你好,我是胜辉。这节课,咱们来聊聊TCP的保活机制。
以前的电视剧里经常会有这样的剧情:女主因为车祸失去了记忆,男主一边摇着女主的肩膀,一边痛苦地问道:“还记得我吗?我是欧巴啊!”可是女主已经对此毫无记忆,迷茫地反问道:“欧巴是谁?”
类似地,TCP其实也需要一种机制,让双方能保持这种“记忆”。Keep-alive这个词,你可能也听说过。特别是当遇到一些连接方面的报错的时候,可能有人会告诉你“嗯,你需要设置下Keep-alive”,然后问题确实解决了。
不过,你有没有深入思考过这样几个问题呢:
如果你对这几个问题的答案还不清楚,那么这节课,我就来帮助你厘清这些概念。以后你再遇到长连接失效、被重置、异常关闭等问题的时候,就知道如何通过抓包分析,解读出心跳包相关的信息,然后运用Keep-alive的相关知识点,去真正解决前面说的一系列问题。
好,按惯例,我们还是从案例说起。
当时我在云计算公司就职,有个客户的应用基于TCP长连接,但长连接经常中断,引起了应用方面的大量报错。由于客户的业务是支付相关的,对实时性和安全性要求很高,这类报错就产生了较大的负面影响,所以急需解决。
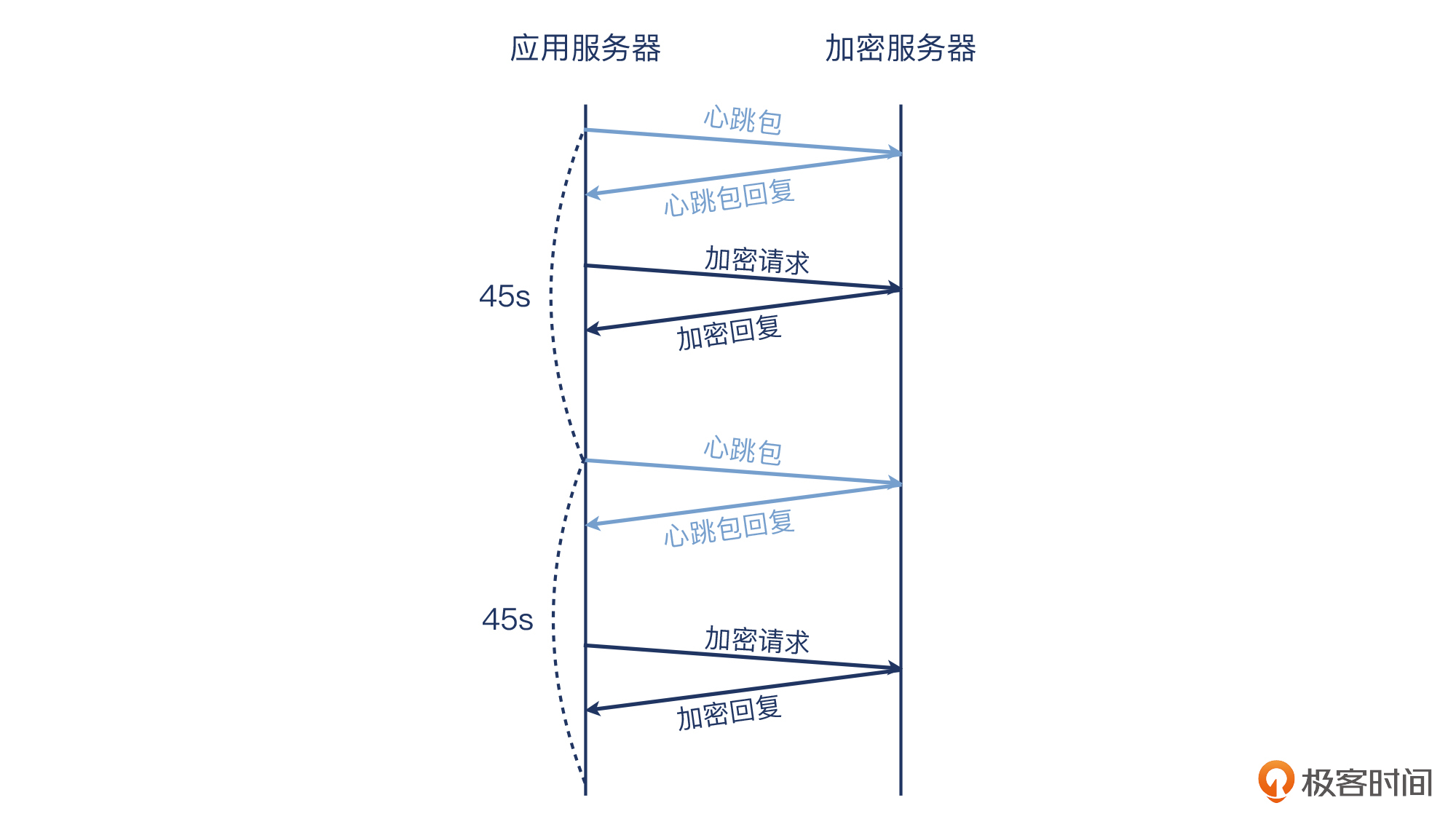
这个应用的架构比较简单:客户在云平台上部署了多台云主机,其中一台云主机专门做加解密,称之为加密服务器。另外几台云主机作为这台加密服务器的客户端,跟这台加密服务器保持TCP长连接。这些客户端会不时地跟加密服务器进行通信,完成加密操作。每45秒,客户端还会发送一次心跳包,这有两个作用:
就像下图这样:
如果加密服务器能在1秒内对心跳包进行回复,那么客户端就认为服务端正常可用,后续的数据交互(即加密请求)将继续在这条长连接上进行。而如果服务端未能在1秒内回复,那么客户端会认为该长连接已经中断,于是重启应用,发起一条新的长连接,并在日志中记录一次报错。
用类Python语法来描述,大体是这样的:
while true:
sleep(45)
if Keep_alive_probe() is true:
continue
else:
log_error()
restart()
整体的排查思路跟网络分层模型有点类似,逐层往下。我们需要先从应用层查找原因,然后是操作系统层面,最后是网络层分析。排查的顺序就是这样的:
应用层代码 -> 操作系统的时间配置 -> 网络的抓包分析
首先,客户自查了应用,没有发现可疑代码,并且尝试过重新部署代码、重装系统、更换IP等,但都未奏效。
那么,会不会是时间服务(ntp)的问题呢?我们检查了两侧机器的ntpd服务的状态,都是正常的。对比了两端机器的实际时间,也没有发现明显的误差。于是这个可能性也被排除了。
