
你好,我是胜辉。
在上节课,我带你深入探讨了TCP重传的知识点,包括超时重传和快速重传。想必你对于重传的现象和背后的原理,也已经有了不少的了解。那么现在,你可以来思考这样一种情况:用Wireshark打开一个抓包文件,你看到了满屏的TCP Retransmission,第一感觉会是什么?
你应该会认为是掉包了,所以客户端重传了对吧?可能是网络路径上出了状况。
但实际上,网络状况是重传的一个重要因素,却不是唯一。另外一个因素也同样重要:操作系统对TCP协议栈的实现。
这是因为,TCP等传输协议不是无根之木,它们必须依托于操作系统而存在,包括各种客户端、服务端、网络设备等等。就以重传为例,表面上看是由于网络状况而引发的,但其实真正操控重传行为自身的,还是操作系统,确切地说,是TCP通信两端的操作系统。
所以,在这节课里,我会给你再介绍一个十分特殊的案例,带你用一种全新的视角来审视TCP重传。通过这节课的学习,你将会对TCP的基本设计,特别是其中最复杂的知识点之一的重传部分,有更加深刻的理解。这样即使以后你在工作中遇到各种奇怪的TCP问题的时候,也不会再轻易被它们的表面所迷惑,而是能有更加准确的判断了。
开头我们假设的那个场景,是一上来就直接分析TCP的重传问题,好像这个问题刚冒头,就是以“TCP重传”的形式出现的一样。但在真实的生产环境当中,问题出现的时候就不会那么直接了,而是以应用层的某种形式,比如以“事务处理慢”这种形式出现的。
下面,我们看一个实际的案例。
eBay的应用大部分都是基于微服务进行设计和开发的。有一天,一个业务开发团队向我们基础架构团队报告了一个情况:从他们客户端集群向服务端(LB上的VIP)发送的请求,遇到了大量的Response Timeout(返回超时)的报错。这里的Timeout是一个应用层的超时设置,如果客户端无法在2秒钟(2000ms)之内收到返回信息,就会抛出超时报错。
