你好,我是海纳。
在前面的几节课程中,我们学习了 CMS 、G1 等垃圾回收算法,这两类GC算法虽然一直在想办法降低GC时延,但它们仍然存在相当可观的停顿时间。
如何进一步降低GC的停顿时间,是当前垃圾回收算法领域研究的最热点话题之一。今天我们就来学习这类旨在减少GC停顿的垃圾回收算法,也就是无暂停GC(Pauseless GC)。由于Hotspot的巨大影响力和普及程度,以及它的代码最容易获得,我们这节课就以ZGC为例来深入讲解无暂停GC。
而且,ZGC对Java程序员的意义和G1是同样重要的。如果说CMS代表的是过去式,而G1是一种过渡(尽管这个过渡期会很长),那么ZGC无疑就是JVM自动内存管理器的未来。
通过这节课的学习,你就能了解到无暂停GC的基本思想和可以使用的条件,从而为未来正确地使用无暂停GC做好充分的准备。
无暂停GC这个词你可能比较陌生,让你觉得这个算法很难,我们不妨先来了解一下它的前世今生,你就能知其然,经过后面对它原理的讲解,你就能知其所以然了。
JVM的核心开发者Cliff Click供职于Azul Systems公司期间,撰写了一篇很重要的论文,也就是Pauseless GC,提出了无暂停GC的想法和架构设计。同时,Azul公司也在他们的JVM产品Zing中实现了一个无暂停GC,将GC的停顿时间大大减少,这就是C4垃圾回收器。
同时,Red hat公司的GC研究小组也开启了一款名为Shenandoah的垃圾回收器,它的工作原理与C4不同,但它在停顿时间这一项上的表现也非常出色。人们把Shenandoah GC也归为无暂停GC。
时隔多年,Oracle 公司也开发了一款面向低时延的垃圾回收器,它的基本思想和C4垃圾回收器的一致,并且也在openjdk社区开源。
了解了无暂停GC的历史后,我们再分别从功能原理和代码实现上来讨论无暂停GC。从功能原理上看,无暂停GC与CMS、Scanvenge等传统算法不同,它的停顿时间不会随着堆大小的增加而线性增加。以ZGC为例,它的最大停顿时间不超过 10ms ,注意不是平均,也不是随机,而是最大不超过 10ms 。是不是感到很震惊呢?这节课我们就一起揭开ZGC的神秘面纱,探究这极低时延背后的真相。
从代码实现上看,ZGC 很复杂,包含很多细节,整个GC周期甚至划分了十个不同的阶段。代码阅读起来也相当困难。不过不用担心,这节课重点介绍的不是ZGC的代码实现,而是ZGC 背后的原理,当我们理解它的原理之后,再去探究实现细节,才会事半功倍。我们就先从刚才提到的那个问题,也就是它为什么可以做到最大10ms的停顿时间开始吧。
ZGC和G1 有很多相似的地方,它的主体思想也是采用复制活跃对象的方式来回收内存。在回收策略上,它也同样将内存分成若干个区域,回收时也会选择性地先回收部分区域。
