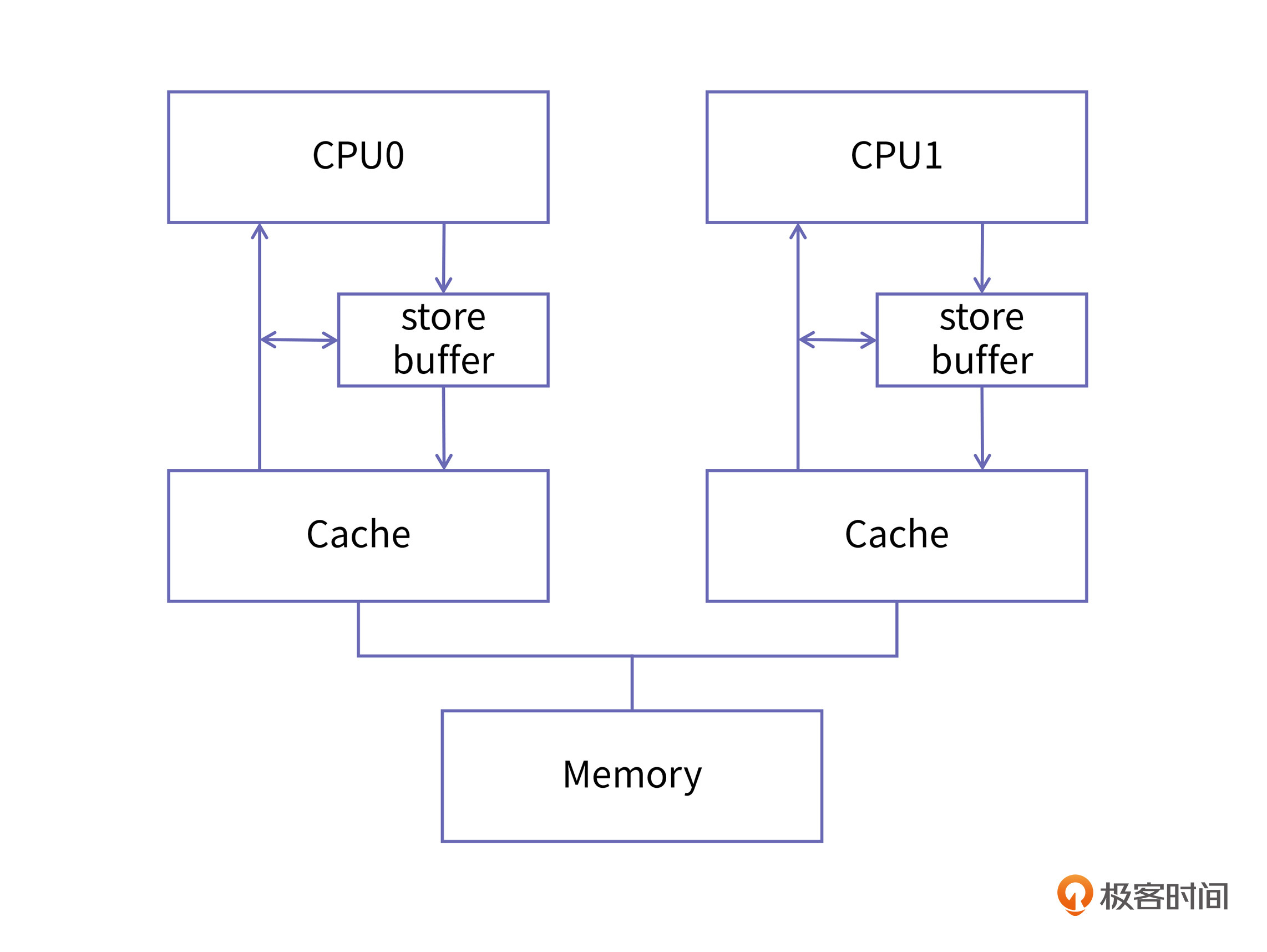
在这样的结构里,如果CPU的某个核再要对一个变量进行赋值,它就不必等到所有的同伴都确认完,而是直接把新的值放入store buffer,然后再由store buffer慢慢地去做核间同步,并且将新的值刷入到cache中去就好了。而且,每个核的store buffer都是私有的,其他核不可见。
为了让你更好理解核间同步的问题,我们现在来举个例子。我们使用两个CPU,分别叫做CPU0和CPU1,其中CPU0负责写数据,而CPU1负责读数据,我们看看在增加了store buffer这个结构以后,它们在进行核间同步时会遇到什么问题。
假如CPU0刚刚更新了变量a的值,并且将它放到了store buffer中,CPU0自己接着又要读取a的值,此时,它会在自己的store buffer中读到正确的值。
那如果在这一次修改的a值被写入cache之前,CPU0又一次对a值进行了修改呢?那也没问题,这次更新就可以直接写入store buffer。因为store buffer是CPU0私有的,修改它不涉及任何核间同步和缓存一致性问题,所以效率也得到了比较大的提升。
但用store buffer也会有一个问题,那就是它并不能保证变量写入缓存和主存的顺序,你先来看看下面这个代码:
// CPU0
void foo() {
a = 1;
b = 1;
}
// CPU1
void bar() {
while (b == 0) continue;
assert(a == 1);
}
你可以看到,在这个代码块中,CPU0执行foo函数,CPU1执行bar函数。但在对变量a和b进行赋值的时候,有两种情况会导致它们的赋值顺序被打乱。
第一种情况是CPU的乱序执行。在Cache的基本原理一课中,我们已经讲过CPU为了提升运行效率和提高缓存命中率,采用了乱序执行。
第二种情况是store buffer在写入时,有可能b所对应的缓存行会先于a所对应的缓存行进入独占状态,也就是说b会先写入缓存。
这种情况完全是有可能的。你想,如果a是Share状态,b是Exclusive状态,那么尽管CPU0在执行时没有乱序,这两个变量由store buffer写入缓存时也是不能保证顺序的。
那这个时候,我们假设CPU1开始执行时,a和b所对应的缓存行都是Invalid状态。当CPU1开始执行第9行的时候,由于b所对应的缓存区域是Invalid状态,它就会向总线发出BusRd请求,那么CPU1就会先把b的最新值读到本地,完成变量b的值的更新,从而跳出第9行的循环,继续执行第10行。
这时,CPU1的a缓存区域也处于Invalid状态,它也会产生BusRd请求,但我们前面分析过,CPU0中对a的赋值可能会晚于b,所以此时CPU1在读取变量a的值时,加载的就可能是老的值,也就是0,那这个时候第10行的assert就会执行失败。
我们再举一个更极端的例子分析一下:
// CPU0
void foo() {
