你好,我是海纳。
在上一节课,我们介绍了分代式垃圾回收算法。把对象分代以后,可以大大减轻垃圾回收的压力,进而就减少了停顿时长。在这种思路的启发下,人们进一步想,如果把对象分到更多的空间中,根据内存使用的情况,每一次只选择其中一部分空间进行回收不就好了吗?根据这个思路,GC开发者设计了分区回收算法。
它在实际场景中应用非常广泛,比如说Hotspot中的G1 GC就是分区回收算法的一种具体实现,Android上的art虚拟机也采用了分区回收算法。而且从JDK9开始,G1 GC就是JDK的默认垃圾回收算法了,所以在将来很长时间里,对G1 GC进行合理的调优,将是Java程序员要重点掌握的知识。
那么这节课,我们就来深入地讲解分区回收算法的基本原理,掌握G1 GC的若干重要参数,从而对G1 GC进行合理的参数调优。
要想理解分区垃圾回收的原理,还得从它的结构讲起。
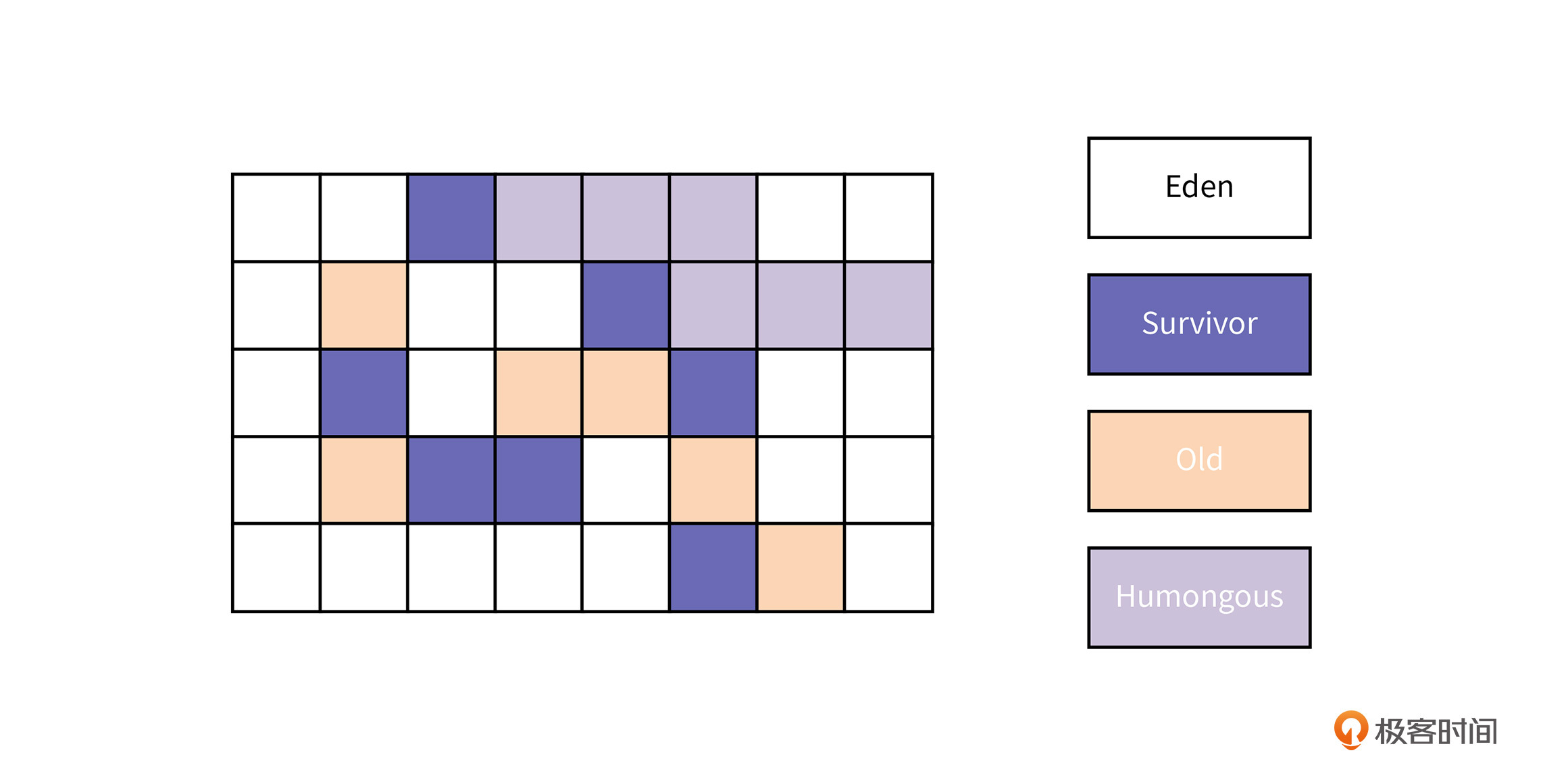
首先,我们来了解一下分区回收算法的堆空间是如何划分的。下图是G1 GC的堆结构:
G1也是一个分代的垃圾回收算法,不过,和之前介绍的CMS、Scavenge算法不同的是:G1的老年代和年轻代不再是一块连续的空间,整个堆被划分成若干个大小相同的Region,也就是区。Region的类型有Eden、Survivor、Old、Humongous四种,而且每个Region都可以单独进行管理。
Humongous是用来存放大对象的,如果一个对象的大小大于一个Region的50%(默认值),那么我们就认为这个对象是一个大对象。为了防止大对象的频繁拷贝,我们可以将大对象直接放到Humongous中。
