
在计算机发展的历史上,对于如何存储这个数据没有形成标准。比如这里讲到的问题,不同的系统就会有两种存法,一种是将0x02高字节存放在起始地址,这个叫做大端字节序(Big-Endian)。另一种相反,将0x01低字节存放在起始地址,这个叫做小端字节序(Little-Endian)。
你好,我是盛延敏,这里是网络编程实战第16讲,欢迎回来。
上一讲我们讲到了使用SO_REUSEADDR套接字选项,可以让服务器满足快速重启的需求。在这一讲里,我们回到数据的收发这个主题,谈一谈如何理解TCP的数据流特性。
在前面的章节中,我们讲的都是单个客户端-服务器的例子,可能会给你造成一种错觉,好像TCP是一种应答形式的数据传输过程,比如发送端一次发送network和program这样的报文,在前面的例子中,我们看到的结果基本是这样的:
发送端:network ----> 接收端回应:Hi, network
发送端:program -----> 接收端回应:Hi, program
这其实是一个假象,之所以会这样,是因为网络条件比较好,而且发送的数据也比较少。
为了让大家理解TCP数据是流式的这个特性,我们分别从发送端和接收端来阐述。
我们知道,在发送端,当我们调用send函数完成数据“发送”以后,数据并没有被真正从网络上发送出去,只是从应用程序拷贝到了操作系统内核协议栈中,至于什么时候真正被发送,取决于发送窗口、拥塞窗口以及当前发送缓冲区的大小等条件。也就是说,我们不能假设每次send调用发送的数据,都会作为一个整体完整地被发送出去。
如果我们考虑实际网络传输过程中的各种影响,假设发送端陆续调用send函数先后发送network和program报文,那么实际的发送很有可能是这个样子的。
第一种情况,一次性将network和program在一个TCP分组中发送出去,像这样:
...xxxnetworkprogramxxx...
第二种情况,program的部分随network在一个TCP分组中发送出去,像这样:
TCP分组1:
...xxxxxnetworkpro
TCP分组2:
gramxxxxxxxxxx...
第三种情况,network的一部分随TCP分组被发送出去,另一部分和program一起随另一个TCP分组发送出去,像这样。
TCP分组1:
...xxxxxxxxxxxnet
TCP分组2:
workprogramxxx...
实际上类似的组合可以枚举出无数种。不管是哪一种,核心的问题就是,我们不知道network和program这两个报文是如何进行TCP分组传输的。换言之,我们在发送数据的时候,不应该假设“数据流和TCP分组是一种映射关系”。就好像在前面,我们似乎觉得network这个报文一定对应一个TCP分组,这是完全不正确的。
如果我们再来看客户端,数据流的特征更明显。
我们知道,接收端缓冲区保留了没有被取走的数据,随着应用程序不断从接收端缓冲区读出数据,接收端缓冲区就可以容纳更多新的数据。如果我们使用recv从接收端缓冲区读取数据,发送端缓冲区的数据是以字节流的方式存在的,无论发送端如何构造TCP分组,接收端最终收到的字节流总是像下面这样:
xxxxxxxxxxxxxxxxxnetworkprogramxxxxxxxxxxxx
关于接收端字节流,有两点需要注意:
第一,这里netwrok和program的顺序肯定是会保持的,也就是说,先调用send函数发送的字节,总在后调用send函数发送字节的前面,这个是由TCP严格保证的;
第二,如果发送过程中有TCP分组丢失,但是其后续分组陆续到达,那么TCP协议栈会缓存后续分组,直到前面丢失的分组到达,最终,形成可以被应用程序读取的数据流。
我们知道计算机最终保存和传输,用的都是0101这样的二进制数据,字节流在网络上的传输,也是通过二进制来完成的。
从二进制到字节是通过编码完成的,比如著名的ASCII编码,通过一个字节8个比特对常用的西方字母进行了编码。
这里有一个有趣的问题,如果需要传输数字,比如0x0201,对应的二进制为0000001000000001,那么两个字节的数据到底是先传0x01,还是相反?
在计算机发展的历史上,对于如何存储这个数据没有形成标准。比如这里讲到的问题,不同的系统就会有两种存法,一种是将0x02高字节存放在起始地址,这个叫做大端字节序(Big-Endian)。另一种相反,将0x01低字节存放在起始地址,这个叫做小端字节序(Little-Endian)。
但是在网络传输中,必须保证双方都用同一种标准来表达,这就好比我们打电话时说的是同一种语言,否则双方不能顺畅地沟通。这个标准就涉及到了网络字节序的选择问题,对于网络字节序,必须二选一。我们可以看到网络协议使用的是大端字节序,我个人觉得大端字节序比较符合人类的思维习惯,你可以想象手写一个多位数字,从开始往小位写,自然会先写大位,比如写12, 1234,这个样子。
为了保证网络字节序一致,POSIX标准提供了如下的转换函数:
uint16_t htons (uint16_t hostshort)
uint16_t ntohs (uint16_t netshort)
uint32_t htonl (uint32_t hostlong)
uint32_t ntohl (uint32_t netlong)
这里函数中的n代表的就是network,h代表的是host,s表示的是short,l表示的是long,分别表示16位和32位的整数。
这些函数可以帮助我们在主机(host)和网络(network)的格式间灵活转换。当使用这些函数时,我们并不需要关心主机到底是什么样的字节顺序,只要使用函数给定值进行网络字节序和主机字节序的转换就可以了。
你可以想象,如果碰巧我们的系统本身是大端字节序,和网络字节序一样,那么使用上述所有的函数进行转换的时候,结果都仅仅是一个空实现,直接返回。
比如这样:
# if __BYTE_ORDER == __BIG_ENDIAN
/* The host byte order is the same as network byte order,
so these functions are all just identity. */
# define ntohl(x) (x)
# define ntohs(x) (x)
# define htonl(x) (x)
# define htons(x) (x)
应该看到,报文是以字节流的形式呈现给应用程序的,那么随之而来的一个问题就是,应用程序如何解读字节流呢?