a = 1;
b = a;
}
这个例子中,b和a之间因为有数据依赖,是不可能乱序执行的,这就意味着上面我们分析的情况一是不会发生的。但由于store buffer的存在,情况二仍然可能发生,其结果就像我们上面分析的那样,CPU执行第10行时会失败。这会让人感到更加匪夷所思。
为了解决这个问题,CPU设计者就引入了内存屏障,屏障的作用是前边的读写操作未完成的情况下,后面的读写操作不能发生。这就是Arm上dmb指令的由来,它是数据内存屏障(Data Memory Barrier)的缩写。
我们还是继续沿用前面CPU0和CPU1的例子,不过这一次我加入了内存屏障:
// CPU0
void foo() {
a = 1;
smp_mb();
b = 1;
}
// CPU1
void bar() {
while (b == 0) continue;
assert(a == 1);
}
在这里,smp_mb就代表了多核体系结构上的内存屏障。由于在不同的体系结构上,指令各不相同,我们使用一个函数对它进行封装。加上这一道屏障以后,CPU会保证a和b的赋值指令不会乱序执行,同时写入cache的顺序也与程序代码保持一致。
所以说,内存屏障保证了,其他CPU能观察到CPU0按照我们期望的顺序更新变量。
总的来说,store buffer的存在是为提升写性能,放弃了缓存的顺序一致性,我们把这种现象称为弱缓存一致性。在正常的程序中,多个CPU一起操作同一个变量的情况是比较少的,所以store buffer可以大大提升程序的运行性能。但在需要核间同步的情况下,我们还是需要这种一致性的,这就需要软件工程师自己在合适的地方添加内存屏障了。
好了,到这里你可能也发现了,我们前面说的都是CPU核间同步的“写”的问题,但是核间同步还有另外一个瓶颈,也就是“读”的问题。那这个又要怎么解决呢?我们现在就来看看。
我们前面说过,当一个CPU向同伴发出Invalid消息的时候,它的同伴要先把自己的缓存置为Invalid,然后再发出acknowledgement。这个从“把缓存置为Invalid”到“发出acknowledgement”的过程所需要的时间也是比较长的。
而且,由于store buffer的存在提升了写入速度,那么invalid消息确认速度相比起来就慢了,这就带来了速度的不匹配,很容易导致store buffer的内容还没有及时更新到cache里,自己的容量就被撑爆了,从而失去了加速的作用。
为了解决这个问题,CPU设计者又引入了“invalid queue”,也就是失效队列这个结构。加入了这个结构后,收到Invalid消息的CPU,比如我们称它为CPU1,在收到Invalid消息时立即向CPU0发回确认消息,但这个时候CPU1并没有把自己的cache由Share置为Invalid,而是把这个失效的消息放到一个队列中,等到空闲的时候再去处理失效消息,这个队列就是invalid queue。
