
第二种是非阻塞I/O。非阻塞的read请求在数据未准备好的情况下立即返回,应用程序可以不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲,并完成这次read调用。注意,这里最后一次read调用,获取数据的过程,是一个同步的过程。这里的同步指的是内核区域的数据拷贝到缓存区这个过程。
你好,我是盛延敏,这里是网络编程实战的第30讲,欢迎回来。
在性能篇的前几讲中,我们谈到了阻塞I/O、非阻塞I/O以及像select、poll、epoll等I/O多路复用技术,并在此基础上结合线程技术,实现了以事件分发为核心的reactor反应堆模式。你或许还听说过一个叫做Proactor的网络事件驱动模式,这个Proactor模式和reactor模式到底有什么区别和联系呢?在今天的内容中,我们先讲述异步I/O,再一起揭开以异步I/O为基础的proactor模式的面纱。
尽管在前面的课程中,多少都涉及到了阻塞、非阻塞、同步、异步的概念,但为了避免看见这些概念一头雾水,今天,我们就先来梳理一下这几个概念。
第一种是阻塞I/O。阻塞I/O发起的read请求,线程会被挂起,一直等到内核数据准备好,并把数据从内核区域拷贝到应用程序的缓冲区中,当拷贝过程完成,read请求调用才返回。接下来,应用程序就可以对缓冲区的数据进行数据解析。
第二种是非阻塞I/O。非阻塞的read请求在数据未准备好的情况下立即返回,应用程序可以不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲,并完成这次read调用。注意,这里最后一次read调用,获取数据的过程,是一个同步的过程。这里的同步指的是内核区域的数据拷贝到缓存区这个过程。
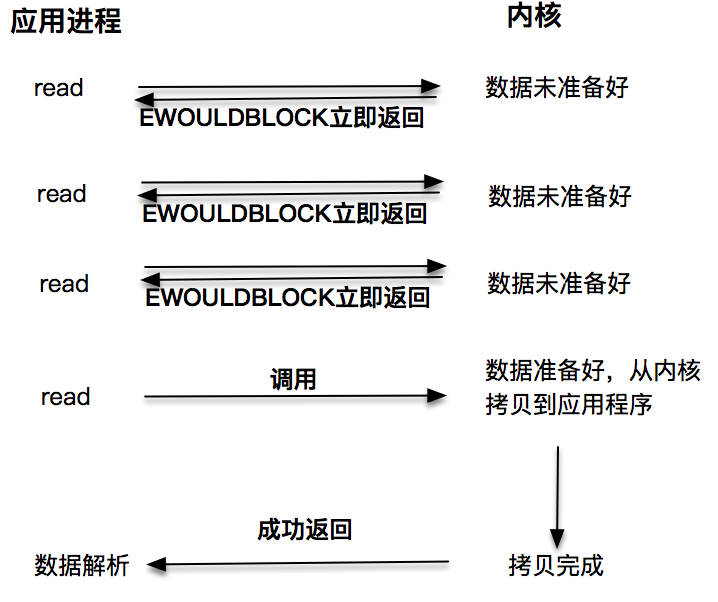
每次让应用程序去轮询内核的I/O是否准备好,是一个不经济的做法,因为在轮询的过程中应用进程啥也不能干。于是,像select、poll这样的I/O多路复用技术就隆重登场了。通过I/O事件分发,当内核数据准备好时,再通知应用程序进行操作。这个做法大大改善了应用进程对CPU的利用率,在没有被通知的情况下,应用进程可以使用CPU做其他的事情。
注意,这里read调用,获取数据的过程,也是一个同步的过程。
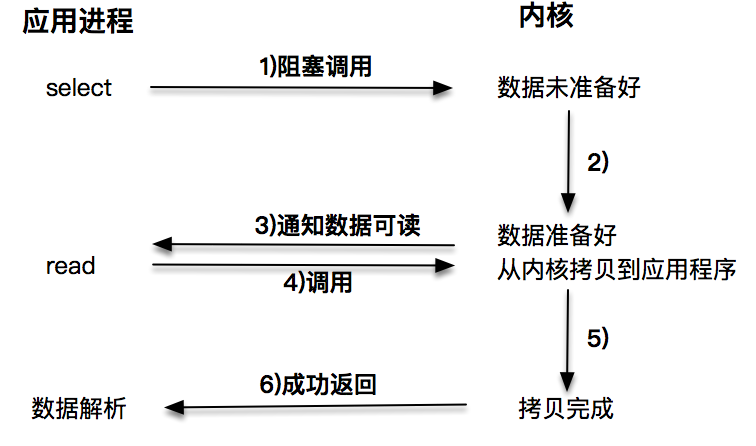
第一种阻塞I/O我想你已经比较了解了,在阻塞I/O的情况下,应用程序会被挂起,直到获取数据。第二种非阻塞I/O和第三种基于非阻塞I/O的多路复用技术,获取数据的操作不会被阻塞。
无论是第一种阻塞I/O,还是第二种非阻塞I/O,第三种基于非阻塞I/O的多路复用都是同步调用技术。为什么这么说呢?因为同步调用、异步调用的说法,是对于获取数据的过程而言的,前面几种最后获取数据的read操作调用,都是同步的,在read调用时,内核将数据从内核空间拷贝到应用程序空间,这个过程是在read函数中同步进行的,如果内核实现的拷贝效率很差,read调用就会在这个同步过程中消耗比较长的时间。
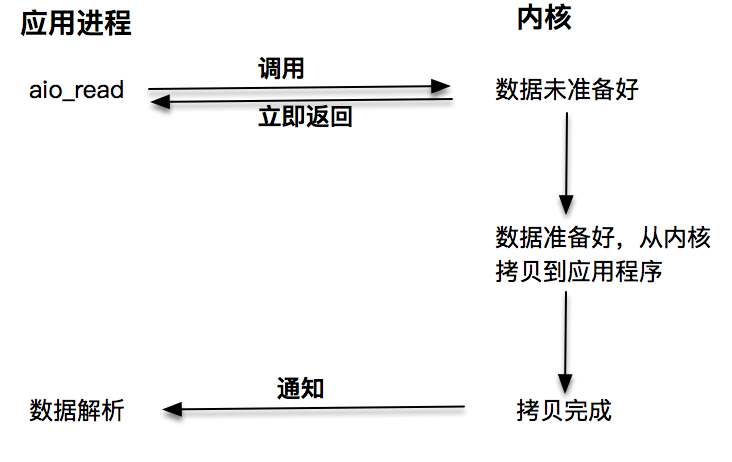
而真正的异步调用则不用担心这个问题,我们接下来就来介绍第四种I/O技术,当我们发起aio_read之后,就立即返回,内核自动将数据从内核空间拷贝到应用程序空间,这个拷贝过程是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。
还记得第22讲中讲到的去书店买书的例子吗? 基于这个例子,针对以上的场景,我们可以这么理解。
第一种阻塞I/O就是你去了书店,告诉老板你想要某本书,然后你就一直在那里等着,直到书店老板翻箱倒柜找到你想要的书。
第二种非阻塞I/O类似于你去了书店,问老板有没有一本书,老板告诉你没有,你就离开了。一周以后,你又来这个书店,再问这个老板,老板一查,有了,于是你买了这本书。
第三种基于非阻塞的I/O多路复用,你来到书店告诉老板:“老板,到货给我打电话吧,我再来付钱取书。”
第四种异步I/O就是你连去书店取书的过程也想省了,你留下地址,付了书费,让老板到货时寄给你,你直接在家里拿到就可以看了。
这里放置了一张表格,总结了以上几种I/O模型。

