你好,我是盛延敏,这里是网络编程实战的第35讲,欢迎回来。
这一篇文章是实战篇的答疑部分,也是本系列的最后一篇文章。非常感谢你的积极评论与留言,让每一篇文章的留言区都成为学习互动的好地方。在今天的内容里,我将针对评论区的问题做一次集中回答,希望能帮助你解决前面碰到的一些问题。
有关这部分内容,我将采用Q&A的形式来展开。
这个问题具体描述是下面这样的。
当应用程序需要发送数据时,比如下面这段,在完成数据读取和回应的编码之后,会调用tcp_connection_send_buffer方法发送数据。
//数据读到buffer之后的callback
int onMessage(struct buffer *input, struct tcp_connection *tcpConnection) {
printf("get message from tcp connection %s\n", tcpConnection->name);
printf("%s", input->data);
struct buffer *output = buffer_new();
int size = buffer_readable_size(input);
for (int i = 0; i < size; i++) {
buffer_append_char(output, rot13_char(buffer_read_char(input)));
}
tcp_connection_send_buffer(tcpConnection, output);
return 0;
}
而tcp_connection_send_buffer方法则会调用tcp_connection_send_data来发送数据:
int tcp_connection_send_buffer(struct tcp_connection *tcpConnection, struct buffer *buffer) {
int size = buffer_readable_size(buffer);
int result = tcp_connection_send_data(tcpConnection, buffer->data + buffer->readIndex, size);
buffer->readIndex += size;
return result;
}
在tcp_connection_send_data中,如果发现当前 channel 没有注册 WRITE 事件,并且当前 tcp_connection 对应的发送缓冲无数据需要发送,就直接调用 write 函数将数据发送出去。
//应用层调用入口
int tcp_connection_send_data(struct tcp_connection *tcpConnection, void *data, int size) {
size_t nwrited = 0;
size_t nleft = size;
int fault = 0;
struct channel *channel = tcpConnection->channel;
struct buffer *output_buffer = tcpConnection->output_buffer;
//先往套接字尝试发送数据
if (!channel_write_event_is_enabled(channel) && buffer_readable_size(output_buffer) == 0) {
nwrited = write(channel->fd, data, size);
if (nwrited >= 0) {
nleft = nleft - nwrited;
} else {
nwrited = 0;
if (errno != EWOULDBLOCK) {
if (errno == EPIPE || errno == ECONNRESET) {
fault = 1;
}
}
}
}
if (!fault && nleft > 0) {
//拷贝到Buffer中,Buffer的数据由框架接管
buffer_append(output_buffer, data + nwrited, nleft);
if (!channel_write_event_is_enabled(channel)) {
channel_write_event_enable(channel);
}
}
return nwrited;
}
这里有同学不是很理解,为啥不能做成无论有没有 WRITE 事件都统一往发送缓冲区写,再把WRITE 事件注册到event_loop中呢?
这个问题问得非常好。我觉得有必要展开讲讲。
如果用一句话来总结的话,这是为了发送效率。
我们来分析一下,应用层读取数据,进行编码,之后的这个buffer对象是应用层创建的,数据也在应用层这个buffer对象上。你可以理解,tcp_connection_send_data里面的data数据其实是应用层缓冲的,而不是我们tcp_connection这个对象里面的buffer。
如果我们跳过直接往套接字发送这一段,而是把数据交给我们的tcp_connection对应的output_buffer,这里有一个数据拷贝的过程,它发生在buffer_append里面。
int buffer_append(struct buffer *buffer, void *data, int size) {
if (data != NULL) {
make_room(buffer, size);
//拷贝数据到可写空间中
memcpy(buffer->data + buffer->writeIndex, data, size);
buffer->writeIndex += size;
}
}
但是,如果增加了一段判断来直接往套接字发送,其实就跳过了这段拷贝,直接把数据发往到了套接字发生缓冲区。
//先往套接字尝试发送数据
if (!channel_write_event_is_enabled(channel) && buffer_readable_size(output_buffer) == 0) {
nwrited = write(channel->fd, data, size)
...
