你好,我是Chrono。
如果按照前几节课的惯例,今天应该是讲运行阶段的。但是,运行阶段跟前面的编码、预处理和编译阶段不同,它是动态的、实时的,内外部环境非常复杂,CPU、内存、磁盘、信号、网络套接字……各种资源交织在一起,可谓千变万化(正如我在第1节课里所说,每一个阶段的差异都非常大)。
解决这个阶段面临的问题已经不是编程技术了,更多的是要依靠各种调试、分析、日志工具,比如GDB、Valgrind、Systemtap等。
所以,我觉得把这些运行阶段的工具、技巧放在课程前面不是太合适,咱们还是往后延一延,等把C++的核心知识点都学完了,再来看它比较好。
那么,今天要和你聊哪些内容呢?
我想了想,还是讲讲“面向对象编程”(Object Oriented Programming)吧。毕竟,它是C++诞生之初“安身立命”的看家本领,也是C++的核心编程范式。
不管我们是否喜欢,“面向对象”早就已经成为了编程界的共识和主流。C++、Java、Python等流行的语言,无一不支持面向对象编程,而像Pascal、BASIC、PHP那样早期面向过程的语言,在发展过程中也都增加了对它的支持,新出的Go、Swift、Rust就更不用说了。
毫无疑问,掌握“面向对象编程”是现在程序员的基本素养。但落到实际开发时,每个人对它的理解程度却有深有浅,应用的水平也有高有低,有的人设计出的类精致灵活,而有的人设计出来的却是粗糙笨重。
细想起来,“面向对象”里面可以研究的地方实在是太多了。那么,到底“面向对象”的精髓是什么?怎样才能用好它?怎样才能写出一个称得上是“好”的类呢?
所以,今天我就从设计思想、实现原则和编码准则这几个角度谈谈我对它的体会心得,以及在C++里应用的一些经验技巧,帮你写出更高效、更安全、更灵活的类。(在第19、20课,我还会具体讲解,到时候你可以参考下。)
首先要说的是,虽然很多语言都内建语法支持面向对象编程,但它本质上是一种设计思想、方法,与语言细节无关,要点是抽象(Abstraction)和封装(Encapsulation)。
掌握了这种代码之外的思考方式,就可以“高屋建瓴”,站在更高的维度上去设计程序,不会被语言、语法所限制。
所以,即使是像C这样“纯”面向过程的编程语言,也能够应用面向对象的思想,以struct实现抽象和封装,得到良好的程序结构。
面向对象编程的基本出发点是“对现实世界的模拟”,把问题中的实体抽象出来,封装为程序里的类和对象,这样就在计算机里为现实问题建立了一个“虚拟模型”。
然后以这个模型为基础不断演化,继续抽象对象之间的关系和通信,再用更多的对象去描述、模拟……直到最后,就形成了一个由许多互相联系的对象构成的系统。
把这个系统设计出来、用代码实现出来,就是“面向对象编程”了。
不过,因为现实世界非常复杂,“面向对象编程”作为一种工程方法,是不可能完美模拟的,纯粹的面向对象也有一些缺陷,其中最明显的就是“继承”。
“继承”的本意是重用代码,表述类型的从属关系(Is-A),但它却不能与现实完全对应,所以用起来就会出现很多意外情况。
比如那个著名的长方形的例子。Rectangle表示长方形,Square继承Rectangle,表示正方形。现在问题就来了,这个关系在数学中是正确的,但表示为代码却不太正确。长方形可以用成员函数单独变更长宽,但正方形却不行,长和宽必须同时变更。
还有那个同样著名的鸟类的例子。基类Bird有个Fly方法,所有的鸟类都应该继承它。但企鹅、鸵鸟这样的鸟类却不会飞,实现它们就必须改写Fly方法。