在我们内网,同数据中心的时延基本在1ms以内,跨数据中心的时延在10ms上下,都很快。这里设置的2000ms的超时,事实上大部分都是预留给了应用程序。这个应用的超时机制,跟TCP超时重传机制类似,应用也不想“干等”。
所以,我们首先采用了挨个测试的方法。因为整个路径是:
客户端 -> LB -> 服务器(就是LB后面的机器)
而报错是在客户端观察到的,那么我们可以对比两种路径:
- 客户端 -> LB -> 服务器
- 客户端 -> 服务器(绕过LB)
看看在这两种情况下传输的请求都有什么不同。
我们发现,如果客户端绕过LB VIP去直接访问服务器,是正常的,没有超时的报错。服务器上的日志显示,很快收到了客户端发出的请求,花了三百多毫秒就处理完并回复了。比如这个服务器日志:
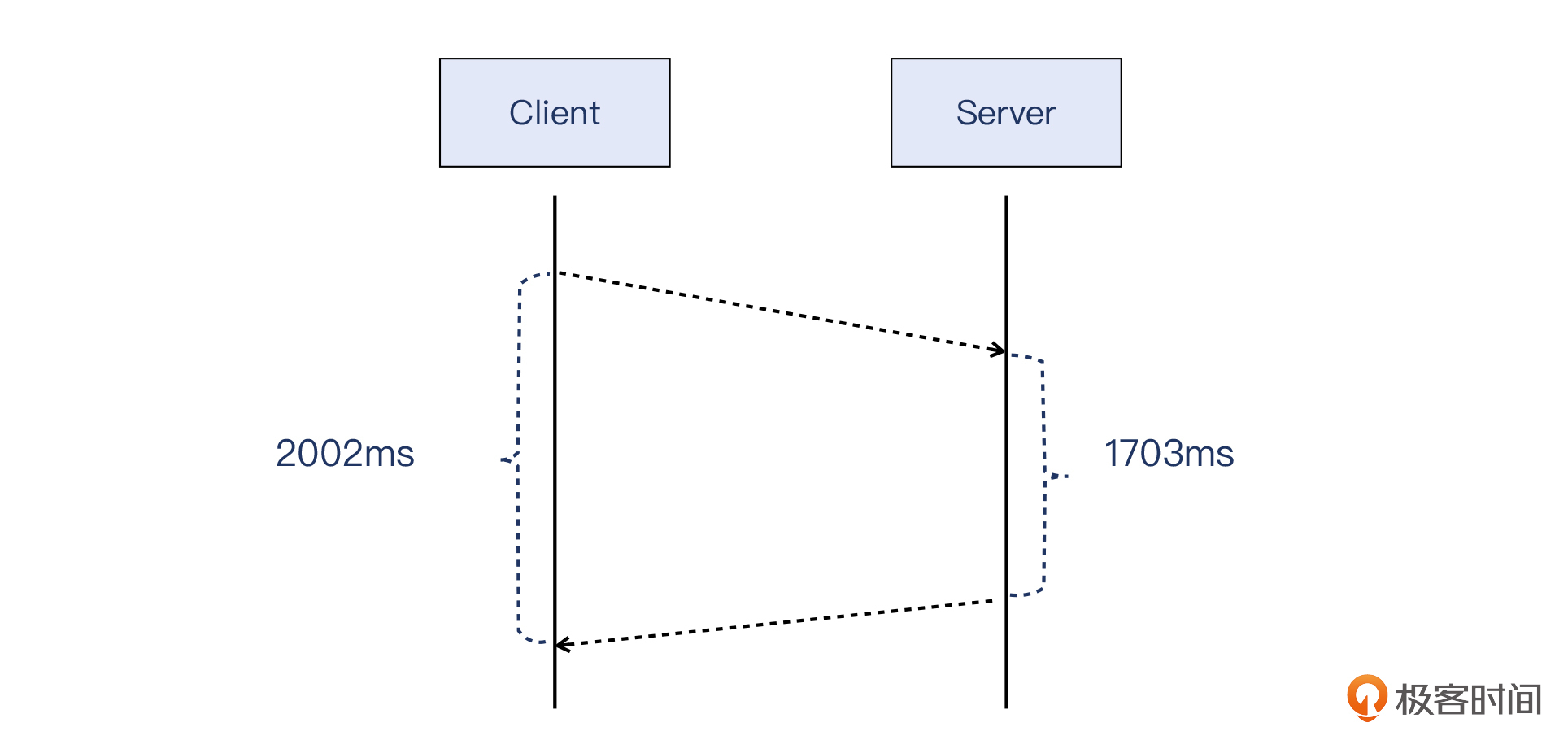
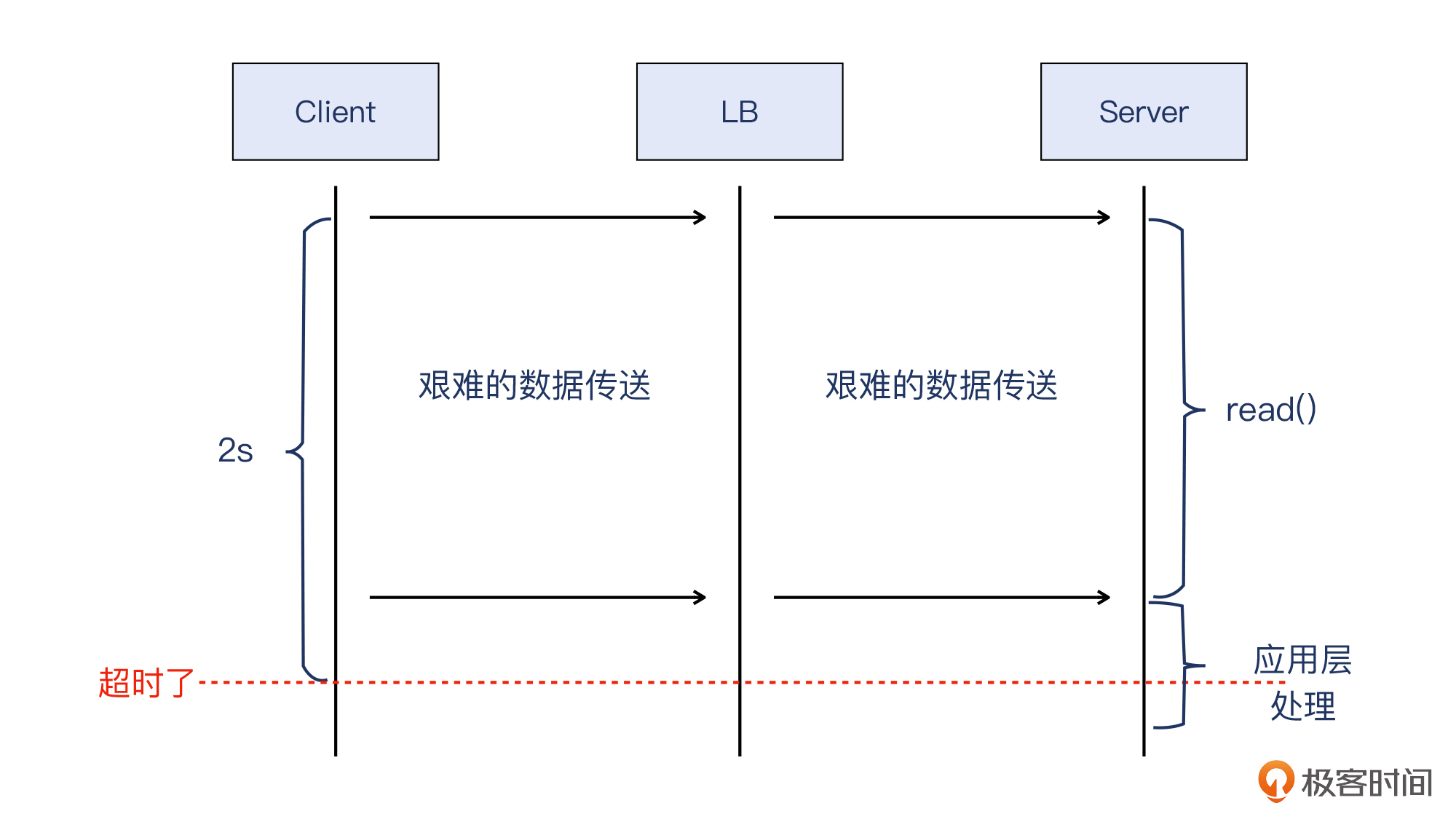
这种情况下,客户端会等待很长的时间才能拿到HTTP响应。日志也印证了这一点:服务器上的日志显示,这个请求的处理耗费了1703毫秒。如下图:

并且,客户端上的日志显示,同样是这个请求,在它看来,从发出请求给LB的VIP,到收到LB的VIP返回的响应,一共消耗了2002毫秒。如下图:

我画了一张示意图,帮助你理解得更加清楚一些:
你也许会问:看起来不是服务器那头本身处理的耗时很长吗?为什么不查查服务器上应用代码的Bug?