而Eden、Survivor、Old三种区域和我们前面课程中介绍的Eden分区、Survivor分区以及老年代的作用是类似的。也就是说,对象会在Eden Regions中分配,当进行年轻代GC时,会将活跃对象拷贝到Survivor Regions;当对象年龄超过晋升阈值时,就把活跃对象复制进Old Regions。如果你不清楚,可以看看第19节课和第20节课,这里我就不再啰嗦了。
在了解了G1的堆空间划分之后,我们就可以开始学习G1算法的回收原理了。实际上,分区垃圾回收算法最大的特点是维护跨分区引用,这也是它实现起来最难的地方。下面我们就以此为切入点,来探寻G1算法的原理。
维护跨分区引用,其中的关键就是写屏障。我们在上节课讲CMS时提到,写屏障是对象在修改引用关系时,额外做一些操作来维护相关信息。在CMS中,写屏障主要有两个作用:
我们先来看第一个作用,也就是解决活跃对象漏标的问题。上一节课介绍了解决漏标问题的两种方法,分别是“往前走”和“往后退一步”。今天这节课,我们就来介绍第三种解法,这个解法呢,是由日本学者汤浅太一提出的,具体的算法如下图所示:
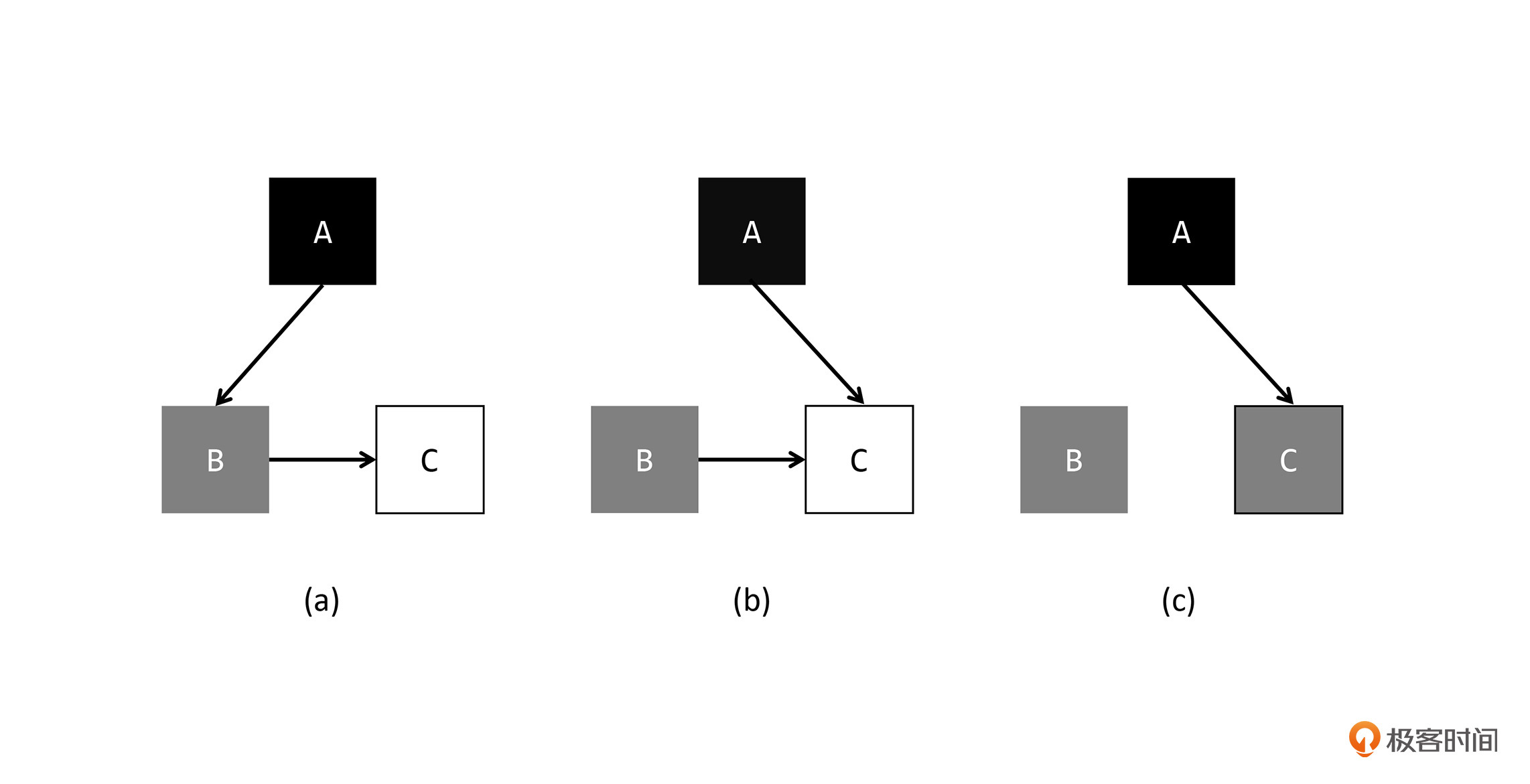
在这张图中,我们可以看到,当对象B对C的引用关系消失以后,再将C标记为灰色,即便将来A对C的引用消失了,也会在当前GC周期内被视为活跃对象。也就是说,C有可能变成浮动垃圾。我们把这种在删除引用的时候进行维护的屏障叫做deletion barrier。
G1中采用的就是这种做法。这种做法的特点是,在GC标记开始的一瞬间,活跃的对象无论在标记期间发生怎样的变化,都会被认为是活跃的对象。
我们知道,当一个对象的全部引用被删除时,才会被当做垃圾。而如果使用我们前面讲到的deletion barrier,在并发标记阶段,即便对象的全部引用被删除,也会被当做活跃对象来处理。就好像在GC开始的瞬间,内存管理器为所有活跃对象做了一个快照一样,所以人们给了这种技术一个很形象的名字:开始时快照(Snapshot At The Beginning,SATB)。