听起来,异步I/O有一种高大上的感觉。其实,异步I/O用起来倒是挺简单的。下面我们看一下一个具体的例子:
#include "lib/common.h"
#include <aio.h>
const int BUF_SIZE = 512;
int main() {
int err;
int result_size;
// 创建一个临时文件
char tmpname[256];
snprintf(tmpname, sizeof(tmpname), "/tmp/aio_test_%d", getpid());
unlink(tmpname);
int fd = open(tmpname, O_CREAT | O_RDWR | O_EXCL, S_IRUSR | S_IWUSR);
if (fd == -1) {
error(1, errno, "open file failed ");
}
char buf[BUF_SIZE];
struct aiocb aiocb;
//初始化buf缓冲,写入的数据应该为0xfafa这样的,
memset(buf, 0xfa, BUF_SIZE);
memset(&aiocb, 0, sizeof(struct aiocb));
aiocb.aio_fildes = fd;
aiocb.aio_buf = buf;
aiocb.aio_nbytes = BUF_SIZE;
//开始写
if (aio_write(&aiocb) == -1) {
printf(" Error at aio_write(): %s\n", strerror(errno));
close(fd);
exit(1);
}
//因为是异步的,需要判断什么时候写完
while (aio_error(&aiocb) == EINPROGRESS) {
printf("writing... \n");
}
//判断写入的是否正确
err = aio_error(&aiocb);
result_size = aio_return(&aiocb);
if (err != 0 || result_size != BUF_SIZE) {
printf(" aio_write failed() : %s\n", strerror(err));
close(fd);
exit(1);
}
//下面准备开始读数据
char buffer[BUF_SIZE];
struct aiocb cb;
cb.aio_nbytes = BUF_SIZE;
cb.aio_fildes = fd;
cb.aio_offset = 0;
cb.aio_buf = buffer;
// 开始读数据
if (aio_read(&cb) == -1) {
printf(" air_read failed() : %s\n", strerror(err));
close(fd);
}
//因为是异步的,需要判断什么时候读完
while (aio_error(&cb) == EINPROGRESS) {
printf("Reading... \n");
}
// 判断读是否成功
int numBytes = aio_return(&cb);
if (numBytes != -1) {
printf("Success.\n");
} else {
printf("Error.\n");
}
// 清理文件句柄
close(fd);
return 0;
}
这个程序展示了如何使用aio系列函数来完成异步读写。主要用到的函数有:
这个程序一开始使用aio_write方法向内核提交了一个异步写文件的操作。第23-27行是这个异步写操作的结构体。结构体aiocb是应用程序和操作系统内核传递的异步申请数据结构,这里我们使用了文件描述符、缓冲区指针aio_buf以及需要写入的字节数aio_nbytes。
struct aiocb {
int aio_fildes; /* File descriptor */
off_t aio_offset; /* File offset */
volatile void *aio_buf; /* Location of buffer */
size_t aio_nbytes; /* Length of transfer */
int aio_reqprio; /* Request priority offset */