经过这样的改进后,CPU1响应失效消息的速度大大提升了,带有invalid queue的缓存结构是这样的:
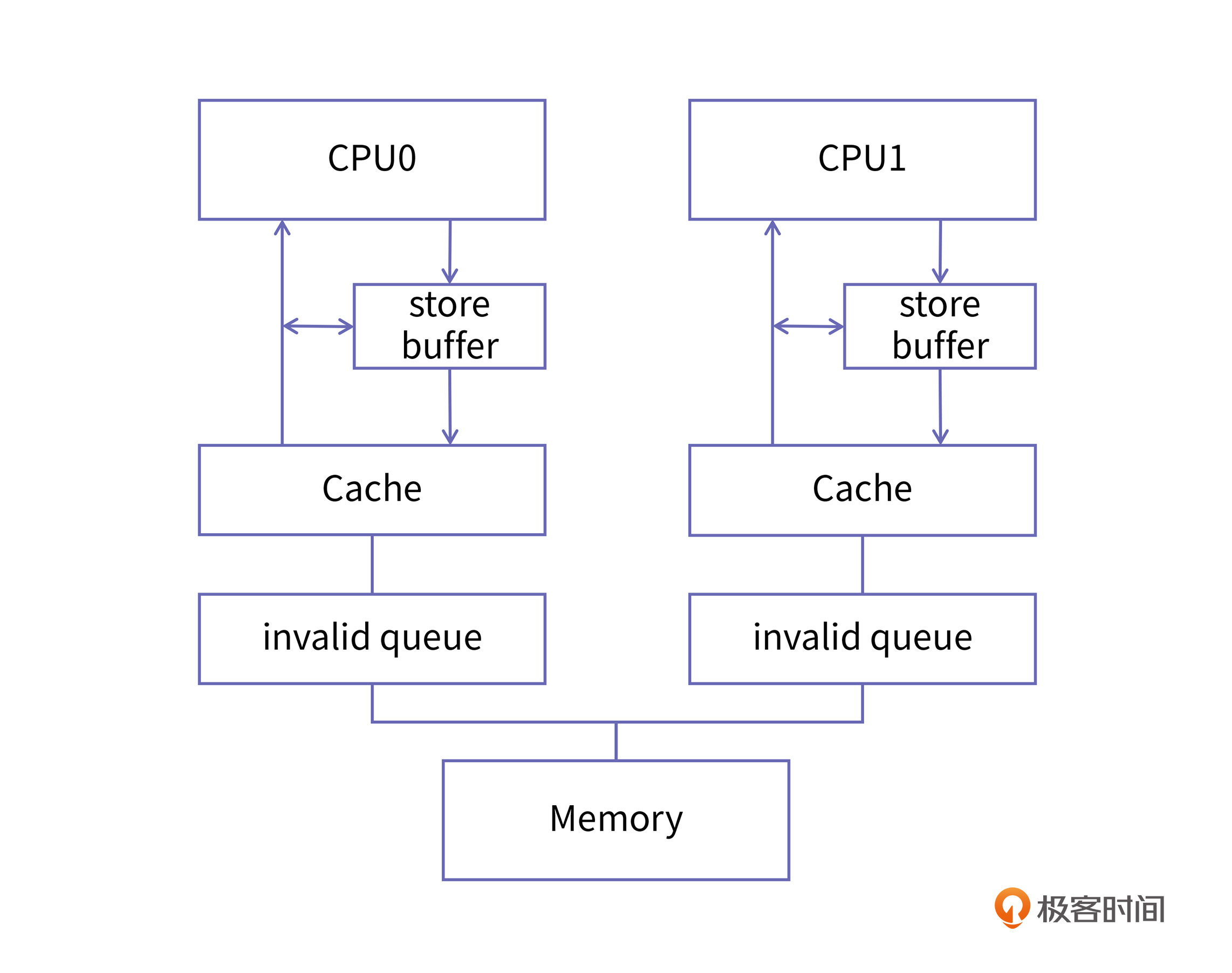
我们还是以前面CPU0和CPU1中的例子来做说明。
假如,CPU0和CPU1的缓存中都有变量a的副本,也就是说变量a所对应的缓存行在CPU0和CPU1中都是Share状态。CPU1中没有变量b的副本,b所对应缓存在CPU0中是Exclusive状态。
当CPU0在将变量a写入缓存的时候,会产生Invalid消息,这个消息到达CPU1以后,CPU1不再立即处理它了,而是将这个消息放入invalid queue,并且立即向CPU0回复了invalid acknowledgement消息。
CPU0在得到这个确认消息以后,就可以独占该缓存了,直接将这块缓存变为Modified状态,然后把a写入。在a写入以后,foo函数中的内存屏障就可以顺利通过了,接下来就可以写入变量b的新值。由于b是Exclusive的,它的更新比较简单,你可以自己思考一下。
接下来我们再看CPU1中的操作。
当CPU1发起对b的请求时,由于b不在缓存中,所以它会向总线发出BusRd请求,总线会把CPU0缓存中的b的新值1更新到CPU1。同时,b所在的缓存行在两个CPU中都变为Share状态。
CPU1得到了b的新值以后,就可以退出第10行的while循环,然后对a的值进行判断。但是由于a的Invalid消息还在invalid queue里,没有被及时处理,CPU1还是会使用自己的Cache中的a的原来的值,也就是0,这就出错了。
你会发现,在这个过程中,虽然CPU1并没有乱序执行两条读指令,但是实际产生的效果却好像是先读到了b的值,后读到了a的值。如果是在严格遵守MESI协议的CPU中,CPU0一定要确保a的值先更新到CPU1,然后才能继续对b赋值。但是放宽了缓存一致性以后,这段代码就有问题了。
解决的方法和写屏障的思路是一样的,我们需要引入一个内存屏障,它会让CPU暂停执行,直到它处理完invalid queue中的失效消息之后,CPU才会重新开始执行,例如:
// CPU0
void foo() {
a = 1;
smp_mb();
b = 1;
}
// CPU1
void bar() {
while (b == 0) continue;
smp_mb();
assert(a == 1);
}
你看,这样在bar函数里增加了内存屏障以后,我们就可以保证a的新值是一定能读到的了。可见smp_mb可以同时对store buffer和invalid queue施加影响。
不过呢,你可能也会发现,在这个例子中,其实我们也不需要smp_mb有那么大的作用。我们只需要在第4行保证store buffer写入的顺序,在第11行保证invalid queue的顺序就好了。所以smp_mb相对于我们的需求来说,做的事情过多了,这也会导致不必要的性能下降。面对这种情况,CPU的设计者也进一步提供了单独的写屏障和读屏障。