你要注意的是,有些文章对SATB的解释是:在GC开始时将堆做一个内存快照,存放到磁盘上。这种说法就是望文生义了。因为快照这个词在计算机领域通常是指压缩,索引等技术,所以就有人把这里的快照理解成了对堆对象的一种压缩。由此,我们就知道这种错误的说法是怎么来的了。
言归正传,我们在理解SATB的含义之后,再来看看SATB具体的工作原理吧。
我们在讲写屏障时提到,当B对象对C对象的引用消失时,C对象将会被标记为灰色。这个动作的效率是比较低的,如果都放在写屏障中做,会极大地影响程序性能。因为写屏障的逻辑是由业务线程执行的。
为了解决这个问题,GC开发者将“C对象标记为灰色”这件事情往后推迟了。业务线程只需要把C对象记录到一个本地队列中就可以了。每个业务线程都有一个这样的线程本地队列,它的名字是SATB队列。
当业务线程发现对象C的引用被删除之后,直接将C放到SATB队列中,并不去做标记,真正做标记的工作交给GC线程去做,这样就减少了写屏障的开销。
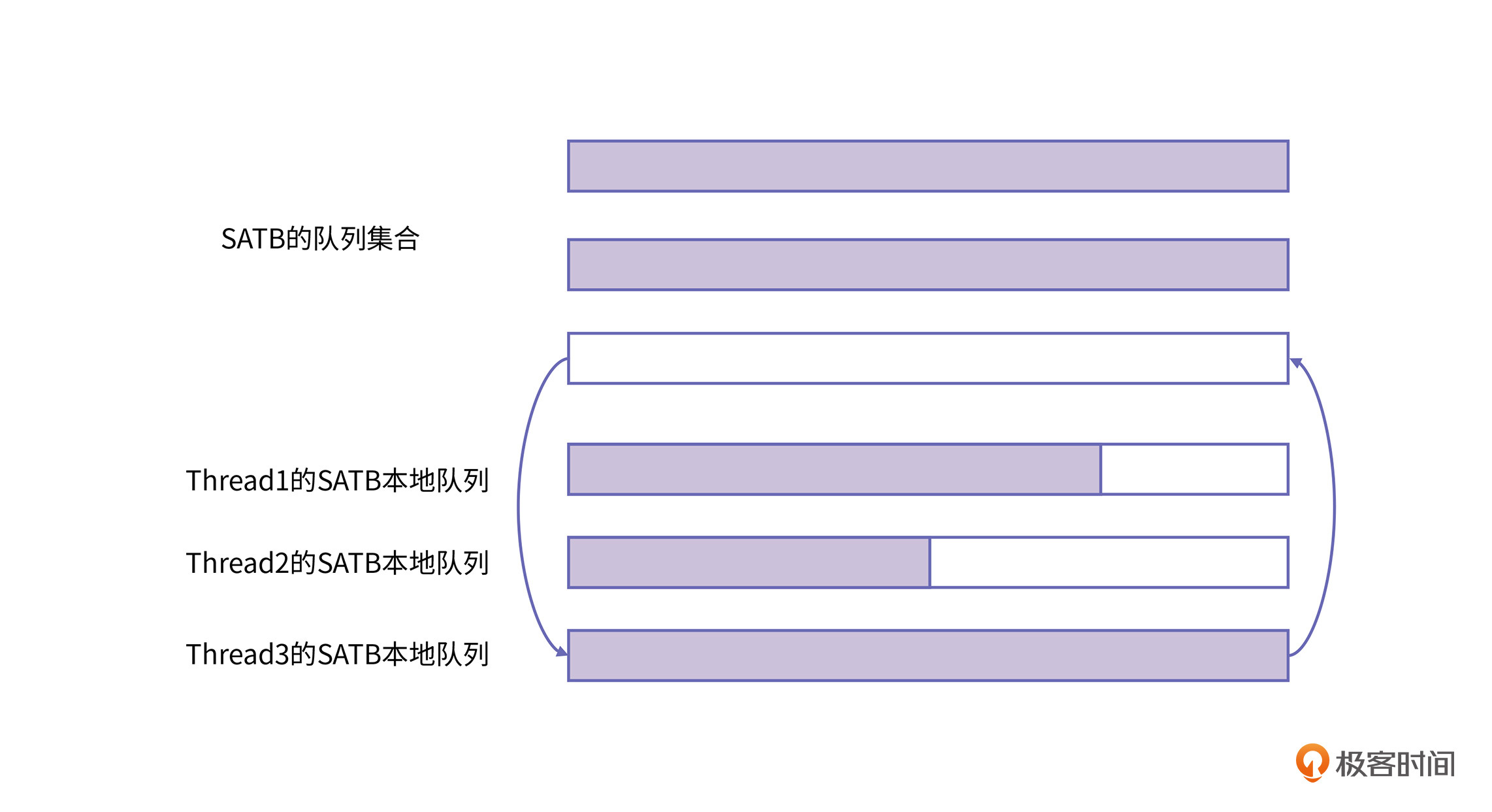
如上图所示,每个线程有自己的本地SATB队列,当本地队列满了之后,就把它交给SATB队列集合,然后再领取一个空队列当做线程的本地SATB队列。GC线程则会将SATB队列集合中的对象标记为灰色,至于什么时候标记,并不需要业务线程关心。
在学习了SATB相关知识后,我们继续来定义G1的两种垃圾回收模式,以方便后面详细地介绍算法的执行过程。
G1的垃圾回收模式有两种:分别是young GC和mixed GC。
我要告诉你的是,无论是young GC还是mixed GC,都会回收全部的年轻代,mixed回收的老年代Region是需要进行决策的(Humongous在回收时也是当做老年代的Region处理的)。那么决定老年代Region是否被回收的因素具体有哪些呢?
