
你好,我是海纳。
随着这节课的开始,我们将进入到专栏的最后一个模块:自动内存管理篇。在这个模块,你将会了解到,以Java为代表的托管型语言是如何自动进行内存管理和回收整理的,这将提高你使用Java、Python、 Go等托管型语言的能力。
为什么我要把自动内存管理篇放到最后才讲呢?因为要理解这一篇的内容,需要软件篇和硬件篇的知识做铺垫。比如说,在面试时,有一个问题面试官问到的频率非常高,但几乎没有人能回答正确,因为它需要的前置知识太多。这个问题是:Java中的volatile有什么用?如何正确地使用它?
这个问题之所以会频繁出现在面试中,是因为Java并发库中大量使用了volatile变量,在JVM的研发历史上,它在各种不同的体系结构下产生了很多典型的问题。那么,在开发并发程序的时候,深刻地理解它的作用是非常有必要的。
幸运的是,前面硬件篇的知识已经帮我们打好了足够的基础,今天我们就可以深入讨论这个问题了。由于在这个问题中,volatile的语义是由Java内存模型定义的,我们就先从Java内存模型这个话题聊起。
我们知道在不同的架构上,缓存一致性问题是不同的,例如x86采用了TSO模型,它的写后写(StoreStore)和读后读(LoadLoad)完全不需要软件程序员操心,但是Arm的弱内存模型就要求我们自己在合适的位置添加StoreStore barrier和LoadLoad barrier。例如下面这个例子:
public class MemModel {
static int x = 0;
static int y = 0;
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
x = 1;
y = 1;
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
while (y == 0);
if (x != 1) {
System.out.println("Error!");
}
}
});
t2.start();
t1.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
上面这个例子在x86机器上运行是没有问题的,但是在Arm机器就有概率打印出Error。原因是第一个线程t1对变量x和y的写操作的顺序是不能保证顺序的,同时,第二个线程t2读取x和y的时候也不保证顺序。这一点我们在第15节课和第16节课 已经分析过了。
为了解决这个问题,Java语言在规范中做出了明确的规定,也就是在JSR 133文档中规定了Java内存模型。内存模型是用来描述编程语言在支持多线程编程中,对共享内存访问的顺序。所以显然,在上面例子中,线程间变量共享的情况,就可以借此来解决。
在JSR133文档中,这个内存模型有一个专门的名字,叫Happens-before,它规定了一些同步动作的先后顺序。当然,这个规范也不是一蹴而就的,它也是经过了几次讨论和更新之后才最终定稿。所以,在早期的JVM实现中仍然存在一些弱内存相关的问题。这些问题我们很难称其为bug,因为标准里的规定就有问题,虚拟机实现只是遵从了标准而已。
接下来,我们探寻一下Happens-before模型究竟会带来什么样的问题,这样你就能深刻体会到volatile存在的意义了。
Java内存模型(Java Memory Model, JMM)是通过各种操作来定义的,包括对变量的读写操作、加锁和释放锁,以及线程的启动和等待操作。JMM为程序中的动作定义了一种先后关系,这些关系被称为Happens-Before关系。要想保证操作B可以看到操作A的结果,A和B就必须满足Happens-Before关系,这个结论与A和B是否在同一线程中执行无关。