分离的写屏障和读屏障的出现,是为了更加精细地控制store buffer和invalid queue的顺序。
再具体一点,写屏障的作用是让屏障前后的写操作都不能翻过屏障。也就是说,写屏障之前的写操作一定会比之后的写操作先写到缓存中。
读屏障的作用也是类似的,就是保证屏障前后的读操作都不能翻过屏障。假如屏障的前后都有缓存失效的信息,那屏障之前的失效信息一定会优先处理,也就意味着变量的新值一定会被优先更新。
这里我们讨论的都是读写屏障对store buffer和invalid queue的影响。其实,这里还隐含了一个事实,那就是对CPU乱序执行的影响:写屏障会禁止写操作的乱序。
这个要求虽然是隐含的,但仔细想一下却是显然的,理由很简单。你想,如果某个CPU在进行写操作的时候,实际的执行顺序都是乱序的话,那我们根本就无法讨论新的值什么时候传递到其他CPU。
而且,分离的读写屏障还有一个好处,就是它可以在需要使用写屏障的时候只使用写屏障,不会给读操作带来负面的影响,这种屏障也可以称为StoreStore barrier。同理,只使用读屏障也不会对写操作造成影响,这种屏障也可以称为LoadLoad barrier。例如我们前面CPU0和CPU1的例子,就可以进一步修改成这样:
// CPU0
void foo() {
a = 1;
smp_wmb();
b = 1;
}
// CPU1
void bar() {
while (b == 0) continue;
smp_rmb();
assert(a == 1);
}
当然,这种修改只有在区分读写屏障的体系结构里才会有作用,比如alpha结构。而在X86和Arm中是没有作用的,这是因为X86采用的TSO模型不存在缓存一致性的问题,而Arm则是采用了另一种称为单向屏障的分类方式。这种单向屏障是怎样的呢?我们也来简单分析一下。
单向屏障(half-way barrier)也是一种内存屏障,但它并不是以读写来区分的,而是像单行道一样,只允许单向通行,例如Arm中的stlr和ldar指令就是这样。
stlr的全称是store release register,也就是以release语义将寄存器的值写入内存;ldar的全称是load acquire register,也就是以acquire语义从内存中将值加载入寄存器。我们重点就来看看release和acquire语义。
首先是release语义。如果我们采用了带有release语义的写内存指令,那么这个屏障之前的所有读写都不能发生在这次写操作之后,相当于在这次写操作之前施加了一个内存屏障。但它并不能保证屏障之后的读写操作不会前移。简单说,它的特点是挡前不挡后。
在支持乱序执行的CPU(当前高性能多核CPU基本都支持乱序执行)中,使用release语义的写内存指令比使用全量的dmb要有更好的性能。