我们也一度有这个怀疑,服务器上运行的是Java代码,会不会是GC造成的影响呢?所以我们也去查了当时JVM的运行情况,发现这段时间内并没有GC事件。因此,这个可能性也被排除。并且我们定位到,服务器的耗时主要是花费在了read()调用上,即读取网络I/O上面,所以还是需要回到网络排查的方向上来。
补充:Java有相关的分析工具来定位耗时所在,或者用strace也可以定位系统调用的性能情况。
我们用一个示意图来概括这两种场景下的区别:
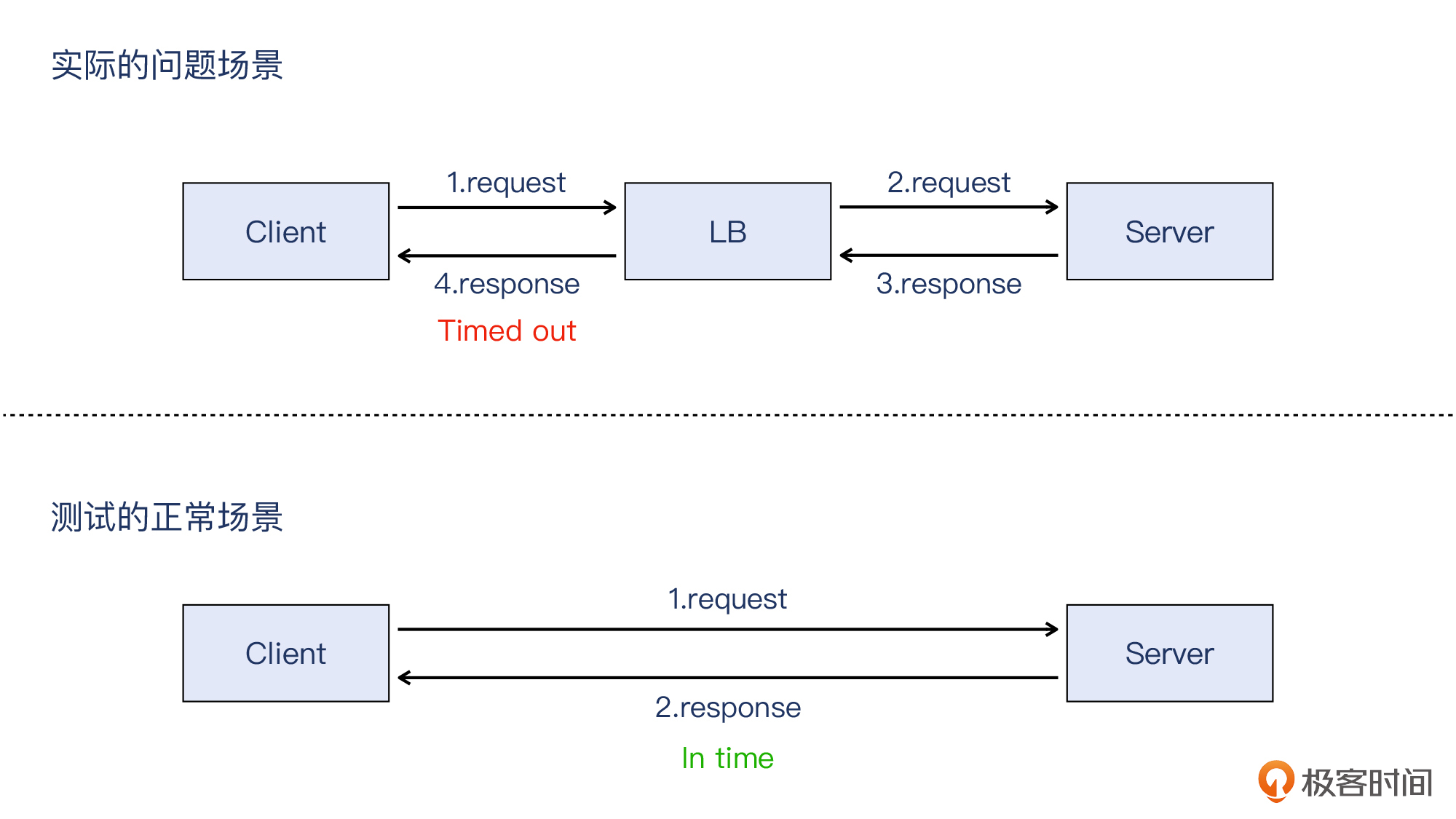
由此,我们可以初步判定:问题出在LB,或者LB前后的网络环节。
这里也是我想分享给你的一个小的排查原则:针对客户端看到超时或者响应慢的这类问题,最好也检查下服务器本身花费的时间,两者对比,就能找到问题的方向了。
我给你把整个思路用伪代码的形式组织如下:
if (服务器耗时约等于客户端耗时) {
检查服务器耗时分布
if (服务器耗时在网络I/O) {
检查中间网络或者LB
} else {
检查服务器应用程序或操作系统
}
} else if (服务器耗时远小于客户端耗时) {
检查中间网络或者LB
}
我也画了一个示意图,供你参考:
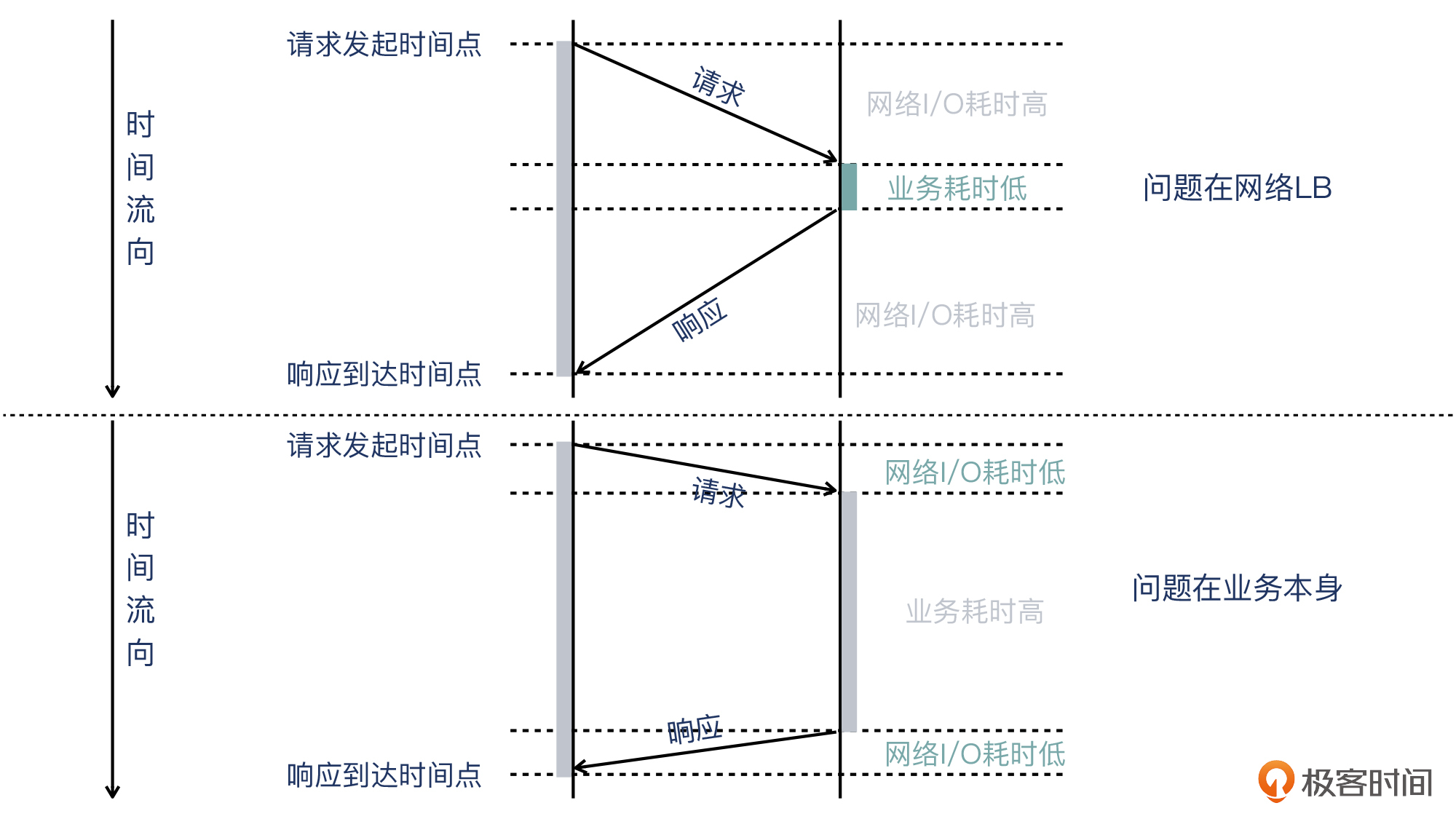
那么下面,我们就可以把排查重点,转到 LB和网络层面上来。
首先,我们在LB进行了抓包,用Wireshark打开抓包文件,一开始看到的是一帆风顺,全绿:

翻了几页,突然画风一变,全红:
补充:抓包示例文件已经上传至Gitee,建议你结合专栏内容和抓包示例文件一起学习,效果更好。
看到这个景象,你是否也会这样判断:“这肯定是有丢包了,所以接收方一直在回复DupAck!赶快去查网络设备的问题。”