这就要说到报文格式和解析了。报文格式实际上定义了字节的组织形式,发送端和接收端都按照统一的报文格式进行数据传输和解析,这样就可以保证彼此能够完成交流。
只有知道了报文格式,接收端才能针对性地进行报文读取和解析工作。
报文格式最重要的是如何确定报文的边界。常见的报文格式有两种方法,一种是发送端把要发送的报文长度预先通过报文告知给接收端;另一种是通过一些特殊的字符来进行边界的划分。
下面我们来看一个例子,这个例子是把要发送的报文长度预先通过报文告知接收端:

由图可以看出,这个报文的格式很简单,首先4个字节大小的消息长度,其目的是将真正发送的字节流的大小显式通过报文告知接收端,接下来是4个字节大小的消息类型,而真正需要发送的数据则紧随其后。
发送端的程序如下:
int main(int argc, char **argv) {
if (argc != 2) {
error(1, 0, "usage: tcpclient <IPaddress>");
}
int socket_fd;
socket_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERV_PORT);
inet_pton(AF_INET, argv[1], &server_addr.sin_addr);
socklen_t server_len = sizeof(server_addr);
int connect_rt = connect(socket_fd, (struct sockaddr *) &server_addr, server_len);
if (connect_rt < 0) {
error(1, errno, "connect failed ");
}
struct {
u_int32_t message_length;
u_int32_t message_type;
char buf[128];
} message;
int n;
while (fgets(message.buf, sizeof(message.buf), stdin) != NULL) {
n = strlen(message.buf);
message.message_length = htonl(n);
message.message_type = 1;
if (send(socket_fd, (char *) &message, sizeof(message.message_length) + sizeof(message.message_type) + n, 0) <
0)
error(1, errno, "send failure");
}
exit(0);
}
程序的1-20行是常规的创建套接字和地址,建立连接的过程。我们重点往下看,21-25行就是图示的报文格式转化为结构体,29-37行从标准输入读入数据,分别对消息长度、类型进行了初始化,注意这里使用了htonl函数将字节大小转化为了网络字节顺序,这一点很重要。最后我们看到23行实际发送的字节流大小为消息长度4字节,加上消息类型4字节,以及标准输入的字符串大小。
下面给出的是服务器端的程序,和客户端不一样的是,服务器端需要对报文进行解析。
static int count;
static void sig_int(int signo) {
printf("\nreceived %d datagrams\n", count);
exit(0);
}
int main(int argc, char **argv) {
int listenfd;
listenfd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(SERV_PORT);
int on = 1;
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on));
int rt1 = bind(listenfd, (struct sockaddr *) &server_addr, sizeof(server_addr));
if (rt1 < 0) {
error(1, errno, "bind failed ");
}
int rt2 = listen(listenfd, LISTENQ);
if (rt2 < 0) {
error(1, errno, "listen failed ");
}
signal(SIGPIPE, SIG_IGN);
int connfd;
struct sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
if ((connfd = accept(listenfd, (struct sockaddr *) &client_addr, &client_len)) < 0) {
error(1, errno, "bind failed ");
}
char buf[128];
count = 0;
while (1) {
int n = read_message(connfd, buf, sizeof(buf));
if (n < 0) {
error(1, errno, "error read message");
} else if (n == 0) {
error(1, 0, "client closed \n");
}
buf[n] = 0;
printf("received %d bytes: %s\n", n, buf);
count++;
}
exit(0);
}
这个程序1-41行创建套接字,等待连接建立部分和前面基本一致。我们重点看42-55行的部分。45-55行循环处理字节流,调用read_message函数进行报文解析工作,并把报文的主体通过标准输出打印出来。