在绝大部分场景下,这种处理方式已经满足数据发送的需要了,不再需要把数据拷贝到tcp_connection对象中的output_buffer中。
如果不满足直接往套接字发送的条件,比如已经注册了回调事件,或者output_buffer里面有数据需要发送,那么就把数据拷贝到output_buffer中,让event_loop的回调不断地驱动handle_write将数据从output_buffer发往套接字缓冲区中。
//发送缓冲区可以往外写
//把channel对应的output_buffer不断往外发送
int handle_write(void *data) {
struct tcp_connection *tcpConnection = (struct tcp_connection *) data;
struct event_loop *eventLoop = tcpConnection->eventLoop;
assertInSameThread(eventLoop);
struct buffer *output_buffer = tcpConnection->output_buffer;
struct channel *channel = tcpConnection->channel;
ssize_t nwrited = write(channel->fd, output_buffer->data + output_buffer->readIndex,buffer_readable_size(output_buffer));
if (nwrited > 0) {
//已读nwrited字节
output_buffer->readIndex += nwrited;
//如果数据完全发送出去,就不需要继续了
if (buffer_readable_size(output_buffer) == 0) {
channel_write_event_disable(channel);
}
//回调writeCompletedCallBack
if (tcpConnection->writeCompletedCallBack != NULL) {
tcpConnection->writeCompletedCallBack(tcpConnection);
}
} else {
yolanda_msgx("handle_write for tcp connection %s", tcpConnection->name);
}
}
你可以这样想象,在一个非常高效的处理条件下,你需要发送什么,都直接发送给了套接字缓冲区;而当网络条件变差,处理效率变慢,或者待发送的数据极大,一次发送不可能完成的时候,这部分数据被框架缓冲到tcp_connection的发送缓冲区对象output_buffer中,由事件分发机制来负责把这部分数据发送给套接字缓冲区。
在epoll-server-multithreads.c里面定义了很多回调函数,比如onMessage, onConnectionCompleted等,这些回调函数被用于创建一个TCPServer,但是在tcp_connection对照中,又实现了handle_read handle_write 等事件的回调,似乎有两层回调,为什么要这样封装两层回调呢?
这里如果说回调函数,确实有两个不同层次的回调函数。
第一个层次是框架定义的,对连接的生命周期管理的回调。包括连接建立完成后的回调、报文读取并接收到output缓冲区之后的回调、报文发送到套接字缓冲区之后的回调,以及连接关闭时的回调。分别是connectionCompletedCallBack、messageCallBack、writeCompletedCallBack,以及connectionClosedCallBack。
struct tcp_connection {
struct event_loop *eventLoop;
struct channel *channel;
char *name;
struct buffer *input_buffer; //接收缓冲区
struct buffer *output_buffer; //发送缓冲区
connection_completed_call_back connectionCompletedCallBack;
message_call_back messageCallBack;
write_completed_call_back writeCompletedCallBack;
connection_closed_call_back connectionClosedCallBack;
void * data; //for callback use: http_server
void * request; // for callback use
void * response; // for callback use
};
为什么要定义这四个回调函数呢?
因为框架需要提供给应用程序和框架的编程接口,我把它总结为编程连接点,或者叫做program-hook-point。就像是设计了一个抽象类,这个抽象类代表了框架给你提供的一个编程入口,你可以继承这个抽象类,完成一些方法的填充,这些方法和框架类一起工作,就可以表现出一定符合逻辑的行为。
比如我们定义一个抽象类People,这个类的其他属性,包括它的创建和管理都可以交给框架来完成,但是你需要完成两个函数,一个是on_sad,这个人悲伤的时候干什么;另一个是on_happy,这个人高兴的时候干什么。
abstract class People{
void on_sad();
void on_happy();
}
这样,我们可以试着把tcp_connection改成这样:
abstract class TCP_connection{
void on_connection_completed();
void on_message();
void on_write_completed();
void on_connectin_closed();
}
这个层次的回调,更像是一层框架和应用程序约定的接口,接口实现由应用程序来完成,框架负责在合适的时候调用这些预定义好的接口,回调的意思体现在“框架会调用预定好的接口实现”。
比如,当连接建立成功,一个新的connection创建出来,connectionCompletedCallBack函数会被回调:
struct tcp_connection *
tcp_connection_new(int connected_fd, struct event_loop *eventLoop,
connection_completed_call_back connectionCompletedCallBack,
connection_closed_call_back connectionClosedCallBack,
message_call_back messageCallBack,
write_completed_call_back writeCompletedCallBack) {
...