DupAck多半是丢包引起的,但这次不是。为什么呢?我们先来看一下抓包文件展现出来的全貌。
那么,我们可以在Wireshark里打开Expert Information看一下汇总信息。
补充:关于Expert Information的解读,我在第5讲有介绍过,如果你感觉现在印象有点模糊的话,可以回头去温习一下。

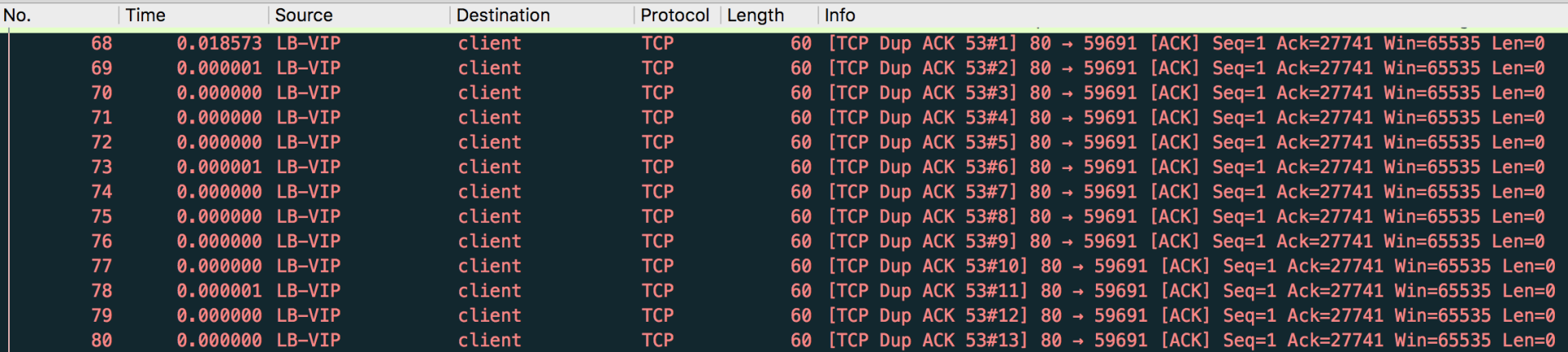
从图上看,快速重传有8个,DupAck有567个,平均每个快速重传对应了约70个DupAck。这里,我们来看看其中一段连续的DupAck和随后的一个快速重传:
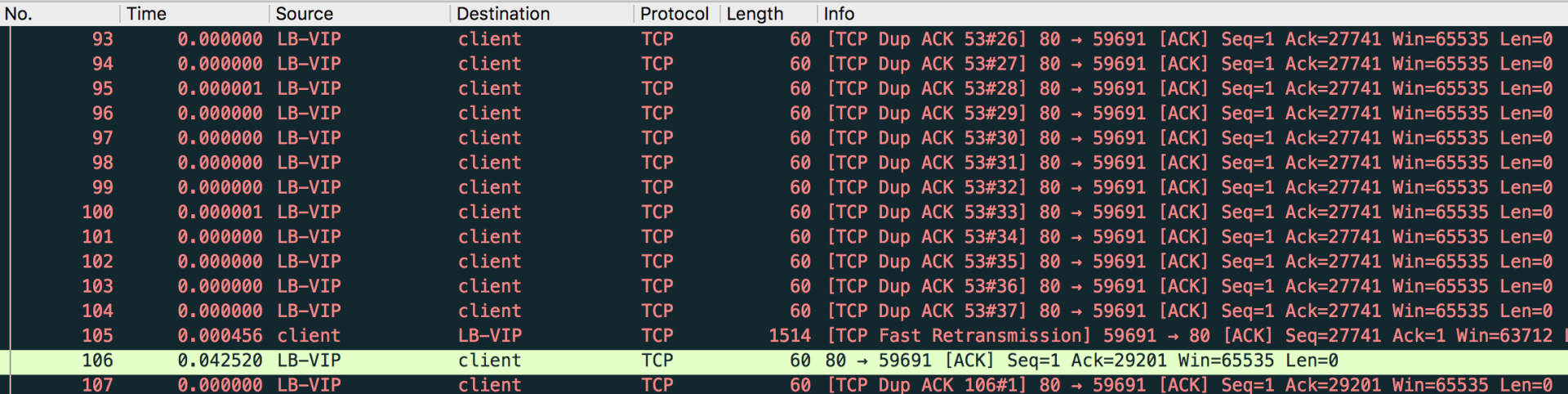
我给你解读一下:在LB给客户端发送了数十个DupAck之后(比如截图里包号93到104),客户端发送了一次快速重传(包号105),然后LB回复ACK(包号106,针对包号105),接着LB继续新一轮的数十个DupAck(从包号107开始),循环往复。
其实这里已经说明了这个案例的特殊性,也就是有“规律性现象”。如果是网络设备问题导致丢包,那么丢包会是随机现象,不太可能像这样有规律(70个DupAck加一个快速重传,不断循环)。而往往规律的背后,一般潜藏着某种未知的机制。
当然,大量的DupAck和重传,确实跟应用层我们看到的严重的延迟现象对上了。也至少能回答“应用为什么变慢”这个问题了。当然,探究根因的话,接下来就是要回答“为什么有重传”这个问题。
在上节课,我们学习过两种重传方式,分别是快速重传和超时重传,而这次的重传呢,Wireshark已经提醒我们,属于快速重传。那为什么会有这种快速重传呢?