各种编程语言为此都加上了一些“补丁”,像C++就有“多态”“虚函数”“重载”,虽然解决了“继承”的问题,但也使代码复杂化了,一定程度上扭曲了“面向对象”的本意。
说了些“高大上”的理论,是不是有点犯迷糊?没关系,下面,我就在C++里细化一下。
就像我刚才说的,“面向对象编程”的关键点是“抽象”和“封装”,而“继承”“多态”并不是核心,只能算是附加品。
所以,我建议你在设计类的时候尽量少用继承和虚函数。
特别的,如果完全没有继承关系,就可以让对象不必承受“父辈的重担”(父类成员、虚表等额外开销),轻装前行,更小更快。没有隐含的重用代码也会降低耦合度,让类更独立,更容易理解。
还有,把“继承”切割出去之后,可以避免去记忆、实施那一大堆难懂的相关规则,比如public/protected/private继承方式的区别、多重继承、纯虚接口类、虚析构函数,还可以绕过动态转型、对象切片、函数重载等很多危险的陷阱,减少冗余代码,提高代码的健壮性。
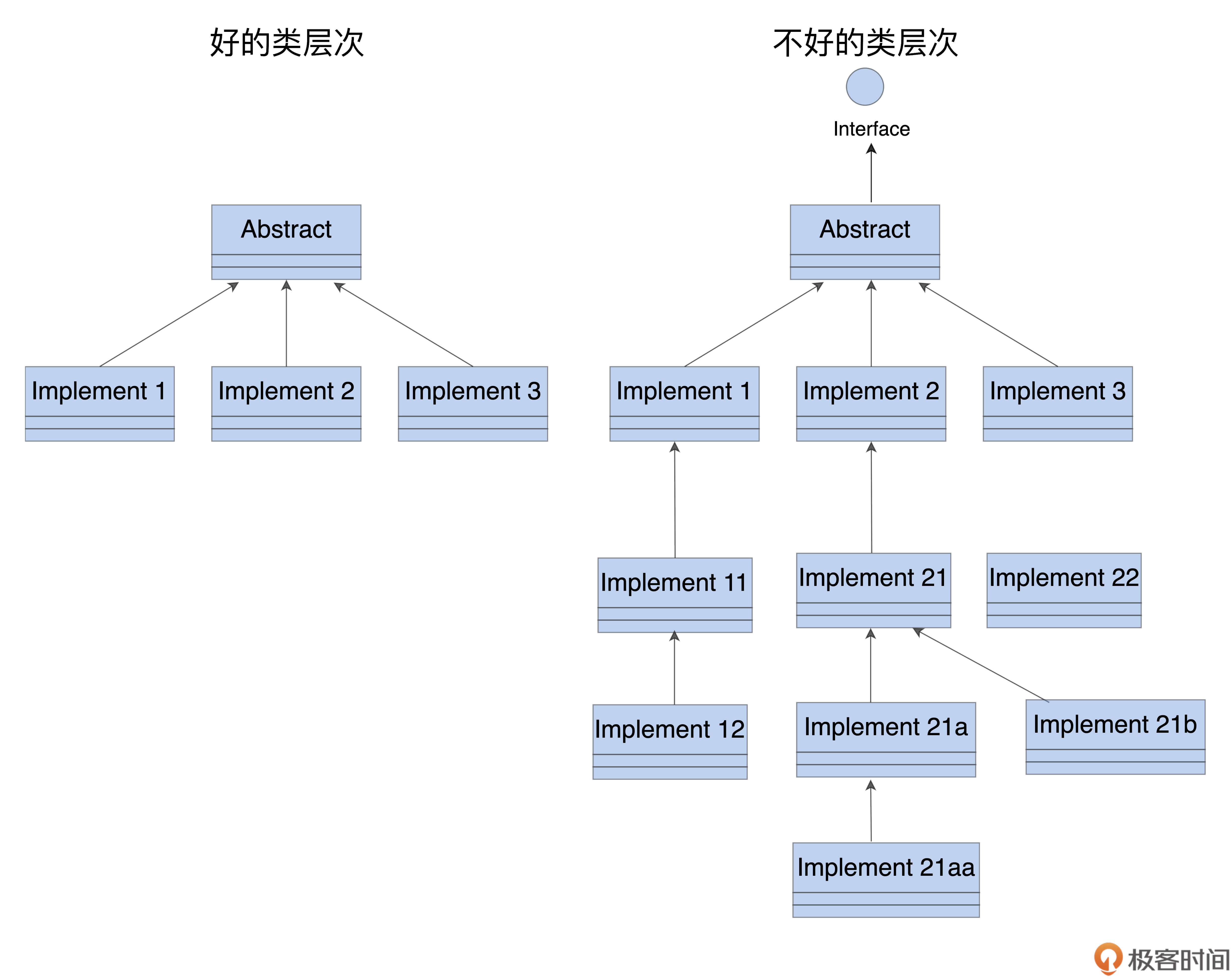
如果非要用继承不可,那么我觉得一定要控制继承的层次,用UML画个类体系的示意图来辅助检查。如果继承深度超过三层,就说明有点“过度设计”了,需要考虑用组合关系替代继承关系,或者改用模板和泛型。
在设计类接口的时候,我们也要让类尽量简单、“短小精悍”,只负责单一的功能。
如果很多功能混在了一起,出现了“万能类”“意大利面条类”(有时候也叫God Class),就要应用设计模式、重构等知识,把大类拆分成多个各负其责的小类。
我还看到过很多人有一种不好的习惯,就是喜欢在类内部定义一些嵌套类,美其名曰“高内聚”。但恰恰相反,这些内部类反而与上级类形成了强耦合关系,也是另一种形式的“万能类”。
其实,这本来是名字空间该做的事情,用类来实现就有点“越权”了。正确的做法应该是,定义一个新的名字空间,把内部类都“提”到外面,降低原来类的耦合度和复杂度。
有了这些实现原则,下面我再来讲几个编码时的细节,从安全和性能方面帮你改善类的代码。
C++11新增了一个特殊的标识符“final”(注意,它不是关键字),把它用于类定义,就可以显式地禁用继承,防止其他人有意或者无意地产生派生类。无论是对人还是对编译器,效果都非常好,我建议你一定要积极使用。
class DemoClass final // 禁止任何人继承我
{ ... };
在必须使用继承的场合,建议你只使用public继承,避免使用virtual、protected,因为它们会让父类与子类的关系变得难以捉摸,带来很多麻烦。当到达继承体系底层时,也要及时使用“final”,终止继承关系。
class Interface // 接口类定义,没有final,可以被继承
{ ... };
class Implement final : // 实现类,final禁止再被继承
public Interface // 只用public继承
{ ... };
C++里类的四大函数你一定知道吧,它们是构造函数、析构函数、拷贝构造函数、拷贝赋值函数。C++11因为引入了右值(Rvalue)和转移(Move),又多出了两大函数:转移构造函数和转移赋值函数。所以,在现代C++里,一个类总是会有六大基本函数:三个构造、两个赋值、一个析构。