ZGC 与G1的区别在于:它可以做到并发转移(拷贝)对象。关于并发转移的概念,这里我还是提醒你一下,并发转移指的是在对象拷贝的过程中,应用线程和 GC 线程可以同时进行,这是其他GC算法目前没有办法做到的。
前面几节课中我们介绍的垃圾回收算法,在进行对象转移时都是需要 “世界停止”(Stop The World,STW)的,而对象转移往往是垃圾回收过程最耗时的一个环节,并且随着堆的增大,这个时间也会跟着增加。ZGC则不同,在应用线程运行的同时,GC线程也可以进行对象转移,这样就相当于把整个GC最耗时的环节放在应用线程后台默默执行,不需要一个长时间的STW来等待。这也正是ZGC停顿时间很小的主要原因。
你可能会问,如何能在应用线程修改对象引用关系的同时,GC线程还能正确地转移对象,或者说GC线程将对象转移的过程中,应用线程是如何访问正在被搬移的对象呢?接下来我就带你了解并发转移的关键技术。
在此之前,我们首先回顾一下并发标记算法的原理。在并发标记的过程中,应用线程可能会修改对象之间的引用关系,为了保证在对象标记的过程中活跃对象不被漏标,我们引入了三色标记算法。虽然三色标记算法会在当前回收周期内产生浮动垃圾,但是不会漏标,而且多标记的垃圾对象也会在下一个回收周期被清理。
在介绍三色标记算法时,我们还讲到了 write barrier 概念。wirte barrier主要是通过拦截写动作,在对象赋值时加入额外操作。这节课,我们就来讲解一个与write barrier对应的操作,它是无暂停GC算法中普遍采用的一个操作,那就是read barrier ,也就是在对象读取时加入额外操作。
通过前面的学习,我们知道CMS算法和G1算法都使用了write barrier来保证并发标记的完整性,防止漏标现象。ZGC的并发标记也不例外,这个技术我们已经深入讨论过了,这里就不再啰嗦了。除此之外,ZGC提升效率的核心关键在于并发转移阶段使用了read barrier。
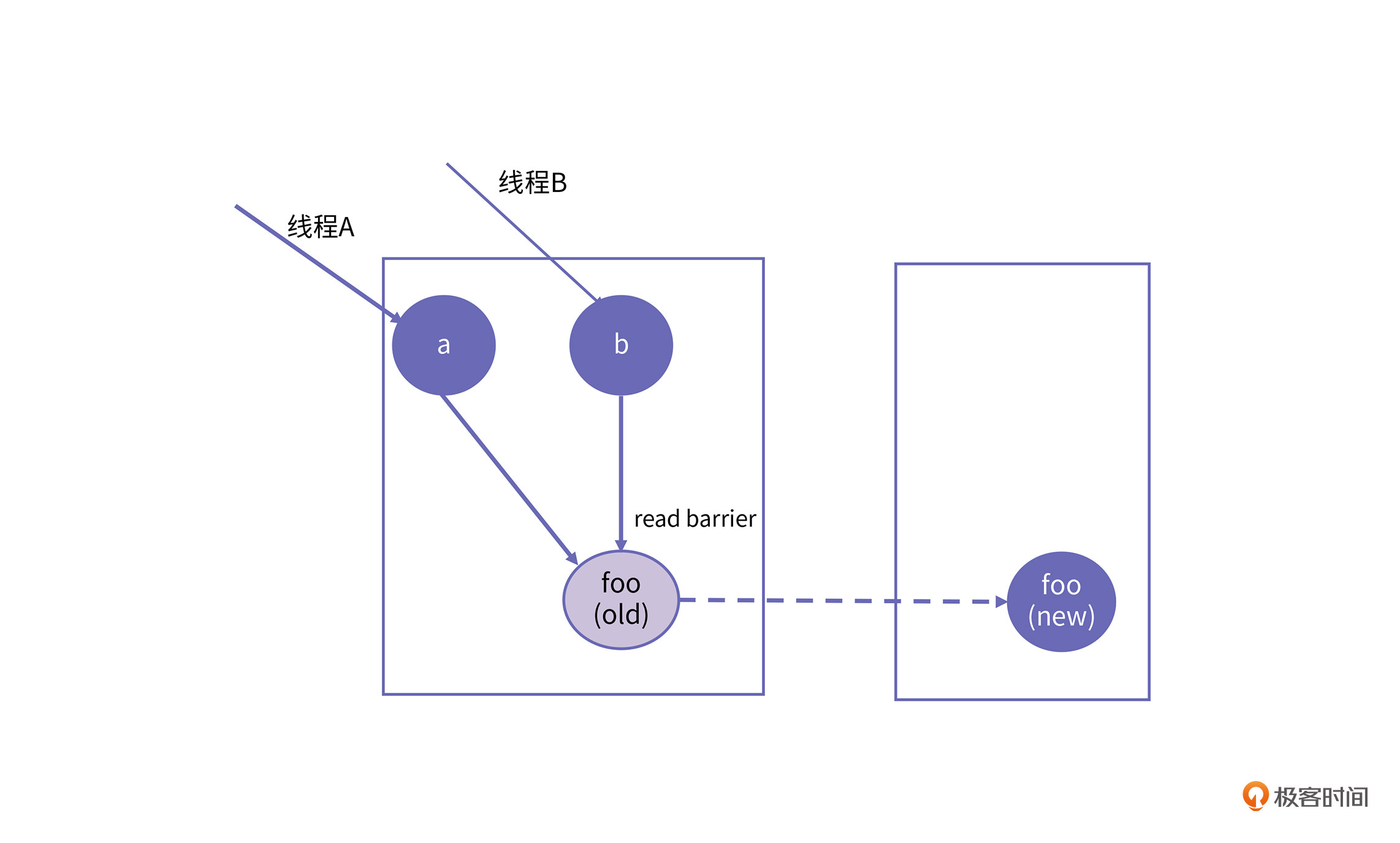
请你试想一下,当应用线程去读一个对象时,GC 线程刚好正在搬移这个对象。如果GC线程没有搬移完成,那么应用线程可以去读这个对象的旧地址;如果这个对象已经搬移完成,那么可以去读这个对象的新地址。那么判断这个对象是否搬移完成的动作就可以由read barrier来完成。
上图中,对象a和对象b都引用了对象foo,当foo正在拷贝的过程中,应用线程A可以访问旧的对象foo得到正确的结果,当foo拷贝完成之后,应用线程B就可以通过read barrier来获取对象foo的新地址,然后直接访问对象foo的新地址。
请你思考一下,如果这里只用 write barrier是否可行?当foo正在拷贝的过程中,应用线程A如果要写这个对象,那么只能在旧的对象foo上写,因为还没有搬移完成;如果当foo拷贝完成之后,应用线程B再去写对象foo,是写到foo的新地址,还是旧地址呢?