我们把mixed GC中选取的老年代对象Region的集合称之为回收集合(Collection Set,CSet)。CSet的选取要素有以下两点:
MaxGCPauseMillis 默认是200ms,一般不需要进行调整,如果需要停顿时间更短可以对它进行设置,不过需要注意的是,MaxGCPauseMillis设置的越小,选取的老年代Region就会越少,如果GC压力居高不下,就会触发G1的Full GC。
触发G1的Full GC代价是很高的。最早的实现是一个单线程的Mark-Compact GC,停顿时间非常长,虽然后来也改进成多线程,但还是需要尽量避免触发G1的Full GC。如果一个应用会频繁触发G1 GC的Full GC,那么说明这个应用的GC参数配置是不合理的,理想情况下G1是没有Full GC的。在这节课的最后,我会介绍几个常用的G1参数,方便你在实践中对G1进行调参。
在学习了G1的垃圾回收模式之后,我们需要解决的问题还有不少,首先就是跨区引用的问题。
在上面的内容中,我们提到了写屏障的两个功能,第二个功能就是维护跨区引用。在第21节课中,我们已经学习了CMS的跨代引用,实际上,CMS的跨代引用和G1的跨区引用的原理是相同的。不同的是,CMS的跨代引用它的回收空间是固定的,例如young GC只回收年轻代,Concurrent Mark Sweep只回收老年代,这样只需要维护一张卡表就可以了。
但是像G1这种分区回收算法,有些Region可能被选入CSet,有些则不会。所以,我们需要知道当一个Region需要被回收时,有哪些其他的Region引用了自己。相应地,为了加快定位速度,分区回收算法为每个Region都引入了记录集(Remembered Set,RSet),每个Region都有自己的专属RSet。
和Card table 不同的是,RSet记录谁引用了我,这种记录集被人们称为point-in型的,而Card table则记录我引用了谁,这种记录集被称为point-out型。
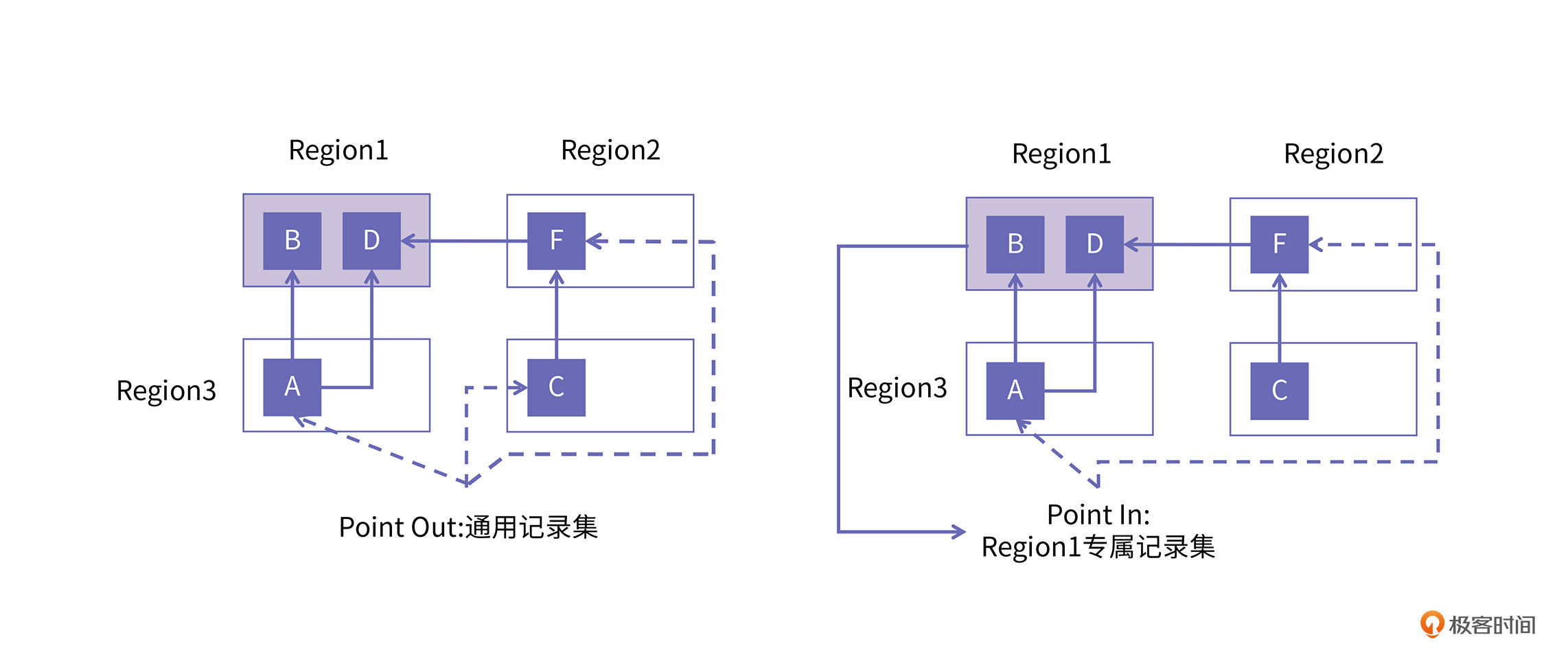
如图所示,图中的左侧展示了一个维护跨区引用的通用记录集,而右侧则展示了只对应于一个Region的专属记录集。