这里我们先来看一下相关数据包的具体细节。
首先,我们看一下在LB回复大量DupAck之前,客户端的发送情况。

可以看到,在第一个LB DupAck包之前,客户端发送的最后一个数据包是包号67,它的信息是:
然后我们再来看一下第一个LB DupAck包,其包号为68:
要知道,TCP协议规定:接收方回复的ACK包的确认号=发送方数据包的序列号+TCP载荷字节数。如果接收方回复了DupAck,假设这个DupAck的确认号为n,那么其含义是:我只收到发送方给我的序列号为n之前的数据包,而序列号为n(及其之后)的数据包,我都没有确认。
所以,LB就通过DupAck包向客户端宣告:“我这边只确认收到序列号27741之前的数据包。”
而这里出现几十次DupAck的原因是,一旦LB认为某个数据包我没有收到(此处是序列号为27741的数据包),那么数据就“断档”了,之后客户端送过来的每个数据包,LB都无法ACK这些数据包的序列号+TCP载荷字节数。所以虽然ACK包还是要发,但确认号却只能“停留”在丢包处的确认号,并且这样重复的ACK会有很多个。
为了便于理解,我把这个过程换一种方式给你展示一遍。除了27741这个号以外,其他序列号是为方便举例而编出来的:
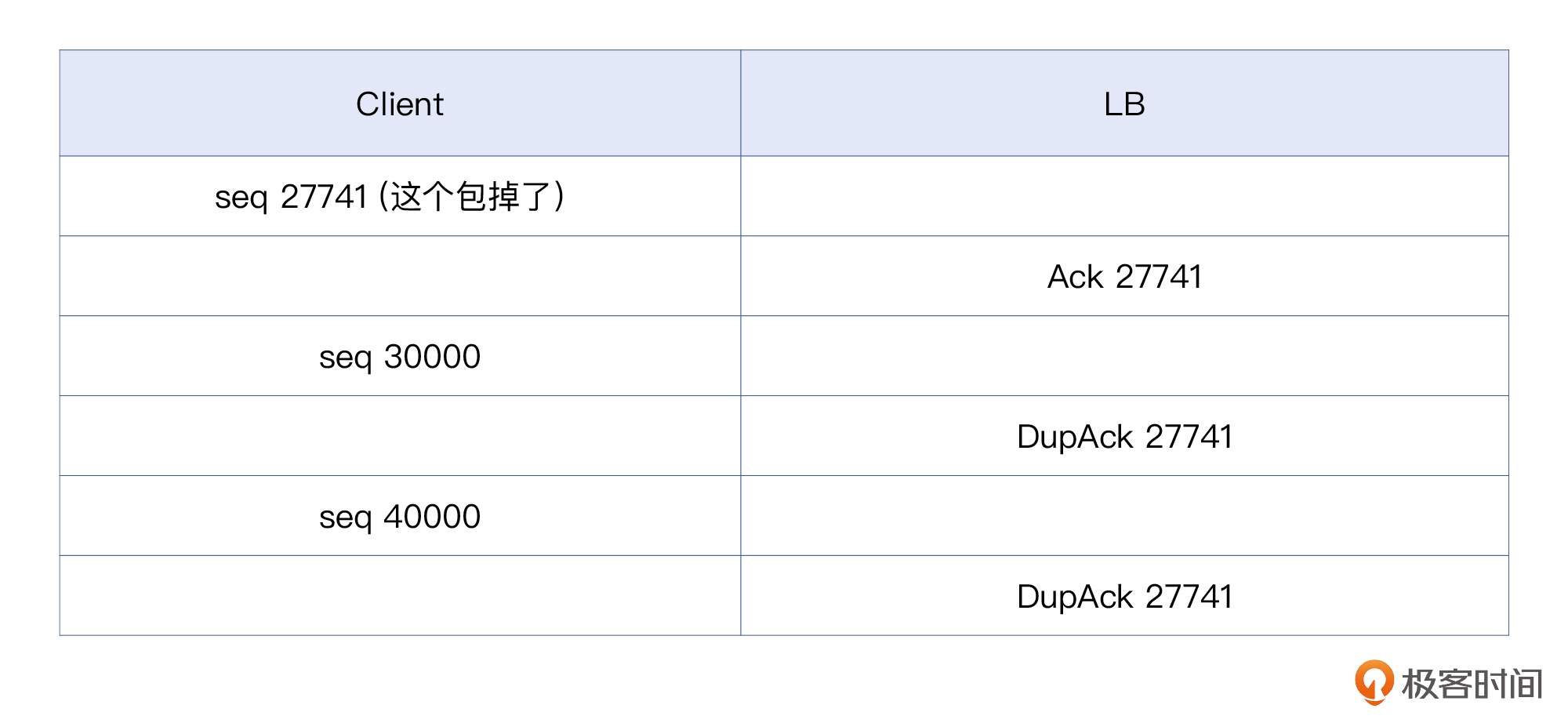
上面是客户端来一个报文,LB回复一次DupAck。当然也可能像下面这样,连续来多个报文,LB回复连续的多个DupAck:
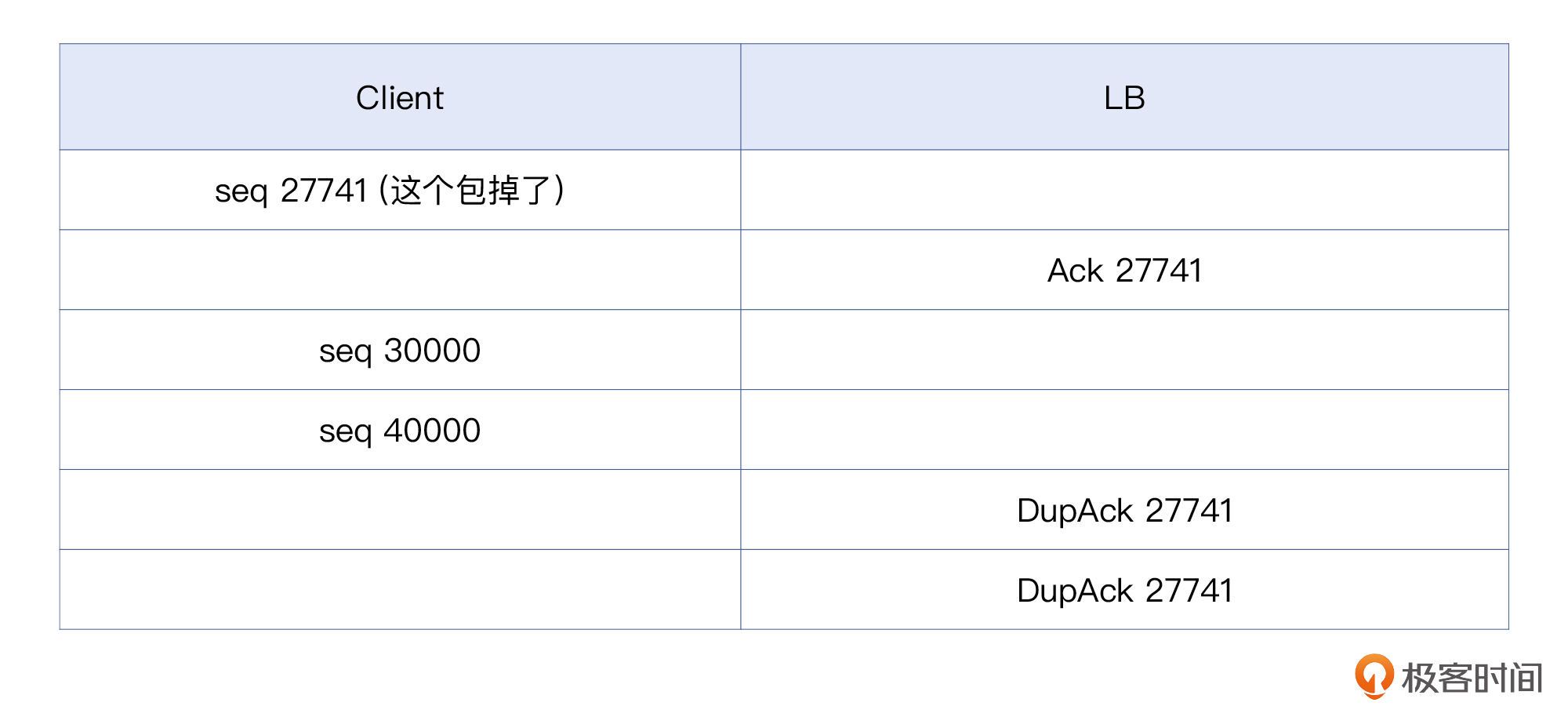
好了,现在情况就比较清楚了,虽然“丢包”的根因还没找到,但整个排查工作的脉络已经相对清晰了,即:某处丢包-> TCP重传-> TCP传输速度下降->应用层超时报错。
看起来,我们离成功只剩一步了,也就是,在抓包文件中找到那个丢失的序列号为27741的数据包!