如果写到旧地址,那么对象foo就白搬移了,如果写到新地址,那么又和线程A看到的内容不一样?所以使用write barrier是没有办法解决并发转移过程中,应用线程访问一致性问题,从而无法保证应用线程的正确性。因此,为了实现并发转移,ZGC使用了read barrier。
与此同时,我们还需要关注一个问题,就是在大多数的应用中,读操作要比写操作多一个数量级,所以read barrier对性能更加敏感(ZGC最初的设计目标之一是吞吐量不低于G1的15%),这就要求read barrier要非常高效。
为了达到这个目的,ZGC采用了用空间换时间的做法,也就是染色指针(colored pointer)技术。通过这个技术,ZGC不仅非常高效地完成了read barrier需要完成的工作,而且可以更高效的利用内存。接下来我们就看看染色指针是怎么一回事吧。
我们知道,在 64 位系统下,当前Linux系统上的地址指针只用到了 48 位,寻址范围也就是 256T。但实际上,当前的应用根本就用不到256T内存,也没有哪台服务器机器上面可以一下插这么多内存条。所以, ZGC 就借用了地址的第 42 ~ 45 位作为标记位,第 0 ~ 41位共 4T 的地址空间留做堆使用。我们结合 JVM 的源码来看看ZGC中对地址具体是怎么标注的。
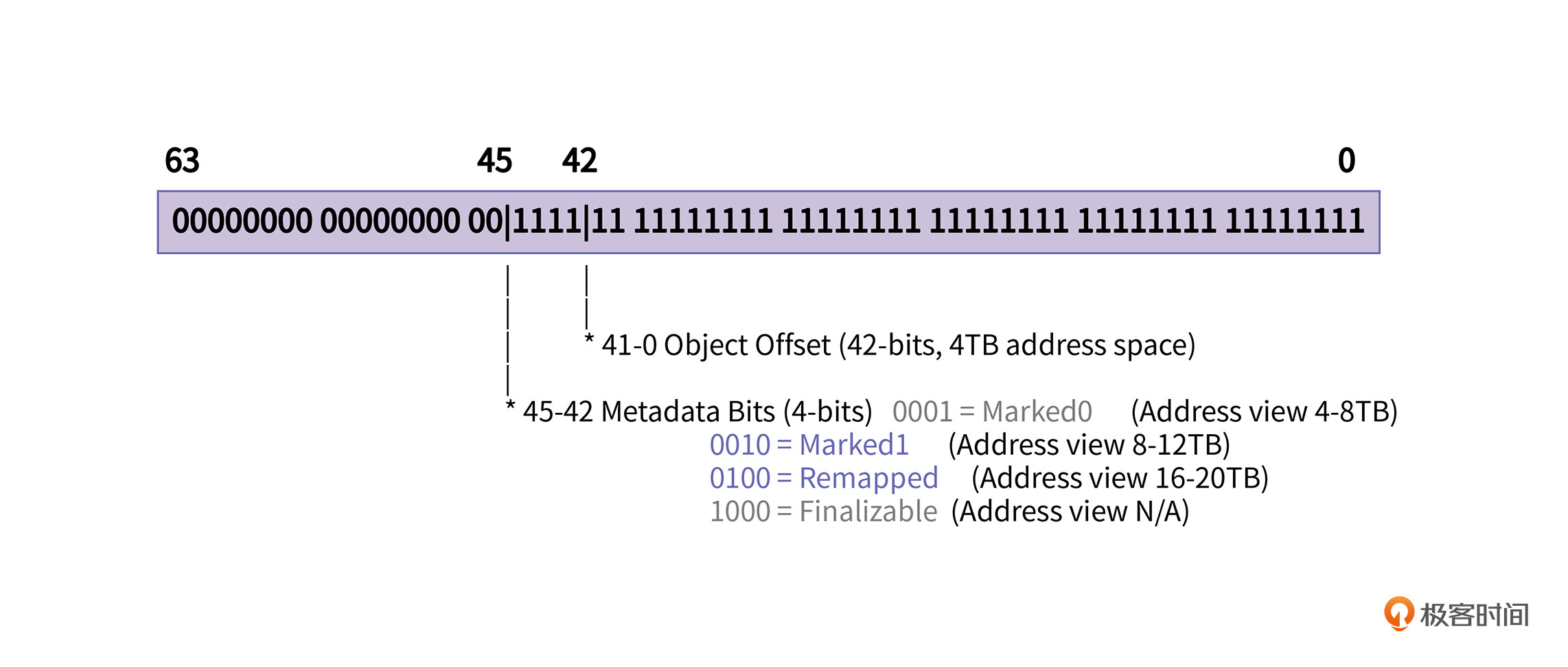
通过上图我们可以看出,第 46 和 47 位是预留的,也就是说标记位可以继续向左移两位,那么可以支持的堆空间就可以扩展到 16T。当前很多资料说 ZGC只支持 4T 内存,实际上现在最新版本已经支持到了 16T,如果你特别感兴趣的话,我建议你可以下载 openJDK 的源码进行查看。
第 42-45 这 4 位是标记位,它将地址划分为 Marked0、Marked1、Remapped、Finalizable 四个地址视图(由于Finalizable与弱引用的实现有关系,我们这里只讨论前三个)。
地址视图应该怎么理解呢?其实很简单,对一个对象来说,如果它地址的第 42 位是 1,那么它就被认为是处于 Marked0 视图。依次类推,如果第 43位是1,这个对象就处于Marked1 视图;如果第 44 位是1,该对象就处于Remapped 视图。