然后就需要排查网络了。我们在一台客户端上启动了抓包程序tcpdump,过滤条件是对端加密服务器的IP和端口。抓多久呢?因为问题大约十几分钟出现一次,那么按照这个频率,我们设定抓包时长为半个小时,得到了抓包文件。这样就能覆盖到一到两次的错误了。
补充:抓包示例文件已经上传至Gitee,建议用Wireshark打开文件,结合文稿学习。
因此,通过检查应用日志,我们发现在抓包时间段内,应用日志又记下了两次报错,比如下面这个:
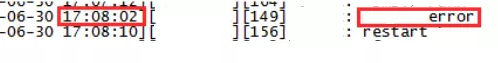
从日志上看,17:08:02这个时间点发生了一次报错,17:08:10发生了一次程序的重启。
有了应用层的信息,接下来,我们就需要在抓包文件中,找到传输层和网络层的信息来与应用层信息对应,这样排查工作才能继续推进。
但是日志记录的时间戳粒度太粗了,只精确到了秒级,而网络报文在Wireshark中都是微秒级的,一秒内可能会有成百上千个报文。所以,仅凭精确到秒的一个时间戳,还不足以让我们在几十个报文中,精确地找到对应的报文。这个时候,我们需要调整一下抓包文件分析工作的切入点。
一个常规的做法是,跳过案例本身的问题特殊性不谈,先从宏观上把握一下排查思路。也就是先不纠结于根据日志时间来寻找报文的难题,而是先看Expert Information,找一找有没有比较可疑的报文。打开Expert Information窗口,如下:

可见,有80个Error级别的Malformed Packet(格式错误)报文和2个RST报文,都很可疑。
我们先看这80个Malformed Packet报文,这传递了什么信息呢?在Protocol栏显示SIGCOMP,说明Wireshark认为这80个报文是SIGCOMP协议的(SIP的信令压缩协议)。不过,客户的应用不是SIP相关的,显然这些报文应该是被Wiresharek误会了。
在这里,我也给你一个小小的提醒:毕竟只有被公开广泛支持的数据格式和协议才能在Wireshark中正确展示,所以如果你看到类似这种Malformed Packet的时候,还是要统筹考虑当前案例的实际情况,未必Malformed报文就真的是格式错误,也可能只是Wireshark不了解某种“方言”而已。
让我们看看这些报文究竟是什么。点开Error,选中一个报文。比如我这里选择37号报文:

随后光标会自动定位到37号报文这里:

然后选了另外几个Malformed Packet,发现它们都是成对出现的。它们还有一个特征是:
这就像是某种“联动”机制了,会不会就是心跳报文呢?你注意下TCP Seglen这一栏(这是我添加的表示TCP载荷长度的列),有没有发现这类报文的长度都是1 ?我们就以 tcp.len eq 1 为过滤器,过滤出报文:
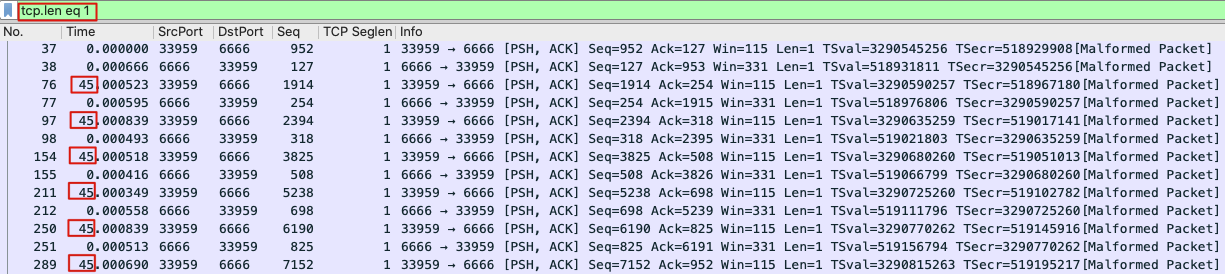