// add event read for the new connection
struct channel *channel1 = channel_new(connected_fd, EVENT_READ, handle_read, handle_write, tcpConnection);
tcpConnection->channel = channel1;
//connectionCompletedCallBack callback
if (tcpConnection->connectionCompletedCallBack != NULL) {
tcpConnection->connectionCompletedCallBack(tcpConnection);
}
...
}
第二个层次的回调,是基于epoll、poll事件分发机制的回调。通过注册一定的读、写事件,在实际事件发生时,由事件分发机制保证对应的事件回调函数被及时调用,完成基于事件机制的网络I/O处理。
在每个连接建立之后,创建一个对应的channel对象,并为这个channel对象赋予了读、写回调函数:
// add event read for the new connection
struct channel *channel1 = channel_new(connected_fd, EVENT_READ, handle_read, handle_write, tcpConnection);
handle_read函数,对应用程序屏蔽了套接字的读操作,把数据缓冲到tcp_connection的input_buffer中,而且,它还起到了编程连接点和框架的耦合器的作用,这里分别调用了messageCallBack和connectionClosedCallBack函数,完成了应用程序编写部分代码在框架的“代入”。
int handle_read(void *data) {
struct tcp_connection *tcpConnection = (struct tcp_connection *) data;
struct buffer *input_buffer = tcpConnection->input_buffer;
struct channel *channel = tcpConnection->channel;
if (buffer_socket_read(input_buffer, channel->fd) > 0) {
//应用程序真正读取Buffer里的数据
if (tcpConnection->messageCallBack != NULL) {
tcpConnection->messageCallBack(input_buffer, tcpConnection);
}
} else {
handle_connection_closed(tcpConnection);
}
}
handle_write函数则负责把tcp_connection对象里的output_buffer源源不断地送往套接字发送缓冲区。
//发送缓冲区可以往外写
//把channel对应的output_buffer不断往外发送
int handle_write(void *data) {
struct tcp_connection *tcpConnection = (struct tcp_connection *) data;
struct event_loop *eventLoop = tcpConnection->eventLoop;
assertInSameThread(eventLoop);
struct buffer *output_buffer = tcpConnection->output_buffer;
struct channel *channel = tcpConnection->channel;
ssize_t nwrited = write(channel->fd, output_buffer->data + output_buffer->readIndex,buffer_readable_size(output_buffer));
if (nwrited > 0) {
//已读nwrited字节
output_buffer->readIndex += nwrited;
//如果数据完全发送出去,就不需要继续了
if (buffer_readable_size(output_buffer) == 0) {
channel_write_event_disable(channel);
}
//回调writeCompletedCallBack
if (tcpConnection->writeCompletedCallBack != NULL) {
tcpConnection->writeCompletedCallBack(tcpConnection);
}
} else {
yolanda_msgx("handle_write for tcp connection %s", tcpConnection->name);
}
}
tcp_connection对象似乎和channel对象有着非常紧密的联系,为什么要单独设计一个tcp_connection呢?