地址视图的巧妙之处就在于,一个在物理内存上存放的对象,被映射在了三个虚拟地址上。前面我们学习地址映射的时候知道,一个物理地址可以被映射到多个虚拟地址,这个映射方式在同一个进程内同样适用。例如下面的代码:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <unistd.h>
#define PAGE_SIZE 4096
int main() {
int fd = memfd_create("anonymous", MFD_CLOEXEC);
ftruncate(fd,PAGE_SIZE);
char* shm0 = (char*)mmap(NULL, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
char* shm1 = (char*)mmap(NULL, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
char* shm2 = (char*)mmap(NULL, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
sprintf(shm0 ,"hello colored pointer");
printf("%s\n",shm1);
printf("%s\n",shm2);
sprintf(shm1 ,"wow!");
printf("%s\n",shm0);
printf("%s\n",shm2);
close(fd);
munmap(shm0,PAGE_SIZE);
munmap(shm1,PAGE_SIZE);
munmap(shm2,PAGE_SIZE);
return 0;
}
使用以下命令,编译并执行这个程序:
$ gcc -Wall -D_GNU_SOURCE multi_mmap.c -o multi
$ ./multi
上面的例子先在内存中创建了一个匿名文件(第10行),然后将这个匿名文件映射到shm0,shm1,shm2三个虚拟地址上(第12-14行)。当我们修改shm0时,shm1和shm2的内容也会跟着变化。地址视图也是用了同样的原理,三个地址视图映射的是同一块物理内存,映射地址的差异只在第42-45位上。这样一个对象可以由三个虚拟地址访问,其访问的内容是相同的。