可见,37和38是0秒发生的,76和77是45秒后发生的,然后98和154以及后面每一对报文,也都符合45秒间隔的规律,正好跟客户程序的45秒心跳包机制对上了。我们可以确认这些报文就是心跳报文了!更确切地说,每次成对出现的两个报文中:
这是第一个比较明显的进展。也就是说,我们已经可以找到应用层的心跳包在网络层的展示形式了,这对于后续的排查非常有帮助。
不过,也不要忘了,我们是来排查“心跳包失败导致连接中断”的问题的,现在只是找到了心跳包的特征,还需要找到真正的跟日志报错相关的报文,而这个报文是跟“连接中断”现象有关的。
那么会是什么样的报文呢?其实,我们在第4讲就研究过TCP挥手。你应该还记得,TCP的连接断开,无非跟两种报文有关:FIN和RST。
我们先尝试寻找FIN报文。输入过滤器:
tcp.flags.fin eq 1
结果发现什么报文都没有出来。可见,这次抓包里,连接的断开并不是用FIN完成的。
接着就是寻找RST报文。其实,在Expert Information里面,就有2个RST报文,我们可以直接从那里入手。当然,用过滤器也同样方便,输入:
tcp.flags.reset eq 1
我们能找到2个RST报文:

我们选中575号报文,然后Follow -> TCP Stream,得到了这个RST所在的TCP流的全部报文:
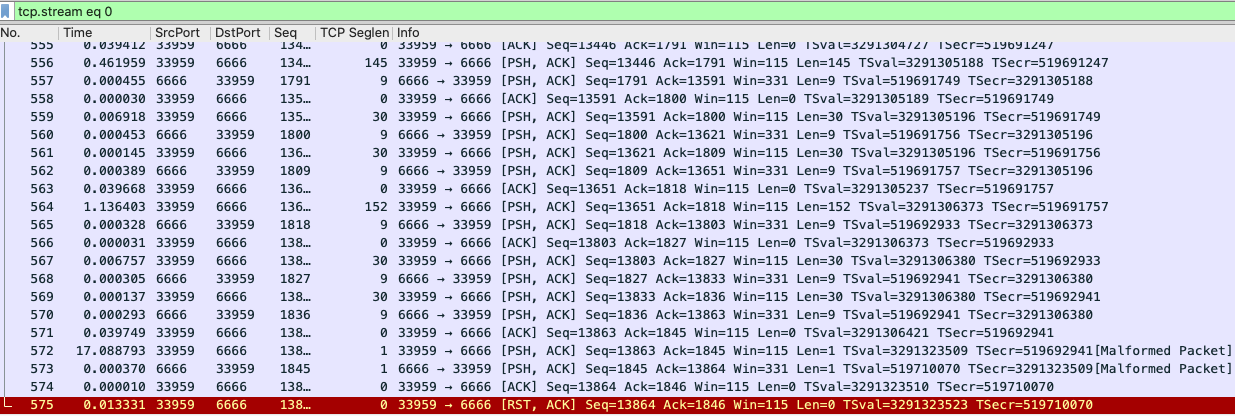
报文很多,上图显示的只是一部分报文。我往前翻阅了更前面的报文,也能看到很多相对长的时间间隔,有17秒、39秒、11秒的,但也没有什么规律。这时候,我们就需要结合前面刚分析到的一些信息,要不然就要在报文的海洋里迷失方向了。
我们通过前面的分析发现,心跳探测包的报文数据是01,心跳回复包的报文数据是41。所以,让我们再次借助强大的过滤器。在 tcp.stream eq 0 后面添加 and tcp.payload eq 01,即整体过滤器变为:
tcp.stream eq 0 and tcp.payload eq 01
这样就过滤出了这个TCP流里面,所有的心跳探测包:
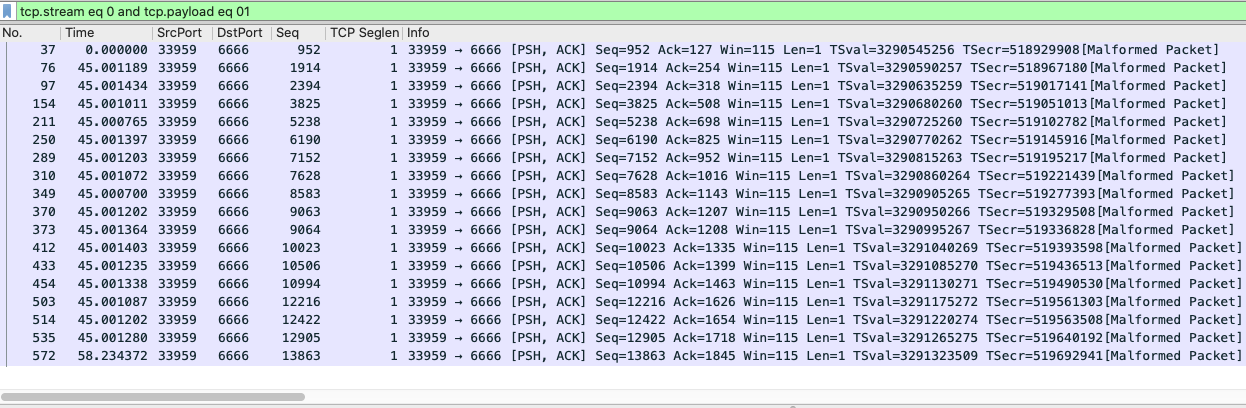
可见,这些心跳探测包也是很明显遵循了45秒间隔的规律。不过,等一下,为什么572号心跳探测包跟它的上一次心跳探测,间隔的时间是58秒,而不是45秒呢?

这很反常,也是第二个很重要的发现。要知道,这45秒的机制是在代码里实现的,照理说不可能出现13秒这么大的误差。现在,我们把 tcp.payload eq 01 这个条件去掉,回到这个TCP流的完整报文区域来综合分析:
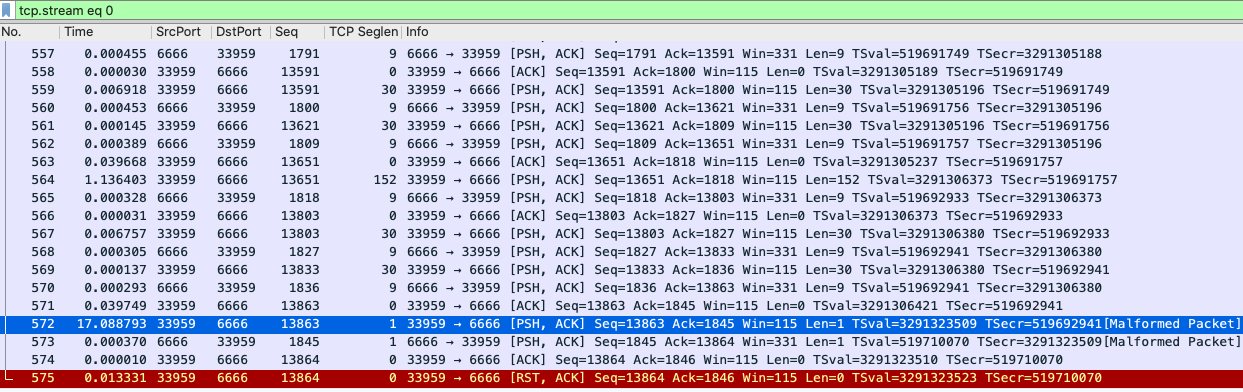
我来给你解读一下:
以上4个报文之间几乎没有时间上的停顿。这里,你可能会有个小疑问:为什么572号报文跟上一个报文的间隔是17秒而不是45秒呢?其实,这是Time列的类型导致的,我这里用的是Delta time displayed类型,是跟前一个被显示的报文的间隔时间。
之前我们看到很多个整齐的45秒,是因为那个窗口里显示的报文,都是过滤过的心跳报文,跟这里显示的报文不同,所以显示的间隔时间也不同。Wireshark里的Time一列有多种配置可选,所以你一方面要理解这里面各种Time的区别,一方面自己做分析的时候,也可以根据实际需要,灵活选择Time类型。
考虑到这里的问题就是跟心跳包和挥手包直接相关,排除掉无关报文,可以让我们的分析思路也变得更加清晰。所以,我们再一次调整过滤器,改为:
tcp.stream eq 0 and (tcp.len == 1 or tcp.flags.reset == 1)
就得到这个TCP流里面的心跳包和挥手包:
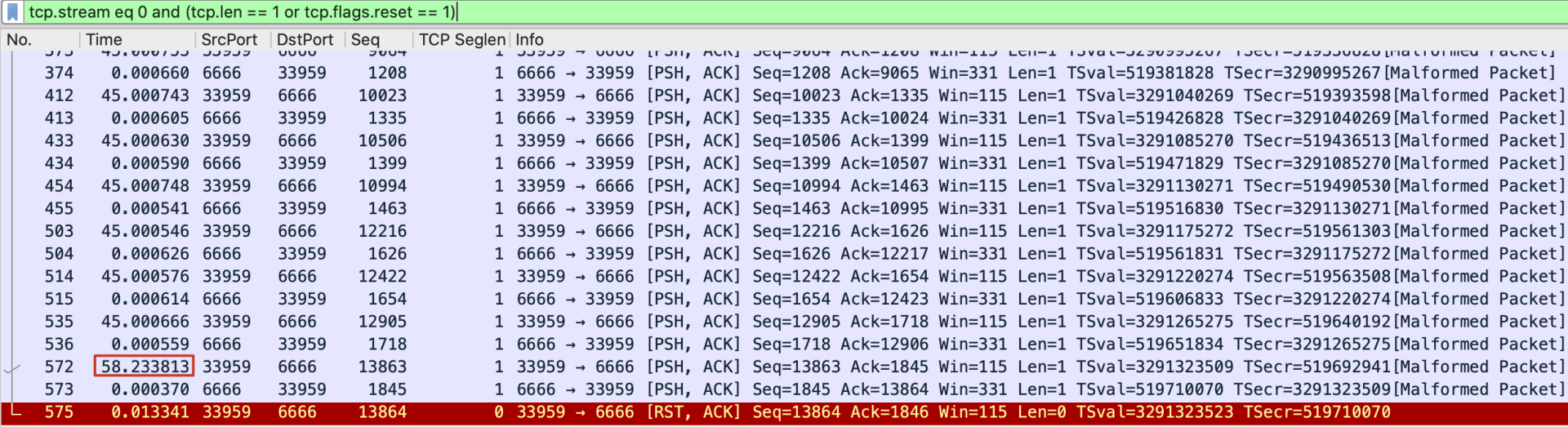
我们最后再确认一下时间戳。这个隔了58秒才发出的心跳包,发送的时间是在17:08:10:
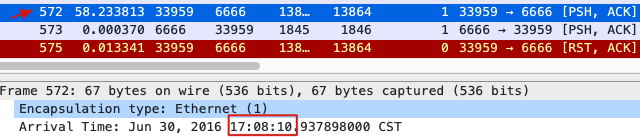
跟日志中restart时间一致:

现在,事实已经很清楚了:客户端在连接被断开之前的心跳探测包,并没有遵循客户声称的“每隔45秒”,而是很意外地隔了58秒。我们结合程序逻辑,已经可以推断出真实的状况了。看示意图:
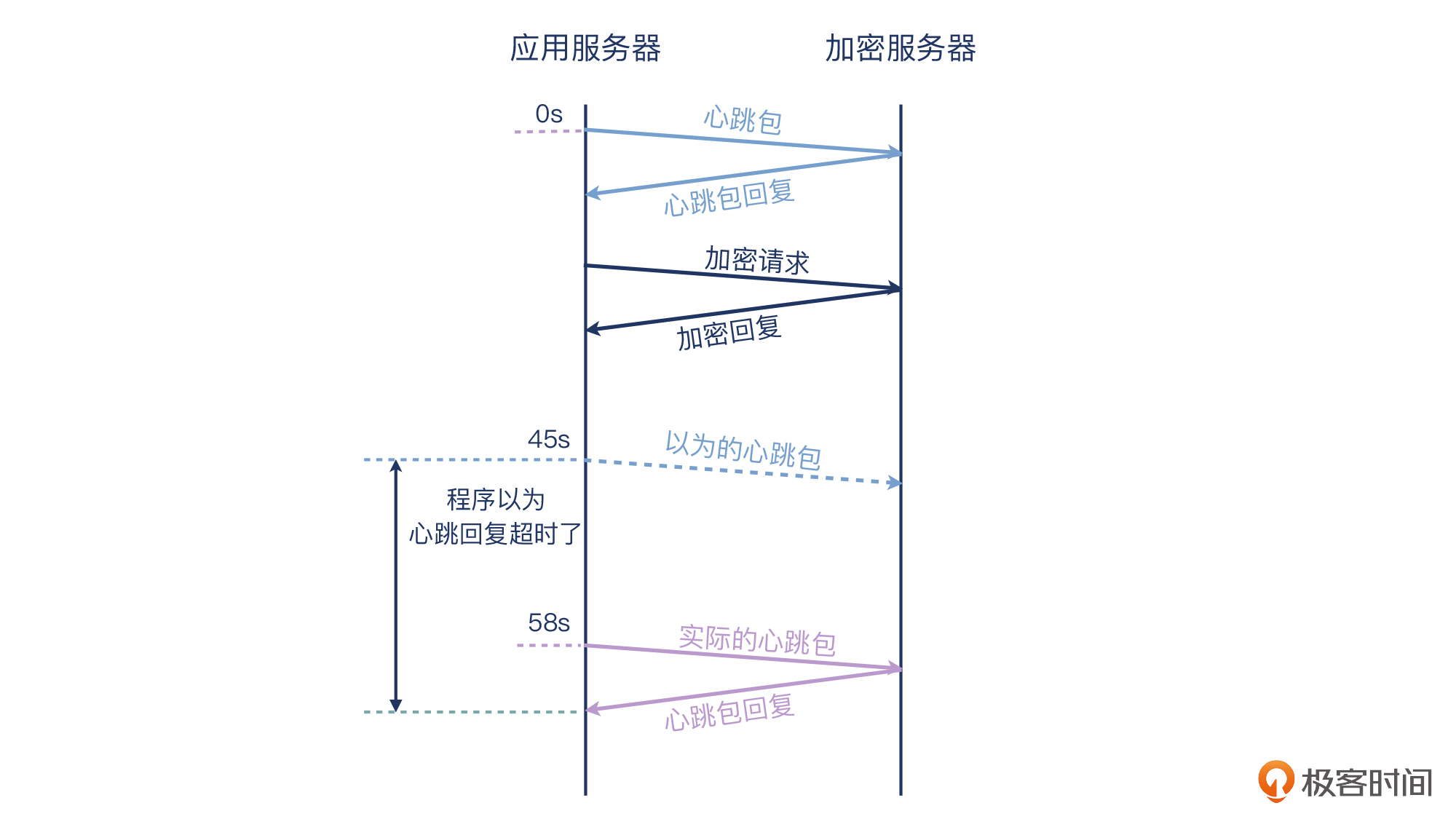
现在,我们已经清楚了这个报错的原因:客户端程序出了一个Bug,某一次心跳探测包发出的时候是在上一次心跳的58秒以后(也就是相对正常情况,迟了13秒)。那么,服务端虽然立即发送了心跳回复包,但也一样是在58秒以后了。程序的逻辑非常简单粗暴:一旦心跳回复包的到达时间超过了第46秒(也就是45秒+1秒超时),就认为是心跳探测失败。
为什么探测包本身会比预定的时间晚了13秒才发出呢?根据这个很明确的信息,客户再次检查了应用代码,终于定位到了出问题的代码段。修复代码后,问题随之解决。
补充一下,在这个案例中,异常时的心跳包探测和回复的耗时本身是正常的。我们可以看到包号572是客户端发出的心跳探测包,包号573是服务端发出的心跳回复包。两者之间,间隔只有0.000370秒,即0.37毫秒,完全是同机房内网时延的正常水平。
显然,这个案例是关于应用层自己实现的心跳机制的,有一定的特殊性。但在机制上,也体现了心跳包的一些特点,比如:
而从更普适的尺度上来看,其实TCP本身提供的Keep-alive机制更为安全易用。
一般来说,对于操作系统已经实现的特性,我们最好直接去利用,而不是自己创造一个类似的轮子。这好比你想基于UDP,在应用层实现类似TCP的种种传输保障机制,也不是不可以,但实现起来会相当复杂(参考QUIC协议)。TCP心跳机制看似简单,但从上面这个案例来看,稍有不慎,还是很容易发生错误的。