我们先来看Happens-Before的规则,然后再对它的特点进行分析。我们要明确Happens-Before模型所讨论的都是同步动作,包括加锁、解锁、读写volatile变量、线程启动和线程完成等。下面这几条规则中所说的操作都是指同步动作。见下面的表格:
Happens-Before模型强调的是同步动作的先后关系,对于非同步动作,就没有任何的限制了。这节课的第一个例子,它里面的读写操作都是非同步动作,所以它在不同的体系结构上运行,会得到不同的结果。但这并不违反JMM的规定。
你要牢记一点的是,JMM是一种理论上的内存模型,并不是真实存在的。它是以具体的CPU的内存模型为基础的。可能我这么说,你还是觉得比较抽象,现在,我们来看JSR 133文档中的两个令人费解的例子,你就能理解了。
第一个例子是控制流依赖,例子中包括了两个线程且变量x和y的初值都是0。第一个线程的代码是:
// Thread1
r1 = x;
if (r1 != 0)
y = 1;
第二个线程的代码是:
// Thread 2
r2 = y;
if (r2 != 0)
x = 1;
由于存在控制流依赖,这两段代码中,第4行都不能提前到第2行之前执行。换句话说,到目前为止,所有的主流的CPU中,上面两段代码都会按照代码顺序执行。你可以推演一下,最终的运行结果一定是r1和r2的值都是0。
但是Happens-before是一种理论模型,如果线程1中,y=1先于r1=x执行,同时线程2中,x=1先于r2=y执行,最后的结果,存在r1和r2的值都是1的可能性。理论上确实可能存在一种CPU,当它进行分支预测投机执行的时候,投机的结果被其他CPU观察到。当然,实际中绝对不可能出现这样的CPU,因为这意味着厂家花费了更多的精力为软件开发者带来了一个巨大的麻烦,而且由于核间同步通讯的要求,CPU的性能还会下降。
第二个例子是数据流依赖。假设x和y的初值是0,而r1和r2的初值是42。线程1的代码是:
r1 = x;
y = r1;
线程2的代码是:
r2 = y;
x = r2;
因为每个线程内部的第2行和第1行之间都存在数据依赖,所以这里是无法产生乱序执行的,所以无论你以怎样的顺序对这两个线程进行调度,都不可能出现r1=r2=42的情况的。但是r1=r2=42在Happens-before模型中却是合理的,因为它没有对数据流依赖进行规定。
也就是说,普通的变量读写在JMM是允许乱序的,如果真的有人造出这么愚蠢的CPU,运行出这种结果却是符合Happens-before的规定的。
但是这两个问题在现实中并不存在。我这里特别想讲这两个例子的原因,是因为JSR 133文档花费了大量的篇幅在介绍本不应该存在的两个问题,这导致这个文档极其晦涩难懂。
从实用的角度,我建议你在理解JMM时,一定要结合具体的CPU体系结构。大体上讲,JMM加上每一种体系结构都有的控制流依赖和数据流依赖,才是一种比较实用的内存模型。纯粹的JMM本身的实用性并不强。
JMM是一种标准规定,它并不管实现者是如何实现它的。具体到Java语言虚拟机的实现,当Java并发库的核心开发者Doug Lea将JMM简化之后,就变得更容易理解一些。我们来看Doug Lea的描述。
Doug Lea为了方便虚拟机开发人员理解Java内存模型,编写了一个名为《Java内存模型Cookbook》的小册子。在这个小册子中,他给出一个表格,现代的JVM基本都是按照这个表格来实现的。
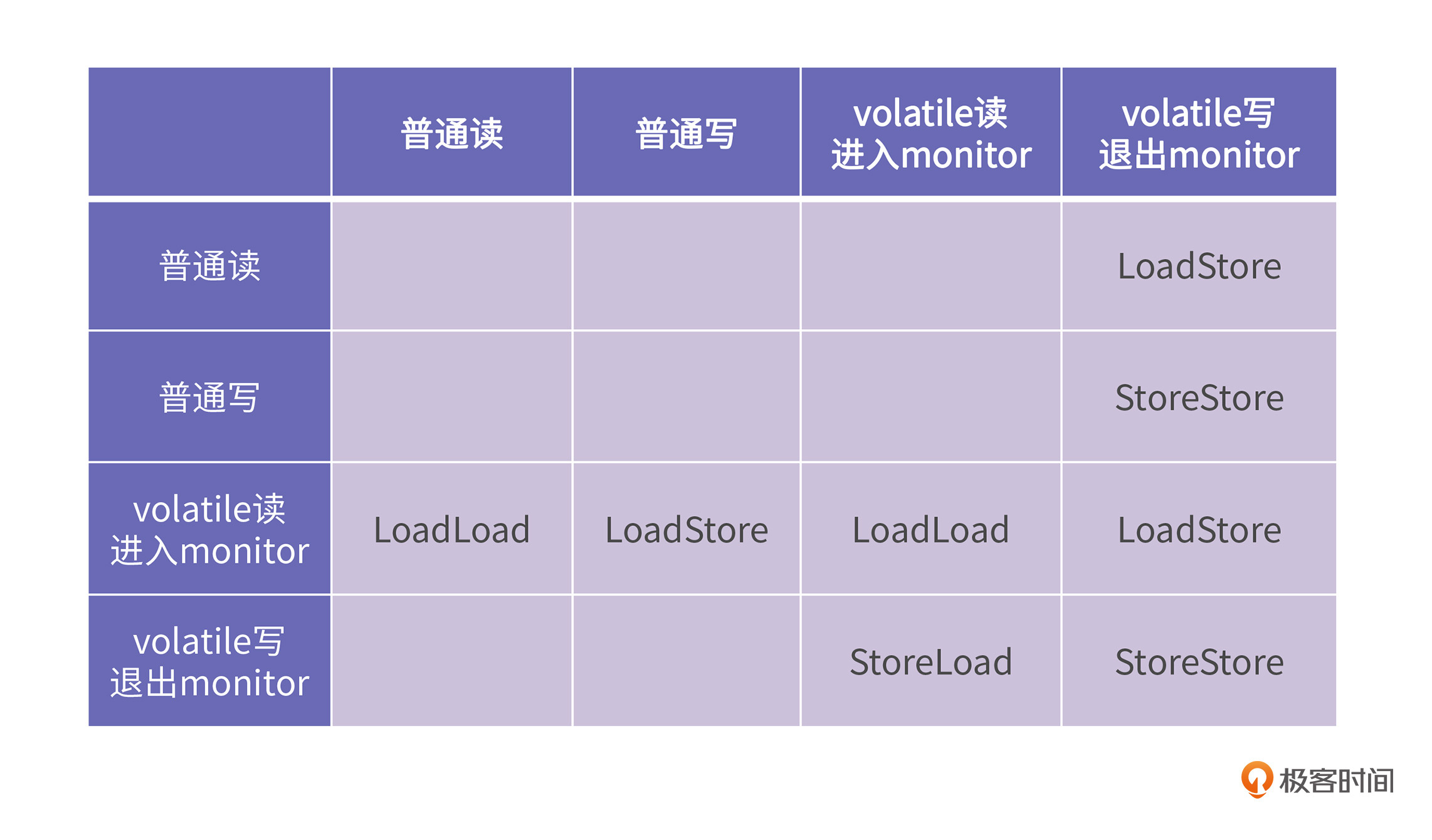
这个表格描述了连续的两个读写动作,JVM应该如何处理。表格的最左列代表了第一个动作,第一行代表了第二个动作。表格中的内容使用了LoadLoad、LoadStore、StoreStore、StoreLoad四种内存屏障,分别表示第一个动作和第二个动作之间应该插入什么类型的内存屏障。