有了地址视图之后,我们就可以在一个对象转移之后,修改它的地址视图了,同时还可以维护一张映射表(下称forwarding table)。在这个映射表中,key 是旧地址,value 是新地址。当对象再次被访问时,通过插入的read barrier 来判断对象是否被搬移过。如果forwarding table中有这个对象,说明当前访问的对象已经转移,read barrier这时就会将对这个对象的引用直接更改为新地址。
我还是举一个例子来说明,搬移一个对象以及访问它的引用所需要的步骤,如下图所示:
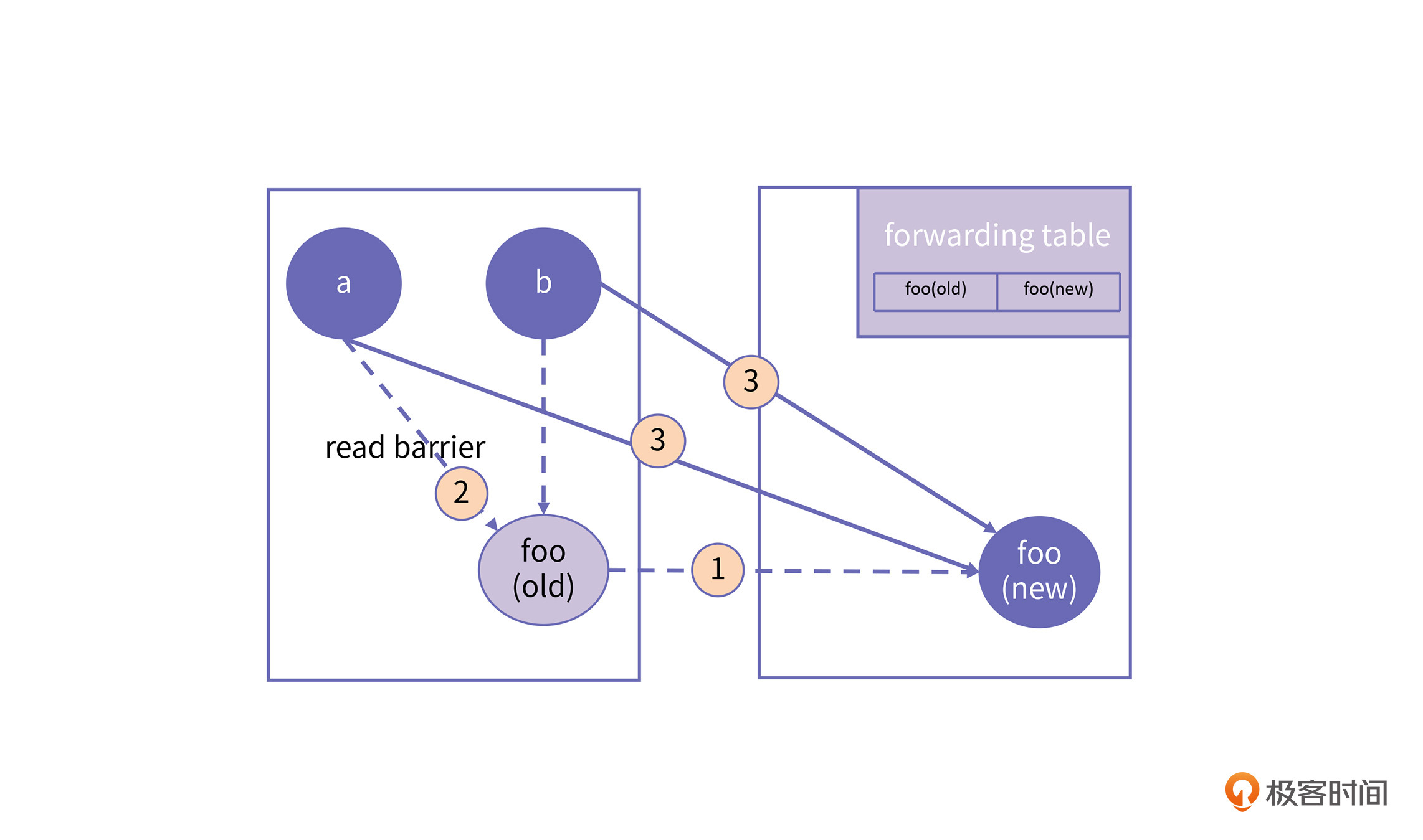
上图中,当foo对象发生转移之后,对象a再访问foo时就会触发read barrier。read barrier会查找forwarding table来确定对象是否发生了转移,确定foo被转移到新地址foo(new)之后,直接将这一次对foo的访问更改为foo(new)。由于整个过程是依托于read barrier自动完成的,这个过程也叫“自愈”。在介绍了 ZGC的关键技术之后,我们来重点讲下 ZGC 的回收原理。
ZGC虽然在实现上有十个左右的小步骤,但在总体思想上可以概括为三个核心步骤,我们通过Pauseless GC原始论文的内容来介绍。
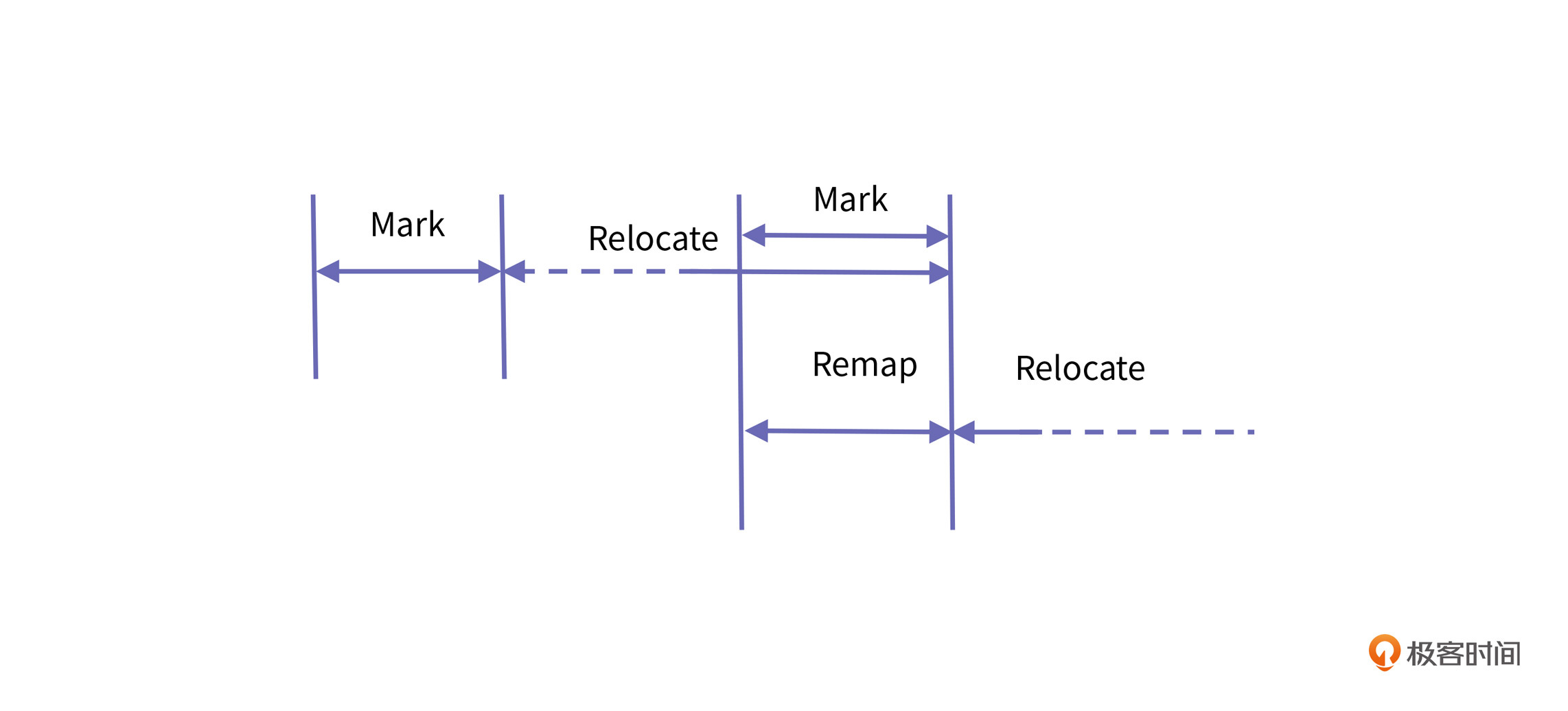
在这张图中,你可以看到 Pauseless 的三个核心步骤分别是:Mark、Relocate和 Remap。接下来我们就简单了解下这三个核心步骤都做了哪些事情。按照步骤的先后顺序,我们先来介绍Mark。
事实上,ZGC 也不是完全没有 STW 的。在进行初始标记时,它也需要进行短暂的 STW。不过在这个阶段,ZGC只会扫描 root,之后的标记工作是并发的,所以整个初始标记阶段停顿时间很短。也正是因为这一点,ZGC 的最大停顿时间是可控的,也就是说停顿时间不会随着堆的增大而增加。
初始标记工作完成之后,就可以根据 root 集合进行并发标记了。前面我们提到的三个地址视图 Marked0、Marked1、Remapped 在这里就起了作用。