好在C++编译器会自动为我们生成这些函数的默认实现,省去我们重复编写的时间和精力。但我建议,对于比较重要的构造函数和析构函数,应该用“= default”的形式,明确地告诉编译器(和代码阅读者):“应该实现这个函数,但我不想自己写。”这样编译器就得到了明确的指示,可以做更好的优化。
class DemoClass final
{
public:
DemoClass() = default; // 明确告诉编译器,使用默认实现
~DemoClass() = default; // 明确告诉编译器,使用默认实现
};
这种“= default”是C++11新增的专门用于六大基本函数的用法,相似的,还有一种“= delete”的形式。它表示明确地禁用某个函数形式,而且不限于构造/析构,可以用于任何函数(成员函数、自由函数)。
比如说,如果你想要禁止对象拷贝,就可以用这种语法显式地把拷贝构造和拷贝赋值“delete”掉,让外界无法调用。
class DemoClass final
{
public:
DemoClass(const DemoClass&) = delete; // 禁止拷贝构造
DemoClass& operator=(const DemoClass&) = delete; // 禁止拷贝赋值
};
因为C++有隐式构造和隐式转型的规则,如果你的类里有单参数的构造函数,或者是转型操作符函数,为了防止意外的类型转换,保证安全,就要使用“explicit”将这些函数标记为“显式”。
class DemoClass final
{
public:
explicit DemoClass(const string_type& str) // 显式单参构造函数
{ ... }
explicit operator bool() // 显式转型为bool
{ ... }
};
C++11里还有很多能够让类更优雅的新特性,这里我从“投入产出比”的角度出发,挑出了三个我最喜欢的特性,给你介绍一下,让你不用花太多力气就能很好地改善代码质量。
第一个是“委托构造”(delegating constructor)。
如果你的类有多个不同形式的构造函数,为了初始化成员肯定会有大量的重复代码。为了避免重复,常见的做法是把公共的部分提取出来,放到一个init()函数里,然后构造函数再去调用。这种方法虽然可行,但效率和可读性较差,毕竟init()不是真正的构造函数。
在C++11里,你就可以使用“委托构造”的新特性,一个构造函数直接调用另一个构造函数,把构造工作“委托”出去,既简单又高效。
class DemoDelegating final
{
private:
int a; // 成员变量
public:
DemoDelegating(int x) : a(x) // 基本的构造函数
{}
DemoDelegating() : // 无参数的构造函数
DemoDelegating(0) // 给出默认值,委托给第一个构造函数
{}
DemoDelegating(const string& s) : // 字符串参数构造函数
DemoDelegating(stoi(s)) // 转换成整数,再委托给第一个构造函数
{}
};
第二个是“成员变量初始化”(In-class member initializer)。
如果你的类有很多成员变量,那么在写构造函数的时候就比较麻烦,必须写出一长串的名字来逐个初始化,不仅不美观,更危险的是,容易“手抖”,遗漏成员,造成未初始化的隐患。