在上一节课中,我们知道了,在不同的体系结构上,这四类barrier的实际含义并不相同。因为x86采用了TSO模型,所以它根本没有定义LoadLoad、LoadStore和StoreStore这三种barrier,x86上只有StoreLoad barrier是有意义的。
而Arm上,由于存在单向的barrier,所以LoadLoad和LoadStore barrier就可以使用acquire load代替,LoadStore和StoreStore barrier也可以使用release store代替,而StoreLoad barrier就只能使用dmb代替了。
我们可以看到,表格的第三行刚好就对应了arm的acquire load barrier,所以我们就知道在arm上,JVM在实现volatile读的时候就必然会使用acquire load来代替。表格的第四列则刚好对应arm的release store barrier,同时,arm上的JVM在实现volatile写的时候,就可以使用release store来代替。
回到这节课开始时的例子,可见,只要将变量 y 改成 volatile,就相当于在第8行和第9行之前增加了StoreStore barrier,同时在第15行和第16行处增加了LoadLoad barrier,那么这段Java代码在Arm上的效果就与上一节课所分析的内存屏障的示例代码逻辑是一致的了。
只要JVM遵守了JMM的规定,那么不管在什么平台上,最后的运行结果都是一样。在这节课刚开始的那个例子中,只要把变量 y 修改成volatile修饰的,就不会再出现在x86上不会打印Error,而在Arm有机率打印Error的情况了。所有平台运行结果的一致性是由JVM遵守JMM来保证的。
到这里,我们就知道了,Happens-before模型是一种理论模型,它没有规定控制流依赖和数据流依赖。但是在实际的CPU中,这两种依赖都是存在的,这是JVM实现的基础。所以在JVM的实现中,主要是参考了Doug Lea所写的Cookbook中的建议。从实用的角度,Java程序员就可以从Doug Lea所给出的表格去理解volatile的意义,而不必再去参考JSR 133文档。
接下来,我们通过两个例子来进一步加深对Java内存模型的理解,看看Java内存模型在实际场景中是如何应用的。
与这节课第一个例子相似,JDK的源代码中有很多使用volatile变量的读写来保证代码执行顺序的例子,我们以CountDownLatch来举例,它有一个内部类是Sync,它的定义如下所示:
private static final class Sync extends AbstractQueuedSynchronizer {
Sync(int count) {
setState(count);
}
int getCount() {
return getState();
}
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
for (;;) {
int c = getState();
if (c == 0)
return false;
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
}
我们看到代码里的tryAcquireShared代表这个方法具有acquire语义,而tryReleaseShared则代表了这个方法具有release语义。从tryAcquireShared的代码里,我们可以推测getState里面应该会有acquire语义,我们继续看AbstractQueuedSynchronizer的代码。
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
/**
* The synchronization state.