我也提到了,开始的时候我并不打算设计一个tcp_connection对象的,后来我才发现非常有必要存在一个tcp_connection对象。
第一,我需要在暴露给应用程序的onMessage,onConnectionCompleted等回调函数里,传递一个有用的数据结构,这个数据结构必须有一定的现实语义,可以携带一定的信息,比如套接字、缓冲区等,而channel对象过于单薄,和连接的语义相去甚远。
第二,这个channel对象是抽象的,比如acceptor,比如socketpair等,它们都是一个channel,只要能引起事件的发生和传递,都是一个channel,基于这一点,我也觉得最好把chanel作为一个内部实现的细节,不要通过回调函数暴露给应用程序。
第三,在后面实现HTTP的过程中,我发现需要在上下文中保存http_request和http_response数据,而这个部分数据放在channel中是非常不合适的,所以才有了最后的tcp_connection对象。
struct tcp_connection {
struct event_loop *eventLoop;
struct channel *channel;
char *name;
struct buffer *input_buffer; //接收缓冲区
struct buffer *output_buffer; //发送缓冲区
connection_completed_call_back connectionCompletedCallBack;
message_call_back messageCallBack;
write_completed_call_back writeCompletedCallBack;
connection_closed_call_back connectionClosedCallBack;
void * data; //for callback use: http_server
void * request; // for callback use
void * response; // for callback use
};
简单总结下来就是,每个tcp_connection对象一定包含了一个channel对象,而channel对象未必是一个tcp_connection对象。
有人在加锁这里有个疑问,如果加锁的目的是让主线程等待子线程初始化event_loop,那不加锁不是也可以达到这个目的吗?主线程while循环里面不断判断子线程的event_loop是否不为null不就可以了?为什么一定要加一把锁呢?
//由主线程调用,初始化一个子线程,并且让子线程开始运行event_loop
struct event_loop *event_loop_thread_start(struct event_loop_thread *eventLoopThread) {