那么TCP自身的Keep-alive,究竟是怎样的一个存在呢?
其实,如果不做显式的配置,默认创建出来的TCP Socket是不启用Keep-alive的,也就是都不会发送心跳包。不过,大部分应用程序已经在代码里启用了Keep-alive,所以你平时不太会遇到连接失效的问题。比如我稍后要演示的一个含心跳包的抓包文件,抓取的就是Chrome浏览器的流量,里面就有很多心跳包,因为Chrome浏览器启用了TCP心跳保活机制。
要打开这个TCP Keep-alive特性,你需要使用setsockopt()系统调用,对已经创建的Socket进行配置,启用Keep-alive。具体的调用方法,你可以参考man setsockopt。
在Linux操作系统层级,也有三个跟Keep-alive有关的全局配置项。
补充:你可以在Linux系统里面,执行man tcp,查看内核对TCP协议栈的详细文档。这里我摘录一下关于Keep-alive的部分:
- tcp_keepalive_intvl (integer; default: 75; since Linux 2.4)
The number of seconds between TCP keep-alive probes.
- tcp_keepalive_probes (integer; default: 9; since Linux 2.2)
The maximum number of TCP keep-alive probes to send before giving up and killing the connection if no response is obtained from the other end.
- tcp_keepalive_time (integer; default: 7200; since Linux 2.2)
The number of seconds a connection needs to be idle before TCP begins sending out keep-alive probes. Keep-alives are sent only when the SO_KEEPALIVE socket option is enabled. The default value is 7200 seconds (2 hours). An idle connection is terminated after approximately an additional 11 minutes (9 probes an interval of 75 seconds apart) when keep-alive is enabled.