*/
private volatile int state;
/**
* Returns the current value of synchronization state.
* This operation has memory semantics of a {@code volatile} read.
* @return current state value
*/
protected final int getState() {
return state;
}
/**
* Sets the value of synchronization state.
* This operation has memory semantics of a {@code volatile} write.
* @param newState the new state value
*/
protected final void setState(int newState) {
state = newState;
}
/**
* Atomically sets synchronization state to the given updated
* value if the current state value equals the expected value.
* This operation has memory semantics of a {@code volatile} read
* and write.
*
* @param expect the expected value
* @param update the new value
* @return {@code true} if successful. False return indicates that the actual
* value was not equal to the expected value.
*/
protected final boolean compareAndSetState(int expect, int update) {
// See below for intrinsics setup to support this
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
从上面的代码中可以看到,state是一个volatile变量,根据JMM模型,我们可以知道getState方法是一种带有acquire语义的读。
在为state变量赋值的时候,AbstractQueuedSynchronizer(AQS)提供了两个方法,一个是setState,另一个是compareAndSetState。其中setState是一个带有release语义的写。那为什么还要提供comareAndSet方法呢?
这是因为compareAndSetState,不仅是强调release语义,它还有原子性语义。这个操作中包含了取值,比较和赋值三个动作,如果比较操作不成功,则赋值操作不会发生。
通过这个例子,我们就可以得到一个结论,内存屏障与原子操作是两个不同的概念。内存屏障强调的是可见性,而原子操作则是强调多个步骤要么都完成,要么都不做。也就是说一个操作中的多个步骤是不能存在有些完成了,有些没完成的状态的。
接下来,我们再举一个与内存模型相关的并发例子。这是一道十几年来经久不衰的面试题,也是Java面试官最喜欢问的。这道题是:如何高效地实现线程安全的单例模式?
我们知道单例模式是设计模式的一种,它的主要特点是全局只能生成唯一的对象。如何才能写出线程安全的单例模式代码呢?
我们从单线程最基本的单例模式开始讲起,它的代码是这样的:
class Singleton {
private static Singleton instance;
public int a;
private Singleton() {
a = 1;
}
public static Singleton getInstance() {
if (instance == null)
instance = new Singleton();
return instance;
}
}
这个类的特点是,构造函数是私有的。这意味着,除了在getInstance这个静态方法里,可以使用“new Singleton”的方式进行对象的创建,整个工程中的其他任意位置都不能再使用这种方法进行创建。
要想得到Singleton的实例就只能使用getInstance这个静态方法。而这个方法每一次都会返回同一个对象。所以这就保证了全局只能产生一个Singleton实例。
这个单例模式看上去写得很正确,但是面试题中的要求是写出线程安全的单例模式。上面的写法显然不是线程安全的。为什么我这么说呢?