在 GC 开始之前,地址视图是 Remapped。那么在 Mark 阶段需要做的事情是,将遍历到的对象地址视图变成 Marked0,也就是修改地址的第 42 位为 1。前面我们讲过,三个地址视图映射的物理内存是相同的,所以修改地址视图不会影响对象的访问。
除此之外,应用线程在并发标记的过程中也会产生新的对象。类似于 G1 中的 SATB 机制,新分配的对象都认为是活的,它们地址视图也都标记为 Marked0。至此,所有标记为 Marked0 的对象都认为是活跃对象,活跃对象会被记录在一张活跃表中。
而视图仍旧是Remapped 的对象,就认为是垃圾。接下来,我们进入 Relocate 阶段,也就是转移阶段。
Relocate 阶段的主要任务是搬移对象,在经过 Mark 阶段之后,活跃对象的视图为 Marked0。搬移工作要做两件事情:
关于第一点,我们前面提到ZGC是分块的,块区域叫Page;G1也是分块的,只不过被分成的块叫Region。虽然细节上有些差异,但它们总体的思想是类似的。
至于forwarding table,我们在前面也提到过,它是一张维护对象搬移前和搬移后地址的映射表,key是对象的旧地址,value是对象的新地址。
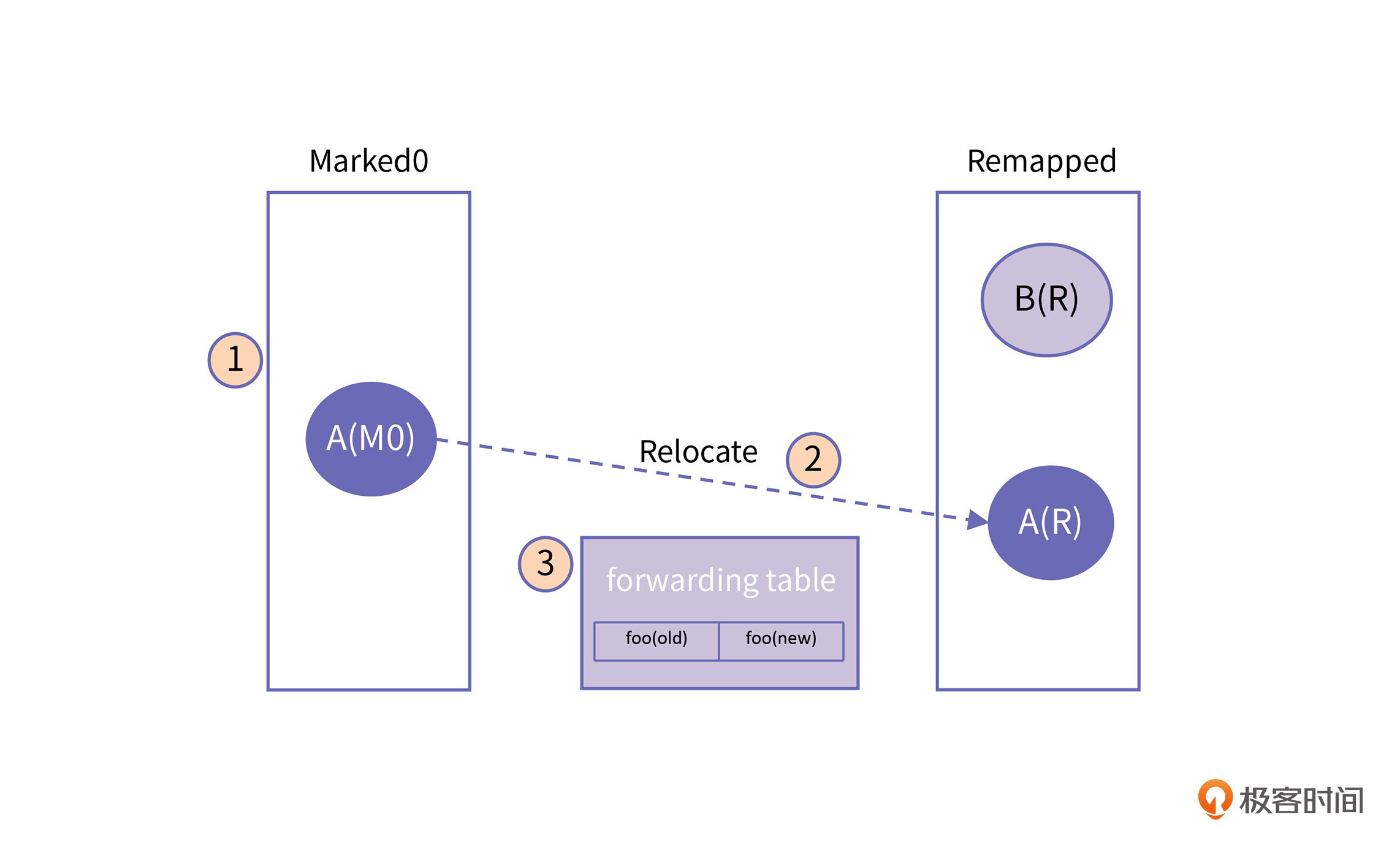
在Relocate阶段,应用线程新创建的对象地址视图标记为Remapped。如果应用线程访问到一个地址视图是Marked0的对象,说明这个对象还没有被转移,那么就需要将这个对象进行转移,转移之后再加入到forwarding table,然后再对这个对象的引用直接指向新地址,完成自愈。这些动作都是发生在read barrier中的,是由应用线程完成的。
当 GC 线程遍历到一个对象,如果对象地址视图是 Marked0,就将其转移,同时将地址视图置为 Remapped,并加入到forwarding table ;如果访问到一个对象地址视图已经是 Remapped,就说明已经被转移了,也就不做处理了。
那么关于三个地址视图我们已经用到了其中两个,你一定好奇Marked1视图什么时候使用。接下来我们就进入Remap阶段,为你揭晓Marked1视图的作用。