如果我们连接启用了Keep-alive,但没有设定自定义的数值,那么就会使用上面这些默认值,即:当连接闲置(没有数据交互)达到7200秒(2小时)时发送心跳包,每次心跳包超时时间为75秒,最多重试9次。
这样的话,对于一个已经失效的TCP连接,最大需要7200+75*9=7875秒(约等于2小时11分钟)才能探测到。
毫无疑问,这个时间是相当长的。不过结合时代背景,这个其实也可以理解:TCP Keep-alive被设计的时候是八十年代,当时因特网还很初级,所以设计者们并不想让心跳包占据太多的网络资源。从而,就有了这么一个感知时间很长的心跳机制。关于TCP Keep-alive的一些更多信息在RFC1122里,你有兴趣的话可以去研究一下。
另外一个值得注意的地方,是Keep-alive报文本身的特点。在上面的案例中,这个特定的应用层代码设定的心跳包特征是这样的:
但是TCP本身提供的Keep-alive报文特征就非常不同了。首先,它的序列号就很奇特,是上一个报文的序列号减1,载荷为0。回复的报文也同样特别,确认号为收到的序列号加1。而且,无论是探测包还是回复包,其载荷长度都为0。
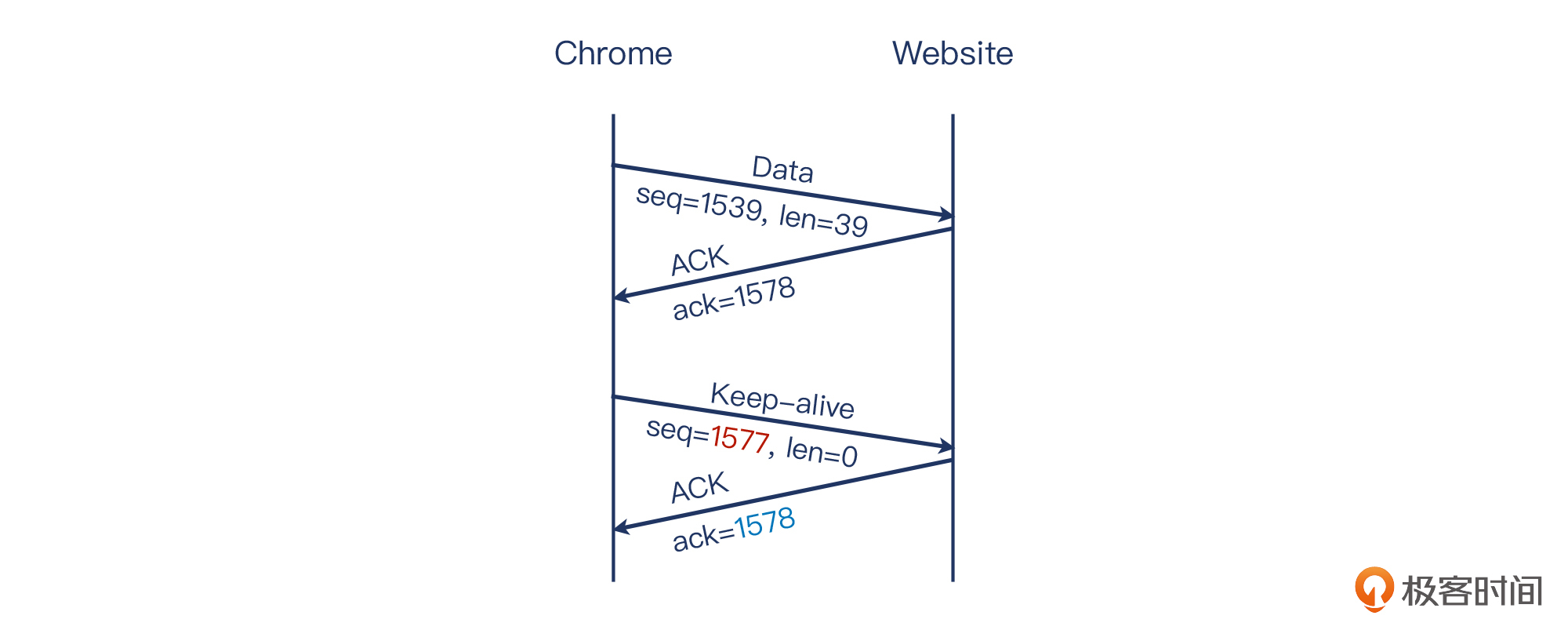
文字描述不是很容易理解,我给你看一个实际的例子。这是某一次我用Chrome浏览器访问网站时做的抓包:
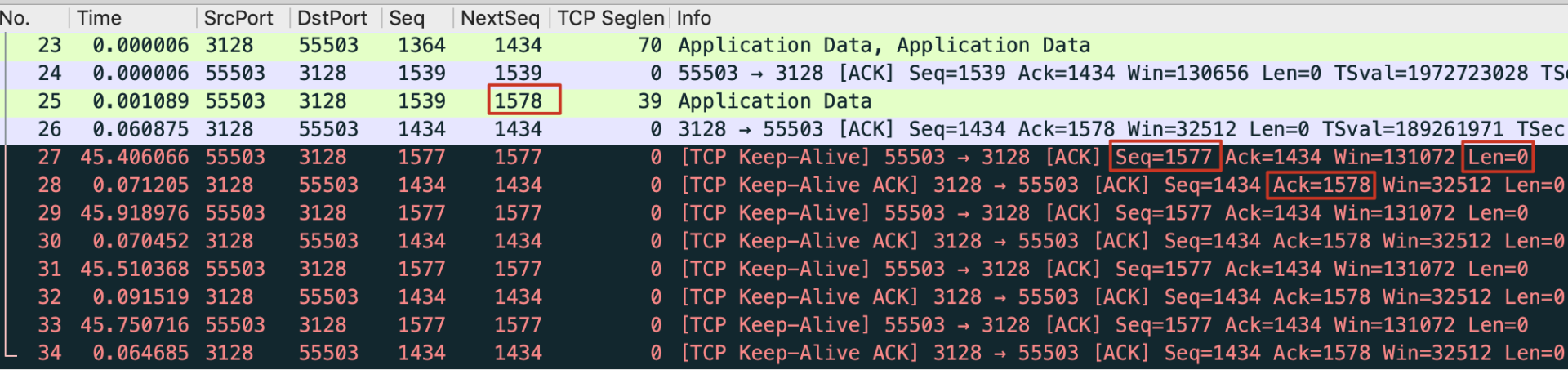
上图的红色底色的多个报文,就是Wireshark识别出来的TCP心跳包。我也把需要关注的信息用红色方框标注出来了。
25号报文是离心跳包最近的一个常规报文,Wireshark告诉我们:它的下一个序列号(图中的NextSeq)是1578。也就是说,如果下一个是常规报文,那么这个常规报文的序列号就是1578。然后看同是这个客户端发出的报文27,这就是一个心跳包,它的序列号却是1577(也就是1578-1),载荷为0(Len=0)。对端对这个心跳包做了回应(包号28),确认号为1578(1577+1),载荷也为0。
我们再来看一下示意图:
要是你了解TCP握手和挥手阶段的确认号的话,你对这个+1机制是不是感觉很熟悉?可见,TCP认为心跳包也是十分重要的,它跟握手和挥手一样,都属于控制报文,它的确认号机制也体现了这一特点。
有趣的是,RFC1122里并没有规定心跳探测包的载荷一定是0,它也可以是1。只是从我有限的抓包经验来看,心跳包都是载荷为0的,看来这是比较常见的实现方式。
那么我们也经常听到的HTTP Keep-alive,又是一个什么东西呢?难道是应用层实现的心跳保活机制?意味着HTTP也有心跳包这种东西吗?