pthread_create(&eventLoopThread->thread_tid, NULL, &event_loop_thread_run, eventLoopThread);
assert(pthread_mutex_lock(&eventLoopThread->mutex) == 0);
while (eventLoopThread->eventLoop == NULL) {
assert(pthread_cond_wait(&eventLoopThread->cond, &eventLoopThread->mutex) == 0);
}
assert(pthread_mutex_unlock(&eventLoopThread->mutex) == 0);
yolanda_msgx("event loop thread started, %s", eventLoopThread->thread_name);
return eventLoopThread->eventLoop;
}
要回答这个问题,就要解释多线程下共享变量竞争的问题。我们知道,一个共享变量在多个线程下同时作用,如果没有锁的控制,就会引起变量的不同步。这里的共享变量就是每个eventLoopThread的eventLoop对象。
这里如果我们不加锁,一直循环判断每个eventLoopThread的状态,会对CPU增加很大的消耗,如果使用锁-信号量的方式来加以解决,就变得很优雅,而且不会对CPU造成过多的影响。
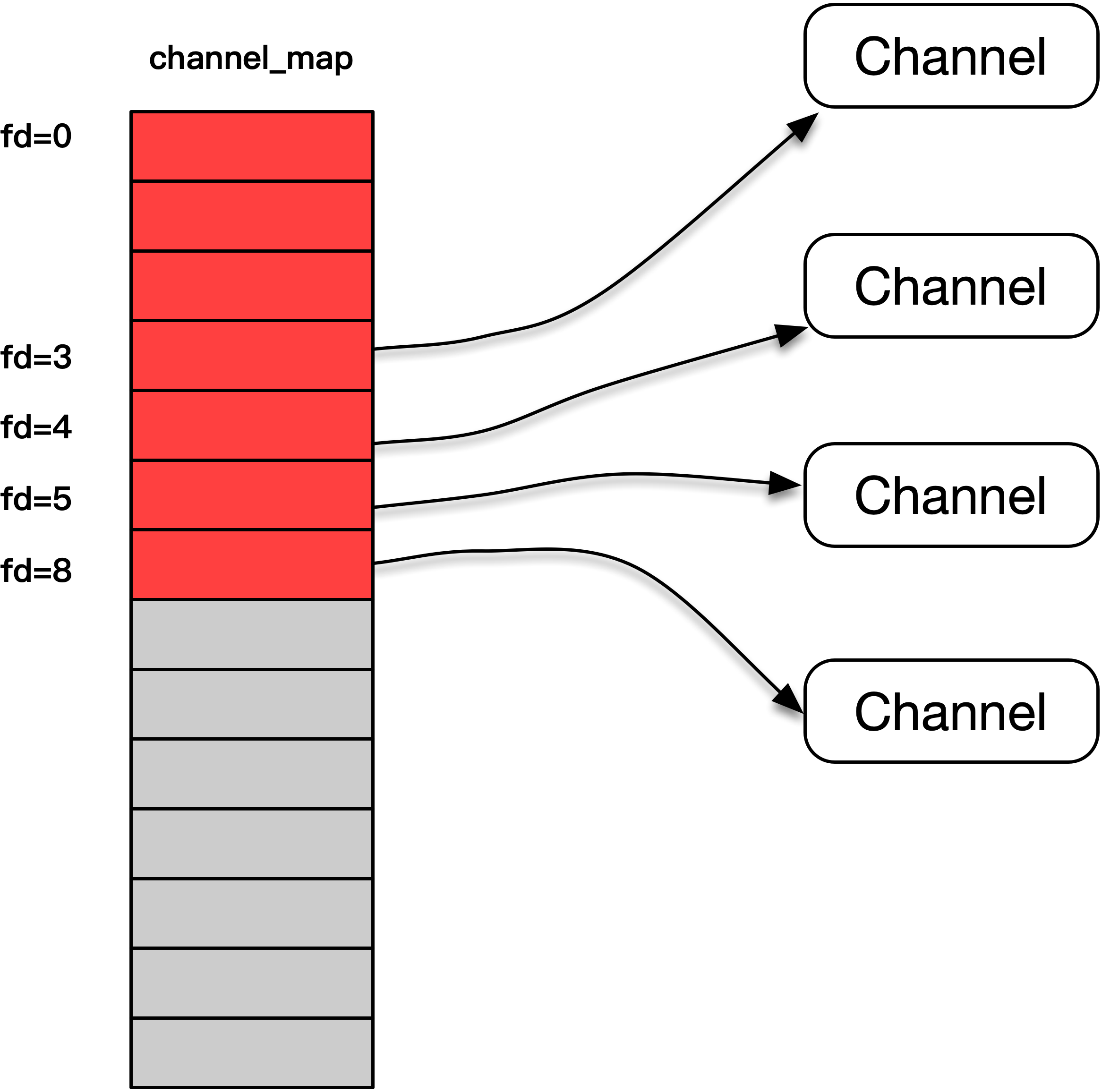
我们来详细介绍一下channel_map。
channel_map实际上是一个指针数组,这个数组里面的每个元素都是一个指针,指向了创建出的channel对象。我们用数据下标和套接字进行了映射,这样虽然有些元素是浪费了,比如stdin,stdout,stderr代表的套接字0、1和2,但是总体效率是非常高的。
你在这里可以看到图中描绘了channel_map的设计。
而且,我们的channel_map还不会太占用内存,在最开始的时候,整个channel_map的指针数组大小为0,当这个channel_map投入使用时,会根据实际使用的套接字的增长,按照32、64、128这样的速度成倍增长,这样既保证了实际的需求,也不会一下子占用太多的内存。
此外,当指针数组增长时,我们不会销毁原来的部分,而是使用realloc()把旧的内容搬过去,再使用memset() 用来给新申请的内存初始化为0值,这样既高效也节省内存。
以上就是实战篇中一些同学的疑问。
在这篇文章之后,我们的专栏就告一段落了,我希望这个专栏可以帮你梳理清楚高性能网络编程的方方面面,如果你能从中有所领悟,或者帮助你在面试中拿到好的结果,我会深感欣慰。
如果你觉得今天的答疑内容对你有所帮助,欢迎把它转发给你的朋友或者同事,一起交流一下。
评论