假设第一个线程调用getInstance时,看到instance变量的值为null,它就会创建一个新的Singleton对象,然后将其赋值给instance变量。当第二个线程随后调用getInstance时,它仍然有可能看到instance变量的值为null,然后也创建一个新的Singleton对象。更具体的过程希望你可以自己进行分析,因为这是并发程序的相关内容,不是我们这节课的重点,所以我就不啰嗦了。
为了解决这个问题,我们可以将getInstance方法改为同步方法,这样就为调用这个方法加上了锁,从而可以保证线程安全:
class Singleton {
private static Singleton instance;
public int a;
private Singleton() {
a = 1;
}
public synchronized static Singleton getInstance() {
if (instance == null)
instance = new Singleton();
return instance;
}
}
显然,上面的代码是线程安全的,我们之前分析过,在线程1还未执行完getInstance,线程2就开始执行的情况,在加锁以后就不会再出现了。但是这样会带来新的问题:访问加锁的方法是非常低效的。
所以,又有另外一种实现方式被提出:
class Singleton {
private static Singleton instance = new Singleton();
public int a;
private Singleton() {
a = 1;
}
public static Singleton getInstance() {
return instance;
}
}
上面代码的第二行是在类加载的时候执行的,而类加载过程是线程安全的,所以不管有多少线程调用getInstance方法,它的返回值都是第二行所创建的对象。
这种创建方式有别于第一种。第一种单例模式的实现是在第一次调用getInstance时,它是在不得不创建的时候才去创建新的对象,所以这种方式被称为懒汉式;第二种实现则是在类加载时就将对象创建好了,所以这种方式被称为饿汉式。
还有的人既想使用懒汉式进行创建,又希望程序的效率比较好,所以提出了双重检查(Double Check),它的具体实现方案如下:
class Singleton {
// 非核心代码略
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}
大多数情况下,instance变量的值都不为null,所以这个方法大多数时候都不会走到加锁的分支里。如果instance变量值为null,则通过在Singleton.class对象上进行加锁,来保证对象创建的正确性,看上去这个实现非常好。
但是经过我们这节课的讲解,你就能理解这个写法在多核体系结构上还是会出现问题的。假设线程1执行到第8行,在创建Singleton变量的时候,由于没有Happens-Before的约束,所以instance变量和instance.a变量的赋值的先后顺序就不能保证了。
如果这时线程2调用了getInstance,它可能看到instance的值不是null,但是instance.a的值仍然是一个未初始化的值,也就是说线程2看到了instance和instance.a这两个变量的赋值乱序执行了。
这显然是一个写后写的乱序执行,所以修改的办法很简单:只需要将instance变量加上volatile关键字,即可把这个变量的读变成acquire读,写变成release写。这样,我们才真正地正确实现了饿汉式和懒汉式的单例模式。
好啦,今天这节课就结束啦,这节课我们学习了Java内存模型。从这节课中,我们了解到JSR 133中所描述的Java内存模型是一种理论模型,它的规则非常少,以至于连控制流依赖和数据流依赖都没有规定,这导致JSR133文档讨论了很多在现实中根本不存在的情况。
而我们在讨论JMM的实现时,必然会与具体的CPU相联系。Doug Lea将JMM做了简单的翻译,使用软件程序员可以看懂的语言重新阐释了JSR 133文档。
到这里,这节课开始处所讲的volatile的机制,其答案也就明晰了。它的作用是为变量的读写增加happens before关系,结合具体的CPU实现,就相当于是为变量的读增加acquire语义,为变量的写增加release语义。
接下来,我们用两个具体的例子来解释可见性、原子性和volatile的用法。
第一个例子是Java并发库中的核心数据结构AbstractQueuedSynchronizer(AQS),它通过使用volatile变量和原子操作来维护对象的状态。
第二个例子是实现线程安全的单例模式。我们梳理了单例模式的各种实现方式,并详细介绍了double check实现方式的问题,以及如何使用volatile来修复这个问题。
请你思考一下,volatile能替代锁(或者CAS操作)的能力吗?比如,下面这个例子的写法,sum的最终结果一定是80000吗?如果不是的话,应该怎么做才能保证呢?欢迎你在留言区分享你的想法和收获,我在留言区等你。
class AddThread extends Thread {
public void run() {
for (int i = 0; i < 40000; i++)
Main.sum += 1;
}
}
class Main {
public static volatile int sum = 0;
public static void main(String[ ] args) throws Exception {
AddThread t1 = new AddThread();
AddThread t2 = new AddThread();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(sum);
}
}

好啦,这节课到这就结束啦。欢迎你把这节课分享给更多对计算机内存感兴趣的朋友。我是海纳,我们下节课再见!
评论