其实没有那么复杂。HTTP的Keep-alive,是用Connection这样一个HTTP header来实现的。你应该知道,HTTP报文的header形式是Key: value。比如常见的header有:
而Keep-alive头部,就是这个形式:Connection: Keep-alive(注意这里有一个“-”符号)。
客户端和服务端都可以发送这个保活头部。表达的意思也跟外交人员的语言一样优雅专业:“我方真诚地希望,贵方能切实履行我们的协议,按照长连接待遇来处理本次连接,谢谢配合”。
你应该也知道,HTTP的版本有0.9、1.0、1.1、2.0。HTTP/0.9现在基本不再使用了,而HTTP/1.0占的流量比例也已经很低了(在公网上小于1%)。目前占主流的是HTTP/1.1和HTTP/2,而这两者都默认使用长连接。
那既然HTTP/1.1默认是长连接了,为什么还要有这个Connection头部呢?在我看来,这有两个原因。
在HTTP/1.0版本中,默认用的是短连接。这导致了一个明显的问题:每次HTTP请求都需要创建一个新的TCP连接。随着因特网带宽和各类资源迅速增长,每次建立TCP连接的开销变成了主要矛盾。
为了克服这个不足,Connection: Keep-alive头部被扩充进了HTTP/1.0,用来显式地声明这应该是一次长连接。当然,从HTTP/1.1开始,长连接已经是默认设置了,但为了兼容1.0版本的HTTP请求,Connection这个头部在HTTP/1.1里得到了保留。
即使在HTTP/1.1里,也并非所有的长连接都需要永久维持。有时候任意一方想要关闭这个连接,又想用一种“优雅”(graceful)的方式,那么就可以用 Connection: Close 这个头部来达到“通知对端关闭连接”的目的,体面而有效。另外,在HTTP/2里,连接关闭是通过另外的机制实现的,与Connection头部无关。
这个Connection头部看似简单,其实有时候也能起到很大的作用。在eBay,我们每年有大量的流量迁移的工作。其中,这个Connection头部就在迁移的平滑度和收敛速度上,起到了很关键的作用。
具体来说,我们在新老两个VIP之间迁移流量,用的是名称解析(基于DNS/GSLB)的返回值的比例,来控制真实的HTTP流量比例,这就可以逐步从新老比例为1:99,到50:50,最后到100:0也就是全部到新VIP。
但是这样会有这么个问题:因为流量基本都是HTTP/1.1(即默认是长连接),客户端依然坚持使用着老的VIP,造成DNS/GSLB的比值调整没有起到应有的效果,真正观察到的流量经常跟DNS/GSLB的设置值相差甚远,或者说有很强的滞后性。
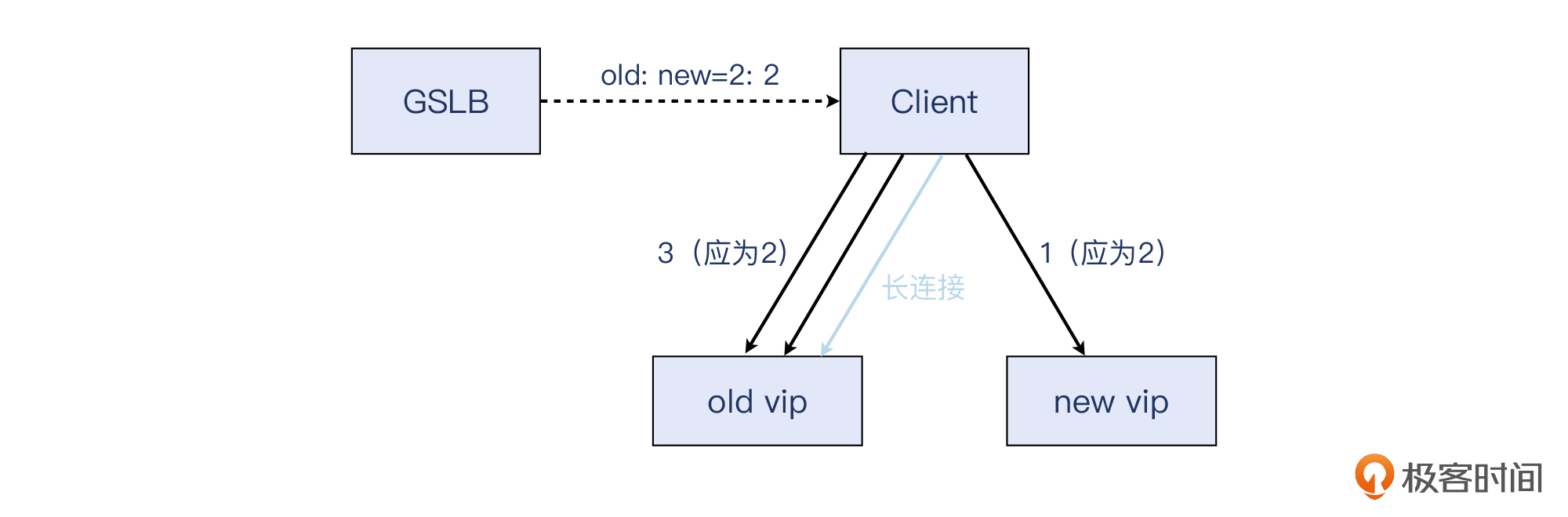