接下来我们继续分析RSet的维护策略,也就是说哪些引用关系需要加入到RSet:
总的来说,RSet 需要维护的引用关系只有两种,非CSet 老年代Region 到年轻代Region的引用,和非CSet 老年代Region到CSet老年代Region的引用。
那么,RSet具体是何时被记录的呢?答案也是写屏障,写屏障的这个作用,我们在上面的内容中已经提到过。如下图所示:

G1在RSet中记录的也是card。比如Region1中的对象A引用了Region2的对象B,那么对象A所对应的card就会被记录在Region2的RSet中(注意!不是Region1的RSet)。
在G1中,我们把这种card称为dirty card。和SATB相似,业务线程也不是直接将dirty card放到RSet中的。而是在业务线程中引入一个叫做dirty card queue(DCQ)的队列,在写屏障中,业务线程只需要将dirty card放入DCQ中,而不做非常细致的检查。
接下来,GC线程中,有一类特殊的线程,它们会从DCQ中找到这种dirty card,然后再去做更精细的检查,只有确实不属于上面所描述的三种情况的跨区引用,才真正放到专属RSet中去。这一类特殊的线程就是G1 GC中的Refine线程。
下面我们再来继续剖析RSet存放的形式是怎样的。考虑某个Region的RSet,它可能会因为引用关系比较多,而变得很大。根据另一个Region对这个Region的引用数量,可以分为少、中、多三种情况。针对这三种情况,RSet准备了三种不同的数据结构来应对,分别是稀疏表、细粒度表和粗粒度表。三种表之间的关系是不断粗化的,如下图所示:
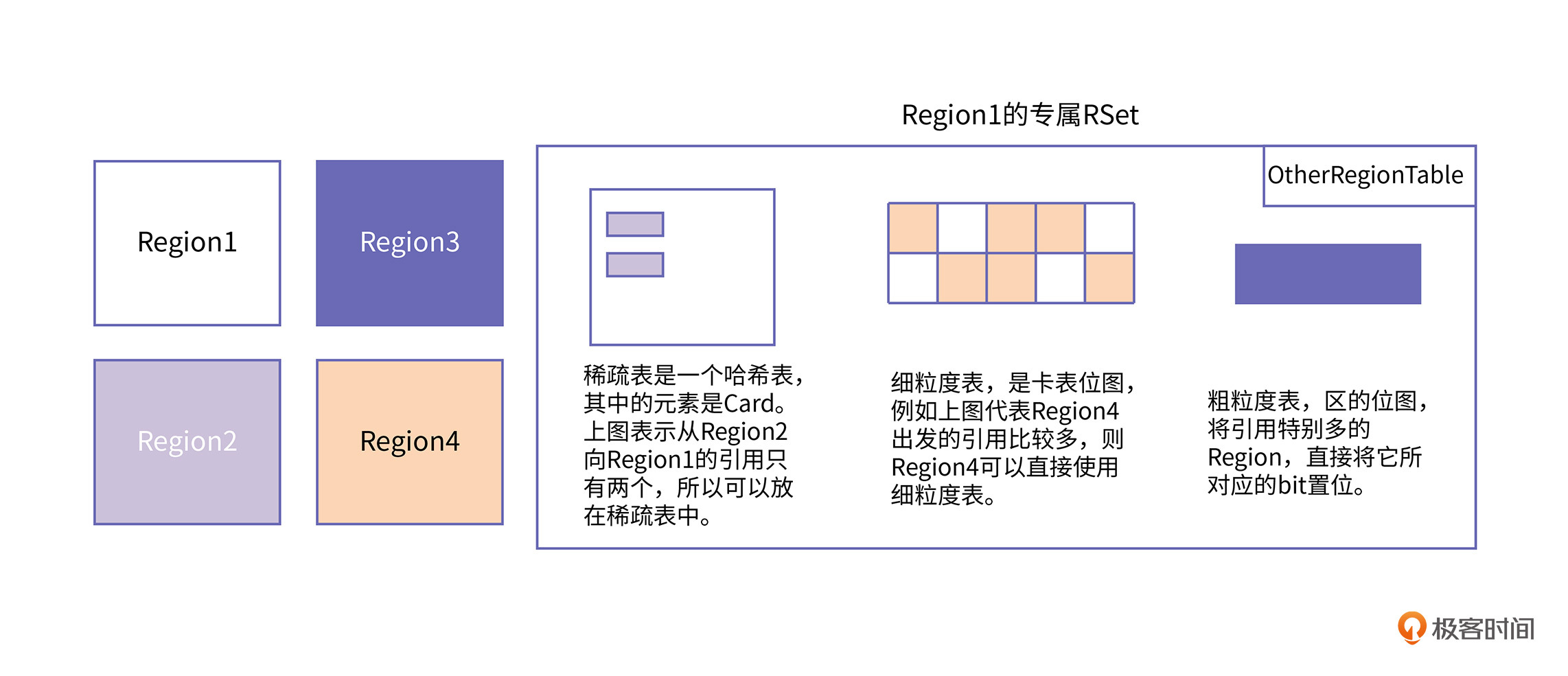
从上图中,我们可以看到:
总之,随着其他Region对本Region的引用关系越多,RSet存放引用关系使用的表粒度就越粗,这样做主要是为了减少RSet记录数,提高定位效率。
在解决了跨区引用的问题之后,接下来我们就可以学习 G1 的垃圾清理过程了,这是垃圾回收器真正回收内存的过程,所以它的重要性不言而喻。