而在C++11里,你可以在类里声明变量的同时给它赋值,实现初始化,这样不但简单清晰,也消除了隐患。
class DemoInit final // 有很多成员变量的类
{
private:
int a = 0; // 整数成员,赋值初始化
string s = "hello"; // 字符串成员,赋值初始化
vector<int> v{1, 2, 3}; // 容器成员,使用花括号的初始化列表
public:
DemoInit() = default; // 默认构造函数
~DemoInit() = default; // 默认析构函数
public:
DemoInit(int x) : a(x) {} // 可以单独初始化成员,其他用默认值
};
第三个是“类型别名”(Type Alias)。
C++11扩展了关键字using的用法,增加了typedef的能力,可以定义类型别名。它的格式与typedef正好相反,别名在左边,原名在右边,是标准的赋值形式,所以易写易读。
using uint_t = unsigned int; // using别名
typedef unsigned int uint_t; // 等价的typedef
在写类的时候,我们经常会用到很多外部类型,比如标准库里的string、vector,还有其他的第三方库和自定义类型。这些名字通常都很长(特别是带上名字空间、模板参数),书写起来很不方便,这个时候我们就可以在类里面用using给它们起别名,不仅简化了名字,同时还能增强可读性。
class DemoClass final
{
public:
using this_type = DemoClass; // 给自己也起个别名
using kafka_conf_type = KafkaConfig; // 外部类起别名
public:
using string_type = std::string; // 字符串类型别名
using uint32_type = uint32_t; // 整数类型别名
using set_type = std::set<int>; // 集合类型别名
using vector_type = std::vector<std::string>;// 容器类型别名
private:
string_type m_name = "tom"; // 使用类型别名声明变量
uint32_type m_age = 23; // 使用类型别名声明变量
set_type m_books; // 使用类型别名声明变量
private:
kafka_conf_type m_conf; // 使用类型别名声明变量
};
类型别名不仅能够让代码规范整齐,而且因为引入了这个“语法层面的宏定义”,将来在维护时还可以随意改换成其他的类型。比如,把字符串改成string_view(C++17里的字符串只读视图),把集合类型改成unordered_set,只要变动别名定义就行了,原代码不需要做任何改动。
今天我们谈了“面向对象编程”,这节课的内容也比较多,我划一下重点。
所谓“仁者见仁智者见智”,今天我讲的也只能算是我自己的经验、体会。到底要怎么用,你还是要看自己的实际情况,千万不要完全照搬。
这次的课下作业时间,我给你留两个思考题:
欢迎你在留言区写下你的思考和答案,如果觉得今天的内容对你有所帮助,也欢迎分享给你的朋友。我们下节课见。

评论