从上图中可以看到,客户端在查询GSLB(相当于智能DNS)的时候,拿到的新老IP的比例为2:2,那么访问量应该也是符合这个比例。但是因为长连接的存在,这些拥有长连接的客户端连问都不会去问GSLB,而是会继续往老的连接(也就是连着老VIP的连接)上发送流量,那么我们迁移流量的工作,就受到影响了。
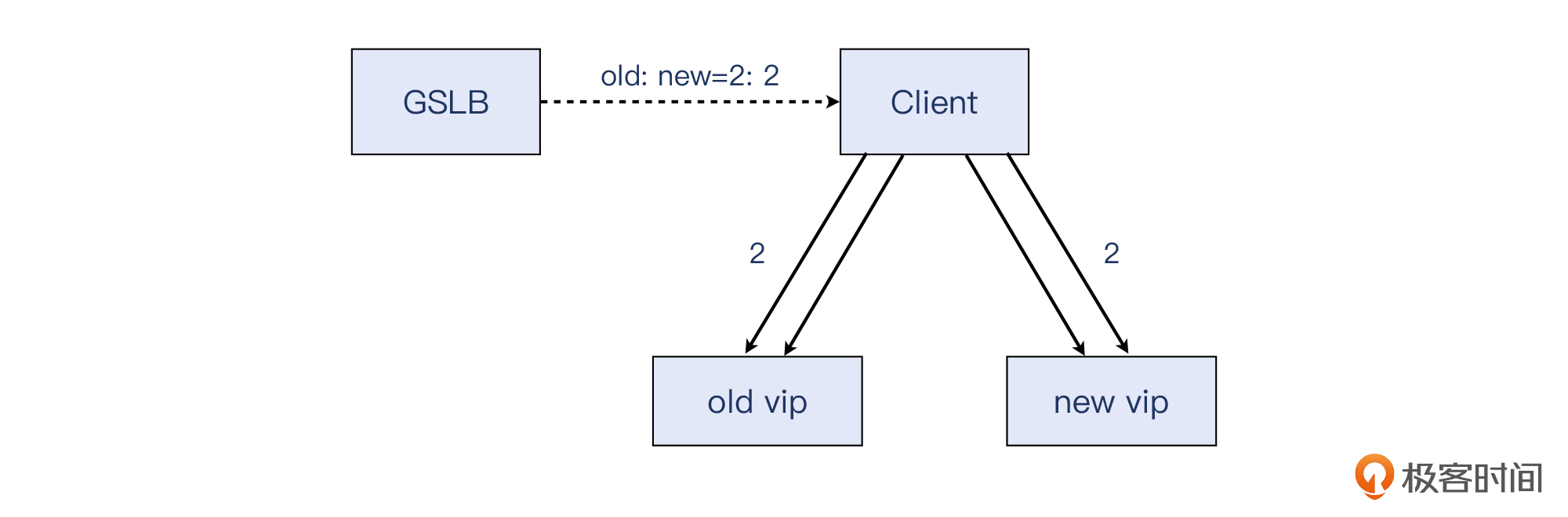
为了解决这个问题,我们当然可以选择等待(比如几小时甚至几天)它自然收敛,但其实我们找到了更好的办法:在新老VIP上都添加了rewrite policy,使得每一定比例的HTTP响应里面,都带上Connection: Close这个头部。
客户端收到这个头部后,按照协议规定,它必须关闭这条长连接。在下一次HTTP请求的时候,客户端就会遵循“DNS解析->发起新连接->发送HTTP请求”这样的工作路径,于是新发起的连接数跟DNS解析数量基本对齐,也就达到了我们的目的。
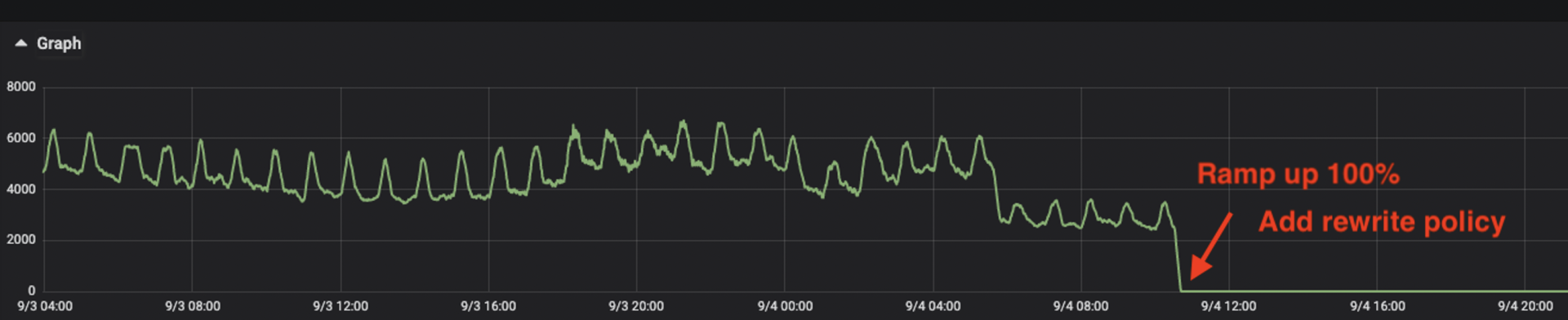
下图是在迁移尾声时候的流量趋势图。在这个阶段,老VIP已经从DNS/GSLB里禁用了。但原先不插入这种Connection: Close头部的话,总还是有很多请求在老的VIP上。在插入了Connection: Close头部后,老VIP上的流量几乎立刻停止,可谓立竿见影。
这节课,我们通过一个奇特的案例,详细探究了一种应用层保活机制的Bug引发的报错。在这个排查过程中,Wireshark过滤器的使用,很大程度上帮助了这次排查。所以,这里我推荐你要熟悉以下这些过滤器,在你以后的网络排查工作中,应该能给到不少的帮助:
tcp.len eq 长度
tcp.flags.fin eq 1
tcp.flags.reset eq 1
tcp.payload eq 数据
抓包分析中,面对Wireshark里千奇百怪的报文,有时候也会遇到不知道从何下手的窘况,那么你可以直接查看Expert Information,从那里寻找线索也不失为一个有效的办法。
另外,在原理部分,我还给你介绍了TCP层面的Keep-alive和HTTP层面的Keep-alive的联系和区别。应该说,这确实是两个容易令人困惑的概念,不仅名称一样,作用也接近。通过这次讲解,希望能帮助你彻底理解这两个概念。
最后,我再给你梳理提炼一下这节课的关键知识点。
首先,对于TCP Keep-alive,你需要掌握:
然后,对于HTTP Keep-alive的知识点,你需要理解:
最后再给你留两道思考题:
tcp.payload eq abc,这个过滤器可以搜索到精确匹配“abc”字符串的报文。那么,如果是模糊匹配,比如只要包含“abc”的报文我都想搜到,这个过滤器又该如何写呢?欢迎你把答案分享到留言区,我们一起进步成长。
抓包示例文件:https://gitee.com/steelvictor/network-analysis/tree/master/07