G1的垃圾清理是通过把活跃的对象,从一个Region拷贝到另一个空白Region,这个空白Region隶属于Survivor空间。这个过程在G1 GC中被命名为转移(Evacuation)。它和之前讲到的基于copy的GC的最大区别是:它可以充分利用concurrent mark的结果快速定位到哪些对象需要被拷贝。
接下来让我们通过一个例子,来看看G1 Evacuation的具体过程吧。
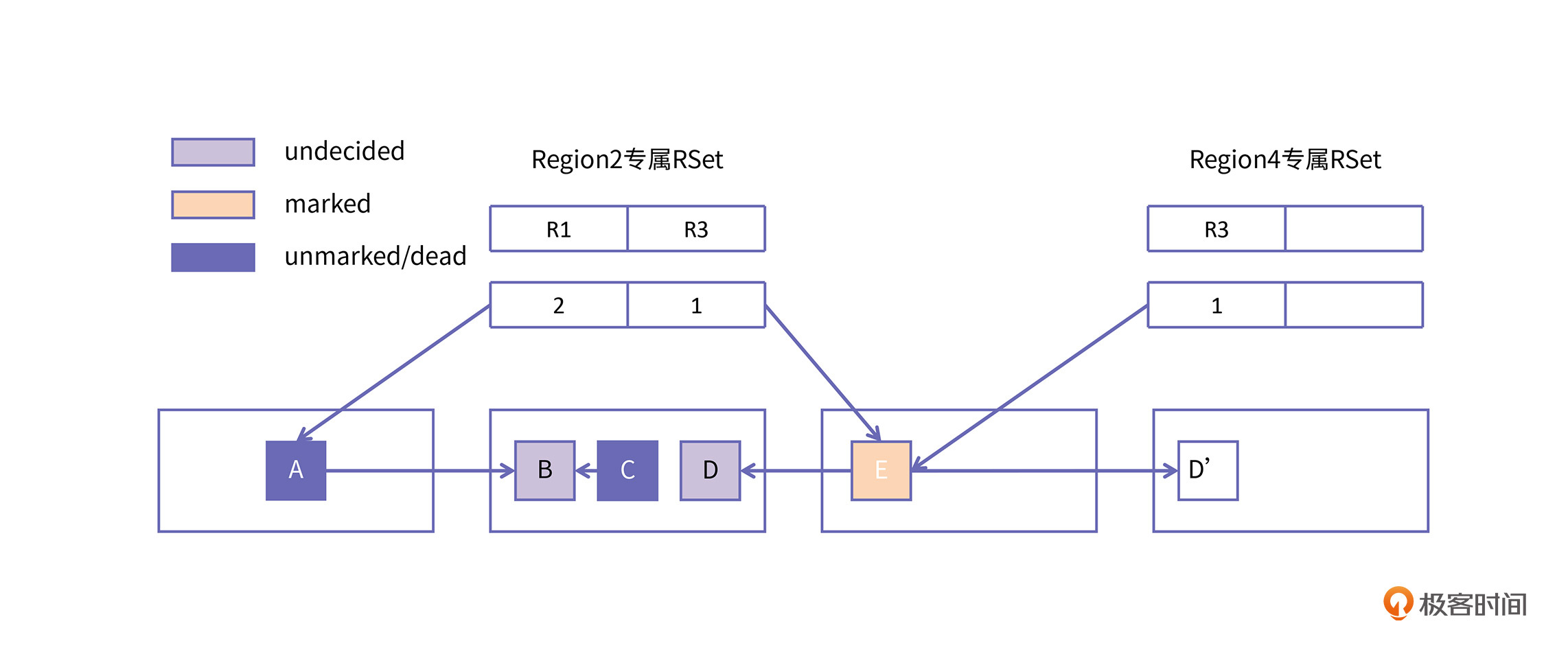
在上图中,Region2是一个待回收的Region,隶属于CSet。在它的专属RSet中记录了Region1 的第二个card和Region3的第一个card,说明Region1和Region3有对Region2的对象引用,Region4 是一个被选为Survivor的空白Region。
假如Region1和Region3都经过了并发标记,识别出A对象是垃圾对象,而E对象是活跃对象。那么,我们就可以从活跃对象E开始进行遍历。注意,这一次遍历的目标是把Region2中的对象搬移到Region4。
Region1中的A是垃圾对象,这在并发标记阶段就已经发现了,所以在转移阶段就不会再起作用了。进而,Region2中的B、C也不会被标记到,最终只有对象D被拷贝到了Region4,与此同时,原始Region2的RSet也会被维护到Region4。
因为Evacuation发生的时机是不确定的,在并发标记阶段也可能发生。所以并发标记要使用一个BitMap来记录活跃对象,而Evacuation也需要使用一个BitMap来将活跃的对象进行搬移。这就产生了读和写的冲突:并发标记需要写BitMap,而Evacuation需要读BitMap。
为了解决这个问题,G1维护了两个BitMap,一个名为nextBitMap,一个名为prevBitMap。其中,prevBitMap是用于搬移活跃对象,而nextBitMap则用于并发标记记录活跃对象。
当并发标记开始以后,新的对象仍然有可能会被继续分配。内存管理器把这些对象全部认为是活跃对象。我们来看下面的这个示意图:
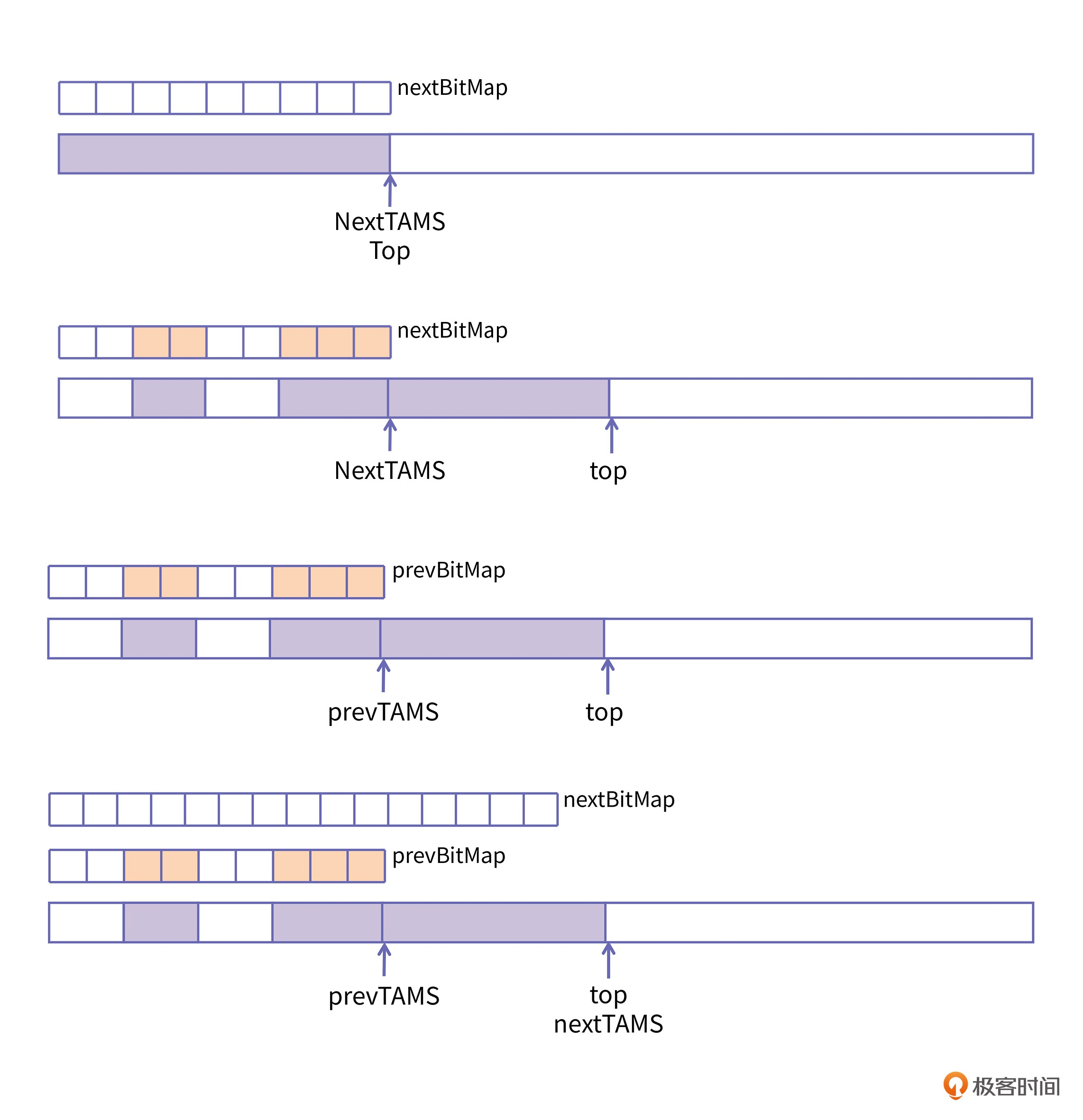
在上图中,TAMS指针,是Top At Mark Start的缩写。初始时,prevTAMS,nextTAMS和top指针都指向一个分区的开始位置。