struct sigevent aio_sigevent; /* Signal number and value */
int aio_lio_opcode; /* Operation to be performed */
};
这里我们用了一个0xfa的缓冲区,这在后面的演示中可以看到结果。
30-34行向系统内核申请了这个异步写操作,并且在37-39行查询异步动作的结果,当其结束时在42-48行判断写入的结果是否正确。
紧接着,我们使用了aio_read从文件中读取这些数据。为此,我们准备了一个新的aiocb结构体,告诉内核需要把数据拷贝到buffer这个缓冲区中,和异步写一样,发起异步读之后在第65-67行一直查询异步读动作的结果。
接下来运行这个程序,我们看到屏幕上打印出一系列的字符,显示了这个操作是有内核在后台帮我们完成的。
./aio01
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
writing...
Reading...
Reading...
Reading...
Reading...
Reading...
Reading...
Reading...
Reading...
Reading...
Success.
打开/tmp目录下的aio_test_xxxx文件,可以看到,这个文件成功写入了我们期望的数据。
请注意,以上的读写,都不需要我们在应用程序里再发起调用,系统内核直接帮我们做好了。
aio系列函数是由POSIX定义的异步操作接口,可惜的是,Linux下的aio操作,不是真正的操作系统级别支持的,它只是由GNU libc库函数在用户空间借由pthread方式实现的,而且仅仅针对磁盘类I/O,套接字I/O不支持。
也有很多Linux的开发者尝试在操作系统内核中直接支持aio,例如一个叫做Ben LaHaise的人,就将aio实现成功merge到2.5.32中,这部分能力是作为patch存在的,但是,它依旧不支持套接字。
Solaris倒是有真正的系统系别的aio,不过还不是很确定它在套接字上的性能表现,特别是和磁盘I/O相比效果如何。
综合以上结论就是,Linux下对异步操作的支持非常有限,这也是为什么使用epoll等多路分发技术加上非阻塞I/O来解决Linux下高并发高性能网络I/O问题的根本原因。
和Linux不同,Windows下实现了一套完整的支持套接字的异步编程接口,这套接口一般被叫做IOCompletetionPort(IOCP)。
这样,就产生了基于IOCP的所谓Proactor模式。
和Reactor模式一样,Proactor模式也存在一个无限循环运行的event loop线程,但是不同于Reactor模式,这个线程并不负责处理I/O调用,它只是负责在对应的read、write操作完成的情况下,分发完成事件到不同的处理函数。
这里举一个HTTP服务请求的例子来说明:
从这个例子可以看出,由于系统内核提供了真正的“异步”操作,Proactor不会再像Reactor一样,每次感知事件后再调用read、write方法完成数据的读写,它只负责感知事件完成,并由对应的handler发起异步读写请求,I/O读写操作本身是由系统内核完成的。和前面看到的aio的例子一样,这里需要传入数据缓冲区的地址等信息,这样,系统内核才可以自动帮我们把数据的读写工作完成。
无论是Reactor模式,还是Proactor模式,都是一种基于事件分发的网络编程模式。Reactor模式是基于待完成的I/O事件,而Proactor模式则是基于已完成的I/O事件,两者的本质,都是借由事件分发的思想,设计出可兼容、可扩展、接口友好的一套程序框架。
和同步I/O相比,异步I/O的读写动作由内核自动完成,不过,在Linux下目前仅仅支持简单的基于本地文件的aio异步操作,这也使得我们在编写高性能网络程序时,首选Reactor模式,借助epoll这样的I/O分发技术完成开发;而Windows下的IOCP则是一种异步I/O的技术,并由此产生了和Reactor齐名的Proactor模式,借助这种模式,可以完成Windows下高性能网络程序设计。
和往常一样,给你布置两道思考题:
欢迎你在评论区写下你的思考,也欢迎把这篇文章分享给你的朋友或者同事,一起交流进步一下。