需要注意的是,stlr指令除了具有StoreStore的功能,它同时还有LoadStore的功能。LoadStore barrier可以解决的问题是真实场景中比较少见的,所以在这里我们就先不关心它了。对于最常用的StoreStore的问题,我们在Arm中经常使用stlr这条带有release语义的写指令来解决,尽管它的能力相比我们的诉求还是大了一些。
接着我们再来看一下与release语义相对应的acquire语义。它的作用是这个屏障之后的所有读写都不能发生在barrier之前,但它不管这个屏障之前的读写操作。简单说就是挡后不挡前。
与stlr相对称的是,它同时具备LoadLoad barrier的能力和StoreLoad barrier的能力。在实际场景中,我们使用最多的还是LoadLoad barrier,此时我们会使用ldar来代替。
好了,今天我们这节课的内容就讲完了,我们简单回顾一下。
在这节课,我们讲解了在CPU的具体实现中,通过放宽MESI协议的限制来获得性能提升。具体来说,我们引入了store buffer和 invalid queue,它们采用放宽MESI协议要求的办法,提升了写缓存核间同步的速度,从而提升了程序整体的运行速度。
但在这放宽的过程中,我们也看到会不断地出现新的问题,也就是说,一个CPU的读写操作在其他CPU看来出现了乱序。甚至,即使执行写操作的CPU并没有乱序执行,但是其他CPU观察到的变量更新顺序确实是乱序的。这个时候,我们就必须加入内存屏障来解决这个问题。
最后我们也学习了读写屏障分离和单向屏障。在不同的情况下,我们需要的内存屏障是不同的。使用功能强大的内存屏障会给系统带来不必要的性能下降,为了更精细地区分不同类型的屏障,CPU的设计者们提供了分离的读写屏障(alpha),或者是单向屏障(Arm)。
如何正确地使用内存屏障是一件很考验功底的事情,如果该加的地方没加,会带来非常严重的正确性问题。在操作系统,数据库,编译器等领域,会产生非常深远的影响,其代价甚至是完全无法接受的。而在不需要加的地方,如果你施加了比较重的屏障则可能带来性能下降,成为系统瓶颈。关于读写屏障更多的实际应用案例,你可以参考下我们华为JDK公众号发布的这篇文章。
假如以下代码是Java代码,你可以看到,代码中采用了full fence来保证缓存一致性。请阅读Java的相关API文档并思考,fullFence是否合理?如果不合理,应该使用哪个API对它进行替代呢?欢迎在留言区分享你的想法,我在留言区等你。
// CPU0
void foo() {
a = 1;
unsafe.fullFence();
b = 1;
}
// CPU1
void bar() {
while (b == 0) continue;
unsafe.fullFence();
assert(a == 1);
}
其实,除此之外,上面这段代码还有一种改法。我给你一个小提示,就是使用volatile关键字。我们会在第17课对volatile关键字进行讲解,如果你有兴趣也可以提前预习一下。

欢迎你把这节课分享给更多对MESI协议和内存屏障感兴趣的人。我是海纳,我们下节课见。
评论