Remap阶段主要是对地址视图和对象之间的引用关系做修正。因为在Relocate阶段,GC线程会将活跃对象快速搬移到新的区域,但是却不会同时修复对象之间的引用(请注意这一点,这是ZGC和以前我们遇到的所有基于copy的GC算法的最大不同)。这就导致还有大量的指针停留在Marked0视图。
这样就会导致活跃视图不统一,需要再对对象的引用关系做一次全面的调整,这个过程也是要遍历所有对象的。不过,因为Mark阶段也需要遍历所有对象,所以,可以把当前GC周期的Remap阶段和下一个GC周期的Mark阶段复用。
但是由于Remap阶段要处理上一轮的Marked0视图指针,又要同时标记下一轮的活跃对象,为了区分,可以再引入一个Mark标记,这就是Marked1标志。可以想象,Marked0和Marked1视图在每一轮GC中是交替使用的。
在Remap阶段,新分配对象的地址视图是Marked1,如果遇到对象地址视图是Marked0或者Remaped,就把地址视图置为Marked1。具体过程如下图所示:
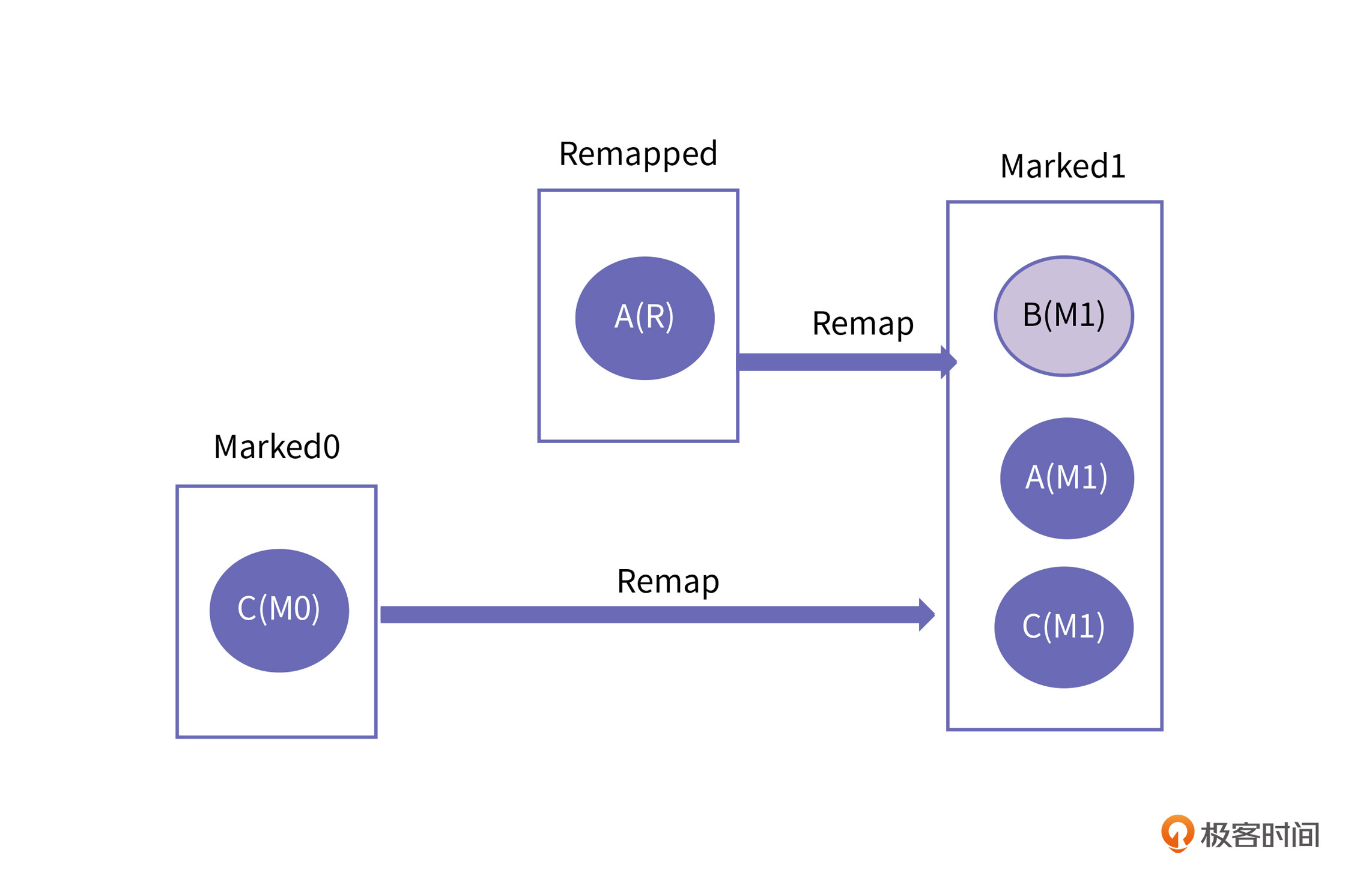
这个过程结束以后,就完成了地址视图的调整,同时也完成了新一轮的Mark。可以看到,Marked0和Marked1其实是交替进行的,通过地址视图的切换,在应用线程运行的同时,默默就把活对象搬走了,把垃圾回收了。
好了,关于ZGC的回收原理我们就讲到这里。ZGC的回收过程大致分为三个主要阶段,其中Mark阶段负责标记活跃对象、Relocate阶段负责活跃对象转移、ReMap阶段负责地址视图统一。因为Remap阶段也需要进行全局对象扫描,所以Remap和Mark阶段是重叠进行的。
好啦,这节课到这里就结束啦。这节课,我们先介绍了无暂停GC的发展历史,然后介绍了无暂停回收算法的特点,那就是能够将垃圾回收的最大停顿时间控制在10ms以内,并且停顿时间不会随着堆的增大而线性增加。
我们选取了openjdk的ZGC作为举例,详细介绍了ZGC停顿时间的真相,同时也分析了ZGC的回收原理。ZGC之所以能够做到这么低的停顿时间,是因为它的大部分工作都是并发执行的,其中也包括了垃圾回收过程中最耗时的对象转移阶段。