随着业务线程的执行,top指针不断向后移动。并发标记开始时(图1),nextTAMS记录下当前的top指针,并且针对nextTAMS之前的对象进行活跃性扫描,扫描的结果就存放在nextBitMap中(图2)。
当并发标记结束以后,nextTAMS的值就记录在prevTAMS中,并且nextBitMap也赋值给prevBitMap。如果此时发生了Evacuation,则prevBitMap已经可用了。如果没有发生Evacuation,那么nextBitMap就会清空,为下一轮并发标记做准备。这样就可以保证,在任意时刻开启Evacuation的话,prevBitMap总是可用的(图3)。
在并发标记开始以后,再创建的对象,其实就是nextTAMS指针到top指针之间的对象,这些对象全部认为是活跃的(注意观察图中紫色部分)。
我们再从对象活跃性的角度理解两个TAMS指针和top的关系。当并发标记开始时,nextTAMS就固定了,但是top还是可能继续向后移,所以nextTAMS和top之间的对象在这次标记过程中都被认为是活跃对象。当Evacuation开始时,它只使用prevBitMap的信息,显然prevBitMap中的信息只能覆盖到prevTAMS处,所以从prevTAMS到top的对象就都认为是活跃的。
top指针是一个Region内已分配区域和未分配区域的界限。通过TAMS和BitMap,GC线程可以清楚地知道一个Region内活跃对象的分布,不仅可以确定Evacation的范围,还可以用来计算一个Region的垃圾比例,为CSet选择提供参考。
好啦,关于G1的算法原理,我们就先介绍到这里吧,下面让我们一起看看G1有哪些常用参数吧,因为掌握G1中重要的参数的意义,才能帮助你对G1 GC进行参数调优。
G1的默认参数已经被调整得很好了,大多数情况下,不需要再调整。但是,也不排除特殊情况,因此我们还是需要掌握一些GC参数,具体列表如下:
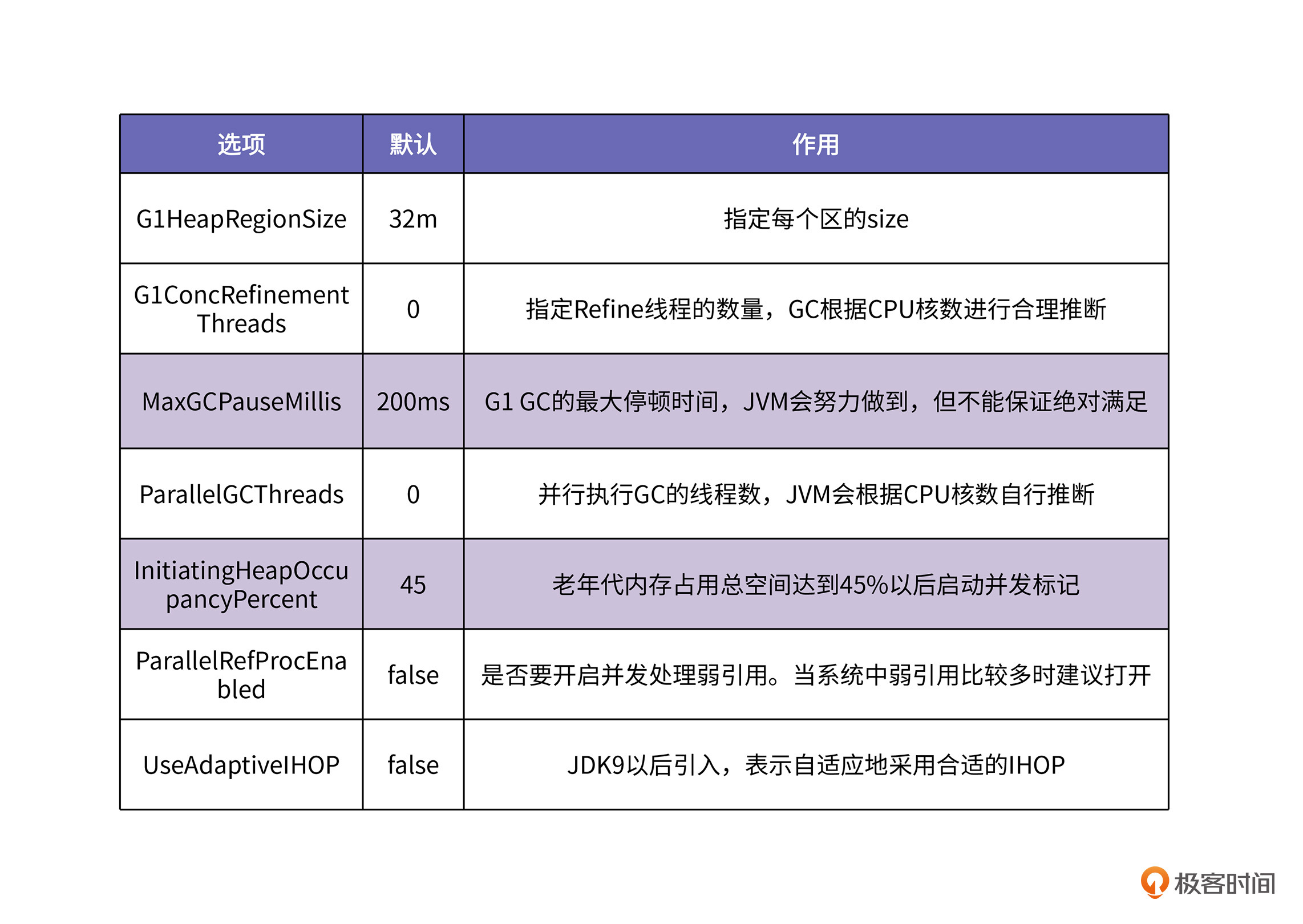
这个表格中最重要、也是你平时最有可能用到的参数,就是MaxGCPauseMillis。它设置了期望的最大停顿时间。MaxGCPauseMillis设置的越小,可以控制的停顿时间就越短。但是如果设置得太短,可能会引起Full GC,代价十分昂贵。