在了解read_message工作原理之前,我们先来看第5讲就引入的一个函数:readn。这里一定要强调的是readn函数的语义,读取报文预设大小的字节,readn调用会一直循环,尝试读取预设大小的字节,如果接收缓冲区数据空,readn函数会阻塞在那里,直到有数据到达。
size_t readn(int fd, void *buffer, size_t length) {
size_t count;
ssize_t nread;
char *ptr;
ptr = buffer;
count = length;
while (count > 0) {
nread = read(fd, ptr, count);
if (nread < 0) {
if (errno == EINTR)
continue;
else
return (-1);
} else if (nread == 0)
break; /* EOF */
count -= nread;
ptr += nread;
}
return (length - count); /* return >= 0 */
}
readn函数中使用count来表示还需要读取的字符数,如果count一直大于0,说明还没有满足预设的字符大小,循环就会继续。第9行通过read函数来服务最多count个字符。11-17行针对返回值进行出错判断,其中返回值为0的情形是EOF,表示对方连接终止。19-20行要读取的字符数减去这次读到的字符数,同时移动缓冲区指针,这样做的目的是为了确认字符数是否已经读取完毕。
有了readn函数作为基础,我们再看一下read_message对报文的解析处理:
size_t read_message(int fd, char *buffer, size_t length) {
u_int32_t msg_length;
u_int32_t msg_type;
int rc;
rc = readn(fd, (char *) &msg_length, sizeof(u_int32_t));
if (rc != sizeof(u_int32_t))
return rc < 0 ? -1 : 0;
msg_length = ntohl(msg_length);
rc = readn(fd, (char *) &msg_type, sizeof(msg_type));
if (rc != sizeof(u_int32_t))
return rc < 0 ? -1 : 0;
if (msg_length > length) {
return -1;
}
rc = readn(fd, buffer, msg_length);
if (rc != msg_length)
return rc < 0 ? -1 : 0;
return rc;
}
在这个函数中,第6行通过调用readn函数获取4个字节的消息长度数据,紧接着,第11行通过调用readn函数获取4个字节的消息类型数据。第15行判断消息的长度是不是太大,如果大到本地缓冲区不能容纳,则直接返回错误;第19行调用readn一次性读取已知长度的消息体。
我们依次启动作为报文解析的服务器一端,以及作为报文发送的客户端。我们看到,每次客户端发送的报文都可以被服务器端解析出来,在标准输出上的结果验证了这一点。
$./streamserver
received 8 bytes: network
received 5 bytes: good
$./streamclient
network
good
前面我提到了两种报文格式,另外一种报文格式就是通过设置特殊字符作为报文边界。HTTP是一个非常好的例子。
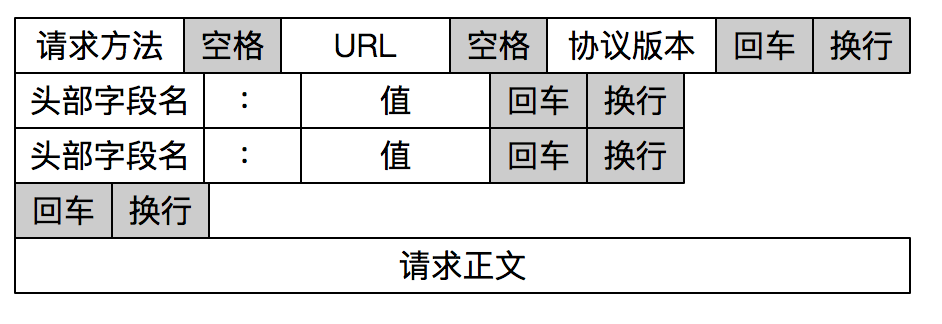
HTTP通过设置回车符、换行符作为HTTP报文协议的边界。
下面的read_line函数就是在尝试读取一行数据,也就是读到回车符\r,或者读到回车换行符\r\n为止。这个函数每次尝试读取一个字节,第9行如果读到了回车符\r,接下来在11行的“观察”下看有没有换行符,如果有就在第12行读取这个换行符;如果没有读到回车符,就在第16-17行将字符放到缓冲区,并移动指针。
int read_line(int fd, char *buf, int size) {
int i = 0;
char c = '\0';
int n;
while ((i < size - 1) && (c != '\n')) {
n = recv(fd, &c, 1, 0);
if (n > 0) {
if (c == '\r') {
n = recv(fd, &c, 1, MSG_PEEK);
if ((n > 0) && (c == '\n'))
recv(fd, &c, 1, 0);
else
c = '\n';
}
buf[i] = c;
i++;
} else
c = '\n';
}
buf[i] = '\0';
return (i);
}
和我们预想的不太一样,TCP数据流特性决定了字节流本身是没有边界的,一般我们通过显式编码报文长度的方式,以及选取特殊字符区分报文边界的方式来进行报文格式的设计。而对报文解析的工作就是要在知道报文格式的情况下,有效地对报文信息进行还原。
和往常一样,这里给你留两道思考题,供你消化今天的内容。
第一道题关于HTTP的报文格式,我们看到,既要处理只有回车的情景,也要处理同时有回车和换行的情景,你知道造成这种情况的原因是什么吗?
第二道题是,我们这里讲到的报文格式,和TCP分组的报文格式,有什么区别和联系吗?
欢迎你在评论区写下你的思考,也欢迎把这篇文章分享给你的朋友或者同事,与他们一起交流一下这两个问题吧。
评论