ZGC能够做到并发转移,背后有两大关键技术,分别是read barrier和colored pointer。read barrier的作用在于应用线程可以在对象转移之后,通过forwarding table实现"自愈"。而colored pointer实现了地址视图,十分高效地完成了read barrier需要完成的工作,在实现并发转移的同时,保证吞吐率不出现大幅下降。
最后我们介绍了ZGC的回收原理,整个回收过程可以大致分为Mark、Relocate、Remap三个阶段,其中Mark和Remap阶段是可以重叠的。
GC开始时,地址视图为Remapped,Mark阶段的主要工作是标记活跃对象,然后将地址视图向Marked0迁移,处于Marked0的对象都被认为是活跃对象。
Relocate阶段开始时,地址视图为Marked0,该阶段主要做对象搬移工作,将地址视图向Remapped迁移。应用线程如果访问一个已经被转移的对象,就会触发read barrier,完成“自愈”,最终访问的是Remapped视图的新对象。
而Remap阶段是地址视图的修复阶段,在Remap阶段开始时,地址视图为Remapped。Remap阶段的功能是做地址视图统一,对于仍处于Marked0 和 Remaped视图的活跃对象,将其地址视图更新为Marked1。当然也可以是对于仍处于Marked1 和 Remaped视图的活跃对象,将其地址视图更新为Marked0。Remap和Mark阶段交替进行,交替操作Marked0和Marked1视图。
通过地址视图的切换以及使用read barrier完成对象“自愈”过程,使得ZGC能够高效、准确的完成并发转移,大大降低了垃圾回收过程中的停顿时间,以至于达到无暂停GC的效果。
好啦,以上就是无暂停垃圾回收算法的核心内容了。
请你思考一下:ZGC在对象转移之后旧对象原来占用的内存空间是否可以重复利用?请你结合colored pointer的功能思考。一点提示:可以思考一下为什么不使用forwarding指针技术,而要使用forwarding table呢?欢迎在留言区分享你的想法,我在留言区等你。

好啦,这节课到这就结束啦。欢迎你把这节课分享给更多对计算机内存感兴趣的朋友。我是海纳,我们下节课再见!