其次,比较关键的参数是InitiatingHeapOccupancyPercent(IHOP),它的作用是在老年代的内存空间达到一定百分比之后,启动并发标记。当然,这更进一步是为了触发mixed GC,以此来回收老年代。如果一个应用老年代对象产生速度较快,可以尝试适当调小IHOP。
好了,今天这节课就到这里来,我们一起来回顾一下这节课的重点内容。这节课,我们首先介绍了G1特点,明确了分区的意义。然后我们讲到了G1的堆空间划分策略,G1的每个分区都可以单独管理,空闲Region可以用来当做Survivor空间,Homongous区是用来存放大对象的,在回收过程中,和老年代同等对待。
然后,我们重点分析了write barrier的两个作用,一个是维护记录集,一个是解决漏标问题。
G1的记录集是与Region一一对应的,是一种point-in类型的记录集。它仍然采用dirty card的设计,将dirty card存放在记录集中。记录集为了管理dirty card,区分了三种粒度,分别是稀疏表,细粒度表和粗粒度表。
解决漏标问题则是采用了SATB的设计,保证了在GC开始的瞬间活跃的对象就始终是活跃的。
接下来,我们解释了G1的两种垃圾回收模式,分别是young GC和mixed GC。young GC只回收年轻代,mixed GC回收全部年轻代和部分老年代。
G1的垃圾清理过程与普通的copy-based不同。我们说,G1的Evacuation可能发生在并发标记阶段,为了保证Evacuation在并发标记阶段可以知道哪些对象是活的、需要被拷贝,我们介绍了两个BitMap和TAMS指针。这样一来,在Evacuation进行的过程中,管理器就有依据判断一个Region中哪些对象是应该被拷贝的。
最后,我还给你讲了在实际工作中需要掌握的几个G1参数,尤其是MaxGCPauseMillis和IHOP。MaxGCPauseMillis用来设置期望最大停顿时间,IHOP用来调整并发标记的处理时机,调整老年代回收的及时性。
请你思考:如何可以进一步减少垃圾回收的最大停顿时间?欢迎在留言区分享你的想法,我在留言区等你。

好啦,这节课到这就结束啦。欢迎你把这节课分享给更多对计算机内存感兴趣的朋友。我是海纳,我们下节课再见!