只要证明这个数据包确实是在网络上丢失的,那么我们就去修复网络。TCP不丢包了不重传了,速度就上来了,应用就不超时了。逻辑圆满自洽,感觉胜利已经在向我们招手了,是不是?
可是峰回路转。我们去翻前面数据包的时候,发现根本就没有那个“序列号为27741”的数据包!

上图是最接近27741序列号的附近的数据包,有序列号27229的包,也有序列号28689的包,但就是没有位于这两个数中间的27741的包。
这个时候,恍惚中有点感觉在看悬疑小说:一桩案件的元凶被查出是某某某,结果发现某某某这个人压根不存在。
你如果有跑步的爱好,应该会知道:跑步过程中会有一个极限区,此时我们的心肺会遇到很大的压力,这种难受的感觉很容易让人放弃。但是,如果继续坚持挺过这个极限区,身体就能提升到一个新的平台上继续平衡运转。进而,我们就可以继续快乐地跑下去了。
显然,我们的排查进入了“极限区”了。止步还是进步,就在一念之间。
那么,这个序列号27741的包是消失了吗?还是说它就在那里,只是我们忽视了它的存在?
TCP序列号、Payload(载荷)、TCP确认号,一般情况下就是一个A+B=C的关系。但是,确认号必须是序列号+全部载荷吗?它可以是序列号+部分载荷吗?
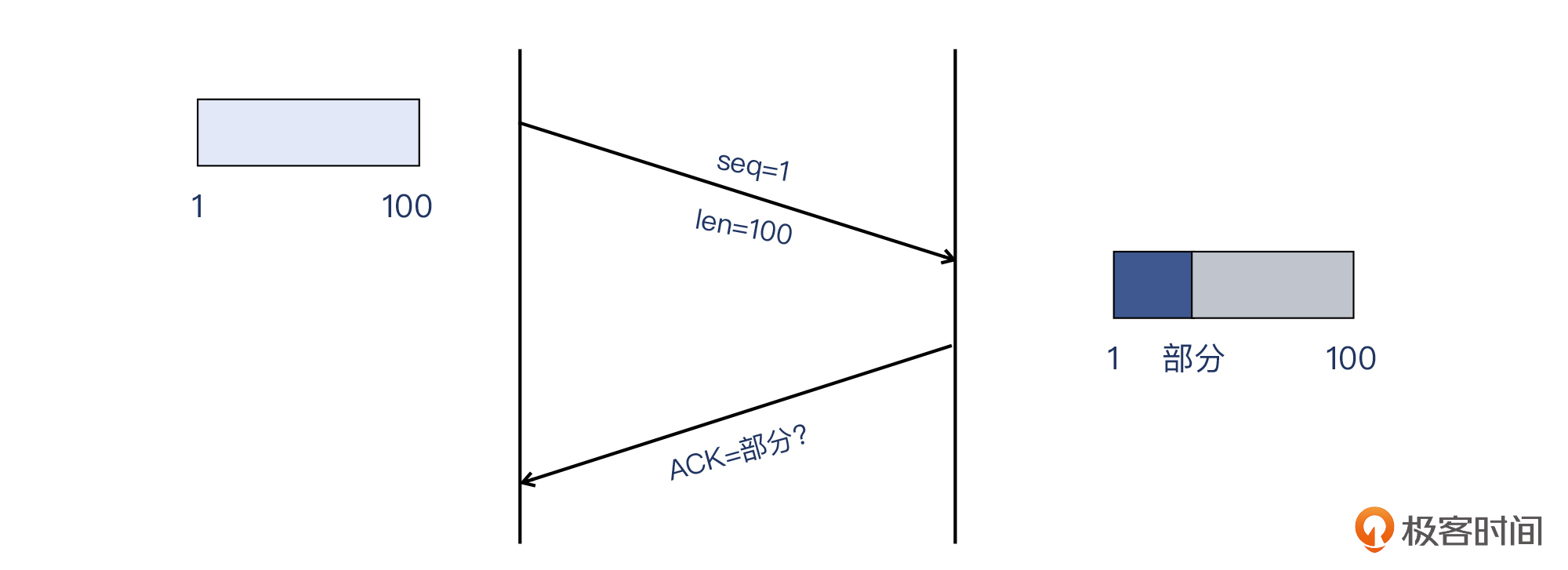
举个例子,如果我从网上购买了一套衣服(上衣+裤子),我也收到了全套。但我觉得裤子尺码不对,上衣还挺合身,我可以只确认我收到了上衣(当然裤子还是要退回的),让卖家重新发裤子给我吗?这是可以的。
如果TCP也可以这样呢?那么,“寻找序列号为27741的包”也许就是个伪命题,这个“包”实际上并不是独立的一个包,它只是某一个TCP包的一部分(前半部分)。我们来看一下包号20(也就是前面找27741的时候,关注的两个报文之一)的详情:
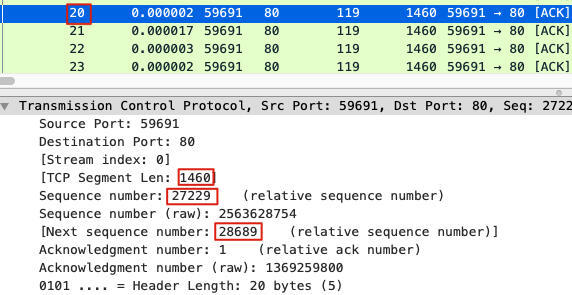
这个包是从客户端发给LB的,它的序列号为27229,载荷为1460字节。Wireshark也告诉我们,客户端将要发的下一个包的序列号会是28689。然而,LB回复的ACK(后续同样的ACK就是DupAck)却是这样:
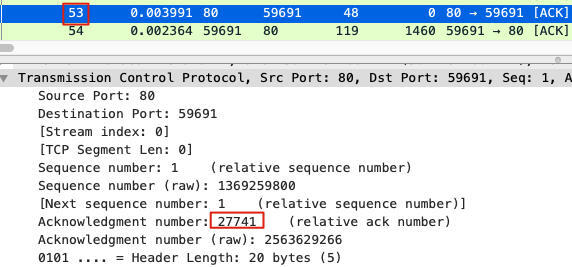
我们再看那个最为可疑的数字27741。显然,27741=27229+512。到这里看清楚了吗?这次LB确认的是一件“上衣”(512字节),而余下的“裤子”(另外的1460-512=948字节),LB并没有确认。没有被确认的数据,在客户端看来,是需要重新发送的。
我们先看看正常情况(即每次确认1460字节 )下的数据包交换过程:
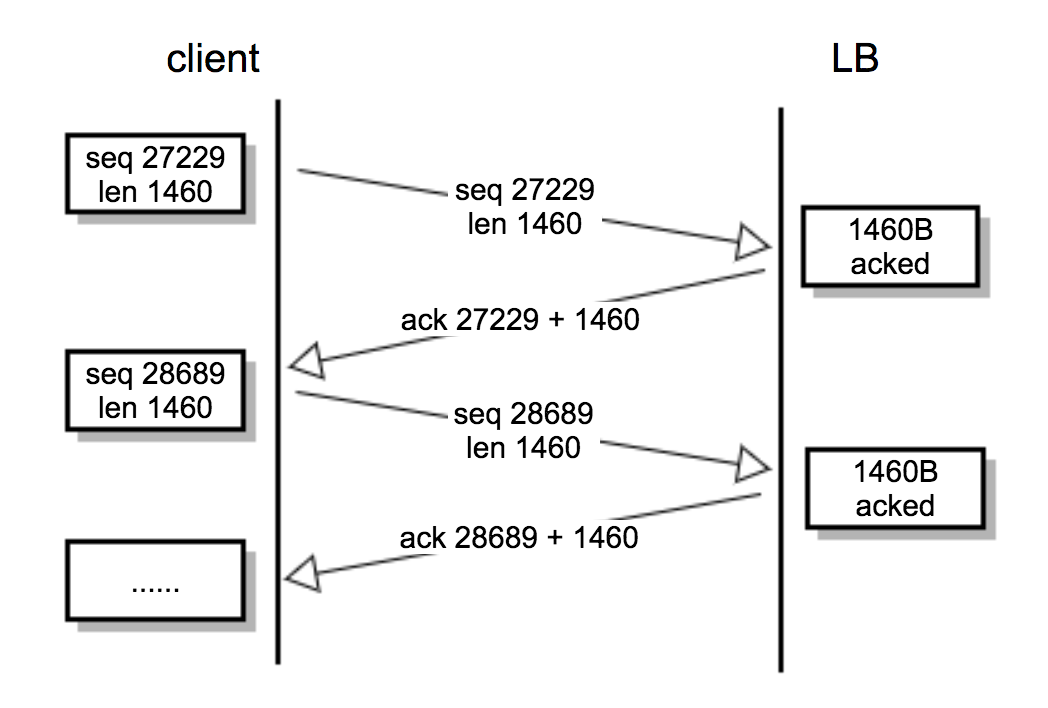
然后再来看一下这次异常交换的过程。
这次异常通信的过程如下图所示:
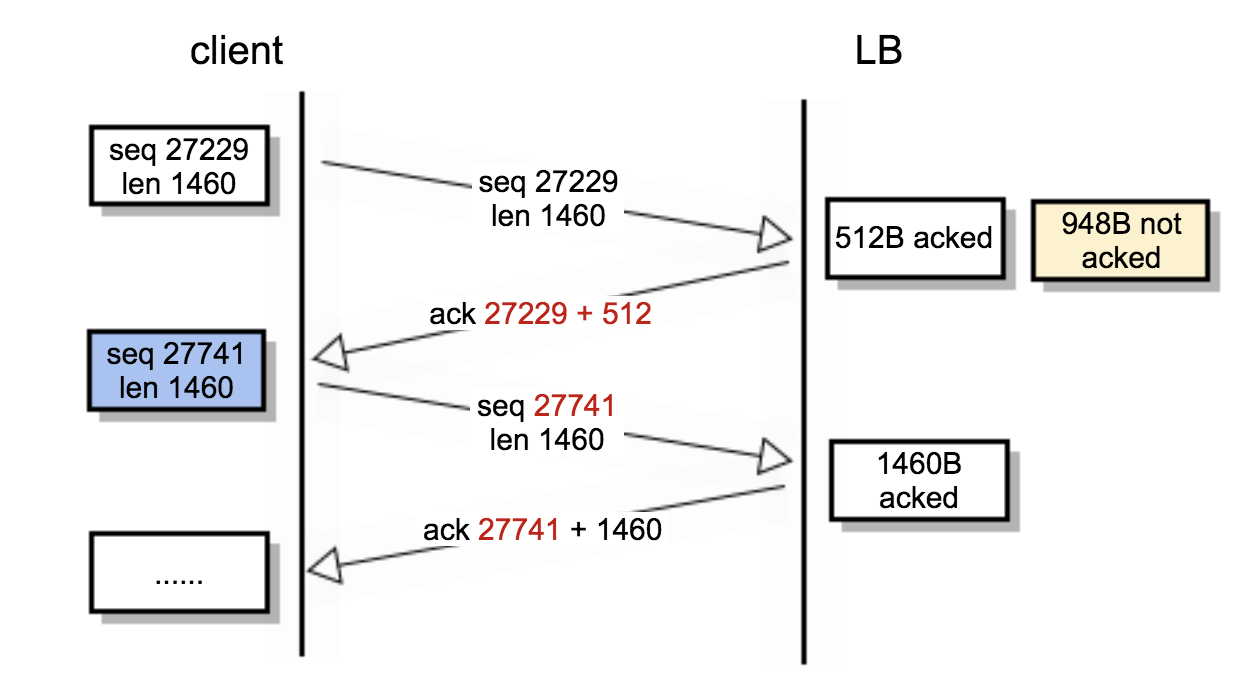
这里,我再提醒你一个关键点:确认号本身代表字节数,所以它是字节级别的,而不是报文级别。也就是说,确认号是精确到某个字节的,而不是某个报文。
说到这里,我们再回顾下前面提到过的现象:平均每个快速重传对应了约70个DupAck,而每次重传都需要客户端把发送缓冲区里面打包好的数据包,挨个拆开,重组成LB想要的样子(512字节的位移的关系)。
想必,现在你已经清楚为什么应用会超时(超过2s)了:因为时间都花费在了各种包的分拆、重组上面了。光是客户端想成功发完一个POST请求,都花费了远远超出预期的时长。就如同一辆车频繁熄火,还怎么可能高速行驶呢?
我画了一张更详细的图,来帮助你理解这个复杂的过程:
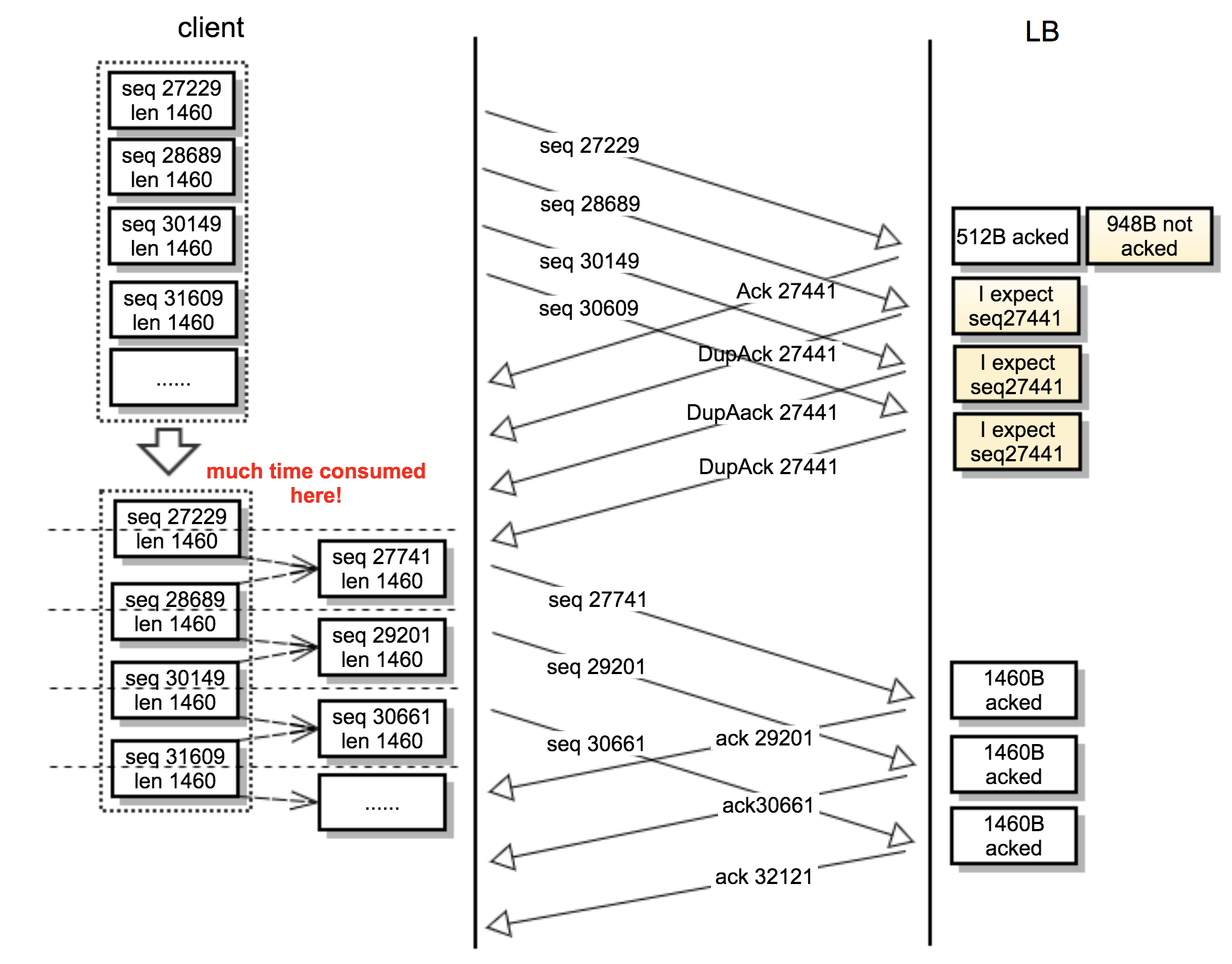
为了更加方便你的理解,我把这个过程概括成了下面这张图:
真相大白了!凭借这些详细的分析和充足的证据,我们说服了LB厂商并确认这是一个Bug,它容易在请求尺寸比较大的情况下被触发。比如在这个案例里,一个POST请求平均大小在100KB,也就触发了这个Bug。
实际上,在Bug修复之前,我们通过扩大TCP receive buffer size,使得缓冲区足够大(你HTTP POST请求大,我缓冲区更大),也做到了对Bug的规避。
今天介绍的确实是一个比较罕见的案例,也是我处理过的众多网络排查案例中,遇到的仅有的一次“确认号在中间位置”的情况。那么从协议规范来说,这样“确认中间位置”的做法,到底是否违规呢?
我们看一下TCP协议的第一版规范RFC793,看看它对确认号的要求是什么:
if the ACK bit is on
......
ESTABLISHED STATE
If SND.UNA < SEG.ACK =< SND.NXT then, set SND.UNA <- SEG.ACK.
其中几个缩写的含义如下:
SND.UNA - send unacknowledged #这是指已发送的但未被确认的TCP段的位置
SND.NXT - send next #这是已经发送的TCP段的下个序列号
“下个序列号”这个知识点在第10讲介绍过,你可以回头复习一下。
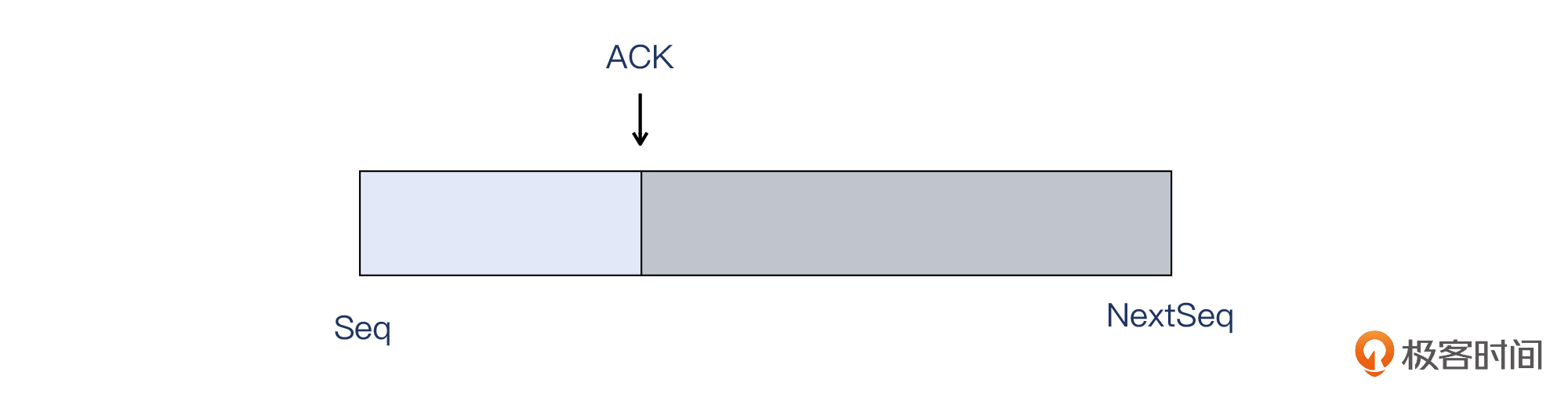
TCP应该接受 SND.UNA < SEG.ACK =< SND.NXT 这样的情形,也就是收到的报文的确认号,应该大于已经被确认的数据的位置,并且小于等于(要发送的)下个序列号。
一般来说,我们看到的大部分是“确认号等于下个序列号”的情况,如下图:

但是从这个案例的情况来看,就是确认号是在中间位置。这虽然很少见,但也不违规,也可以被操作系统接纳并处理。只不过,引起的开销有点过大了。
除了上面的知识点以外,我也建议你务必关注整个排查过程带来的启发:
最后还是给你留两道思考题:
欢迎在留言区分享你的答案,也欢迎你把今天的内容分享给更多的朋友。
抓包示例文件:https://gitee.com/steelvictor/network-analysis/tree/master/13